
작성자: 16기 이승주
Contents
1. Starting Research
2. Review of Gated Neural Sequence Models
3. MT Topics
4. Research Evaluation, others
5. References
Final projects
SQuAD question answering이 기본 final project이고 자유 주제도 가능하며 1 ~ 3명의 인원으로 진행하는 프로젝트이다. 언어나 프레임워크의 제한은 없다고 한다.
1. Starting Research
SQuAD란?
- 스탠포드 대학의 NLP 그룹에서 크라우드 소싱을 통해 만든 위키피디아 아티클에 대한 107,785개의 질문-대답 데이터셋
- 기계 독해 기술은 사람이 맥락을 이해하고 논리적으로 답을 찾는 것처럼 질의에 대한 답을 찾는 기술
- 지문(Context)-질문(Question)- 답변(Answer)으로 이루어진 데이터셋 형태
- 질문의 답변 여부에 따라 정답이 있는 데이터셋 70만 건과 정답이 없는 데이터셋 30만 건으로 구성
- 정답이 없는 데이터셋은 질문에 대한 답이 지문에 없을 경우 기계 독해 모델이 정답이 없음을 판단할 수 있도록 학습하기 위해 사용된다.
- 정답이 있는 데이터셋과 동일하게 지문-질문-답변의 형태이지만, 답변은 질문의 의도에 대응하는 정답처럼 보이지만 의미적으로 틀린 대답(plausible answer)을 채택하고 있다.

NLP 연구 예시
- 모델의 application을 찾아보고 어떻게 효율적으로 적용할 지 찾는 연구
- 복잡한 neural architecture을 구현해보고 특정 데이터에 대한 성능을 평가하는 연구
- 새롭거나 변형된 NN 모델을 구상 후 구현하여 성능 향상을 보여주는 연구
- 새로운 연구
- 모델의 동작법을 분석하는 연구
-
모델의 application을 찾아보고 어떻게 효율적으로 적용할 지 찾는 연구
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1174/reports/2762063.pdf

-
복잡한 neural architecture을 구현해보고 일부 데이터에 대한 성능을 평가하는 연구
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1174/reports/2753780.pdf

-
새롭거나 변형된 NN 모델을 구상 후 구현하여 성능 향상을 보여주는 연구
https://cs224d.stanford.edu/reports/InanKhosravi.pdf

-
새로운 연구
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/reports/997.pdf

연구는 어디서부터 시작하나?
- 논문을 열심히 읽는다.
- NLP논문에 대한 ACL Anthology 참조
- 주요 ML 컨퍼런스들의 논문들을 참조(NeurIPS, ICML, ICLR...)
- 기존 프로젝트 참조
- 출판 전 논문 본다. (http://arxiv.org)
NLP 연구에서 가장 중요한 것 : 데이터
적절한 데이터를 찾는것이 중요하다. ( 최소 10,000개의 레이블된 데이터)
- 기존의 프로젝트에서 구한 데이터 / 기업에서 갖고 있는 데이터
- 실행가능한, 적절한 Task를 찾는것도 중요하다.
- 공개되고, 잘 관리된 dataset 활용하기
Task를 찾으면 이를 평가할 수 있는 자동화된 metric도 있어야함
데이터 찾기

http://catalog.ldc.upenn.edu/
https://linguistics.stanford.edu/resources/resources-corpora

http://statmt.org
https://universaldependencies.org
온라인에는 더 많은 데이터 셋들이 존재한다.
- 캐글
- 기존 연구 논문에 있는 데이터
- NLP 데이터셋을 모아둔 곳
https://machinelearningmastery.com/datasets-natural-language-processing/
https://github.com/niderhoff/nlp-datasets
2. Review of gated neural sequence models
Gated Recurrent Units
- 직관적으로 RNN을 이해하고 사용하자
- vanishing gradient 문제는 큰 문제이다. gradient가 0이 되면 문제가 명확해지지 않는다.
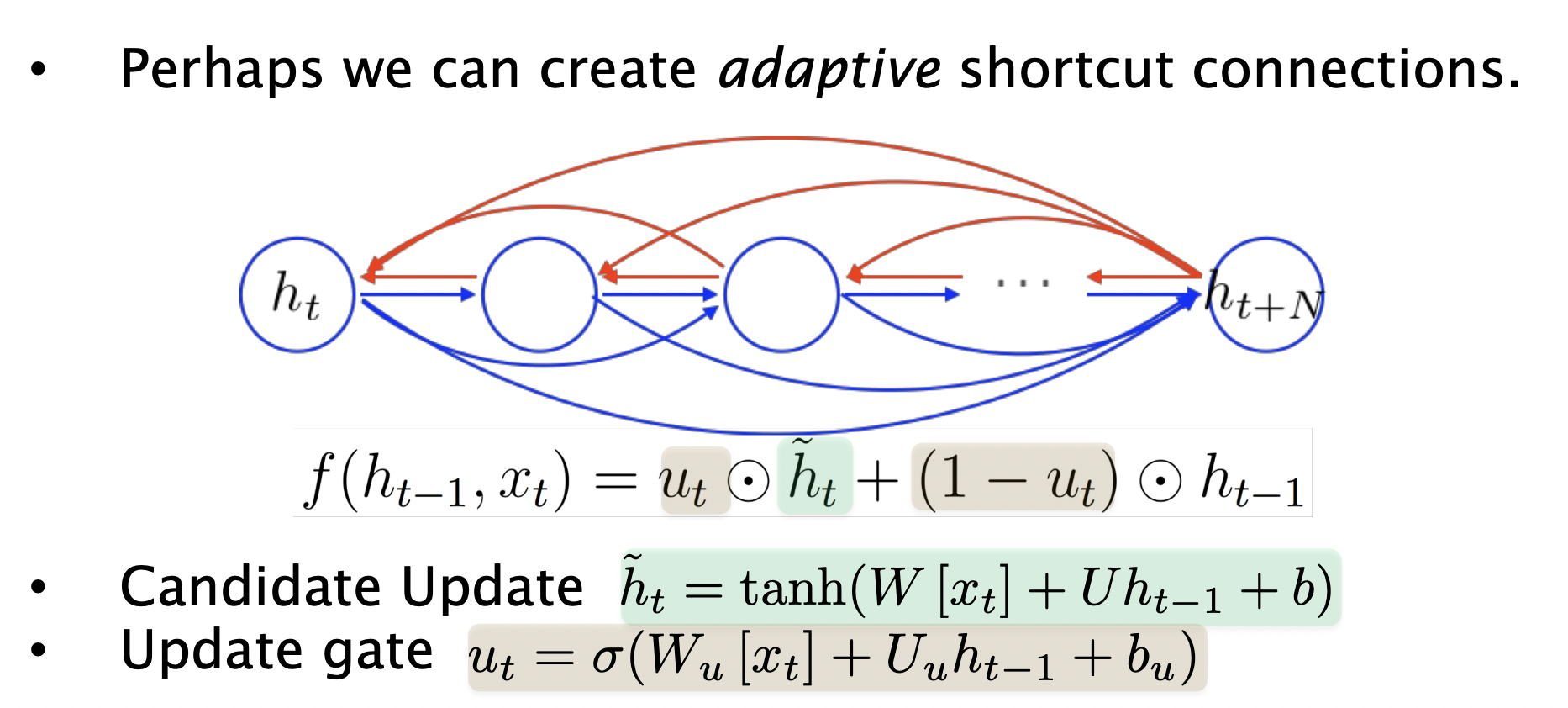
No dependency between t and t+n ? 아니면 Wrong configuration of parameters?
backprop은 잘 안될수도 있기 때문에 shortcut connection을 만들거나 adaptive shortcut connection도 만들 수 있다.
3. A couple of MT topics
MT Evaluation
- 수동
Adaquacy and fluency
오류 분석
번역 순위 메기기- 자동
BLEU(bilingual evaluation understudy)
BLEU
BLEU score란 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 성과지표이다. 데이터의 X가 순서정보를 가진 단어들로 이루어져 있고, y또한 단어들의 시리즈(문장)로 이루어진 경우에 사용되며 3가지 요소는 아래와 같다.
- n-gram을 통한 순서쌍들이 얼마나 겹치는지 측정
- 문장길이에 대한 과적합 보정
- 같은 단어가 연속적으로 나올때 과적합 되는 것을 보정
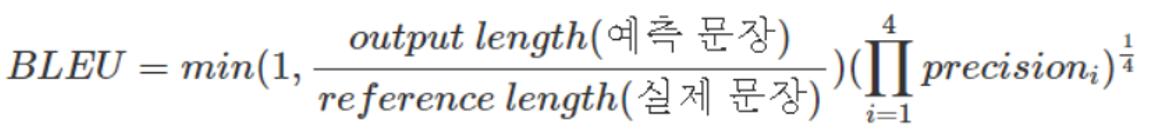
보통 Blue4를 활용하는데 n-gram 길이가 4까지 계산한다.
4단어 미만 문장은 bleu 0점.
아래 예시의 bleu score를 계산하면 다음과 같다.



4. Research Evaluation, etc.
연구는 어떻게?
- Define Task
- Define Dataset (Summarization이라는 task을 정하자)
- Dataset hygiene (Dataset을 정하자)
- Define your metric (평가 metric을 정하자)
- Establish a baseline (Baseline을 정하자)
- Implement existing neural net model
- Always be close to your data
visualize the dataset
collect summary datset
look at erros
analyze how different hyperparameters affect performance- Try out different models and model variants Aim to iterate quickly via having a good experimental setup (다른 시도도 많이 하자)
데이터셋은?
- Many publicly available datasets are released with a train/dev/test structure. We're all on the honor system to do test-set runs only when development is complete.
: (보통 데이터셋은 Train/dev/test 데이터셋이 있다. 연구자 윤리를 위해서 개발이 끝난 후에만 test set을 사용하자.)- Splits like this presuppose a fairly large dataset.
: (이렇게 분리하면 데이터셋이 꽤 크다)- If there is no dev set or you want a separate tune set, then you create one by splitting the training data, though you have to weigh its size/usefulness against the reduction in train-set size. Having a fixed test set ensures that all systems are assessed against the same gold data. This is generally good, but it is problematic where the test set turns out to have unusual properties that distort progress on the task.
: (만약 데이터 셋이 없으면 알아서 분리해라. 이렇게 데이터 셋을 분리하면 모든 사람들이 같은 데이터를 가지고 평가를 진행해서 좋지만 만약 하나의 데이터셋에만 이상값들이 많이 존재하면 문제가 생길 수 있다.)- You build (estimate/train) a model on a training set.
: (Training set에서 트레이닝을 진행한다.)- Often, you then set further hyperparameters on another,independent set of data, the tuning set
The tuning set is the training set for the hyperparameters!
: (Tuning set에서 하이퍼파라미터 튜닝을 한다.)- You measure progress as you go on a dev set (development test set or validation set)
If you do that a lot you overfit to the dev set so it can be good to have a second dev set, the dev2 set
: (Dev set에서 트레이닝이 잘되었는지 확인한다. 단 dev set을 많이 쓰면 오버피팅이 있을 수 있다.)- Only at the end, you evaluate and present final numbers on a test set
: (마지막에만 test set을 쓴다. 한두번만 쓰는게 좋다고 한다.)
Use the final test set extremely few times … ideally only once
: (모든 데이터 셋들은 독립적이어야 한다.)
RNN 학습할때
- Use an LSTM or GRU: it makes your life so much simpler!
(LSTM 또는 GRU를 사용하자)- Initialize recurrent matrices to be orthogonal (recurrent matrices을 직교하게 초기화하자)
- Initialize other matrices with a sensible (small!) scale (다른 행렬들을 small scale로 초기화하자)
- Initialize forget gate bias to 1: default to remembering (forget gate bias 를 1로 두자.)
- Use adaptive learning rate algorithms: Adam, AdaDelta, …
- Clip the norm of the gradient: 1–5 seems to be a reasonable threshold when used together with Adam or AdaDelta.(1부터 5가 적당한 threshold이다.)
- Either only dropout vertically or look into using Bayesian Dropout (Gal and Gahramani – not natively in PyTorch) (dropout을 vertical하게 사용하거나, Bayesian Dropout을 사용하자)
- Be patient! Optimization takes time (학습은 인내심을 갖고 기다리자)
Experimental strategy (연구방법론)
- Work incrementally! (점진적으로 한단계씩 연구를 진행하는게 좋다.)
- Start with a very simple model and get it to work (처음에는 아주 간단한 모델에서 부터 시작하자)
- Add bells and whistles one-by-one and get the model working with each of them (or abandon them) (그 다음에 간단한 모델에 점차 많은 것들을 추가하며 학습하자.)
- Initially run on a tiny amount of data (처음엔 아주 작은 데이터 셋으로 학습해보자)
You will see bugs much more easily on a tiny dataset
Something like 8 examples is good
Often synthetic data is useful for this (인위적으로 제작한 데이터도 좋다.)
Make sure you can get 100% on this data
Otherwise your model is definitely either not powerful enough or it is broken- Run your model on a large dataset (데이터 셋의 크기를 점차 키우자.)
- It should still score close to 100% on the training data after optimization (데이터 셋을 키우고 100프로에 가까운 정확도가 나와야한다)
Otherwise, you probably want to consider a more powerful model (만약 100프로 정확도 달성이 안되면 모델을 바꿔봐라)
Overfitting to training data is not something to be scared of when doing deep learning (딥러닝에서는 training set의 오버피팅은 괜찮다.)
These models are usually good at generalizing because of the way distributed representations share statistical strength regardless of overfitting to training data- But, still, you now want good generalization performance:
Regularize your model until it doesn’t overfit on dev data
Strategies like L2 regularization can be useful
But normally generous dropout is the secret to success
Details matter!
- Look at your data, collect summary statistics
- Look at your model’s outputs, do error analysis (모델의 출력값을 보고 오류 분석을 진행하자)
- Tuning hyperparameters is really important to almost all of the successes of NNets (하이퍼 파라미터 튜닝은 성공적인 NNets 모델에 아주 중요한 요소 중 하나이다.)
5. References

3개의 댓글

16기 주지훈
NLP 연구의 예시와 실제 연구를 어떻게 해야 하는지 자세하게 설명해주셔서 앞으로 연구를 할 때 많이 참고할 것 같습니다! 그리고 연구를 할 때 정해야 하는 것(데이터셋, 평가 metric, task 등), 데이터셋을 어떻게 가공하는지, RNN 학습 시 팁 등 실제 연구할 때 도움이 될만한 부분들에 대해 알기 쉽게 정리해주셔서 앞으로 많은 도움이 될 것 같습니다. 감사합니다!
NLP 뿐만 아니라 다양한 분야의 연구에 필요한 조건 및 방법론에 대해 알아 볼 수 있었습니다. 데이터 셋의 구성방법과 다루는 법, 연구 방향을 찾는 법, 그 연구 속에서 필요한 matrix들을 알 수 있었습니다. 본 강의 시간에 배운내용을 토대로 앞으로 연구시에 참고해야할 점들이 많음을 알았습니다. 연구방법론들을 보며 방향성을 찾을 수 있을거 같습니다
15기 김현지
이번 세션에서는 전반적인 NLP 연구 방법론에 대해 설명해주셨습니다. NLP 연구의 예시와 데이터 셋, 평가방법 소개와 데이터 셋 및 논문 리서치를 위한 다양한 참고 링크들을 첨부해주셔서 나중 NLP 연구를 할 때 많은 도움이 될 거 같습니다😇 특히 연구가 어떻게 진행되어야 하는지, 그리고 데이터 셋은 어떻게 다루어야 하는지 그리고 연구 방법론에 대해 구체적으로 가이드라인을 잘 정리해주셔서 NLP 연구 방법론에 대해 아주 잘 이해할 수 있었습니다. 좋은 자료와 발표 감사드립니다!