
작성자: 고려대학교 통계학과 김현지
Contents
1. Language Modeling
2. n-gram Language Model
3. Neural Language Model
4. RNN Language Model
1. Language Modeling
Language Modeling: 주어진 단어의 시퀀스에 대해, 다음에 어떤 단어가 나올지 예측하는 작업
Language Model: Language Modeling을 수행하는 시스템
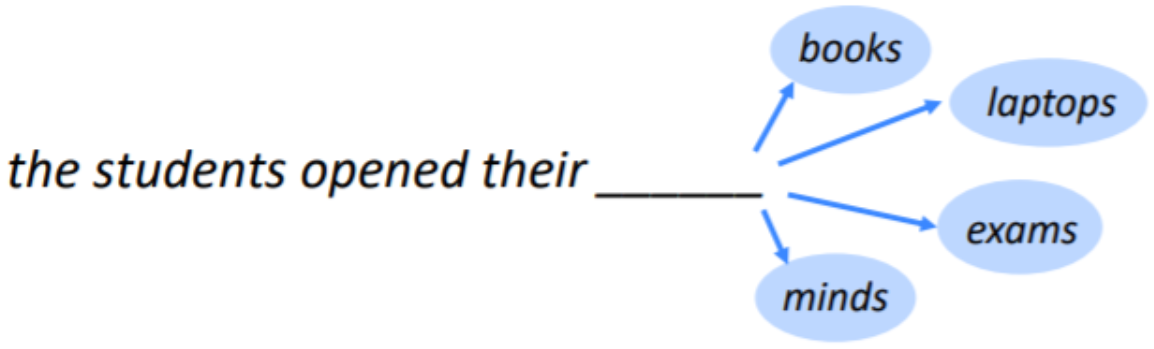
- More formally: 단어들의 시퀀스 x^{(1)}, x^{(2)}, ..., x^{(t)}가 주어졌을 때, 다음 단어 x^{(t+1)}의 확률분포를 계산하는 것
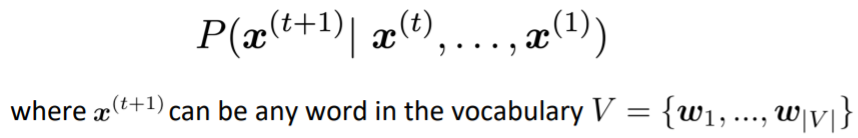
- Language Model은 텍스트에 확률을 할당하는 시스템으로 생각할 수 있다.
- 예를 들어 텍스트의 일부 를 가지고 있을 때, Language Model에 따라 이 텍스트가 발생할 확률(자연스러운 문장일 확률)은 다음과 같다.

⇒ 단어의 시퀀스(문장)에 대해서 얼마나 자연스러운 문장인지를 확률을 이용해 예측한다.
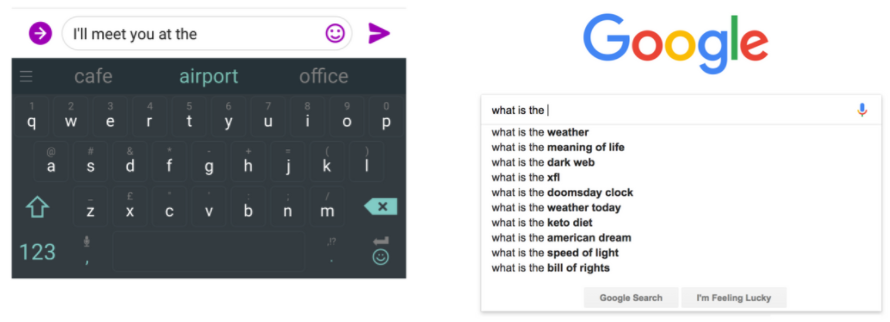
You use Language Models every day!
2. n-gram Language Models
Deep Learning 이전에 Language Model에 주로 사용된 모델
N-gram: n개의 연속된 단어 덩어리
"the students opened their _"
- unigrams: "the", "students", "opened", "their"
- bigrams: “the students”, “students opened”, “opened their”
- trigrams: “the students opened”, “students opened their”
- 4-grams: “the students opened their”
Idea: 서로 다른 N-grams의 빈도에 대한 통계를 수집하고 이를 다음에 올 단어를 예측하는 데 사용한다.
simplifying assumption: 단어 은 앞의 개의 단어에만 영향을 받는다.

- Question: n-gram과 (n-1)-gram의 확률을 어떻게 얻을 수 있을까?
- Answer: 큰 텍스트 뭉치(corpus)에서 그들의 빈도를 counting하여 구한다.
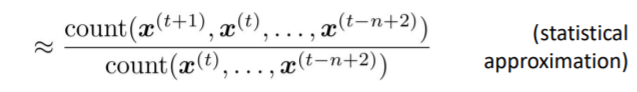
Example
4-gram model

- 4-gram model을 사용하므로 'students' 이전 단어들을 고려하지 않는다.
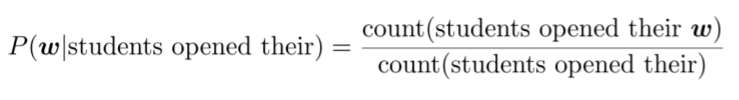
- 'students opened their' 다음에 단어 가 나올 확률: 4-gram을 3-gram으로 나눈 값
- For example, suppose that in the corpus:
- "students opened their" : 1,000번 발생
- "students opened their books" : 400번 발생
⇒
- "students opened their exams" : 100번 발생
⇒
N-gram Language Model의 문제점
1. Sparsity Problems
- Sparsity Problem 1
- Problem: "students opened their "가 훈련 코퍼스에 존재하지 않으면, 의 확률은 0이 된다. ⇒ 위 조건부 확률의 분자가 0
- (Partial) Solution: smoothing 모든 의 count에 대해 작은 값의 를 더해준다.
- Sparsity Problem 2
- Problem : "students opened their" 훈련 코퍼스에 존재하지 않으면, 의 확률은 계산할 수 없다. ⇒ 위 조건부 확률의 분모가 0
- (Partial) Solution: backoff n-gram 대신 (n-1)-gram인 "opened their"의 값으로 대신한다.
n이 커질수록 문제가 심각해진다. 따라서 일반적으로 n < 5로 설정한다.
2. Storage Problems

- Storage: Corpus 내 모든 n-gram에 대한 count를 저장해줘야 한다.
이 커지거나 corpus가 증가하면 모델의 크기가 증가한다.
Generating text with a n-gram Language Model
trigram Language Model


- 인 2개의 단어 "today the"로 다음 단어를 예측한다.
- 해당 단어들을 기반으로 확률 분포를 구하면, 가능성이 있는 단어들의 확률 분포를 얻을 수 있다.
- 생각보다 문법적인 결과이다.
- 하지만 전체적인 의미에서 일관성이 없다. '다음 단어는 오직 직전의 개의 단어에만 영향을 받는다'라는 가정 때문에 이전 문맥을 충분히 반영하지 못한다.
- 의 크기를 늘리면 이러한 문제를 어느정도 해결할 수 있겠지만 동시에 Sparsity 문제가 심해지게 된다.
3. Neural Language Model
Recall the Language Modeling task:
- Input: 단어들의 시퀀스
- Output: 다음에 올 단어의 확률 분포
Window-based neural model
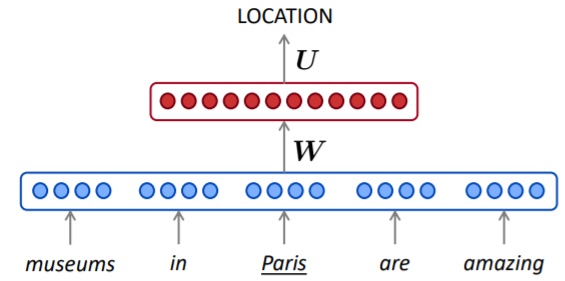
- Lecture 3에서 NER에 적용했던 Window-based neural network는 Center를 기준으로 앞뒤의 window를 정했다면

- Lecture 6에서는 예측할 단어의 이전에 window를 고정
A fixed-window neural Language Model
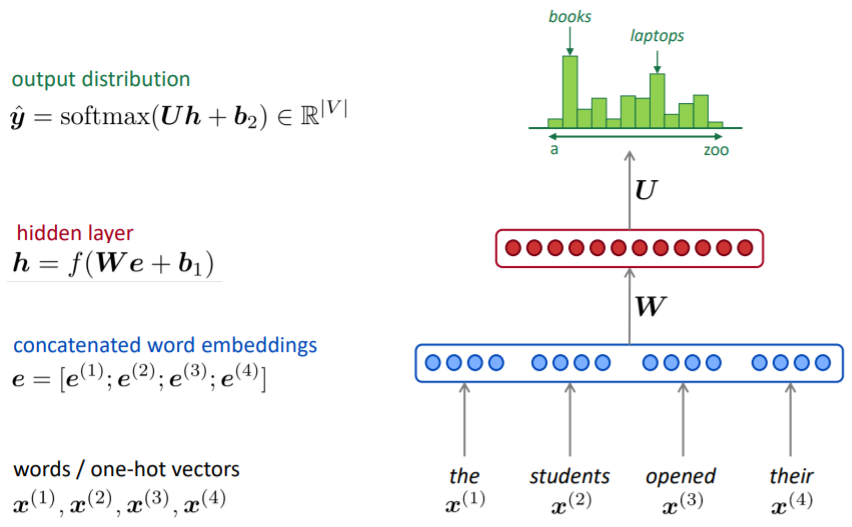
window 사이즈 만큼의 단어를 one-hot vector 형태로 입력하여 임베딩한다. 임베딩 벡터들을을 concatenate하여 가중치 값과 연산한 후 hidden layer를 통과한다. 최종적으로 softmax 함수를 통해 각 단어들의 확률 분포값을 얻을 수 있으며, 이를 통해 제일 가능서이 높은 다음 단어를 예측한다.
이와 같이 특정 개수의 단어를 Neural Network의 input으로 받는 model을 Fixed-window Neural Language Model이라고 한다.
n-gram LM에 대한 개선점
- 단어의 embedding을 통한 sparsity problem 해결
- 관측된 n-gram을 저장할 필요가 없음
남아 있는 문제점
- 고정된 window가 너무 작다. → n-gram 모델과 같이 문맥을 반영하지 못한다.
- Window를 크게 하면 도 커진다. → window 크기의 한계
- 와 에는 완전히 다른 가중치 가 곱해지기 때문에 No symmetry하다. → 단어의 위치에 따라 곱해지는 가중치가 다르기 때문에 모델이 비슷한 내용을 여러 번 학습하는 비효율성을 가진다.
어떤 길이의 input도 처리할 수 있는 neural architecture가 필요하다!
4. RNN Language Model
Recurrent Neural Networks (RNN)
- Core idea: 동일한 가중치 W를 반복적으로 적용한다.
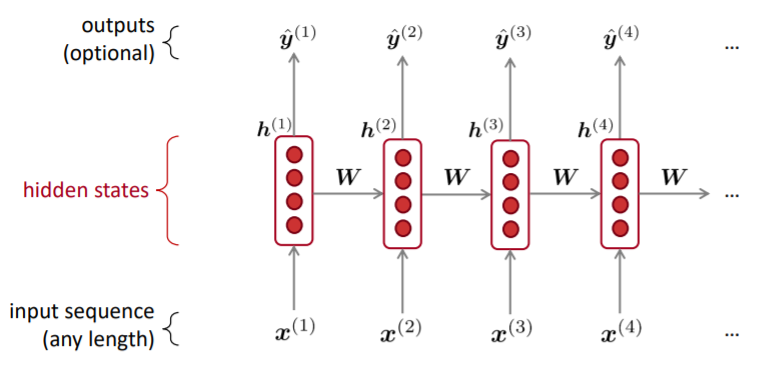
- 기존의 뉴럴 네트워크 알고리즘은 고정된 크기의 입력을 다루 데는 탁월하지만 ,가변적인 크기의 데이터를 모델링하기에는 적합하지 않다.
- RNN(Recurrent Neural Network, 순환신경망)은 시퀀스 데이터를 모델링하기 위해 등장했으며, 기존의 뉴럴 네트워크와 다른 점은 '기억(hidden state)'을 갖고 있다는 점이다.
- 기존의 신경망 구조에서는 모든 입력이 각각 독립적이라고 가정했는데, 많은 경우에 이런 방법은 옳지 않을 수 있다. 예를 들어, 문장에서 다음에 나올 단어를 추측하고 싶다면 이전에 나온 단어들의 연속성은 아는 것 자체가 큰 도움이 될 수 있다.
- RNN이 recurrent하다고 불리는 이유는 동일한 태스크를 한 시퀀스의 모든 요소마다 적용하고, 출력 결과는 이전의 계산 결과에 영향을 받기 때문이다.
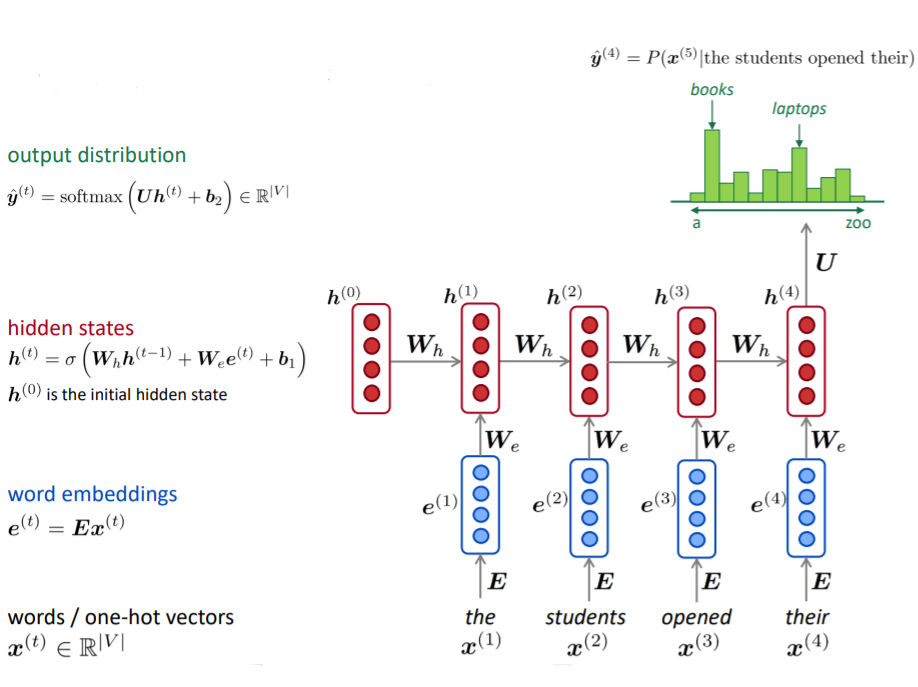
A RNN Language Model
-
RNN 계층은 그 계층으로의 입력과 1개 전의 RNN 계층으로부터의 출력을 받는다. 그리고 이 두 정보를 바탕으로 현 시각의 출력을 계산한다.
-
: 시간 스텝에서의 입력 벡터, one-hot vector 형태
-
: 입력 벡터 에 대한 word embedding
-
: 시간 스텝에서 RNN의 기억을 담당하는 hidden state
-
RNN에는 가중치가 2개 있다.
- : 입력 의 임베딩 를 출력 로 변환하기 위한 가중치
- : RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치
- 편향
-
결과로 시각 의 출력 가 된다. 이 는 다음 계층을 향해 위쪽으로 출력되는 동시에, 다음 시각의 RNN 계층(자기 자신)을 향해 오른쪽으로도 출력된다.
-
현재의 출력()은 한 시각 이전 출력()에 기초해 계산됨을 알 수 있다.
-
다른 관점으로 보면, RNN은 라는 '상태'를 가지고 있으며, 위 식의 형태로 갱신된다고 해석할 수 있다.
-
그래서 RNN 계층을 '상태를 가지는 계층' 혹은 '메모리(기억력)가 있는 계층'이라고 한다.
장점
- 입력(input)의 길이에 제한이 없다.
- (이론적으로) time step 에서 여러 이전 단계의 정보를 사용할 수 있다.
- 입력의 길이가 길어져도 모델의 크기가 증가하지 않는다.
- 매 time step 에 동일한 가중치를 적용하므로 symmetry하다.
단점
- Recurrent 계산이 느리다.
- 이론적으로는 먼 곳의 정보도 반영할 수 있지만, 실제로는 vanishing gradient problem 등의 문제 등으로 잘 반영되지 않은 경우도 있다.
Training a RNN Language Model
- 단어 들로 이루어진 시퀀스의 큰 corpus를 준비한다.
- 를 순서대로 RNN-LM에 입력하고, 매 step 에 대한 출력분포 를 계산한다.
- 주어진 단어에서부터 시작하여 그 다음 모든 단어들에 대한 확률을 예측
- step 에 대한 손실함수 Cross-Entropy를 계산한다.
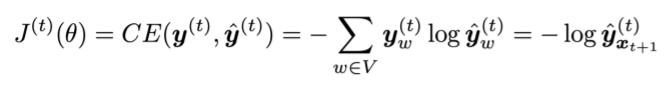
- 전체 training set에 대한 손실을 구하기 위해 평균값을 구한다.
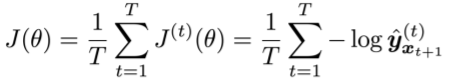
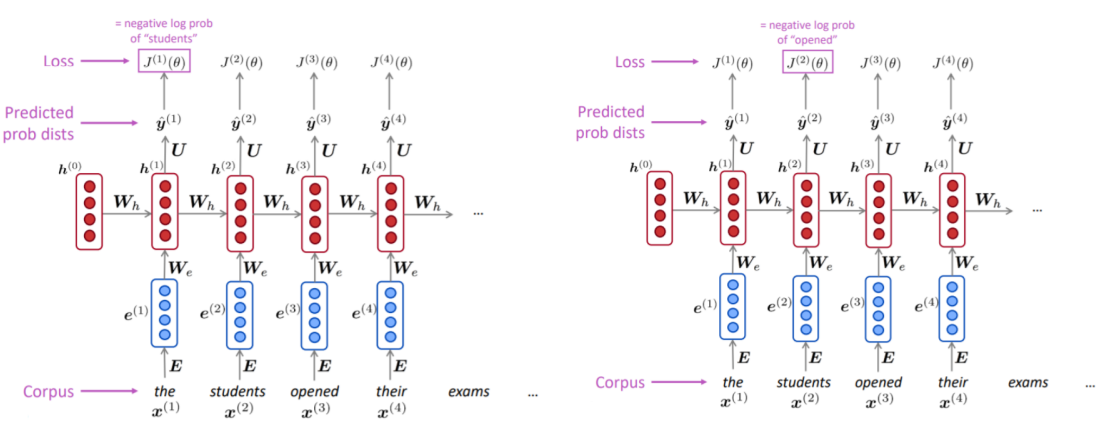
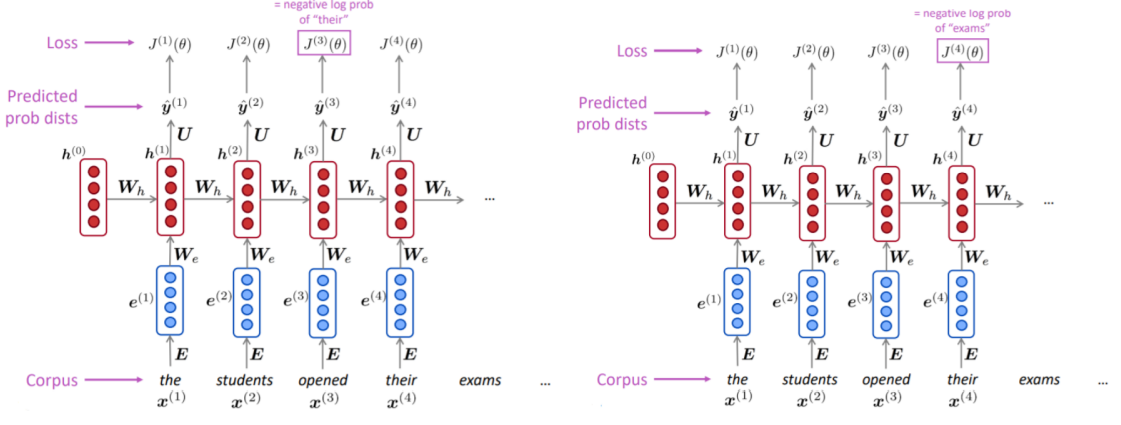
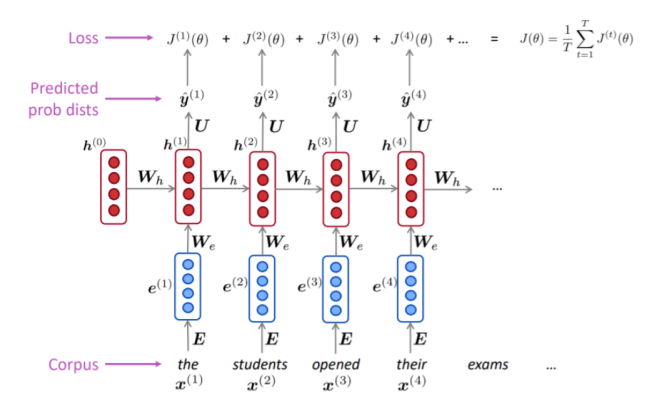
- 다만 전체 corpus 에 대한 loss와 gradients를 계산하는 데는 많은 시간이 걸리기 때문에, 실제로는 문장이나 문서 단위로 입력을 주기도 한다.
- SGD를 통해서 Optimize하는 것도 하나의 방법이다.
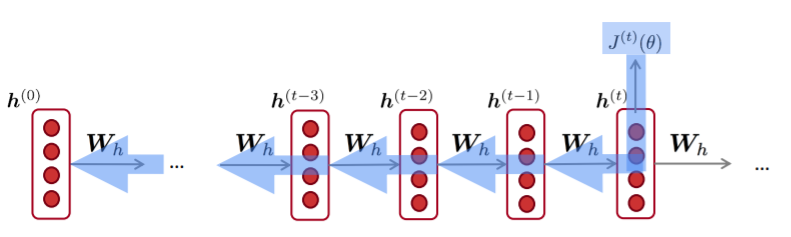
Backpropagation for RNNs
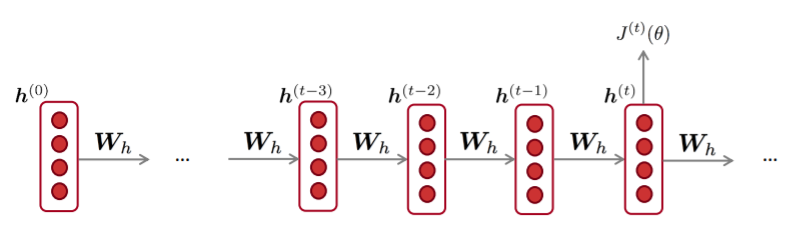
Question: 반복되는 가중치 행렬 에 관한 의 도함수는 어떻게 구할까?
Answer: 반복되는 가중치에 관한 gradient는 그것이 나타날때마다의 gradient의 합이다.
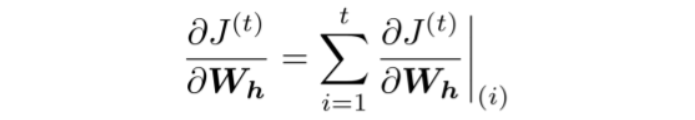
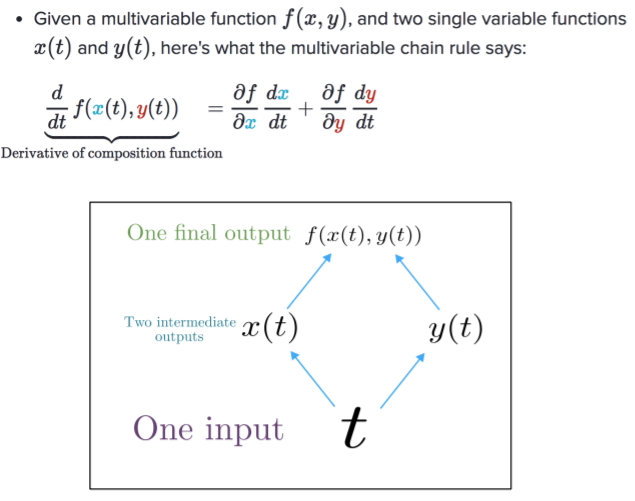
Multivariable Chain Rule
Backpropagation for RNNs: Proof sketch
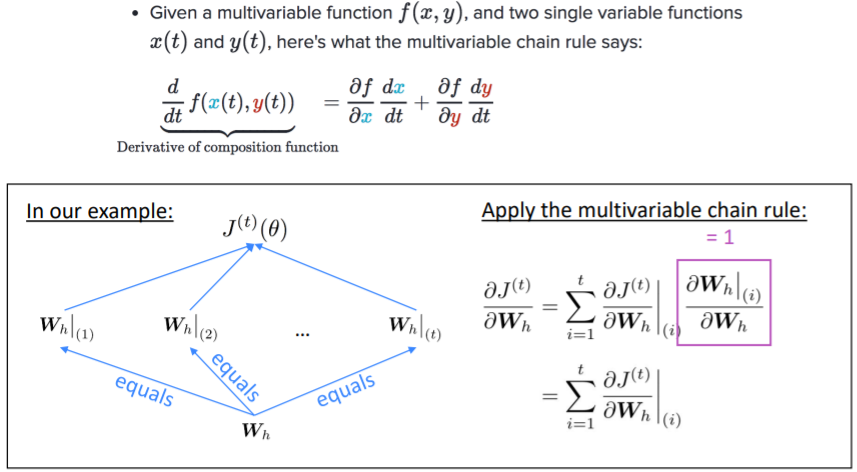

Question: 이걸 어떻게 계산할까?
Answer: BPTT(Backpropagation Through Time) → timesteps 에 따라 gradients를 더해간다.
Generating text with a RNN
- n-gram Language Model과 같이 RNN Language Model을 사용해 반복된 샘플링으로 text를 생성할 수 있다.
- 샘플링된 출력은 다음 단계의 입력이 된다.
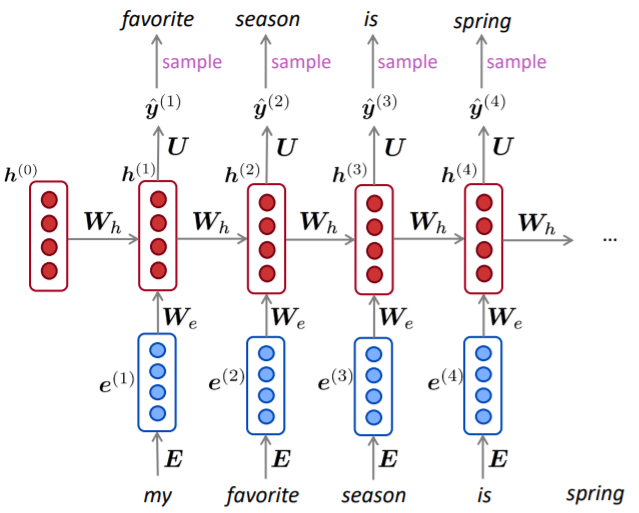
특정 종류의 text에서 RNN-LM을 학습시킨 다음 해당 style의 text를 생성할 수 있다.
-
RNN-LM trained on Obama speeches:

-
RNN-LM trained on Harry Potter:

-
RNN-LM trained on recipes:

-
RNN-LM trained on paint color names:

Evaluating Language Models
-
Language Models을 위한 대표적인 평가 지표는 Perplexity이다.

⇒ Language Model을 통해 예측한 corpus의 inverse를 corpus의 길이로 normalize해준다. -
Perplexity는 출현할 단어의 확률에 대한 역수(inverse)라고 할 수 있다.
-
cross-entropy에다가 로그를 취한값의 exponential 값과 같다.
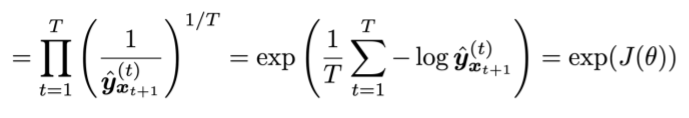
-
Perplexity 값이 작을수록 좋은 Language Model이다.
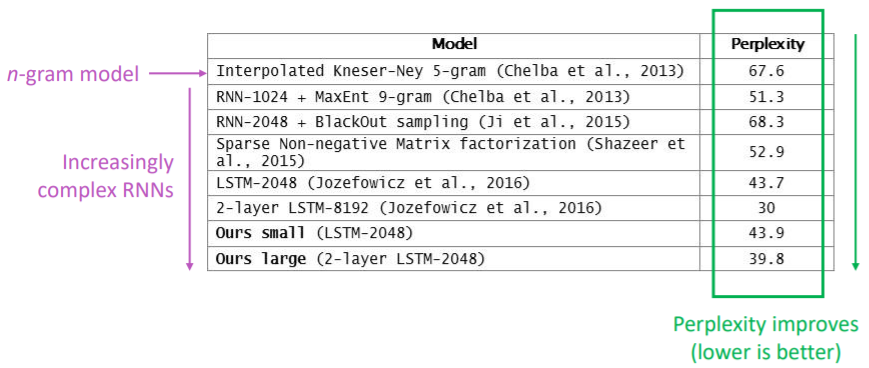
RNNs can be used for tagging
e.g. part-of-speech tagging, named entity recognition
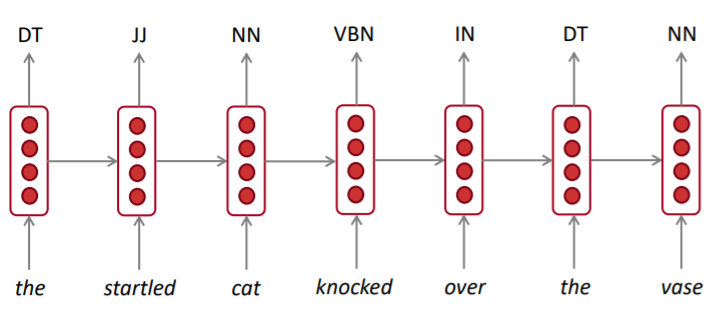
RNNs can be used for sentence classification
RNNs can be used for sentence classification
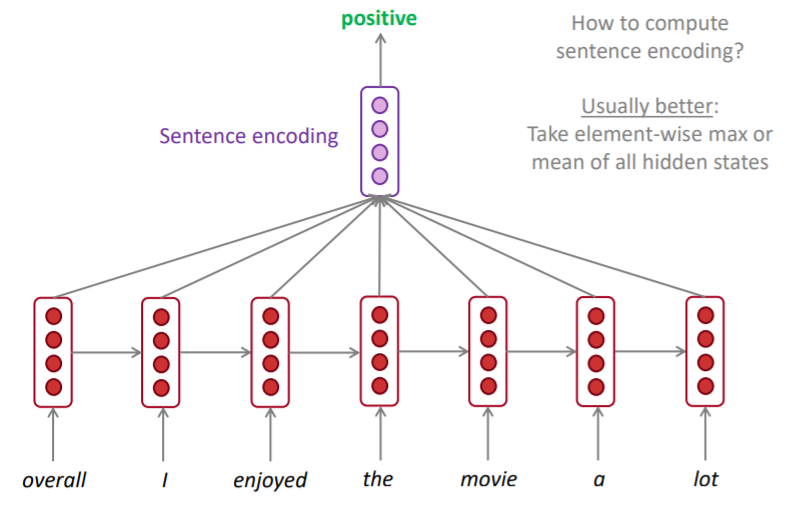
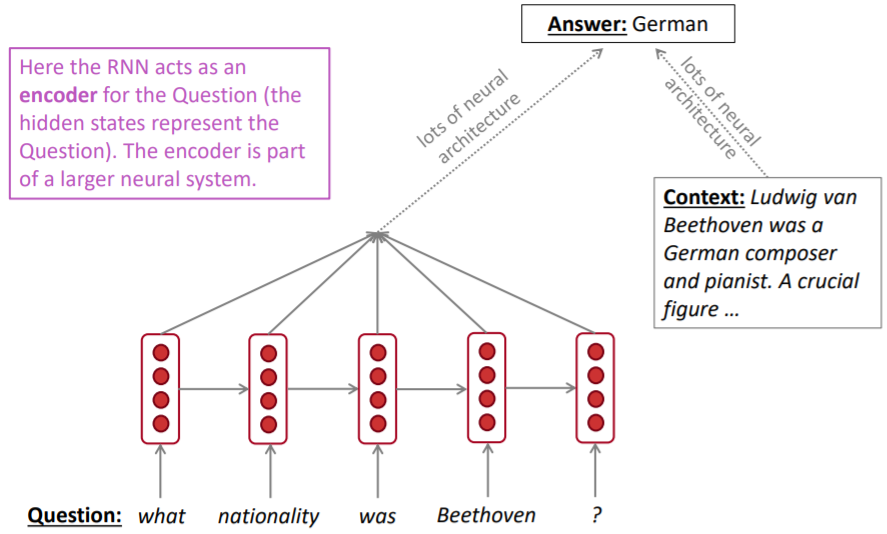
RNNs can be used as an encoder module
e.g question answering, machine translation, many other task!
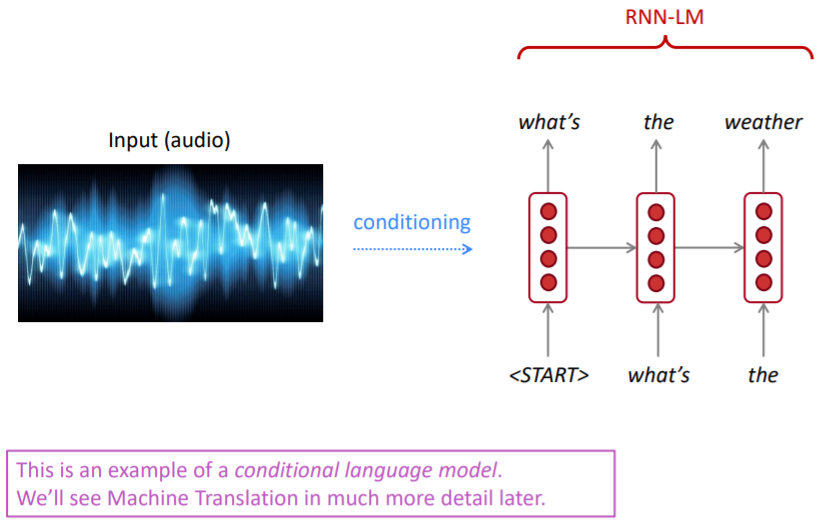
RNN-LMs can be used to generate text
e.g. speech recognition, machine translation, summarization
Standford CS224N: NLP with Deep Learning | Winter 2019
Reference

2개의 댓글

16기 이승주
Language Modeling은 주어진 단어의 시퀀스에 대해, 다음에 어떤 단어가 나올지 예측하는 작업이며
Language Model은 텍스트에 확률을 할당하는 시스템으로 생각할 수 있다.
n-gram Language Models은 Deep Learning 이전에 Language Model에 주로 사용된 모델이다.
- Sparsity Problems
- Storage Problems
Neural Language Model은 특정 새수의 단어를 neural network의 input으로 받아 각 단어들의 확률 분포를 구하고 가장 가능성이 높은 단어를 다음 단어를 예측하는 모델이다.
RNN이 recurrent하다고 불리는 이유는 동일한 태스크를 한 시퀀스의 모든 요소마다 적용하고, 출력 결과는 이전의 계산 결과에 영향을 받기 때문이다.
16기 주지훈
Language Modeling: 주어진 단어의 시퀀스에 대해, 다음에 어떤 단어가 나올지 예측하는 작업
Neural Language Model: 특정 새수의 단어를 neural network의 input으로 받아 각 단어들의 확률 분포를 구하고 가장 가능성이 높은 단어를 다음 단어를 예측하는 모델
RNN: 동일한 가중치 W를 반복적으로 적용, 여러 이전 단계의 정보를 사용할수 있고 입력의 길이에 제한이 없다.
Language Model의 평가지표
강의로 들을 땐 RNN에 대해 이해가 잘 안 됐는데, 현지님 발표를 들으니 이해할 수 있었습니다! 쉽게 설명해주셔서 감사합니다 :)