1. 기존 딥러닝의 한계와 메타러닝
1.1. 현재 딥러닝의 한계
모두가 알다시피, 근래 몇 년간 딥러닝은 수 많은 데이터에 의존해왔습니다.
데이터가 없다면, 성능이 잘 나오지 않죠.
(여러 데이터셋 중 하나인 IMAGENET dataset)
딥러닝의 성능이 너무나도 좋아서 각광을 받고 있긴 하나, 대용량 데이터가 있어야만 제 기능을 하는 것은 인공지능이라기보다는 고도의 통계처리 기계라고 보는 것이 옳다는 의견도 많습니다.
더군다나, 데이터에 라벨까지 필요한 지도 학습 task라면 데이터셋 구축 조차 쉽지 않겠죠.
그래서 최근 몇 년간 데이터 의존성을 줄이기 위한 수 많은 연구가 있었습니다.
- Domain Adaptation
- Semi-supervised learning
- Self-supervised learning
4. Meta-learning
대표적으로 본 글에서 다룰 Few-shot Learning에 적용되는 Meta-Learning 또한 이에 해당합니다.
1.2. Meta Learning & Few-Shot Learning
메타러닝(Meta-Learning) : Learning-to-learn, 즉 학습을 잘 하는 방법을 학습하는 것에 대한 연구 분야
퓨샷러닝(Few-Shot Learning) : 적은 데이터만을 가지고 좋은 성능을 뽑아내기 위한 방법론들을 다루는 연구 분야
위의 두 분야는 분명 다른 분야지만, 결국 목표는 '처음 마주하는 데이터(적은 데이터)에 대한 일반화 성능 확보'이기에 서로 밀접하게 연관되어 있다 할 수 있습니다.
일반화, 혹은 보편화를 더더욱 추구하는 연구 분야이기 때문에 미래 우리가 나아가야 할 범용 인공지능(Artificial generel Intelligence)를 위한 초석이라도 보는 사람도 많구요.
사실 처음 마주하는 데이터에 대한 일반화 성능 확보는 모든 딥러닝 연구의 목표라고 봐도 무방합니다.
1.3 메타 러닝(Meta Learning)
메타러닝에는 아래와 같이 다양한 종류의 알고리즘이 존재합니다.
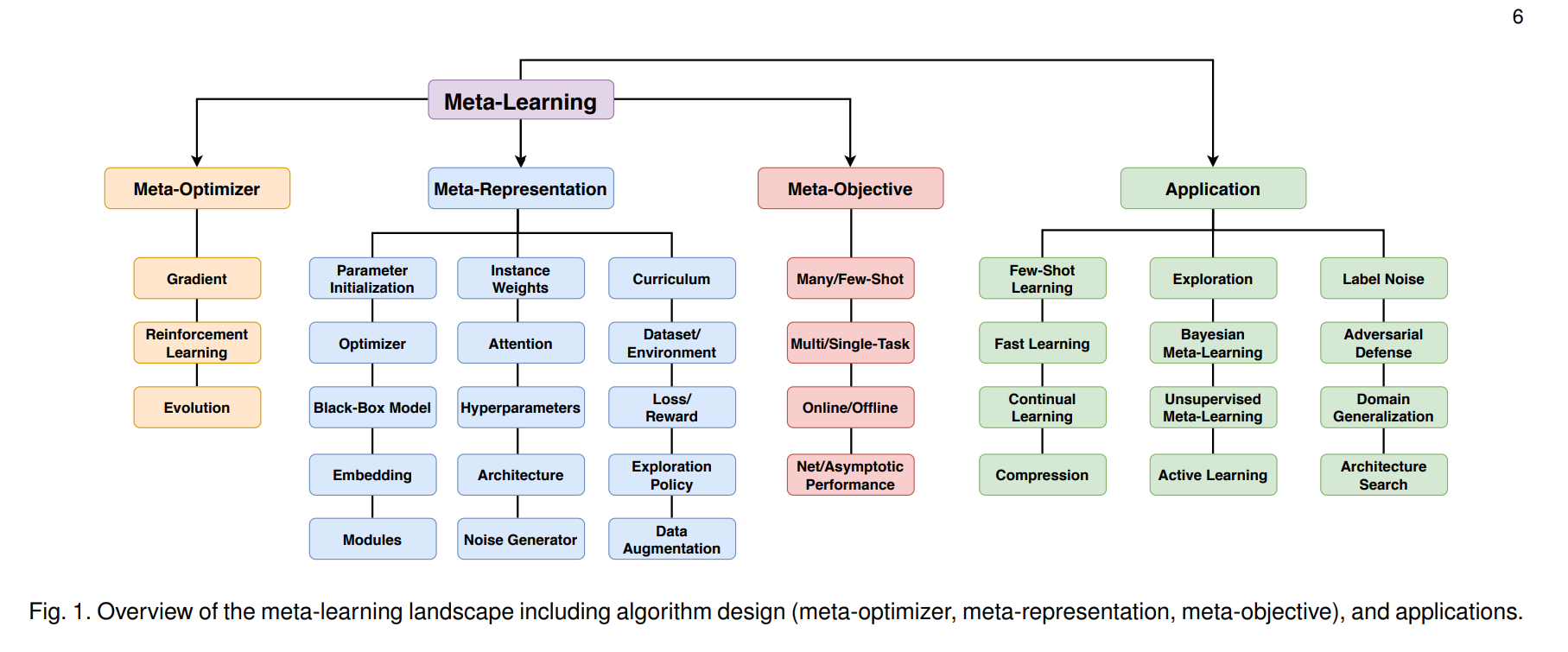
오른쪽 Application에 Few-Shot Learning이 보이네요.
다만, 여기서는 Optimization-based Meta-Learning에 대해서만 간단히 다루겠습니다.
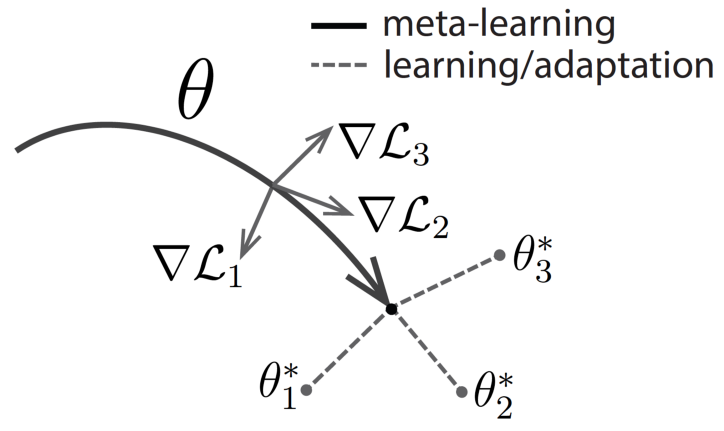
(Figure in "Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks")
우선, 는 각기 다른 task에서 나오는 각기 다른 Loss라 할 수 있습니다.
이 때의 task가 주로 Few-Shot task가 되겠죠.
위의 과정을 Meta-Learning과 Adaptation으로 나눌 수 있습니다.
- Meta-Learning : 를 활용해 3개의 task에 모두 잘 작동할 수 있는 weight를 찾는 과정
-즉, 일반화 성능이 좋은 초기값을 찾는 문제(Initialization) - Adaptation : 메타러닝 과정에서 찾은 weight를 초기치로 활용해 각 task에 적합시키는 과정( fine-tuning)
- 다양한 task에 일반적으로 잘 적용되는 weight를 초기치로 이용하기 때문에 적은 데이터로도 빠르게 optimal point로 나아갈 수 있습니다.
위와 같이 일반적으로 메타러닝은 다양한 task에 보편적으로 적용될 수 있는 초기 parameter를 찾는 것을 목표로 한다고 봐도 무방합니다.
2. Few-Shot Learning
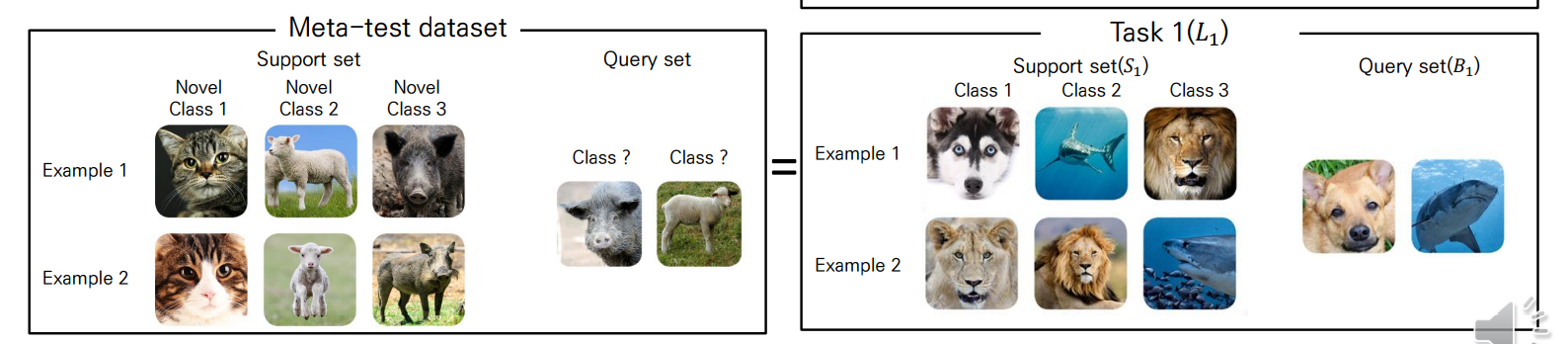
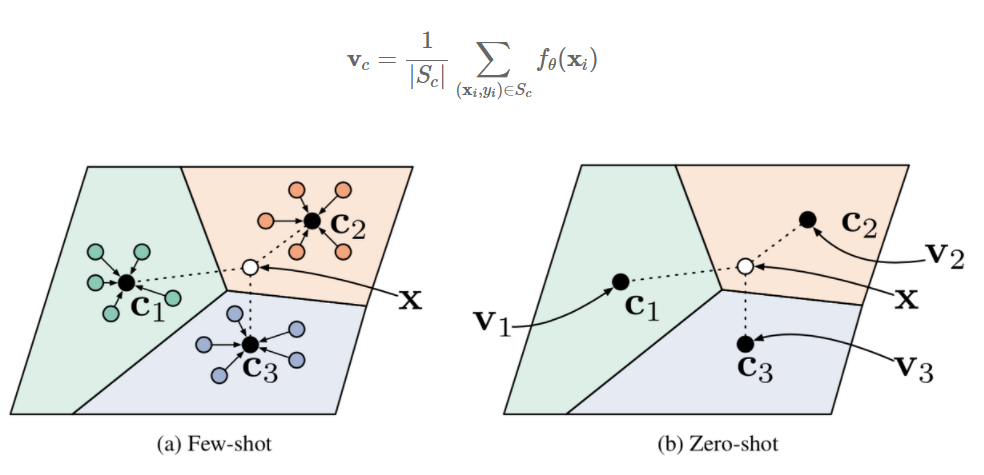
퓨샷 러닝의 목적은 아래와 같이 매우 적은 학습 데이터(Support set)으로도 평가 데이터(Query set)를 올바르게 예측하는 것입니다.

우선, 아래에서 사용하는 용어에 대해 간단히 정리합시다.
2.1. Definition
N-way, K-shot** (classification)
N-way : class의 수
K-shot : class 당 example의 수

보통 ,
- 특히, 인 경우 Zero-Shot이라 합니다.
Dataset 구조
Few-Shot Learning은 (일반적으로) 기존 학습 방법과 다르기 때문에 데이터 셋 용어 또한 달라져야 합니다.
기존 : Train-set 학습 Test-set 평가
↓↓↓↓↓
변경 : Meta-train dataset 학습 -> Meta-test dataset 학습+평가
이 과정을 구체적으로 나타내면 아래와 같습니다.
- 메타러닝 학습 Adaptation 학습 Test-set 평가
- (Meta-train set 이용) (Support set 이용) (Query set 이용)

Support set Train set
새로운 클래스에 대한 학습 데이터(Support)

Query set Test set
새로운 클래스에 대한 평가 데이터(Query)

Meta-Train Dataset
Meta-Test를 잘 수행하기 위해 메타러닝에 쓰이는 학습 데이터

- 당연히, Meta-train dataset의 클래스와 Meta-test dataset의 클래스는 달라야 합니다.
즉, 우리는 위와 같이 적게 주어지는 Support set으로부터 Query set의 label을 올바르게 예측하기 위해서 Meta-train dataset을 활용해 학습을 진행하게 됩니다.
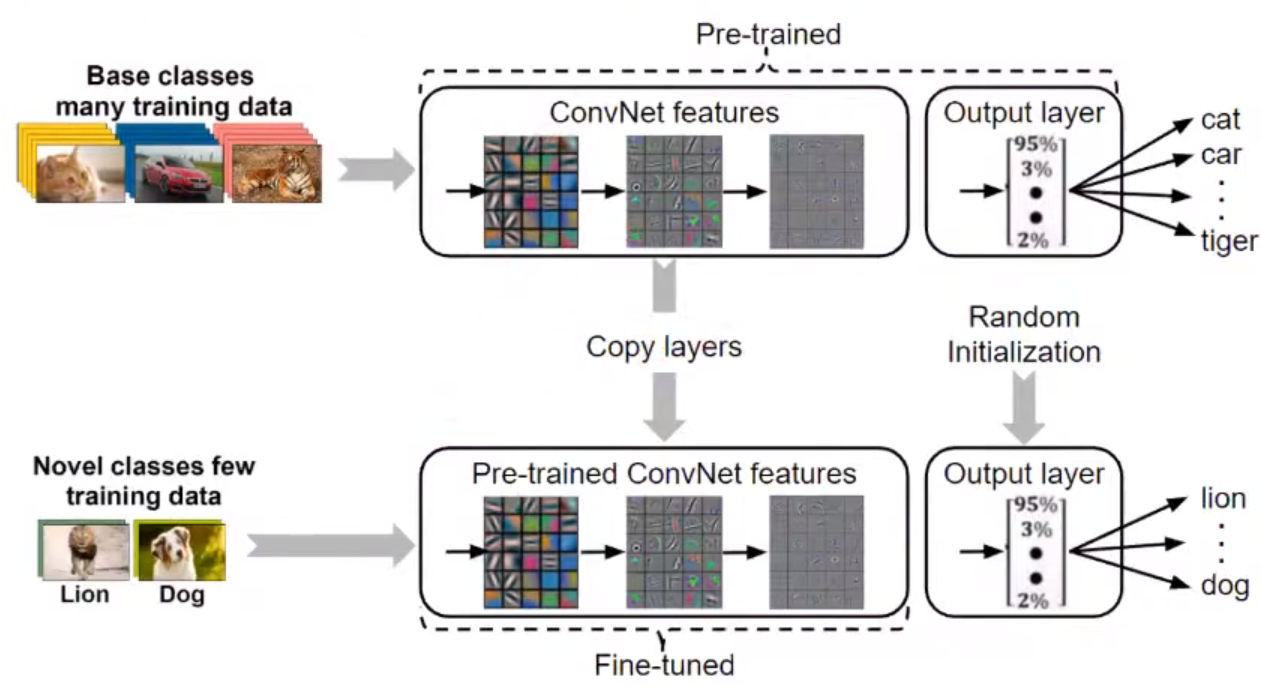
전이학습(Transfer Learning)과 유사?
- large-scale dataset에 학습한 pre-trained model을 활용하면 비교적 적은 데이터셋으로도 좋은 성능을 낼 수 있습니다(전이학습).
- 하지만 일반적인 전이학습으로는 Few-shot task를 수행할 수는 없습니다(적어도 데이터 수백~수천 개는 있어야..).
2.2. Training strategy(Episodic training)
Few-shot task에서 학습은 주로 Episodic training을 활용합니다(강화학습 아님).
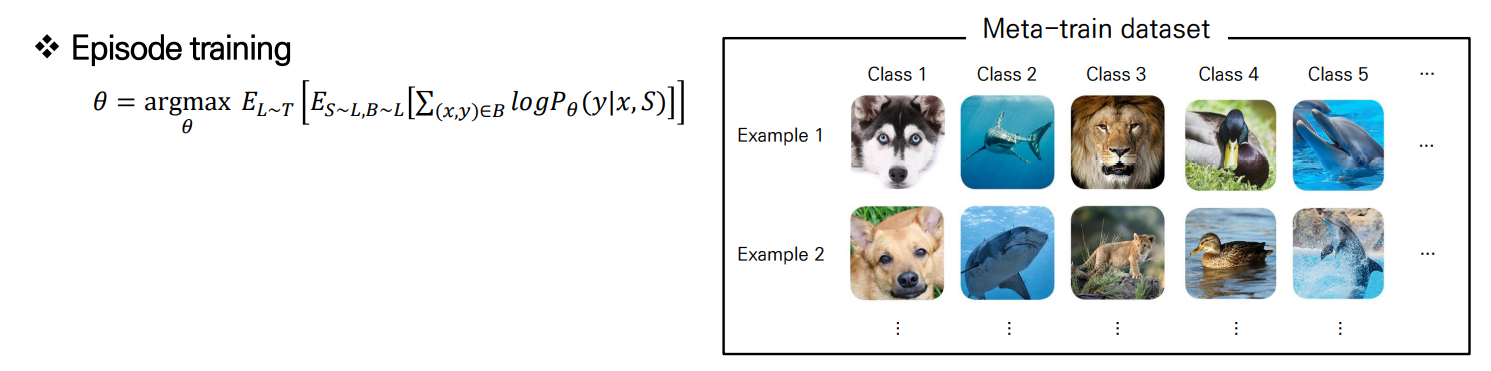
이 때 아래의 수식을 하나하나 파악해봅시다.
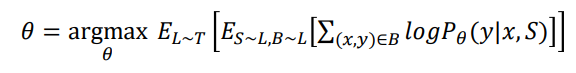
Task sampling
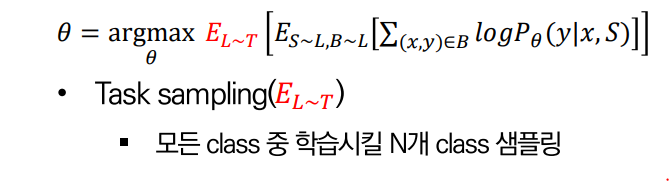
우선, Meta-Train dataset에서 개의 class를 샘플링하게 됩니다.
이 때 개의 class로 학습을 진행하는 것이 1개의 task가 됩니다.
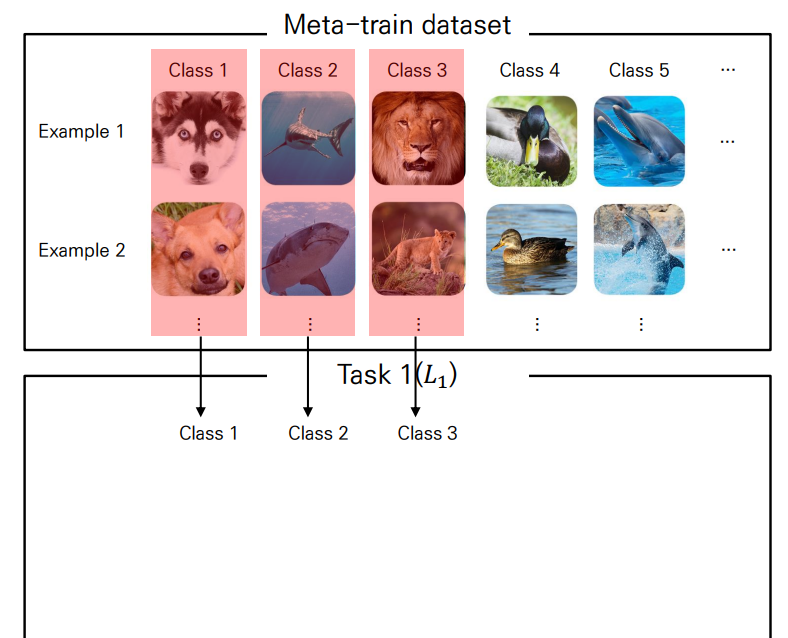
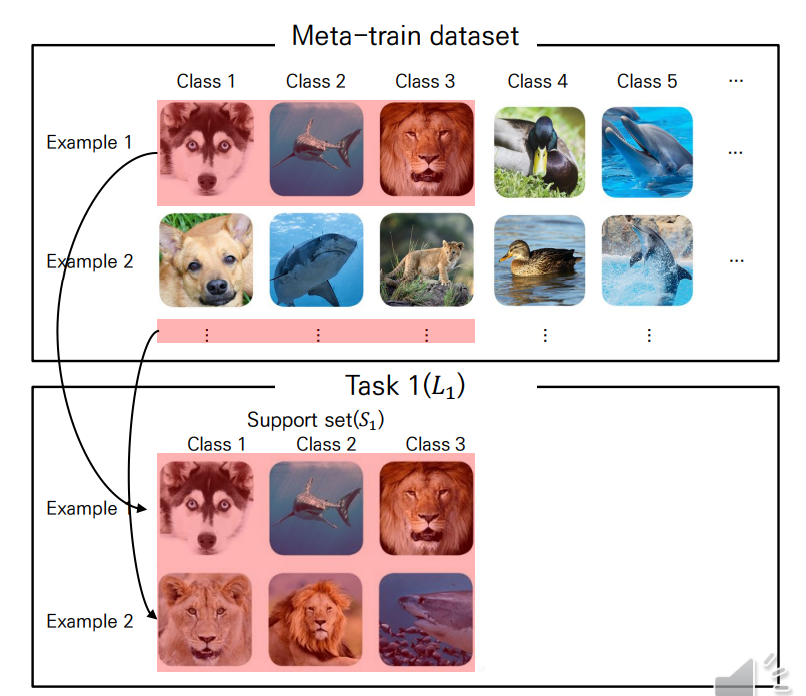
Support set sampling
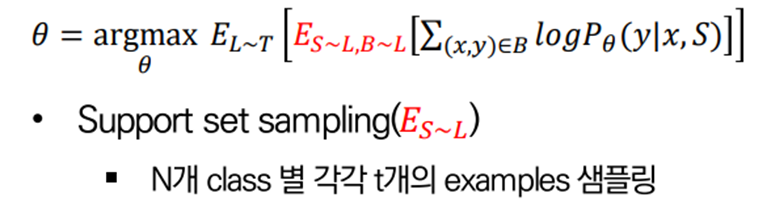
하나의 task가 정해지면, class 또한 정해집니다.
이 때 개의 class에 대한 개의 example을 샘플링해 support set으로 사용합니다.
Query set sampling
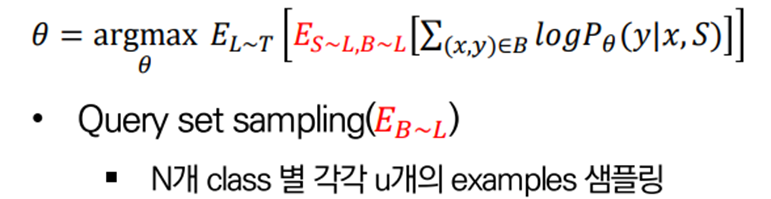
마찬가지로 개의 class에 대한 개의 example을 샘플링해 query set으로 사용합니다.
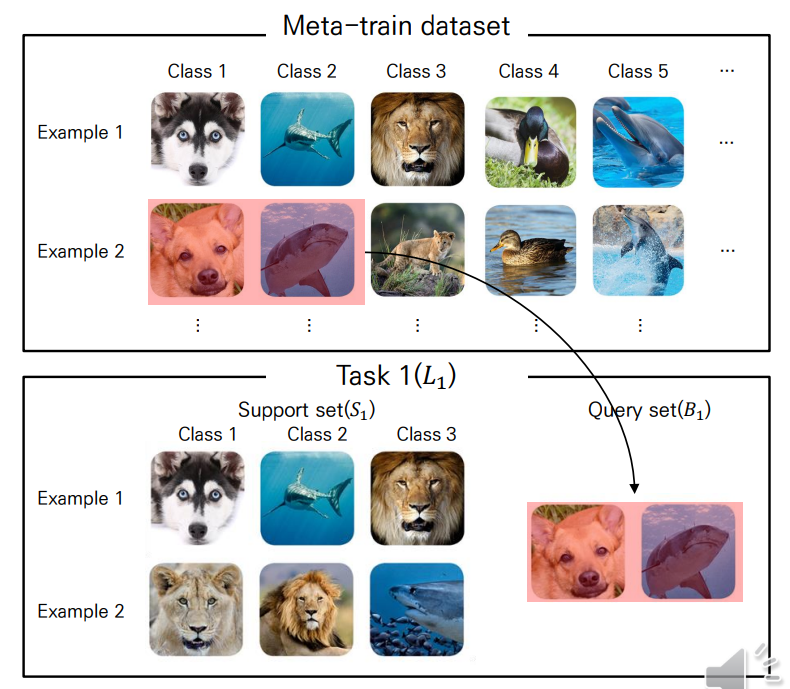
여기까지 하나의 에피소드입니다.
Maximize log-likelihood
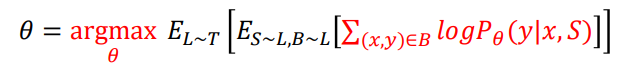
이렇듯 특정 Class와 example을 샘플링하는 에피소드를 여러 번 거치면서, Query set의 이미지 와 Support set 가 주어졌을 때, Query set의 label인 의 확률을 높히는 방향으로 parameter 를 최적화하게 됩니다.
위와 같이 학습을 진행한다면 실제 Meta-test dataset과 동일한 환경이 되기 때문에 좋은 성능을 내도록 학습할 수 있습니다.
2.3. Common Apporach
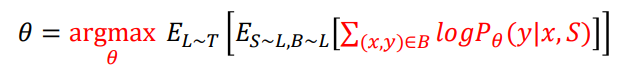
위와 같은 Objective를 보아하니, 일반적인 딥러닝 학습처럼 위에서 샘플링되는 의 집합을 mini-batch, 그리고 손실함수로 Negative log likelihood를 사용해 Gradient Descent 기반 방법론들을 사용하면 될 것 같은데..
애초에 딥러닝이랑 환경이 다르니 다른 방법들도 생각해봐야겠죠?
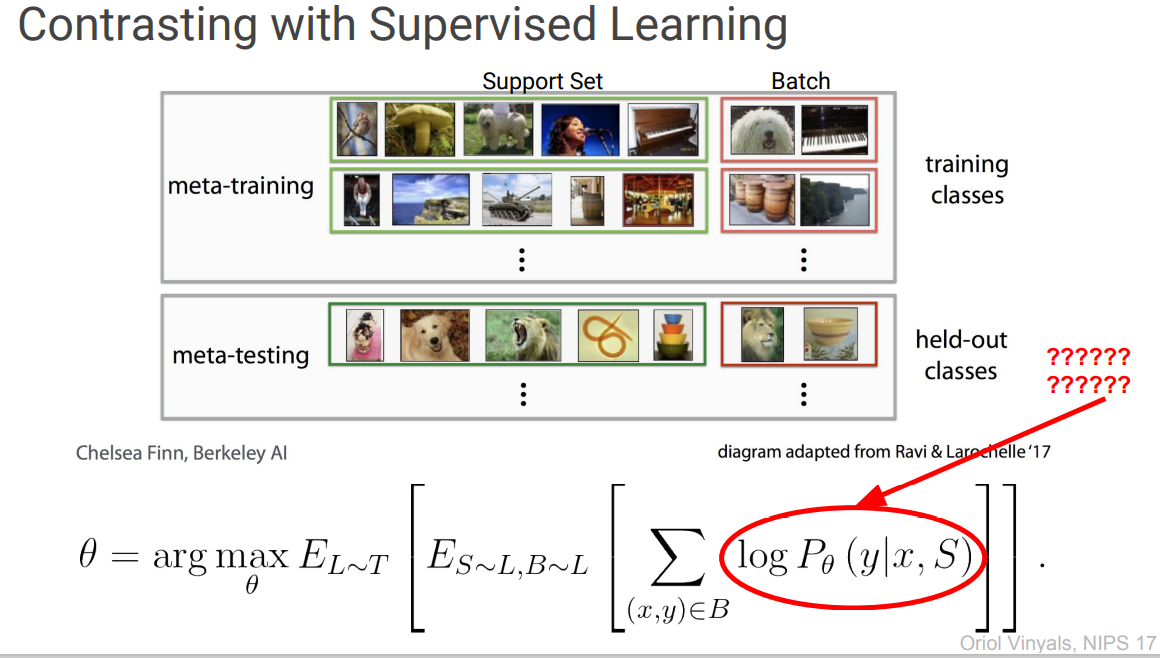
(Vinyals(Deepmind) : ???????? in NIPS 17)
학습을 위해서 제안되는 방법은 주로 아래와 같이 Model-based, Metric based, Optimization based 3가지로 나눌 수 있습니다.
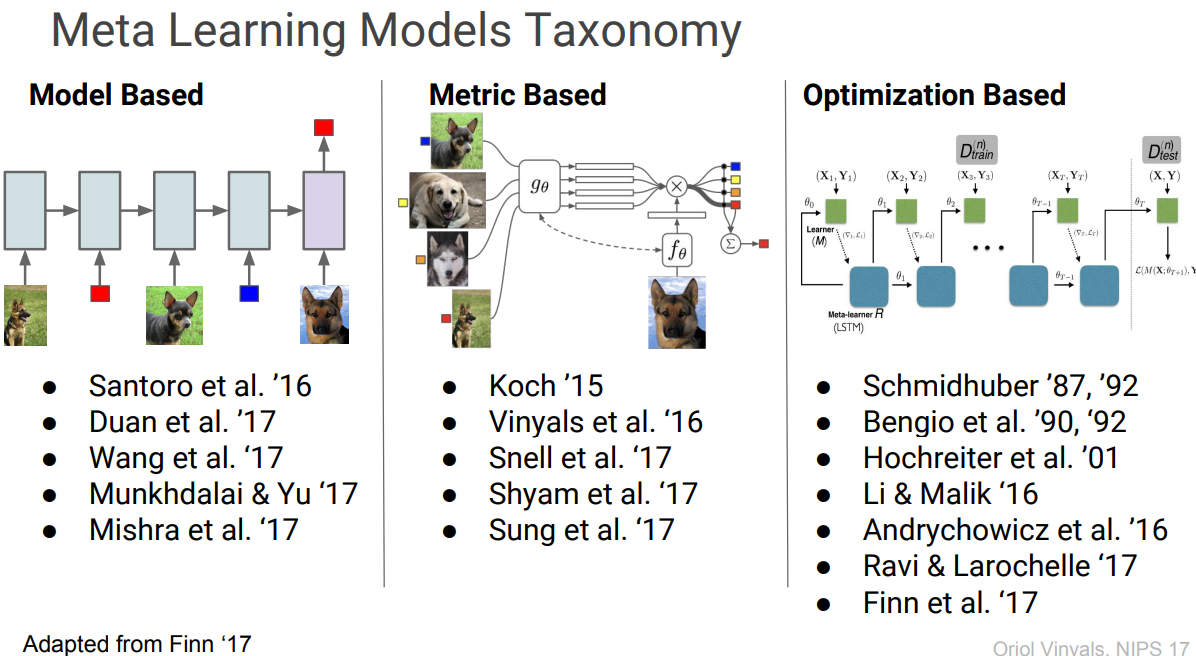
3. Types of Few Shot Learning
3.1. Model-based Meta Learning
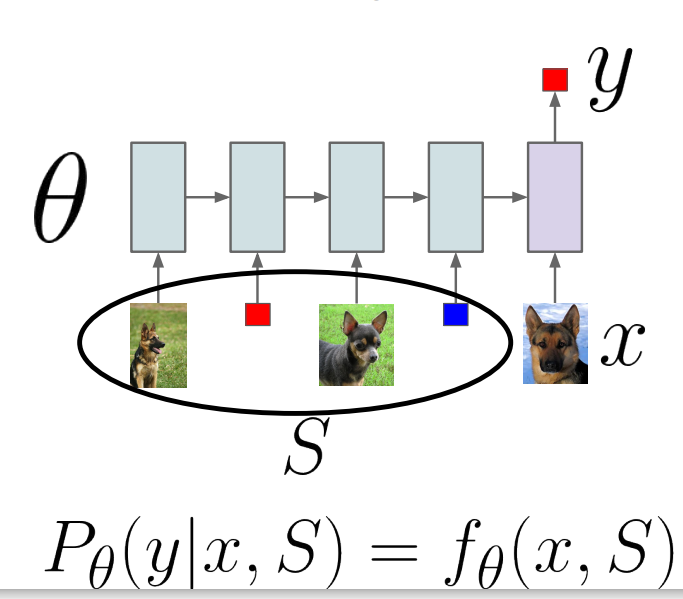
Model-based 방법론은 일반적으로 모델 를 활용해, Objective의 likelihood 를 정의합니다.
위의 그림과 같이 RNN 계열 모델처럼 정의한다면 [sigmoid/softmax] activation으로 probability 를 반환하고, 그 결과가 가장 좋은 hidden layer 내 를 weight로 사용하면 됩니다.
단, 애초에 적은 데이터를 사용하기 때문에 large dataset에 특화된 모델을 사용하는 것이 아닌, fast-learning에 특화된 모델을 사용하게 됩니다.
또한, 웬만한 것은 모델 에 맡기기 때문에 에는 어떠한 가정도 포함되지 않습니다.
Memory-Augmented Neural Networks (MANN)
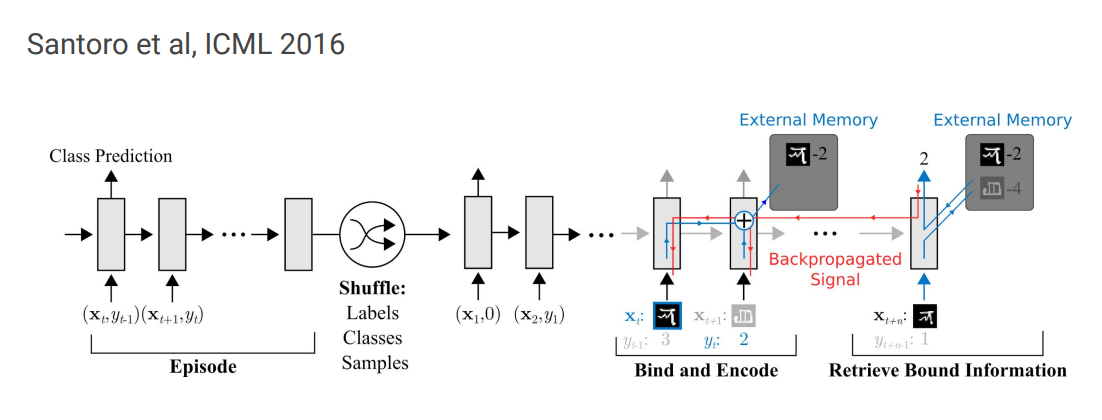
위와 같은 형태를 가지는 아키텍처는 학습을 위해 외부 memory storage를 활용합니다.
이런 storage buffer를 통해서 network는 새로운 정보에 대해 빠르게 이해할 수 있고, 미래에도 이 정보를 잊지 않을 수 있습니다.
Few-Shot Learning에 쓰이는 만큼 적은 sample 만으로도 빠르게 새로운 task에 적용할 수 있게끔 설계되어야 합니다.
즉, 새로운 task에 대한 정보를 빠르게 인코딩해 얻어낼 수 있어야 하고, 저장된 representation 또한 쉽고 안정적으로 접근할 수 있어야 합니다.
뿐만 아니라 기존의 정보를 잊지 않게끔 메모리 또한 존재합니다.
3.2. Metric Base Meta Learning
Metric-based meta learning의 근본적인 개념 자체는 K-Means clustering과 같은 알고리즘이나 density estimation과 유사합니다.
즉, 딥러닝처럼 대용량 데이터가 아닌, 소수의 데이터로도 충분한 관계성을 파악할 수 있는 metric(거리) 기반 방법을 활용하는 것입니다.
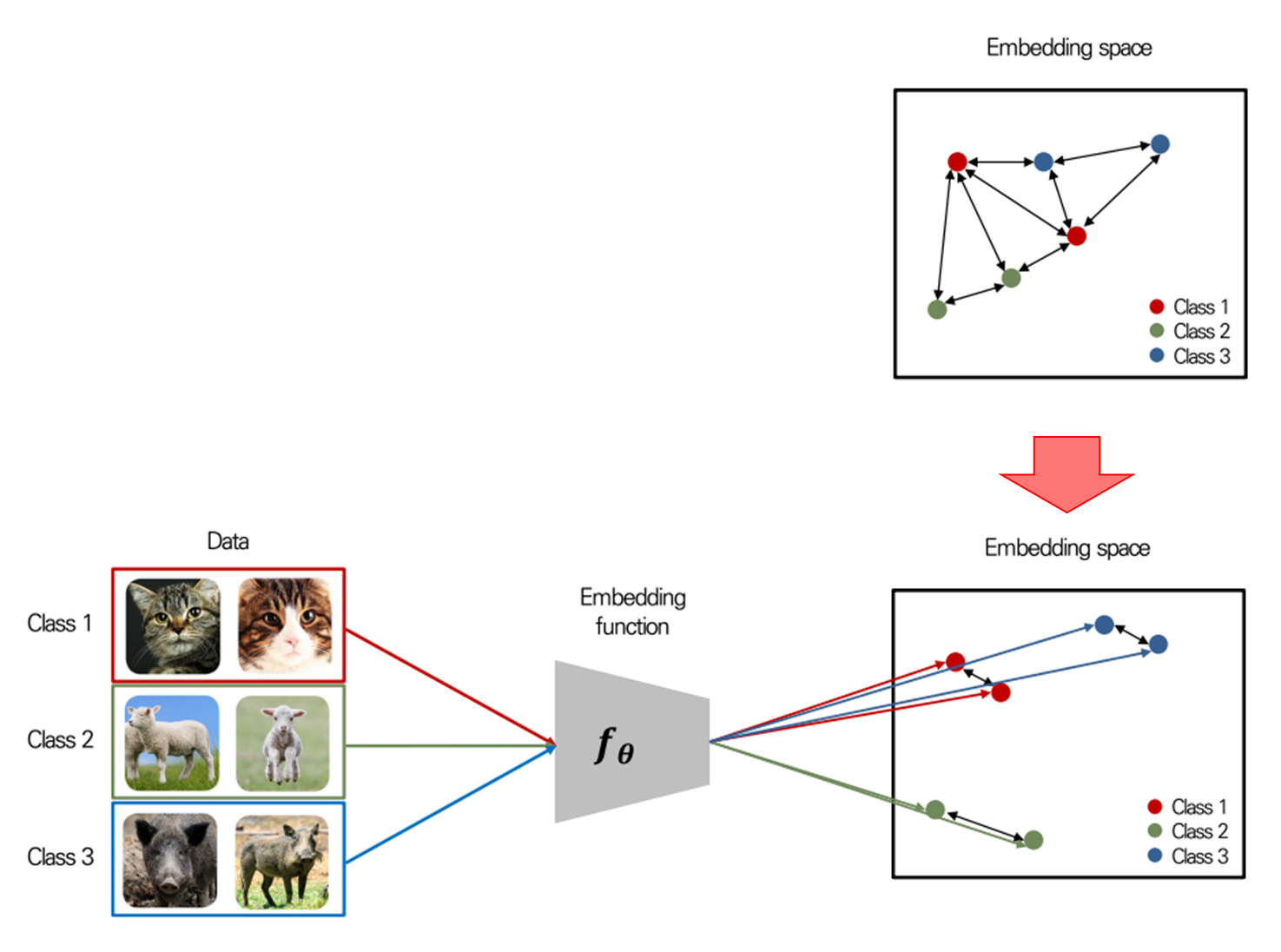
(2개의 데이터만 가지고도 충분히 관계성을 파악할 수 있게끔 Embedding function 를 학습할 수 있다)
다만 이를 위해서 Mapping function(Embedding function)을 잘 학습하는 게 목표가 되겠습니다.
Matching Networks for One Shot Learning(2016)

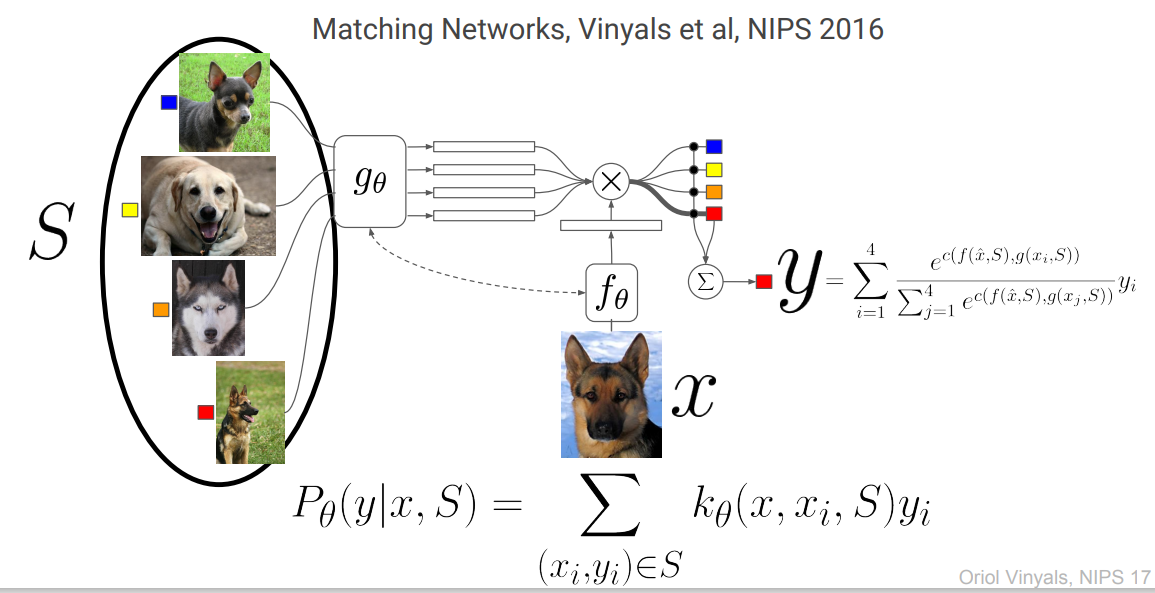
Matching Networks는 임베딩 함수를 활용해 최종적으로 Query set의 input 에 대응되는 label 의 distribution을 반환하는 네트워크입니다.
위 그림에서 볼 수 있다시피, 는 Support set의 임베딩 함수, 는 Query set의 임베딩 함수입니다.
위 저자들은 Embedding function으로 아래와 같은 모델을 제안합니다.
- Simple embedding()
- Conv-4
- Full contextual embeddings()
- : bi-LSTM
- : attLSTM
위의 임베딩 함수를 토대로 만들어낸 Query set의 임베딩 벡터 가 Support set의 임베딩 벡터 4개()와의 유사도를 구할 수 있습니다.
이 때 일반적으로 유사도함수 는 cosine similarity를 사용하고, soft-max를 거쳐 label의 weight(attention)로 사용됩니다.
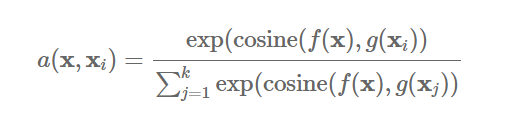
그리하여 아래와 같은 (query set의 label 에 대한) 최종 확률식이 나오게 되는 것입니다.
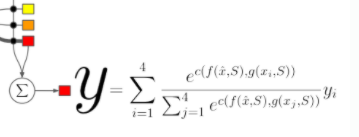
Other examples
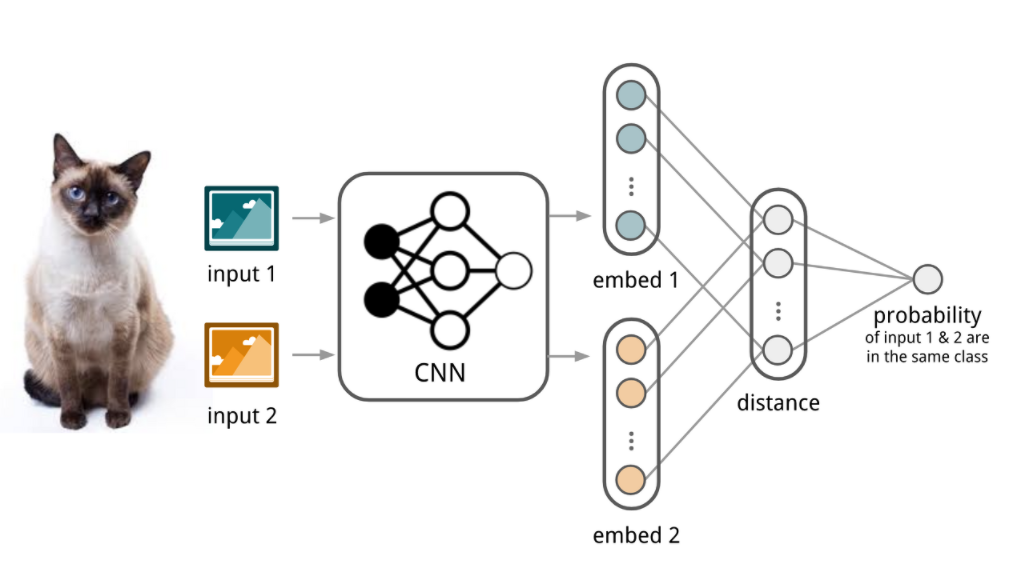
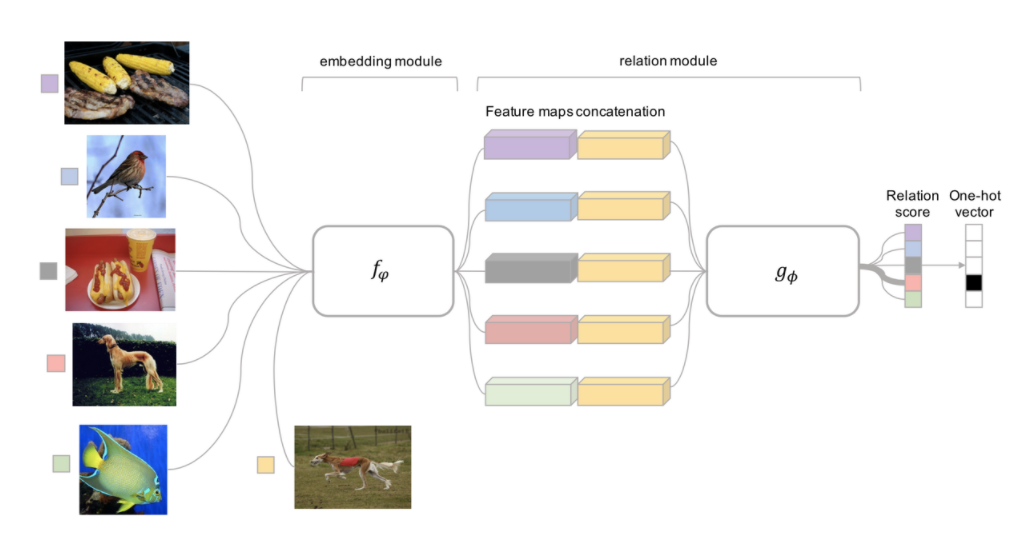
이외에도 twin CNN을 embedding에 활용하는 Convolutional Siamese Neural Network, 이를 개선한 Relation Network, 각 Class의 mean-point vector를 활용한 Prototypical Networks 등이 있습니다.
Convolutional Siamese Neural Network(2015)
Prototypical Networks(2017)
Relation Network(2018)
3.2. Optimization based Meta Learning
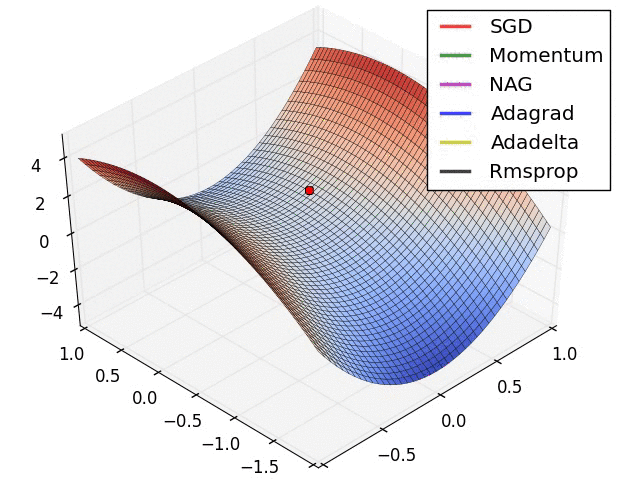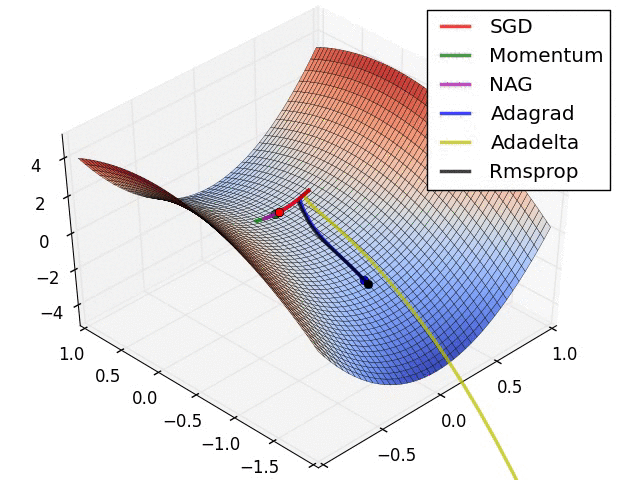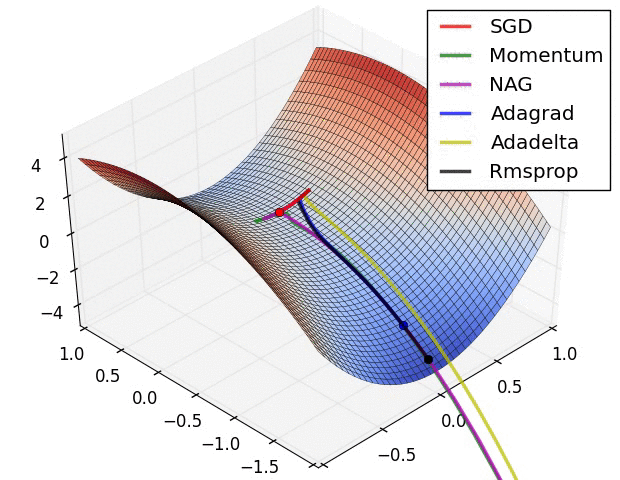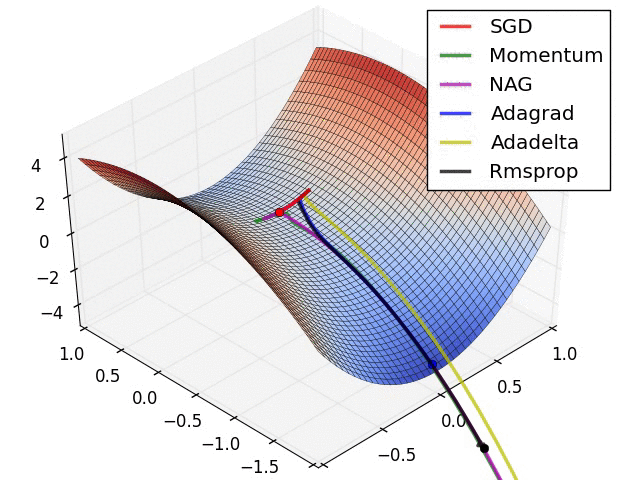
(대용량 데이터에 적합한 Gradient Descent 방법을 그대로 활용할 수는 없다).
Few-Shot learning에서는 단순하게 생각했을 때 여러 task에 대해 각기 다른 매개변수를 갖는 모델을 사용해야 합니다.
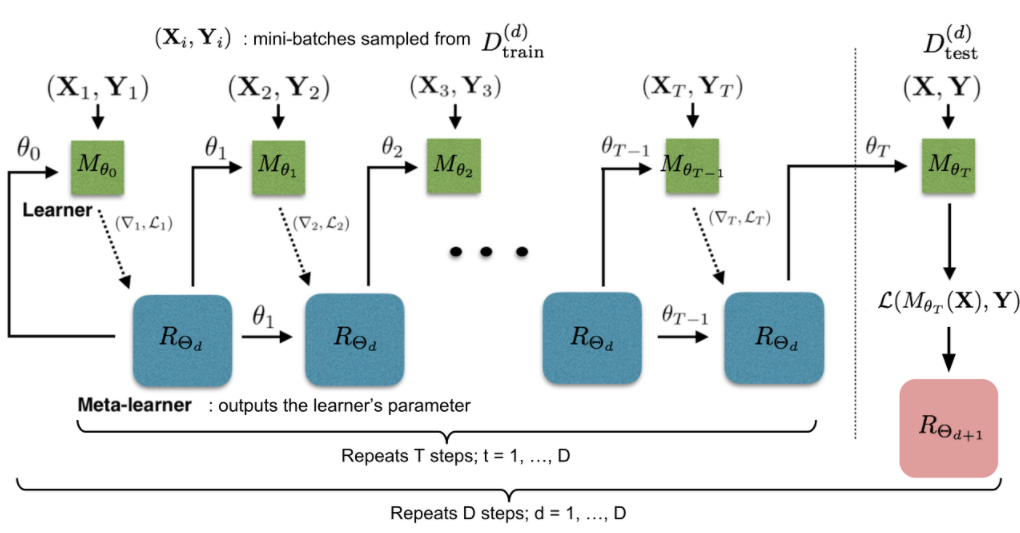
즉, 위 그림과 같이 Learner 이 여러 개 주어져 각각 task에 대한 Optimization을 수행하고, Meta-Learner 이 이런 정보를 받아 최종적으로 메타 러닝을 조절할 수 있습니다(LSTM 활용).
여기서는 보다 직관적인 모델인 Model-Agnostic Meta-Learning(MAML)에 대해서만 다루어봅시다.
3.2.1 MAML
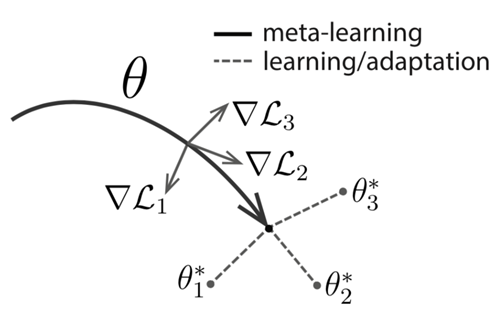
우선, update 식을 봅시다.
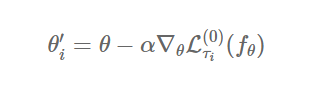
update하고자 하는 모델은 , 그리고 현재의 task는 입니다.
이 때는 그냥 우리가 아는 gradient descent 방식으로 새로운 parameter 를 얻으면 됩니다.
다만, 우리의 목표는 하나의 task가 아닌, 다양한 task에 일반화시키는 것입니다.
즉, 여러 task에 대해 빠르게 적응할 수 있는 최적의 parameter 를 찾기 위해 Meta-update를 수행해야 합니다.
이 때에는 여러 task에 대해, task-specific으로 얻었던 여러 를 이용해, 이전과는 다른 데이터를 활용해 업데이트하게 됩니다.
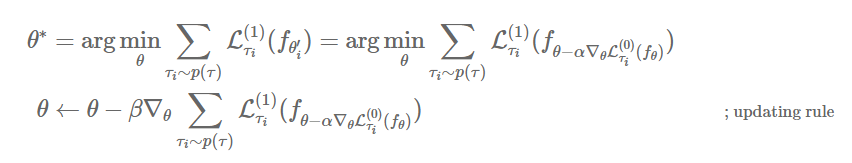
이에 대해 일반화된 알고리즘은 아래와 같습니다.

해당 모델은 물론 초기 모델에 가깝기 때문에 여러 단점도 많습니다만, 메타러닝의 사실상 목표인 "다양한 task에 일반화된 weight 찾기"를 가장 잘 보여주는 모델입니다.
4. Trend in Few-Shot
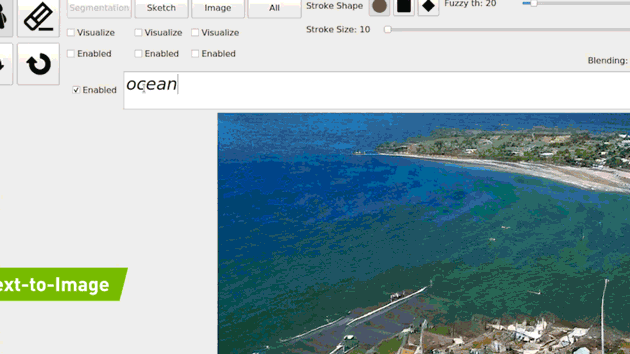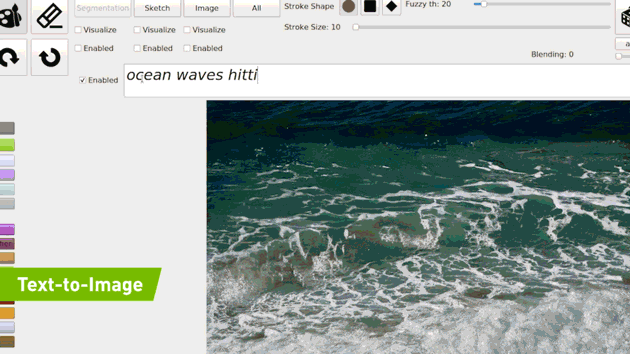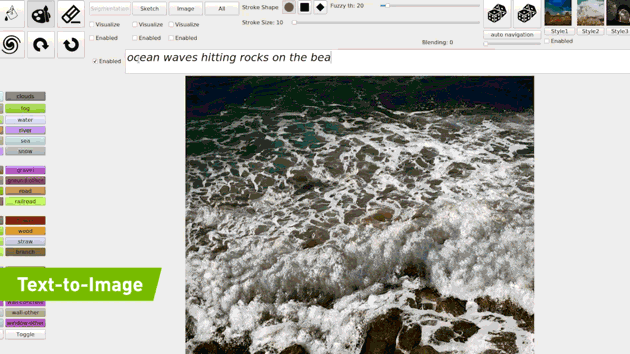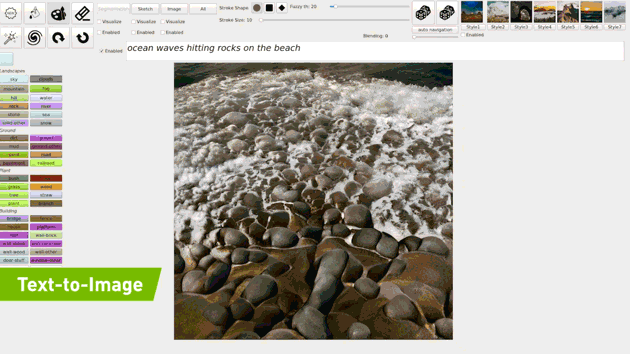
4.1. ZERO-SHOT Text-to-Image Generation
- 특정 문장을 아예 학습하지 않고(Zero-shot) 문장에 대한 이미지를 생성하는 모델입니다(DALL-E).

- 그걸 Real-time 으로 진행하는 모델(GauGAN2)
Few-Shot 방식으로 예상은 하나, 아직 논문은 안 나와서 확실하지 않습니다.
4.2. Few-Shot Object Detection

딥러닝 분야의 미래 중 하나라고 할 수 있는 Few-Shot Learning에 대해 알아보았습니다. !
Ref
https://talkingaboutme.tistory.com/entry/DL-Meta-Learning-Learning-to-Learn-Fast
Meta-Learning in Neural Networks: A Survey
https://velog.io/@tobigs_xai/6%EC%A3%BC%EC%B0%A8-Introduction-to-Meta-Learning
https://velog.io/@tobigs-gm1/Few-shot-Learning-Survey
https://evolution.ml/pdf/vinyals.pdf
