
작성자: UNIST 산업공학과 김건우
Contents
Unit 01. word2vec (review)
Unit 02. Optimization, Negative Sampling
Unit 03. Word prediction methods
Unit 04. GloVe
Unit 05. How to evaluate word vectors?
Unit 06. Word senses and word sense ambiguity
01. word2vec (review)
- one-hot vector cannot calculate among words (sparse representation)
- word2vec can calculate similarity among words (distributed representation)
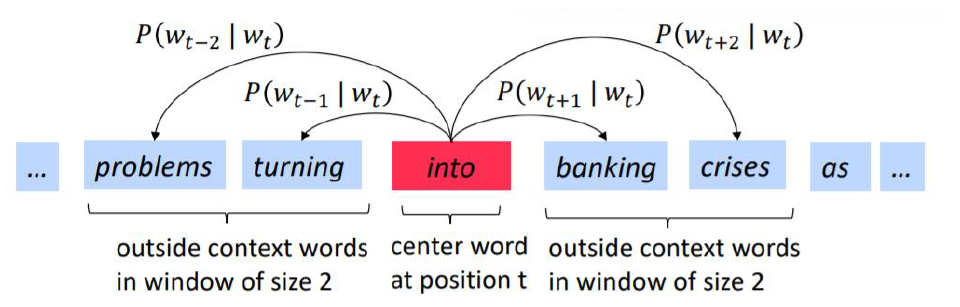
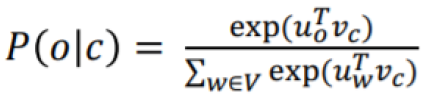
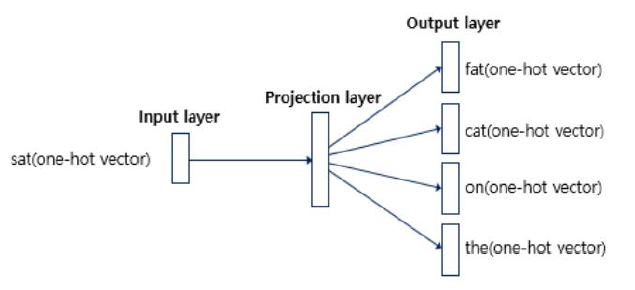
CBOW ⇒ input: context vector / output: target vector

skip-gram ⇒ input: target vector / output: context vector
02. Stochastic Gradient Descent (review)
- (Batch) Gradient Descent Algorithm
- Update 𝜃 after calculating all data's gradients
- Since it considers all data, it converges in correct direction
- As the data size increases, the training takes a long time
- Stochastic Gradient Descent (CS224 recommended)
- Randomly select one sample from the data, calculate its gradient then update 𝜃
- Since only one data is considered, it may not be able to converge in correct direction
- Training time takes less time than gradient descent algorithm
- Mini-batch Gradient Descent (Usually, the best method)
- Select mini-batch size sample from the data, calculate its gradient then update 𝜃
02. Negative Sampling
- word2vec problem: high cost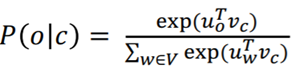
- Denominator ('normalizing factor' which computes over the entire vocab') is too computationally expensive (skip-gram)
solution
- Negative sampling: Maximizing the similarity of the words in the same context and minimizing it when occur in different contexts. Randomly select 'k' number of negative samples.
objective function (maximize)

change it to negative log -> objective function (minimize)

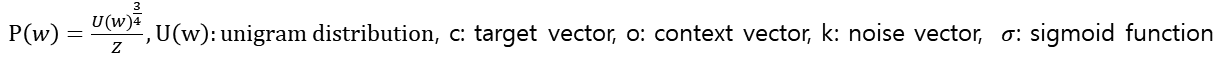
03. Word Prediction Methods

Problem
- Increase in size with vocab
- Very high dimensional
- Subsequent classification models have sparsity issue
Solution
- Dimensionality Reduction on co-occurrence matrix
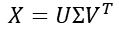
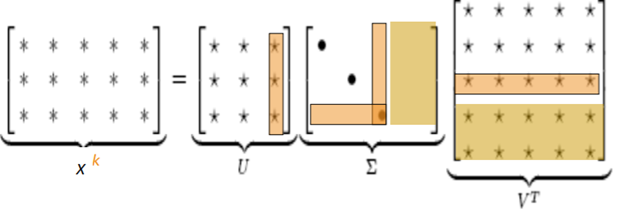
- Scaling counts in the cell
-
Min(X,t) with t ≈100
-
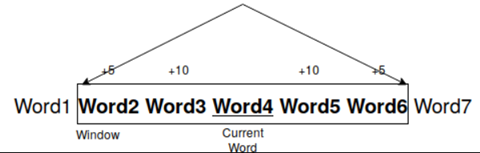
Ramped Window
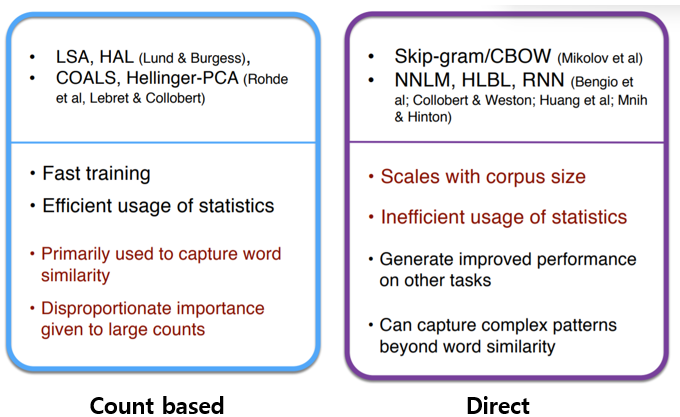
04. GloVe (Global Vectors for Word Representation)

Glove uses both count based method and direct method
- co-occurence matrix + calculate similarity among words
- making embedding vector which follows the value of dot product between embedded target vector and context vector converge in co-occurence probabilites


Derive objective function

 Problem: co-occurence matrix can be sparse matrix. Low values in X are useless
Problem: co-occurence matrix can be sparse matrix. Low values in X are useless
Solution: adjust weighting function 'f' to loss function
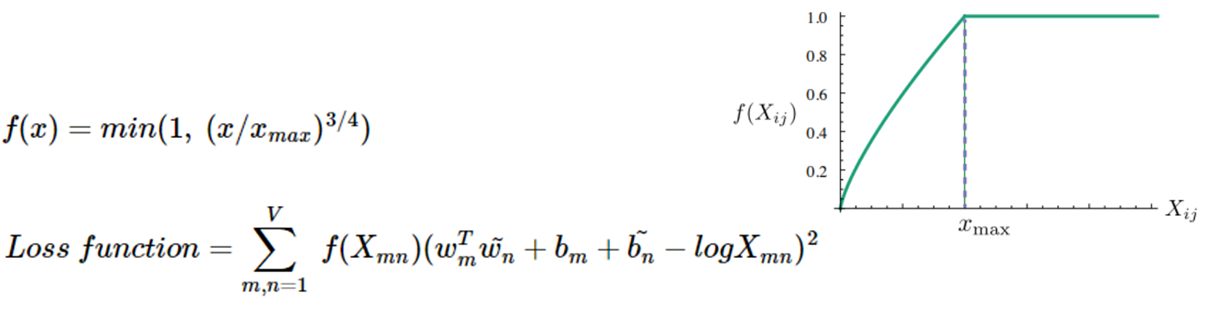
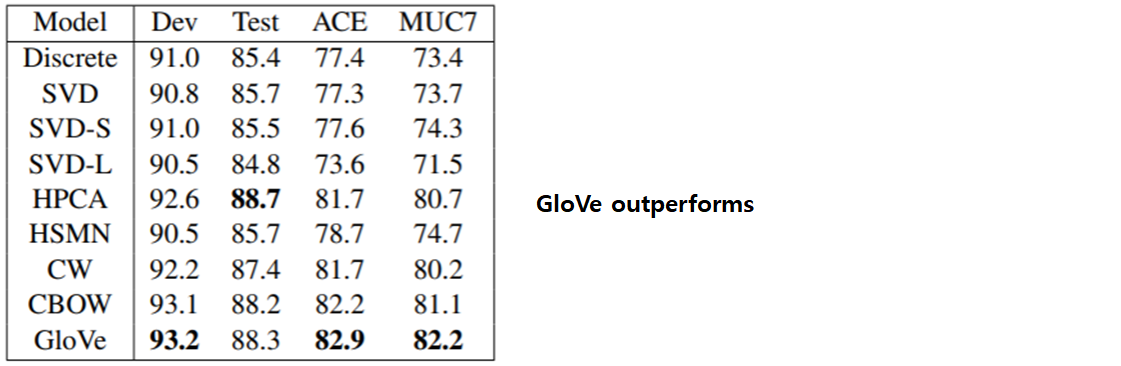
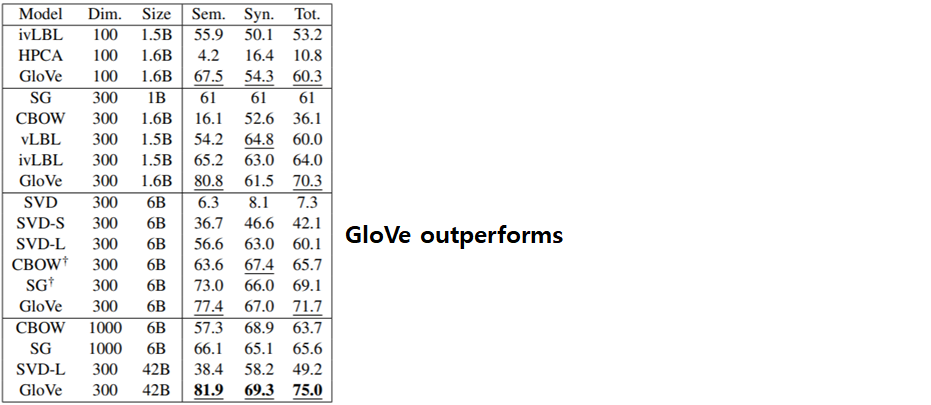
Experiment Results

05. How to evaluate word vectors?
- Extrinsic evaluation
- Evaluation on a real task
- Take a long time to compute accuracy
- Unclear if the subsystem is the problem or its interaction or ther- Intrinsic evaluation
- Evalutaion on a specific subtask
- Fast to compute
- Helps to understand that systemExtrinsic Evaluation
Named entity recognition: finding a person, organization or location
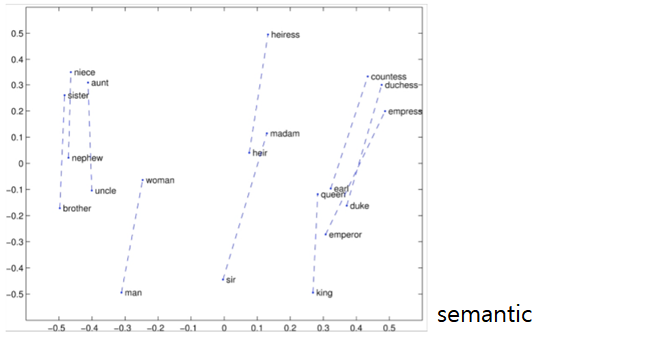
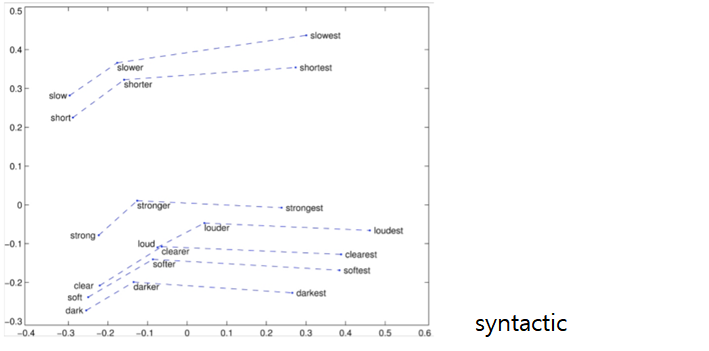
Word Analogies task - syntactic / semantic

Intrinsic Evaluation
correlation evaluation
- Evaluate word embedding by calculating correlation between distance among word vectors and human judgements

06. Word senses and word sense ambuigity
Most words have lots of meanings
- Common words
- Words that have existed for a long time
Example: Pike

Improving Word Representation Via Global Context And Multiple Word Prototypes (Huang et al. 2012)
1) Fix window size, then gather occurrence data
2) Calculate context words weighted average word on each context word
3) Cluster context representation by using k-means clustering
4) Connect each word on allocated cluster and re-labelling then, train word representation on its cluster

Linear Algebraic Structure of Word Senses, with Applications to Polysemy
Create new word vector by linear combination with weight based on weighed frequency and existing word vector.
- well classifying how the word’s meaning is used when having clustering with this new vector

Reference
http://sujayskumar.blogspot.com/2017/02/word-embedding-techniques.html?m=1
http://solarisailab.com/archives/959
https://www.baeldung.com/cs/nlps-word2vec-negative-sampling
https://wikidocs.net/22660
https://velog.io/@tobigs-text1415/Lecture-2-Word-Vectors-and-Word-Senses
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture02-wordvecs2.pdf
https://www.youtube.com/watch?v=8wG0sJm1EaU&list=PLetSlH8YjIfVdobI2IkAQnNTb1Bt5Ji9U&index=2

5개의 댓글

투빅스 16기 주지훈
- Word2Vec의 효율성을 높이는 방법
- SGD: 데이터로부터 랜덤으로 하나의 샘플을 뽑고, 그것의 기울기를 계산해 업데이트를 한다. 계산량이 적다.
- Negative Sampling: Word2Vec의 높은 비용을 해결하기 위해 같은 문맥 내 유사한 단어를 최대화하고, y가 다른 문맥에서 발생할 때에는 최소화한다.
- Word Prediction 방법
- Window based co-occurence matrix: window에 각 단어가 몇 번 등장했는지를 센다. 차원이 크다는 단점이 있다.
- GloVe: count based와 direct method 모두 사용하여 co-occurrence matrix를 고려하고 단어가 유사도를 계산-한다.
- word vector 평가방법
- Extrinsic evaluation: 현실 문제에 대한 평가이고 정확도를 계산하는 데 오랜 시간이 걸린다. 어떤 시스템이 문제인지 아니면 시스템간의 교호작용 때문인지 불확실하다.
- Intrinsic evaluation: 특정 subtask를 통해 성능을 평가하고 계산이 매우 빠르며 시스템을 이해하는 데 도움이 된다.
- Word senses and word sense ambiquity
하나의 단어가 여러 의미를 가질 때
- 하나의 단어가 벡터 공간에서 서로 다른 cluster를 형성하는 경우에는 해당 단어를 여러 개로 분류해서 벡터를 생성한다.
- 하나의 단어의 서로 다른 의미를 나타내는 벡터들에 가중치를 부여하고 선형결합을 통해 새로운 word vector를 생성한다.
GloVe 함수가 왜 등장했는지부터 목적함수, 그리고 성능까지 전반적인 내용을 쉽게 이해할 수 있었습니다. 감사합니다!

투빅스 15기 김현지
Negative Sampling
- Word2vec의 문제점: 예측함수의 부모의 계산비용이 크다.
- 해결: 같은 맥락에 있는 단어들의 유사도를 최대화하고, 다른 맥락에서 발생할 때는 유사도를 최소화한다.
Word Prediction Methods
- count based
- 학습 속도가 빠르며 통계 정보를 효율적으로 사용 가능하다.
- 단어간의 유사성 여부만 포착 가능하므로 단어간의 관계를 고려 할 수 없다.
- 큰 빈도수에 과도하게 중요도를 부여한다.
- Direct
- 코퍼스 크기에 따라 성능이 좌우되며, 통계 정보를 효율적으로 사용하지 못한다.
- 부분의 영역에서 좋은 성능을 보이고, 단어간의 유사성 이상의 복잡한 패턴을 포착할 수 있다.
GloVe
- count based와 direct prediction의 장점을 동시에 가지는 모델
⇒ corpus의 통계정보 사용 가능 + 단어 벡터 간의 유사도 측정 가능
Word vector 평가 방법
- Extrinsic evaluation: 실제 task에 대한 평가방법으로, 정확도를 계산하는데 오랜 시간이 걸리며 문제가 생겼을 때 subsystem 때문인지 시스템간 interaction 때문인지 파악하기 어렵다.
- Intrinsic evalution: 특정 subtask에 대한 평가방법으로, 계산 속도가 빠르고 시스템을 이해하는데 도움이 된다.
좋은 자료와 발표 감사합니다! 특히 GloVe의 목적함수를 하나하나 나누어 자세히 수식적으로 유도해주셔서 해당 모델을 이해하는데 큰 도움이 되었습니다~

투빅스 16기 이승주
- word2vec
비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가집니다. 맥락단어가 input, 중심단어가 output인 CBOW 방식과 중심단어가 input, 맥락단어가 output인 Skip-gram 방식이 있습니다. Word2Vec의 효율성을 높이는 방법으로는 SGD 방식이 있습니다. 그러나 Sparse한 vector는 불필요한 계산이 일어나 SGD에서 문제가 발생합니다. 또한 subsampling과 negative sampling에 쓰이는 확률값들은 고정된 값으로 학습을 시작할 때 미리 구해놓는 방식으로 word2vec의 효율을 높입니다. - Count Based : Co-occurrence matrix(동시발생행렬)
word prediction methods에는 count based와 direct prediction, 크게 두가지로 나눌 수 있습니다. 특히 count based는 효율적으로 통계 정보 사용이 가능하기 때문에 skip-gram의 단점을 보완해줍니다. 동시 발생 행렬은 크게 단어-문맥 행렬과 단어-문서 행렬이 있습니다. 단어-문서 행렬은 한 문서를 기준으로 단어의 등장 횟수를 행렬로 나타내는 방법으로서 LSA(잠재적 의미 분석)를 가능하게 하는 기법입니다. - GloVe(Global Vectors for Word Representation)
count based와 direct prediction의 장점을 동시에 가진 GloVe는 corpus 전체의 통계정보 사용하며 동시에 임베딩된 단어벡터 간의 유사도 측정 가능하다는 특징을 갖고 있습니다. - How to evaluate word vector?
word embedding모델의 평가방법은 크게 외적평가와 내적평가로 나눌 수 있습니다. 외적평가는 현실 문제에 직접 적용했을때의 성능을 평가하는 방식입니다. 그러나 문제가 발생했을 때 어떤 시스템이 문제인지, 아니면 시스템간의 교호작용 때문인지 평가하기가 어렵습니다. 내적평가는 word embedding 자체의 성능을 측정하기 위해 specific/intermediate subtask를 통해 성능을 평가합니다. 또한 계산속도도 빠릅니다. 크게 word analogies와 correlation evaluation이 있습니다. - Word senses and word sense ambiguity
다양한 의미를 가지고 있는 단어들을 제대로 의미 표현을 하시 위한 방법을 제시합니다. 하나의 단어가 벡터 공간에서 서로 다른 cluster를 형성하는 경우, 해당 단어를 여러개로 분류해서 벡터를 생성합니다. 또 다른 방법은 한 단어의 서로 다른 의미를 나타내는 벡터들에 가중치를 부여하고 선형결합을 통해 새로운 word vector를 생성합니다.
좋은 강의 감사합니다!

기존에 알고 있던 word2vec과 SGD방법에 이어서 word2vec의 문제점을 보완하기 위한 negative sampling에 관해 알게되었습니다. Negative sampling은 같은 맥락에 있을때 유사도를 최대로 하며, 다른 맥락에 있을때는 유사도는 최소로 합니다.
단어를 prediction하는 방법으로는 count based와 direct으로 나뉩니다. Count based는 단어의 유사성만 파악하여 단어간의 관계성을 알지 못합니다. Direct의 경우 단어간의 패턴을 찾아 해결할 수 있습니다.
Glove model은 conut based의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적으로 나왔고, 이에 대한 성능 수식들을 살펴보왔습니다. 다소 복잡한 목적함수를 이해하기 힘들었는데 그 부분을 잘 풀어서 설명해 주셔서 감사합니다
투빅스 14기 박지은
이번 강의에서는 저번에 배운 word2vec과 stochstic gradient descent를 복습하고, 새로운 최적화 기법으로 negative sampling에 대하여 배웠습니다. Negative sampling 기법은 word2vec의 denominator 연산량이 많다는 단점을 보완하기 위하여 같은 맥락에 있는 단어들의 유사도를 최대화하고, 다른 맥락에서 y가 발생할 때의 유사도를 최소화하는 방법입니다. 단어 임베딩을 찾기 위한 방법으로 크게 matrix factorization을 활용하는 count-based 방법론과, window에 기반하여 학습하는 direct 방법론이 있습니다. 이들은 각각 전체 맥락 단위로 유사도를 파악하는 것과, 작은 단위에서 단어 임베딩을 학습하는 것에 유효하며, 서로 반대는 취약하다는 단점이 있는데 이를 보완하기 위해 GloVe가 제안되었습니다. GloVe는 count-based와 direct 방법론을 co-occurence matrix와 단어 간 유사도를 모두 고려하는 모델로, 목적함수는 두 단어벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 정의됩니다. GloVe 목적함수의 경우 처음에는 복잡하게 느껴졌는데 하나하나 이유와 과정을 설명해주셔서 이해하는 데에 도움이 되었습니다. 감사합니다!