
작성자: 고려대학교 통계학과 김현지
Contents
1. Constituency Parsing
2. Simple Tree RNN
3. Syntactically-United RNN
4. Matrix-Vector RNN
5. Recursive Neural Tensor Network
6. Summary
1. Constituency Parsing
문장을 이해하고 단어를 표현하는 방법에는 Bag of words 방법과 RNN 기반이나 CNN 기반의 모델을 사용하여 고차원적으로 표현하는 방법, 그리고 tf-idf를 통해서 벡터로 표현하는 방법들이 있다.

Compositionality란 사전적으로는 ‘합성성’이라는 뜻을 가지는데, 위 그림과 같이 작은 부품들이 모여서 하나의 새로운 것을 만든다는 것을 의미한다. 각 부품들은 고유한 의미를 가지고 있고, 이것이 합쳐서 하나의 의미를 이룬다. 이때 이 의미들을 어떻게 구조적으로 결합하느냐에 따라 전혀 다른 기계가 될 수도 있다.
이러한 개념은 언어적인 측면에서도 볼 수 있다. 즉, 여러 개의 단어들을 모아서 하나의 문장을 만들어내고, 각 단어들의 의미를 조합해서 한 문장의 의미를 파악할 수 있다.

위 그림에서 “snowboarder”과 “person on a snowboard”를 살펴보자. 두 개의 의미는 동일함에도 후자는 여러 개의 단어들을 사용해서 하나의 단어를 표현한 것을 알 수 있다.
이 개념들을 바탕으로 위 그림과 같이 구조적으로 문장을 나누고 각 단어의 조합이 나타내는 의미를 찾아 문장 전체의 의미를 파악하는 것이 이번 강의의 목표이다.
Recursive neural networks vs Recurrent neural networks
이번 강의에서 다루는 Tree RNN의 RNN은 Recursive neural network이다. sentance나 phrase가 필요할 때 주로 이 네트워크가 사용되고, 어떤 phrase가 문장에서 얼마만큼의 의미를 반영하는지를 해당 네트워크를 통해서 알 수 있다. 또한 문장의 덩어리들을 파악할 수 있다.
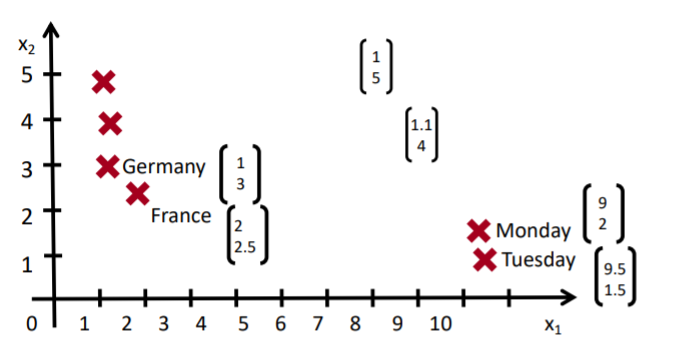
먼저 단어 벡터 공간을 생각해보자. 학습이 완료된 벡터 공간을 살펴보면 위와 같이 비슷한 의미를 가진 단어들이 가까운 곳에 분포되는 것을 볼 수 있다.
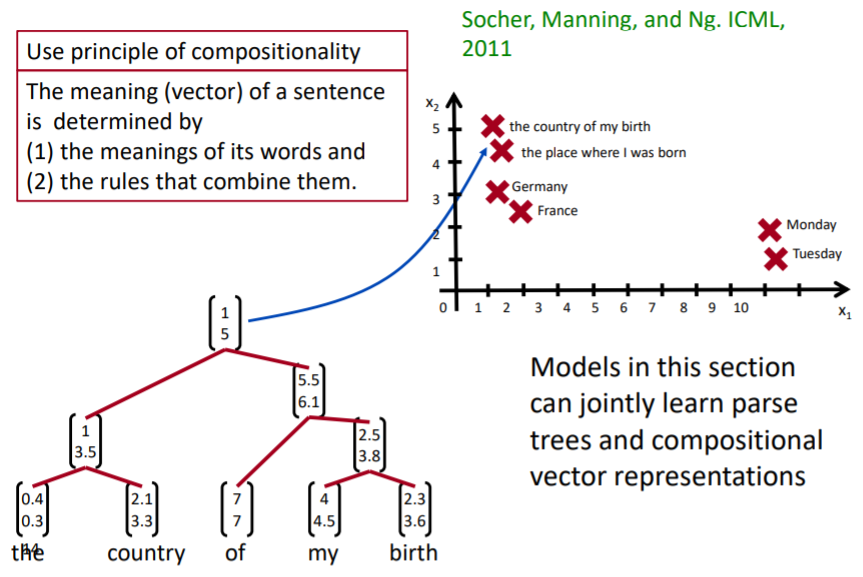
우리의 목표는 compostionality를 파악하는 것이다. 이를 위해 트리 기반의 RNN(recursive neural network)으로 단어와 구 덩어리, 문장 덩어리를 표현할 수 있다. 트리 가반의 RNN을 나타내기 위해서는 먼저 가장 기본적인 단어의 의미, 즉 단어 벡터들을 알아야 한다. 그 다음 단어들이 어떻게 결합하는 지에 대한 규칙들을 활용해 단계별로 문장의 의미를 추출하여 최종 벡터를 얻을 수 있다. 이러한 트리 기반의 RNN 구조는 일반적인 RNN(recurrent neural network) 구조보다 의미 파악에 훨씬 유용하다.
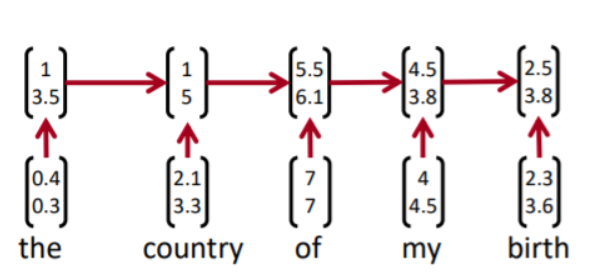
Recurrent neural network는 마지막 hidden state를 반영해서 문장을 표현하게 되는데, 이는 앞에 단어들의 의미를 잃어버리기 쉬운 구조이다. 즉 앞단에 있는 hidden state 정보들을 점점 엃어버리게 된다.
2. Simple Tree RNN
이 모델의 특징은 ‘very good’처럼 문법적, 의미적 응집성이 높은 입력값을 트리 형태로 결합해나가는 것이다.
Tree RNN을 진행하기 위해서는 다음 2가지를 알고 있어야 한다.
- 단어들의 의미
- 단어들이 결합하는 방식
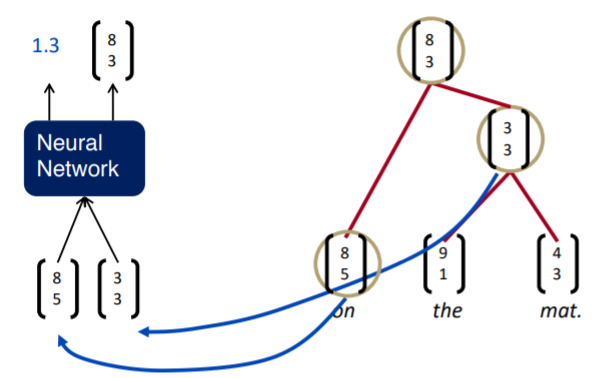
단어의 의미를 알고 있으므로 단어 벡터를 Tree RNN에 input으로 넣게 되면 score와 semantic representation을 출력한다. score는 해당 두 단어들이 결합했을 때 그 결합한 결과가 얼마나 그럴듯 한지를 나타낸다. 즉 두 단어를 결합해야 하는지 말아야 하는지에 대한 점수라고 해석할 수 있다. 그리고 만약 결합하게 된다면 결합된 것의 의미를 표현하는 벡터를 출력한다.
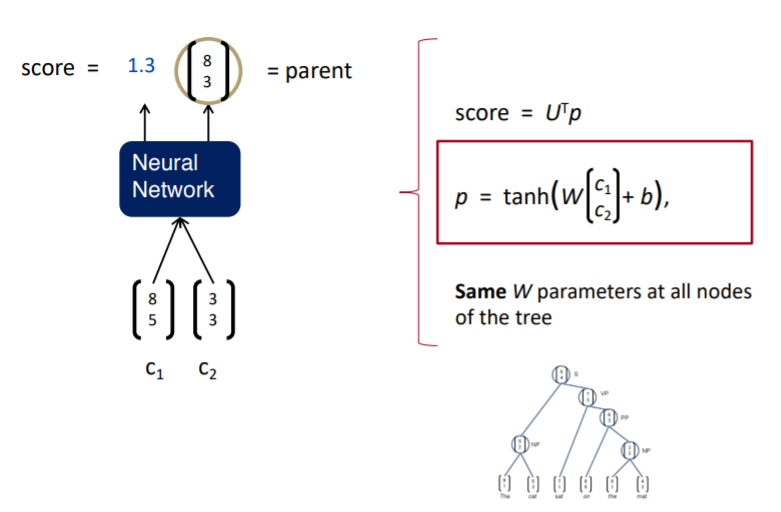
라는 의미를 가지는 벡터가 있다고 하면 이를 Neural Network를 통과시킨다. 그러면 가 결합한 것에 대한 score와 semantic representation를 얻을 수 있다. 이때 semantic representation는 두 단어 벡터 를 concat한 다음 weight를 곱하고 bias를 더한 다음 비선형인 tanh를 씌워 구한다. 이 semantic representation에 단순한 선형 행렬 연산을 하여 score를 나타낼 수 있고, 이 값이 크면 해당 두 노드를 결합하고 작으면 결합을 하지 않게 된다.
Simple Tree RNN 같은 경우에는 위 계산에서 weight인 매트릭스 는 모든 조합의 계산에서 같은 값을 사용한다.
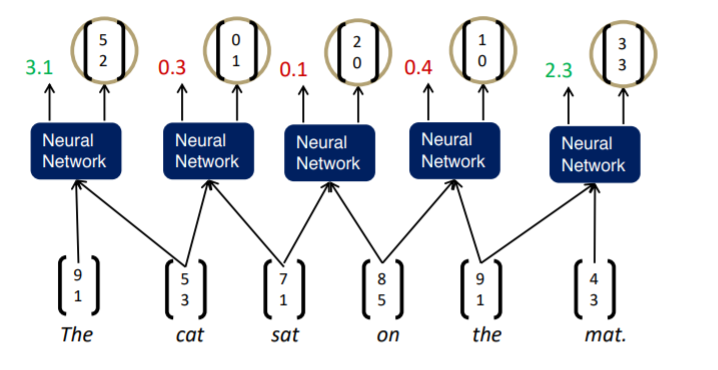
이 과정을 greedily하게 진행한다. 가장 먼저 인접한 단어들의 조합에 대해 semantic representation과 score를 구한다.
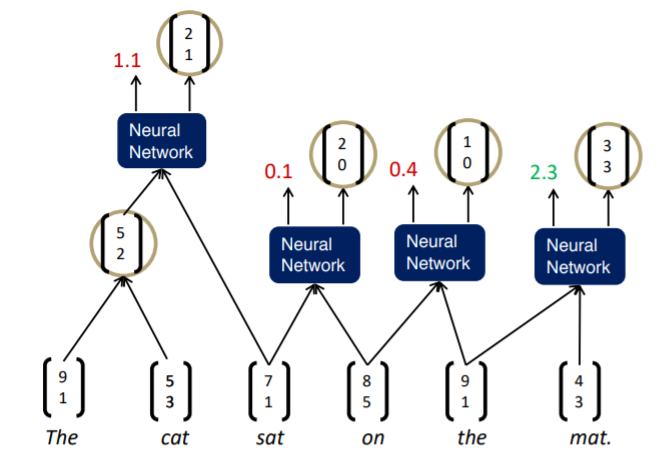
그리고 가장 높은 score 값을 가지는 노드를 멀지해주고, 다시 새롭게 인접한 단어들의 조합에 대해 semantic representation과 score를 구한다.
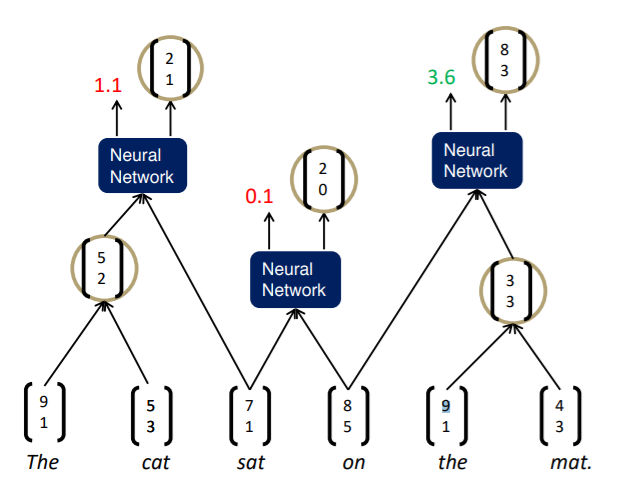
이런 유사한 방식으로 끝까지 가다보면 하나의 노드, 즉 문장 하나만 남게 된다.
Simple Tree RNN의 한계점
- score와 semantic representation를 계산할 때 모든 노드에 같은 (weight matrix)를 사용한다.
- 일부 현상에서는 적합할 수 있지만 더 복잡하고, 고차 구성 및 긴 문장에서는 적절하지 못하다.
- input 단어 간 interaction을 잘 파악하지 못한다.
- 조합 함수가 모든 경우에 대해서 동일하게 작용한다.
3. Syntactically-United RNN
Syntactically-United RNN은 Simple RNN의 한계점을 개선한 모델로, 모든 조합에서 똑같이 사용되었던 행렬 를 각기 다른 행렬로 설정한다.
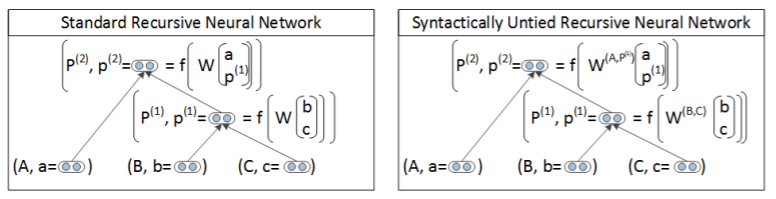
이런 방식으로 진행할 경우, 각 matrix를 찾아야하기 때문에 학습이 오래 걸리는데, 이를 해결하기 위해 PCFG방식을 사용한다.
즉 SU-RNN은 PCFG와 Tree RNN을 결합한 방법이다. 먼저 문장이 하나 주어지면dynamic programming 알고리즘을 사용해서 개의 문장 구조를 발생시킨다. 그리고 문장 구조들이 만들어지면 앞서 사용한 방법으로 문장에 대해 semantic representation과 score를 구한다. 이때 weight를 ‘명사+동사’, ‘형용사+명사’ 등 여러 문법적 조합에 따라 다르게 적용시킨다. 이렇게 조합된 단어의 확률을 계산하고 Tree RNN에 적용한 모델이다.

4. Matrix-Vector RNN
또 다른 버전으로 Matrix-Vector RNN이 있다. 이 모델은 simple Tree RNN과 달리 결합하는 단어가 다르면 그 결합 과정 또한 다를 것이라는 전제가 깔려있는 기법이다. 이전 모델들과 다르게 단어들이 벡터 정보만 가지고 있는게 아니라 행렬에 대한 정보까지 같이 가지고 있다. 단어가 지니는 정보를 더 가지게 함으로써 문장의 의미를 더욱 잘 파악할 수 있도록 한다.
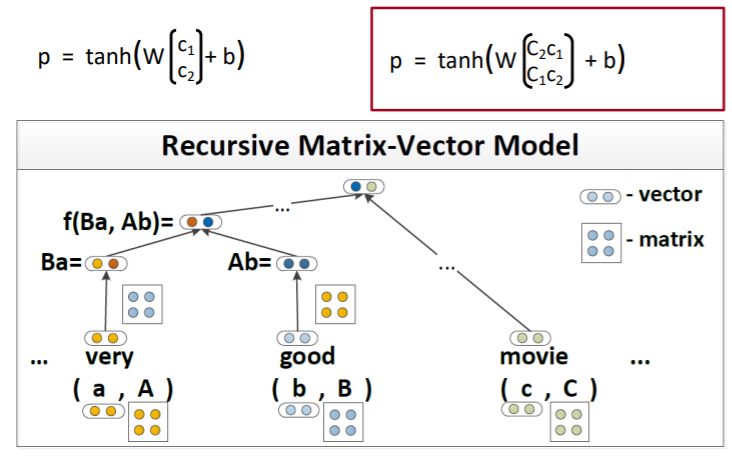
연산은 다음 그림과 같이 ‘very’의 단어벡터와 ‘good’의 행렬, 반대로 ‘good’의 단어벡터와 ‘very’의 행렬이 곱연산 되고, 그 값에 일련의 함수처리를 하여 최종값을 구해준다.
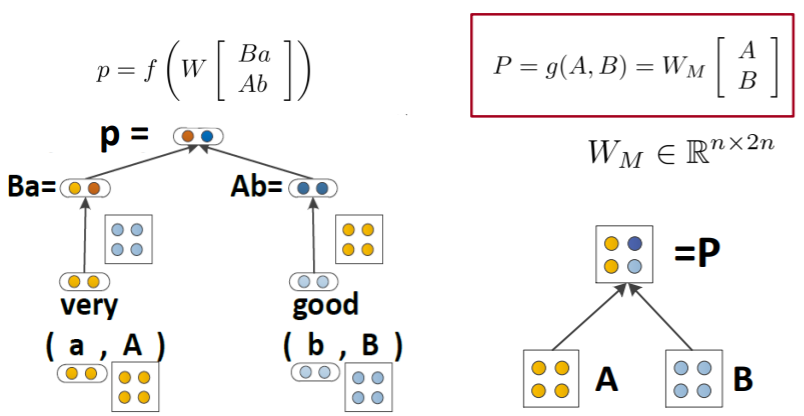
이렇게 두 노드가 멀지할 때 단어벡터와 행렬이 서로 interaction되도록 곱해주기 때문에 더 semantic한 정보를 반영할 수 있게 된다.
5. Recursive Neural Tensor Network
오래전부터 감성 분석 태스크는 꾸준히 연구되어 왔다. 굳이 Tree RNN을 통해 단어와 문장을 분석하지 않고, Bag of Words를 통해서 임베딩하여 분석을 해도 90% 정도의 성능을 보인다고 한다. 하지만 아래와 같이 조롱 섞인 문장의 경우 그 안의 감성을 잘 찾지 못한다.

이런 문제는 MV-RNN에서도 계속해서 발견되면서 이를 분석하기 위해 새로운 모델이 필요했고, 그래서 제시된 모델이 바로 RNTN이다.
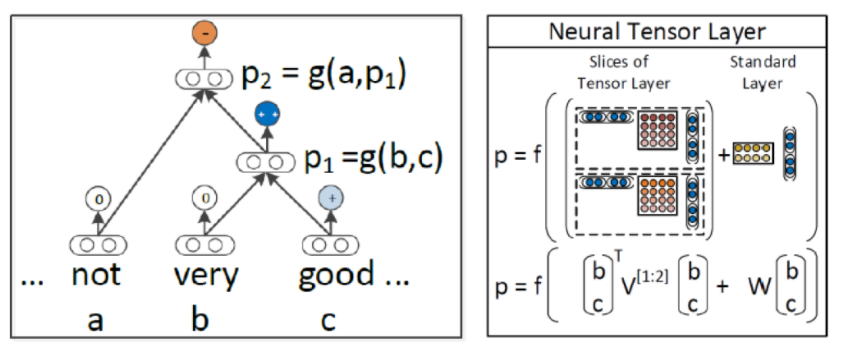
오른쪽 그림이 RNTN의 구조이다. 해당 모델은 MV-RNN보다 적은 파라미터를 가진다. MV-RNN은 모든 결합에 대해 각 노드마다 행렬을 생성하고 계속 연산을 진행해야 하므로 cost가 높아질 수 밖에 없다. 반면에 RNTN은 Tensor(3차원)로 연산을 진행하여 동일한 정보에 대해 파라미터를 줄여 cost를 낮추었다.
위 그림처럼 RNTN은 모든 단어와 모든 결합에 대해 행렬을 생성하는 대신 모든 단어와 모든 결합 노드가 공유하는 tensor를 설정한다. 위 그림에서는 가 tensor를 의미한다.
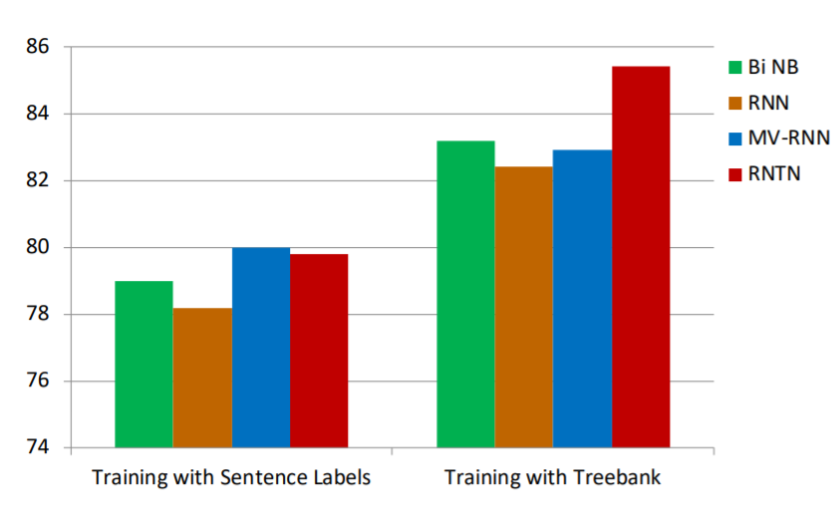
이렇게 만들어진 RNTN은 일반적인 데이터셋에서는 큰 효과를 얻지 못했지만 TreeBank에 관한 데이터 셋에서는 큰 Accuracy를 얻었다.
6. Summary
- 언어학적 개념을 이용해서 Tree RNN 모델에 대한 아이디어가 제안되었다.
- 요즘 NLP에서는 활용이 안되는 추세이다.
- LSTM, CNN, Transformer 등 contextual language model의 성능이 더 좋다.
- 트리 기반 모델에 사용할 데이터 셋을 구하는 데 비용이 많이 든다.
- Tree RNN 모델은 문장마다 다른 구조를 가지므로 GPU 연산이 용이하지 않다.
- 다른 영역에서 적용이 시도되고 있다.
- 물리학에서의 적용
- 프로그래밍 언어 번역 task에 적용
cs224n-2019-lecture18-TreeRNNs
Reference
