Deep Convolutional Models: Case Studies

작성자 : 동국대학교 통계학과 이윤정
Contents
- 왜 케이스 스터디를 하나요?
- 고전적인 네트워크들
- ResNets
- 왜 ResNets이 잘 작동할까요?
- Network 속의 Network
- Inception 네트워크의 아이디어
- Inception 네트워크
Deep Convolutional Models: Case Studies
이번 강의에서는 합성곱 신경망의 사례와 구조에 대해 배울 수 있습니다.
왜 케이스 스터디를 하나요?
Computer Vision에서는 앞선 강의에서 배운 padding, pooling 그리고 fully connected layer를 통해 Convolution Neural Network을 구축하는 것이 가장 중요합니다. 이때, 한 task에서 잘 동작하는 CNN 구조는 다른 task에서도 유용하게 동작하기 때문에 CNN을 구축하기 위해서는 신경망 구조를 살펴보아야 합니다.
고전적인 네트워크들
1. LeNet-5
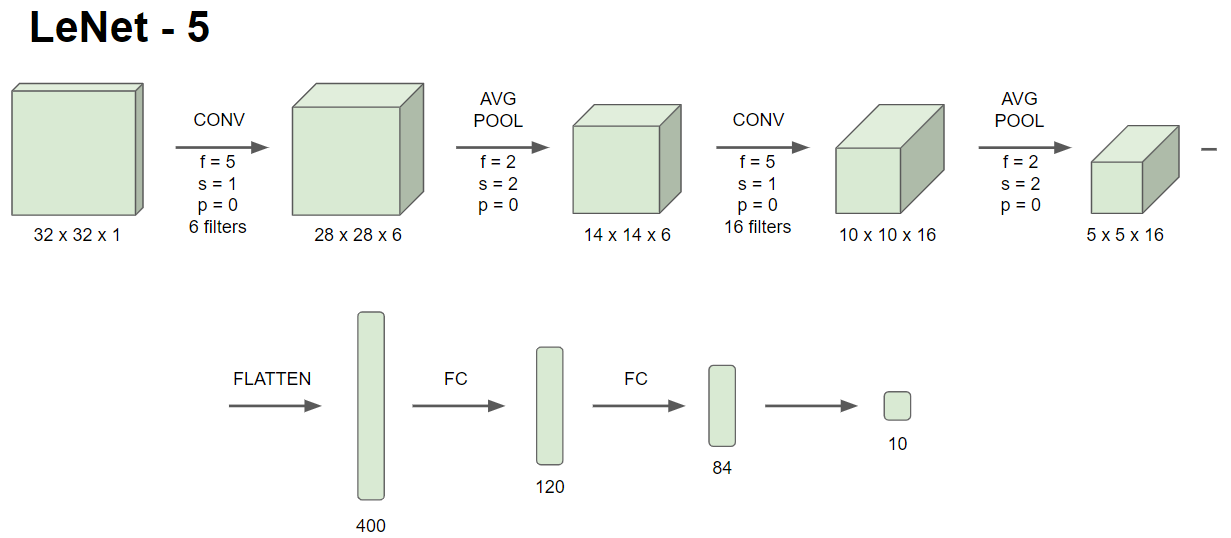 LeNet-5의 목적은 손글씨 인식입니다. 그 중 흑백으로 된 손글씨를 인식하기 위해 input channel이 1입니다. 또한, conv pool ... conv pool ... fc fc output의 구성을 보임을 알 수 있습니다. 다만, 해당 모델을 구상하는 당시에는 padding을 사용하지 않는 경향이 있었습니다. 그렇기 때문에 층이 깊어질수록 높이와 너비는 줄어드는 반면, 채널의 수는 늘어나는 경향을 지닙니다. 그 뿐만 아니라, 해당 모델을 구상하는 당시에는 Relu activation function이 아닌 Sigmoid와 tanh activation function을 사용하였습니다.
LeNet-5의 목적은 손글씨 인식입니다. 그 중 흑백으로 된 손글씨를 인식하기 위해 input channel이 1입니다. 또한, conv pool ... conv pool ... fc fc output의 구성을 보임을 알 수 있습니다. 다만, 해당 모델을 구상하는 당시에는 padding을 사용하지 않는 경향이 있었습니다. 그렇기 때문에 층이 깊어질수록 높이와 너비는 줄어드는 반면, 채널의 수는 늘어나는 경향을 지닙니다. 그 뿐만 아니라, 해당 모델을 구상하는 당시에는 Relu activation function이 아닌 Sigmoid와 tanh activation function을 사용하였습니다.
2. AlexNet
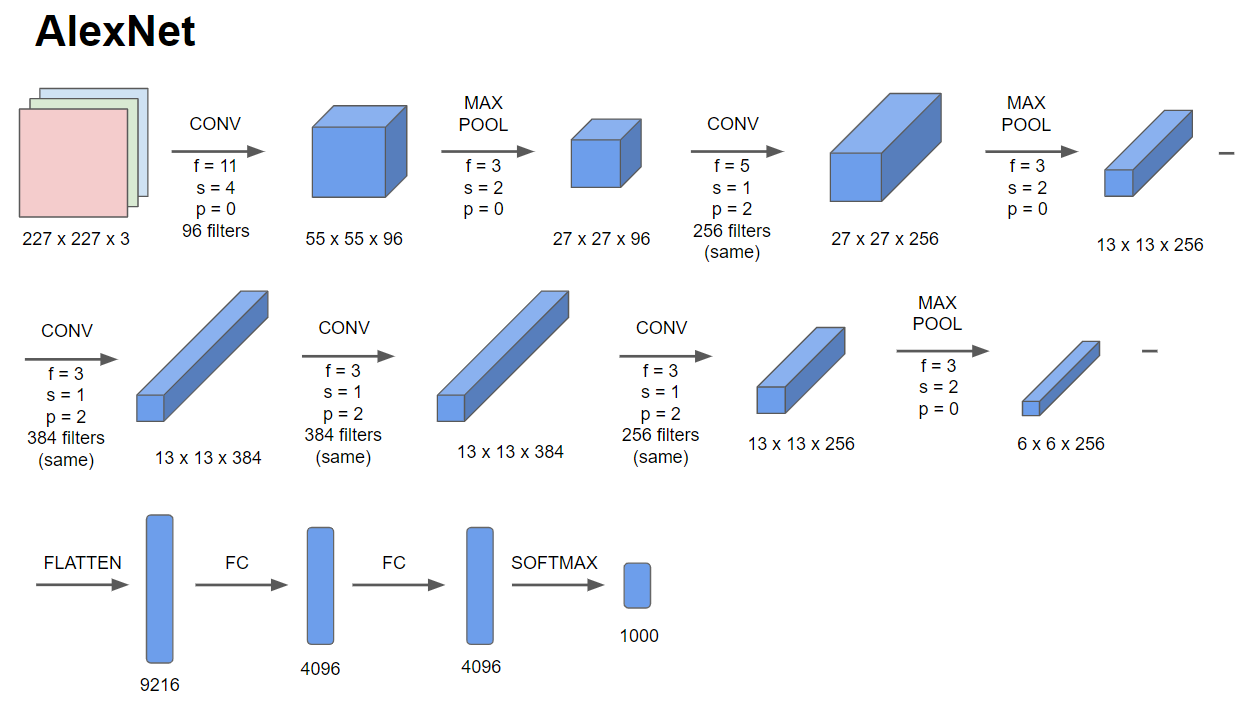 AlexNet의 목적은 이미지를 1000개에 해당하는 클래스로 분류하는 것 입니다. 이때, 논문에서 Input Image는 224x224x3이지만, 실제로 계산해보면 227x227x3이 타당하므로 그림을 보면 input size가 227x227x3입니다.
AlexNet의 목적은 이미지를 1000개에 해당하는 클래스로 분류하는 것 입니다. 이때, 논문에서 Input Image는 224x224x3이지만, 실제로 계산해보면 227x227x3이 타당하므로 그림을 보면 input size가 227x227x3입니다.
Input Image 227x227x3에 대해 11x11, 5x5, 3x3 커널을 사용하였으며 5개의 convolutional layer와 3개의 dense layer로 이루어져 있습니다. AlexNet은 LeNet-5와 유사한 구조지만 parameter 수에서 가장 큰 차이를 보입니다. LeNet의 경우 6만개의 parameter를 갖는다면 AlexNet의 경우 6천만개의 parameter를 갖습니다. 또한, AlexNet은 Relu activation function을 사용했습니다.
3. VGG-16
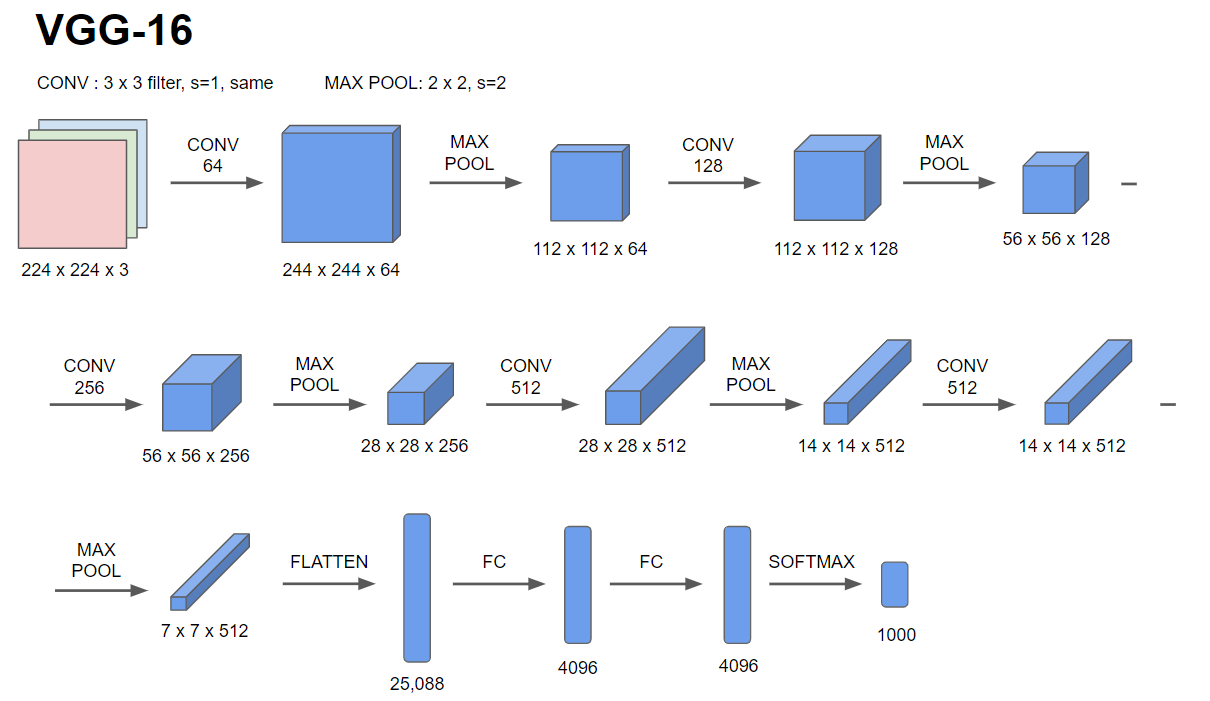 VGG-16은 수많은 parameter를 갖는 대신, 모든 합성곱 연산이 3x3 filter를 가지고 padding 크기는 2, stride는 1을 사용하는 동일합성곱 연산입니다.
VGG-16은 수많은 parameter를 갖는 대신, 모든 합성곱 연산이 3x3 filter를 가지고 padding 크기는 2, stride는 1을 사용하는 동일합성곱 연산입니다.
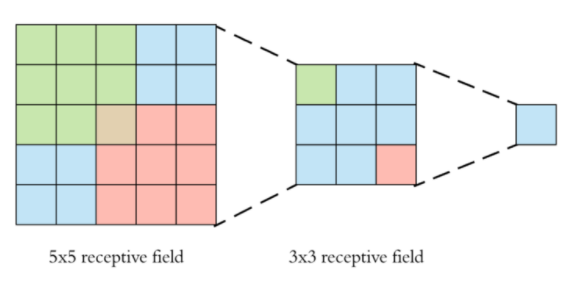 이렇게 3x3 filter를 중첩하여 쌓는 이유는 3개의 3x3 convolutional layer를 중첩하면 1개의 7x7 convolutional layer와 receptive field가 같아지지만, activation function을 더 많이 사용할 수 있어 더 많은 비선형성을 얻을 수 있으며, parameter 수도 줄어드는 효과를 얻을 수 있기 때문입니다. (3x3x3=27 < 7x7=49) 그럼에도 불구하고, parameter 수가 많으므로 네트워크의 크기가 커진다는 단점이 있습니다.
이렇게 3x3 filter를 중첩하여 쌓는 이유는 3개의 3x3 convolutional layer를 중첩하면 1개의 7x7 convolutional layer와 receptive field가 같아지지만, activation function을 더 많이 사용할 수 있어 더 많은 비선형성을 얻을 수 있으며, parameter 수도 줄어드는 효과를 얻을 수 있기 때문입니다. (3x3x3=27 < 7x7=49) 그럼에도 불구하고, parameter 수가 많으므로 네트워크의 크기가 커진다는 단점이 있습니다.
- 동일합성곱 연산 : 이전 layer의 높이와 너비를 같게 만드는 padding을 갖는 연산
- receptive field : 각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지 영역의 일부
ResNets
vanishing gradient와 exploding gradient 문제로 인해 고전적인 네트워크들은 아주 깊은 신경망을 학습하지 못하였습니다. 그러만, ResNet은 Skip Connection을 통해 이러한 문제를 해결하였습니다.
1. ResNet의 Main Path
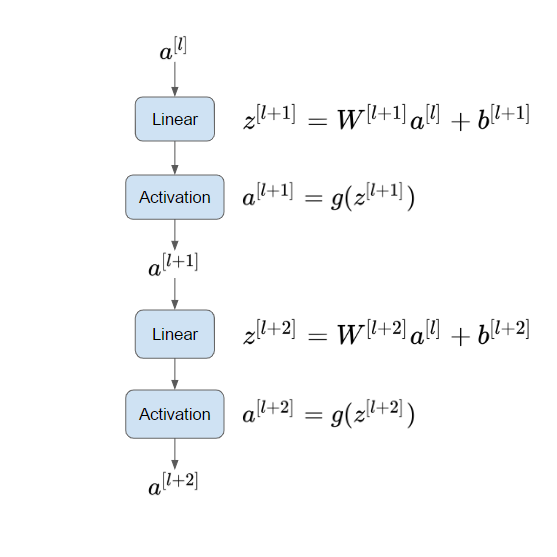 예를 들어, 2개의 layer가 존재할 때 다음과 같이 존재하는 모든 층을 지나는 일련의 연산 과정을 main path라고 부릅니다. 따라서, 의 정보가 로 흐르기 위해서는 다음과 같은 연산 과정을 거쳐야 합니다. 이때, Relu activation function을 통해 비선형성을 적용해줄 수 있습니다.
예를 들어, 2개의 layer가 존재할 때 다음과 같이 존재하는 모든 층을 지나는 일련의 연산 과정을 main path라고 부릅니다. 따라서, 의 정보가 로 흐르기 위해서는 다음과 같은 연산 과정을 거쳐야 합니다. 이때, Relu activation function을 통해 비선형성을 적용해줄 수 있습니다.
2. Skip Connection (Short Cut)
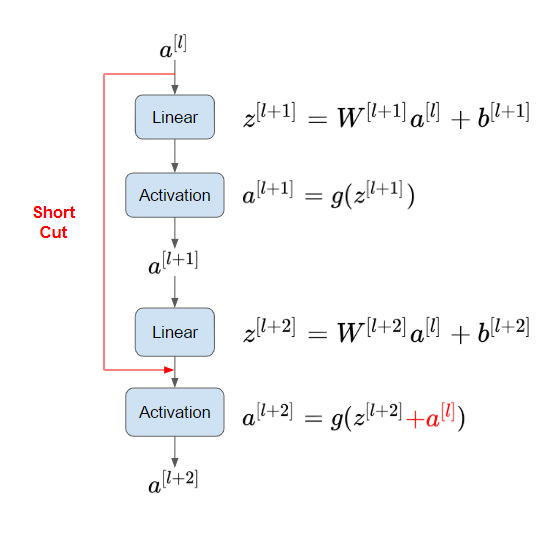 많은 layer를 걸쳐 backpropagation될 때 vanishing gradient 문제가 발생하므로, ResNet은 gradient가 몇 개의 layer를 건너 뛰어 연결될 수 있는 short cut을 사용했습니다. 이를 통해 의 정보를 변하지 않고 더 깊은 layer에 전달할 수 있습니다.
많은 layer를 걸쳐 backpropagation될 때 vanishing gradient 문제가 발생하므로, ResNet은 gradient가 몇 개의 layer를 건너 뛰어 연결될 수 있는 short cut을 사용했습니다. 이를 통해 의 정보를 변하지 않고 더 깊은 layer에 전달할 수 있습니다.
3. Residual Block
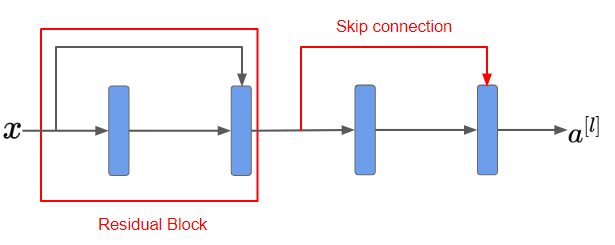 를 더해서 다시 activation function에 넣는 부분까지를 residual block이라고 부르며, ResNet은 여러 개의 residual block으로 구성됩니다.
를 더해서 다시 activation function에 넣는 부분까지를 residual block이라고 부르며, ResNet은 여러 개의 residual block으로 구성됩니다.
왜 Res(잔차)Net인가요?
기존의 신경망은 입력값 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목적입니다. 그러나 ResNet은 F(x)+x를 최소화하는 것을 목적으로 합니다. 이때, x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 됩니다.
F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 됩니다. F(x)=H(x)-x이므로 F(x)를 최소로 해준다는 것은 H(x)-x를 최소로 해주는 것과 동일한 의미를 지닙니다. 여기서 H(x)-x를 잔차(residual)라고 합니다. 즉, 잔차를 최소로 해주는 것이므로 ResNet이라고 칭합니다.
왜 ResNets이 잘 작동할까요?
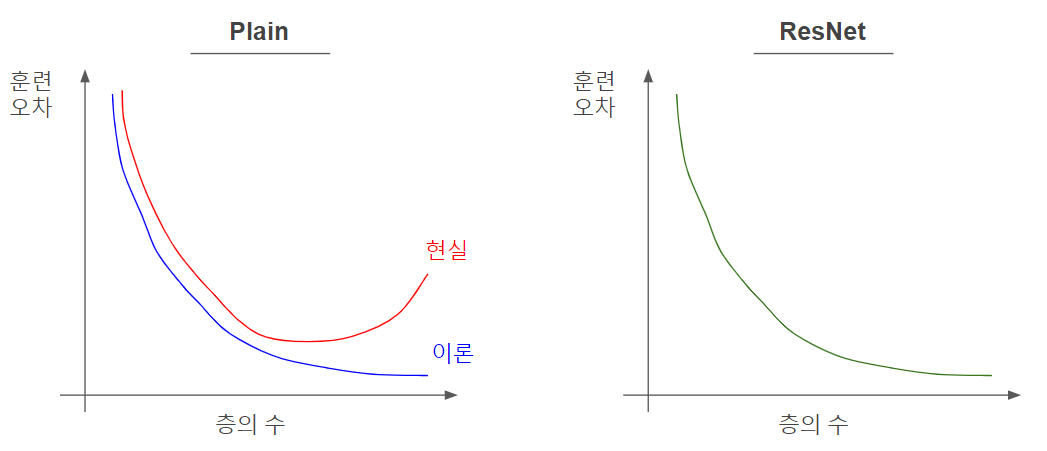
Plain 모델의 경우 layer의 개수를 늘릴 수록 훈련 오차가 감소하다가 다시 증가하는 경향을 보였습니다. 반면, ResNet의 경우 layer의 개수를 늘릴 수록 훈련 오차가 꾸준히 감소하는 경향을 보입니다.
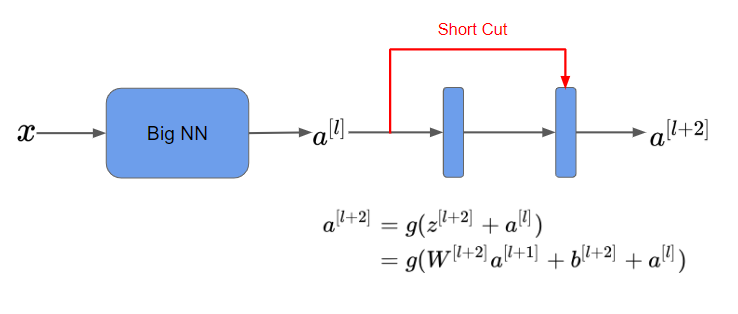 Skip Connetion을 통한 출력값 = 입니다. 이때, 와 의 값이 극도로 작아져 0에 가까워진다면 로 항등식이 되며, Relu activation function로 인해 양수 값만 존재하게 됩니다.
Skip Connetion을 통한 출력값 = 입니다. 이때, 와 의 값이 극도로 작아져 0에 가까워진다면 로 항등식이 되며, Relu activation function로 인해 양수 값만 존재하게 됩니다.
이처럼, 양수인 경우 항등 함수인 Relu로 학습이 되면 이므로 적어도 성능 저하는 발생하지 않습니다. 다만, 다음과 같이 전개되기 위해서는 와 이 같은 차원을 가져야 합니다. 따라서, 동일합성곱 연산을 하거나 차원을 같게 만들어주는 행렬 를 곱해줍니다.
 그림을 자세히 보면 output feature map의 개수가 변함에 따라 Shortcut이 실선이 아니라 점선을 이용하는 것을 알 수 있습니다. Output feature map의 개수가 2배로 커질 때 마다 feature map의 가로, 세로 size는 절반으로 줄여주는 방식을 이용하고 있으며, 이 때는 pooling 대신 stride를 2로 갖는 convolution 연산을 이용하는 점이 특징입니다. 이 경우, Shortcut에서도 feature map size를 줄여주어야 하기 때문에 projected shortcut을 이용합니다. 이러한 shortcut 구조를 통해 vanishing gradient에 강인한 학습을 수행할 수 있게됩니다.
그림을 자세히 보면 output feature map의 개수가 변함에 따라 Shortcut이 실선이 아니라 점선을 이용하는 것을 알 수 있습니다. Output feature map의 개수가 2배로 커질 때 마다 feature map의 가로, 세로 size는 절반으로 줄여주는 방식을 이용하고 있으며, 이 때는 pooling 대신 stride를 2로 갖는 convolution 연산을 이용하는 점이 특징입니다. 이 경우, Shortcut에서도 feature map size를 줄여주어야 하기 때문에 projected shortcut을 이용합니다. 이러한 shortcut 구조를 통해 vanishing gradient에 강인한 학습을 수행할 수 있게됩니다.
simple shortcut VS projected shortcut
shortcut을 적용할때 에서 F(x)는 convolution filter를 통과하였습니다. 이때, filter 수가 증가하게 되면 차원 수가 높아지기 때문에 x의 차원을 높여줘야 합니다. 따라서 차원이 증가한 경우 1x1 convolution을 사용하는 projected shortcut을 통해 x의 차원을 증가시킵니다.
Network 속의 Network
1x1 합성곱은 1x1 크기를 가지는 Filter를 사용한 Convolution Layer입니다. 1x1 합성곱은 channel이 1개일 때는 유용해보이지 않지만, 여러 개의 channel을 가지고 있을 때에는 3가지 특징을 지닙니다.
1. Channel 수 조절
pooling을 통해서 높이와 너비는 줄일 수 있지만, channel은 줄일 수 없습니다. 이때, channel을 줄일 수 있는 방법은 1x1 convolution입니다. 1x1 convolution 연산을 위해 필요한 필터는 (1 x 1 x #channel x #filter)입니다. 여기서, #channel은 입력의 channel 수와 동일해야 하고 #filter는 원하는 출력의 channel 수로 지정해야 합니다.
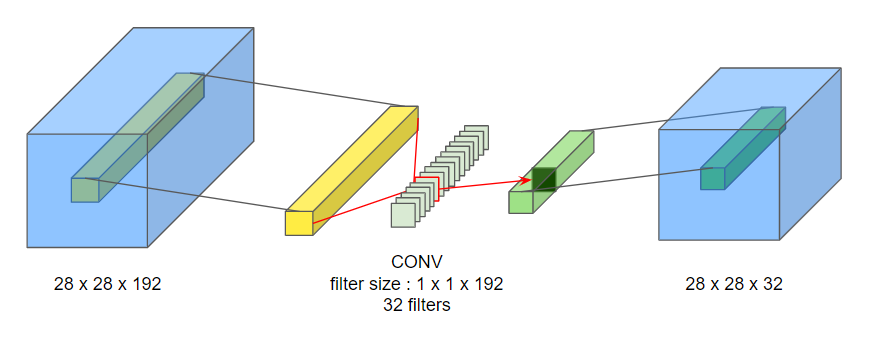 28x28x192의 input이 32개의 1x1 필터와 합성곱을 하여 28x28 x32의 output이 됩니다. 이는 input channel의 수만큼 유닛을 입력으로 받아 이들을 하나로 묶는 연산과정 통해 output channel의 수만큼 출력을 하는 작은 신경망 네트워크로 간주할 수 있습니다. (: 네트워크 안의 네트워크)
28x28x192의 input이 32개의 1x1 필터와 합성곱을 하여 28x28 x32의 output이 됩니다. 이는 input channel의 수만큼 유닛을 입력으로 받아 이들을 하나로 묶는 연산과정 통해 output channel의 수만큼 출력을 하는 작은 신경망 네트워크로 간주할 수 있습니다. (: 네트워크 안의 네트워크)
2. 연산량 조절
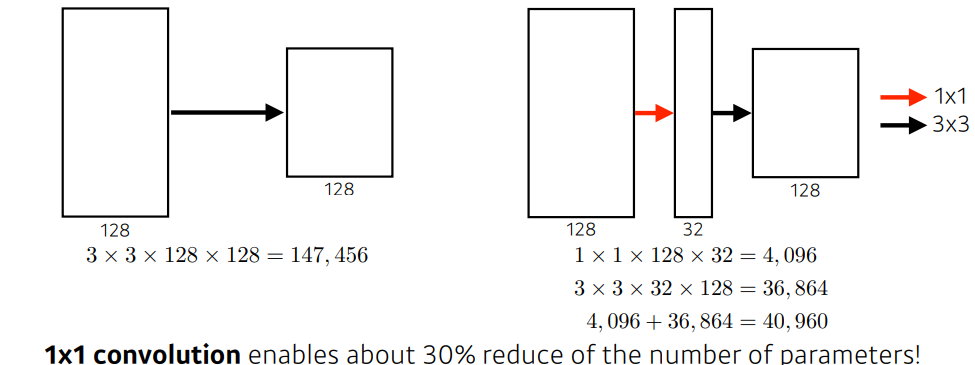 깊이 128의 입력 데이터로 깊이 128의 출력 데이터를 만들기 위해 3x3 convolution을 적용하면 3∗3∗128∗128=147,456개의 파라미터 수를 가집니다. 이때, 1x1 convolution을 통해 깊이를 32로 줄인 다음 3x3 convolution으로 깊이 128의 출력 데이터를 만든다고 한다면 1∗1∗128∗32+3∗3∗32∗128 = 4096+36,864 = 40,960개의 parameter를 가져 연산량 조절을 할 수 있음을 확인할 수 있습니다.
깊이 128의 입력 데이터로 깊이 128의 출력 데이터를 만들기 위해 3x3 convolution을 적용하면 3∗3∗128∗128=147,456개의 파라미터 수를 가집니다. 이때, 1x1 convolution을 통해 깊이를 32로 줄인 다음 3x3 convolution으로 깊이 128의 출력 데이터를 만든다고 한다면 1∗1∗128∗32+3∗3∗32∗128 = 4096+36,864 = 40,960개의 parameter를 가져 연산량 조절을 할 수 있음을 확인할 수 있습니다.
3. 비선형성 부여
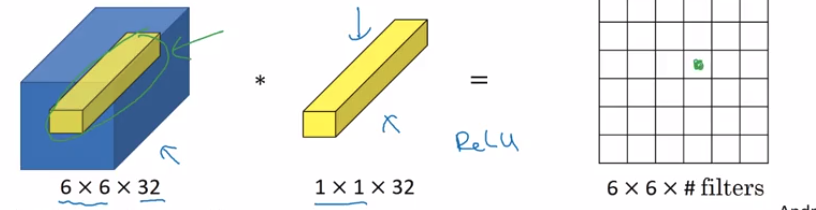 1x1 convolution이 수행하는 작업은 여기에 있는 36가지 위치(높이와 너비의 곱에 의한 픽셀 갯수)를 각각 살펴보고 32개의 숫자(channel)와 필터의 32개 숫자 사이에 요소 간 곱셈을 하는 것입니다. 그리고 나서 ReLU 비선형성을 적용합니다.
1x1 convolution이 수행하는 작업은 여기에 있는 36가지 위치(높이와 너비의 곱에 의한 픽셀 갯수)를 각각 살펴보고 32개의 숫자(channel)와 필터의 32개 숫자 사이에 요소 간 곱셈을 하는 것입니다. 그리고 나서 ReLU 비선형성을 적용합니다.
Inception 네트워크의 아이디어
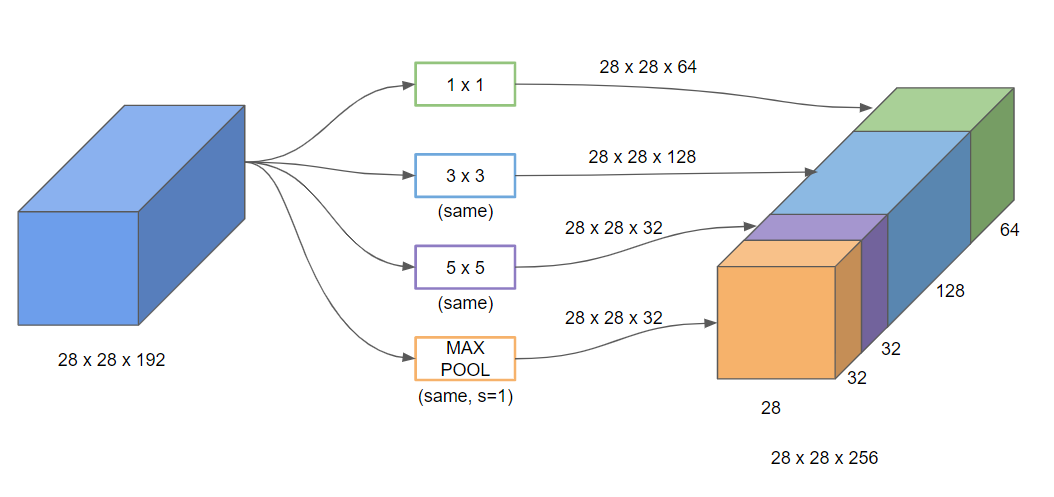 인셉션 네트워크의 아이디어는 filter의 크기나 pooling을 결정하는 대신 한 layer 안에서 여러 종류의 filter를 사용해 네트워크가 스스로 조합을 학습하게 만드는 것입니다.
인셉션 네트워크의 아이디어는 filter의 크기나 pooling을 결정하는 대신 한 layer 안에서 여러 종류의 filter를 사용해 네트워크가 스스로 조합을 학습하게 만드는 것입니다.
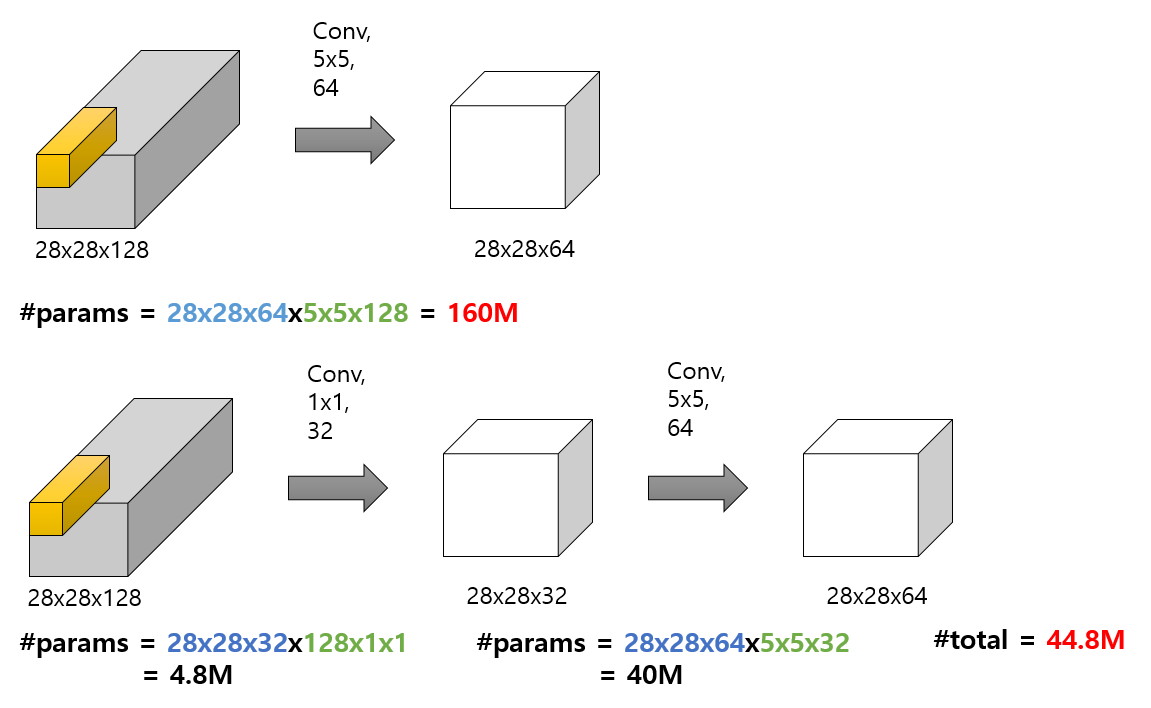 다만, 특정한 filter size에 국한된 것이 아니라는 점은 다양성을 띄지만 계산 비용에 있어서 문제가 발생합니다. 단순 5x5 필터를 사용한 연산 과정에서 계산해야 할 parameter 개수는 28x28x64x5x5x128 = 약 1억 6천만개이기 때문입니다.
다만, 특정한 filter size에 국한된 것이 아니라는 점은 다양성을 띄지만 계산 비용에 있어서 문제가 발생합니다. 단순 5x5 필터를 사용한 연산 과정에서 계산해야 할 parameter 개수는 28x28x64x5x5x128 = 약 1억 6천만개이기 때문입니다.
이러한 문제점을 해결하기 위해서 1x1 Convolution을 활용하게 됩니다. 동일한 사이즈의 입력 데이터를 1x1 Convolution을 사용한 후, 5x5 Convolution을 사용한 연산 결과를 보면 단순 convolution 연산 결과인 28x28x64와 동일한 사이즈입니다. 이때, 연산 과정에서 계산해야할 parameter 개수는 총 4천 480만개입니다. 학습에 필요한 계산 비용이 크게 줄어든 것을 알 수 있습니다.
여기서 사용된 1 x 1 합성곱 층을 병목 층이라고도 합니다. 병목층을 사용시 표현의 크기가 줄어들어 성능에 영향을 지장을 줄지 걱정 될 수도 있는데, 적절하게 구현시 표현의 크기를 줄임과 동시에 성능에 큰 지장 없이 많은 수의 계산을 줄일수 있습니다.
Inception 네트워크 (GoogLeNet)
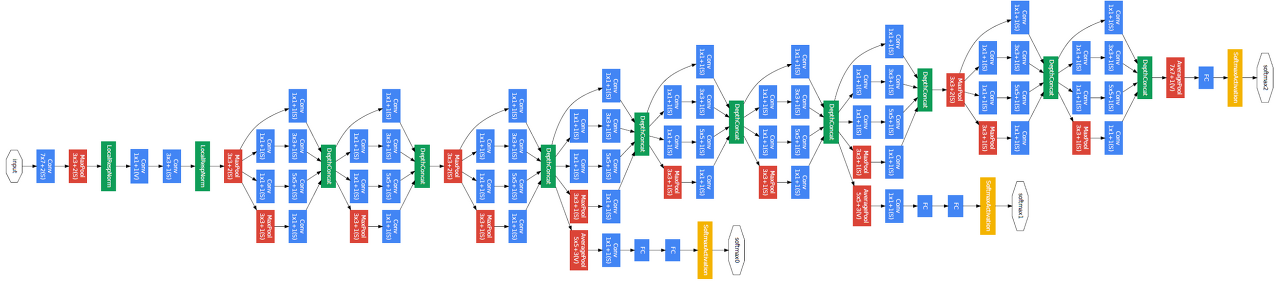 GoogLeNet은 상술한 바와 같이 22개 층으로 구성되어 있습니다. 파란색 블럭의 층수를 세보면 22개 층임을 알 수 있습니다.
GoogLeNet은 상술한 바와 같이 22개 층으로 구성되어 있습니다. 파란색 블럭의 층수를 세보면 22개 층임을 알 수 있습니다.
1. 1x1 Convolution
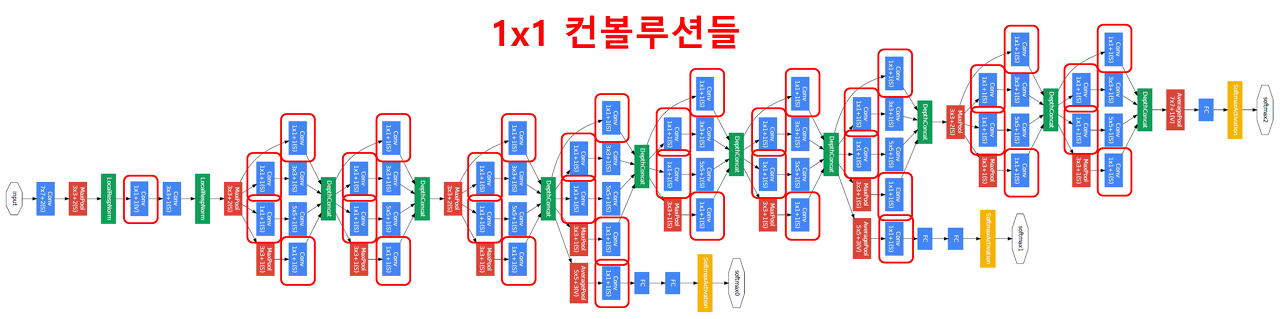 GoogLeNet에서 1x1 convolution은 feature map의 개수를 줄이는 목적으로 사용됩니다. feature map의 개수가 줄어들면 그만큼 연산량이 줄어듭니다.
GoogLeNet에서 1x1 convolution은 feature map의 개수를 줄이는 목적으로 사용됩니다. feature map의 개수가 줄어들면 그만큼 연산량이 줄어듭니다.
2. Inception Module
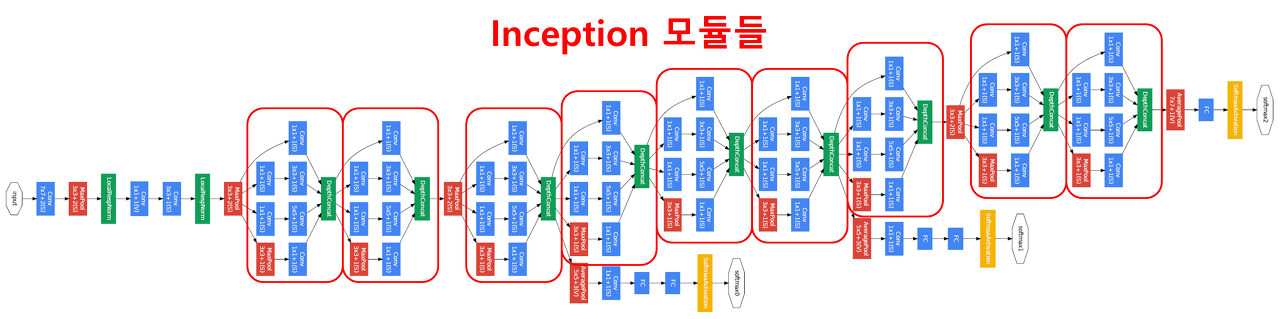 GoogLeNet은 총 9개의 인셉션 모듈을 포함하고 있습니다. 인셉션 모듈을 하나 확대해서 자세히 살펴봅시다.
GoogLeNet은 총 9개의 인셉션 모듈을 포함하고 있습니다. 인셉션 모듈을 하나 확대해서 자세히 살펴봅시다.
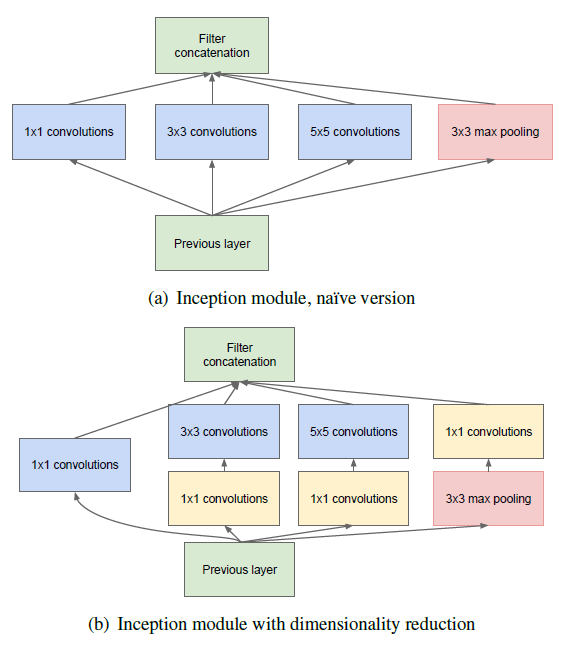 GoogLeNet에 실제로 사용된 모듈은 1x1 convolution이 포함된 (b) 모델입니다. 아까 살펴봤듯이 1x1 convolution은 feature map의 개수를 줄여주는 역할을 합니다. 노란색 블럭으로 표현된 1x1 convolution을 제외한 (a) 모델을 살펴보면, 이전 층에서 생성된 feature map을 1x1 convolution, 3x3 convolution, 5x5 convolution, 3x3 max pooling해준 결과 얻은 feature map을 모두 함께 쌓아줍니다.
GoogLeNet에 실제로 사용된 모듈은 1x1 convolution이 포함된 (b) 모델입니다. 아까 살펴봤듯이 1x1 convolution은 feature map의 개수를 줄여주는 역할을 합니다. 노란색 블럭으로 표현된 1x1 convolution을 제외한 (a) 모델을 살펴보면, 이전 층에서 생성된 feature map을 1x1 convolution, 3x3 convolution, 5x5 convolution, 3x3 max pooling해준 결과 얻은 feature map을 모두 함께 쌓아줍니다.
AlexNet, VGGNet 등 이전 CNN 모델들은 한 층에서 동일한 사이즈의 filter를 이용해서 convolution을 해줬던 것과 차이가 있습니다. 따라서 좀 더 다양한 종류의 특성이 도출되며, 1x1 convolution이 포함되었으므로 연산량 역시 감소하게 됩니다.
왜 여러 크기의 filter를 사용하나요?
자동차가 있는 두 이미지에 (3,3) 크기의 filter를 하나만 사용해 이미지의 특징을 찾아봅시다. 그림에서도 볼 수 있듯이 같은 물체일지라도 서로 다른 비율로 위치할 경우 한 종류의 필터를 사용하는 것이 효율적이지 않다는 것을 생각할 수 있습니다. 이러한 아이디어에 따라 GogLeNet은 다른 크기의 필터를 가진 인셉션 모듈 9개가 입력 이미지의 서로 다른 영역의 특징을 찾아 축적합니다.
3. Global Average Pooling
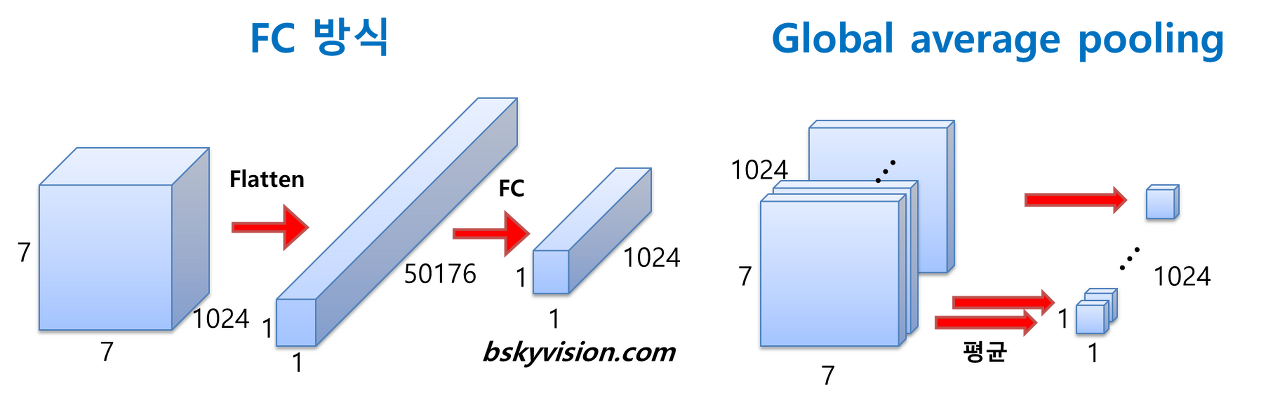 AlexNet, VGGNet 등에서는 fully connected layer(FC)들이 망의 후반부에 연결되어 있습니다. 그러나 GoogLeNet은 FC 방식 대신에 global average pooling이란 방식을 사용합니다. global average pooling은 전 층에서 산출된 feature map들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것입니다. 1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결해줄 수 있기 때문입니다. 만약 전 층에서 1024장의 7x7의 feature map이 생성되었다면, 1024장의 7x7 feature map 각각 평균내주어 얻은 1024개의 값을 하나의 벡터로 연결해주는 것입니다.
AlexNet, VGGNet 등에서는 fully connected layer(FC)들이 망의 후반부에 연결되어 있습니다. 그러나 GoogLeNet은 FC 방식 대신에 global average pooling이란 방식을 사용합니다. global average pooling은 전 층에서 산출된 feature map들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것입니다. 1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결해줄 수 있기 때문입니다. 만약 전 층에서 1024장의 7x7의 feature map이 생성되었다면, 1024장의 7x7 feature map 각각 평균내주어 얻은 1024개의 값을 하나의 벡터로 연결해주는 것입니다.
4. Auxiliary Classifier
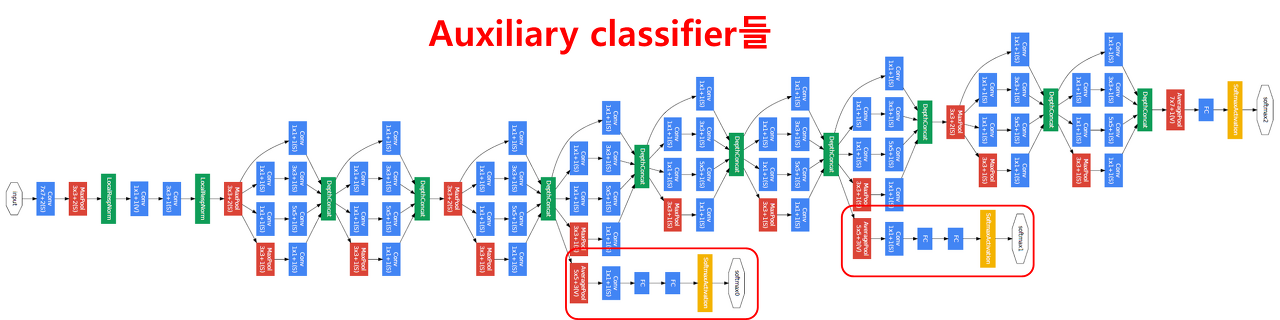 네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient 문제를 피하기 어려워집니다. 가중치를 훈련하는 과정에 backpropagation를 활용하는데, 이 과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리기 때문입니다. 따라서 네트워크 내의 가중치들이 제대로 훈련되지 않는 문제가 발생합니다.
네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient 문제를 피하기 어려워집니다. 가중치를 훈련하는 과정에 backpropagation를 활용하는데, 이 과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리기 때문입니다. 따라서 네트워크 내의 가중치들이 제대로 훈련되지 않는 문제가 발생합니다.
이 문제를 극복하기 위해서 GoogLeNet에서는 네트워크 중간에 두 개의 보조 분류기(auxiliary classifier)를 달아주었습니다. 보조 분류기의 구성을 살펴보면, 5x5 평균 pooling (stride 3) -> 128개 1x1 convolution -> 1024 FC layer -> 1000 FC layer -> softmax 순입니다.
결론
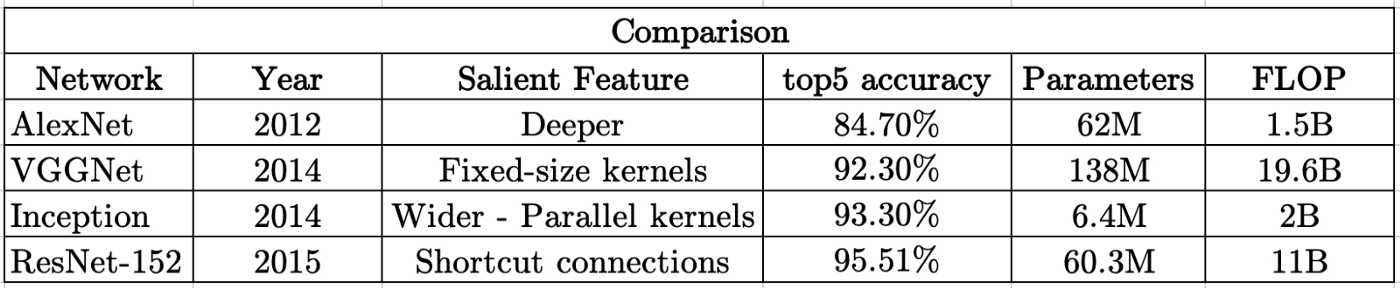 LeNet-5를 제외한 오늘 배운 모델들의 Imagenet 데이터셋에 대한 상위 5개의 정확도와 parameter의 수입니다.
LeNet-5를 제외한 오늘 배운 모델들의 Imagenet 데이터셋에 대한 상위 5개의 정확도와 parameter의 수입니다.
- AlexNet과 ResNet-152는 둘 다 약 6천만 개의 parameter를 가지고 있지만 상위 5개 정확도에는 약 10%의 차이가 있습니다. 그러나 ResNet-152를 훈련하려면 많은 계산이 필요합니다. (AlexNet의 약 10배) 이는 더 많은 훈련 시간이 필요함을 의미합니다.
- VGGNet은 ResNet-152에 비해 더 많은 매개변수와 FLOP을 가질 뿐만 아니라 정확도도 떨어집니다. 감소된 정확도로 VGGNet을 훈련하는 데 더 많은 시간이 걸립니다.
- AlexNet 교육은 Inception 교육과 거의 같은 시간이 걸립니다. 향상된 정확도(약 9%)로 메모리 요구 사항이 10배 감소합니다.
reference
https://www.boostcourse.org/ai218/joinLectures/138359?isDesc=false
https://bskyvision.com/
https://hoya012.github.io/blog/deeplearning-classification-guidebook-1/
https://techblog-history-younghunjo1.tistory.com/132
https://ganghee-lee.tistory.com/41
https://ardino.tistory.com/44

4개의 댓글

[투빅스 15기 강지우]
LeNet
- input : 32x32x1
- output : 10
- sigmoid, tanh
- 6만개의 parameter
- 깊어질수록 h, w는 작아지고 채널의 수는 늘어남
AlexNet
- input : 227x227x3
- output : 1000
- LeNet과 유사하게 깊어질수록 h, w는 작아지고 채널의 수는 늘어남
- conv, pooling, dense 의 구성
- 11, 5, 3 filter 사용
- 6천만개의 parameter
VGG-16
- input ; 224x224x3
- output : 1000
- 3x3 filter, padding 2, stride 1 구성의 same convolution
- conv - pooling의 반복적인 구성
- 3x3 filter 2번 연산 == 5x5 filter 1번 연산, 3x3 filter 3번 연산 == 7x7 filter 1번 연산 (output feature map의 크기가 같다.)
큰크기의 필터를 쓰는 것보다 작은 크기의 필터를 여러번 쓰는 것의 장점은 1. 파라미터의 수가 줄어든다. 2. 여러 레이어를 거치면서 여러번 activation func를 통과하고, 이는 비선형성을 증가시켜준다.
ResNet
어떻게 gradient를 잘 유지하면서 깊게 쌓을 수 있을까? 깊이로의 확장
degradation problem
- layer를 깊이 쌓을수록 over-fitting 문제가 일어난다고 생각하지만, 실험결과 층이 적은 모델이 train error, test error 모두 적었다. 따라서 층이 많으면 학습이 안되는 이유는 gradient vanishing or gradient exploding 문제때문이다.
skip connection
위의 degradation 문제를 skip connection 을 통해 해결한다. short cut path를 통해 gradient가 유지될 수 있다.
Inception
너비로의 확장
한 레이어에서 다양한 크기의 filter로 convolution을 해서 다양한 특성을 추출
1x1 conv
1x1 conv로 연산량 줄임
Auxiliary Classifier
gradient를 보충해줌
GAP
dense layer대신 GAP사용
결론
inception이 다른 모델에 비해 적은 파라미터에 대비해 우수한 성능을 가지지만 복잡한 구조로 인해 backbone으로 널리 사용되진 않는다고 한다.
VGGnet은 파라미터수가 굉장히 많고, ResNet은 이에 비해 적고 성능도 좋다.

[투빅스 16기 김경준]
-
VGG-16은 3x3 필터만으로 네트워크를 구성하였다. 3개의 3x3 필터를 중첩하면 7x7 필터와 receoptive fileld는 동일하지만 연산량이 줄어들며 activation funciton을 통해 비선형성을 증가시킬 수 있다는 장점이 있다. 결과적으로 네트워크를 더욱 깊게 쌓을 수 있기 때문에 성능이 좋다.
-
RestNet은 Skip connection을 통해 vanishing gradient 문제를 해결하였다. Skip connection은 몇 레이어 전의 정보를 그대로 가지고 오는 것으로 역전파 과정에서 Shortcut이 생기기 때문에 위의 문제를 완화시킬 수 있다.
-
GoogLeNet은 여러가지 크기의 필터를 활용하여 다양하게 이미지를 바라볼 수 있는 feature map을 만드는 inception module을 활용한다. 이 과정에서 과도한 연산량이 발생하여 1x1 convolution layer를 추가해주며 중간에 보조 분류기를 두어 vanishing gradient로 인해 앞 단의 레이어들이 훈련되지 않는 문제를 해결한다.
투빅스 16기 전민진입니다.
: 손글씨 흑백 사진 데이터셋을 사용해 손글씨 인식을 목표로 하는 모델
이 모델은 기본적으로 Conv, pool을 만복하고, 마지막에 flatten해 몇 번의 fc를 거쳐 최종 output을 뽑아냄.
이 때엔 패딩을 사용하지 않아 층이 깊어질수록 높이와 너비는 줄어드는 반면, 채널의 수는 늘어나는 경향이 있음.
또한, activation function으로는 Relu가 아닌 sigmoid와 tanh을 사용.
: RGB이미지를 1000개에 해당하는 클래스로 분류하는 목적으로 학습됨.
11x11, 5x5, 3x3커널을 사용하였으며 5개의 conv와 3개의 fc로 구성됨. LeNet-5와 유사하지만 parmas수가 훨씬 많음.
또한, activation function으로 Relu를 사용.
: 수많은 파라미터 대신 모든 합성곱 연산을 3x3 filter, padding=2, stride=1로 설정.
이처럼 작은 크기의 필터를 여러 개 중첩해서 쌓을 경우, 작은 파라미터로 더 많은 비선형성을 얻을 수 있음.
다만 그럼에도 불구하고 params수가 많아 네트워크 크기가 커진다는 단점.
: vanishing gradient와 exploding gradient문제를 해결해 깊은 신경망을 이용하고자 skip connection 사용.
중간 과정을 거치치 않은 직전 레이어의 값을 그대로 넣어줌으로써 gradient vanishing문제를 어느 정도 예방할 수 있었음.
이 덕분에 layer의 개수를 늘려도 훈련 오차가 꾸준히 감소하는 경향을 보임.
: 다양한 크기의 필터를 순서대로 쌓아서 학습을 진행.
중간에 크기를 조절하기 위해 1x1 conv를 활용한다. 다양한 크기의 필터가 입력 이미지의 서로 다른 영역의 특징을 찾아 축적하는 것이 특징.
또한 다른 CNN모델과 다르게 fc 대신에 global average pooling이라는 방식을 활용.
마지막으로 네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient문제를 피하기가 어려워지는데, 이를 방지하기 위해 보조 분류기를 달아줌.