[10주차] (MAML) Model-agnostic Meta Learning for Fast Adaptation of Deep Networks 논문 리뷰
Model Agnostic Meta-Learning for Fast Adaptation of Deep Networks review
1. Introduction
MAML의 키워드는 'Model Agnostic'과 'Fast adapation'입니다.
Model Agnostic은 모델에 상관없이 적용 가능하다는 의미로, gradient descent방식을 사용하는 모든 모델에 MAML을 적용 가능하다는 의미입니다.
Fast adaptation은 새로운 task를 빠르게 (적은 update) 학습할 수 있다는 의미로, 메타러닝의 핵심 개념에 해당합니다.
MAML은 여러 task에 대해서 적합한(broadly suitable for many tasks) 모델을 학습하면 세부 task 에 적용할 때 fine-tuning 과정이 빠를 것이라는 아이디어에 기반합니다.
메타러닝의 3가지 접근 방식 중 Optimization-based 방식에 해당합니다.
2. Model Agnostic Meta-Learning
자료 출처 : DMQA 세미나
MAML 알고리즘은 9주차에서 다루었던 것과 같습니다.

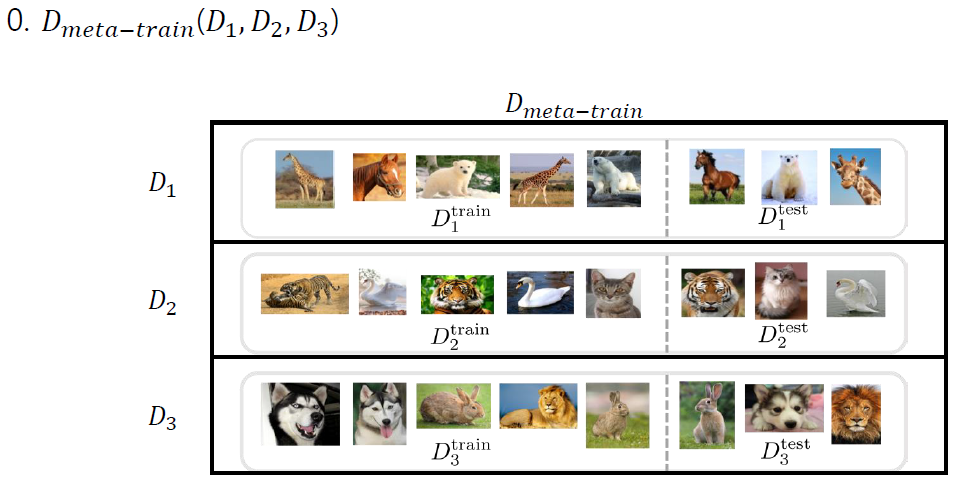
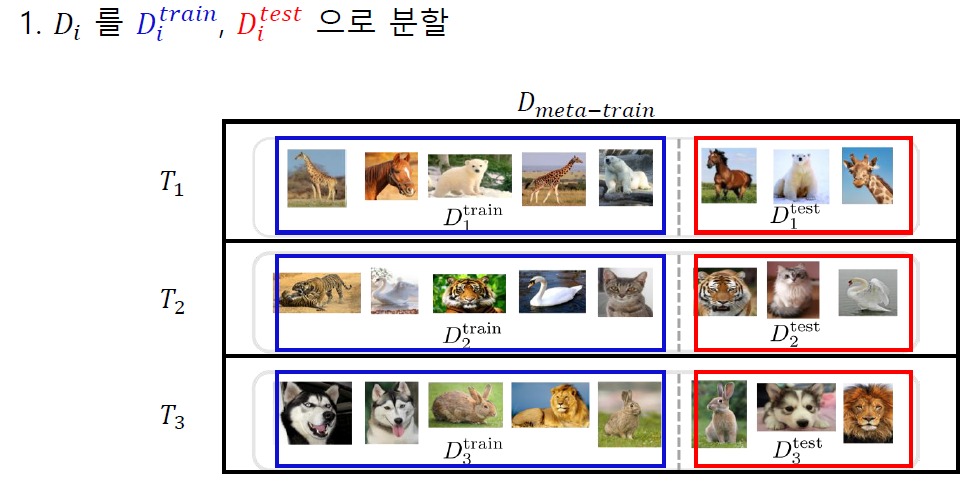
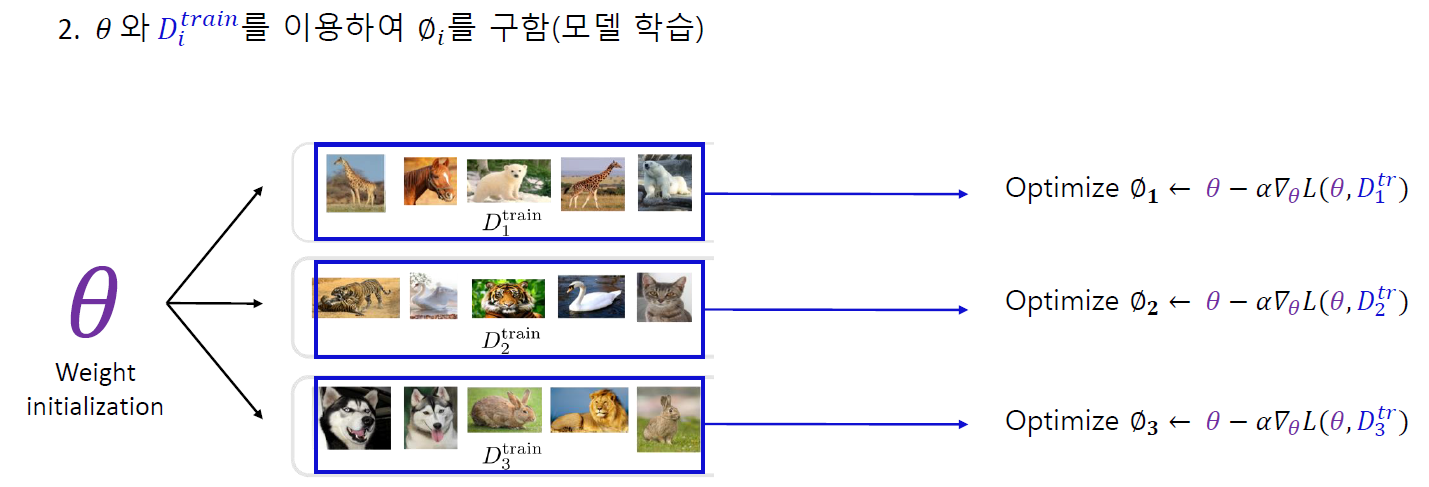

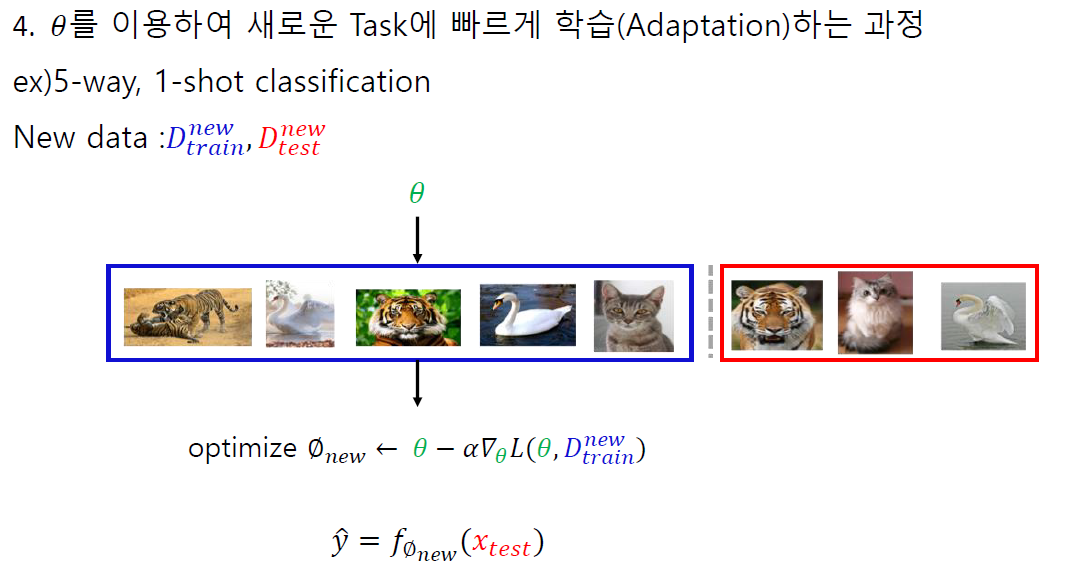
MAML의 구체적인 학습 목표는 개별 task에서 계산된 Loss의 합을 최소화하는 것입니다.
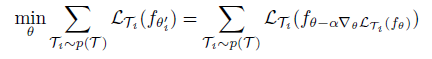
MAML 알고리즘은 어떠한 내재된 representation이 다른 태스크에 더 잘 적응할 수 있는 (transferrable, broadly applicable) 성질을 가질 수도 있지 않을까 라는 생각에서 출발하였습니다. 예를 들면, 어떠한 representation은 각각의 task 측면보다 general한 측면에서 더 적절할 것입니다. (실제로 파라미터가 이것에 해당합니다.)
논문의 표기법을 따르자면, 모든 task의 분포 'P(t)'의 representation을 찾는다는 것입니다.
그런 representation이 존재한다면, 그것을 어떻게 찾을 수 있을까요?
모델이 gradient 기반 학습 방식으로 fine-tuned 될것이기 때문에 gradient learning 방식이 개별 task에 대해서 크게 변화하는 방식으로 모델을 학습시켰다고 합니다. 즉, 모델 파라미터는 task의 변화에 대해 민감해서 파라미터의 작은 변화가 개별 task의 loss에 큰 향상을 주는 방식입니다.
파라미터가 task의 변화에 민감하면 새로운 task를 마주했을 때 적은 데이터만으로도 adaptation이 가능할 것입니다.
결국은 파라미터 를 최적화하는 것이기 때문에 모델의 최적화는 새로운 task에서 적은 수의 gradient step이 해당 task에 대해 가장 효과적인 향상을 이끌어내도록 하였습니다. (메타러닝의 기본 목적과 같은 맥락)
3. Species of MAML
3가지 모델 (Regression, Classification, RL)을 다루는데, loss에만 차이가 있습니다. (line 10의 loss 부분)

3.1 Supervised Regression and Classification

: input, output pair sampled from task (K-shot 에서 pair가 K개)
regression의 경우에는 MSE를 다음과 같이 사용하고,
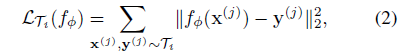
classification의 경우에는 cross-entropy loss를 다음과 같이 사용합니다.
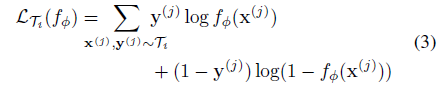
우리가 알고 있는 MSE와 Cross-entropy가 동일하게 각 task의 데이터에 적용된 형태임을 알 수 있습니다.
3.2 Reinforcement Learning

RL의 loss함수는 다음과 같습니다.
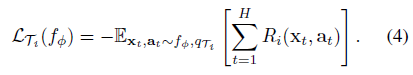
5. Experimental Evaluation
다음 3가지 질문에 대해 실험을 진행합니다.
- MAML이 새로운 task를 빠르게 학습할 수 있는가?
- MAML이 여러 도메인에 적용될 수 있는가? (회귀, 분류, 강화학습)
- MAML로 학습한 모델이 gradient update를 계속할때 더 개선되는가?
Regression task
- NN 모델, K = 5, 10, sin 함수를 예측
성능 평가를 위해 MAML모델과 메타러닝을 사용하지 않은 Pre-trained 모델로 Few-shot adaptation을 실행시킨 결과를 비교하고 있습니다.
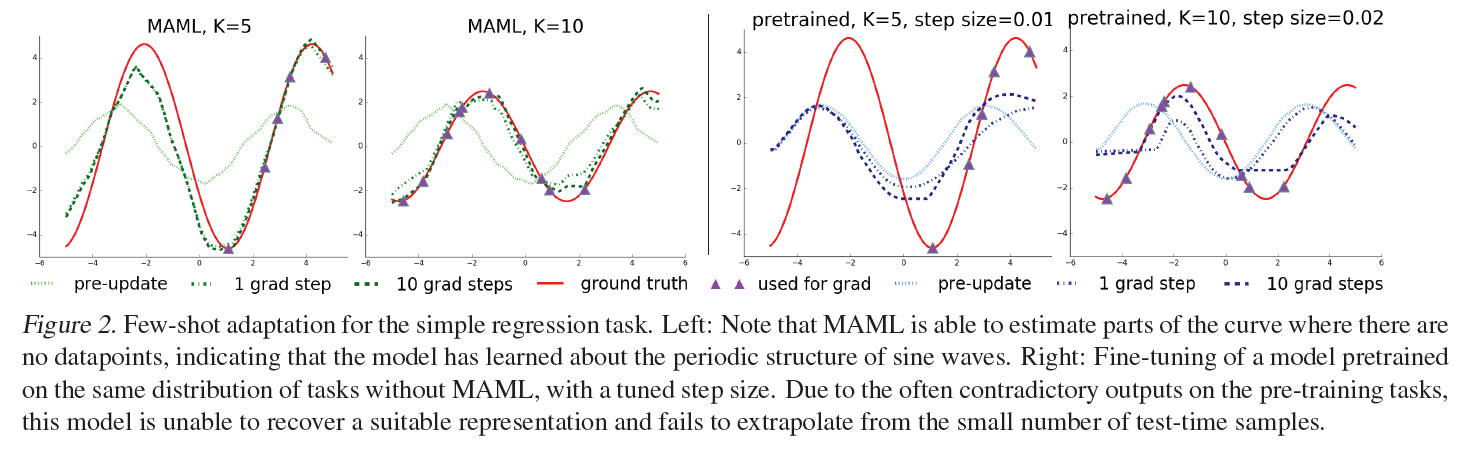
왼쪽의 두 그래프는 MAML 모델의 예측을 나타낸 것이고, 오른쪽의 두 그래프는 pre-trained 모델의 예측을 나타낸 것입니다.
연두색 : MAML update 이전
초록색 : MAML update 후
빨간색 : Ground truth
보라색 ▲ : test에 사용되는 K개의 data points
MAML 모델은 모두 update 이전에는 pre-trained와 유사하게 예측하지만, update 이후에는 ground truth 와 상당히 유사하게 예측하는것을 알 수 있습니다. 반면, pre-trained는 step이 늘어나도 비교적 변화가 작고, ground truth와는 상이합니다.
또한, 보라색 ▲ 데이터가 일부 구간에만 몰려있음에도 불구하고 MAML은 데이터가 없는 구간도 잘 예측하고 있음을 알 수 있습니다. MAML 모델이 sin 함수의 주기성을 잘 파악한 것으로 추정됩니다. (1번 질문에 대한 답)
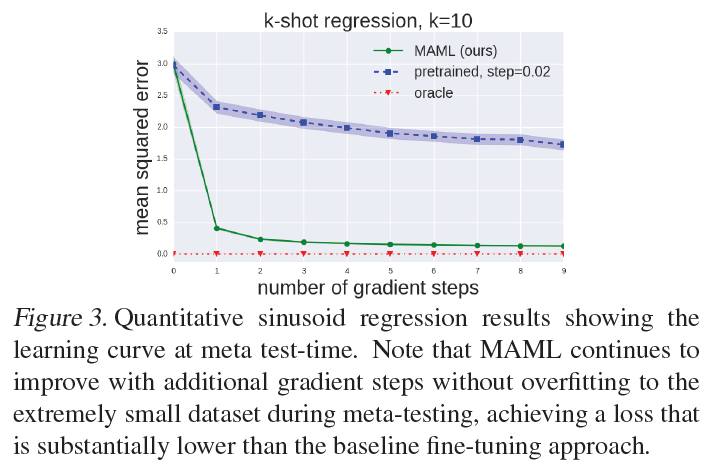
MAML의 Learning curve를 보면 gradient step이 늘어나면서 MAML이 에 대해 오버피팅되지 않고 계속 향상되고 있음을 알 수 있습니다. (3번 질문에 대한 답)
Classification
- 9주차에 등장했던 Omniglot dataset과 MiniImagenet 데이터를 활용하여 실험, CNN 사용

실험 결과는 다음과 같습니다.
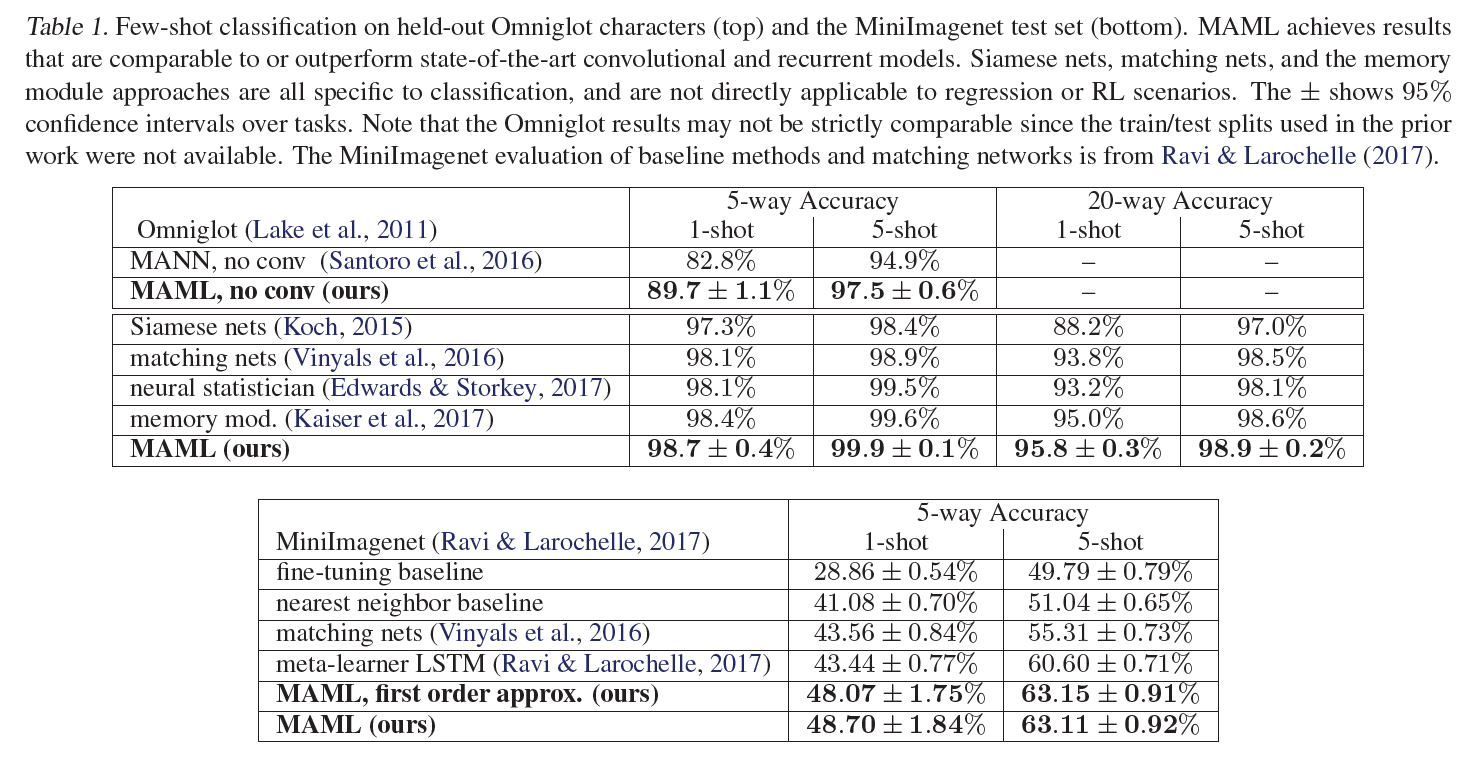
비교하는 모델로 다른 메타러닝 방법인 Siamese Networks, Matching Networks 등을 이용했습니다. MAML no conv 모델은 CNN이 아닌 단순 4-layer NN 구조를 사용한 MAML로, MAML의 flexibility를 실험하기 위해 비교하였다고 합니다. MAML이 가장 좋은 성능을 보입니다.
MAML이 Matching networks와 meta-learner LSTM보다 더 적은 파라미터를 사용하는데도 더 좋은 성능을 보입니다.
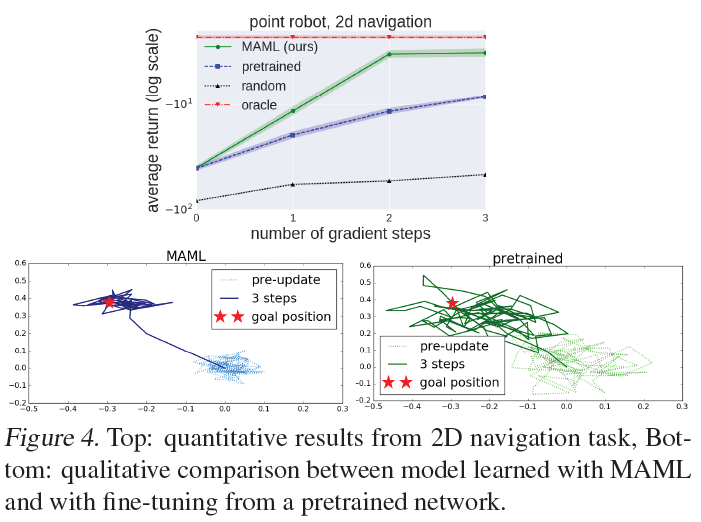
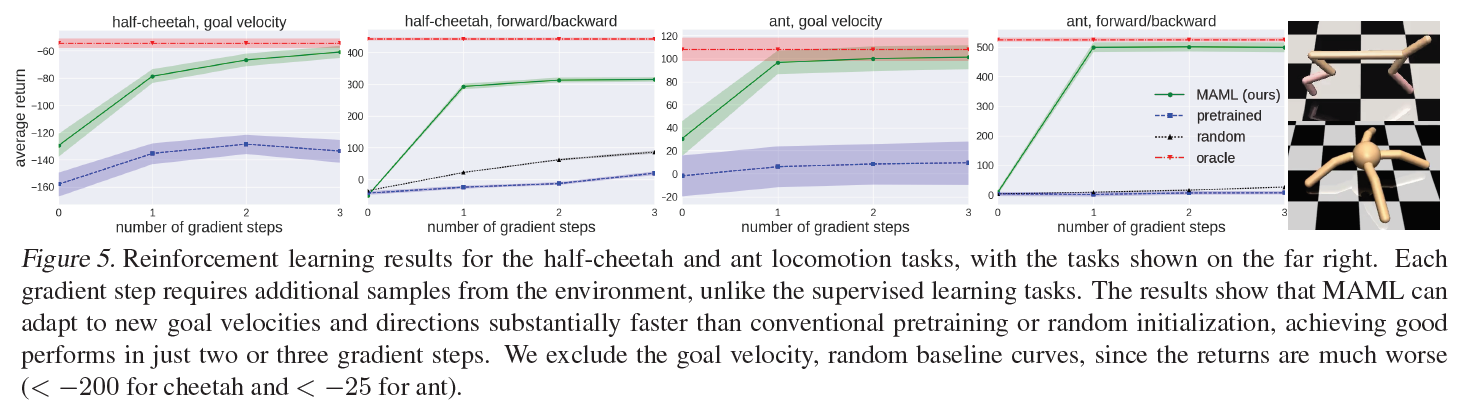
Reinforcement Learning
- 2D Navigation, Locomotion
다른 논문에서의 언급 (Survey)
Meta-Learning in Neural Networks: A Survey 에서는 16번 언급
-
유명한 parameter initialization 방법





-
전체 task의 분포를 고려하는 방법 (Optimization 방법)

-
다양한 관련 후속 연구
Bayesian MAML, Online MAML, combined with autoencoders ...
Initialization 관련해서 언급된 것이 가장 많았고, 굉장히 유명한 논문인 것은 틀림 없습니다. MAML을 이용한 후속 연구도 굉장히 많이 이루어졌습니다.
참고자료
https://chioni.github.io/posts/maml/
http://dmqm.korea.ac.kr/activity/seminar/265
