
작성자 : 투빅스 13기 정민준
Contents
- Constituency Parsing
- Simple TreeRNN
- Syntactically-United RNN
- Matrix-Vector RNN
- Recursive Neural Tensor Network
1.Constituency Parsing
문장을 이해하고 단어를 잘 표현하기 위하여 여러 임베딩, 파싱 기법들이 이전 강의에서 소개되었습니다. 이번 강의에서는 TreeRNN을 활용하여 문장을 구조적으로 나누어 분석하는 방법들에 대해서 소개하겠습니다.
먼저 Compositionality라는 용어를 살펴보겠습니다. 예를들어 10개의 단어를 통해 한 문장이 만들어 진다면 각 단어의 조합을 통해 새로운 의미를 나타내고 이 말인 즉슨 단어의 조합으로 부터 문장의 의미를 파악할 수 있다는 말으로 해석됩니다.

다음 그림을 통해 두 문장의 박스내 단어를 살펴보겠습니다. 'A person on a snowboard'의미와 'snowboarder'의 의미는 동일합니다. 이렇게 'A person on a snowboard'에서 다섯 단어의 조합으로 snowboarder를 표현할 수 있게 됩니다.
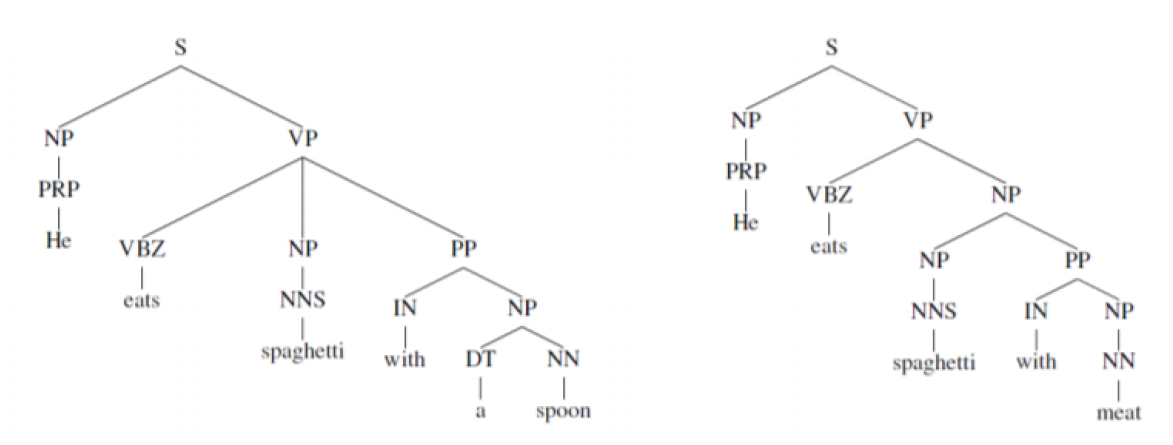
다음 그림과 같이 구조적으로 문장을 나누고 각 단어의 조합이 나타내는 의미를 찾아 문장 전체의 의미를 파악하는게 목표입니다. 어떻게 의미를 찾아나가는지 이어서 보겠습니다.
더 큰 구절은 어떻게 벡터 스페이스에 매핑시켜야 할까요? 'the country of my birth', 'the place where i was born'을 예를들어 보겠습니다.
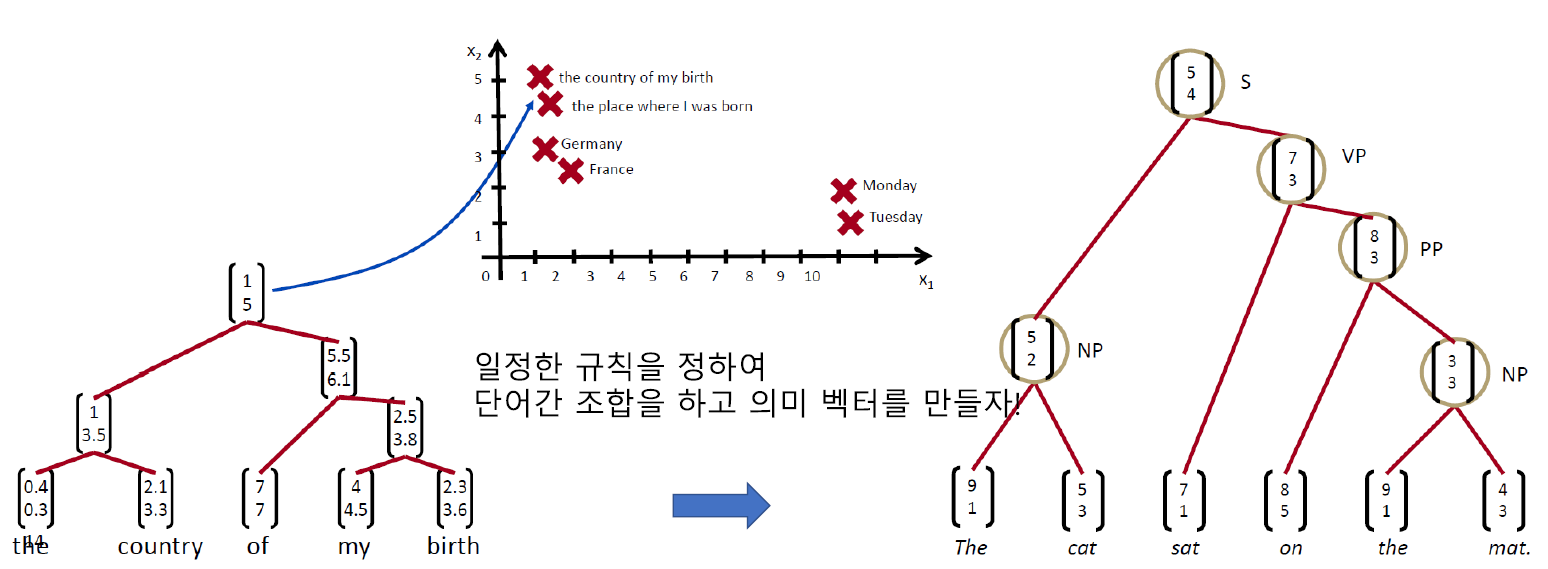
먼저 'the country of my birth' 문장에서 각 단어의 조합을 TreeRNN을 통해 추출한 값을 저장하고 일정한 규칙을 통하여 문장의 의미 벡터를 추출하게 됩니다. 다음 그림에서는 규칙에 의해 'the'와 'country', 'my'와 'birth'가 먼저 조합이 되었고 이후 'of'그리고 전체 의미 벡터를 얻게 됩니다.
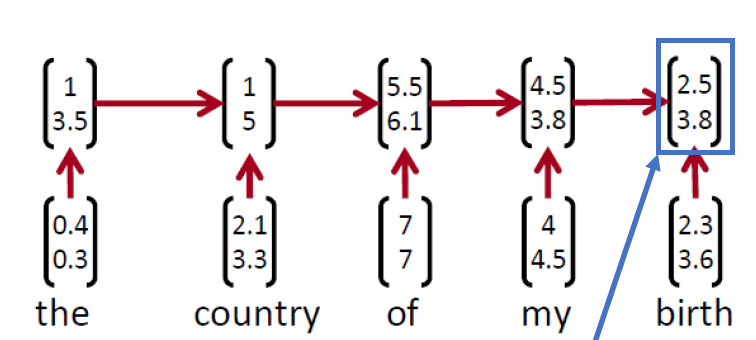
TreeRNN을 알아보기전에 RNN을 통해 문장을 분석하는 경우를 살펴보겠습니다. 다음과 같이 문장의 의미를 얻을 경우 인접 단어를 합친 단어의 의미는 충분히 반영하지 못합니다. 또한 마지막 단어 벡터를 주목하는 경향이 있기에 RNN보다 TreeRNN이 문장의 의미를 파악하는데 유용하다고 볼 수 있습니다.
2. Simple TreeRNN
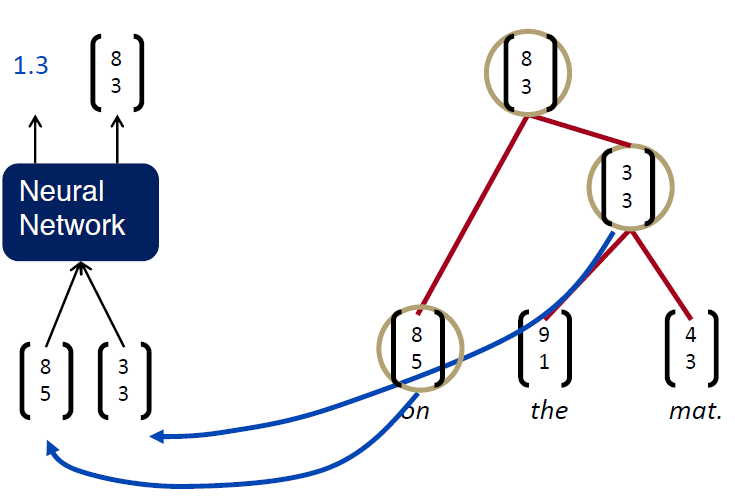
먼저 다음과 같이 'on the mat' 문장의 의미 벡터를 얻기 위해 'the'와 'mat'조합 단어 벡터를 계산 후 나머지 'on'와 조합하는 과정을 거쳤습니다.
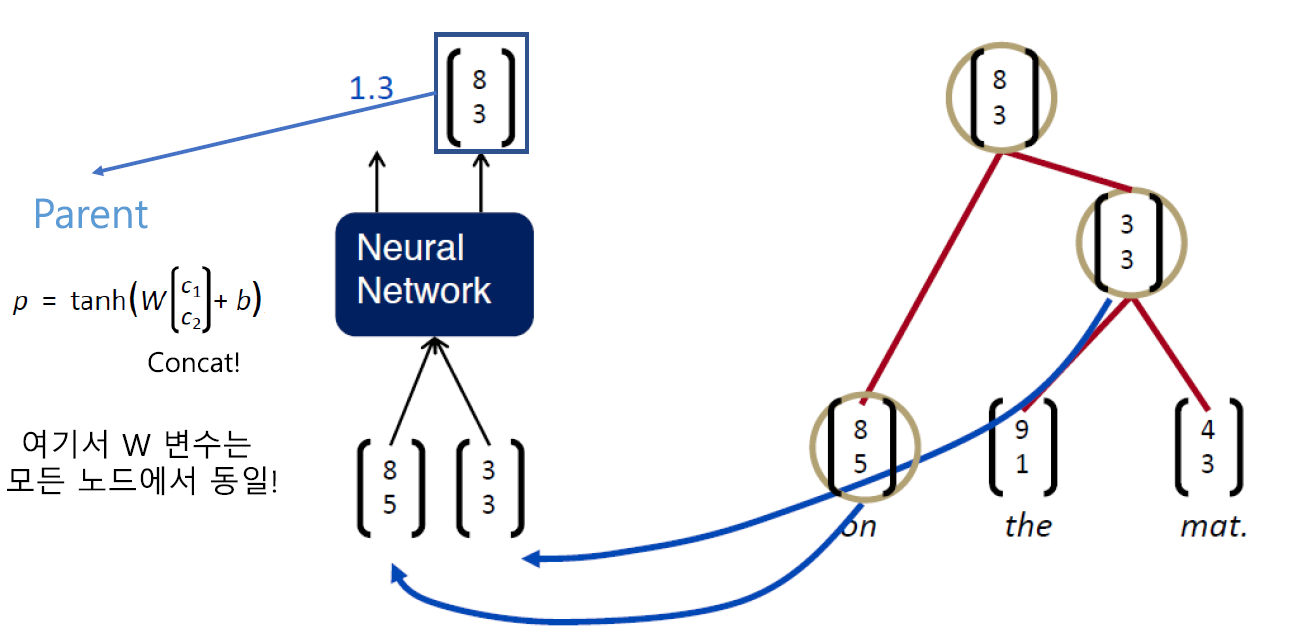
여기서 먼저 봐야할 벡터는 부모 벡터값입니다. 그림의 수식을 통해 벡터값을 계산하게 되며 여기서 사용하는 W 행렬은 모든 TreeRNN에서 동일합니다.
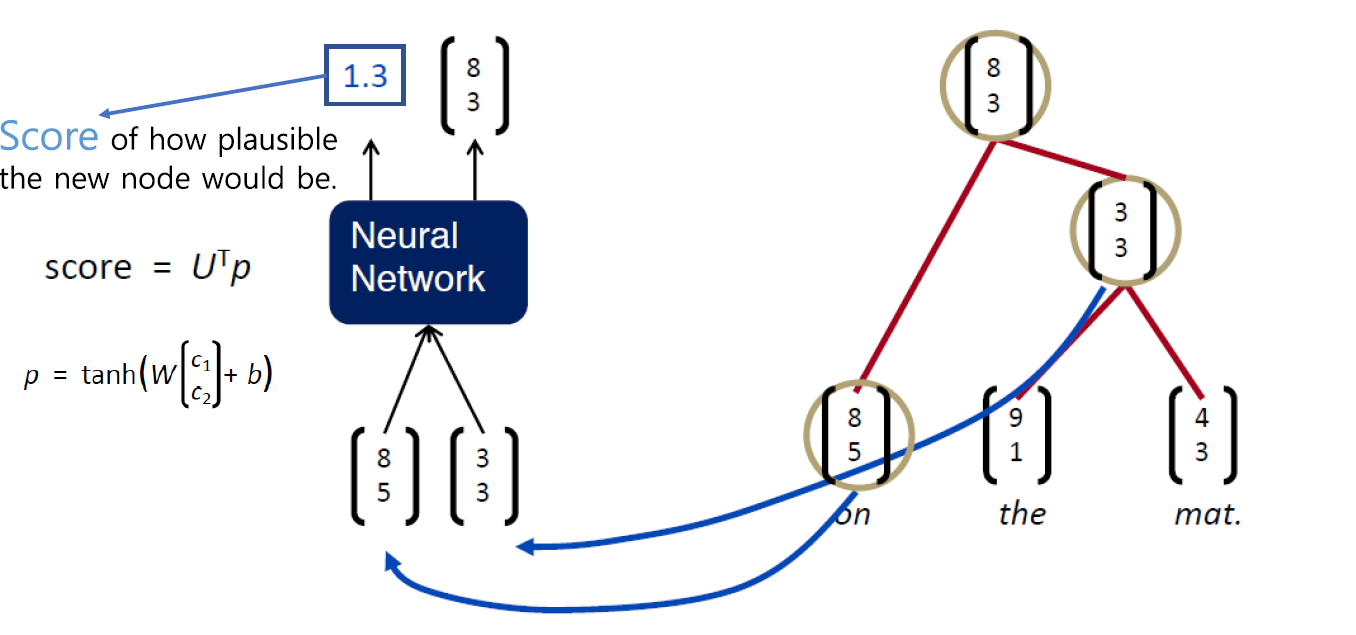
다음은 Score 입니다. Score은 조합할 단어를 선택할 때 반영되는 값입니다. 해당 단어가 얼마나 그럴듯 한지를 의미합니다. 이후 Score값을 통해 문장의 단어들을 조합해가는 과정을 통해 자세히 알아보겠습니다.
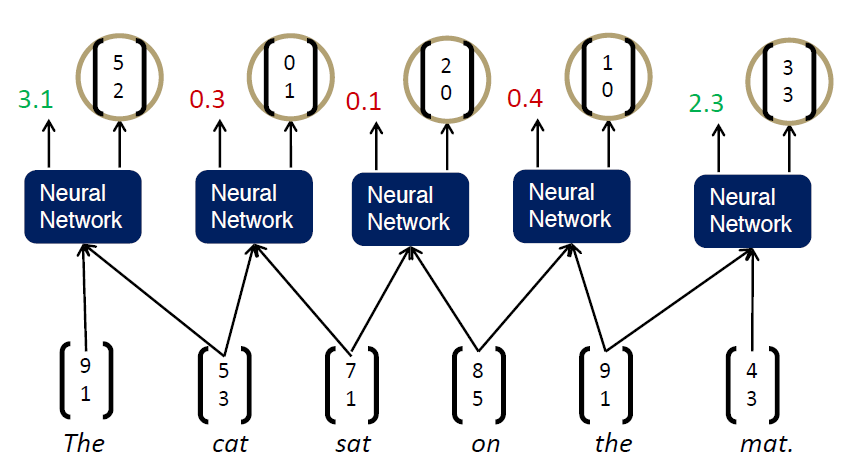
해당 단어들의 조합으로 부모 단어의 벡터와 Score값을 얻었습니다. 여기서는 Greedy 알고리즘을 통해 다음 단어를 조합하게 됩니다.
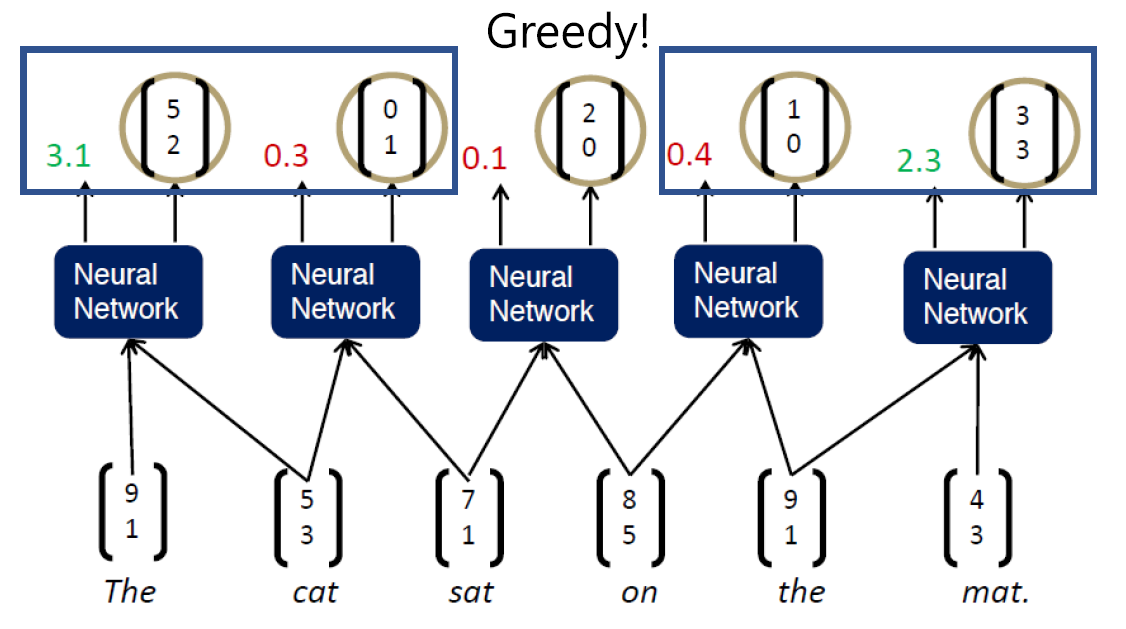
다음과 같이 Greedy하게 인접한 단어의 Score가 높은 조합으로 다음 부모 단어의 벡터와 Score값을 계산하게 됩니다. 이어서 다음 과정을 보겠습니다.
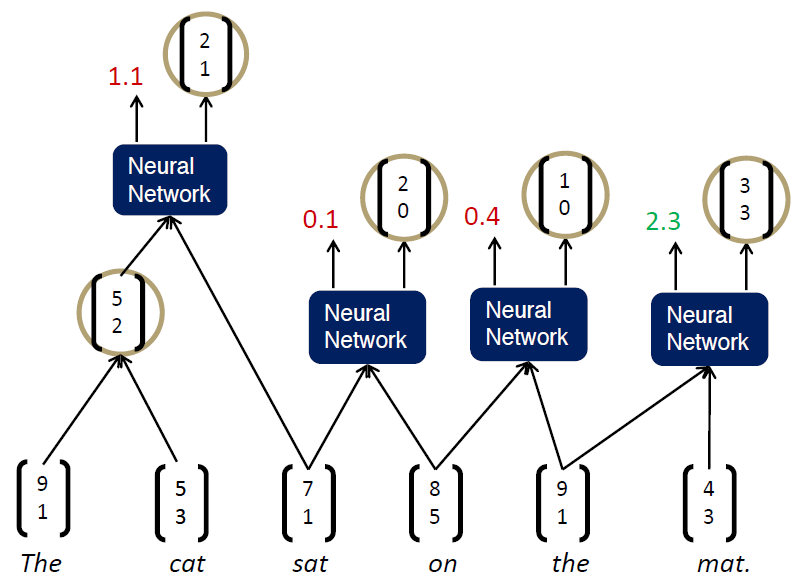
이전 선택된 단어의 조합으로 부모 단어의 벡터와 Score을 계산하였습니다. 이어서 오른쪽 부분도 계산하게 됩니다.
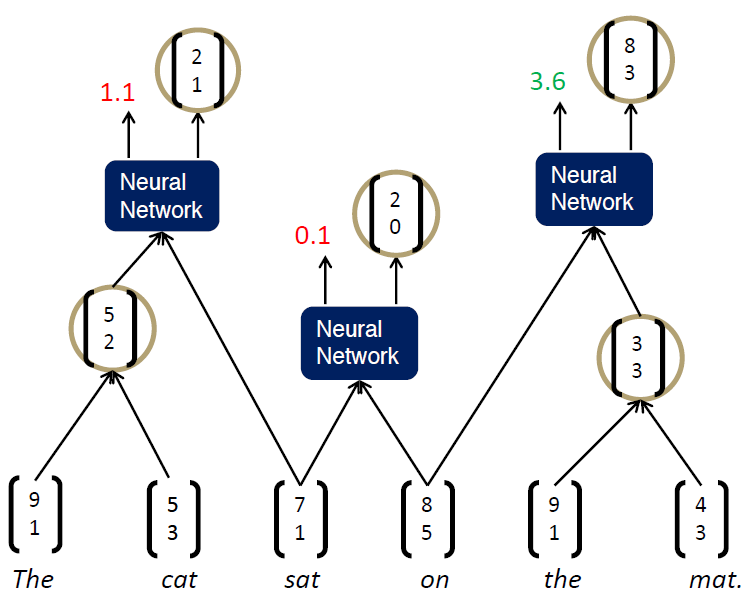
이렇게 계산되면 다음 연산은 어떻게 될까요? Score값이 0.1, 3.6인 단어 벡터의 조합으로 부모 단어의 벡터와 Score를 계산하고 좌측의 단어와의 조합을 통해 문장의 의미를 파악하게 됩니다. 여기서 Greedy하게 조합을 이어나간다고 설명했는데 여기서 쓰이는 Beam Search Algorithm을 간단히 알아보고 가겠습니다.
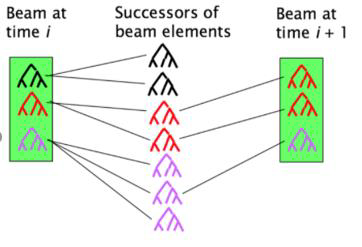
Beam Search Algorithm은 BFS 알고리즘에 탐욕법을 더한 알고리즘으로 볼 수 있습니다. BFS 알고리즘이 적용된다면 다음 단계로 가기위해서 넓이 우선적으로 탐색을 진행합니다. 그러면 해당 노드들과 이어진 모든 간선을 순차적으로 검사해야 합니다. 분명 비효율적인 면이 있으며 해당 속도로는 문장 분석을 시간내에 할 수 없을지도 모릅니다.

이때까지 Simple TreeRNN에 대해서 알아보았습니다. Simple TreeRNN은 다음과 같은 한계점을 보입니다.
3. Syntactically-United RNN
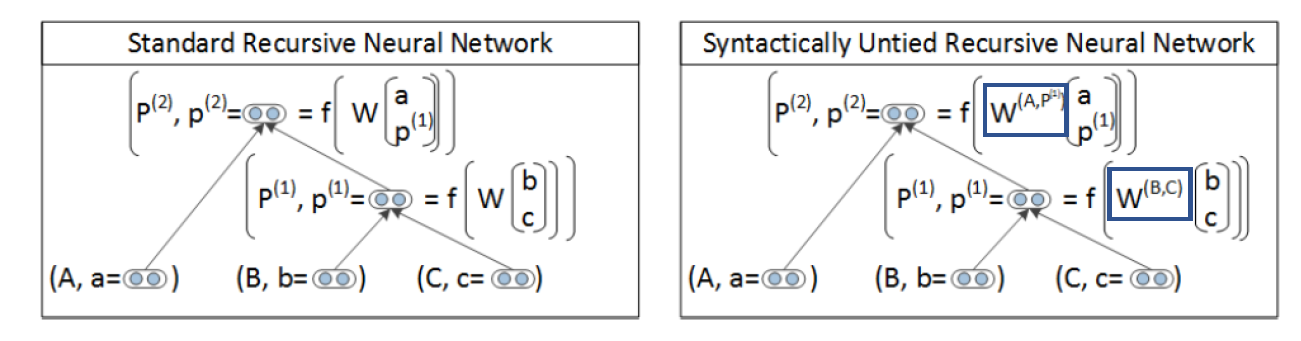
해당 모델은 Simple RNN의 한계점을 개선한 모델입니다. 모든 조합에 똑같이 사용되었던 행렬 W를 각기 다른 행렬로 설정합니다.
1. Probabilistic Context Free Grammar(PCFG)

각 규칙은 생성 확률을 가지고 있으며 해당 Non-terminal로 부터 생성하는 규칙들의 확률의 합은 1입니다. 다음 그림을 통해 더 자세히 보겠습니다.

이렇게 조합될 단어의 확률을 계산하고 TreeRNN에 적용한 모델이 Syntactically-United RNN 입니다.
4. Matrix-Vector RNN
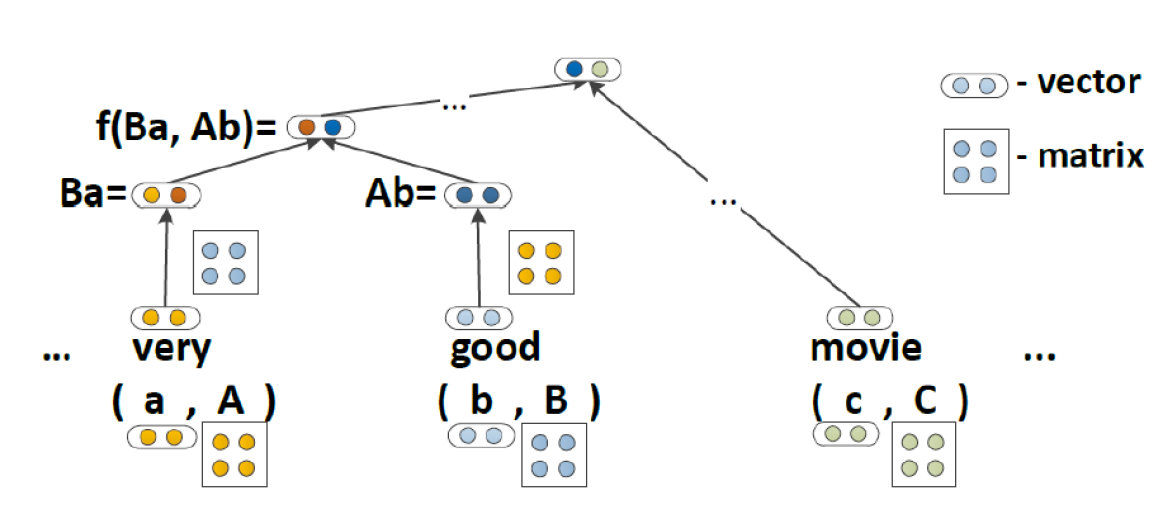
다음 모델은 이전 모델들과 다르게 단어들이 벡터정보만 가지고 있는게 아닌 행렬에 대한 정보까지 같이 가지고 있습니다. 해당 모델에서는 단어가 지니는 정보를 하나 더 가지게 함으로써 문장의 의미를 더욱 잘 파악할 수 있도록 합니다.
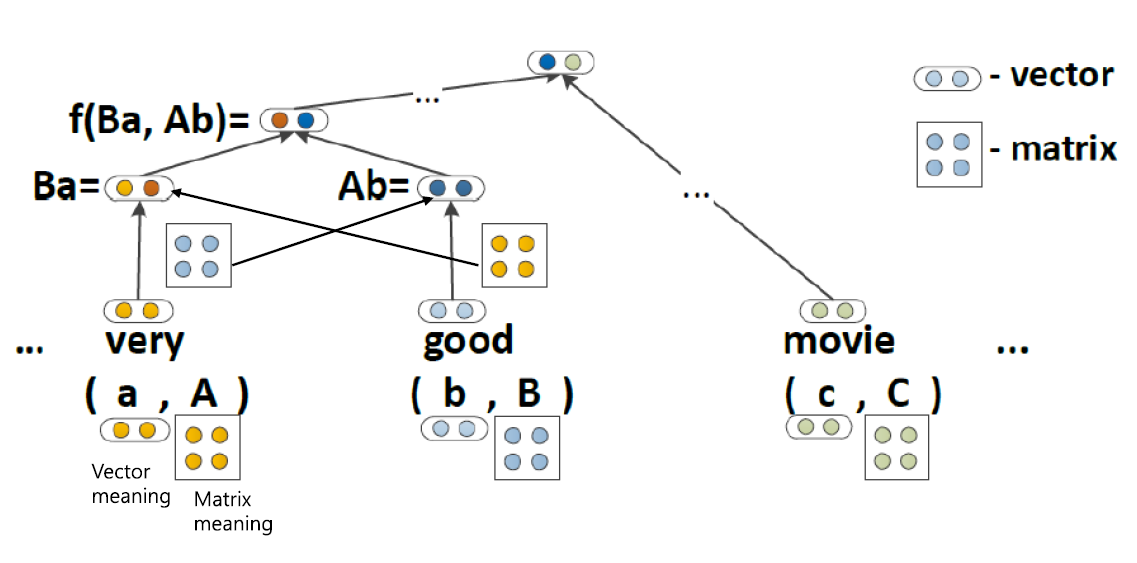
연산은 다음과 같이 'very'의 단어벡터와 'good'의 행렬 반대로 'good'의 단어벡터와 'very'의 행렬이 곱연산 되어 부모 노드로 전달됩니다.
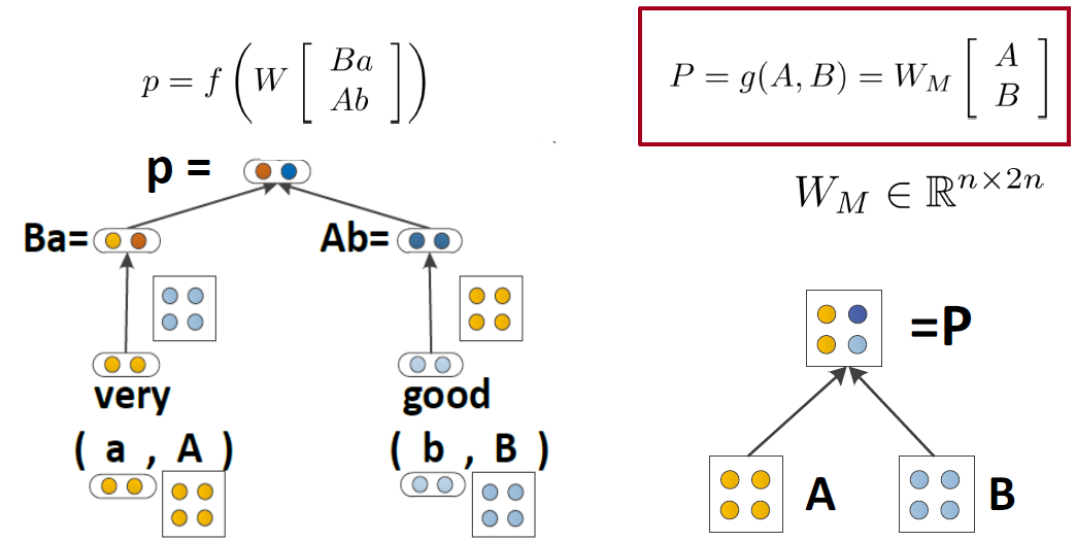
전달된 값은 다음과 같이 계산됩니다.
5. Recursive Neural Tensor Network

오래전부터 단어의 감정을 분석하는 태스크는 꾸준히 연구되어 왔습니다. 굳이 TreeRNN을 통해 단어, 문장을 분석하지 않고 Bag of Words를 통해서 임베딩하여 문장을 분석하여도 90%정도의 성능을 보인다고 합니다. 하지만 다음과 같은 경우는 모델이 단어의 감정을 분석하기 힘듭니다. 후회와 긍정은 부정을 의미하기에 이를 분석하기 위한 또 다른 무언가가 필요합니다.
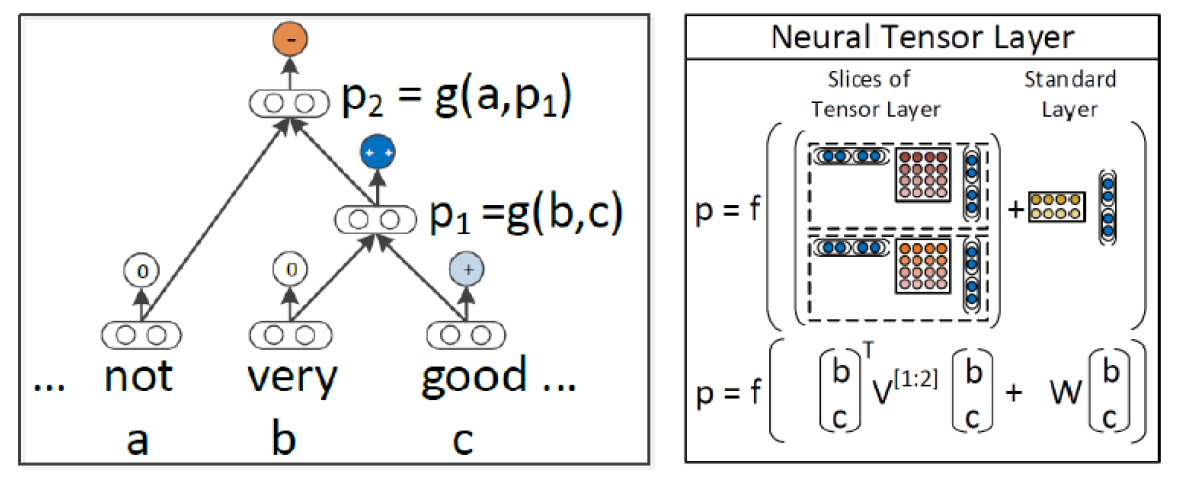
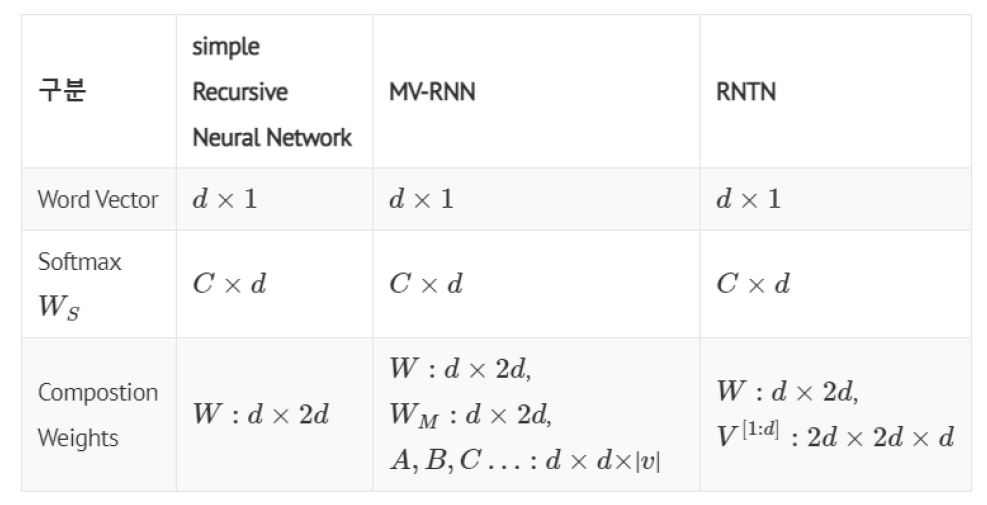
해당 모델은 MV-RNN보다 적은 파라미터를 가집니다. MV-RNN은 모든 결합에 대하여 각 노드마다 행렬을 생성하고 계속 연산을 진행해야 함으로 cost가 높아질 수 밖에 없습니다. 해당 모델에서는 파라미터수를 확연히 줄임으로써 MV-RNN보다 cost를 낮추었고 단어의 채널을 통해서 의미를 분석하는데 사용합니다.
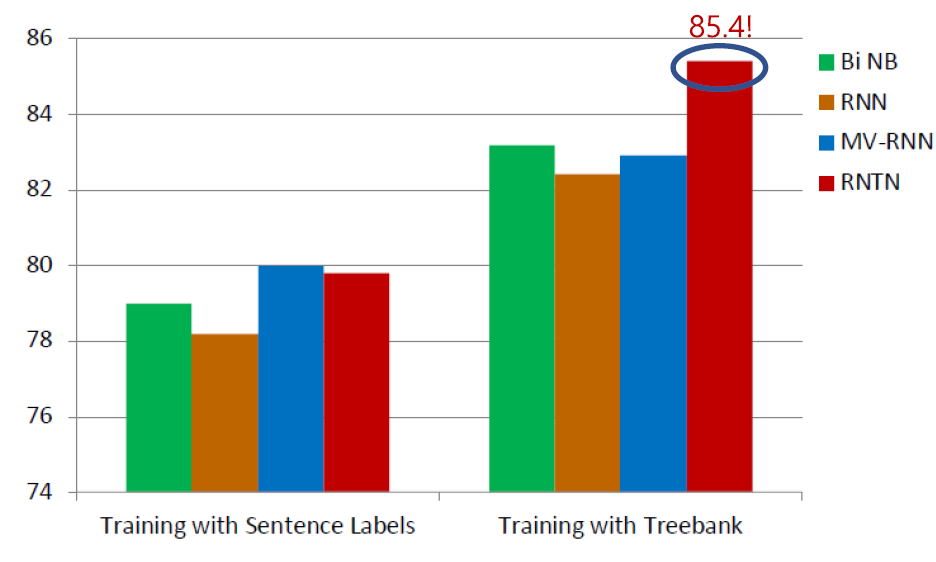
다음 긍/부정을 분석한 결과를 보겠습니다. RNTN이 다른 모델에 비해 높은 성능을 보입니다. 결과를 통해 또 다른 정보를 얻을 수 있었습니다.
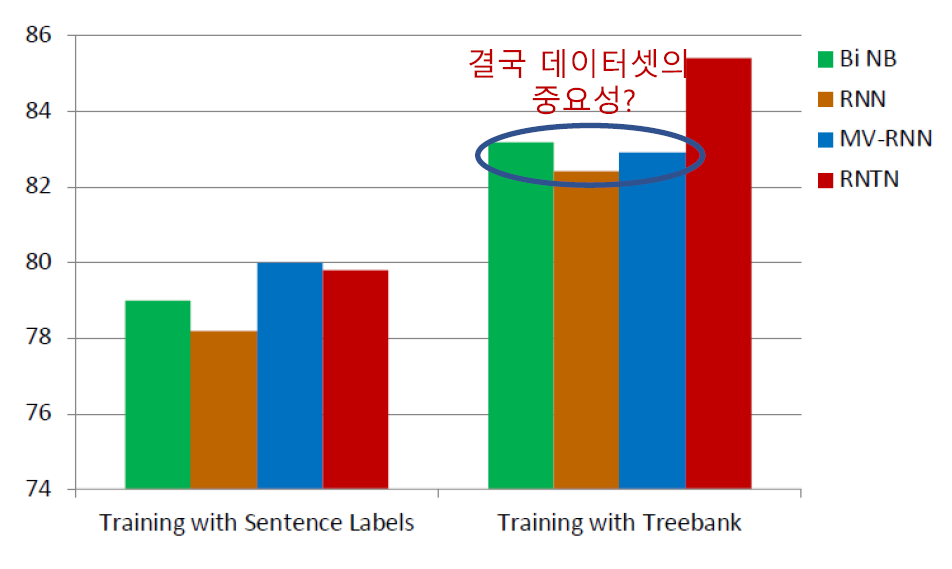
Treebank 데이터는 구조적 분석에서 각 단어에 모두 라벨링이 되어있습니다. 해당 데이터를 사용했더니 제일 간단한 Bi NB 모델의 성능이 RNN, MV-RNN보다 높음을 볼 수 있습니다. 이는 결국 데이터셋의 중요성을 보여주는 지표이기도 하다는 생각이 들었습니다.
결론
이전까지 TreeRNN에 관한 여러 모델을 살펴보았습니다. 현실적으로 TreeRNN은 사용하기 힘들다고 합니다. 이유는 GPU 연산이 힘듭니다. 병렬적으로 연산이 진행되어야 하는데 모든 task 마다 연산 구조가 동일하지 않고 Tree 모양이 다르기 때문이라 합니다. 또한 데이터에 라벨링을 모두 거쳐야 하는데 이 데이터를 구축하는데에 어려움이 있습니다.
References


TreeRNN은 실제로 활용하기 어렵다고 합니다. GPU 계산의 어려움이 원인입니다. super mario bros