DeepPose: Human Pose Estimation via Deep Neural Networks

Introduction
 Deep Pose는 DNN 기반의 Pose Estimation(사람의 관절 위치를 찾는 task) 방법을 제안하며, 해당 task 최초로 DNN을 적용하여 SOTA를 달성하였다. 그 뿐만 아니라, 당시에는 딥러닝을 주로 Classification task에만 사용하였는 데 Regression task에서도 훌륭히 적용할 수 있음을 증명하였다.
Deep Pose는 DNN 기반의 Pose Estimation(사람의 관절 위치를 찾는 task) 방법을 제안하며, 해당 task 최초로 DNN을 적용하여 SOTA를 달성하였다. 그 뿐만 아니라, 당시에는 딥러닝을 주로 Classification task에만 사용하였는 데 Regression task에서도 훌륭히 적용할 수 있음을 증명하였다.
Pose Estimation task에서 CNN이 적합한 이유
1. 관절 위치 예측 시 이미지의 맥락을 파악하여 예측 할 수 있다. 따라서, 관절들 사이의 상관 관계를 학습할 수 있다.
2. 기존 방식은 관절 별 특징 검출(Feature Representation)과 검출기(Detector)를 만든 다음 조합하는 방식이었다면, CNN을 통해 단일 신경망으로 모든 관절 위치를 예측할 수 있다.
Deep Learning Model for Pose Estimation
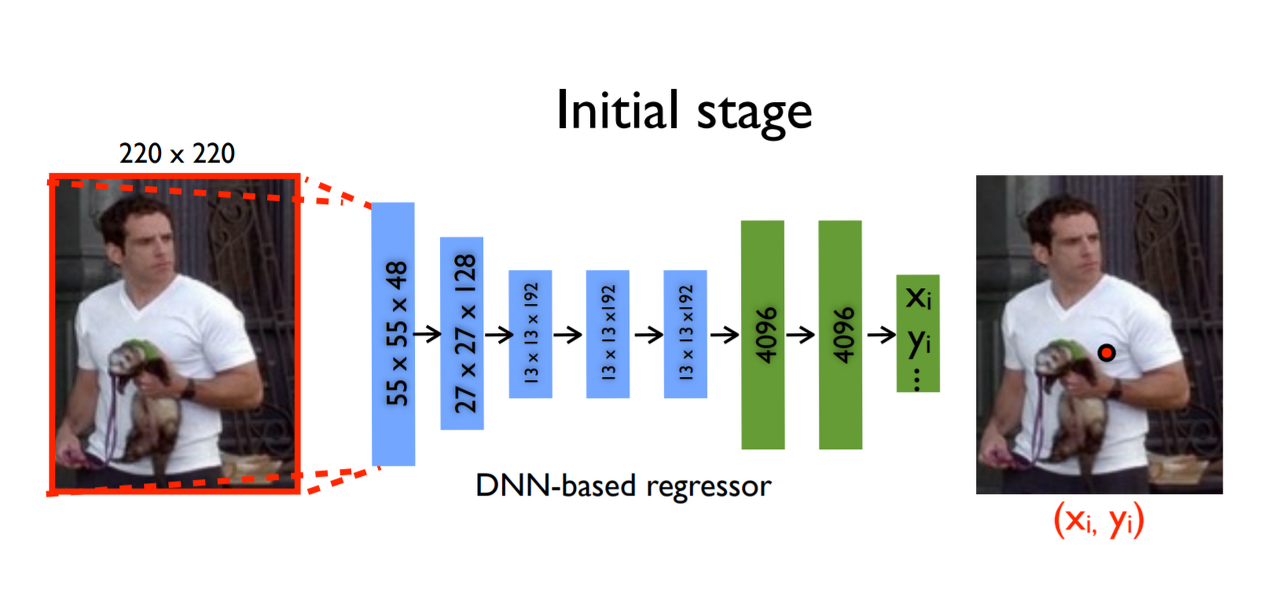 Input Image가 CNN을 통과하면, 각 관절 별로 x, y 좌표 2개씩 k개의 관절에 대해서 예측 값을 도출하며 이는 총 2k 차원의 벡터를 의미한다.
Input Image가 CNN을 통과하면, 각 관절 별로 x, y 좌표 2개씩 k개의 관절에 대해서 예측 값을 도출하며 이는 총 2k 차원의 벡터를 의미한다.
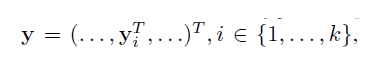
- x : Image data
- y : Ground truth pose vector
- K : 신체 관절 수
- y_i : i번째 관절의 x, y 좌표 (이미지 내 절대 좌표)
이때, 벡터 y_i는 i번째 관절의 x, y 좌표를 담은 2차원 벡터이며, 벡터 y는 2차원 벡터 k개를 쭉 펼쳐서 이어 붙인 2k 차원의 벡터이다.
y_i 벡터는 i번째 관절의 x, y 좌표와 중심점 간의 차를 구하고, 각각을 너비와 높이로 나눠 주어 normalize하여 사용한다.
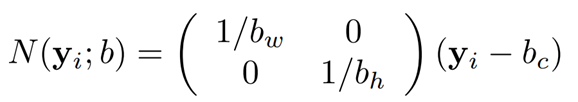
- b = (b_c, B_w, B_h) : 사람 신체에 대한 bounding box
- b_c : bounding box의 중심
- b_w : bounding box의 너비
- b_h: bounding box의 높이
예를 들어, Bounding Box (x, y, w, h) = (120, 150, 200, 300)이고 머리에 대한 좌표가 (120, 370)이라면 normalize된 좌표는 , = (0, 0.73)이다.
해당 normalize 과정을 Pose Vector 모두에 적용해주면 다음과 같은 normalized pose vector를 얻을 수 있다.
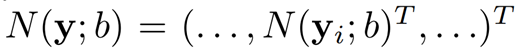
이렇게 normalize된 값을 통해 학습하여 예측 값을 도출할 수 있다. 그렇다면, 예측 값을 원래 이미지에 찍어주기 위해서는 normalize에 대한 역 연산을 진행해야하며 수식은 다음과 같다.
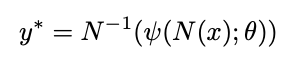 즉, Input image와 파라미터를 통해 CNN이 normalize된 예측 값을 도출하고 이를 다시 역으로 적용하면 관절 예측 벡터인 y*를 구할 수 있다.
즉, Input image와 파라미터를 통해 CNN이 normalize된 예측 값을 도출하고 이를 다시 역으로 적용하면 관절 예측 벡터인 y*를 구할 수 있다.
- x : Input Image
- φ : CNN 모델을 통과시키는 함수
- θ : 학습되는 파라미터
다만, 이런 방식(Initial Stage)의 경우 큰 이미지를 보고 예측한 결과 값이기 때문에 정교함이 떨어질 수 있다. 따라서, 이를 보완하기 위한 아이디어는 예측 좌표를 기반으로 bounding box를 다시 그리고 crop하여 다시 CNN 모델을 통과하는 Cascasde 방식(Stage S)이다.
앞서 Pose Vector에 대해 진행한 Normalize는 crop 전 이미지 내 좌표이기 때문에 이후 과정에서 원활히 사용하기 위함이다.
Cascade of Pose Regressors
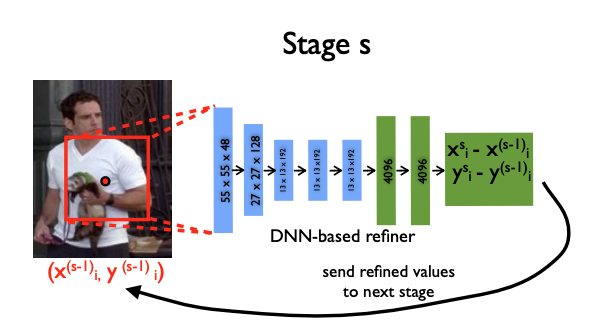
앞서, 설명한 바와 같이 예측 좌표를 기반으로 bounding box를 다시 그리고 crop하여 다시 CNN 모델을 통과시켜 정교화된 좌표 예측값을 구할 수 있다. 이는 식으로 표현하면 다음과 같다.
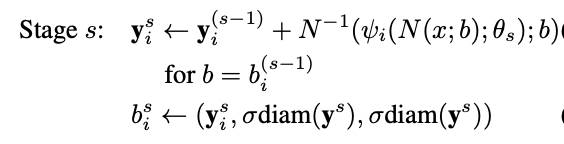
이때, 모든 좌표들에 대해서 새로운 바운딩 박스를 그리며, σ*diam(ys)라는 수식에 의해서 크기가 결정된다.
- diam(ys) : 이전에 예측한 좌표들에서 왼쪽 어깨와 오른쪽 엉덩이 좌표 간의 거리
- σ : diam(ys)를 키워주는 파라미터, 따로 수식적으로 구하기 보단 임의의 상수 (2, 3...)을 입력해준다.
Training
과정
- Stage 1 모형을 학습하여 Input Image 속 관절의 대략적인 위치를 파악한다.
- 관절 별로 Stage t 모형에 새로운 Bounding Box를 입력해 예측 값을 산출하고 이를 S번 반복한다. ()
Metric : Percent of Detected Joints (PDJ)
- 몸통의 길이를 계산한다.
- (특정 임계값 * 길이)가 반지름인 원을 생성한다.
- 예측 위치가 원 내부에 있는 지 여부를 확인한다.
- 예측 결과에 대한 PDJ (= 원 내부에 있는 경우/전체 관절수)를 계산한다.
Result
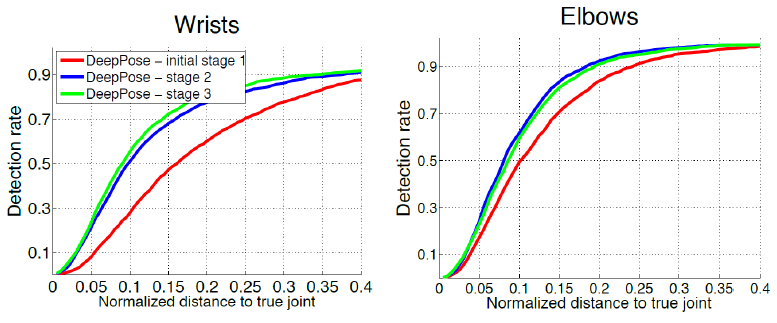
Stage 1만 진행하는 것보다 관절별 모델 학습 시 탐지 성능이 증가함을 확인할 수 있다
한계점
-
관절과 관절 간의 공간적 상관관계 정보를 고려하지 않기 때문에, 이미지 상으로 보이지 않는 관절들을 예측하기 어렵다.
-
Input Image에 대한 crop을 반복하고, 각 단계별로 별개의 CNN을 학습시키는 방식에는 비효율적인 계산 과정이 존재한다.

3개의 댓글

투빅스 16기 전민진입니다
Deep pose는 DNN 기반의 Pose estimation을 제안하는 모델입니다
input image가 cnn을 통과하면, 각 관절 별로 x,y좌표 2개씩 k개의 관절에 대해서 예측값을 도출하며, 이는 총 2k 차원의 벡터를 의미합니다.
이후 예측값을 normalize해주면, 이를 통해 학습하여 예측값을 도출할 수 있습니다.
다만, 이런 방식의 경우 큰 이미지를 보고 예측한 결과이기 때문에 정교함이 떨어 질 수 있어 이를 보완하기 위해
예측 좌표를 기반으로 bounding box를 다시 설정하고 crop하여 CNN을 통과하는 방식(cascade)를 사용합니다.
실험 결과 stage 1만 진행하는 것보다 관절별로 모델 학습 시 탐지 성능이 증가함을 확인할 수 있었습니다.
다만 이 모델의 경우 관절과 관절 간의 공간적 상관관계 정보를 고려하지 않기 때문에, 이미지 상으로 보이지 않는 관절들을 예측하기가 어렵습니다.
또한, input image에 대해 crop을 반복하고, 각 단계별로 별개의 CNN을 학습시키기 떄문에 비효율적인 계산 과정이 존재합니다.

투빅스 16기 박한나입니다.
- Deep Pose는 DNN 기반의 pose estimation 방법을 제안한 모델이며 regression task에서도 딥러닝을 잘 적용시켰습니다.
- Pose Estimation task에 CNN을 사용하면 관절 위치 예측 시 이미지의 맥락을 파악하여 관절들 사이의 상관관계를 학습할 수 있고 단일 신경망으로 모든 관절 위치를 예측할 수 있습니다.
- 이미지가 cnn을 통과하면 각 k개의 관절별로 x,y 좌표 즉 2k의 관절을 예측합니다. 해당 벡터를 정규화시킨 후 학습하여 예측값을 도출하고 역으로 적용하여 관절 예측 벡터인 y*을 구합니다.
- Stags s를 통해 예측 좌표를 기반으로 바운딩 박스를 그리고 crop 후 다시 CNN 모델을 통과하여 정교화된 좌표 예측값을 구할 수 있습니다.
- 한계점은 관절간의 공간적 상관관계 정보를 고려하지 않는다는 것과 CNN 학습에 비효율적인 계산 과정이 존재한다는 것입니다.
투빅스 16기 김경준입니다.