[논문리뷰] Zero-Shot Text to Image Generation: DALL-E
Paper: https://arxiv.org/abs/2102.12092
Code: https://github.com/openai/DALL-E
0. Abstract
Text-to-image generation은 원래 전통적으로 fixed dataset을 학습하기 위한 더 좋은 모델(의 가정)을 찾는 것에 초점을 두고 연구가 진행돼왔습니다.
그렇다 보니 이런 모델링 가정들은 복잡한 구조, 보조 손실 함수, 추가적인 라벨(object part, or segmentation mask) 등을 필요로 하곤 했습니다.
저자들은 이렇게 복잡한 가정들을 필요로 하지 않는 간단한 접근법을 제안합니다.
특히, 이런 접근법은 text와 image tokens을 마치 데이터의 single stream으로서 autoregressive하게 모델링하는 트랜스포머를 기반으로 합니다.
이런 방법들을 필두로, 충분한 데이터와 scale이 주어진다면 domain-specific model들과도 견줄 수 있는 성능을 보입니다.
특히 zero-shot으로 진행해도요.
1. Introduction
text to image 합성연구는 2015년에 시작해, image caption 조건이 주어질 경우 text로 새로운 visual senes을 생성할 수 있는 잠재력을 보여주었습니다.
2016년에는 (recurrent) VAE 대신 GAN을 사용해 이미지의 정확도를 향상했고, 이러한 시스템을 통해 좋은 수준의 object를 생성할 수 있을 뿐만 아니라 zero-shot 일반화도 가능함을 보여주었습니다("Generative adversarial text to image synthesis").
역대 연구 분야들 중 발전 속도가 제일 빠른 딥러닝 분야 답게 최근에는 더더욱 발전을 이루었습니다.
- multi-scael generator를 사용(StackGAN)
- attention과 보조 손실을 통합(AttnGAN)
- text 외의 추가 조건을 활용
- paper : (2016)"Learning what and where to draw"
- condition : informal text descriptions & object location
- paper : )(2019)"Object-driven text-to-image synthesis via adversarial training(Obj-GAN)"
- condition : the text description & a pre-generated semantic layout
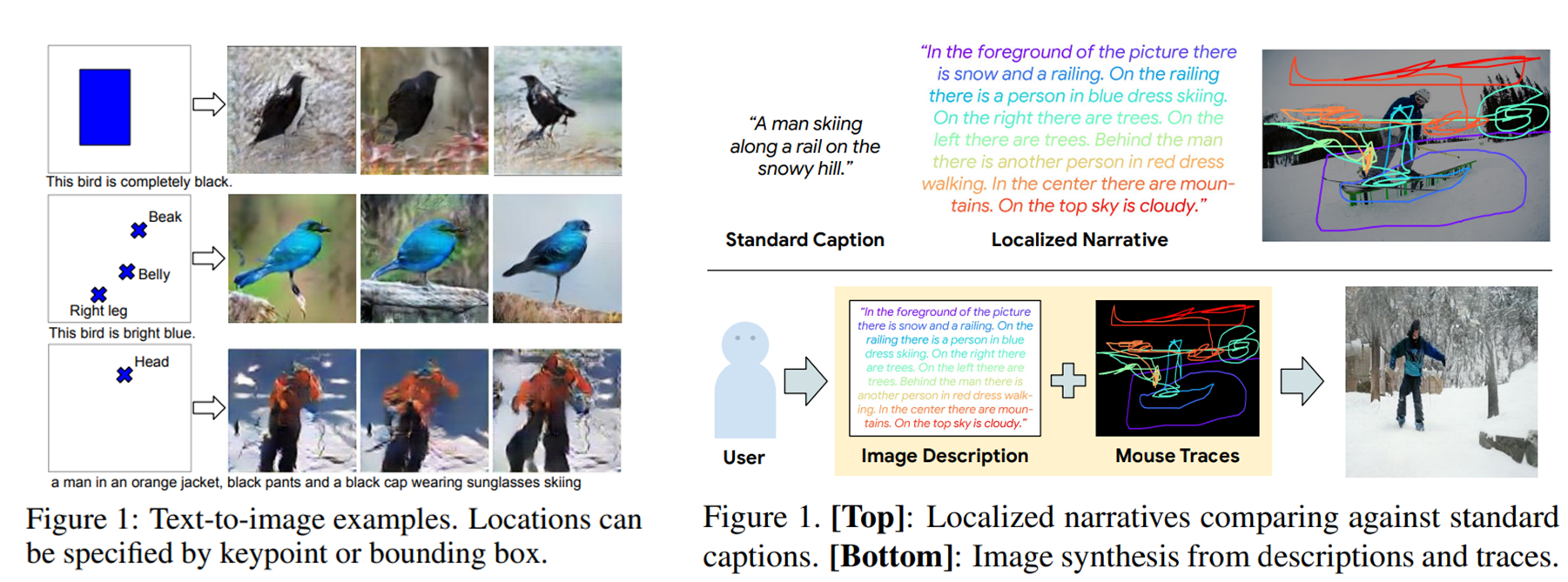
- paper : (2021)"Text-to-image generation grounded by fine-grained user attention"
- condition : text description & Mouse Traces
- paper : (2016)"Learning what and where to draw"
(좌 : Object location, 우 : Mouse Traces)
또한, conditional image generation을 위한 energy-based framework를 제안한 연구도 있었는데, 이는 사전학습 된 판별 모델을 활용할 수 있었고, 기존 모델들에 비해 훨씬 개선된 성능을 보였습니다.
특히, MS-COCO dataset에 사전학습된 captioning model을 활용할 경우 Text-to-Image Generation 또한 가능했기 때문에 개인적으로 훌륭한 연구라고 생각합니다.
연구 : (2017)Conditional iterative generation of images in latent space

pretrained cross-modal masked language model을 활용한 아래의 연구도 존재합니다.
연구 : (2020)X-LXMERT: Paint, Caption and Answer Questions
with Multi-Modal Transformers

2015년 이래로 Text-to-Image Generation 분야에도 정말 많은 발전이 있었지만, 한계점 또한 열실히 드러납니다.
- 물체 왜곡
- 실재할 수 없는 물체 위치
- 배경과 잘 어우러지지 못하는 물체
다만, 최근에는 large-scale genreative model이 발전의 길을 열어주고 있긴 합니다.
연산, 모델 크기, 데이터 등이 적절하게 조절된다면 autoregressive transformer는 text, image, audio등의 다양한 도메인에서 인상적인 결과를 보여준다는 연구 결과들이 많습니다.
위에서 말하는 large-scale generative model은 GPT-2와 같은 초대형 모델들을 활용하는 생성모델 정도로 보면 될 것 같습니다.
text : "Language Models are Unsupervised Multitask Learners"
Image : "Generative pretraining from pixels."
autoregressive transformer는 그냥 흔히 쓰이는 트랜스포머라고 생각하면 됩니다.
연구 : "Attention is all you need"
다만, 아직 text-to-image generation같은 경우 비교적 작은 데이터셋인 MS-COCO나 CUB-200을 이용해서 평가되곤 합니다.
이런 데이터 셋들의 크기나 모델의 크기가 분명 현존하는 접근법들의 한계일 수 있기 때문에, 본 연구에서 저자들은 large-scale dataset을 활용해 Text-to-Image Generative Model을 학습했다고 합니다.
자세히는,
- 120억개의 parameter를 갖는 transformer
- 2억 5천만개의 image-text pair.
저자들은 이렇게 대용량 데이터를 활용해 초대형 모델을 학습한다면, 자연어 문장으로 컨트롤 할 수 있는 높은 수준의 이미지를 생성할 수 있음을 보였습니다.
(MS-COCO의 Label을 사용하지 않고 zero-shot으로도 높은 수준의 이미지를 생성할 수 있었습니다).
또한 Image-to-Image translation task 마저도 기초적인 수준에서 수행할 수 있었습니다
기존엔 "Image-to-Image Translation with conditional adversarial networks" 연구에서 소개했던 것처럼 따로 task-specific한 모델을 구축했어야 했습니다.
이런 구축 없이 (성능은 당연히 기존 모델에 필적하지 못할지라도) 단일 모델이 translation task를 수행할 수 있다는 것은 아주 큰 발전입니다.
Image-to-Image Translation 간단 정리
2. Method
저자들의 목표는 Transformer 변형 모델들의 원형이 되는 연구 "Attention is all you need"에서 제안된 Autoregressive Transformer를 학습하는 것입니다.
단, text와 image token들을 'single stream'으로 모델링하게 됩니다.
하지만 image를 pixel 단위에서 사용하는 것은 메모리 문제를 야기할 수밖에 없습니다.
Likelihood*를 목표함수로 사용하는 모델들은 pixel 간의 short-range dependencies을 우선시하는 경향이 있기 때문에 우리가 납득할 수 있는 결과를 반환하기 위해 low-frequency 특성보다는 high-frequency** details을 포착하는데 capacity를 더 많이 사용할 것입니다.
(참고)
Likelihood*
위에서 말하는 short-range dependencies는 연구 Pixel CNN++에서 나오는 얘기이긴 합니다.
다만 Likelihood를 목표함수로 하는 것은 그냥 대부분의 딥러닝 모델에 해당된다고 보면 됩니다.
예를 들어, 생성모델 중 하나인 VAE 또한 likelihood 기반이라고 할 수 있는데, 애초에 목표함수가 꼴로 주어지기 때문입니다.
(즉, 생성자의 parameter가 주어진 상태에서 주어진 데이터셋의 분포에 가까워지도록 학습)
이에 대해서는 아래의 글을 참고하면 될 듯 합니다.
[딥러닝 기본] Deep Learning 배경지식
VAE 정리(본 블로그)
Why VAE are likelihood-based generative models
high-frequency**
frequency에 대한 내용은 i2i translation(본 블로그)에도 간략하게 있습니다.
아무튼, 저자들은 이런 이슈를 다루기 위해 2-stage Training을 사용합니다(Oord et al, Neural Discrete Representation Learning.
Stage 1
- discrete VAE를 활용해 RGB 이미지를 의 이미지 토큰으로 압축.
- 단, 각 token은 8192가지의 값을 가질 수 있음.
- 그 결과 트랜스포머의 context size를 visual quality의 큰 손실 없이 192배 가량 줄일 수 있음()

Stage 2
- 최대 256 BPE-encoded text tokens을 1024(32x32) image tokens와 concat
- text / image tokens의 결합 분포를 모델링하는 autoregressive transformer 학습
전반적인 과정은 ELB(Evidence lower bound)를 최대화하는 것과 유사합니다.
단, images , (텍스트 형태의)captions , (encoded RGB 이미지의) tokens 의 joint likelihood에 대한 하한을 잡습니다.
즉, 를 모델링하게 되며, 이를 로 나눠서 모델링하게 됩니다.
즉, 아래와 같은 하한이 잡힙니다.
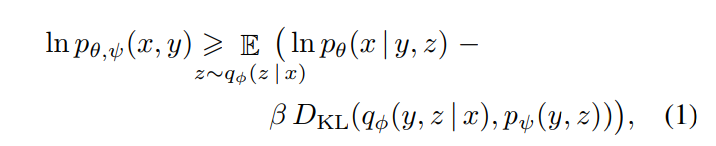
: RGB image 를 dVAE로 인코딩한 image token의 분포
: image tokens를 dvAE로 디코딩한 RGB images의 분포
: 트랜스포머로 모델링되는 text tokens, image tokens의 결합분포
아래에서 디테일을 살펴봅시다.
2.1. Stage One : Learning the Visual Codebook
첫번 째 단계에서 저자들은 ELB를 에 대해 최대화합니다.
는 images에 대해서만 dVAE를 학습하는 파트입니다(아직 text는 사용 x).
그렇기 때문에 initial prior 를 codebook vector에 대한uniform categorical distribution으로 가정합니다.
code book : 임베딩 벡터를 담은 fixed-size table.
또한 를 8192개의 logits에 의해 매개화되는 categorical distribution이라 가정합니다.
dVAE encoder의 output이 의 grid를 가지며 각 position에서 8192개의 값을 가질 수 있기 때문입니다.
또한, 가 discrete 분포기 때문에 ELB를 최적화하기가 굉장히 어렵습니다(reparameterization gradient를 사용할 수 없음).
저자들은 이를 해결하기 위해 gumbel-softmax relaxation을 사용해 에 대한 기댓값을 에 대한 기댓값으로 대체합니다.
의 우도는 log-laplace distribution을 활용해 evaluate됩니다.
KL weight를 으로 증가시킨 것이 codebook의 효율을 높히고, 궁극적으로 더 낮은 reconstruction error를 보였다고 합니다.
2.2. Stage Two: Learning the Prior
두번 째 단계에서는 를 fix한 후 에 대한 ELB를 최대화함으로써 text와 image tokens의 사전 분포를 학습합니다.
여기서 가 130억 개의 parameter를 갖는 sparse transformer에 해당합니다.
text-image pair가 주어지면 아래와 같이 인코딩을 수행합니다.
text : BPE-encoder를 이용, voca size 16,384개를 갖는 최대 256 tokens을 활용해 lowercased caption을 인코딩합니다.
image : voca size 8,192개를 갖는 tokens을 활용해 image를 인코딩
image tokens은 dVAE encoder logits으로부터 argmax sampling을 활용해 얻어집니다.
최종적으로 위의 text-image tokens는 concat되어 single stream of data로서 autoregressively하게 모델링됩니다(트랜스포머에 의해).
트랜스포머는 각 image token이 모든 text token과 attend할 수 있는 decoder-only model입니다.
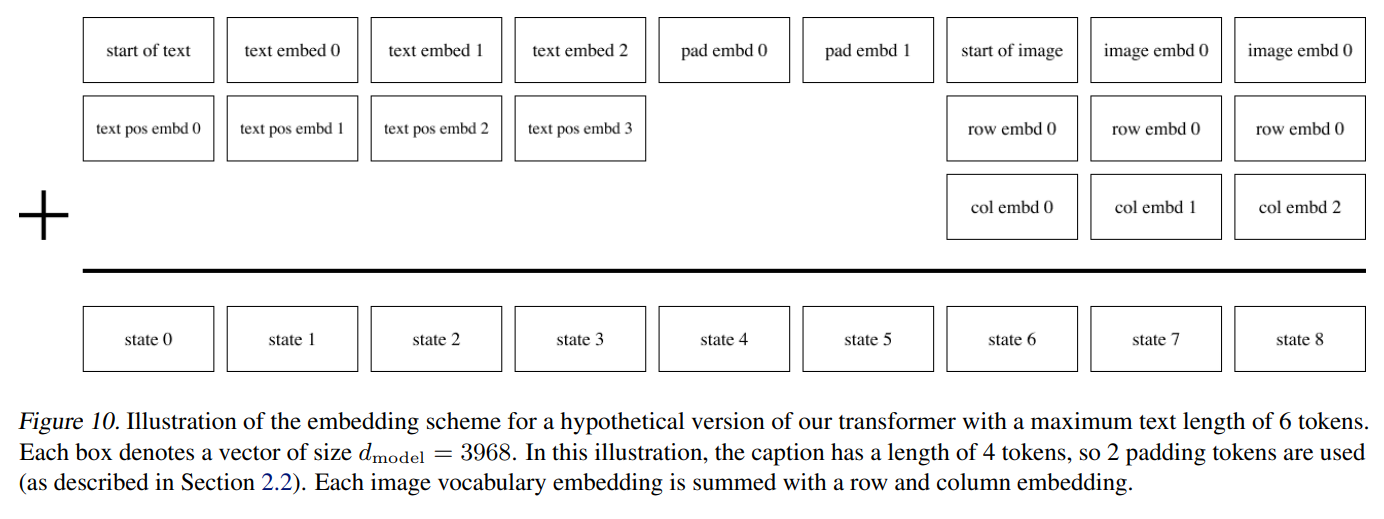
총 64개의 self-attention layer가 존재하는데, 이 중 어느 한 곳에서 attention이 일어납니다.

추가적인 self-attention mask는 3개 사용되었습니다.
text-to-text attention : standard causal mask
image-to-image attention : row,column, or convolutional attention mask
text-image tokens에 대한 cross-entropy loss는 각 배치에 속한 개수로 정규화됩니다.
저자들은 imgae modeling에 주로 초점을 맞추기 때문에 text에 대한 loss를 배, image에 대한 loss를 배로 해 사용합니다.
Optimization은 Adam을 사용합니다(with exponentially weighted iterate averaging).
2.3. Data Collection
저자들의 experiements는 주로 330만개의 text-image pair를 갖는 MS-COCO dataset에 수행되었으며, 모델의 파라미터는 12억개 정도입니다.
모델의 파라미터를 120억개 정도로 늘리기 위해 JFT-300M dataset과 비슷한 스케일의 데이터 셋을 구축했습니다(2억 5천개의 text-image pair).
2.4. Mixed-Precision Training
GPU 관련 내용, 패스
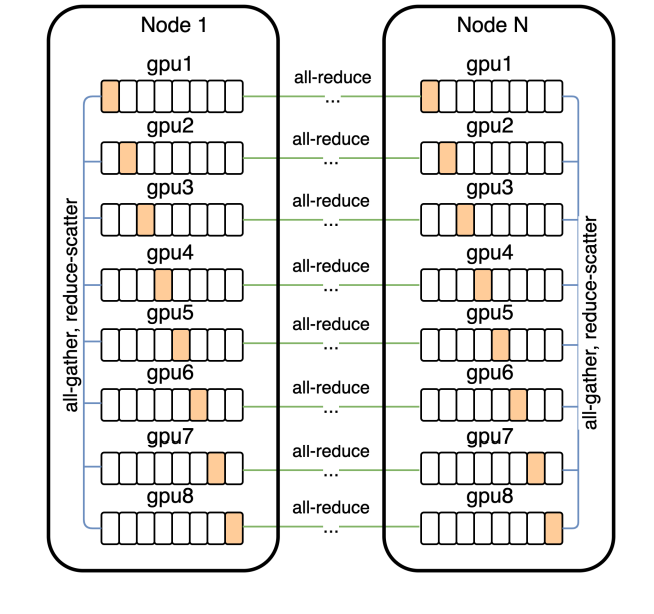
2.5. Distributed Optimization
GPU 관련 내용.
120억개의 parameter를 갖는 모델은 대략적으로 24 GB 정도 차지합니다.
이는 16GB NVIDIA V100 GPU의 용량을 뛰어넘죠.
저자들은 이런 문제를 parameter sharding을 사용해 해결했습니다.
3. Experiments
본 단락에서는 간략하게 Table과 Generated sample만 다루겠습니다.
3.1. Quantitative Results
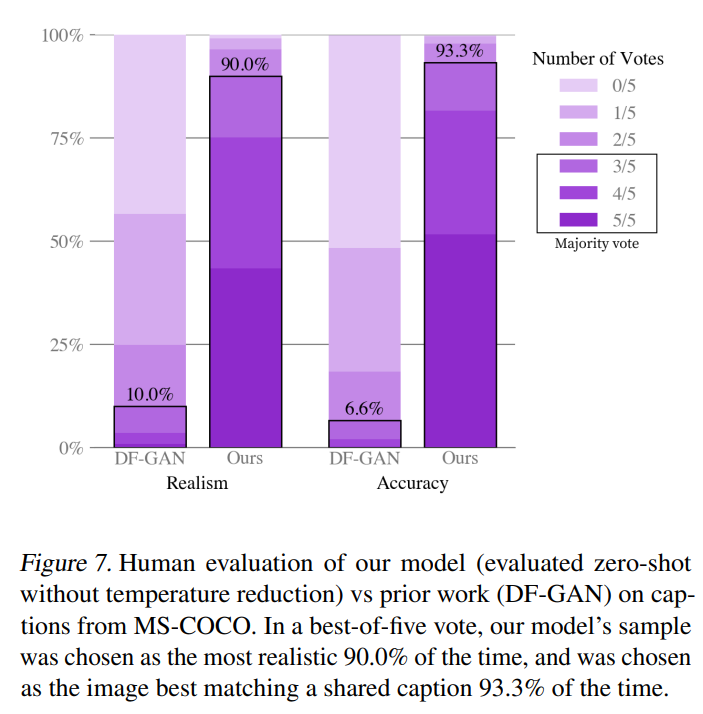
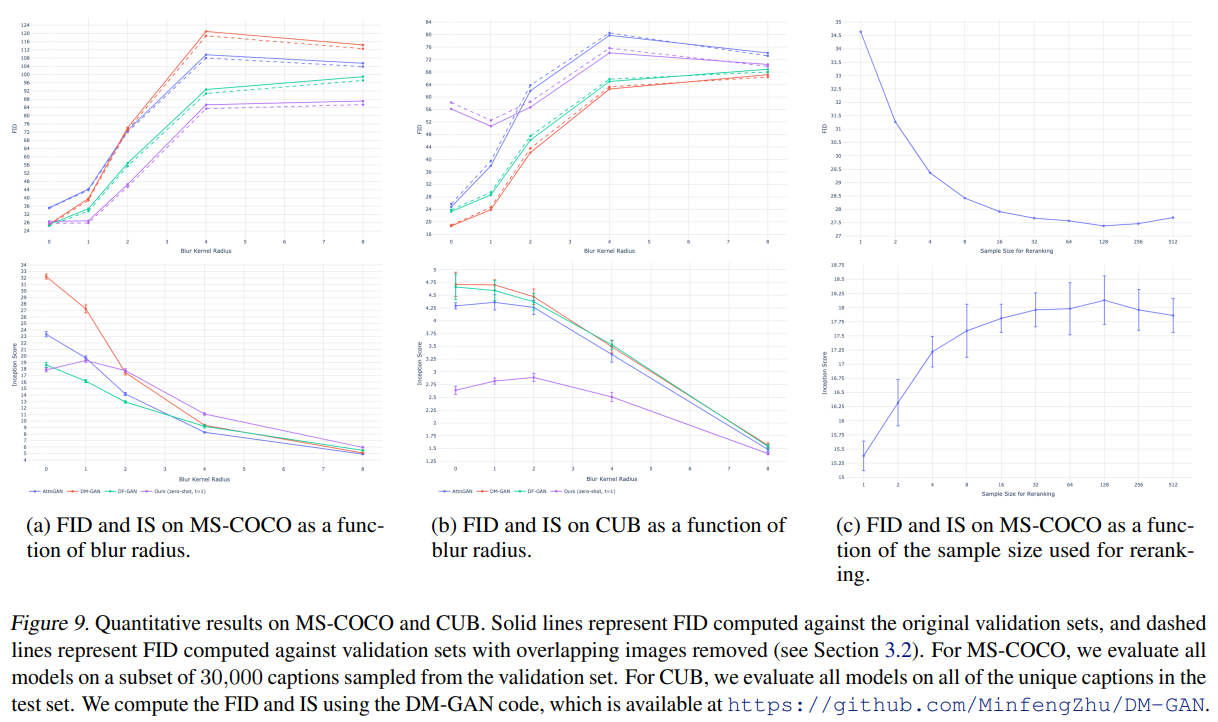
저자들은 zero-shot model을 AttnGAN, DM-GA
N, DF-GAN과 비교했습니다(DF-GAN은 MS-COCO에 대해 Inception Score, FID 둘 다 sota).

3.3. Qualitative Findings
저자들은 해당 모델이 기대하지 않은 방식으로 일반화 능력을 갖췄다고 얘기합니다.
가령, " a tapir made of accordion..."이라는 캡션을 받았을 때, 모델은 아래와 같은 output을 반환합니다.

이런 결과는 모델이 높은 수준의 추상화로 특이한 컨셉을 구성할 수 있는 능력을 갖췄음을 암시합니다.
또한, 해당 모델은 combinatorial generalization(조합 일반화) 능력도 있는 것처럼 보입니다.
가령, text를 렌더링할 때에는 아래와 같습니다.

혹은 "크리스마스 옷을 입고 있는 고슴도치가 강아지를 산책시키고 있다"라는 복잡한 문장 또한 가능합니다.
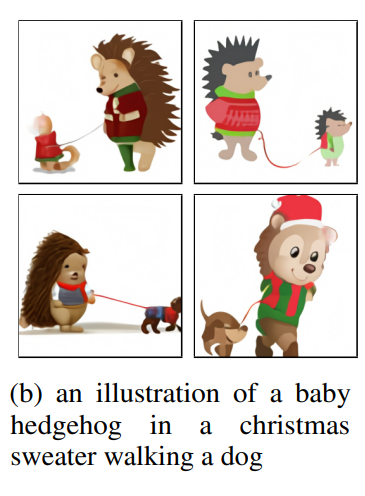
특히 위의 문장은 모델이 애초에 variable binding을 수행해야 가능한 일입니다.
(즉, 고슴도치가 크리스마스 옷을 입어야지, 개가 크리스마스 옷을 입으면 안 됩니다).
그냥 문장 내 단어 간 종속성 정도를 이해할 수 있다는 얘기로 받아들이면 될 것 같습니다.
하지만 완벽하게는 못 하고, 개와 고슴도치가 둘 다 크리스마스 옷을 입고 있다거나, 고슴도치가 고슴도치를 산책시켰다거나 하는 결과물도 있었습니다.
반면, 제한된 수준의 성능이지만, 모델이 zero-shot image-to-image translation 또한 가능하다고 합니다.
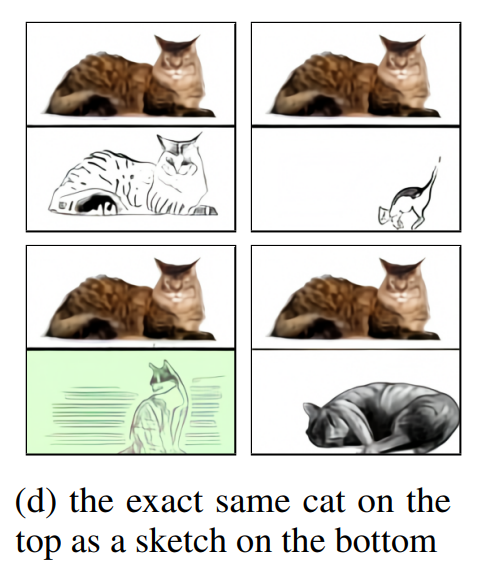
뿐만 아니라 이미지의 색을 바꾸거나, 흑백으로 바꾸거나, 상하를 반전시키거나, style을 transfer하는 등의 여러가지 transformation이 가능합니다.
그렇다는 건 모델이 기초적인 수준의 object segmentation이 가능하다는 방증이겠죠.


4. Conclusion
저자들은 autoregressive transformer를 기반으로 text-to-image generation task를 위한 간단한 접근법을 제안합니다(특히 large scale에서).
그런 scale이 zero-shot performance와 single generaive model 등의 관점에서 훌륭한 수준의 일반화 성능을 보장했음을 보여줍니다.
