

작성자 : 투빅스 14기 장예은
Contents
- Purely Character-Level Models
- Subword-Models
- Hybrid Models

Cs224n 강의에서 언어학 관련 용어가 많이 등장하여 자주 등장하는 용어를 정리해보았습니다. 강의를 들으시면서 참고하시면 좋을 것 같습니다. :)

오늘 소개할 3가지 종류의 모델 중 첫번째인 Purely character level 모델입니다.
Purely-character level model의 필요성은 두 가지입니다. 첫째로, 언어마다 단어 표현 방법이 다르기 때문에 character level로 접근하는 것이 더 효과적인 경우가 있기 때문입니다. 둘째로, 말 그대로 ‘large’하고 ‘open’한 어휘를 다룰 수 있어야 하기 때문입니다. 이어서 두 가지 이유에 대해 더 자세히 살펴보겠습니다.

Purely character level model이 필요한 첫 번째 이유, 언어별로 특성이 상이하다는 점은 이러한 예시를 통해 명확하게 알 수 있습니다. 중국어의 경우에는 띄어쓰기가 없고, 프랑스어와는 달리 아랍어의 경우에는 의미가 추가될 때 하나의 단어처럼 결합됩니다.
독일어 Lebensversicherungsgesellschaftsangestellter와 영어 life insurance company employee는 같은 의미입니다. 이처럼 같은 내용이라도 언어마다 표기 방식이 상이하기 때문에 일부 언어에서는 character level의 접근이 더 효과적입니다.

두번째 이유, large, open vocabulary를 다룰 필요성은 체코어와 같이 풍부한 형태학 (morphology)를 가진 언어와 외래어 표기와 같은 음역 (transliteration) , sns등에서 자주 볼 수 있는 맞춤법에 맞지 않는 철자 표기 등의 문제점 때문에 주목받고 있습니다. Sns에서 자주 사용하는 good vibeeeees, idc와 같은 표기는 그 의미가 명확하게 전달되지만, 모델은 이 표기를 good vibes, i don’t care와 완전히 동일하게 인식하지 못할 수 있기 때문입니다.

Purely character level model은 특히 체코어 번역에서 우수한 성능을 보입니다. 2015년에 발표된 Pure character level seq2seq system은 character level model로 영어-체코어 번역을 했지만 학습시간이 3주나 되었고, BLEU(성능 측정 메트릭)가 15.9에 불과하다는 단점이 있었습니다. 예시에서 볼 수 있듯이 word level 모델에 비해 사람 이름을 잘 번역하는 경향이 나타났습니다.
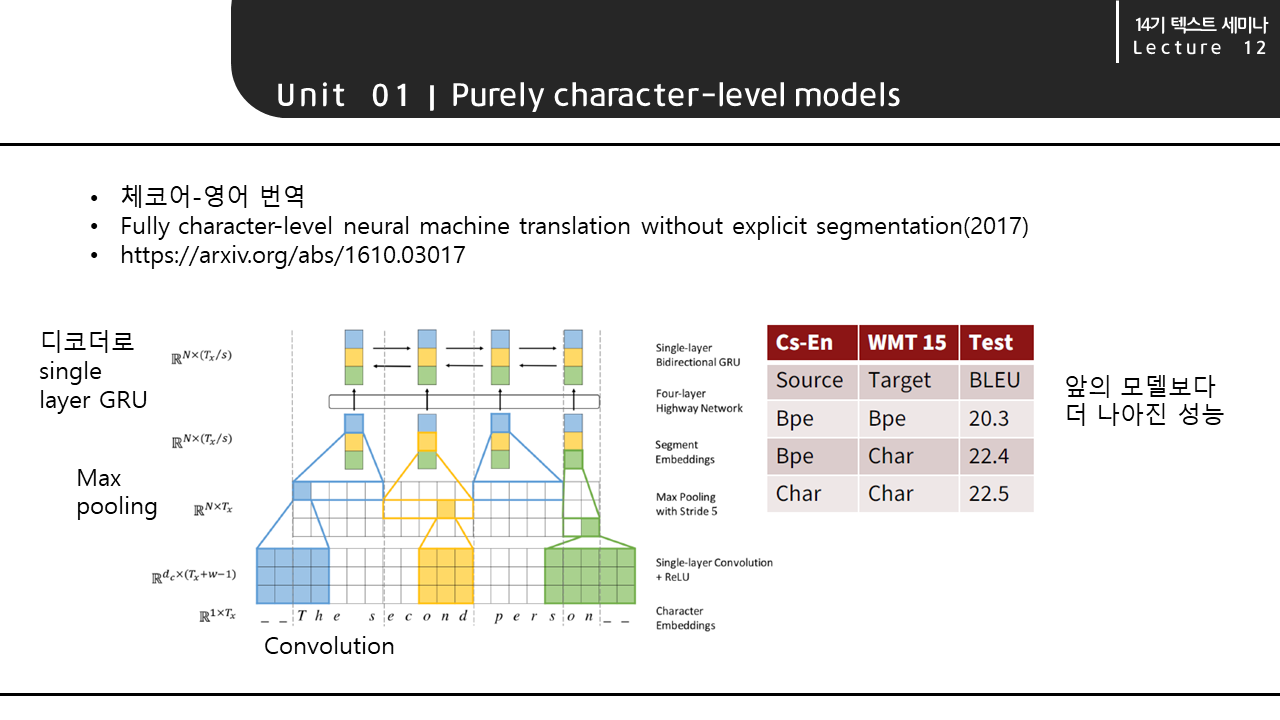
2017년에 나온 또 다른 character level 번역 모델은 앞선 모델보다 더 나은 성능을 보였습니다. 이 모델의 인코더의 구조는 먼저 character 단위의 input을 주고, convolution layer를 거친 다음, max pooling과 single layer GRU를 거치는 구조입니다. 앞선 모델의 BLEU 15.9보다 더 나은 성능을 보여주고 있습니다.

앞서 살펴본 그림의 구조는 모델의 인코더에 해당하는 부분의 구조였습니다. 모델의 전체적인 구조는 왼쪽 table 1과 같이 인코더 외에 2 layer GRU 디코더가 추가되어 있습니다.
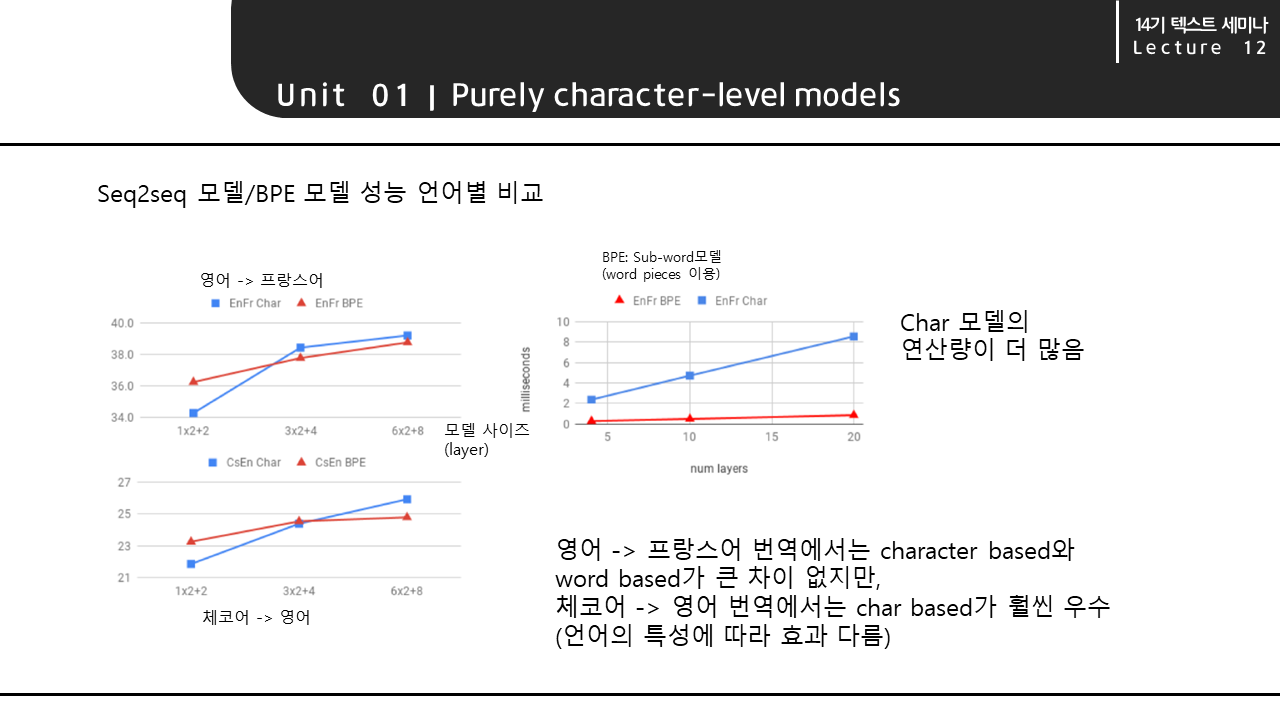
character level의 seq2seq 모델과 word level의 BPE 모델의 성능을 비교한 그래프입니다. 왼쪽의 두 그래프를 보면 영어 -> 프랑스어 번역에서는 두 모델의 성능이 크게 차이가 나지 않지만, 체코어 -> 영어 번역에서는 character based 모델인 BPE가 훨씬 우수한 성능을 보이고 있음을 알 수 있습니다.
이를 통해 언어의 특성에 따라 word level 모델과 character level 모델의 성능에 차이가 있음을 알 수 있습니다. 오른쪽의 그래프는 두 모델의 연산량 차이를 비교하고 있는데, character level 모델의 연산량이 훨씬 더 많습니다.

오늘 소개할 두번째 모델 종류는 Subword model입니다.
Subword 모델은 word level 모델과 동일하지만, 더 작은 word인 word pieces를 이용합니다. Subword모델의 대표적인 예시인 BPE 모델은 딥러닝과 무관한 간단한 아이디어를 사용하고 있습니다. 이 모델은 자주 나오는 byte pair(n gram)를 새로운 byte(a new gram)로 clustering하여 추가하는 방식입니다. 예시를 통해 살펴보겠습니다. 왼쪽 그림과 같은 딕셔너리가 있을 때, es, est, lo가 자주 등장합니다. 따라서 이 단어들을 새로 추가하여 각각 하나의 단어로 취급합니다. 지정된 최대 길이를 넘으면 이러한 추가 과정을 중단합니다.
이러한 점에서 시스템의 vocabulary를 자동적으로 결정한다고 할 수 있습니다. BPE모델은 효과적인 성능이 검증되어 널리 응용되고 있습니다.

Wordpiece와 sentencepiece에 대해 강의에서 나온 부분 이외에 추가적으로 더 살펴보겠습니다. Word piece 모델은 BPE를 변형한 알고리즘입니다. BPE는 앞서 언급했던 것과 같이 빈도수에 기반해서 가장 많이 등장한 쌍을 병합합니다. 하지만 Word piece모델은 가장 많이 등장한 쌍이 아닌 병합되었을 때 코퍼스의 우도를 가장 높이는 쌍을 병합합니다. BPE와의 유사점은 자주 등장하는 piece는 unit으로 묶고, 자주 등장하지 않는 것은 분리한다는 점입니다.
예시를 참고하면 이해하기가 수월할 것입니다. Word piece 모델을 수행한 결과에서 자주 나오지 않는 단어 Jet와 feud는 J, et fe, ud로 나누어졌습니다. 원래의 문장에서 띄어쓰기가 있던 부분은 언더바 ( _ )로 대체하는데, 이는 수행 결과를 수행 전의 결과로 복원하는 과정을 위함입니다. 원래의 문장으로 복원하는 방법은 수행 결과의 모든 띄어쓰기를 제거하고, 언더바를 띄어쓰기로 바꾸는 것입니다.

Sentencepiece는 word piece 토큰화를 수행하는 패키지입니다. 구글에서 2018년에 공개한 비지도학습 기반 형태소 분석 패키지로, 사용하려면 pip install sentencepiece 명령을 통해 설치해야 합니다.

이외에도 다른 word piece, sentence piece 모델이 있습니다. BERT도 하나의 예시인데요, BERT는 vocab size가 크지만, 엄청 크지는 않기 때문에 word piece를 사용할 필요가 있습니다. 따라서 상대적으로 등장 빈도가 높은 단어들과 더불어 wordpiece를 사용합니다. 예를 들면 사전에 없는(등장 빈도가 높지 않은) Hypatia 라는 단어의 경우 H yp ati a 처럼 4개의 word vector piece로 쪼개집니다.
오늘 소개할 마지막, 세번째 모델의 종류는 Hybrid 모델입니다.
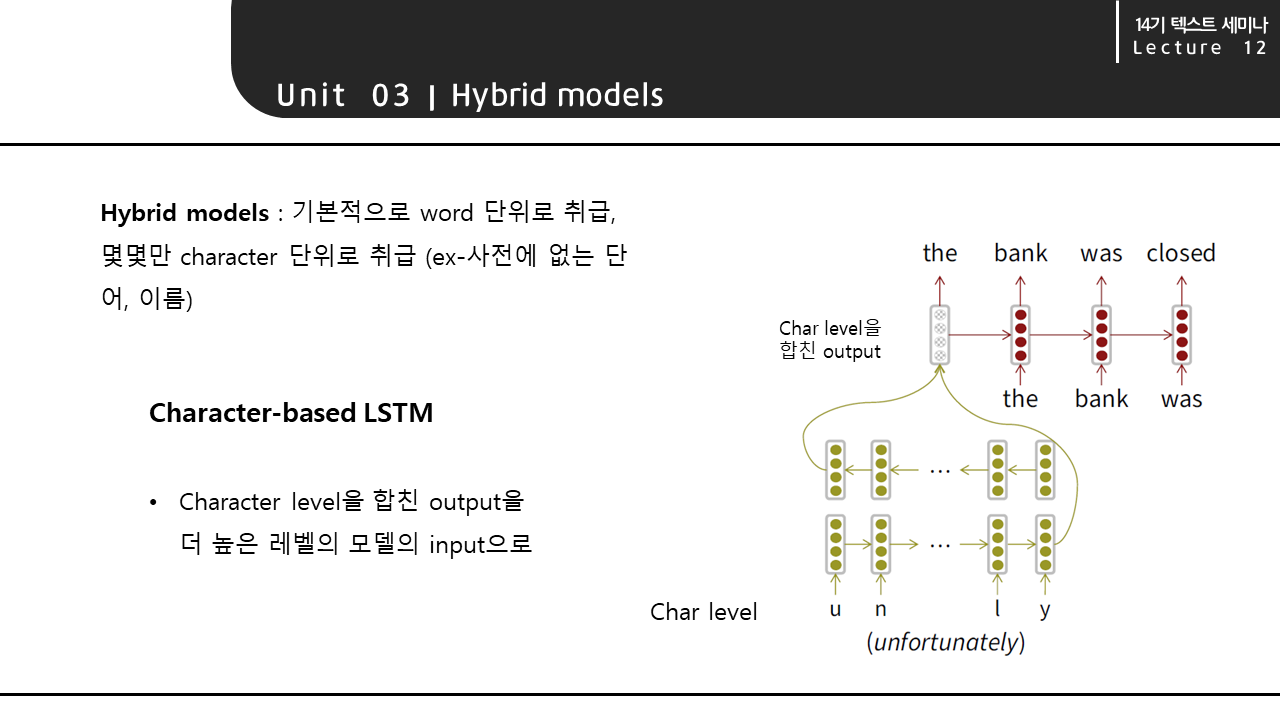
Hybrid 모델은 기본적으로 단어를 word 단위로 취급하고, 몇몇만 character 단위로 취급하는 모델입니다. character 모델과 word 모델의 방식을 혼용한 것이라 할 수 있습니다. 주로 고유명사나 사전에 없는 단어를 character 단위로 취급합니다. Hybrid 모델의 일종인 character-based LSTM의 구조는 오른쪽의 그림과 같습니다. 처음의 input 단어를 character level로 다루고, 이것을 합친 output이 더 높은 레벨의 모델의 input이 되는 구조입니다.
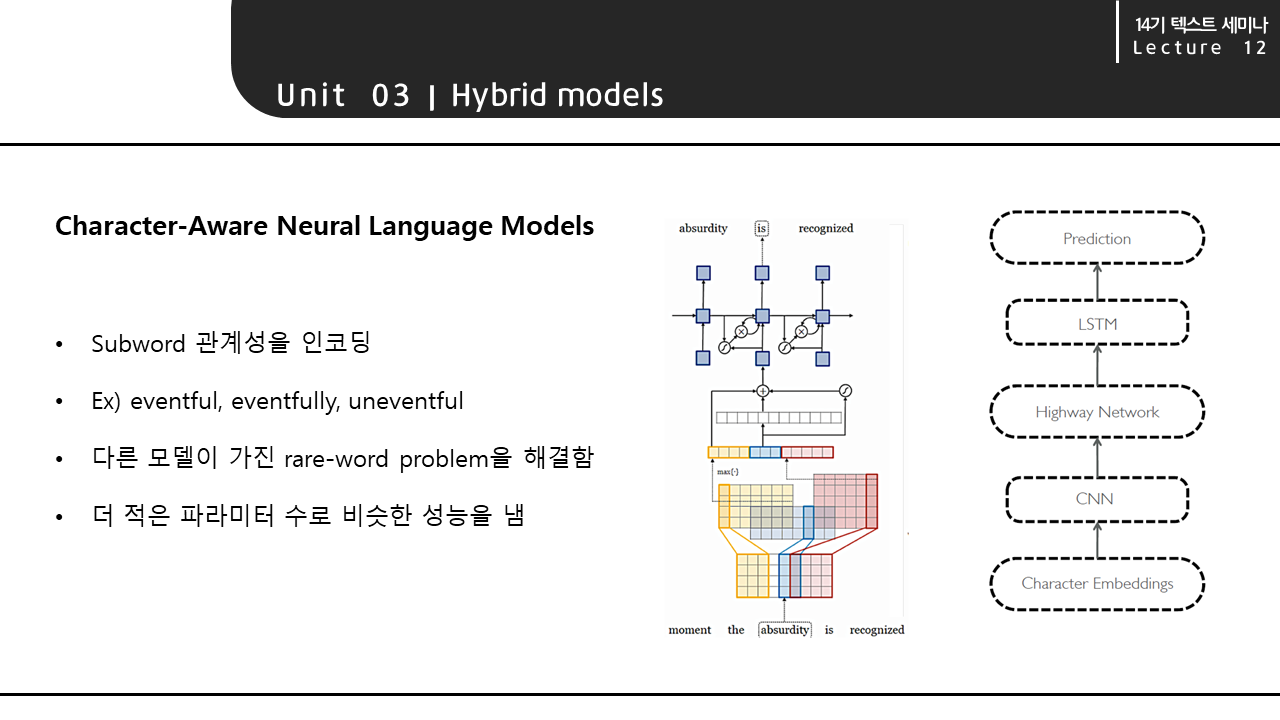
Hybrid 모델의 두번째 예시인 Character Aware Neural Language Model은 subword의 관계성을 인코딩하는 모델입니다. 세 단어 eventful, eventfully, uneventful 처럼 공통된 subword에 의해 의미적인 관계가 존재하는 경우에 유용합니다. 이 모델은 다른 모델이 가진 rare-word problem을 해결하고, 더 적은 파라미터 수로 비슷한 성능을 낸다는 장점이 있습니다. 모델의 전체적인 구조는 오른쪽의 그림과 같습니다.
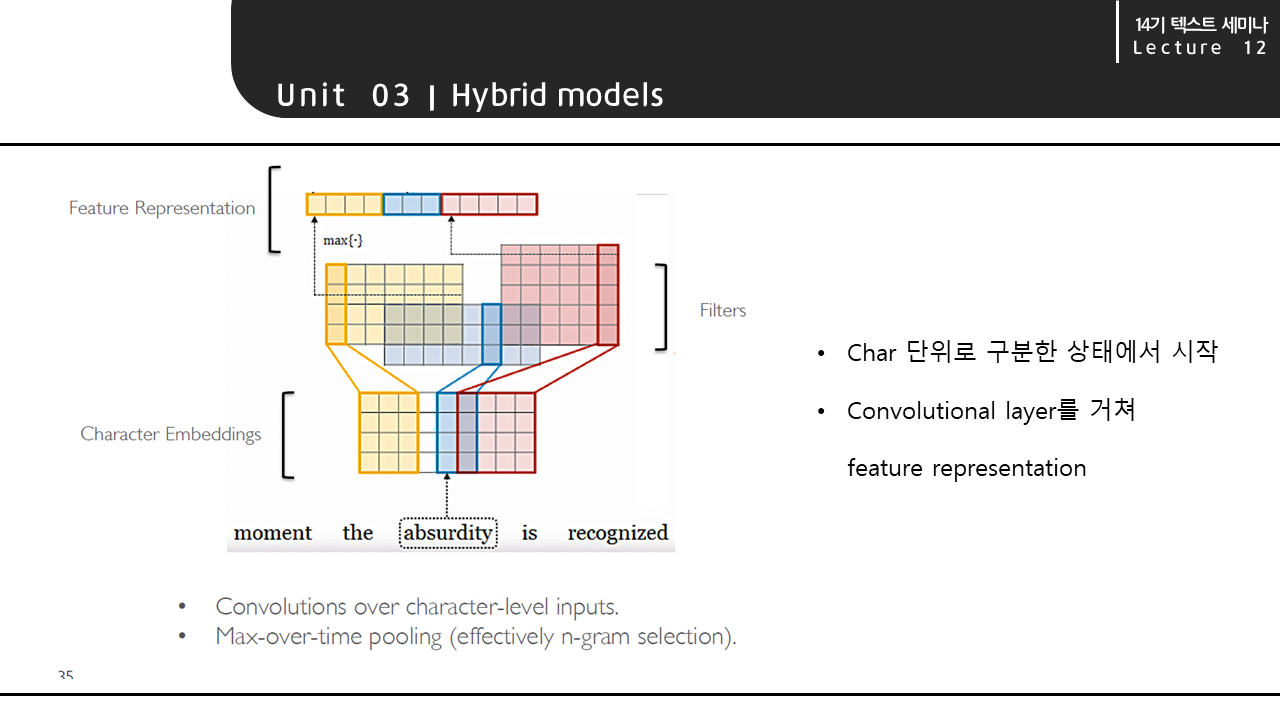
모델의 구조에 대해 더 자세히 살펴보겠습니다. 먼저 input값에 해당하는 단어를 character 단위로 구분한 상태에서 시작합니다. character 단위로 구분된 단어가 convolutional layer를 거쳐 feature representation 단계로 넘어갑니다.
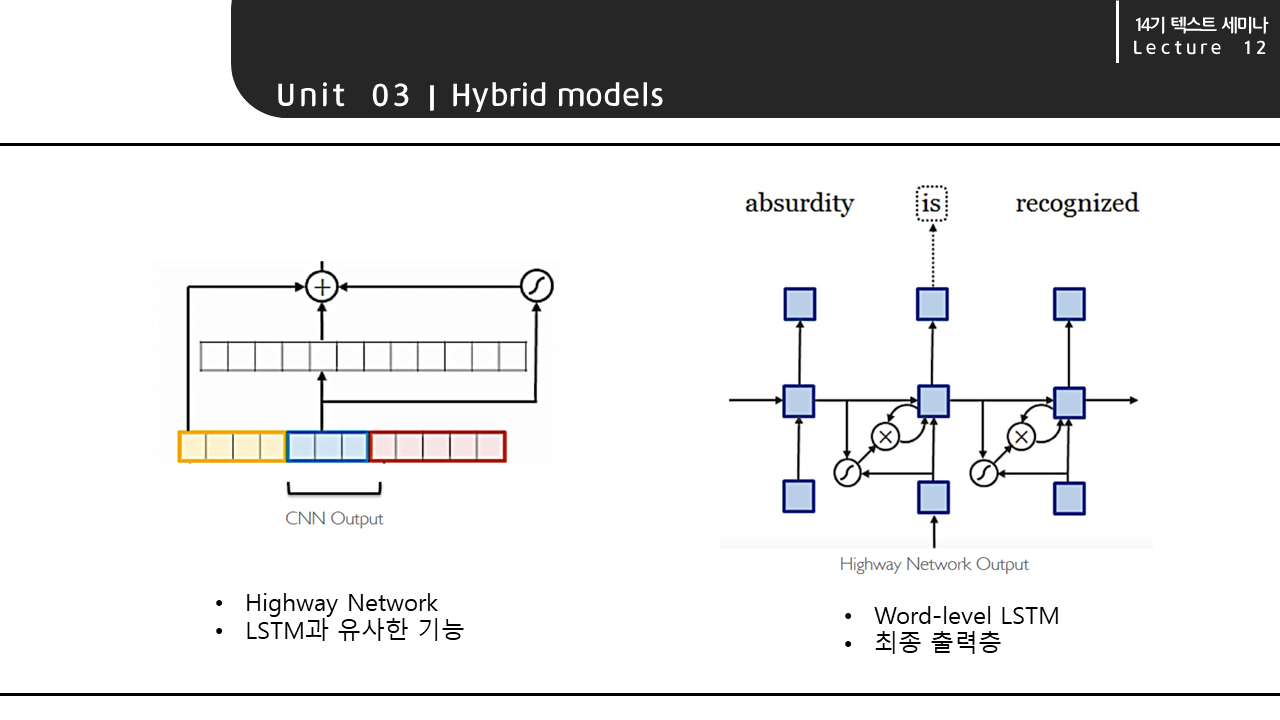
생성된 feature representation은 highway network를 거칩니다. 이 과정은 LSTM과 유사한 기능을 합니다. Highway network의 output은 Word level LSTM을 거쳐 최종 output을 출력합니다.
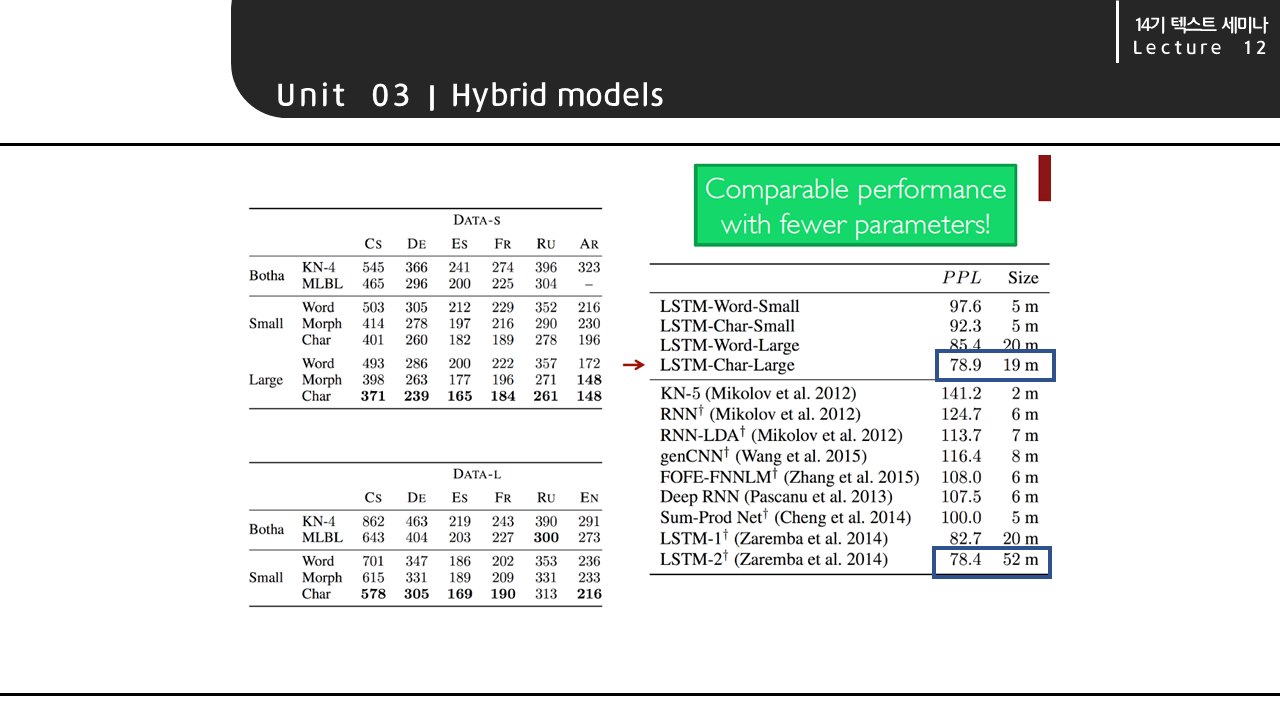
이 모델의 실험 결과를 보면 앞서 언급했던 것처럼 다른 모델(size: 52m)보다 훨씬 더 적은 수의 파라미터 수로 (size: 19m) 비슷한 성능을 내는 것을 알 수 있습니다.

이 모델에서 볼 수 있는 흥미로운 점은 highway network 부분의 역할입니다. Richard 라는 사람 이름은 input으로 주었을 때, highway block 부분 이전에는 Richard와 의미가 아닌 철자만 유사한 hard, rich 등의 단어들이 가장 유사한 단어로 출력되었습니다. 단어의 철자의 유사도만 파악하고, 단어의 의미를 파악하지 못한 것입니다.하지만, highway block 부분을 거친 이후에는 이 단어의 의미를 파악하여 Edward, Carl 등 다른 사람 이름을 유사한 단어로 출력하고 있음을 볼 수 있습니다.
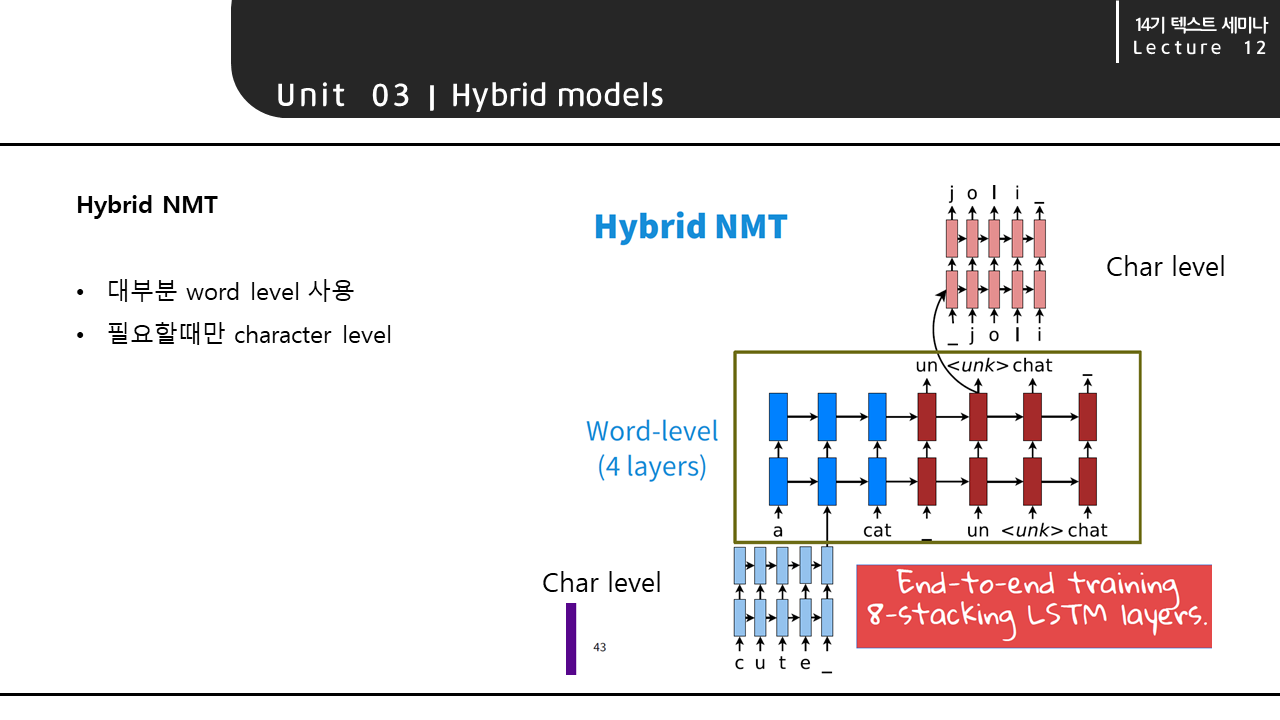
Hybrid 모델의 세번째 예시인 Hybrid NMT의 구조는 오른쪽의 그림과 같습니다. 이 모델은 대부분 word level에서 접근하고, 필요할때만 character level로 접근합니다. 모델 예시를 나타낸 그림에서 cute와 joli 단어 부분만 character level로 접근하고, 나머지 단어들에 대해서는 word level로 접근하고 있는 것을 볼 수 있습니다.

지금까지 살펴보았던 Hybrid모델의 우수성은 다음 예시에서도 확인해볼 수 있는데요, Word level 모델은 diagnosis라는 단어를 아예 잃어버려 unknown으로 출력하거나 po라는 직전에 등장한 단어를 그대로 출력한 것을 볼 수 있습니다. 반면에, hybrid 모델은 이 단어도 놓치지 않고 정확하게 번역한 것을 볼 수 있습니다.

강의에서 짧게 FastText Embedding이 언급되었는데요, word2vec과 같은 차세대 word vector learning library로 주목받고 있는 임베딩 방법입니다. 한 단어의 n gram과 원래의 단어를 모두 학습에 사용한다는 특징이 있습니다. 예시를 통해 사려보면, where이라는 단어가 있을 때 원래의 단어인 where와 이 단어의 n gram인 wh, whe, her, ere, re를 모두 학습에 사용합니다. N gram인 her는 기존에 존재하는 단어인 ‘her’와 다르듯, 이러한 점을 반영한다는 점에서 효과적입니다.
참고자료
CS224n 12강 subword
https://wikidocs.net/22592
https://lovit.github.io/nlp/2018/04/02/wpm/
https://arxiv.org/pdf/1607.04606.pdf
