

작성자 UNIST 산업공학과 김건우
Contents
Unit 01. Introduction
Unit 02. Transformers and Self-Attention
Unit 03. Image Transformer and Local Self-Attention
Unit 04. Music Transformer and Relative Positional Self-Attention
01. Introduction
Variable-length representation in seq2seq
(Summariziation, Q&A etc.)
1. RNN (Recurrent Neural Network)
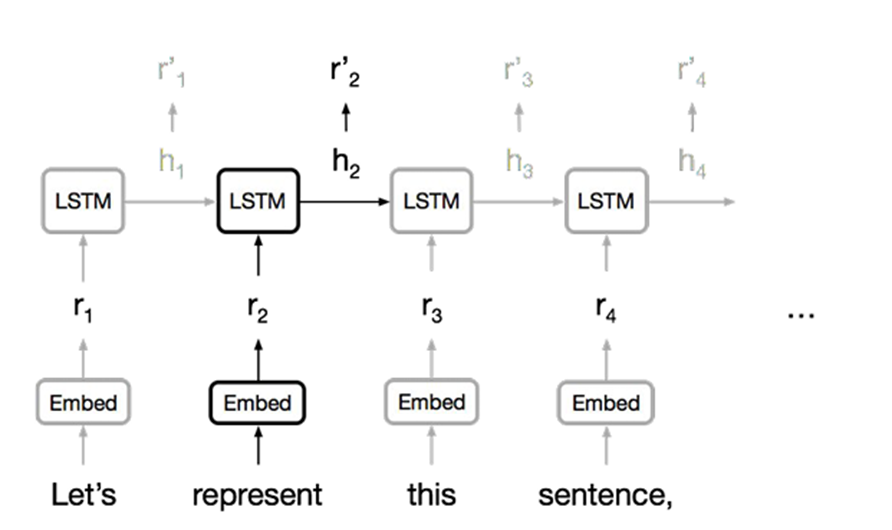
Limitations
- Long-term dependency problem happens when the lenght of sequence becomes longer
- Cannot apply parallelization so it takes high cost to train
2. CNN (Convolutional Neural Network)
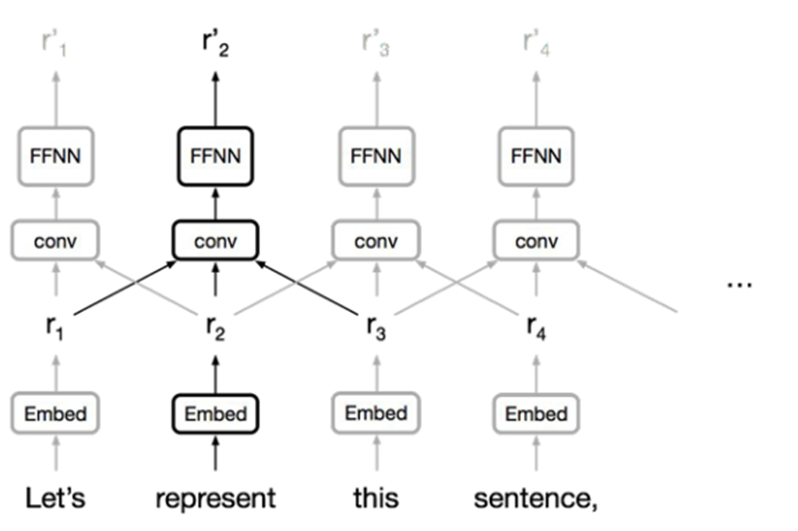
Advantage
- Trivial to parallelize so it can insert input sequence all at once
Disadvantage
- In order to get long dependency, model needs many layers due to the limitation on the size of receptive fields
3. Attention
- "Can we use 'Attention' method for representation?"
02. Transformers and Self-Attention
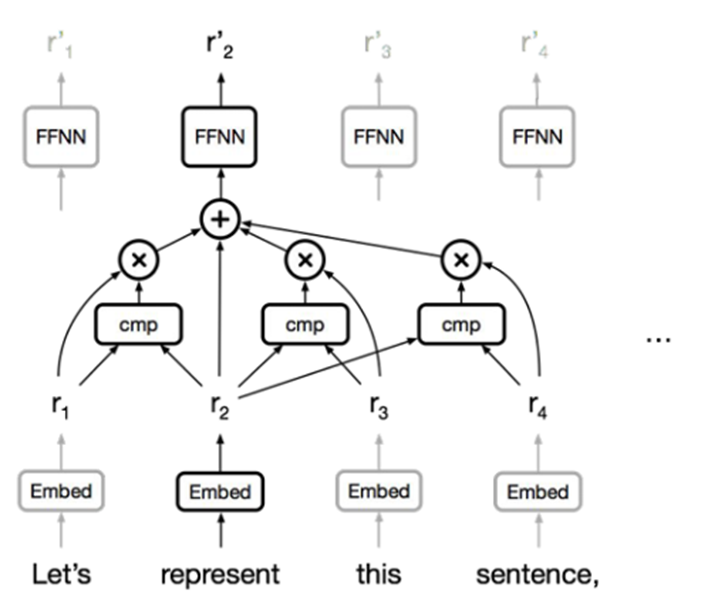
A token which refers to 'represent' in this sequence is expressed as new vectors through arbitrary calculations (will be explained later)
Advantages
- Trivail to parallelize so it can insert input sequence all at once
- Solve out long-term dependency problem since it can catch long-term dependency regardless of the distance between words that are far away
Self-Attention
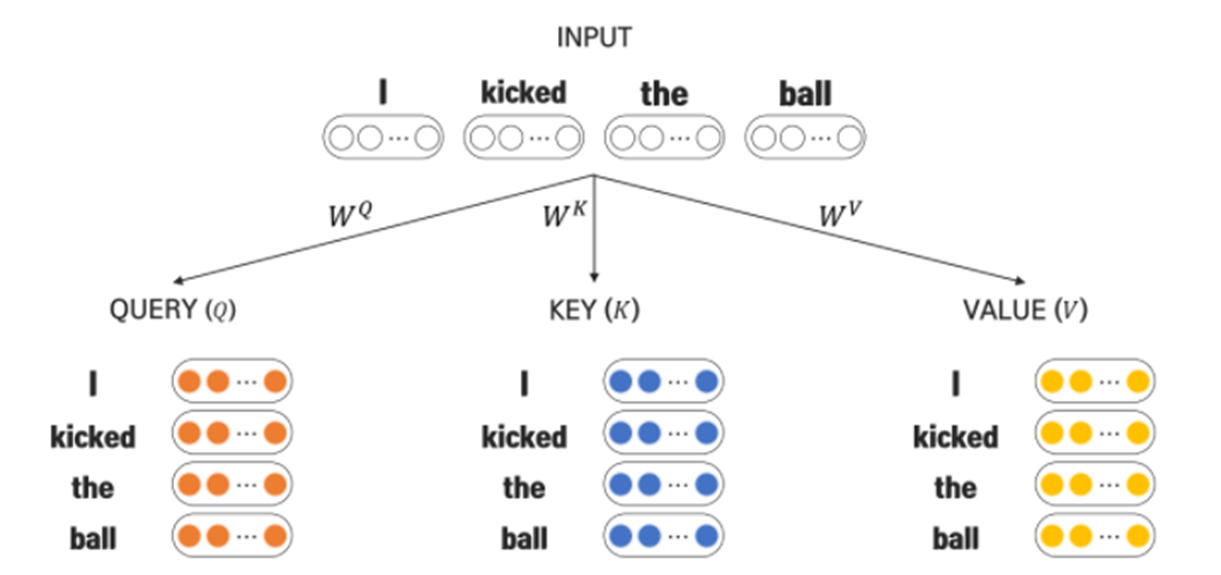
- After linear transformation with input sequence vector 'X' and weight 'W', it generates Q,K,V vectors
- Q,K,V vecotrs are generated for each token in the sequence
-'Q' for 'I', 'kicked', 'the', 'ball'
-'K' for 'I', 'kicked', 'the', 'ball'
-'V' for 'I', 'kicked', 'the', 'ball'
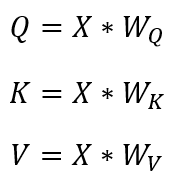
Self-Attention procedures
Attention formula
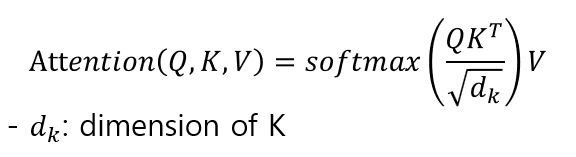
we set the size of dimension in K as 4 in the following example
1) Dot product between Q,k
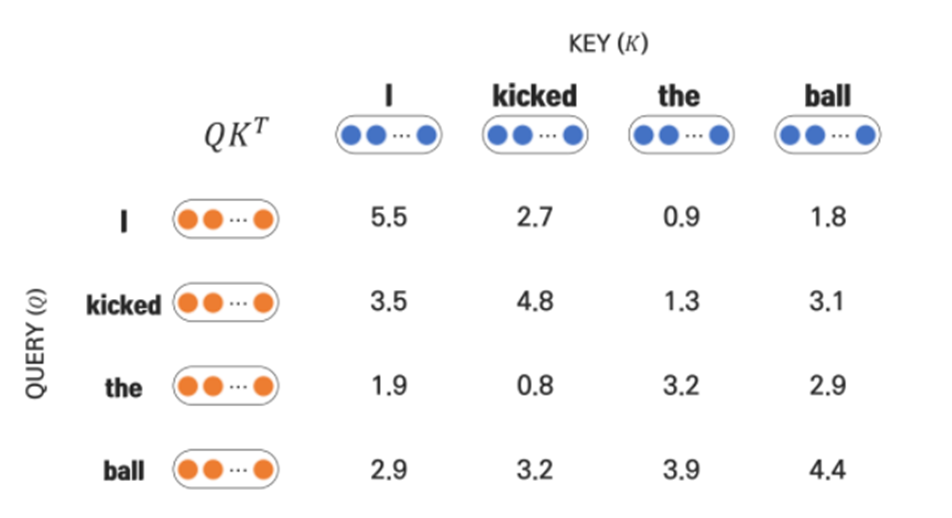
2) Scaling with 'd_k'
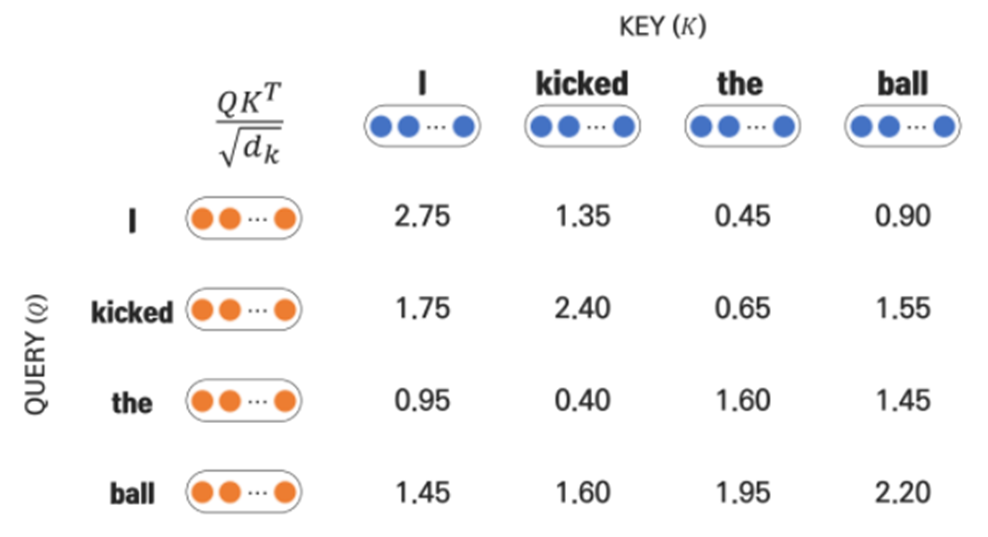
3) Appyling softmax function
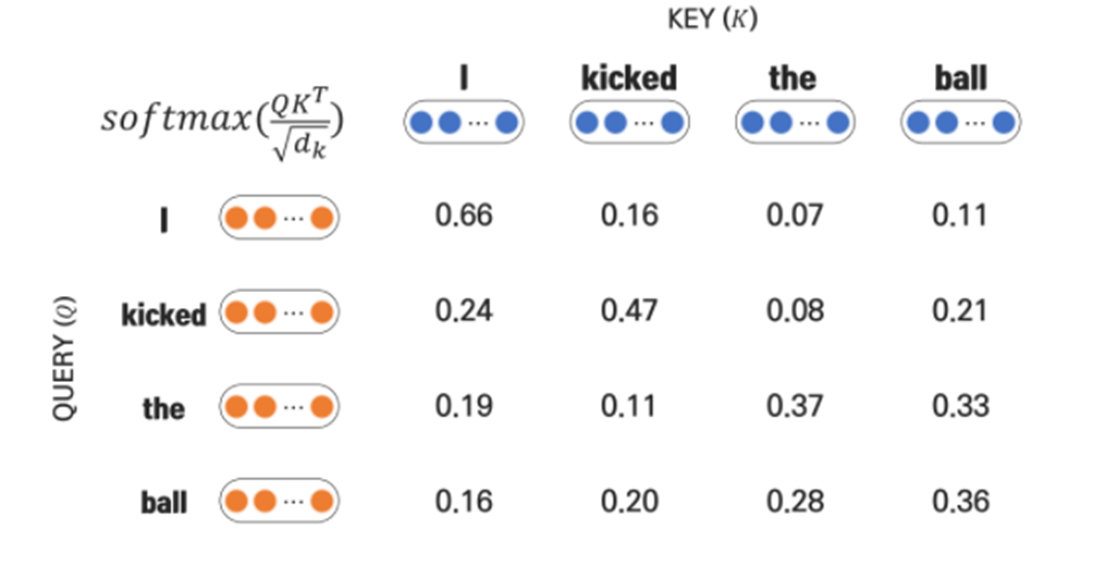
4) Weighted sum with V

The output vectors from self-attention has the same size as K
Compare Self-Attention's big O with Recurrent and Convoultion

-
Complexity Per Layer: Usually, sequence length (‘n’) is smaller than model dimension (‘d’)
-
Sequential Operations: O(1) refers to parallelization
-
Maximum Path Length: O(1) refers to solve out long-term dependency
Self-Attention in Transformer
Encdoer
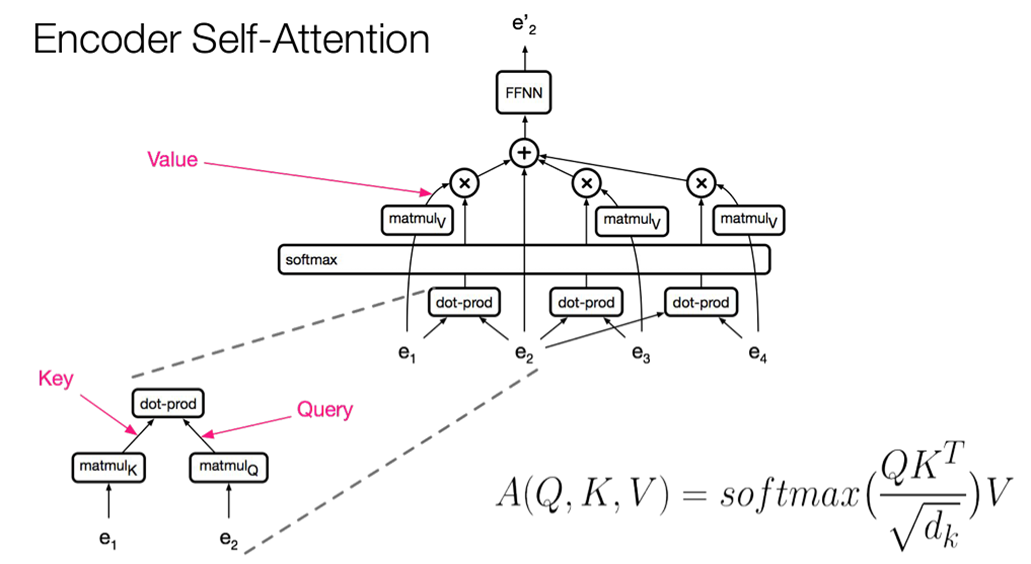
Self-attention in encoder gets all the tokens at once and process them
Decoder
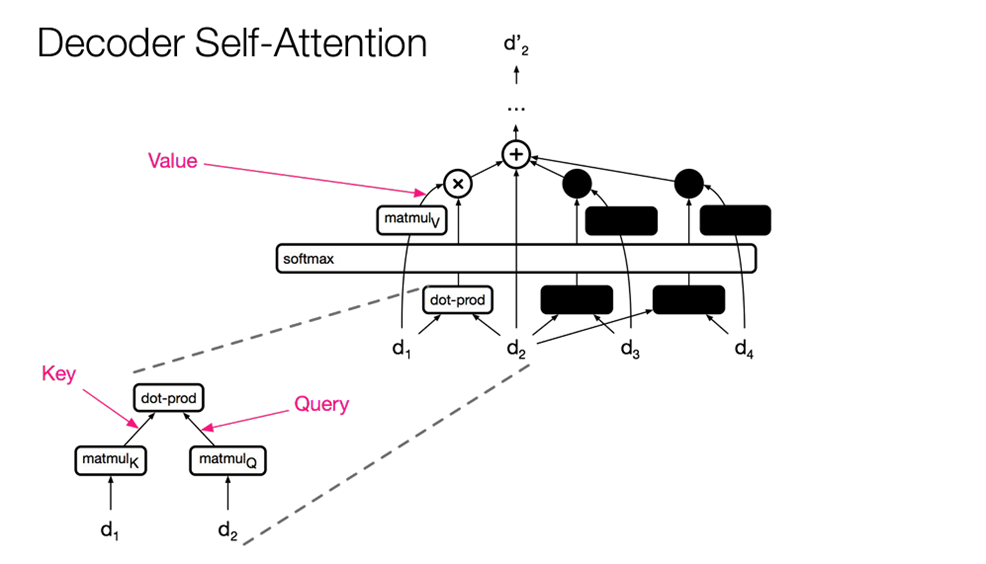
Self-attention in decoder masks some tokens since if it knows the values in advance, it will be cheating
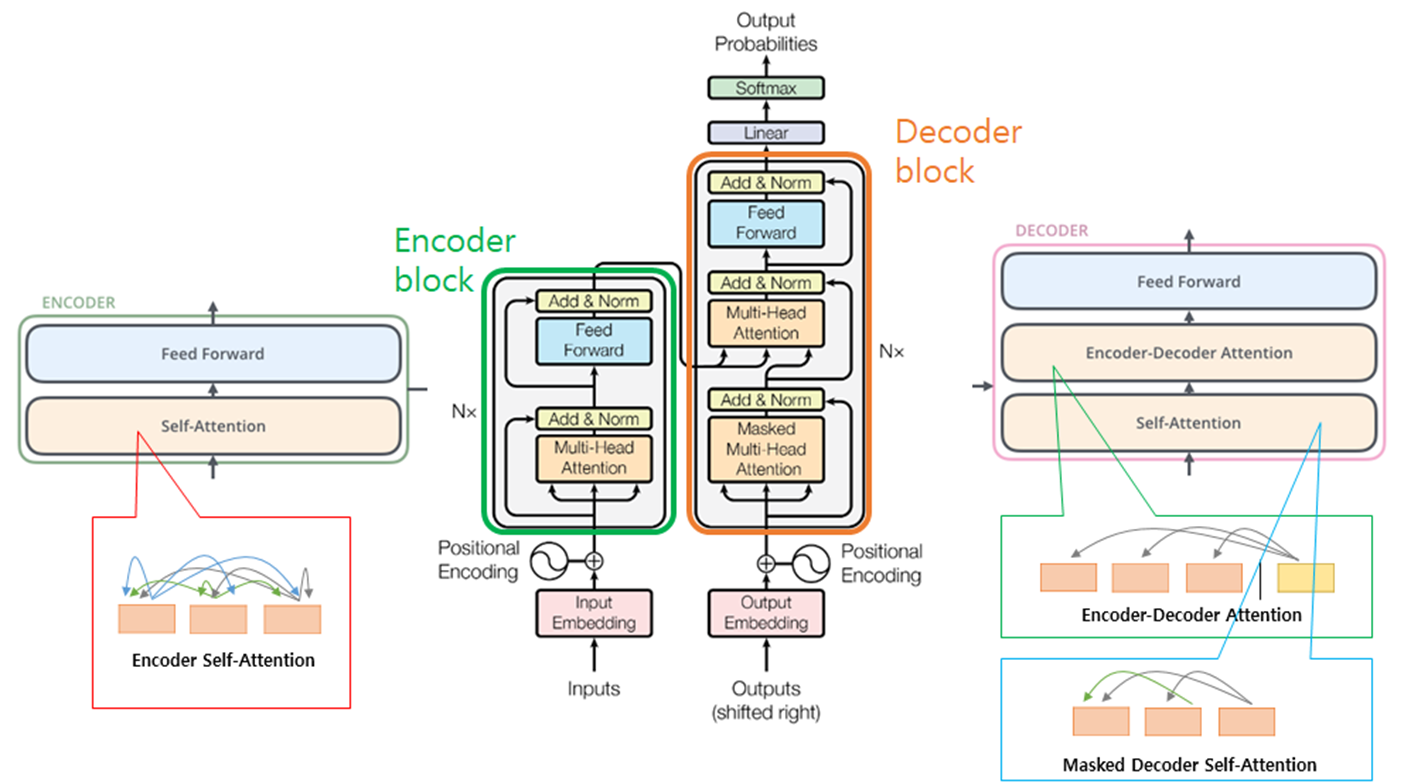
Transformer - overall structure
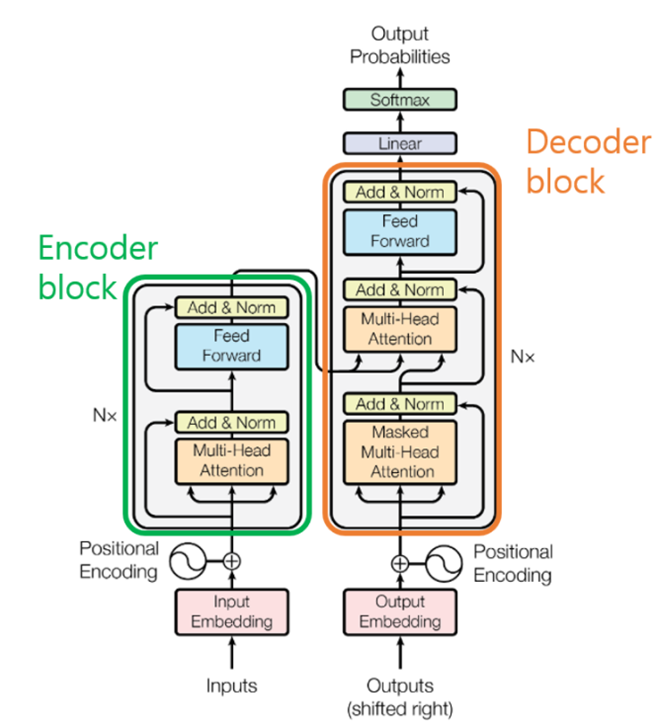

Transformer - Encoder structure
1) Input - word2vec (word embedding)

Input vectors in encoder are embedded to low-level tokens from word embedding such as 'word2vec' and 'Glove'
2) Positional Encoding
-
Input sequence in Transformer is not inserted sequentially unlike RNN. So, in order to get position data from input sequence, we manually add position information on input sequence by positional encoding
-
Positional encoding is calculated through cos, sin function

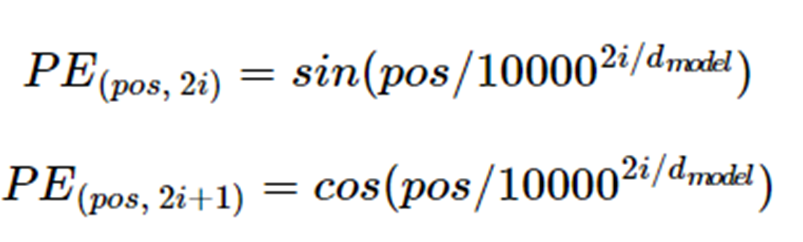
3) Self-Attention (explained above)
4) Multi-Head Attention: learning 8 attention layers while setting different initial values
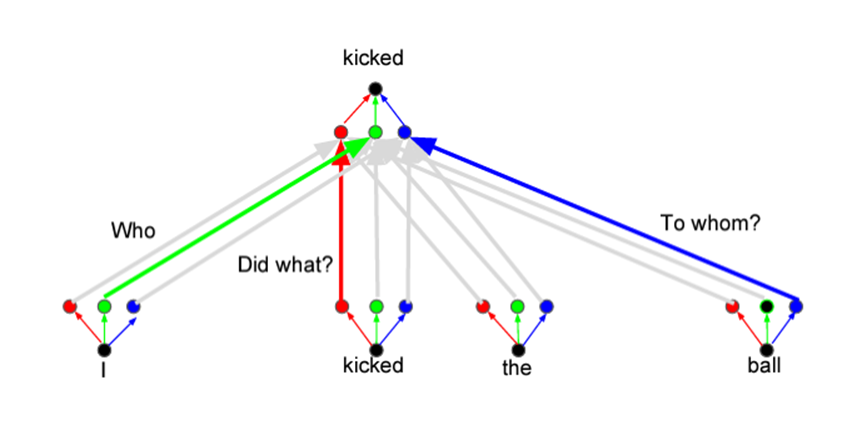
Usually, Sequence data contains a variety of information. 'Multi-Head Attention' concept was introduced from the idea that it would be better to use different multiple attention layers because all information cannot be expressed if only one attention layer is used.For example, in the sentence 'I kicekd the ball', the word 'kiced' has different diverse meanings for the word 'who, did what, which, and to whom'. In the following example here, three attention layers are used to represent the meanings of 'kiced'. But if it only uses 'green' attention layer, 'kicked' does not have meaning for who the ball was kiced or what it kiced, so it is limied in representation.
-
Sequence contains diverse information, so only using one 'Attention' layer cannot reflect all information
5) Residual connection + Layer Normalization
Residual connection
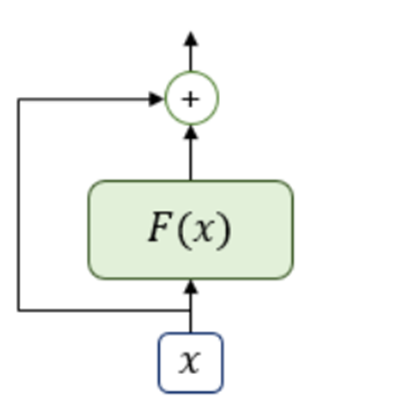
-
By using residual connection, it can pass gradient well while on backpropagation
Layer Normalization
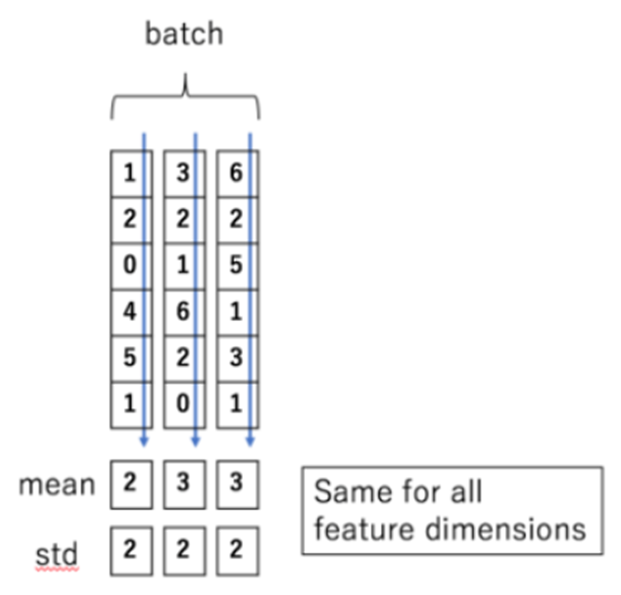
-
Unlike Batch Normalization, layer normalization normalizes values that correspond to same index on batch
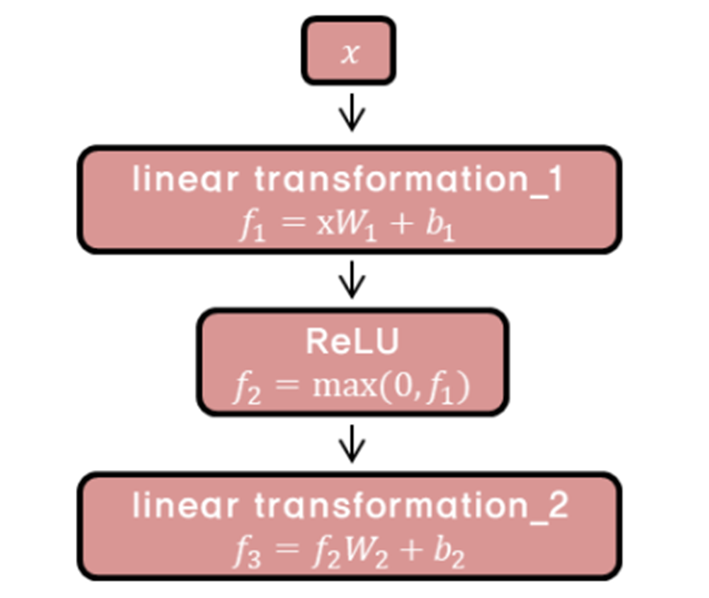
6) Point-Wise Feed-Forward Networks
- FFNN is formulated through two linear transformations. Since the dimension size from attention is same as before, the size of dimension entering the FFNN remains the same.
Entering size: (size of length, d_model = 526)
After first linear transformation: (d_modle, d_ff)
After second linear transformation: (d_ff, d_model)
Output size: remains same as 'entering size'
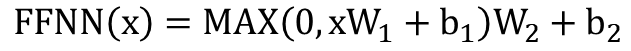

Transformer - Decoder structure
- Overall Decoder's structure is similar to Encoder's.
- Different points only exist in attention part and added layers which are 'Linear and Softmax' layers.
Attention in Decoder
1) Encoder-Decoder Attention
- K,V are from Encoder's output but uses Q from Decoder
2) Decoder Self-Attention
- Works same as Encoder's Self-Attention module but it masks tokens from the later point of view.
ex) decoder's current state: 't', maksing tokens: from 't+1' to the end
- While on training, in order to use 'Teacher Forcing' it gets all tokens at once
03. Image Transformer and Local Self-Attention
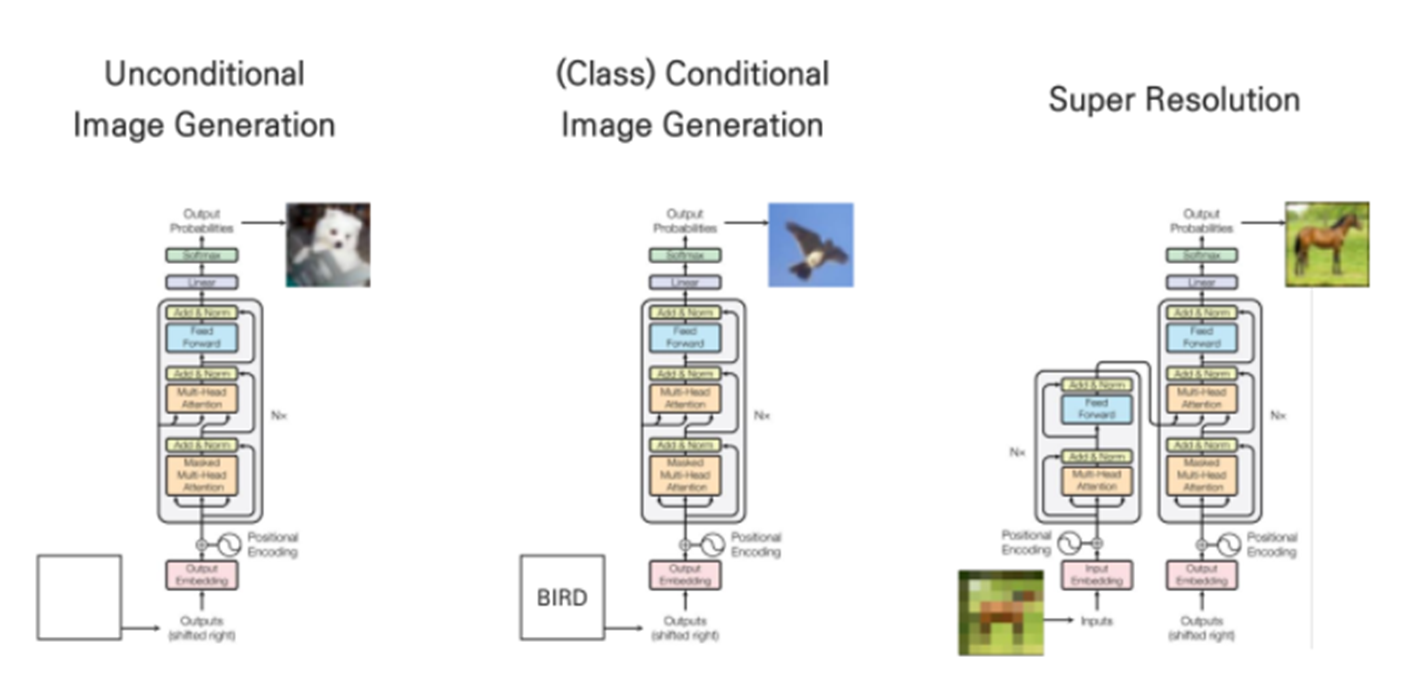
Unconditional Image Generation
- generating specific images from large data
- only uses Decoder
(Class) Conditional Image Generation - generating specific images from class embedding vectors
- only uses Decoder
Super Resolution - generating high resolution image from low resolution image
- only 'Super Resolution' taks uses both Encoder and Decoder.
Image Transfromer Problem

If Image Transformer uses high dimension images such as (32x32), the length of image pixel is defiend as (32x32xRGB(3) = 3072) which needs high complexity calculating Self-Attention which computes O(3072x3072xd)
In reality, it can be seent that self-attention cannot be utilized in super resolution tasks
Solution
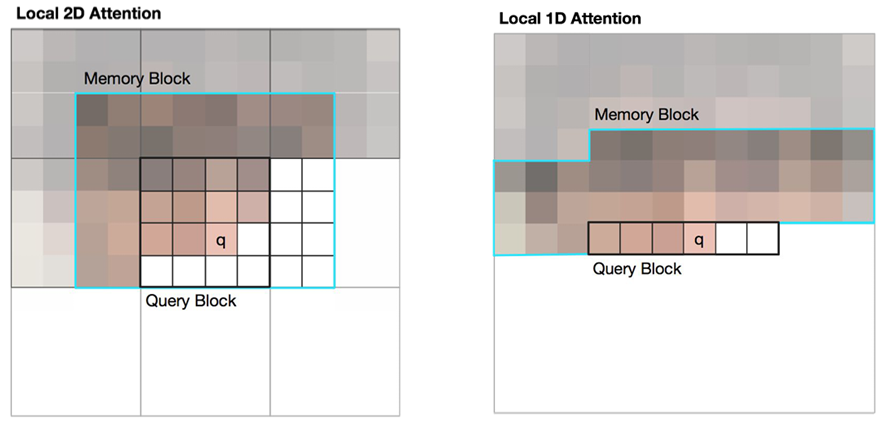
Local Self-Attention: applying self-attention only on local sequence not global
Steps for Local 2D Attention
1) Set Query block which also follows raster scan order
2) Last generated pixel on Query block is query
3) Set Memory block which surrounds Query block on side and upward
4) Pixels on Memory block are keys and values.
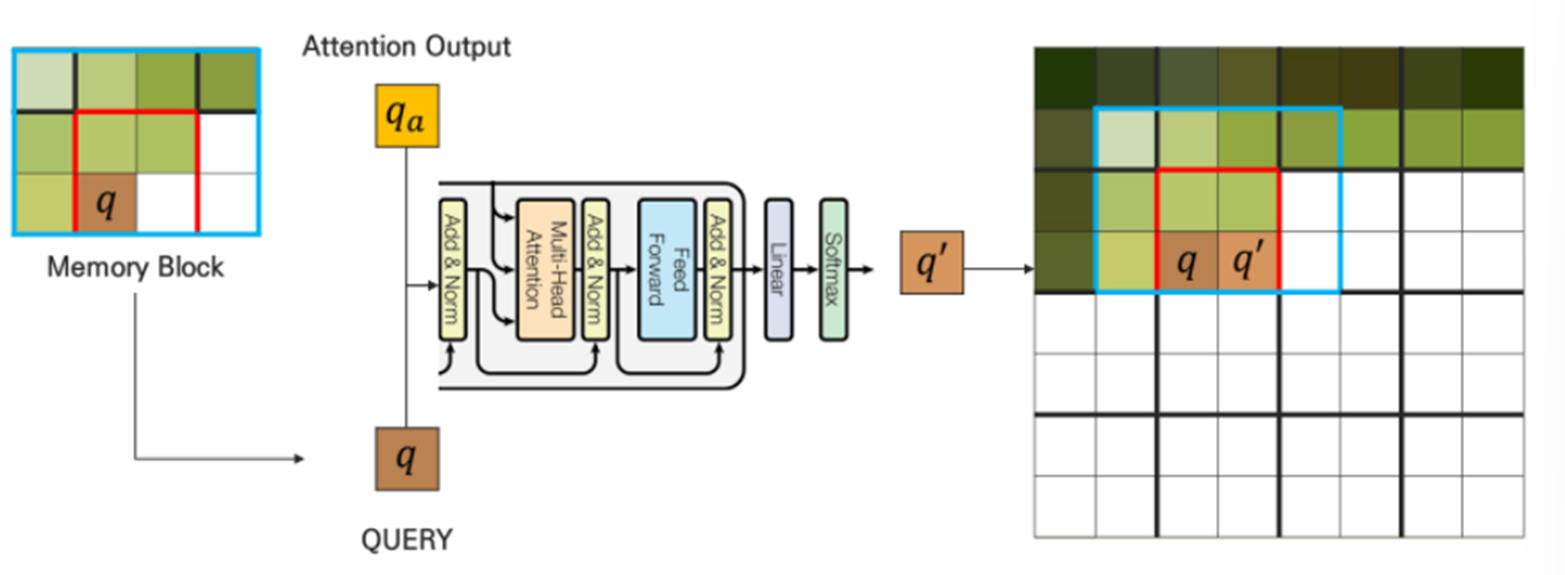
5) Self-Attention with following Q, K, V
6) With following results, after Transformer’s Decoder Attention and FFNN, output pixels are generated
generate q' pixel from decoder which uses q as query pixel
Experiment Results

04. Music Transformer and Relative Positional Self-Attention
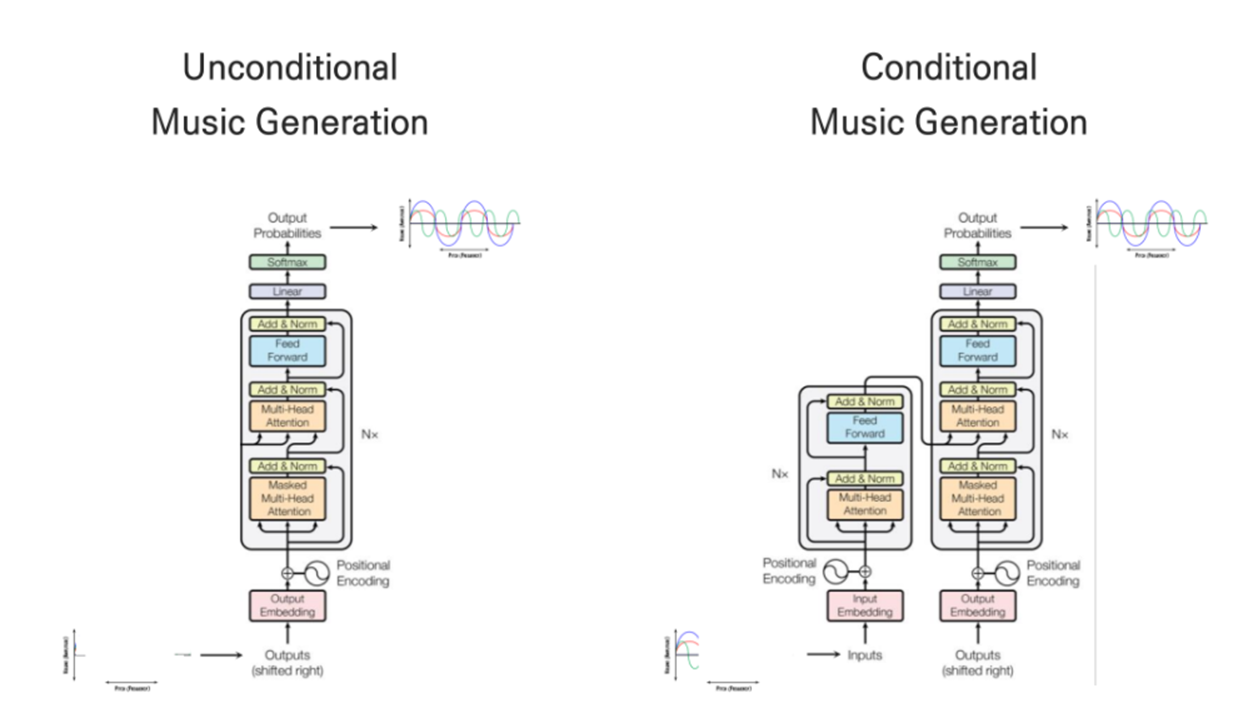
Unconditional Music Generation
- generating specific msuic from large data
- only uses Decoder
(Class) Conditional Music Generation - generating specific music from class embedding vectors
- only uses Decoder
We can know weighted average on sequene from self-attention explained above. However, we cannot know the distance between Q and K tokens. While generating music, we should consider frequency and repetitive concepts so distance between Q and K tokens is essential.
In order to calcuate distance between Q and K tokens, it introduces new attention concept
Reflect distance between Query and Key on attention weight
**Relative Attention = Multi-head Attention + Convolution**
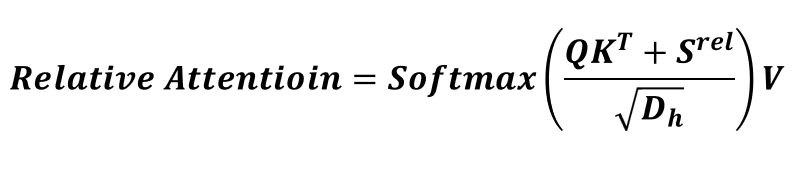
How to solve out relative positional Self-Attention?
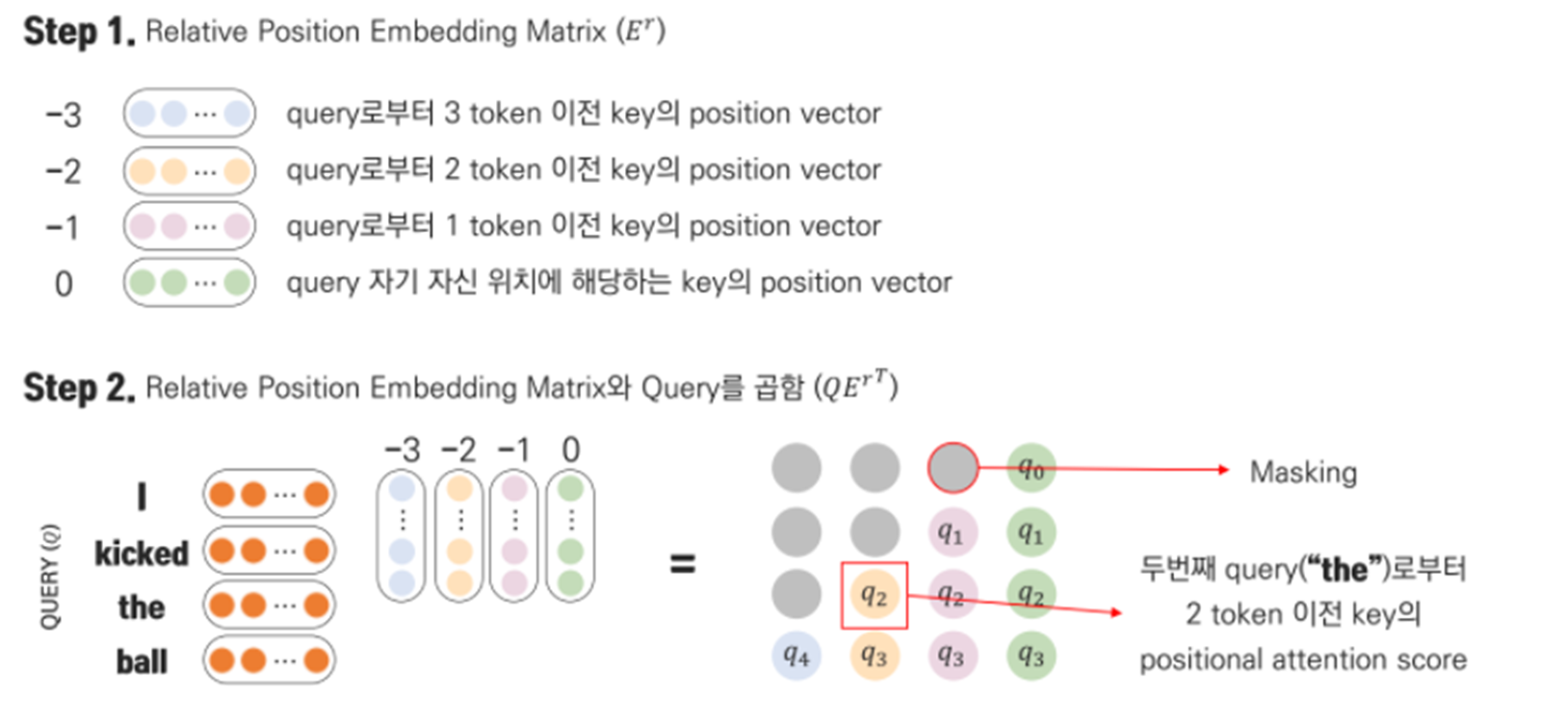
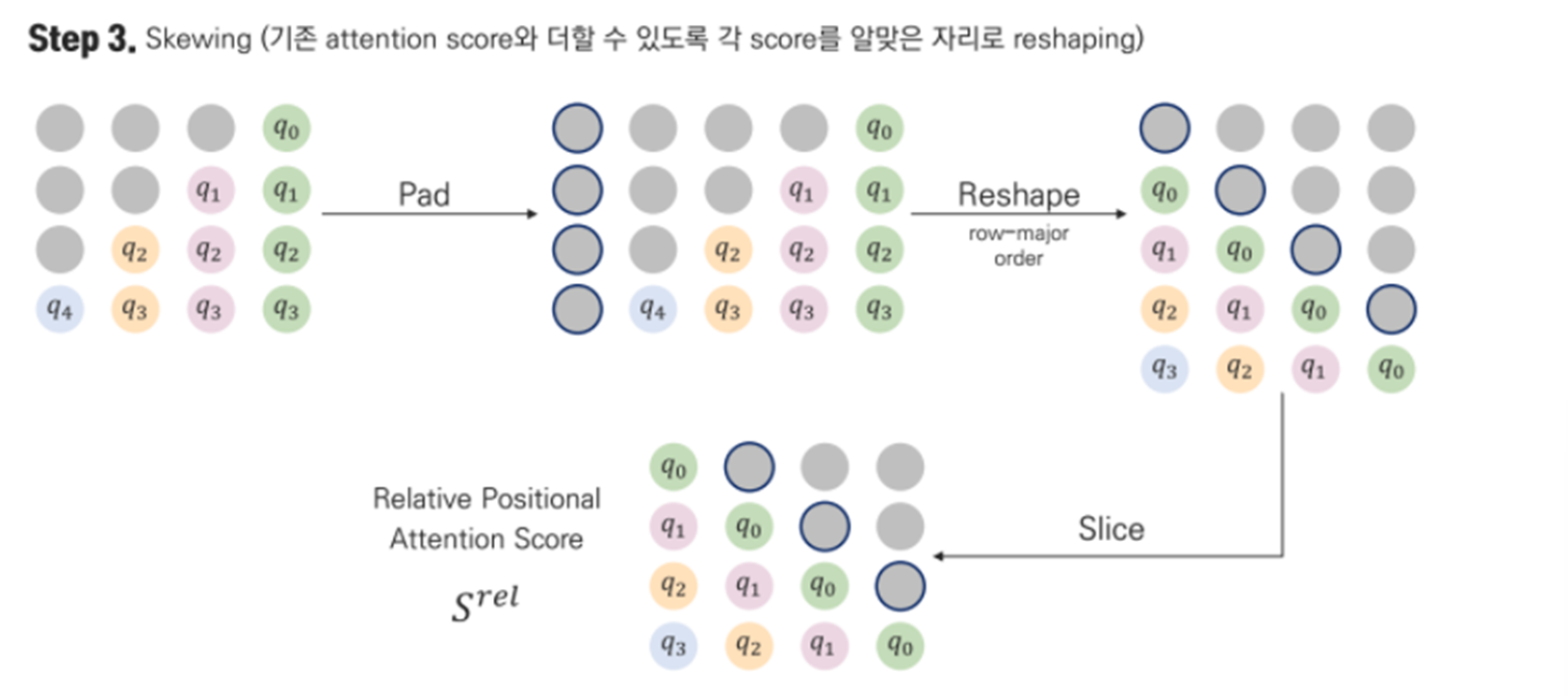
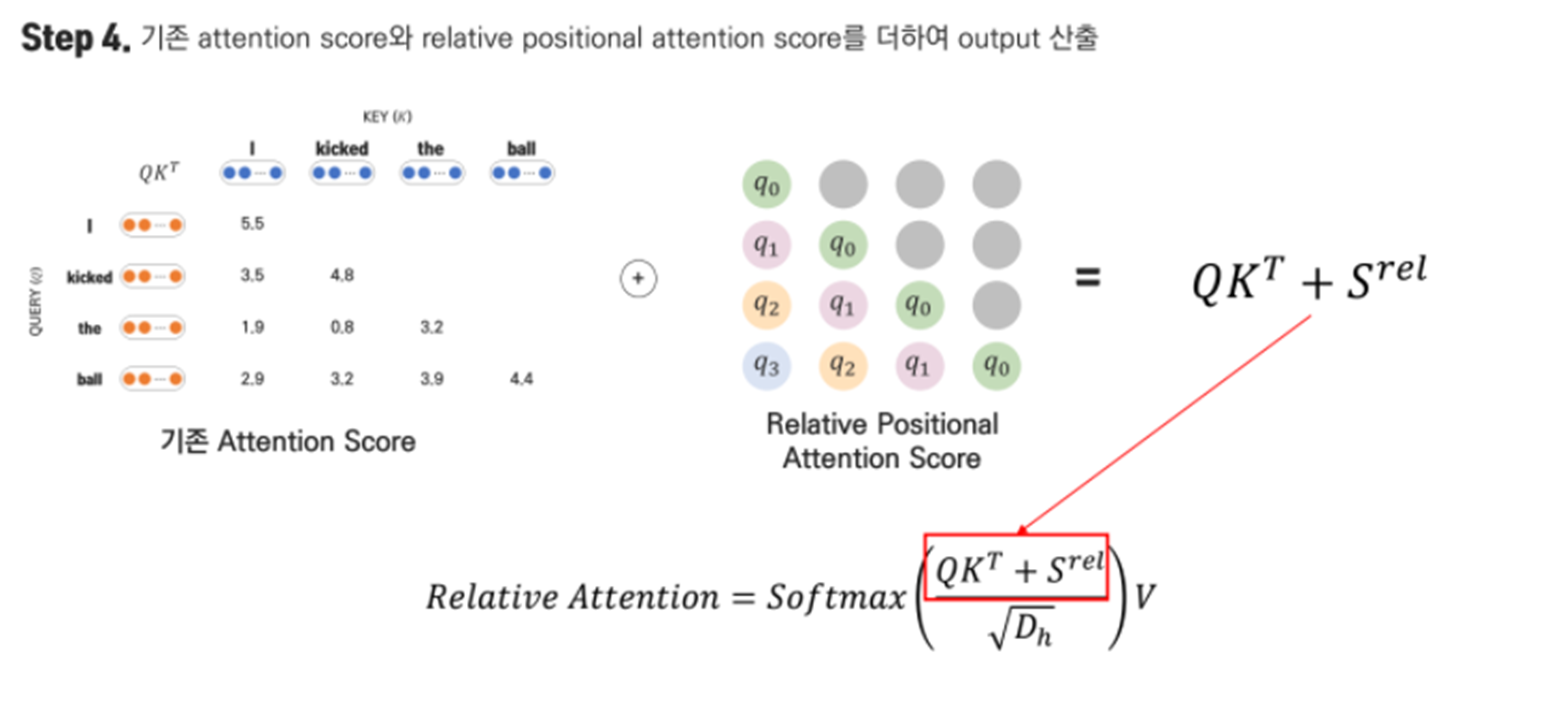
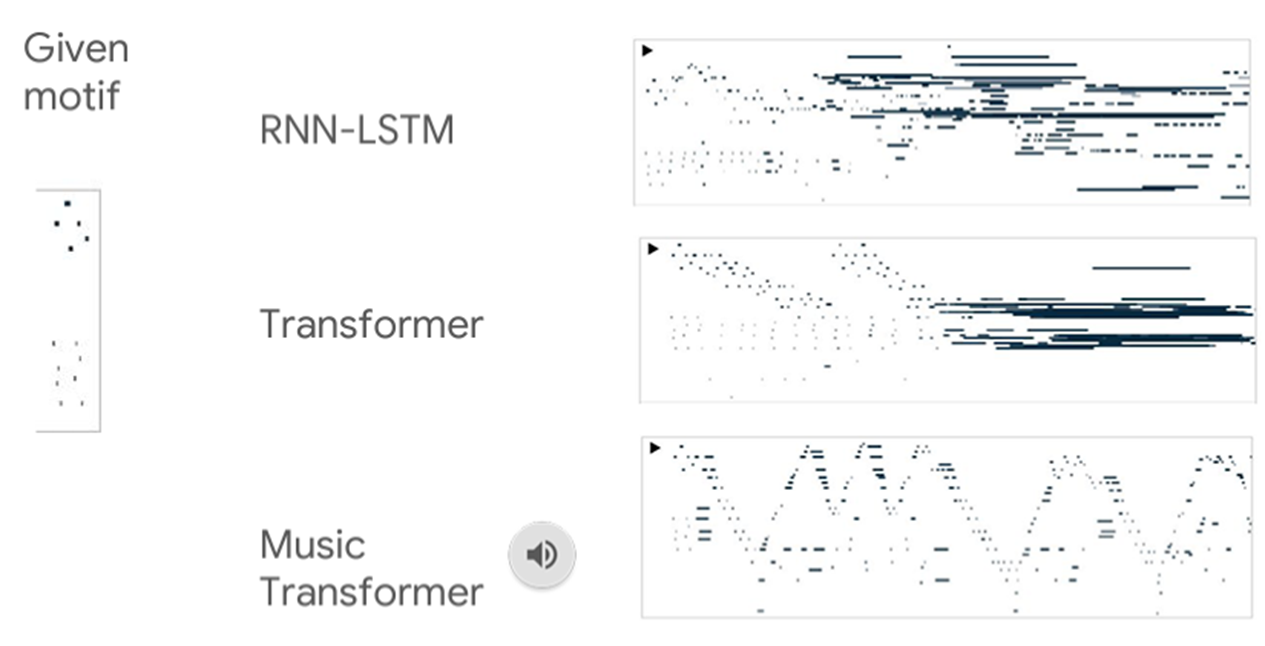
Experiment Results
Reference
https://blog.promedius.ai/transforme
https://m.blog.naver.com/sogangori/221035995877r/
https://wikidocs.net/31379
https://velog.io/@tobigs-text1415/Lecture-14-Transformer-and-Self-Attention
https://velog.io/@tobigs-text1314/CS224n-Lecture-14-Transformer-and-Self-Attention
고려대학교 산업경영공학과 DSBA 연구실 CS224n Winter 2019 세미나 중 14. Transformers and Self-Attention For Generative Models 강의자료와 강의 영상 (노영빈님)
CS224n: Natural Language Processing with Deep Learning in Stanford

2개의 댓글

16기 주지훈
Transformers and Self-Attention
-
Advantages
Trivail to parallelize so it can insert input sequence all at once
Solve out long-term dependency problem since it can catch long-term dependency regardless of the distance between words that are far away -
Self-Attention procedures
1) Dot product between Q,k
2) Scaling with 'd_k'
3) Appyling softmax function
4) Weighted sum with V -
Encoder Structure
1) Input - word2vec (word embedding)
2) Positional Encoding
3) Self-Attention (explained above)
4) Multi-Head Attention: learning 8 attention layers while setting different initial values
5) Residual connection + Layer Normalization
6) Point-Wise Feed-Forward Networks -
Attention in Decoder
1) Encoder-Decoder Attention
2) Decoder Self-Attention
16기 이승주
RNN
순차적 계산으로 인한 병렬화 불가능과 Long-term dependency problem이 존재한다.
CNN
병렬화 가능하고 Local dependency에는 강하지만, Long-term dependency를 표현하기 위해서는 많은 계층이 필요하다는 단점이 있다.
Self-Attention
병렬화 가능하고 각 token이 최단거리로 연결되어 long-term dependency 문제도 해결한다.
1) Q,K,V 벡터 얻기
2) Scaled dot-product Attention 수행
3) Head 통합하기
4) Fc layer 통과하기
Transformer
encoder와 decoder self-attention과 encoder-decoder attention의 구조를 지닌다. Transformer는 Language 뿐만 아니라 Image, Music 등의 분야에도 다양한 활용사례가 있다.