[CS224n] Lecture 7 : Machine Translation, Sequence-to-sequence and Attention
<요약>
Machine Translation의 발전과정과 그 과정에 있던 SMT(Statistical Machine Translation)에 대해서 알아보고, NMT(Neural Machine Translation)의 문제점과 이를 해결하는 Attention을 학습할 예정이다.
-
통계적 기계번역(SMT) : NMT 이전의 방식
-
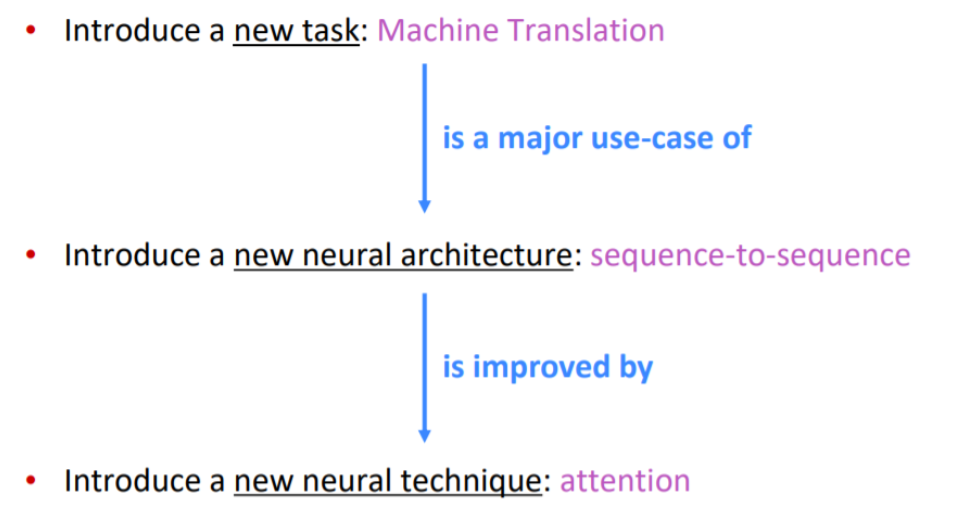
새로운 neural architecture 소개 : 기계 번역의 한계를 극복한, NMT에서 사용한 방식인 "sequence-to-sequence"
-
새로운 neural technique 소개 : Seq2Seq 병목현상을 극복한 "Attention"
1. Machine Translation
Pre-Neural Machine Translation

Machine Translation (MT) 은
한 언어의 문장을(x: source language) → 목표 언어의 문장(y: target language)으로 번역하는 작업이다.
시대에 따라 기계 번역의 번역 방법이 어떠한 방식으로 계속 바뀌었는지 알아봅시다.

기계 번역(Machine Translation)은 1950년대 초에 시작되었다.
특히 당시 냉전시대 서구는 러시아인의 말을 알고 싶어 했기 때문에, 러시아어를 영어로 번역하는 작업이 많았다. 그리고 당시 번역은 대부분 Rule-Based 방식이었다. 이중 언어 사전을 큰 이중 사전에 저장하여 검색해 찾아내는 단순한 방식이다.

1990년 초부터는 통계적 기계번역 Statistical Machine Translation(SMT)이 시작되었다.
SMT의 중심 아이디어는 번역을 수행하기 위해 데이터에서 확률 모델을 배우는 것이다. 즉, 데이터를 통해 확률을 가장 높이는 방법으로 번역을 한다.
예를 들어, 프랑스어 문장 x가 주어졌을 때 가장 좋은 영어 문장 y를 찾고 싶다는 아이디어가 있다면, 수학적으로 x가 주어졌을 때 y의 조건부 확률 P의 argmax y를 찾는 것으로 공식화할 수 있다.
argmaxyP(y∣x) : 주어진 문장 x에 대해 최적의 y를 찾는 문제
베이지안 rule을 이용해서 이 식을 두개의 component로 나눌 수 있다.
-P(x∣y) Translation Model : 단어와 구가 어떻게 번역되어야 하는지를 학습. 번역의 정확성에 초점을 둠 (fidelity : 충실도)
-P(y) Language Model : 다음 sequence of words의 probability를 의미. 좋은 문장 구조와 단어 위치에 초점을 둠 (fluency : 유창함)

번역 모델 P(x∣y)을 학습하기 위해서는 많은 양의 병렬 데이터가 필요하다.
병렬 말뭉치의 예는 아주 예전의 Rosetta Stone이 있다.

a, alignment라는 개념을 넣어서 x와 주어진 y에 대한 a의 조건부 확률로 표현한다.
a(alignment)는 source sentence x와 target sentence y에 대해 얼마나 correspond 한지 나타내는 값이다.
영어와 프랑스 문장에 어떠한 대응을 하는지 4가지 정렬을 통해 알아봅시다.

One-to-one alignment로써, 정확히 같은 순서로 대응된다.
하지만 프랑스어에서 여성형 단수를 의미하는 “Le”와 같은 spurious word는 대응 관계가 없다.
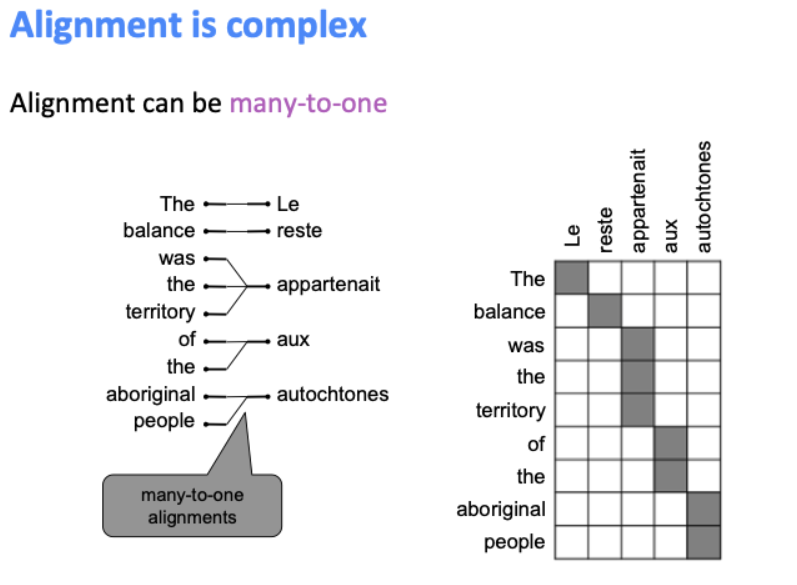
Many-to-one이 될 수도 있다.
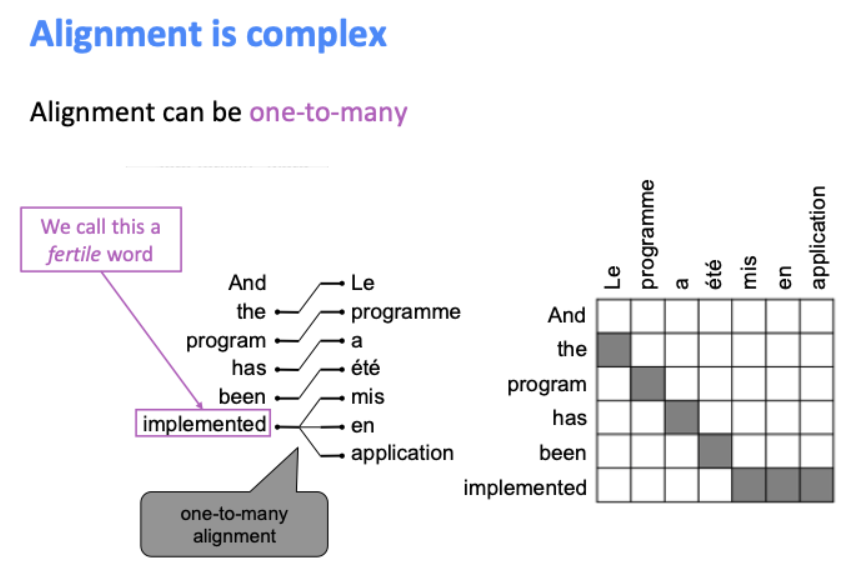
반대로 one-to-many가 될 수도 있으며, 이런 단어를 fertile word라고 한다.
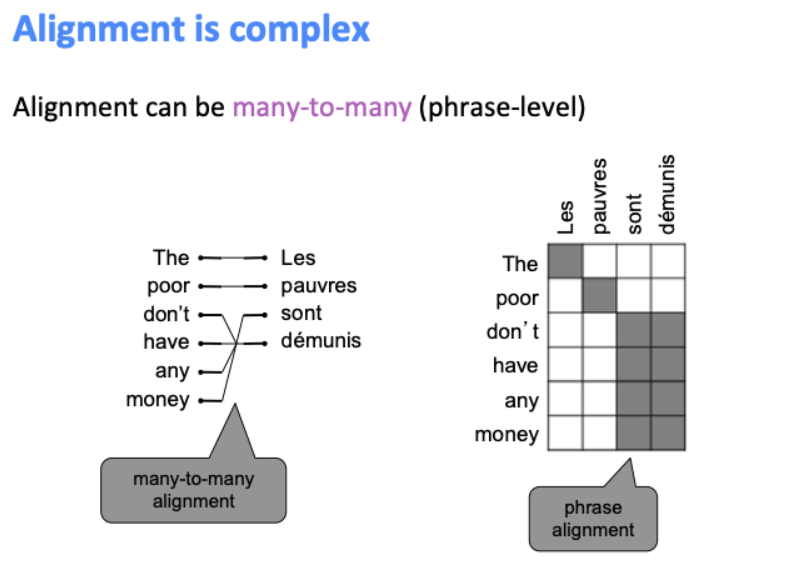
Many-to-many 또한 가능하다.
이렇게 가능한 게 많은 경우에는 alignment를 어떻게 학습시킬 수 있을까가 고민이다.
이를 해결하기 위하여 'x와 y가 주어졌을 때 a의 조건부 확률'을 배운다.
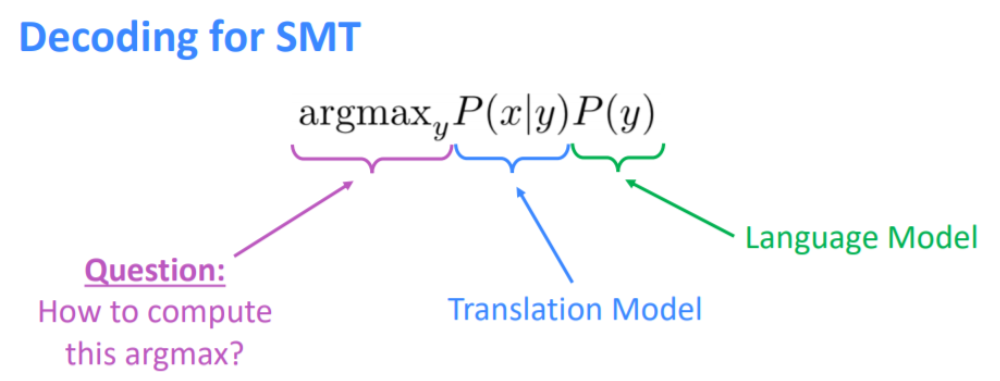
번역 모델과 언어 모델을 학습 시킨 뒤, 어떻게 y에 대해 argmax를 수행하는지가 문제이다.
한 가지 방법으로는 "가능한 모든 y를 열거"한다는 것이다. 하지만 비용이 비싸고, 각 단계마다 많은 가설을 유지하고 있는지를 확인하며 가지치기를 하게 된다. 높은 확률 위주의 가지들을 쳐내가는 최상의 시퀀스를 찾는 프로세스를 디코딩이라고 한다.
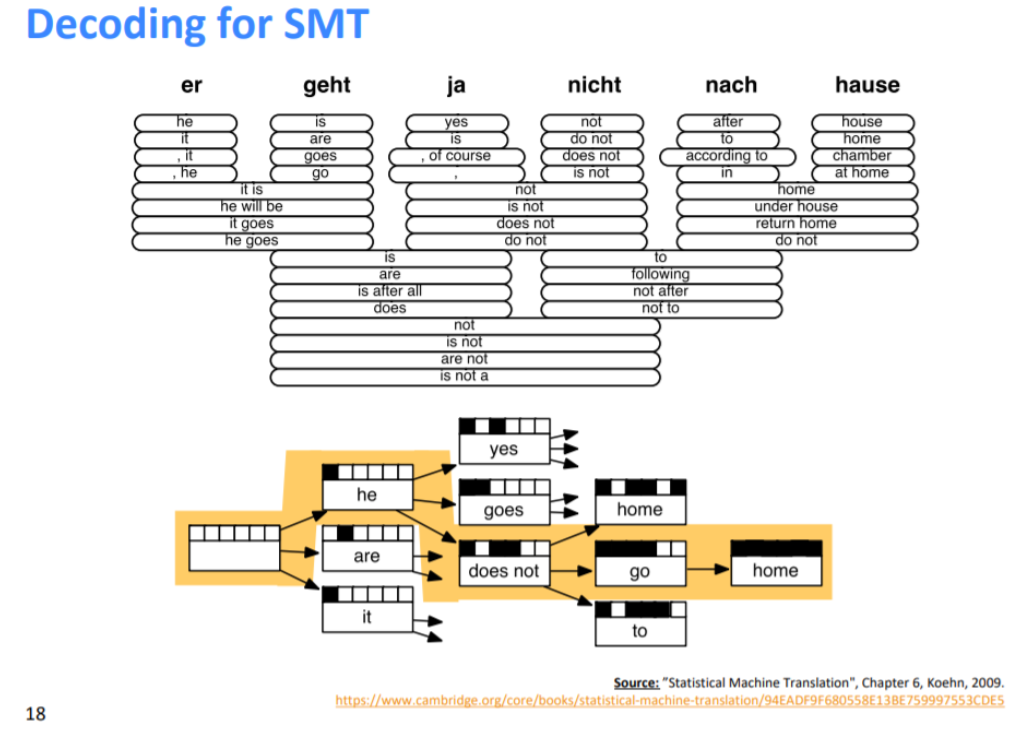
디코딩이 SMT에서 동작하는 개요는 개별 단어를 어떻게 번역할 수 있는지에서 확장하여 개별 구문 번역으로, 마지막으로는 전체 문장으로 확장한다.
즉 확률이 높은 단어를 선택한 후, 확률 낮은 구문을 제거하면서 높은 확률로 가는 형식이다.

통계적 기계 번역(SMT)는 1990- 정교하고 인상적인 시스템이었지만 너무 복잡하고 리소스 유지 등에 인간의 노력이 매우 필요하다.
2. Neural Machine Translation "Sequence to Sequence"

Neural Machine Translation (NMT)는 말 그대로 단일 신경망으로 기계 번역을 수행하는 방법이다.
여기서 신경망은 seq2seq라고 불리며 2개의 RNN을 포함한다.
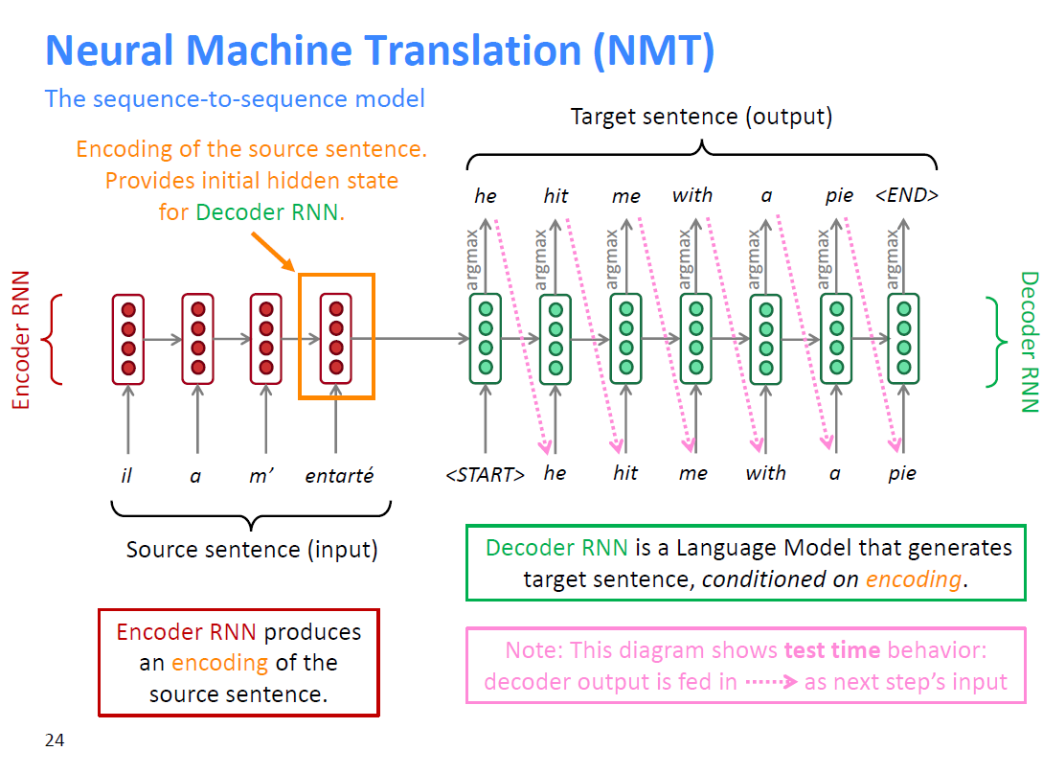
먼저 Encoder RNN은 소스 문장의 인코딩을 생성한다.
소스 문장에서 마지막 단어의 output(orange box)이 Decoder RNN의 초기 hidden state 값이 된다.
Decoder RNN은 조건부 언어 모델이며, conditional이 앞에 붙는 이유는 인코딩에 의해 조건화된 출력 값(orange box)에 의해 target sentence가 생성되기 때문이다.
Decoder의 시작 토큰 'START'를 디코더에 주입하고 계산을 통해 예측하는데 이용되는 hidden state에 소스 문장의 인코딩 값을 사용한다.
이렇게 디코더로부터 첫번째 출력을 얻고, 다음에 어떤 단어가 나올지 확률분포를 구한다. 그것을 argmax를 취하여 예측 단어를 얻는다.
디코더가 최종 토큰을 만들어낼 때까지 이 작업을 반복하고, 멈추게 된다.
여기서 일어나는 모든 일들은 TEST TIME에서 일어나는 일이다.

Seq2seq는 다양하게 사용된다.
- 요약 (긴 문장 → 짧은 문장)
- 대화 (이전 발화 → 다음 발화를 예측)
- parsing (input 텍스트 → 시퀀스로써 output parse로)
- 코드 생성 (일반 언어 → 파이썬 코드로)

sequence to sequence 모델은 조건부 언어 모델이다.
디코더에서 y가 주어졌을 때 다음 문장을 예측하여 문장을 만드는 언어 모델이고, 인코더의 output에 의해 예측이 가능하니까 조건부이다.
NMT 모델의 학습 방법은 큰 병렬 말뭉치를 얻는 것이다. 아래에서 자세히 보겠다.
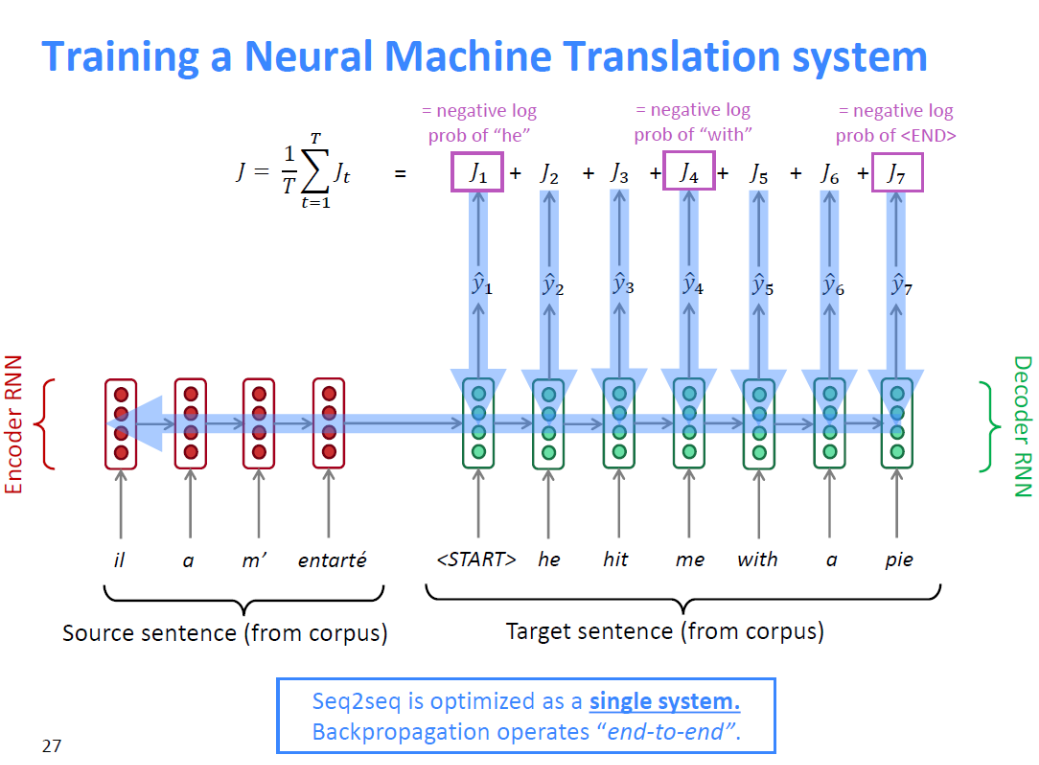
먼저 큰 병렬 말뭉치에서 문장 쌍을 얻는다. 소스 문장을 인코더 RNN에 넣고, 타겟 문장을 디코더 RNN에 입력하고, 인코더 RNN의 final hidden state를 디코더의 initial hidden state로 입력한다. 그리고 디코더 RNN의 모든 단계에서 다음에 올 확률분포 Y HAT의 손실을 계산합니다. 손실은 교차 엔트로피 등으로 계산할 수 있으며 손실들을 모두 더해 단계 수로 나누어 최종 LOSS 값을 구한다. END-TO-END 방식으로 학습하는 게 문장 요소를 모두 고려해 좋은 결과물을 도출한다고 합니다. 즉, backpropagation이 '전체 시스템을 통해서 흐른다는 것'이고, 이 단일 손실에 대해서는 전체 시스템이 학습한다는 점이다.
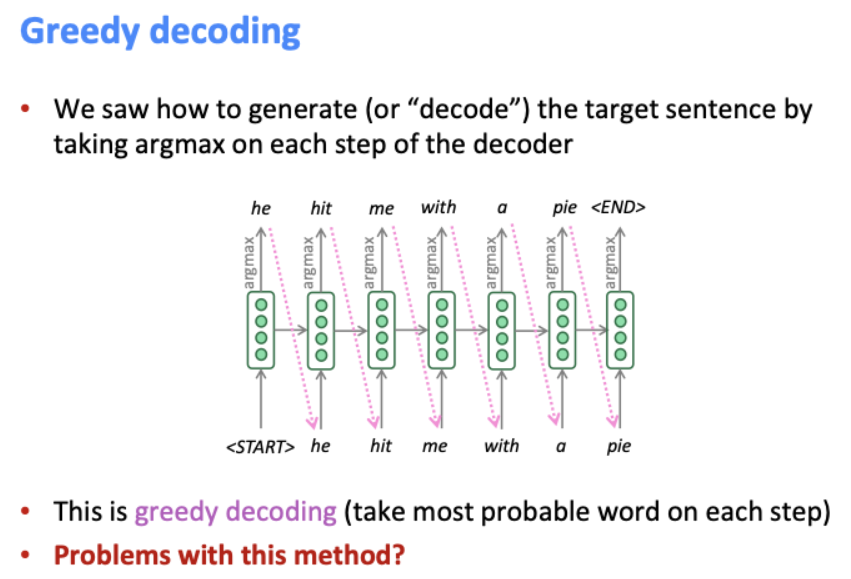
여기서 문제는 greedy decoding이 발생한다는 점이다.
확률이 가장 높은 단어를 단계마다 도출하다보니, 한 번 선택하면 다시 돌아갈(다른 단어를 선택할) 방법이 없다.

첫번째 해결 방법으로는, 모든 확률을 따져 최적의 결과를 출력하는 방법이다. 하지만 시간도 오래 걸리고 비용도 크다는 단점이 있다.
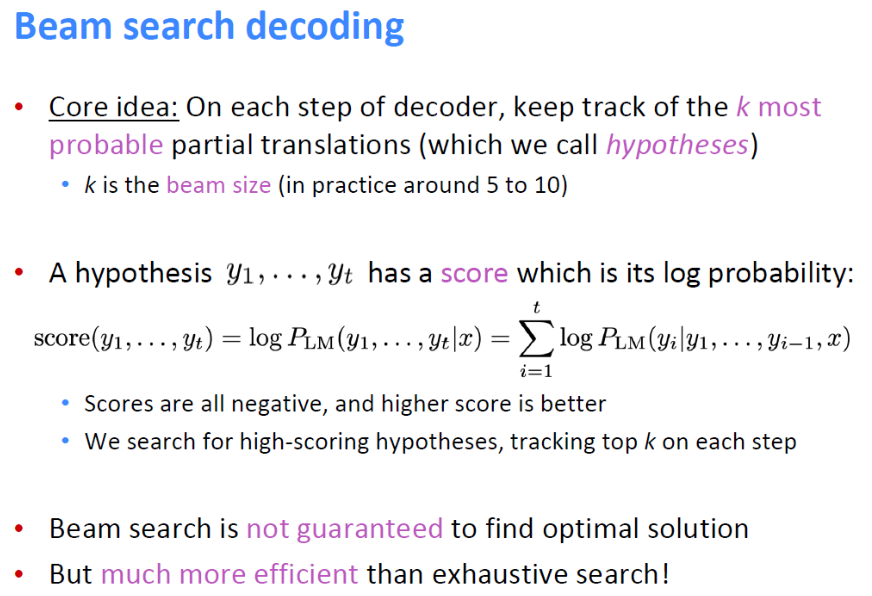
두번째 해결 방법으로는, 빔 검색 디코딩 방법이다.
빔 검색 디코딩 방법의 핵심 아이디어는 "디코더의 각 단계에서 k 개(k는 beam size)의 가장 가능성 있는 부분(=가설) 번역을 추적한다" 이다. score로 가설의 성능을 평가하는데, score는 x(소스문장) 즉, 이전 번역 단어들이 주어질 때 현재 단어가 올 확률의 로그 값을 모두 더한 값이 된다. score는 높을수록 좋다.

SMT와 비교해 NMT의 장점
1. 성능이 낫다.
더 유창하고, 문맥 표현이 더 낫고, 구문의 유사성에 따른 성능이 더 좋다.
2. end-to-end로 최적화할 수 있는 단일 신경망이라는 점
SMT처럼 개별적으로 최적화해야 하는 subcomponent들이 없다는 점에서 훨씬 편리하다는 점
3. 인간의 노력이 덜 든다
feature engineering을 할 필요가 없고, 모든 언어 쌍에 대해 거의 동일한 방법이 사용된다.

SMT와 비교해 NMT의 단점
1. 해석력이 낮다
end-to-end 방식으로 내부에서 어떤 방식으로 학습이 이루어지는지 디버깅이 상대적으로 힘들다는 점
2. 다루기 힘들다
SMT에서는 규칙을 정하여 프로그래밍하면 되었지만, NMT 시스템에는 단계별로 수행 작업을 정의할 수는 없다. NMT 시스템에서는 특정한 나쁜 단어를 말하는 것에 대해서 제어하기 힘들다는 의미이다.

NMT의 주로 사용되는 평가 지표로는 BLEU이다.
기계 번역 시스템에서 생성된 번역과 사람이 적은 번역을 n-gram precision, 짧은 문장에 대한 페널티를 부과하는 등을 기반으로 하는 similarity score를 구한다.
BLEU는 유용하지만 완벽하지는 않다는 점을 유의해야 한다.
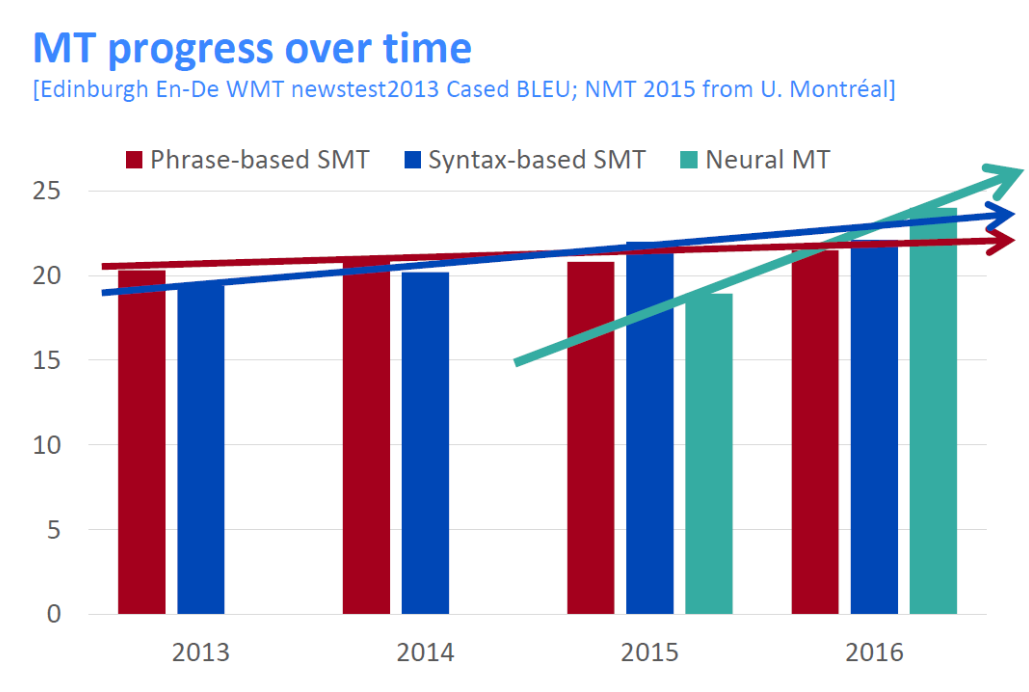
BLEU 스코어로 NMT 가 얼마나 단기간에 발전했는지를 알 수 있다.
빨간, 파란 막대 그래프는 두 종류의 SMT의 발전 속도에 비해 NMT는 1년 사이에 기존 시스템의 score를 넘어선 것처럼 아주 빠르게 진행되었다. NMT는 NLP 딥러닝에서 큰 성과를 보였다.
하지만 NMT로 기계번역 분야는 모두 해결되지는 않았다. 사용하려는 분야가 다를 때 발생하는 문제, 긴 문장에서의 문맥 유지 등의 문제들이 발생할 수 있다.
3. Attention
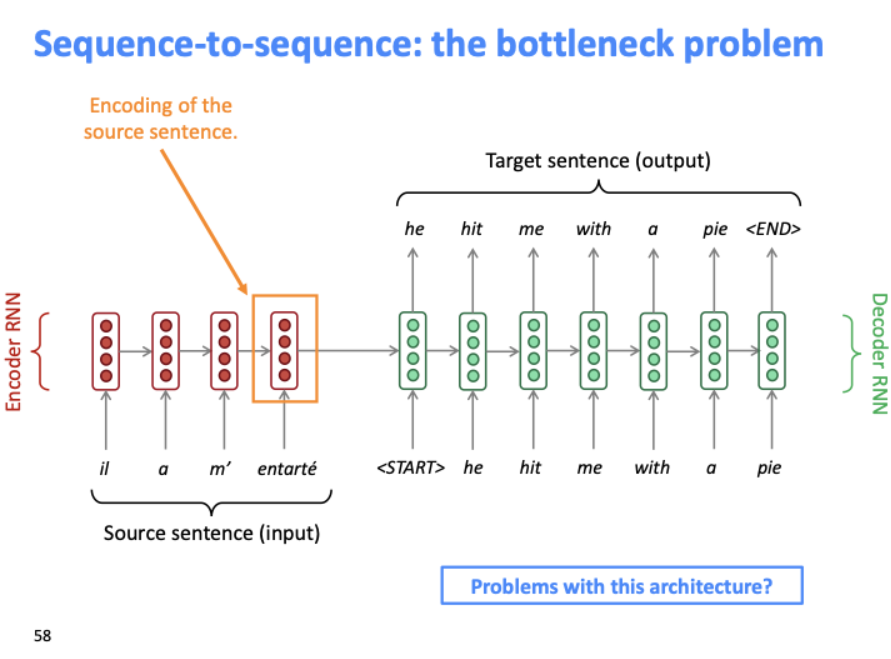
seq-to-seq의 문제점은 인코더의 마지막 벡터(orange box)가 전체 소스 문장을 대표하고 있다. 모든 소스 문장의 내용이 이 벡터에 캡처되기를 집중하고 있는 구조가 문제점이다.
그리하여 Attention이 이 병목현상의 문제점을 해결할 솔루션을 제공한다. 각 단계의 디코더에서 소스 문장의 특정 부분에 집중하기 위해 인코더에 직접 연결을 사용하는 것이다.
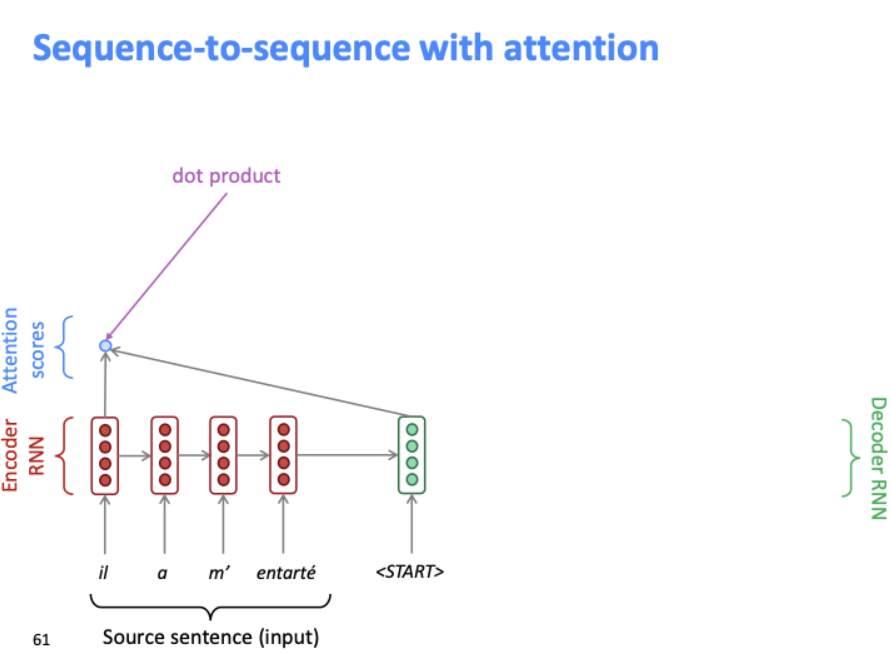
디코더의 첫번째 은닉 상태와 인코더의 첫번째 은닉 상태를 내적 곱하는 것으로 attention score를 얻는다. attention score는 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현시점의 은닉 상태와 얼마나 유사한지를 판단하는 스코어 값이다.
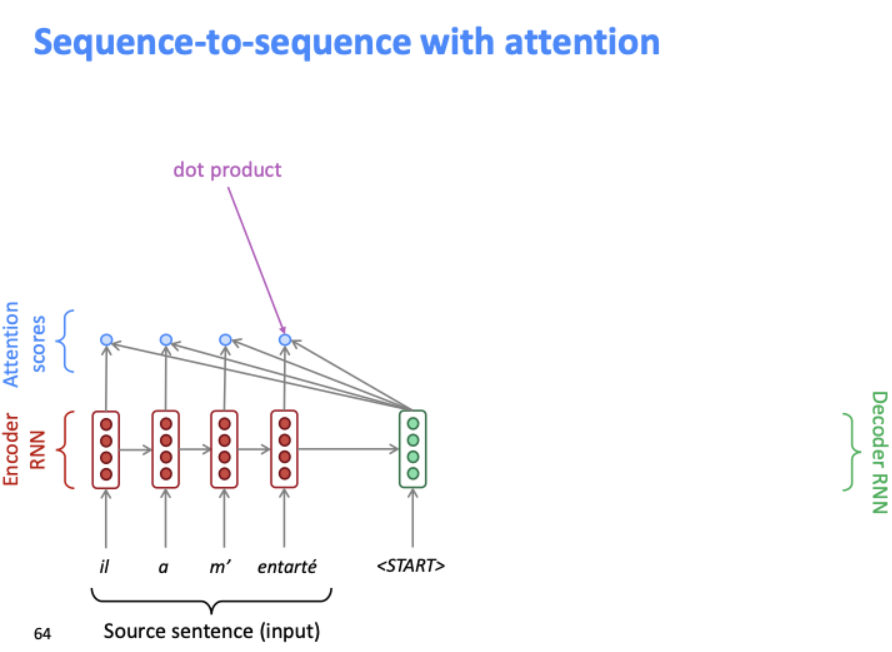
각 소스 단어(은닉 상태)마다 하나의 attention score를 얻는다.
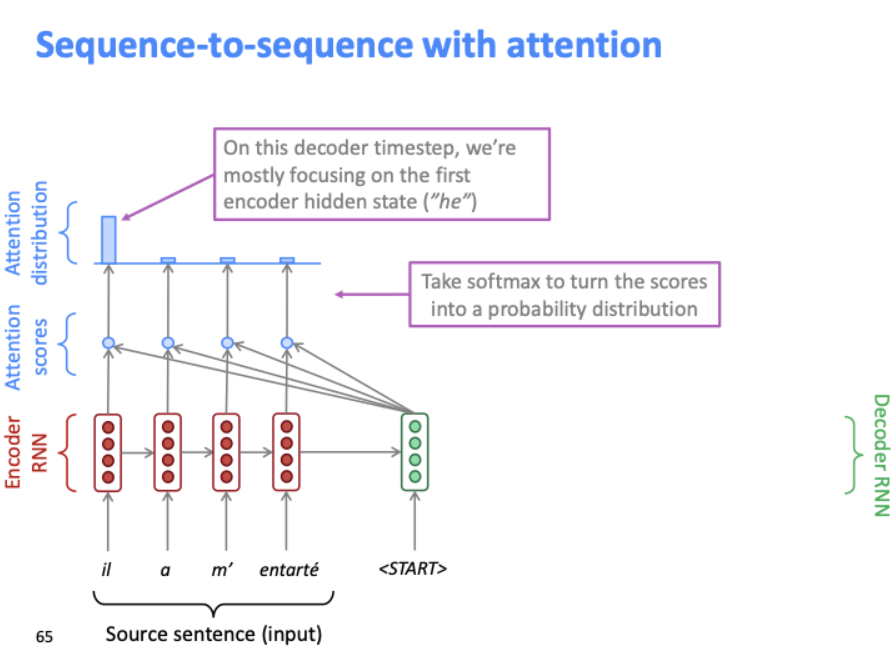
디코더의 첫번째 은닉 상태에 대해 소스 단어들의 attention score가 모두 계산되면, 이를 softmax에 통과시켜 확률 분포를 얻는다. 그 분포를 bar chart로 나타낸 것이 위의 그림이다.
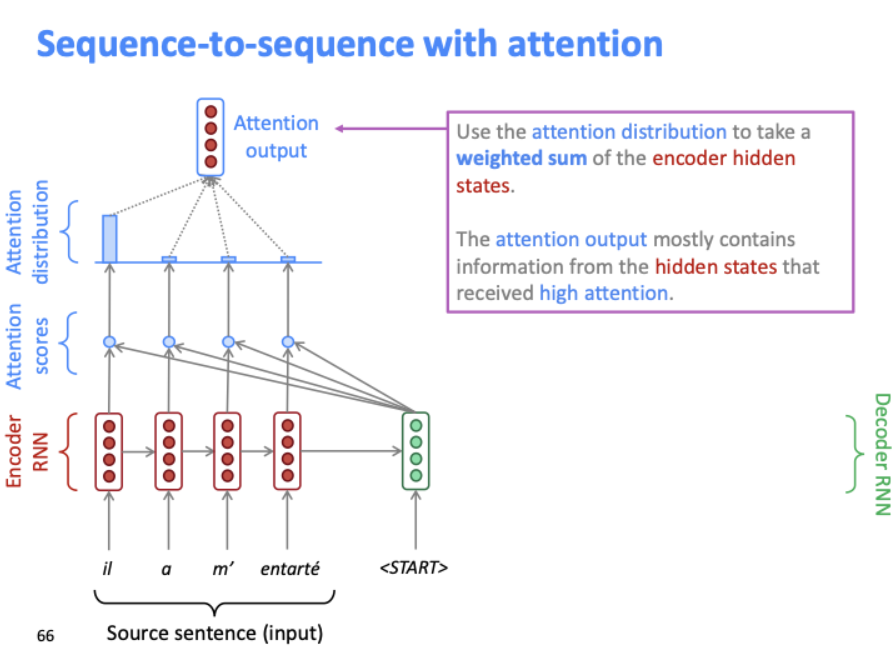
인코더 은닉 상태의 가중치를 attention distribution으로 사용한다. 이 분포로 attention output을 만든다. 위의 attention output은 가장 높은 attention score를 얻은 은닉 층의 대부분의 정보를 포함한다.
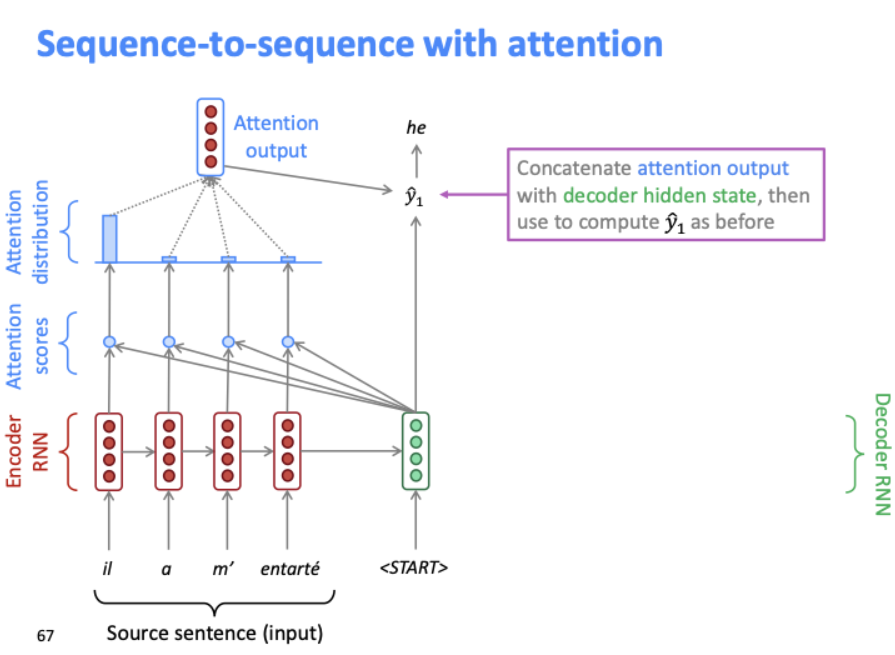
attention output과 디코더 은닉층 상태를 결합하여 다음 단어(y1)을 예측한다. 이전 seq-to-seq에서는 디코더 은닉층 상태만으로 다음단어를 예측했던 것에 비해, 쌍인 "attention output, decoder hidden state"를 사용하여 예측한다.
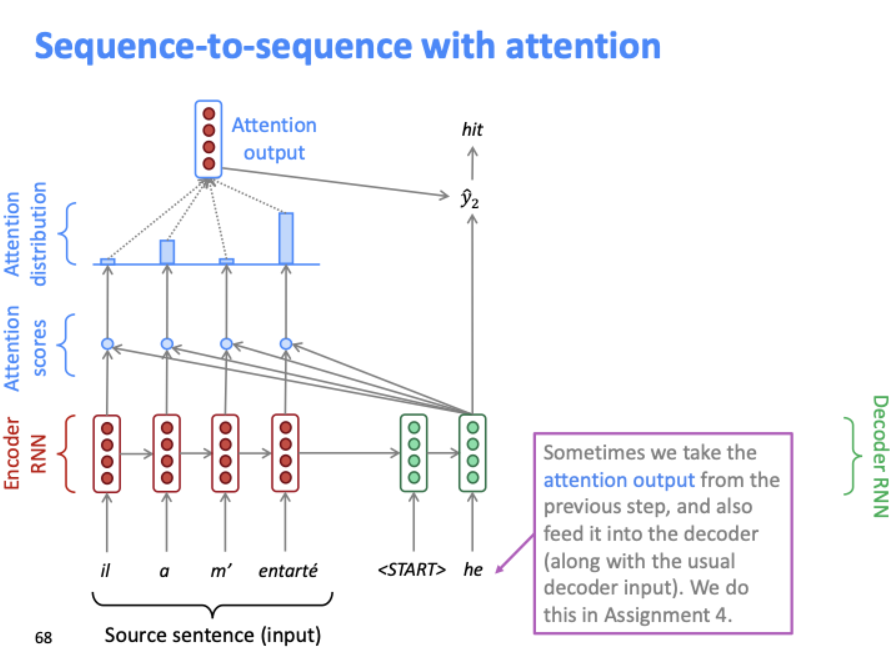
그 다음 단계도 같은 과정을 반복한다. 그리고 이전 단계의 attention output은 다음 단계에서도 유용할 수 있기 때문에 디코더로 다시 feed된다.

위의 attention에 대한 diagram에서 설명한 것과 동일한 방정식이다. 여기서 attention output을 의미하는 α는 인코더의 은닉 상태와 동일한 벡터 사이즈를 갖는다.

Attention의 좋은 점
기존 신경망 기계 번역의 성능을 향상시켰다.
병목현상 문제점을 해결할 수 있다.
기울기 소실 문제를 해결해준다.
추적이 가능하다. 어디서 오류가 발생했는지 확인할 수 있다.
