본 lecture에서는 다음과 같은 순서로 강의가 진행됩니다.
- machine translation
- Seq2Seq
- Attention
Machine Translation

Machine translation은 기계번역으로 위 그림처럼 입력으로 들어온 source(x)문장을 target 문장(y)로 번역하는 task를 model이 수행하는것입니다. Input 문장의 언어인 프랑스어를 output 문장의 언어인 영어로 번역을 하는것이고 기계번역에서는 이것을 source와 target으로 지칭합니다.
Machine translation의 역사를 보면 1950년대에서 처음으로 기계번역의 연구가 시작되었습니다. 이때 기계번역은 군사목적을 위해서 연구가 시작되었으며, 동일한 뜻을 가진 단어를 target의 언어로 대체하는 단순한 방식을 이용했습니다.
Statistical Machine Translation
1990년대부터 2010년대까지는 통계를 기반으로 확률 model을 사용하기 시작했습니다. 입력 문장 x가 주어졌을 때 이에대한 조건부확률을 최대화하는 번역 문장인 y를 찾는 형태인데 이를 bayes rule를 이용하여 translation model과 language model로 분리합니다.
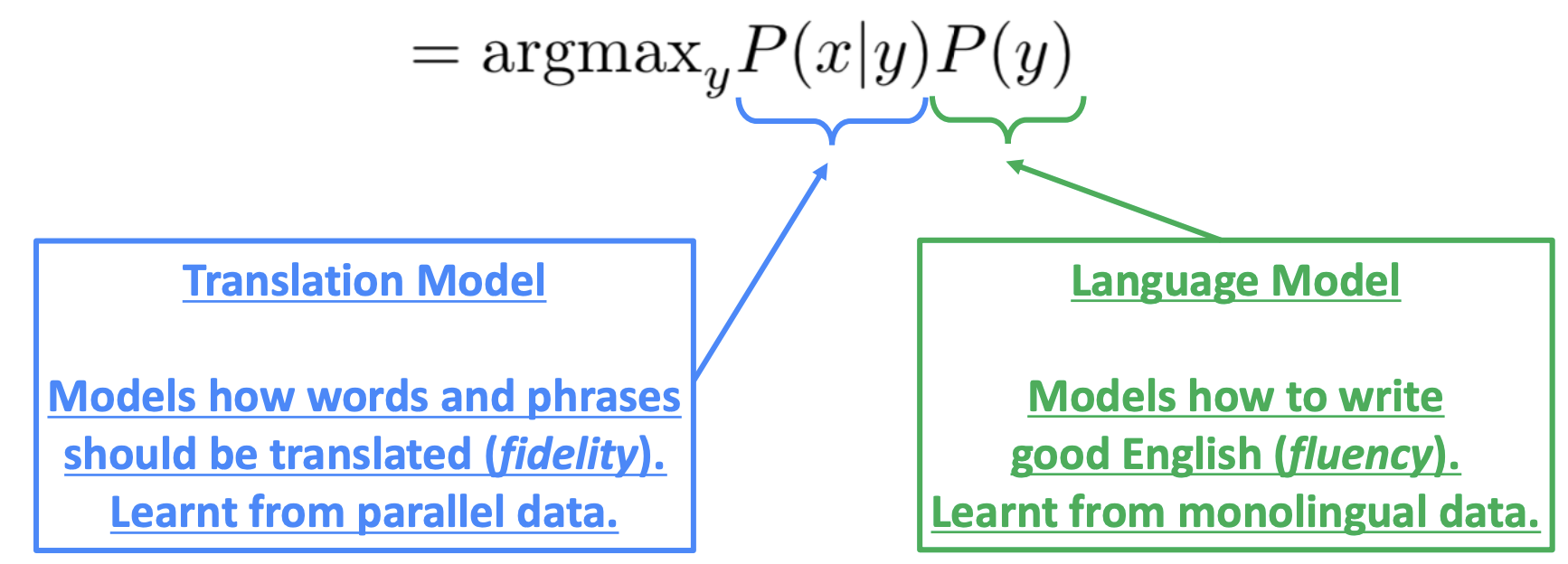
이때 각 model의 역할을 보면, translation model은 각 단어와 구가 어떻게 번역이 되어야할지를 병렬 데이터로부터 학습을하고 language model은 가장 적합한 문장을 생성하도록 단일 언어로부터 학습됩니다.
기본적으로 통계기반의 번역 모델은 많은 양의 학습 데이터를 필요로합니다. 또한 SMT model은 source와 target 단어 단위로 mapping할때 단어의 배열 정보를 담을 수 있는 alignment를 사용합니다.
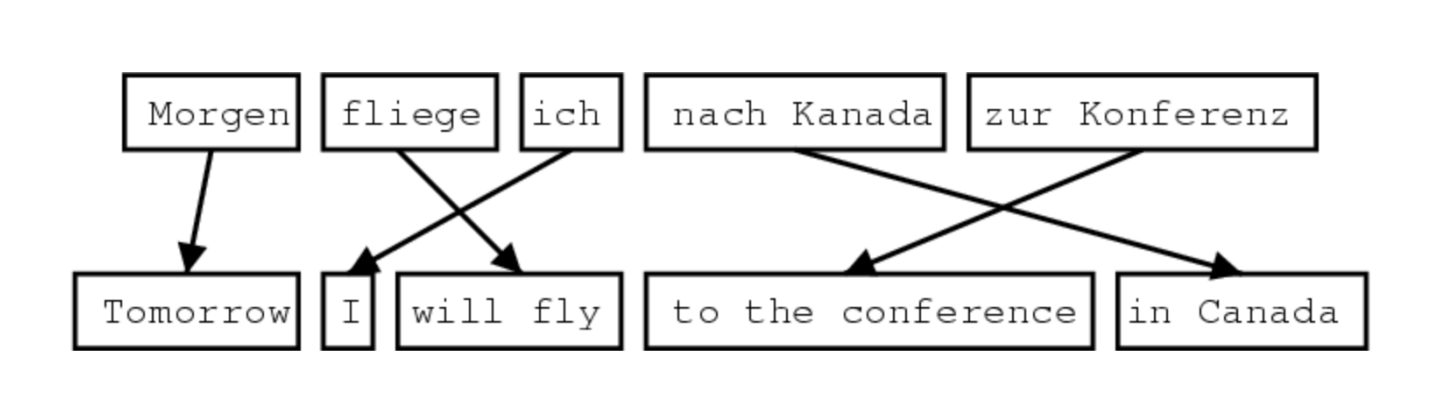
그러나 1:1로 mapping 되는 경우는 거의 존재하지 않는다. 다음과 같은 경우로 인해 SMT의 성능이 많이 떨어질 수 있습니다.
- No counterpart
- Many-to-one
- One-to-Many
- Many to Many
학습한 translation model과 language model을 통해 번역문을 생성하는 과정을 decoding이라고 합니다. Decoding에도 여러 방법이 존재하는데, 가능한 모든 번역문의 확률을 비교하는것은 많은 계산량을 요구하기 때문에 여러 독립적인 가정을 모델에 부여하고 dynamic programming을 통해 최적의 번역문을 찾는 방법을 주로 사용했습니다.
SMT에는 여러 한계점이 존재합니다.
- 모델이 많이 복잡함
- Feature Engineering을 필요로 함
- 추가적인 resource가 필요함(동등한 phrase)
- 사람이 노력이 많이 필요함(병렬 데이터셋)
Neural Machine Translation
이러한 한계점을 극복한 NMT가 등장했습니다. NMT는 다음과 같은 특징을 가지고 있습니다.
- Subcomponent가 따로 필요하지 않은 single end-to-end neural network로 구성
- 2개의 RNN으로 구성된 seq2seq모델
Seq2Seq model
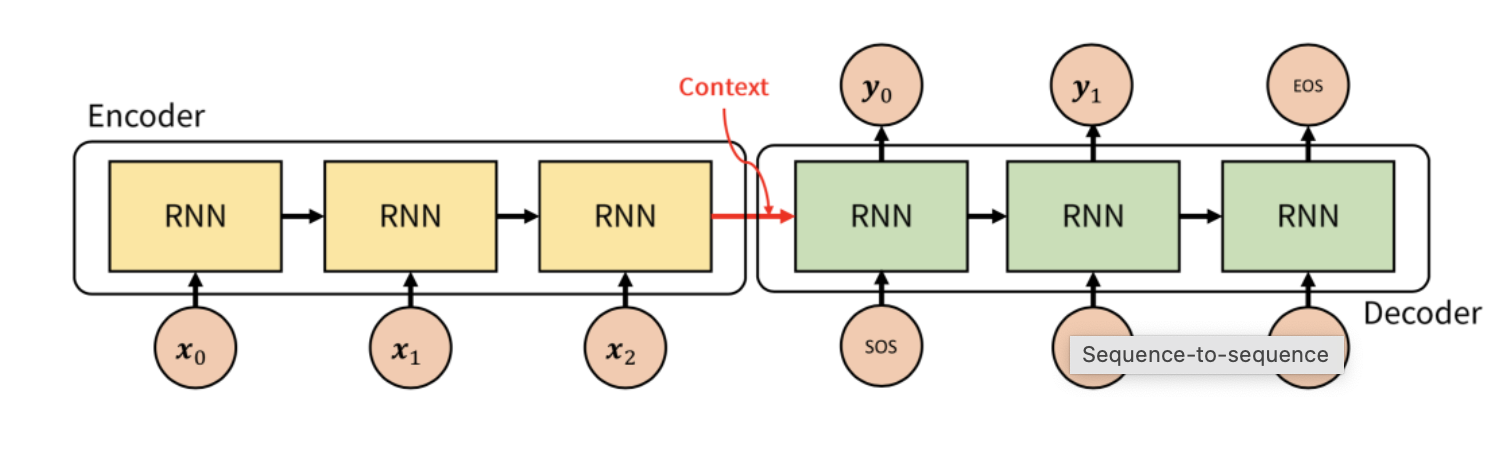
Seq2Seq model은 위 그림과 같이 encoder와 decoder로 구성되어 있습니다. Encoder는 입력된 source text를 encoding하고 decoder는 encoding을 condition으로 target text를 생성하는 역할을 합니다. 그리고 encoder의 마지막 cell의 output이 decoder의 첫번째 cell의 hidden state로 사용되는데 이를 context vector라고 부릅니다. Decoder는 train과 test할때 조금 다르게 작동하는데 먼저 train과정에서는 encoder의 마지막 cell로부터 받은 context vector와 실제 정답인 target sentence가 출력된다고 알려주면서 훈련합니다. Test시에는 decoder RNN의 timestep 별 output이 다음 timestep의 input으로 사용됩니다.
Seq2seq model은 machine translation뿐만 아니라 text를 입력받고 text를 출력하는 summarization, dialogue, parsing, code generation,등 여러 task에서도 많이 사용된다.
SMT에서는 bayes rule을 통해 translation model과 language model을 분리한것과는 다르게 NMT에서는 conditional probability를 직접 계산합니다.
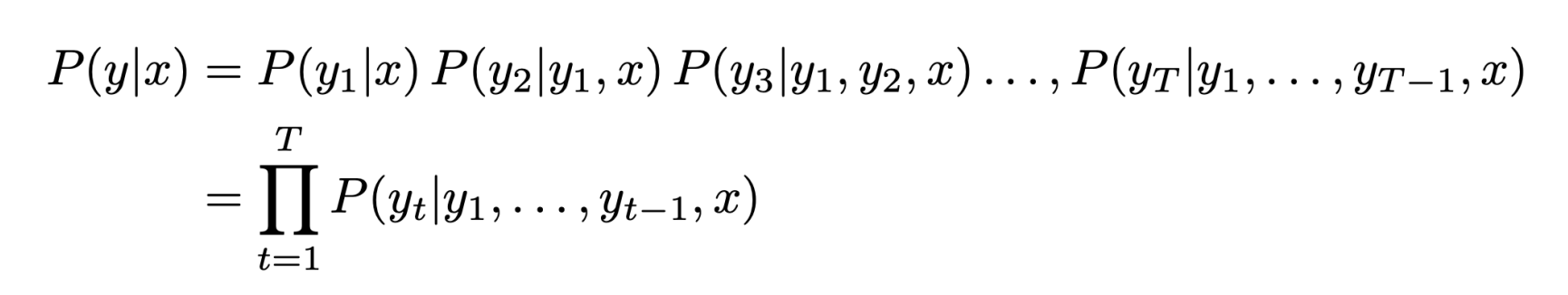
End-to-End 학습이 가능하지만 계산량이 너무 크고 여전히 많은 병렬 corpus가 필요합니다.
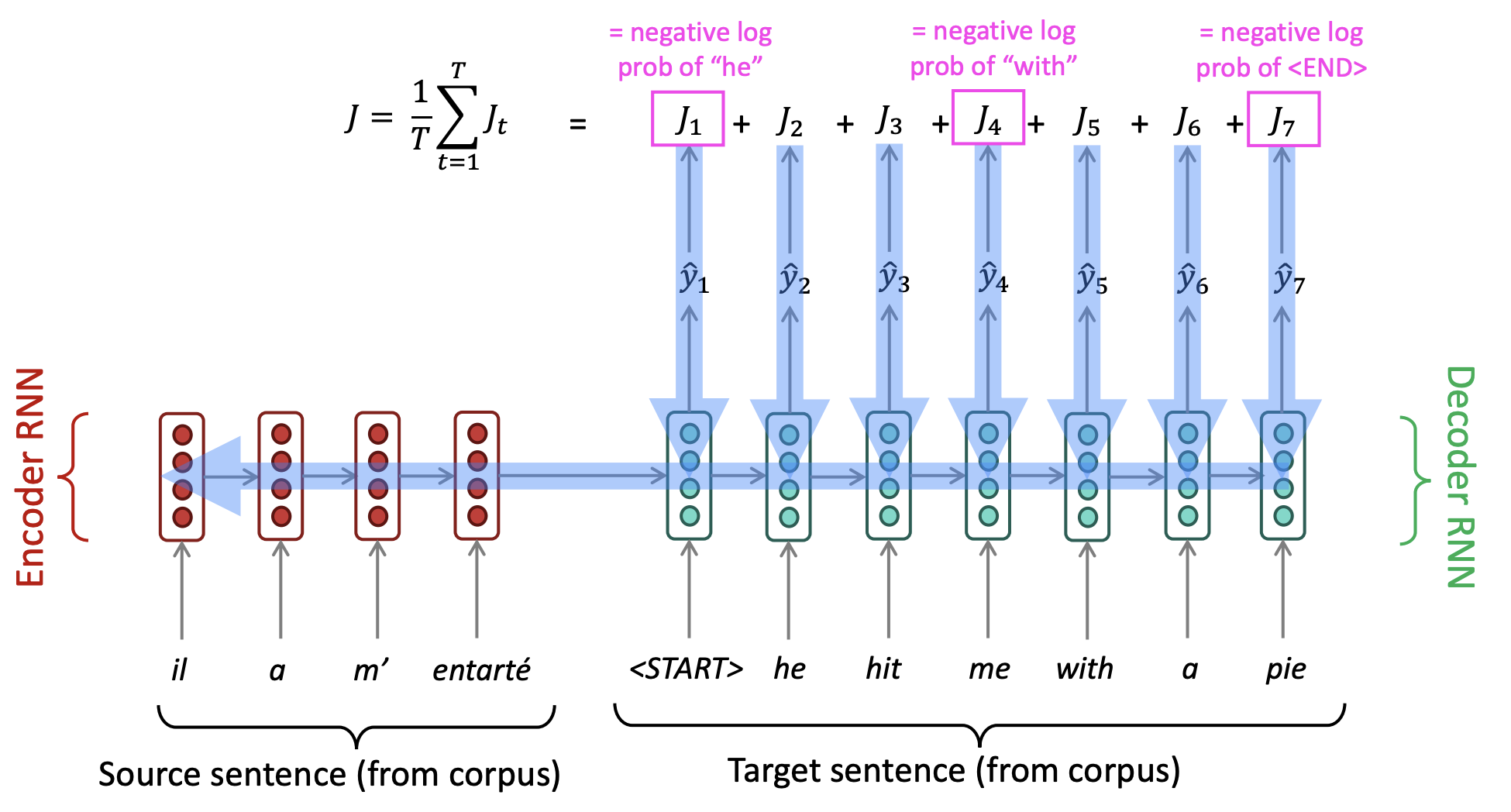
Seq2seq model은 decoder의 timestep별 output은 target sentence에 단어를 생성하게되고 생성된 단어와 실제 단어의 negative log likelihood를 통해 loss를 구하고 0부터 mapping하여 loss를 최소화합니다.
Greedy decoding
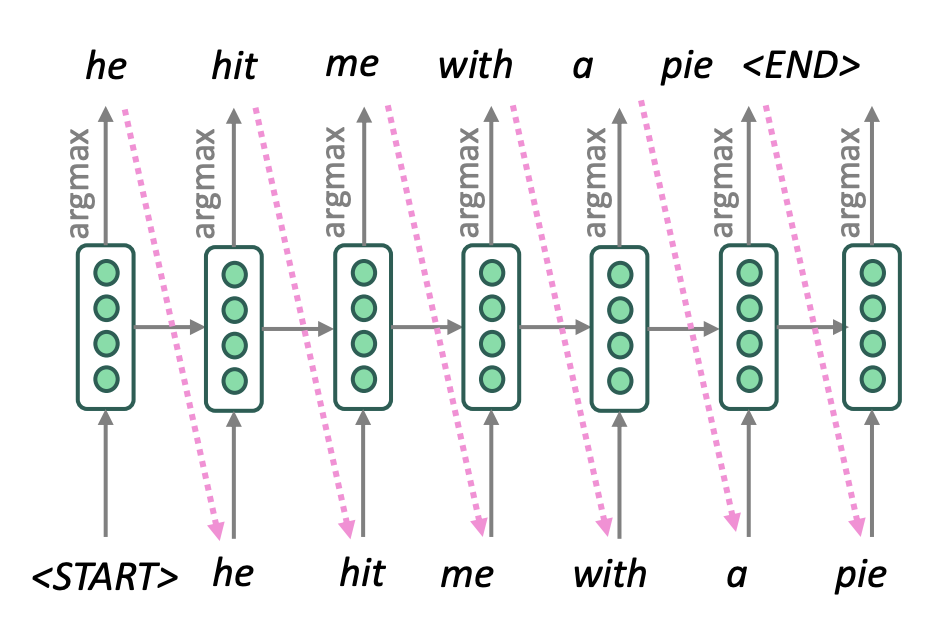
앞서 설명한것처럼 decoding과정에서 생성될 수 있는 모든 target sentence를 비교하는 exhaustive search방식은 계산량이 너무 크기 때문에 greedy decoding을 도입합니다. 각 timestep별 argmax 확률을 사용하는 방법이지만 이상한 문장이 생성될 수 있습니다.
Beam search decoding
그래서 beam search decoding 방법을 많이 사용합니다. 최적의 번역본을 생성하는것은 아니지만 exhaustive search보다는 효율적으로 계산할 수 있고 greedy decoding보다는 더 적합한 번역본을 만들 수 있습니다.
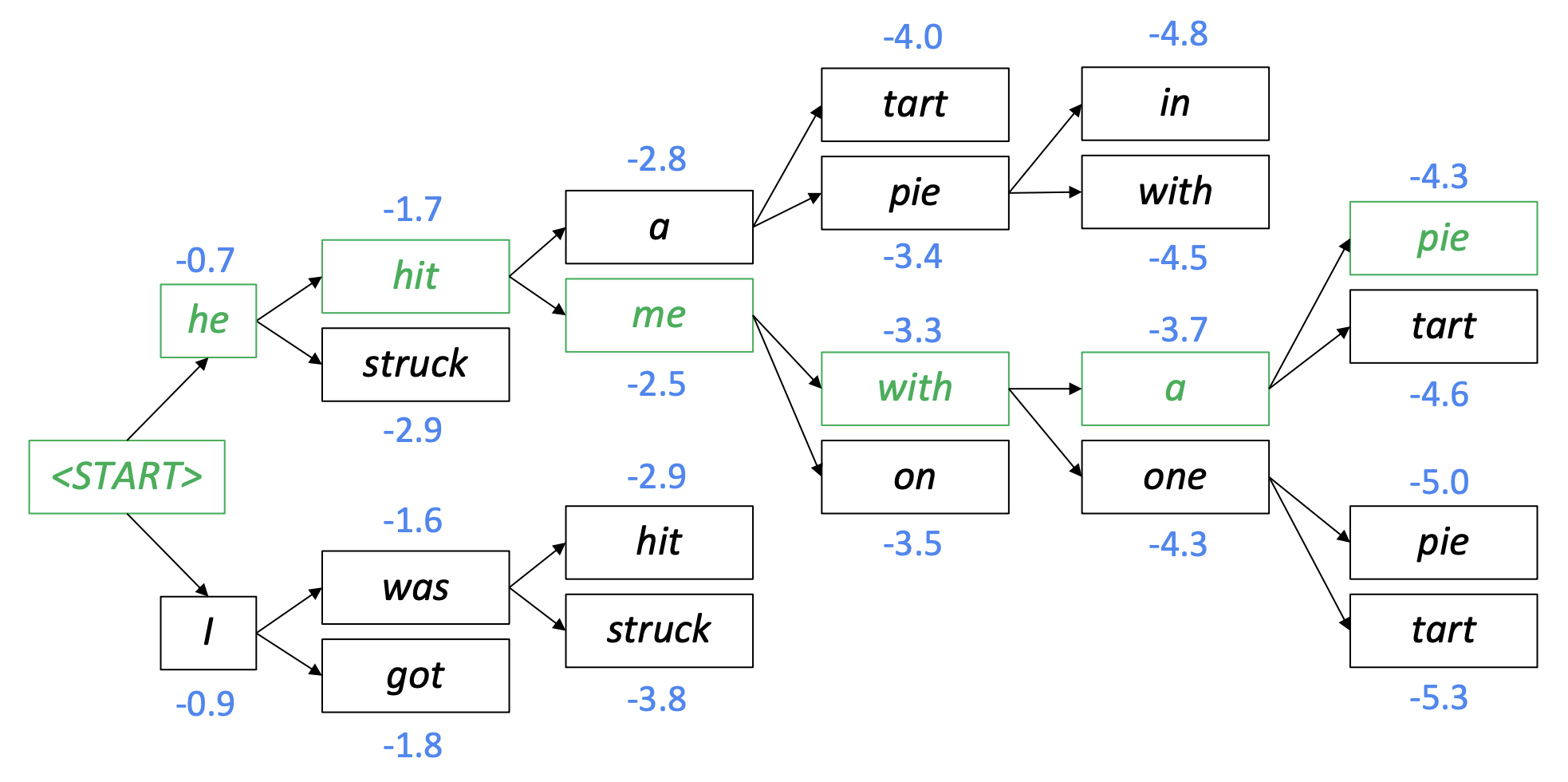
먼저 < sos > token이 들어온 시점에서 부터 예측 값의 확률 분포중 가장 높은 확률 k(2)개를 고릅니다. 그 다음 k(2)개의 beam에서 각각 다음 예측 값의 확률 분포 중 가장 높은 k(2)개를 고릅니다. 그리고 총 개의 자식 노드 중에 누적 확률 순으로 상위 k개를 뽑습니다. 다시 뽑힌 k개의 자식 노드를 새로운 빔으로 다시 상위 k개의 자식 노드를 만듭니다. 마지막으로 < eos > token이 나올때까지 반복합니다. 그러나 < eos > token이 나오기전에 문장이 너무 길어질경우, 사전에 정의된 max timestep(T)를 정의하기도 합니다. 또한 log-likelihood로 생성된 문장을 비교할 때, 긴 문장의 합이 짧은 문장보다 작아져 짧은 문장을 우선적으로 선택되는것을 막기위해 문장 길이로 나눠 정규화를 해줍니다.
BLEU (Bilingual Evaluation Understudy)
Machine translation 성능을 평가하는 지표로는 대표적으로 BLEU score가 있습니다. 실제 문장과 생성된 문장을 비교할 때, n-gram precision 방식이 사용됩니다.
첫번째 항은 짧은 문장에 대한 penalty를 주고있고 두번째 항은 n-gram precision에 대한 기하평균입니다.
NMT's difficulty
NMT가 기존 SMT의 한계점을 뛰어 넘었다고해서 한계점이 없지는 않습니다. 다음과 같은 한계점이 존재합니다
- Out-of-vocabulary words
- 도메인에 적합하지 않은 train과 test data
- 긴 텍스트에서 문맥을 제대로 반영하지 못함
- 병렬 언어 데이터 부족
- 정확한 문장의 의미를 잡지 못함
- 대명사를 파악하지 못함
- 형태소가 일치하지 않음
또한 관용표현의 뜻을 담지 못한다는 한계점이 있습니다.
예시로 paper jam은 프린터기에 용지가 낀것을 말하는 관용표현인데 번역모델이 종이가 담긴 잼통으로 번역을 한것인데, 이처럼 관용표현을 제대로 해석하지 못하는 한계점이 있습니다.
다음 한계점은 bottleneck problem입니다.
일반적으로 RNN기반의 모델 구조이기 떄문에 hidden state의 dimension이 고정된 상태로 계속 정보를 누적하는데 길어지게되면 앞부분의 정보가 손실됩니다.
Attention
Bottleneck 문제와 기존 gradient vanshing 문제를 해결책으로 attention을 도입했습니다. 이를 통해 decoder가 각 timestep에서 source sentence의 중요한 부분에 더 집중할 수 있도록 합니다.
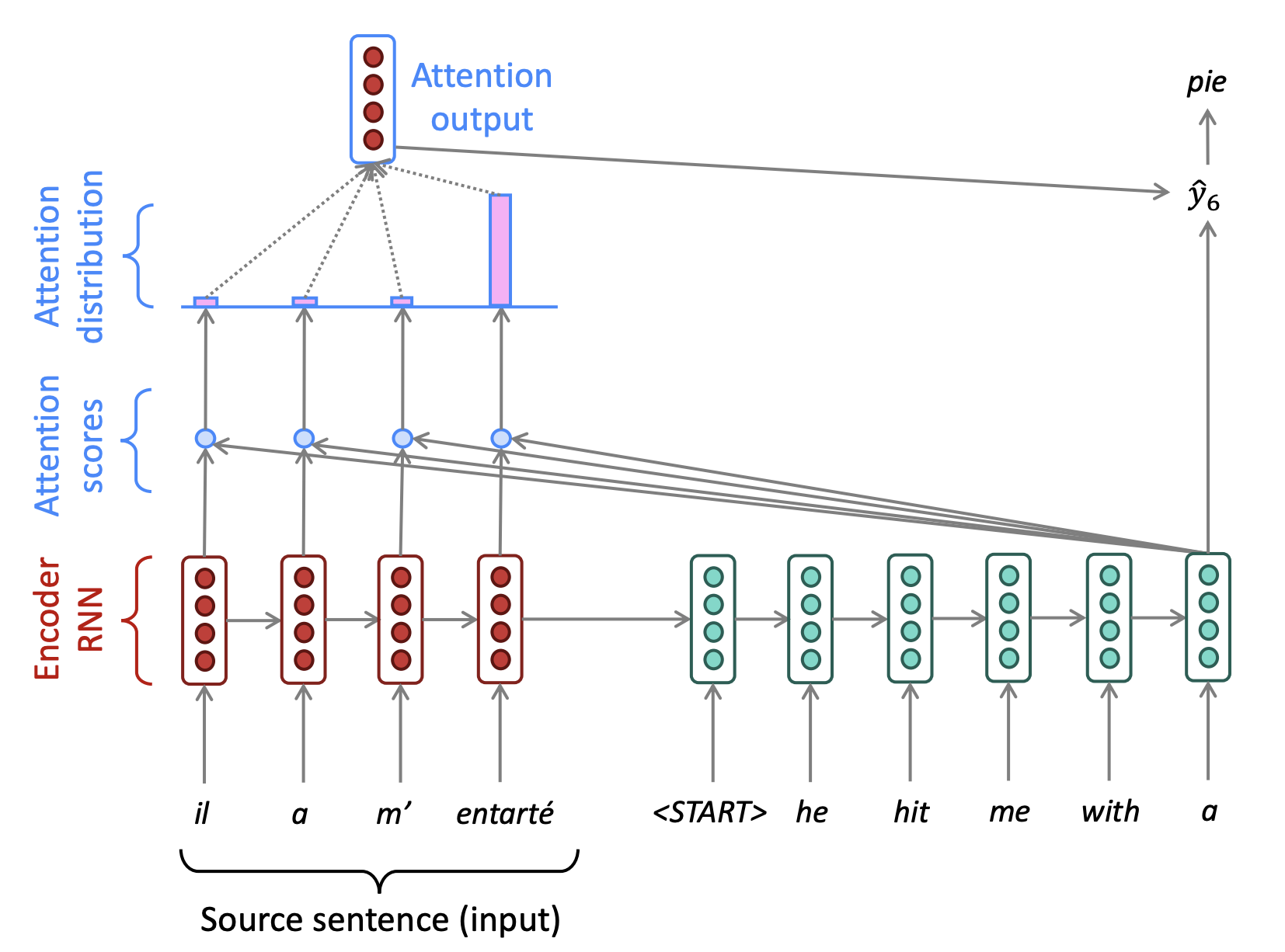
먼저 encoder의 각 timestep 별 hidden state와 decoder의 hidden state의 유사도를 계산하여 attention score를 softmax함수를 거쳐 확률값으로 나타냅니다.
그 다음 attention distribution과 encoder의 hidden state를 가중합하여 최종 output을 생성합니다.
그리고 출력된 output과 decoder의 hidden state를 concat하여 해당 timestep의 단어를 만듭니다.
Attention mechanism을 통해 source sentence의 모든 embedding vector를 참고하는 구조를 사용하여 bottleneck 문제를 해결했고 거리가 먼 state에 대해서 shortcut의 구조를 사용하여 gradient vanishing 문제를 줄였습니다. 또한 모델이 정의하기 어려운 alignment를 스스로 학습할 수 있습니다.
