
작성자: 14기 박지은
1. Purely Character-level Models
1-1. Human Language Sounds
이번 주제를 살펴보기에 앞서, 언어학 용어를 몇 가지 짚고 넘어가겠습니다.
- Phonetics (음성학): 사람의 말소리를 과학적으로 연구하는 학문으로 말소리의 물리적인 발성과 인지를 연구
- Phonology (음운론): 특정 개별 언어 또는 여러 언어의 소리 체계를 연구하는 언어학의 하위 분야
- Morphology (형태론): 형태소를 분석하고, 단어의 어형 변화를 다루며, 형태소 간의 상관관계를 규명하는 연구 분야
- Morpheme (형태소): 언어학에서 일정한 의미가 있는 가장 작은 말의 단위
예를 들어 아래 그림을 보시면, unfortunately는 unfortunate와 -ly, 그리고 unfortunate는 다시 un-과 fortunate로 최소한의 의미를 가지도록 나눌 수 있습니다. 그래서 오른쪽 아래 논문처럼 2013년에 매닝 교수님과 학생들이 이런 형태론을 반영해서 토크나이징 하는 실험을 해보셨다고 하는데, 이는 형태소별로 쪼개기가 힘들기도 하고, 최근에는 이러한 방식보다는 뒤에서 다룰 character 단위의 n-gram 방식이 많이 사용된다고 합니다.

1-2. Why Character-level?
그럼 왜 문법에 기초한 형태론 단위보다 문법을 파괴하고 쓰는 character 단위로 접근하는게 더 좋을까요? 여기에는 두 가지 이유가 있습니다. 우선 언어마다 단어를 표현하는 방식이 다릅니다. 먼저 중국어나 일본어 같은 경우 띄어쓰기 없이 모든 단어를 다 붙여 씁니다. 그리고 접어 같은 경우에도, 이걸 어떻게 읽어야할지는 모르겠지만 이 네 단어가 사실 한 개의 단어를 의미하기도 하고, 아래처럼 합쳐져있지만 사실 4개의 단어이기도 하다고 합니다. 합성어의 경우도 마찬가지로 언어마다 결합 방식이 달라진다고 합니다.

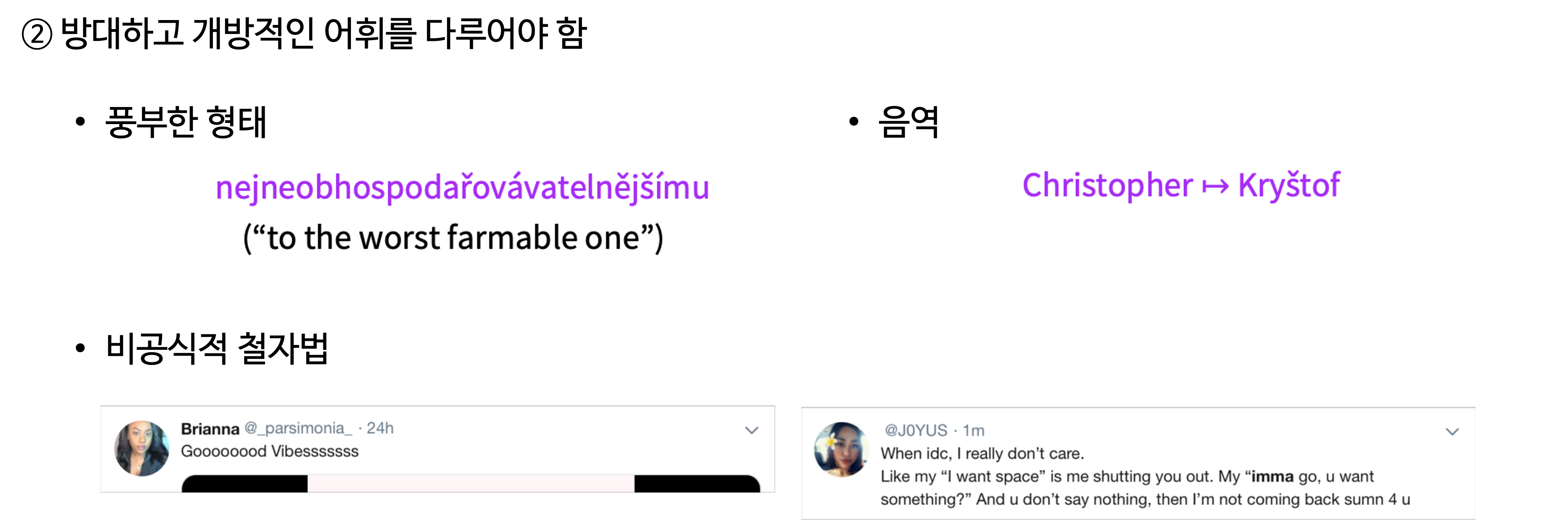
다른 이유로는, 방대하고 개방적인 어휘를 다루어야 하기 때문입니다. 왼쪽에 있는 예시는 체코어인데, 영어로는 이렇게 다섯 단어로 표현할 것을 체코어로는 여러 가지 형태소를 이용하여 한 단어로 표현할 수 있다고 합니다. 그리고 아래 있는 예시처럼 신조어가 생기거나 일상 속에서는 맞춤법에 어긋나는 사용도 많습니다. 그 외에도 음역 등의 문제도 존재하고, 때문에 형태소 기반의 모델을 만들게 되면 데이터가 많이 필요하고, 단어 기반의 모델을 만들게 되면 다루어야 하는 단어가 너무 많아집니다.
1-3. Purely Character-level Model
Pure Character-level Seq2seq (LSTM) NMT System (2015)
그래서 이러한 문제점을 극복하기 위해 character 단위의 모델이 제안되었는데요, 아래는 매닝 교수님께서 실험하신 pure character-level seq2seq (LSTM) NMT 모델의 결과입니다. 체코어가 character level로 이것저것 실험해보기 좋은 언어라고 하는데요, 체코어 번역에서 해당 모델이 좋은 성능을 보였다고 합니다. 비록 character 레벨로 시퀀스 길이가 길어져서 학습시간이 3주나 걸리고 BLEU wjatnrk 15.9에 불과했지만, 예시에서 볼 수 있듯이 word level에 비해서 사람의 이름을 잘 번역하는 모습을 볼 수 있습니다.

Fully Character-level Neural Machine Translation without Explicit Segementation (2017)
그 후 2017년에도 또 다른 character level의 번역 모델이 제안되어 더 좋은 성능을 보였습니다. 아래와 같은 인코더를 취하고 있는 모델인데, 보시면 먼저 character 단위의 인풋을 받아 컨볼루션 레이어를 거쳐 representation을 뽑아냅니다. 그리고 이를 max pooling 한 뒤 highway network를 지나 양방향 GRU를 거쳐 최종 representation을 얻는 구조입니다. 디코더는 그냥 character level의 시퀀스 모델인데, 앞의 모델보다 더 나은 성능을 보여줬다고 합니다. 모델의 전체적 구조는 오른쪽 표를 참고하시면 되겠습니다.

이렇게 단어 기반이 아니라 character 기반으로 모델을 만들게 되면 아까 앞에서 다루었던 광범위한 단어들을 다룰 수도 있고, 해당 단어들에 의미를 부여할 수도 있게 되며, 다음으로 합성어 같은 connected language에 대해서도 분석이 가능해집니다. 또한 character n-gram 단위로 의미를 추출하게 되는데 이러면 문법적으로는 맞지 않을 수 있지만 더 성능이 좋다고 합니다.
2. Subword Models
그럼 이제 두 가지 트렌드의 subword 모델에 대해 알아볼 텐데요, 먼저 word piece model에서 대표적인 BPE를 살펴보고, hybrid한 모델을 살펴보겠습니다.
2-1. BPE (Byte Pair Encoding)
우선 subword model은 word보다 작은 word pieces를 이용하는 모델입니다. 이에 대표적인 BPE는 Byte Pair Encoding은 원래는 압축 알고리즘으로 딥러닝과는 무관한 아이디어를 가지고 있습니다. 이 모델은 자주 등장하는 byte 쌍, 즉 n-gram 쌍을 새로운 byte, 새로운 gram으로 클러스터링하여 추가하는 방식으로 이루어집니다. 예를 들어 아래의 왼쪽 Dictionary처럼 각각의 단어가 왼쪽의 횟수만큼 등장한다고 하면, es는 총 9번 등장하게 됩니다.

그러면 이렇게 자주 등장하는 단어들은 새롭게 오른쪽의 vocabulary에 추가되어 각각 하나의 단어로 취급됩니다. 그럼 왼쪽에서 es는 하나의 단어 취급을 받는 모습을 확인하실 수가 있고, 이후에도 est를 추가하고 lo를 추가하는 식으로 이어지다가, 지정된 최대 길이를 넘으면 중단합니다. 이렇게 시스템의 vocabulary는 자동적으로 결정되어 전통적인 방식의 단어 기반 방식은 더 이상 쓰이지 않게 됩니다. 이러한 BPE 방식은 순수한 data-driven이며 언어에 대해 독립적이라고 합니다.

2-2. WordPiece Model
다음으로는 BPE에 대한 변형을 몇 가지 알아보겠습니다. 먼저 WordPiece 같은 경우는 단어 안에서 토크나이징을 진행하게 됩니다. 앞서 말씀드렸던 BPE 같은 경우는 character 단위로 dictionary에 있고, 거기서 bigram 기준으로 frequency가 높은 단어를 vocabulary에 추가해주는 방식이었는데, 이 WordPiece는 빈번하게 등장하는 단어들에 대해 먼저 Vocabulary에 추가를 해주는 Pre-segmentation 뒤에 BPE를 적용합니다. 또한 BPE는 빈도수에 기반하여 가장 많이 등장한 쌍을 병합했는데, 이와 달리 병합되었을 때 코퍼스의 우도를 가장 높이는 쌍을 병합합니다. 밑에 있는 예시 문장을 보시면 Jet는 J와 et로 나누어졌으며, feud는 fe와 ud로 나누어진 것을 볼 수 있습니다. 여기서 WordPiece 모델은 문장 복원을 위해 모든 단어의 맨 앞에 언더바를 붙이고, 단어는 subword로 통계에 기반하여 띄어쓰기로 분리됩니다. 예를 들어서 Jet는 _J와 ef가 되어 기존에 없던 띄어쓰기가 추가되어 subword를 구분해주고, 기존에 있던 띄어쓰기와 구분자 역할의 띄어쓰기는 언더바로 구별하면 됩니다. 그리고 문장 복원을 위해서는 모든 띄어쓰기를 전부 제거하고 언더바를 띄어쓰기로 바꾸면 가능하게 됩니다. 이 알고리즘은 저희가 알고있는 Transformer, ELMo, BERT, GPT-2 등 최신 딥러닝 모델에서 사용되기도 했다고 합니다.

2-3. SentencePiece Model
이외에도 내부 단어 분리를 위한 모델로 SentencePiece가 있는데, 이는 2018년에 구글에서 실행한 연구입니다. 내부 단어 분리 알고리즘을 사용하기 위해서, 데이터에 단어 토큰화를 먼저 진행한 상태여야 한다면 이러한 알고리즘은 모든 언어에서 사용하기 어렵습니다. 예를 들어 중국어 같은 경우에는 단어 단위로 구분을 할 수가 없기 때문인데, 이런 사전 토큰화 작업 없이 전처리를 하지 않은 raw data에 바로 단어 분리 토크나이저를 적용할 수 있다면 어떤 언어에도 적용이 가능할 것입니다. SentencePiece는 이러한 아이디어를 살려 만들어진 토크나이저로, 사전 토큰화 작업이 없기 때문에 언어에 종속되지 않고 사용할 수 있는 형태소 분석 패키지입니다. 또한 공백은 공백 토큰으로 따로 지정되어 BPE 방식으로 진행되는데, frequency 기반인 기존 BPE와는 달리 해당 bigram에 대한 co-occurrence 확률 값을 기반으로 vocabulary에 추가합니다.

3. Hybrid Models
그럼 이제 마지막으로 hybrid 모델에 대해 알아보겠습니다.
3-1. Hybrid Models
Learning Character-level Representations for Part-of-Speech Taggging
만약 character-level을 사용해서 무한한 범위의 단어를 커버하며, 이들을 더 큰 시스템으로 결합하고 싶다면 어떻게 해야할까요? Hybrid Model은 character 모델과 word 모델의 방식을 혼용한 모델로, 기본적으로 word 단위로 단어를 취급하지만 몇 개만 character 단위로 취급하게 됩니다. 주로 고유명사나 사전에 없는 단어를 character 단위로 취급하게 되는데, 예를 들어 2014년에 제안된 오른쪽 모델은 character 단위로 시작합니다. 그리고 이들에 convolution 연산을 취해 단어 임베딩을 생성하고 이러한 임베딩을 더 높은 level의 모델에 사용하여 POS 태깅을 하는 fixed window 모델입니다.
3-2. Character-based LSTM
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
Convolution 연산 대신 LSTM을 사용할 수도 있습니다. 앞의 모델이 제안되고 1년 후, 마찬가지로 character에서 단어 representation을 생성하여 character-level의 양방향 LSTM 모델이 연구되었습니다. 아래 그림의 모델 구조를 보시면 input layer에서 LSTM으로 각 character에 대한 벡터를 학습하고, 두 개의 final state를 concat하여 더 높은 수준의 LSTM에 넣습니다.

3-3. Character-aware Neural Language Model
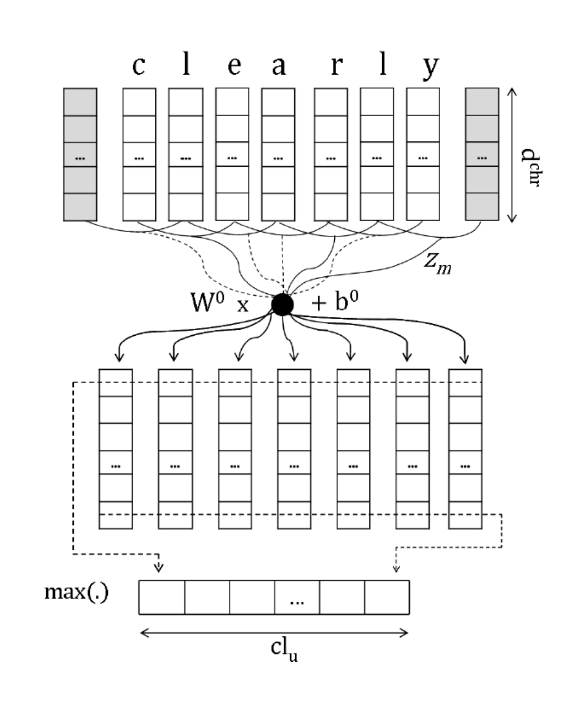
이외에도 Character-aware Neural Language Model로, subword의 관계를 인코딩하는 모델입니다. 이는 eventful, eventfully, uneventful처럼 공통된 subword에 의해 의미적 관계가 존재하는 경우 유용합니다. 해당 모델은 기존 모델들의 rare-word 문제를 해결하고, 더 적은 파라미터 수로 비슷한 성능을 낸다는 장점이 있습니다. 모델의 전체적 구조는 아래의 그림과 같습니다.

조금 더 구체적으로 살펴보면, 먼저 character embedding이 들어가 컨볼루션 연산을 거칩니다. 이때 필터는 2나 3, 4의 n-gram의 character sequence를 갖게 되어 단어의 부분적인 representation을 얻게 됩니다. 다음으로는 max pooling over time을 시행하여 각 n-gram 중 어떤 것이 단어의 의미를 가장 잘 표현하는지 고릅니다.

그럼 다음으로 이렇게 character n-gram에 대한 output representation을 얻은 상황에서 이를 highway network에 통과시킵니다. 이는 LSTM의 memory cell과 비슷한 역할을 하는데, 원본 데이터에 변형을 가하여 n-gram의 상호작용을 모델링합니다. 그럼 그 아웃풋이 word-level이 되는데, 이를 word-level의 LSTM 네트워크에 넣어 최종 아웃풋을 얻을 수 있습니다. 이러한 모델은 다른 언어 모델과 마찬가지로 perplexity를 낮추는 방향으로 학습하게 됩니다.

실험 결과를 보시면, 더 작은 모델로 비슷하게 좋은 성능을 내는 것을 관찰할 수 있습니다. 오른쪽 표에서 밑에 있는 모델들이 기존의 모델들인데, perplexity를 보시면 가장 밑에 성능이 제일 좋았던 모델이 78.4입니다. 그런데 위를 보시면 character 단위의 LSTM 모델로 비슷하게 78.9를 기록하며, 파라미터의 수는 약 40%로 훨씬 작은 것을 보실 수 있습니다.

이외에도 해당 모델에서 주목할 부분은 highway network의 역할입니다. 아래 표를 보시면 richard라는 단어에 대해 단어 단위의 LSTM은 비슷하게 다른 이름들을 유사한 단어로 출력합니다. 이와 다르게 character 단위로 했을 때, highway network를 지나기 전에는 Richard와 의미가 아닌 철자가 비슷한 hard, rich, richer 등의 단어를 출력하고 있습니다. 그러나 highway network를 지나가게 되면 의미도 파악하게 되어 Edward, Carl 등의 이름도 출력하지만 여전히 character도 기억하고 있다는 것을 보실 수 있습니다. 이를 통해 hightway 레이어를 통과하면 단순 character sequence representation이 의미를 포착할 수 있게 된다는 것을 알 수 있습니다. 이외에도 오른쪽 표를 보시면 loooook처럼 OOV인 단어들에 대해서도 잘 작동하는 것을 확인할 수 있습니다.

3-4. Hybrid NMT
마지막으로 살펴볼 모델은 Hybrid NMT 모델로 또 매닝교수님께서 제안하신 모델인데요, 빠르고 실용적으로 사용할 수 있도록 개발하셨다고 합니다. 구조는 오른쪽처럼 생겼는데 우선은 그냥 attention이 있는 sequence to sequence LSTM neural machine translation system을 사용합니다. 실제로는 그림과 다르게 4개의 레이어로 이루어진 word-level의 구조로 되어있다고 합니다. 작동방식은 우선 16000개의 vocabulary에 대해 common word는 그냥 word representation을 구하여 neural translation model에 넣지만, vocabulary에 없는 단어는 character level LSTM을 이용하여 단어 representation을 구하게 됩니다. 그럼 이제 한쪽에서는 16000개의 단어에 대한 softmax를 하고 있을텐데, 만약 단어 중에 <unknown>을 생성하게 되면, 이 hidden representation을 character level LSTM에 넣어 character sequence를 만들게 하여 단어를 생성합니다. 디코더도 마찬가지로 단어 수준과 <unk>에 대해서는 character 수준의 beam search로 진행된다고 합니다.

그 결과 앞서 살펴본 다른 모델들에 비해 성능이 좋았고, 당시에 SOTA 모델까지 달성했다고 합니다. 그리고 오른쪽을 보시면 앞에서 다루었던 영어-체코어 번역에서도 굉장히 좋은 성능을 보이고 있습니다. character-level 모델은 이름을 잘 포착하지 못하고, word-level 모델은 diagnosis를 잡아내지 못하고 를 생성했을 때, 그냥 attention의 원리로 바로 앞의 po를 그대로 출력하고 있습니다. 그러나 hybrid system은 모든 경우에서 가장 정확하게 번역을 하고 있습니다.

3-5. FastText Embedding
마지막으로 간단하게 FastText Embedding에 대해 소개드리고 마치겠습니다. 강의에서는 FastText Embedding을 word2vec과 같은 차세대 단어 벡터 학습 라이브러리로 언급을 하는 임베딩 방법론입니다. FastText도 마찬가지로 하나의 단에 여러 단어들이 존재하는 것으로 간주하여, 즉 내부 단어를 고려해서 학습을 하게 되는데, 각 단어는 글자 단위 n-gram의 구성으로 취급하되 한 단어의 n-gram과 전체 단어를 모두 학습에 사용한다는 특징이 있습니다. 예를 들어보면 where의 경우 n이 3일 때 이렇게 시작과 끝을 의미하는 토큰을 도입하여 옆의 5개 내부 단어 토큰을 벡터로 만듭니다. 그리고 추가적으로 원래 단어에 <. >를 붙인 토큰도 벡터화하여 사용하고, 이러한 representation의 합으로 단어를 표현하게 됩니다. 이렇게 FastText를 활용하게 되면 모르는 단어, OOV에 대해서도 subword를 활용하여 다른 단어와 유사도를 계산할 수 있게 되며, 등장 빈도 수가 적은 rare word의 경우에도 다른 단어와 n-gram을 비교하여 임베딩 값을 계산할 수 있다는 장점이 있습니다.

References
CS224 Winter 2019: Natural Language Processing with Deep Learning
https://velog.io/@tobigs-text1314/CS224n-Lecture-12-Subwords
https://wikidocs.net/22592
https://wikidocs.net/86657

2개의 댓글

16기 이승주
character-level
언어마다 단어를 표현하는 방식이 다르고 방대하고 개방적인 어휘를 다뤄야하기 때문에 문법에 기초한 형태론 단위보다 문법을 파괴하고 쓰는 character 단위로 접근하는게 더 좋다.
subword model은 word보다 작은 word pieces를 이용하는 모델이다.
Byte Pair Encoding은 n-gram 쌍을 새로운 byte, 새로운 gram으로 클러스터링하여 추가하는 방식으로 이루어진다.
WordPiece Model는 빈번하게 등장하는 단어들에 대해 먼저 Vocabulary에 추가를 해주는 Pre-segmentation 뒤에 BPE를 적용한다. 또한 BPE는 빈도수에 기반하여 가장 많이 등장한 쌍을 병합했는데, 이와 달리 병합되었을 때 코퍼스의 우도를 가장 높이는 쌍을 병합한다.
SentencePiece Model: 사전 토큰화 작업 없이 전처리를 하지 않은 raw data에 바로 단어 분리 토크나이저를 적용하여 언어에 종속되지 않고 사용할 수 있는 형태소 분석기이다.
Hybrid Model은 character 모델과 word 모델의 방식을 혼용한 모델이다.
Character-based LSTM은 character에서 단어 representation을 생성하여 character-level의 양방향 LSTM 모델. Input layer에서 LSTM으로 각 character에 대한 벡터를 학습하고, 두 개의 final state를 concat하여 더 높은 수준의 LSTM에 넣는다.
Character-aware Neural Language Model은 subword의 관계를 인코딩하는 모델입니다. 이는 eventful, eventfully, uneventful처럼 공통된 subword에 의해 의미적 관계가 존재하는 경우 유용하다. 해당 모델은 기존 모델들의 rare-word 문제를 해결하고, 더 적은 파라미터 수로 비슷한 성능을 낸다는 장점이 있다.
FastText Embedding은 모르는 단어, OOV에 대해서도 subword를 활용하여 다른 단어와 유사도를 계산할 수 있게 되며, 등장 빈도 수가 적은 rare word의 경우에도 다른 단어와 n-gram을 비교하여 임베딩 값을 계산할 수 있다는 장점이 있다.
16기 주지훈
character-level
Subword Model
Hybrid Models