작성자: 16기 주지훈
Contents
- Machine Translation
- Sequence to sequence
- Attention
1. Machine Translation

Machine Translation이란 특정 언어의 문장을 다른 언어의 문장으로 번역하는 것을 말합니다. 이때 input(x)으로 들어간 언어의 문장을 source language, output(y)으로 나오는 언어의 문장을 target language라고 합니다. 위의 예시에서는 프랑스어 문장이 source language, 번역된 영어 문장이 target language입니다.
 Machine Translation은 1950년대에 처음 등장했습니다. 냉전 시기에 소련과 미국이 소통을 위해 문서들을 자동으로 번역할 필요가 있었고, 이때 나온 것이 바로 Machine Translation입니다. 방식은 Rule-based였는데, 미리 러시아어와 영어 사전을 구축해두고 각 단어가 대응되는 단어를 찾아 번역하는 방식입니다.
Machine Translation은 1950년대에 처음 등장했습니다. 냉전 시기에 소련과 미국이 소통을 위해 문서들을 자동으로 번역할 필요가 있었고, 이때 나온 것이 바로 Machine Translation입니다. 방식은 Rule-based였는데, 미리 러시아어와 영어 사전을 구축해두고 각 단어가 대응되는 단어를 찾아 번역하는 방식입니다.
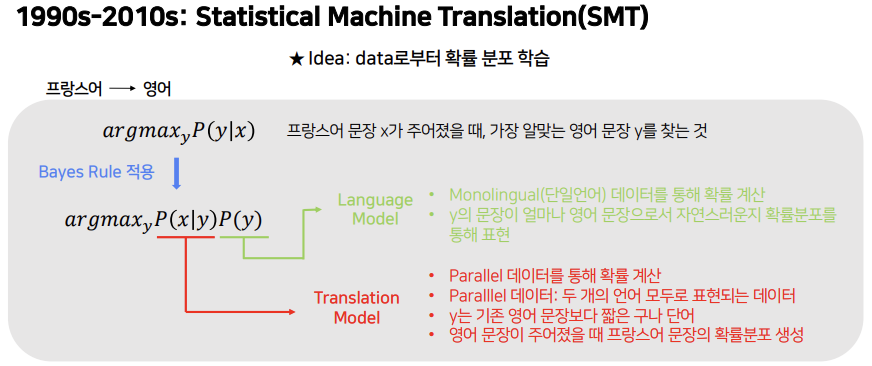
1990년대부터 2010년초까지는 Statistical Machine Translation인 SMT가 사용됩니다. 핵심 아이디어는 데이터로부터 확률 분포를 학습하는 것입니다. 프랑스어를 영어로 번역한다고 했을 때, 프랑스어 문장 x가 주어졌을 때 가장 그럴듯한 영어 문장 y를 찾는 것입니다. 여기에 Bayes Rule을 적용하면 아래와 같이 식이 바뀝니다.
: Translation Model
- 두 개의 언어 모두로 표현된 데이터인 Parallel 데이터를 통해 확률을 계산
- y는 기존 영어 문장보다 짧은 구나 단어
- 영어 문장이 주어졌을 때 프랑스어 문장의 확률 분포 생성
: Language Model
- 단일언어 데이터인 Monolingual 데이터를 통해 확률 계산
- y의 문장이 얼마나 영어 문장으로서 자연스러운지를 확률분포를 통해 표현
그렇다면 항은 어떻게 학습시킬 수 있을까요?
우선 엄청나게 많은 양의 parallel data가 필요합니다. 그리고 이 데이터로부터 를 학습시킬 때 사용되는 개념이 바로 alignment입니다.

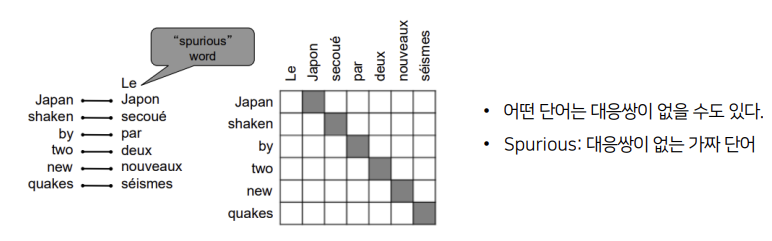
alignment는 두 문장 사이에서 특정 단어 쌍들의 대응을 말합니다. 위의 예시는 대부분 일대일 대응이 되고 있지만, Le 같은 경우에는 대응하는 영어단어가 존재하지 않습니다. 이처럼 어떤 단어는 대응쌍이 없을 수도 있고, 이런 단어를 Spurious(가짜)단어라고 부릅니다.
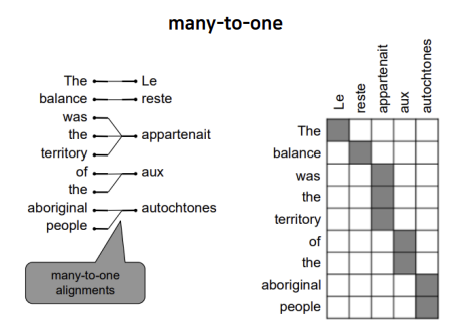 위의 예시는 여러 단어가 하나의 단어로 대응되는 many-to-one입니다.
위의 예시는 여러 단어가 하나의 단어로 대응되는 many-to-one입니다.
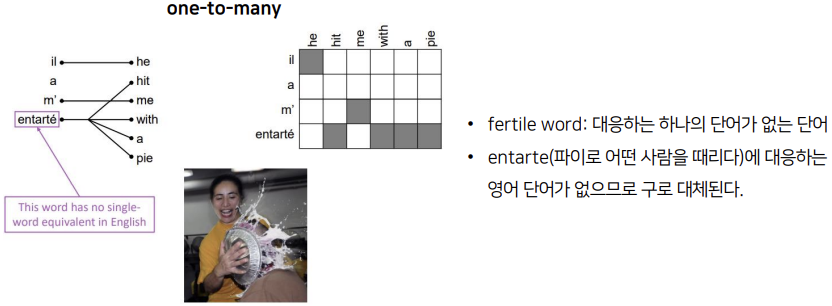 반면 하나의 단어가 여러 단어로 대응될 수도 있습니다. 이렇게 대응하는 하나의 단어가 없는 단어를 fertile word라고 부릅니다. 위의 예시에서 entarte는 '파이로 어떤 사람을 때리다'라는 프랑스어인데, 이에 대응하는 영어 단어가 없으므로 'hit me with a pie'라는 구로 대체됩니다.
반면 하나의 단어가 여러 단어로 대응될 수도 있습니다. 이렇게 대응하는 하나의 단어가 없는 단어를 fertile word라고 부릅니다. 위의 예시에서 entarte는 '파이로 어떤 사람을 때리다'라는 프랑스어인데, 이에 대응하는 영어 단어가 없으므로 'hit me with a pie'라는 구로 대체됩니다.
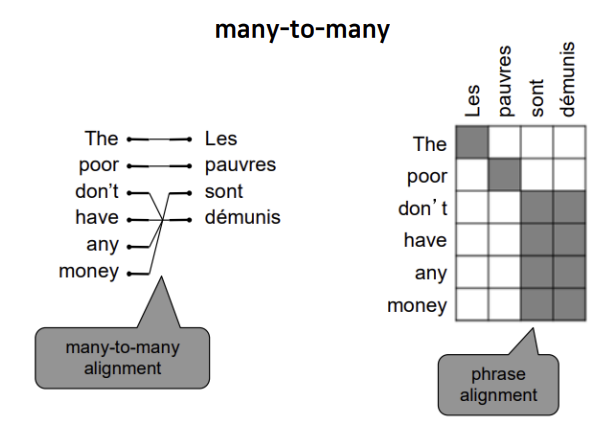 여러 개의 단어가 여러 개의 단어에 대응될 수도 있습니다.
여러 개의 단어가 여러 개의 단어에 대응될 수도 있습니다.
 alignment는 다양한 경우의 수가 존재하기 때문에 특정 단어가 특정 단어에 정렬될 확률, 특정 단어가 fetility할 확률 등 고려해야 할 사항이 많아 매우 복잡합니다.
alignment는 다양한 경우의 수가 존재하기 때문에 특정 단어가 특정 단어에 정렬될 확률, 특정 단어가 fetility할 확률 등 고려해야 할 사항이 많아 매우 복잡합니다.
그렇다면 alighment는 어떻게 학습할 수 있을까요?
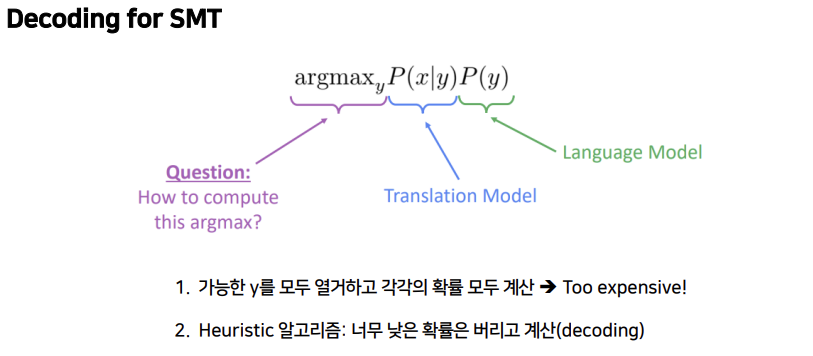 가장 단순한 방법은 가능한 y를 모두 열거하고 각각의 확률을 모두 계산하여 그 중 최댓값을 갖는 경우를 고르는 것입니다. 하지만 이 방법은 많은 비용이 듭니다.
가장 단순한 방법은 가능한 y를 모두 열거하고 각각의 확률을 모두 계산하여 그 중 최댓값을 갖는 경우를 고르는 것입니다. 하지만 이 방법은 많은 비용이 듭니다.
다른 방법은 너무 낮은 확률은 버리고 계산하는 Heuristic 알고리즘입니다. Heuristic 알고리즘을 수행하는 과정을 decoding이라고 합니다.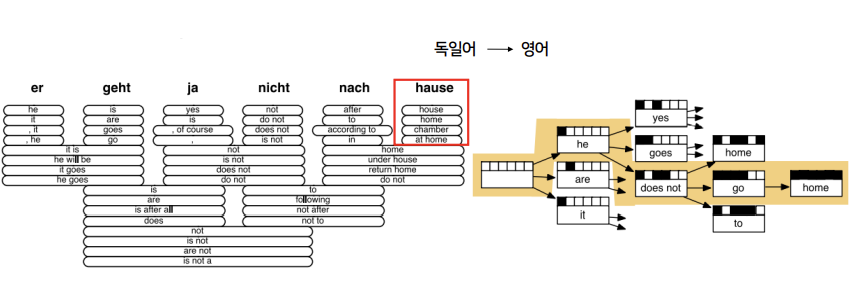 독일어를 영어로 번역하는 예시를 보겠습니다. 왼쪽 그림에서 제일 오른쪽에 있는 독일어 hause는 영어로 house, home, chamber, at home으로 번역될 수 있습니다. 이 중 가장 확률이 높은 home을 선택하고, 나머지는 확률이 낮으니 제거합니다. 이렇게 다양한 가설 중에서 확률이 높은 가설만 선택하고 확률이 낮은 가설은 버리면서 가지를 치는 것입니다.
독일어를 영어로 번역하는 예시를 보겠습니다. 왼쪽 그림에서 제일 오른쪽에 있는 독일어 hause는 영어로 house, home, chamber, at home으로 번역될 수 있습니다. 이 중 가장 확률이 높은 home을 선택하고, 나머지는 확률이 낮으니 제거합니다. 이렇게 다양한 가설 중에서 확률이 높은 가설만 선택하고 확률이 낮은 가설은 버리면서 가지를 치는 것입니다.
SMT의 단점
- 성능은 좋지만 구조가 복잡: 각 system은 분리된 많은 subcomponent들로 이루어졌다.
- 많은 feature engineering이 필요하다.
- 추가적인 많은 자료가 필요하다.
- 유지보수를 위해 사람의 노력이 많이 필요: 각각의 언어쌍(영어-프랑스어, 영어-독일어 등)을 만들어야 해서 많은 노력이 필요하다.
2. Sequence-to-sequence
Neural Machine Translation
- 하나의 신경망 네트워크를 이용한 Machine Translaion
- 두 개의 RNN을 포함한다.(인코더, 디코더에 하나씩)
- 이 신경망 네트워크 구조를 seq2seq라고 부른다.
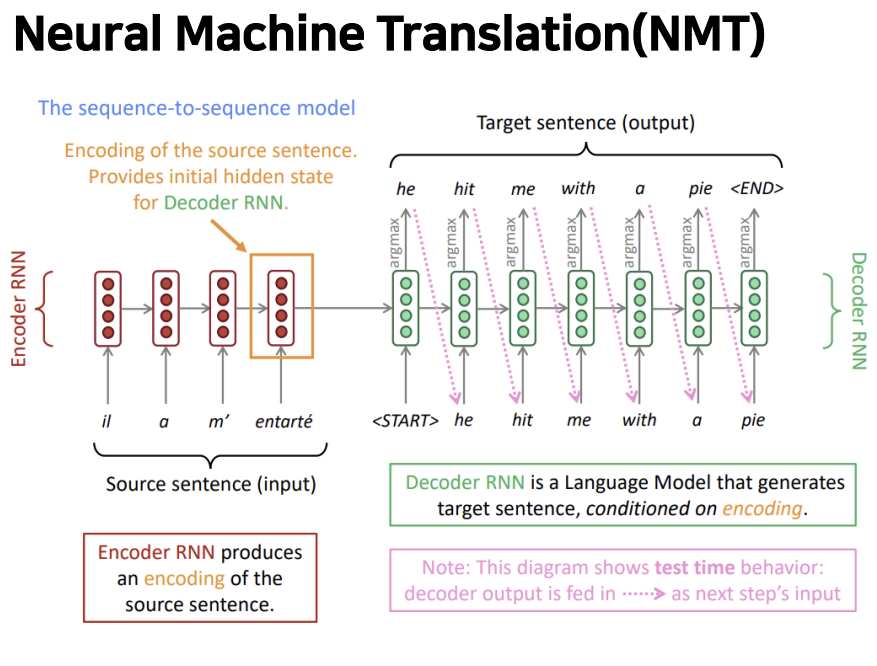 Encoder
Encoder
- 번역할 프랑스어 문장 입력
- 각 단어의 임베딩 벡터가 각 시점마다 입력값으로 사용된다.
- 소스 문장을 마지막에 인코딩시켜 디코더에 넘긴다.
- RNN은 bidirectional rnn, LSTM, GRU 등 모두 가능하다.
Decoder
- 인코더의 마지막 hidden state에서 넘어온 프랑스어 정보와 문장의 시작을 의미하는 start 토큰을 입력 받아 다음에 나올 단어의 확률분포 argmax를 취한다.
- 디코더의 출력값은 다음 디코더의 입력값이 된다.
- 조건부 언어 모델
- end 토큰을 출력하면 종료된다.
seq2seq의 다양한 쓰임

 NMT는 조건부 언어 모델입니다.
NMT는 조건부 언어 모델입니다.
- 언어 모델: 디코더가 target sentence인 y의 다음 단어를 예측
- 조건부: 디코더에 source sentence인 x가 주어지면 y를 뽑고, 첫 번째 y와 x를 이용해 두 번째 y를 뽑는 과정을 반복
지금까지의 과정은 예측 과정입니다. 학습은 어떻게 시킬 수 있을까요?
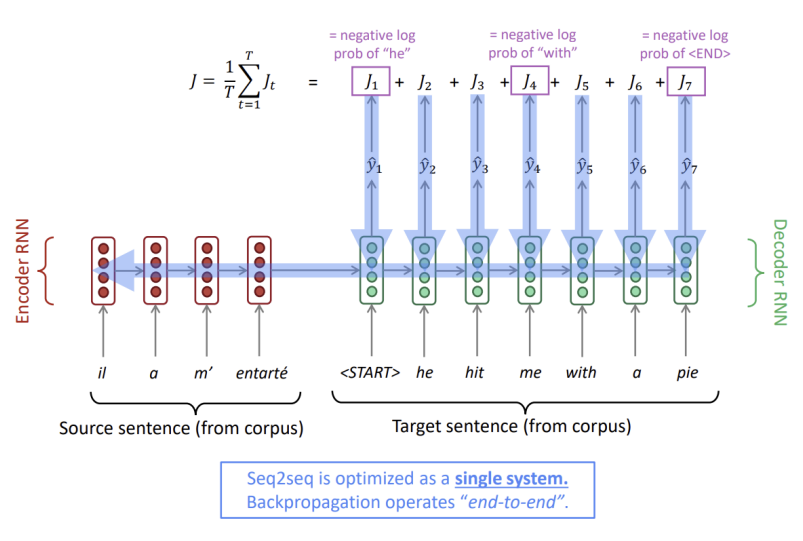
먼저 본래 병렬 말뭉치에 존재하는 이전 시점의 영어 단어를 고정된 입력값으로 디코더에 넣어줍니다. 디코더 RNN의 모든 단계에서 교차 엔트로피 등으로 의 손실을 계산한 후, 손실들의 평균을 낸 최종 Loss를 구합니다.
이렇게 손실값부터 모델의 입력값까지 한 번에 역전파가 일어나는 방식을 end-to-end라고 하고, end-to-end는 시스템을 전반적으로 최적화한다고 할 수 있습니다.
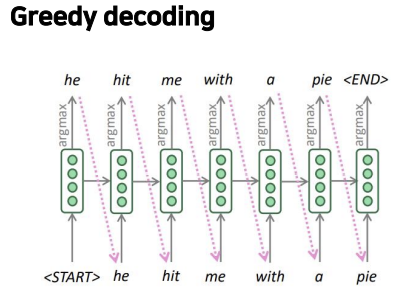 디코더의 각 step에서 argmax를 취하는 것을 greedy decoding이라고 하는데, greedy decoding으로 인해 문제가 발생합니다.
디코더의 각 step에서 argmax를 취하는 것을 greedy decoding이라고 하는데, greedy decoding으로 인해 문제가 발생합니다.  greedy decoding은 틀린 단어로 예측되어도 되돌아 갈 수 없습니다. 위의 예시를 보면, hit 다음에 me가 와야 하는데 a로 잘못 예측되었고, 수정할 수 없기 때문에 틀린 문장을 계속 써 내려갑니다.
greedy decoding은 틀린 단어로 예측되어도 되돌아 갈 수 없습니다. 위의 예시를 보면, hit 다음에 me가 와야 하는데 a로 잘못 예측되었고, 수정할 수 없기 때문에 틀린 문장을 계속 써 내려갑니다.
이를 해결할 수 있는 방법으로는 두 가지가 있습니다. 바로 Exhaustive Search Decoding과 Beam Search Decoding입니다.
1. Exhaustive Search Decoding
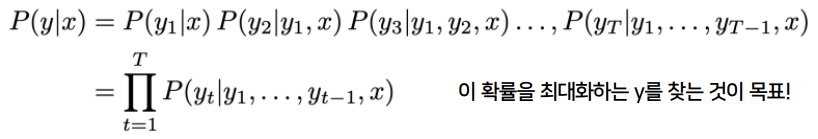 우리는 위의 확률을 최대화하는 y를 찾는 것이 목표입니다. exhaustive search decoding은 모든 경우의 수를 다 계산해서 그 중 최댓값을 갖는 y를 찾습니다. 정해진 시퀀스 길이 T에 대해 각 시점마다 일어날 수 있는 모든 토큰 조합의 확률을 계산하고, 이 중 최대값을 가지는 토큰 조합을 최종 생성 문장으로 선택합니다. 하지만 이 방법은 시간복잡도가 너무 큽니다.
우리는 위의 확률을 최대화하는 y를 찾는 것이 목표입니다. exhaustive search decoding은 모든 경우의 수를 다 계산해서 그 중 최댓값을 갖는 y를 찾습니다. 정해진 시퀀스 길이 T에 대해 각 시점마다 일어날 수 있는 모든 토큰 조합의 확률을 계산하고, 이 중 최대값을 가지는 토큰 조합을 최종 생성 문장으로 선택합니다. 하지만 이 방법은 시간복잡도가 너무 큽니다.
2. Beam Search Decoding
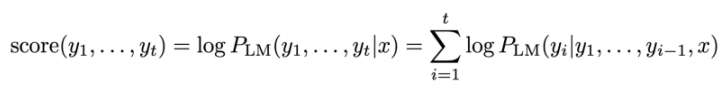 beam search decoding의 핵심 아이디어는 디코더의 각 step에서 가장 가능성이 높은 k개의 번역을 선택하여 가지치기를 하는 것입니다. 이때 k는 beam size를 의미하고, k가 커질수록 각 단계에서 더 많은 것을 고려합니다.
beam search decoding의 핵심 아이디어는 디코더의 각 step에서 가장 가능성이 높은 k개의 번역을 선택하여 가지치기를 하는 것입니다. 이때 k는 beam size를 의미하고, k가 커질수록 각 단계에서 더 많은 것을 고려합니다.
각 가설은 로그 확률로서 위의 식과 같은 score를 가집니다. t시점까지 생성된 문장 후보 y의 score는 언어모델을 이용해 계산한 조건부 확률의 로그값입니다. 따라서 그럴듯한 문장일수록 0에 가깝습니다. 우리는 여기서 높은 score를 갖는 k개의 가설을 각 step마다 선택할 것입니다. beam search decoding은 최고의 성능을 보장하지는 않지만, 모든 경우의 수를 탐색하는 exhaustive search decoding보다는 훨씬 효율적입니다.
beam size인 k=2라고 가정하고 beam search decoding의 예를 들어보겠습니다. k=2이므로 첫 번째 가지에서는 우선 he와 I 모두 선택됩니다.
k=2이므로 첫 번째 가지에서는 우선 he와 I 모두 선택됩니다.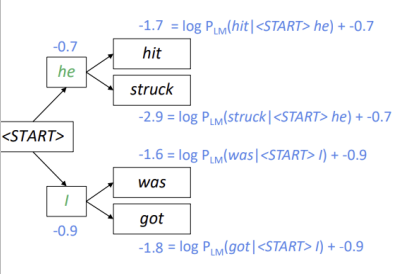 각 토큰에서 두 개의 가설이 생성되는데, 이때 score는 현재 생성된 토큰의 score와 이전에 생성된 토큰의 score의 합입니다.
각 토큰에서 두 개의 가설이 생성되는데, 이때 score는 현재 생성된 토큰의 score와 이전에 생성된 토큰의 score의 합입니다.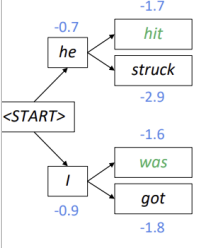 4()개의 가설 중 가장 가능성이 높은, 즉 가장 score가 높은 2개의 가설만 유지합니다. 여기서는 hit과 was가 채택되어 he hit, I was가 됩니다.
4()개의 가설 중 가장 가능성이 높은, 즉 가장 score가 높은 2개의 가설만 유지합니다. 여기서는 hit과 was가 채택되어 he hit, I was가 됩니다.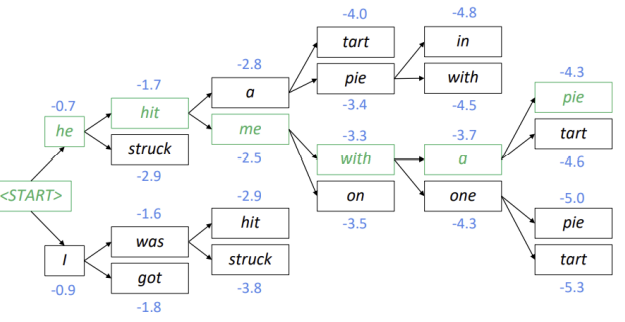 위의 과정을 반복합니다.
위의 과정을 반복합니다.
Stopping Criterion
Greedy decoding은 토큰이 나오면 종료합니다. 하지만 Beam Search Decoding은 한 가설이 토큰을 생성하더라도 다른 가설은 계속 탐색을 이어갑니다. 따라서 최대 문장 길이 T를 설정하거나, n개의 완료된 가설이 생성되면 종료하도록 할 수 있습니다. 하지만 두 번째 방법에는 문제가 있습니다.
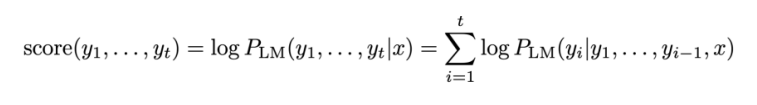 우리는 위의 score식으로 구한 값 중 가장 높은 값을 가진 가설을 선택했는데, score는 계속 더해지기 때문에 문장의 길이가 길면 음수가 많이 더해져 score가 더 작을 수밖에 없습니다.
우리는 위의 score식으로 구한 값 중 가장 높은 값을 가진 가설을 선택했는데, score는 계속 더해지기 때문에 문장의 길이가 길면 음수가 많이 더해져 score가 더 작을 수밖에 없습니다.
따라서 이를 해결하기 위해 score식을 문장의 길이로 나누어 normalize를 해줍니다.
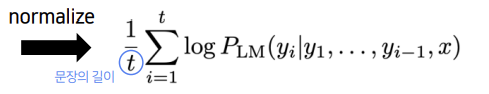
NMT의 장단점

BLEU
Machine Translation은 어떻게 평가할 수 있을까요? 우리는 BLEU 지표를 사용합니다. BLEU(Bilingual Evaluation Understudy)는 기계에 의해 번역된 문장과 사람이 번역한 문장을 비교해서 유사도를 측정하여 성능을 측정하는 지표를 말합니다.
BLEU는 n-gram precision과 너무 짧은 번역 문장에 대한 penalty를 더한 것에 기반하여 계산합니다.
n-gram precision
 우선 Unigram precision부터 보겠습니다. Unigram precision은 기계까 번역한 문장에 대해서, 사람이 번역한 문장에 기계가 번역한 unigram이 얼마나 등장하는지 비율을 계산한 것입니다. 그런데 이 방식에는 문제가 있습니다.
우선 Unigram precision부터 보겠습니다. Unigram precision은 기계까 번역한 문장에 대해서, 사람이 번역한 문장에 기계가 번역한 unigram이 얼마나 등장하는지 비율을 계산한 것입니다. 그런데 이 방식에는 문제가 있습니다. 위의 문장에서 기계가 번역한 문장인 candidate는 the가 반복되는 터무니 없는 번여기지만, reference에 the가 등장해기 때문에 성능은 1로 나옵니다.
위의 문장에서 기계가 번역한 문장인 candidate는 the가 반복되는 터무니 없는 번여기지만, reference에 the가 등장해기 때문에 성능은 1로 나옵니다.
이를 개선하기 위해, 중복을 제거하여 식을 보정합니다.  reference에 unigram이 최대 몇 번 등장했는지 세보고, 이와 원래 셌던 candidate에 등장한 unigram의 수를 비교하여 최솟값을 선택합니다.
reference에 unigram이 최대 몇 번 등장했는지 세보고, 이와 원래 셌던 candidate에 등장한 unigram의 수를 비교하여 최솟값을 선택합니다.  보정한 식을 적용하면, Count=7, Max_Ref_Count=2였으므로 이 중 최솟값은 2이고, 그 결과 2/7이라는 결과가 나옵니다.
보정한 식을 적용하면, Count=7, Max_Ref_Count=2였으므로 이 중 최솟값은 2이고, 그 결과 2/7이라는 결과가 나옵니다.
하지만 이 또한 문제가 존재합니다. 위의 예시에서 ca2는 ca1의 모든 unigram의 순서를 랜덤으로 섞은 것입니다. ca2는 문법에는 전혀 맞지 않지만 unigram precision은 ca1과 동일합니다.
위의 예시에서 ca2는 ca1의 모든 unigram의 순서를 랜덤으로 섞은 것입니다. ca2는 문법에는 전혀 맞지 않지만 unigram precision은 ca1과 동일합니다.
따라서 순서를 고려하여 n-gram으로 확장하게 됩니다.  n-gram은 다음에 등장하는 단어까지 함께 고려하여 카운트를 합니다. 카운트 단위를 몇 개로 보느냐에 따라 2-gram, 3-gram 4-gram이 됩니다.
n-gram은 다음에 등장하는 단어까지 함께 고려하여 카운트를 합니다. 카운트 단위를 몇 개로 보느냐에 따라 2-gram, 3-gram 4-gram이 됩니다.
이를 바탕으로 나온 BLEU 식은 다음과 같습니다.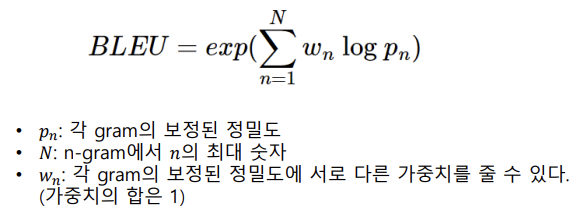 하지만 위의 식을 그대로 사용하면 Candidate의 문장이 짧으면 점수가 높게 나오는 문제가 발생합니다. precision에서 분모가 Candidate의 count이기 때문입니다.
하지만 위의 식을 그대로 사용하면 Candidate의 문장이 짧으면 점수가 높게 나오는 문제가 발생합니다. precision에서 분모가 Candidate의 count이기 때문입니다.
이를 해결하기 위해 Candidate의 길이가 짧을 때 패널티를 주는 Brevity Penalty가 등장합니다.
Brevity Penalty
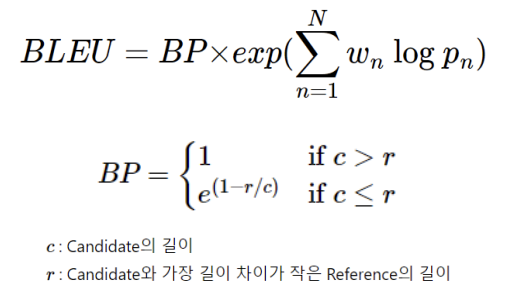 candidate가 reference보다 길이가 길다면 패널티를 주지 않지만, 길이가 더 짧다면 패널티를 주어 BLEU 점수를 낮춰줍니다.
candidate가 reference보다 길이가 길다면 패널티를 주지 않지만, 길이가 더 짧다면 패널티를 주어 BLEU 점수를 낮춰줍니다.
 BLEU는 속도도 빠르고 활용성이 높지만 완벽하지는 않습니다. 단순히 단어 단위로 직역하지 않고 맥락을 파악하여 의역을 했을 때 엉뚱한 단어가 등장할 수 있는데, 이러면 BLEU score가 낮아지게 됩니다.
BLEU는 속도도 빠르고 활용성이 높지만 완벽하지는 않습니다. 단순히 단어 단위로 직역하지 않고 맥락을 파악하여 의역을 했을 때 엉뚱한 단어가 등장할 수 있는데, 이러면 BLEU score가 낮아지게 됩니다.
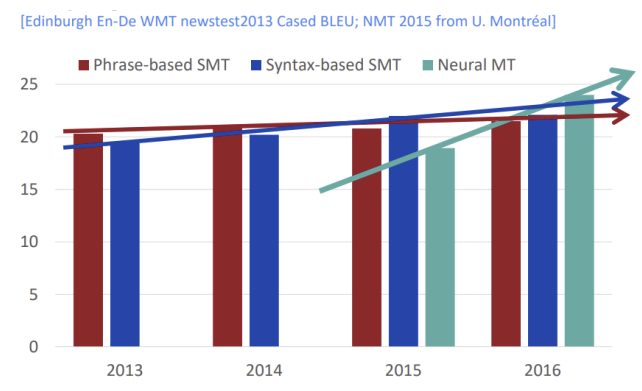 NMT는 등장한지 2년만에 SMT의 성능을 뛰어넘었습니다. 실제로 구글은 번역시스템을 SMT에서 NMT로 전환한 후 수백명의 엔지니어가 수년간 한 작업들을 소수의 엔지니어로 몇 달만에 더 나은 성과를 냈습니다.
NMT는 등장한지 2년만에 SMT의 성능을 뛰어넘었습니다. 실제로 구글은 번역시스템을 SMT에서 NMT로 전환한 후 수백명의 엔지니어가 수년간 한 작업들을 소수의 엔지니어로 몇 달만에 더 나은 성과를 냈습니다.
여전히 남은 Machine Translation의 한계
- Out of Vocabulary: 학습 데이터에 존재하지 않는 단어가 입력되면 목표 단어 생성 불가
- Domain Mismatch: train 데이터와 test 데이터 사이에 domain이 일치하지 않으면 성능 하락
- Context: 긴 문장의 문맥을 유지하기 힘들다.
- Low-resource language pairs: NMT 학습을 위한 많은 양의 병렬 코퍼스 구축이 어렵다.
 또한 관용적인 표현이 잘 학습되지 않습니다. 위의 예시에서 '프린트가 종이를 먹다'라는 표현이 엉뚱하게 해석되었음을 볼 수 있습니다.
또한 관용적인 표현이 잘 학습되지 않습니다. 위의 예시에서 '프린트가 종이를 먹다'라는 표현이 엉뚱하게 해석되었음을 볼 수 있습니다. 왼쪽 텍스트에서는 성별이 정해지지 않았는데, 영어로 번역한 결과 간호사의 주어는 she, 프로그래머의 주어는 he로 멋대로 할당하였습니다. 인터넷 상에 존재하는 문서들에는 암묵적인 사회적 편향이 담겨 있는데, MT는 이 데이터들을 그대로 학습하기 때문에 편향된 표현으로 번역합니다.
왼쪽 텍스트에서는 성별이 정해지지 않았는데, 영어로 번역한 결과 간호사의 주어는 she, 프로그래머의 주어는 he로 멋대로 할당하였습니다. 인터넷 상에 존재하는 문서들에는 암묵적인 사회적 편향이 담겨 있는데, MT는 이 데이터들을 그대로 학습하기 때문에 편향된 표현으로 번역합니다.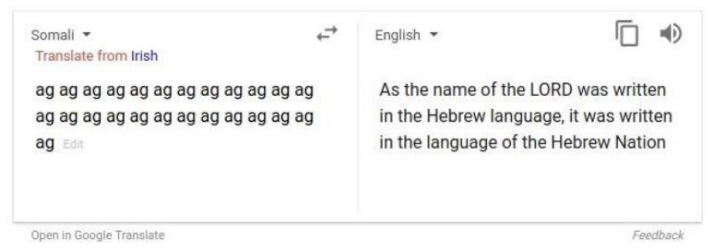 왼쪽 문장은 단순히 ag를 반복한 해석이 불가능한 문장인데, MT는 이를 마음대로 해석해버립니다.
왼쪽 문장은 단순히 ag를 반복한 해석이 불가능한 문장인데, MT는 이를 마음대로 해석해버립니다.
이러한 MT의 한계들을 보완하기 위해 나온 것이 바로 Attention입니다.
3. Attention
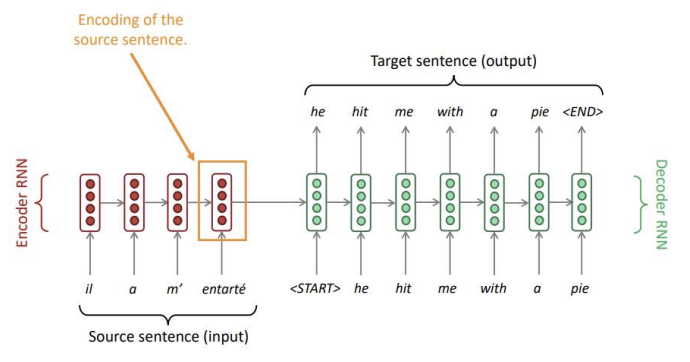 seq2seq는 인코더의 마지막 hidden state에 번역하고자 하는 문장의 모든 정보가 담겨 있어야 하기 때문에, 너무 많은 압력이 가해지게 됩니다. 즉 문장의 정보가 마지막 hidden state에서 다 인코딩 되어 버려 정보가 쏠리는 정보병목현상이 발생합니다.
seq2seq는 인코더의 마지막 hidden state에 번역하고자 하는 문장의 모든 정보가 담겨 있어야 하기 때문에, 너무 많은 압력이 가해지게 됩니다. 즉 문장의 정보가 마지막 hidden state에서 다 인코딩 되어 버려 정보가 쏠리는 정보병목현상이 발생합니다.
Attention은 디코더의 각 step에서 인코더에 대한 직접 연결을 사용하여 소스 문장의 특정 부분마다 집중함으로써 정보병목현상을 해결합니다.
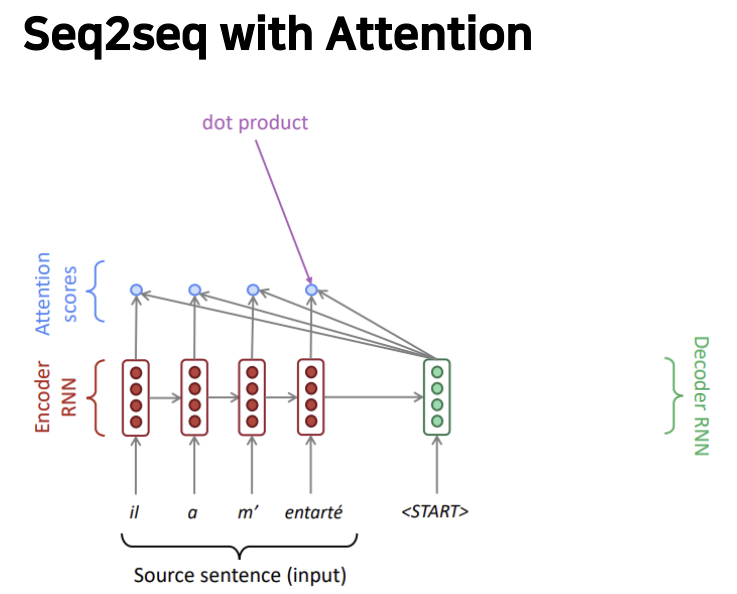
attention score
: 하나의 디코더와 각 인코더를 내적하여 스칼라 값을 구하면 그것이 바로 각각의 attention score
즉 attention score는 현재 시점의 디코저의 정보와 인코더의 매 시점의 정보간 유사도를 의미합니다.
attention distribution
: attention score를 softmax 함수에 통과시켜 생성된 확률 분포
위의 예시에서는 il에 가장 분포가 집중되었으므로 가장 먼저 he를 생성합니다.
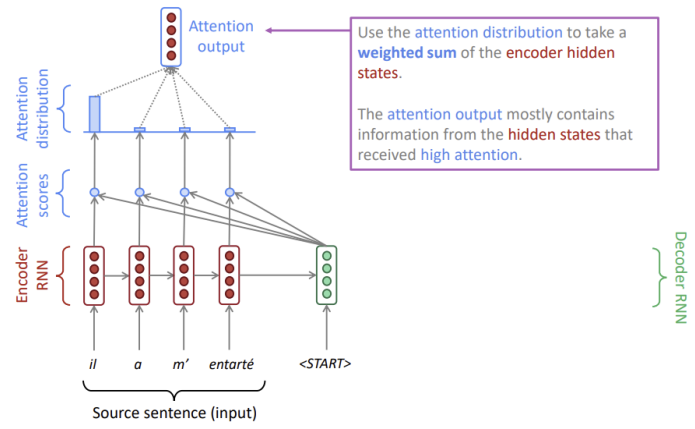
attention output
: attention distribution을 가중치로 하여 인코더의 각 hidden state를 가중합한 것
attention output은 높은 attention을 가진 hidden state의 정보를 포함하고 있습니다.
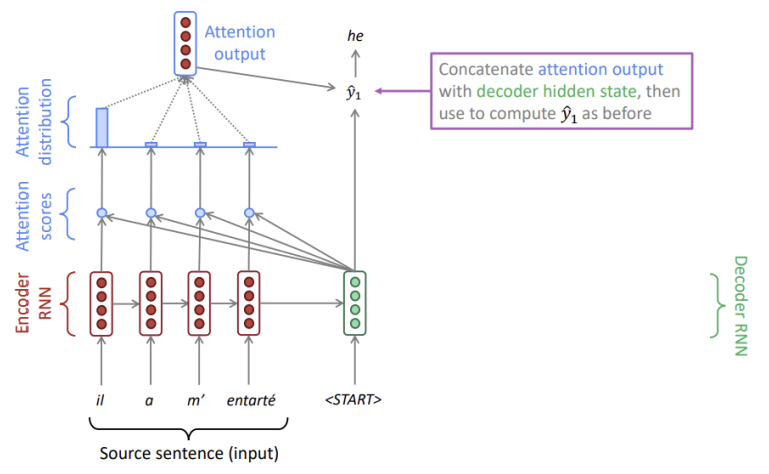 마지막으로 attention output과 디코더의 hidden state를 결합하여 를 산출합니다. 그리고 각 디코더에서 위의 과정을 반복합니다. SMT는 완전 대응하거나 대응하지 않는 har binary이지만, attention은 softmax를 취해서 더 유연한 정렬을 할 수 있습니다.
마지막으로 attention output과 디코더의 hidden state를 결합하여 를 산출합니다. 그리고 각 디코더에서 위의 과정을 반복합니다. SMT는 완전 대응하거나 대응하지 않는 har binary이지만, attention은 softmax를 취해서 더 유연한 정렬을 할 수 있습니다.
Equation
위의 과정을 수식으로 정리하면 다음과 같습니다.
 인코더의 각 hidden state와 t시점의 디코더의 각 hidden state를 내적하면 source sentence와 같은 길이의 벡터인 attention score가 나오고, 이를 softmax 함수에 넣으면 attention distribution이 나옵니다. 그리고 attention distribution과 인코더의 각 hidden state를 가중합하면 인코더의 hidden state와 같은 크기의 벡터가 나오고, 이를 디코더의 hiddenstate와 concat하면 가 나옵니다.
인코더의 각 hidden state와 t시점의 디코더의 각 hidden state를 내적하면 source sentence와 같은 길이의 벡터인 attention score가 나오고, 이를 softmax 함수에 넣으면 attention distribution이 나옵니다. 그리고 attention distribution과 인코더의 각 hidden state를 가중합하면 인코더의 hidden state와 같은 크기의 벡터가 나오고, 이를 디코더의 hiddenstate와 concat하면 가 나옵니다.
Attention의 장점
- 디코더가 소스 문장의 특정 부분에 집중함으로써 NMT의 성능을 비약적으로 향상시켰다.
- 디코더가 직접 인코더의 모든 시점에서 정보를 보게 함으로써 병목 현상을 해결했다.
- 문장의 길이가 길수록 기울기 소실 문제가 발생하는데, attention은 전체 문장 중 확률이 높은 단어에 더 집중함으로써 기울기 소실 문제를 해결했다.
- attention distribution을 통해 디코더가 어디에 집중하고 있는지 볼 수 있기 때문에 해석이 가능하다.
Generalization
attention은 seq2seq뿐만 아니라 많은 모델에서 사용될 수 있으며, MT뿐만 아니라 많은 task에서도 사용될 수 있습니다. 따라서 attention을 일반화시키면, vector values와 vector query가 주어졌을 때 query에 의존해서 value의 가중합을 계산하는 방법론입니다. 이때 attention output은 query가 집중하고자 하는 value의 요약된 정보이고, attention은 고정된 벡터 사이즈를 통해 query가 value들의 정보에 접근하는 방식을 말합니다.
Reference
- CS224 Winter 2019: Natural Language Processing with Deep Learning
- https://velog.io/@tobigs-text1314/CS224n-Lecture-8-Machine-Translation-Sequence-to-sequence-and-Attention
- https://velog.io/@tobigs-text1415/Lecture-8-Translation-Seq2Seq-Attention
- https://wikidocs.net/31695
!%5B%5D(https://velog.velcdn.com/images%2Ftobigs1516text%2Fpost%2F1229d302-a87b-4e36-9417-e2e8fb327dec%2Fimage.png){kind=link}

2개의 댓글

16기 이승주
-
Machine Translation
특정 언어의 문장을 다른 언어의 문장으로 번역하는 것이다. -
Sequence-to-sequence
Neural Machine Translation은 하나의 신경망 네트워크를 이용한 Machine Translaion으로 두 개의 RNN을 포함한다. 이 신경망 네트워크 구조를 seq2seq라고 부른다. 또한 NMT는 조건부 언어 모델이다. 디코더의 각 step에서 argmax를 취하는 것을 greedy decoding이라고 하는데 이는 틀린 단어로 예측되어도 되돌아 갈 수 없어 틀린 문장을 계속 써 내려가야하는 단점이 있다. 이를 해결할 수 있는 방법으로는 Exhaustive Search Decoding과 Beam Search Decoding 두가지가 있다.
BLEU(Bilingual Evaluation Understudy)는 기계에 의해 번역된 문장과 사람이 번역한 문장을 비교해서 유사도를 측정하여 성능을 측정하는 지표를 말한다. Machine Translation의 평가지표로 쓰인다.
- Attention
Attention은 디코더의 각 step에서 인코더에 대한 직접 연결을 사용하여 소스 문장의 특정 부분마다 집중함으로써 정보병목현상을 해결한다. 디코더가 직접 인코더의 모든 시점에서 정보를 보게 함으로써 병목 현상을 해결하고 문장의 길이가 길수록 기울기 소실 문제가 발생하는데, attention은 전체 문장 중 확률이 높은 단어에 더 집중함으로써 기울기 소실 문제를 해결했다.
15기 김현지
Machine Translation
: 특정 언어의 문장(x)를 다른 언어의 문장(y)으로 번역하는 것
Neural Machine Translation
: 하나의 신경망 네트워크를 이용한 Machine Translation
Attention
seq2seq에서는 문장의 정보가 마지막 hidden state에 다 인코딩되어 벼러 정보가 쏠리는 정보병목현상 발생
⇒ Attention은 디코더의 각 step에서 인코더에 대한 직접 연결을 사용하여 소스 문장의 특정 부분마다 집중함으로써 정보병목현상 해결
→ attention distribution 생성 → attention output 출력
Machine Translation이 어떻게 이루어지는지 잘 이해할 수 있었습니다! 좋은 자료와 발표 감사드립니다:)