Vision Transformer(ViT) (AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE)

Abstract
- Transformer는 자연어처리 분야를 완전히 장악한 표준 모델이 되었으나 컴퓨터 비전에서는 Transformer의 활용이 제한적이었다.
- 비전에 self attention을 적용하려는 이전 연구들은 convolutional network와 함께 사용하거나 convolutional network의 전체 구조에서 몇몇 요소들만 대체하는 식으로 사용되었다.
- ViT는 CNN에 의존하지 않고 순수한 transformer가 image patch의 시퀀스에 다이렉트로 적용되어 image 분류 task에서 좋은 성능을 보일 수 있음을 밝혔다.
- 큰 데이터셋에 pre-trained 시킨 후 작거나 중간의 image recognition 벤치마크 데이터셋에 전이 학습을 할 때 ViT는 기존 CNN SOTA 모델들보다 계산량은 줄고 좋은 성능을 보였다.
Introduction
- 컴퓨터비전에서는 아직까지 convolutional 구조가 지배적이다.
- Convolutional layer를 전부 self-attention으로 바꾼 연구도 있었는데 이론적으로는 효율적이었으나 현대 하드웨어 가속기 GPU를 활용하지 못한다는 단점이 있었고 그만큼 어텐션을 컴퓨터 비전에 적용하는 것은 어려운 일이었다.
- 이번 연구에서는 최소한의 수정으로 표준 transformer에 이미지를 직접 적용하였다. 이미지를 패치로 분할하고 패치의 선형 임베딩 시퀀스를 트랜스포머 인코더의 입력으로 넣는다. 이미지 패치는 NLP에서 토큰(단어)와 같은 방식으로 처리된다.
- 다시 말해, NLP 시점에서 보면 인풋 이미지가 문장, 패치가 문장을 구성하는 각각의 단어라고 할 수 있다.
- 하지만 ImageNet과 같은 중간 크기의 데이터셋에 대해 학습할 때는 ResNet과 같은 모델들에 비해 정확도가 떨어졌다. 왜냐하면 CNN이 가지고 있는 inductive bias가 Transformer에는 부족하기 때문에 충분하지 못한 양의 데이터로 학습시킬 경우 모델의 일반화 성능이 좋지 않았다.
Inductive bias란?
- 새로운 데이터에 대해 좋은 성능을 내기 위해 모델에 사전적으로 주어지는 가정
- SVM: Margin 최대화, CNN: Locality (지역적인 정보), RNN: Sequentiality (순차적인 정보)
- CNN은 2차원의 지역적인 특성을 유지하며 레이어를 통과하며 지역적인 정보를 중요하게 여기며 모델을 학습한다.
- 반면 Transformer는 데이터를 1차원으로 만든 후 self attention을 통해 layer를 학습하기 때문에 2차원의 지역적인 정보가 유지가 되지 않으므로 CNN에 비해 inductive bias가 적다. 다만 모델의 자유도가 CNN보다 높아 데이터로부터 더 많은 것을 학습할 수 있다.
Method
ViT 모델 구조
- 오리지널 Transformer의 구조를 가능한한 그대로 사용하였고 이를 통해 쉽게 확장 가능한 NLP Transforemr의 구조와 효율적인 구현을 바로 사용할 수 있다.
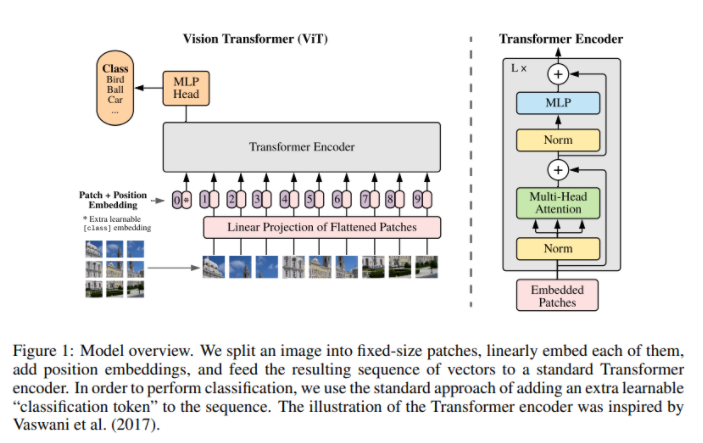
Transformer encoder의 Input
- Transformer는 input으로 1차원 토큰 임베딩 시퀀스를 받기 때문에 2D의 이미지를 사용하기 위해 H X W X C의 이미지를 N X (P X P X C) 인 이미지 패치들로 변환해야 한다.
- 여기서 P는 패치의 크기이고, N = HW/(P*P) 은 패치의 수이며 시퀀스 길이를 의미한다.
- 2차원인 patch를 1차원으로 flatten 시키고 linear projection을 통해 D차원 벡터로 매핑시킨다. 이 projection 결과가 patch embeddings이다.
- 이미지 분류를 위해 임베딩된 패치들의 맨 앞에 class token을 추가한다. (class embedding)
- 각 시퀀스의 순서를 나타내는 position embedding을 추가한다.
- 이렇게 총 3개의 임베딩 벡터들로 이루어진 시퀀스가 transformer의 encoder의 input으로 입력된다.
Transformer Encoder
- 트랜스포머 인코더는 MSA(Multi head self-attention)와 MLP(Mulit layer perceptron) 블록들로 구성된다. LN(Layer Norm)은 모든 블록에 사용되며 블록 이후에는 residual connection이 적용된다.

- Transformer의 Encoder의 입력에 해당하는 부분이다. Xclass는 class token, Xp는 각각의 이미지 패치들, E는 linear projection의 가중치라서 XpE는 patch embedding이다. Epos는 positional embedding이다.
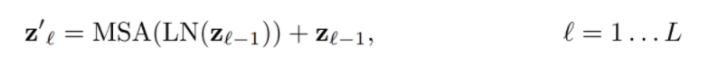
- Transformer encoder의 수식이다. 이전 입력값 z(l-1)에 학습을 안정성을 위해 layer norm을 적용한 후 Multi-head attention을 적용한다. 그리고 z(l-1)을 더해줌으로 skip connection을 해준다.
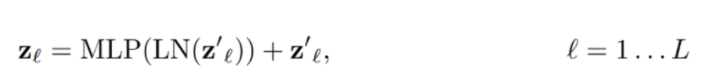
- Multi-head attention 결과로 얻은 값을 layer norm을 적용한 후 MLP을 해준다.
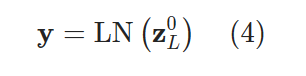
- z0L은 class token의 최종 output이다. 이를 layer norm을 적용한 후 y를 얻는다. 이후 y를 MLP 헤드에 넣어 이미지의 class를 예측한다.
Hybrid Architecture
- Raw 이미지 패치 대신 CNN의 중간 feature map에서 input sequence를 형성할 수 있다. Patch embedding projection E는 CNN의 feature map으로부터 추출된 패치들에 적용되고 classification token과 positional embedding은 위와 동일하게 추가된다.
Fine-tuning and Higher Resolution
- ViT는 기존 이미지 인식 모델과 동일하게 거대한 양의 데이터셋으로 사전 학습하고 파인튜닝하는 단계를 거친다. 웬만한 거대한 데이터셋을 사용하지 않으면 좋은 성능을 기대하기 어렵다. ViT는 구글 내부 이미지 6억장을 사용하여 사전학습을 했다고 한다.
- 파인 튜닝시에는 pre-trained prediction head를 제거하고 0으로 초기화된 D*K 차원의 feedforward layer를 추가한다. 여기서 K는 downstream task의 class의 개수이다.
- 또한, 사전학습 때보다 더 높은 resolution으로 파인 튜닝하는 것이 종종 도움이 된다. 그리고 패치의 크기는 사전학습과 파인튜닝에서 동일하다. 파인튜닝시에 resolution이 더 높기 때문에 파인튜닝 때는 패치의 수가 증가한다.
- ViT는 패치의 수(시퀀스의 길이) N을 얼마든지 늘릴 수 있으나 길이가 늘어날 경우 사전학습된 모델의 positional embedding은 의미가 없을 수 있다. 이를 보완하기 위해 이럴 때는 2차원 구조를 사용하여 positional embedding을 조정한다.
Experiments
Comparision To State Of The Art
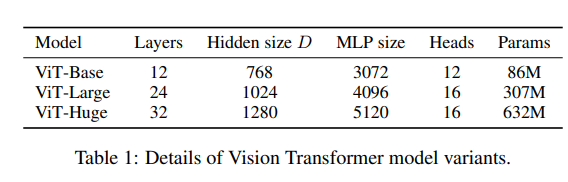
- ViT 모델은 BERT에 사용되는 구성을 기반으로 하였으며, Base와 Large model은 BERT에서 그대로 차용했고 Huge 모델은 저자들이 추가했다.
- VIT-L/16의 의미는 Large 모델을 사용했고 패치의 사이즈가 16*16 이라는 뜻이다.
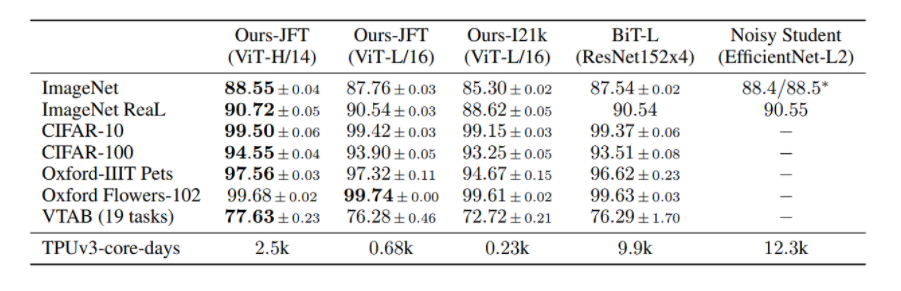
- 위쪽이 pre-trained에 사용한 데이터와 모델이고 왼쪽이 fine-tuning에 사용한 데이터셋이다. 해당 연구가 진행된 시점 기준으로 EfficintNet으로 학습시킨 Noisty Student가 ImageNet의 SOTA였고 다른 데이터셋에서는 ResNet으로 학습시킨 BiT-L이 SOTA였다.
- TPUv3-core-days는 쉽게 말해 해당 모델을 학습시키기 위해 사용되는 자원의 양이다. ViT가 기존 모델보다 효율적으로 사전 학습이 가능함을 알 수 있고 성능은 기존 모델과 거의 비슷하거나 우수함을 알 수 있다.
Pre-Training Data Requirements
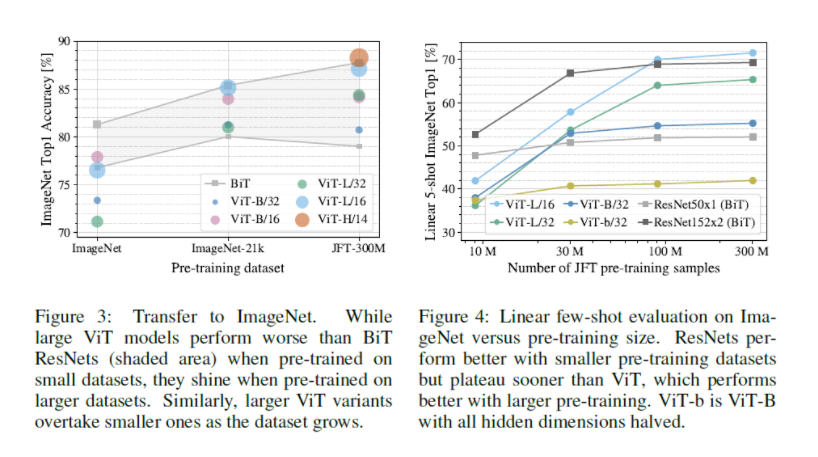
- ViT는 pre-trained 데이터셋이 작다면 성능이 좋지 않다. ImageNet에 학습시켰을 때는 BiT의 성능이 ViT보다 좋았고 JFT와 같은 거대한 데이터셋으로 pre-traiend 학습시켰을 때 비로소 ViT 성능이 BiT를 넘었다. (참고로 회색 영역은 BiT-50와 BiT-152의 성능 구간) (Figure 3)
- JFT 데이터셋을 샘플링해서 pre-trained 시킨 결과 샘플 데이터가 작으면 ResNet이 few-shot evaluation에서 더욱 우수했고 샘플 데이터가 커지면 ViT의 성능이 ResNet을 넘었다. (Figure 4)
Scaling Study
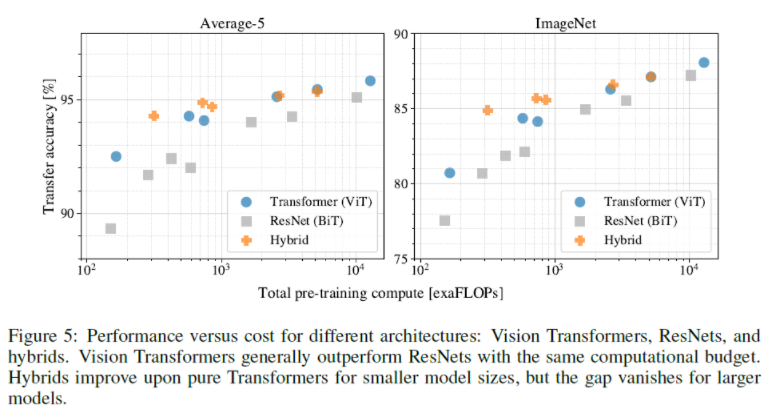
- ViT, ResNet, Hybrid 각 모델의 performance 대비 pre-training cost를 비교하였는데 ViT가 ResNet보다 효율적이다. 왜냐하면 동일한 성능 달성을 위해 ResNet보다 2~4배 정도 적은 컴퓨팅 자원을 사용하였기 때문이다.
- Hybrid는 적은 계산 비용에서는 ViT의 성능을 넘었는데 계산 비용이 커질수록 성능 차이가 사라진다.
- ViT은 모델이 커지면 성능이 어느정도 포화되었던 ResNet과 달리 포화되지 않기 때문에 추후 더 좋은 성능 향상을 기대할 수 있다.
Reference

2021 투빅스 15, 16기 이미지 세미나입니다
2개의 댓글

2021년 12월 7일
투빅스 16기 전민진입니다
ViT는 CNN에 의존하지 않고 순수한 transformer가 impage patch의 시퀀스에 다이렉트로 적용되어 image분류 task에서 좋은 성능을 보일 수 있음을 밝혔습니다.
큰 데이터셋에 pre-trained 시킨 후 작거나 중간의 image recognition 벤치마크 데이터셋에 전이 학습을 할 때 ViT는 기존 CNN SOTA모델들 보다 계산량 대비 좋은 성능을 보였습니다.
ViT는 다음과 같은 과정으로 학습을 진행합니다.
1. 우선 이미지를 여러개의 패치로 나눠 각각을 1차원으로 Flatten시키고 linear projection을 통해 D차원 벡터로 매핑시킵니다.
2. 1의 과정으로 얻은 patch embedding의 맨 앞에 class token을 추가하고, 각 시퀀스의 순서를 나타내기 위해 position embedding을 추가합니다.
3. 이후 이를 transformer에 넣어 이미지의 class를 예측합니다
hybrid architecture
- raw 이미지 패치 대신, 중간 feature map에서 input sequence를 형성할 수 있습니다.
- 적은 계산 비용에서는 기본 모델보다 뛰어나지만, 계산 비용이 커질수록 기본 모델과의 성능 차이가 사라집니다.
Fine-tuning and High resolution
- ViT는 웬만한 거대한 데이터셋 없이는 좋은 성능을 기대하기가 어렵습니다.
- 파인 튜닝 시에는 pre-trained prediction head를 제거하고, 0으로 초기화된 d*k차원의 feedforward layer를 추가합니다.
- 또한 사전 학습 떄보다 높은 resolution으로 파인 튜닝하는 것이 종종 도움이 됩니다.(단 패치의 크기는 동일하고, 다만 resolution이 더 높기 떄문에 파인 튜닝 시엔 패치의 수가 증가합니다.)
- 패치의 수는 얼마든지 늘릴 수 있으나, 길이가 늘어난 경우 사전 학습된 모델의 positional embedding은 의미가 없을 수 있습니다. 이를 보완하기 위해 2차원 구조를 사용하여 positional embedding을 조정합니다.
답글 달기
투빅스 16기 김경준입니다.