Xai는 기존 인공지능 위에 설명성을 부여하는 기법입니다. 따라서 전통적인 머신러닝 모델 혹은 딥러닝 모델에만 적용할수 있는 xai 기법도 있고, 모델의 제약 없이 적용 가능한 방법도 있습니다.
4단원에서는 전통적인 머신러닝에 적용가능한 xai기법을 배울 것입니다.
Feature Importance (피쳐 중요도, = permutation importance)
- 개념
- 데이터의 피쳐가 알고리즘의 정확한 분류에 얼마나 큰 영향을 미치는지 분석하는 기법
- 특정 피쳐의 값을 임의의 값으로 치환했을 때 원래 데이터보다 예측 에러가 얼마나 더 커지는지를 측정하는 것
- 특정 피쳐를 변형했을 때 모델의 예측 결과가 크게 달라졌다면, 모델은 이 피쳐에 대한 의존도가 높고, 이 피쳐는 중요도가 높다
- 피쳐 간 의존성이 낮을 때 적합
- 계산 방법
- 주어진 모델의 에러를 측정한다 (e_original)
- 피쳐 매트릭스 X의 피쳐 k개에 대하여
a. 피쳐 k를 매트릭스 X에서 임의의 값으로 변경하여 피쳐 매트릭스 X_permutation을 만든다
b. 바꾼 X로 모델 에러 측정 (e_permutation)
c. 피쳐 중요도 산정 (e_permutation/e_original 또는 에러의 차이) - 피쳐 중요도를 구한다
부분 의존성 플롯 (PDP)
- 개념
- 영향력을 알고싶은 피쳐의 수치를 선형적으로 변형하면서 목표값(y) 얼마나 증감하는지를 시각화
- 피쳐 자체를 변형했던 피쳐 중요도 방법과 달리 피쳐의 수치를 변형
- 피쳐의 값이 변할 때 모델에 미치는 영향을 가시적으로 이해 가능 (직관적)
- pdpbox 패키지로 구현
- 부분의존성이 계산되는 피쳐는 다른 피쳐들과 상관관계가 없다고(독립성) 가정
- 최대 3차원까지만 표현이 가능하기 때문에 1개 또는 2개의 피쳐에 대해서만 시각화 가능
다음은 PDP의 예시입니다.
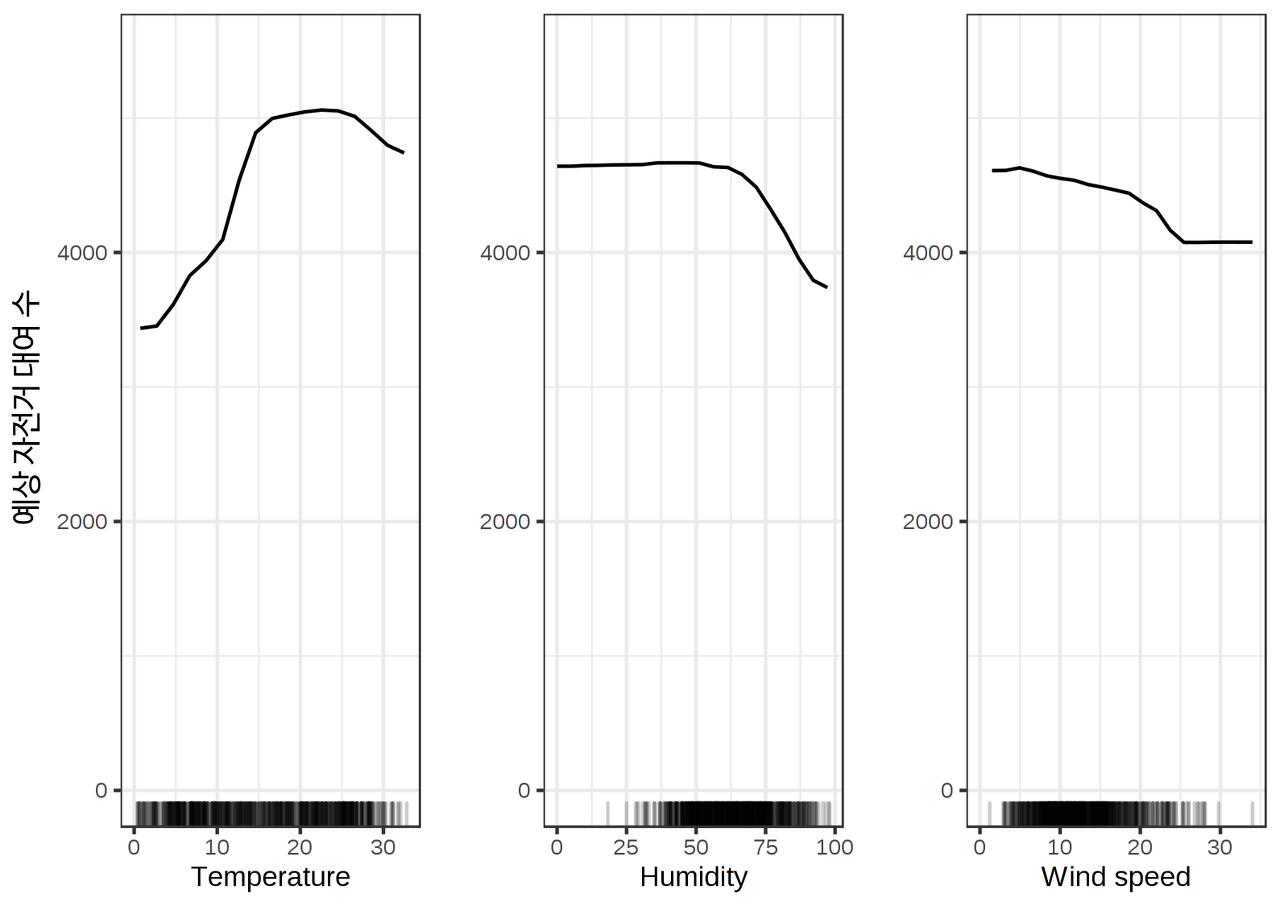
주어진 기간에 대여될 자전거의 수를 예측하는 문제에서 부분의존성을 그린 플롯입니다. 너무 춥거나 덥지 않을 때에 자전거 대여량이 많고, 습도가 너무 높아지면 자전거 대여량이 적어집니다.
여기서 염두에 둘 부분은 데이터의 분포입니다. 풍속이 높은 경우에는 대여량이 낮은 상태에서 변화하지 않는 것처럼 보이는데, 그래프 하단의 데이터 분포를 보면 이것은 데이터가 없어서 나타난 현상입니다.
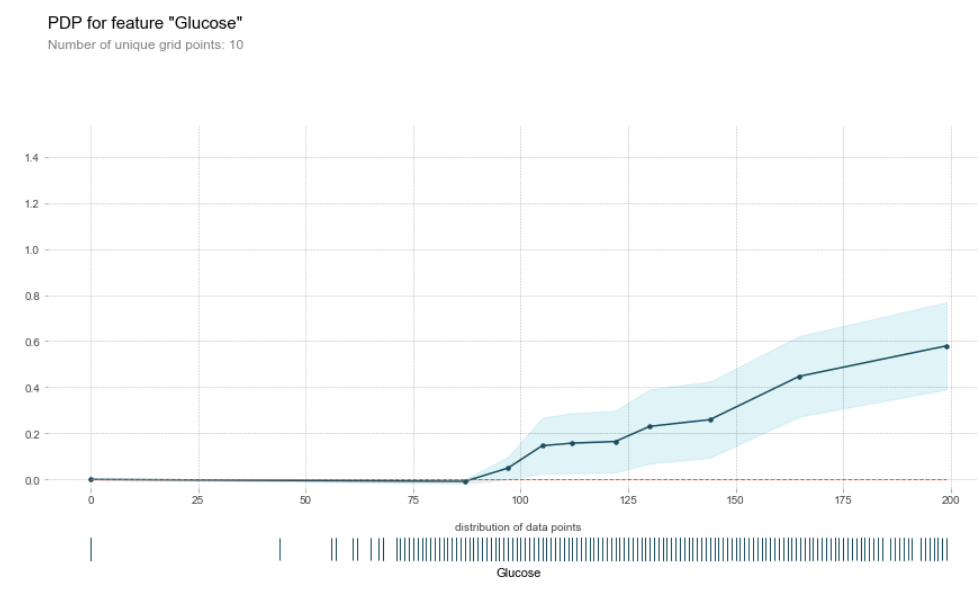
영향력을 알고 싶은 피쳐 'Glucose' 값을 고정했을 때 다른 피쳐들의 조합으로 나타난 결과가 하늘색 음영에 해당하는 부분입니다. 이 값들을 평균하여 부분의존성을 구합니다.
**Y축 : 영향력을 알고싶은 결과값. ex)자전거 대여 수, 집값 등
- 계산 방법
출처 - https://www.youtube.com/watch?v=hV6FsDBMtx0
(PDP에 대해 설명이 잘 되어있는 영상이니 참고하시면 좋을것 같습니다 :) )

부분 의존성 함수는 다음과 같이 정의됩니다
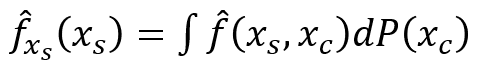
몬테카를로 방법을 이용하여 부분함수는 다음과 같이 추정됩니다
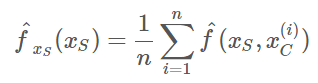
x_s는 부분 의존성 함수가 시각화할 피쳐, x_c는 해당 피쳐를 제외한 나머지 피쳐들로 타겟변수(y)의 변화 예측 시에 사용됩니다.

XGBoost
- 개념
XGBoost는 기본적으로 부스팅 기법을 사용합니다. 부스팅의 원리는 정규세션 Ensemble 강의에서 설명했었습니다
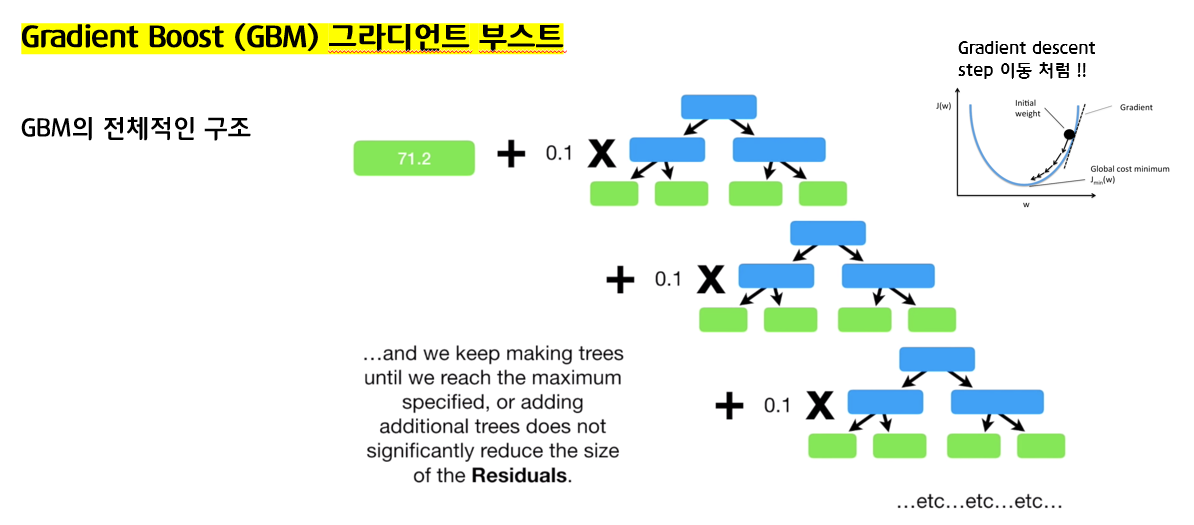
XGBoost는 GBM의 구조와 아주 유사한 구조를 가지고 있습니다.
출처 - https://www.youtube.com/watch?v=OtD8wVaFm6E
이 영상 또한 XGBoost의 계산 과정을 자세히 설명하고 있으니 참고하세요~
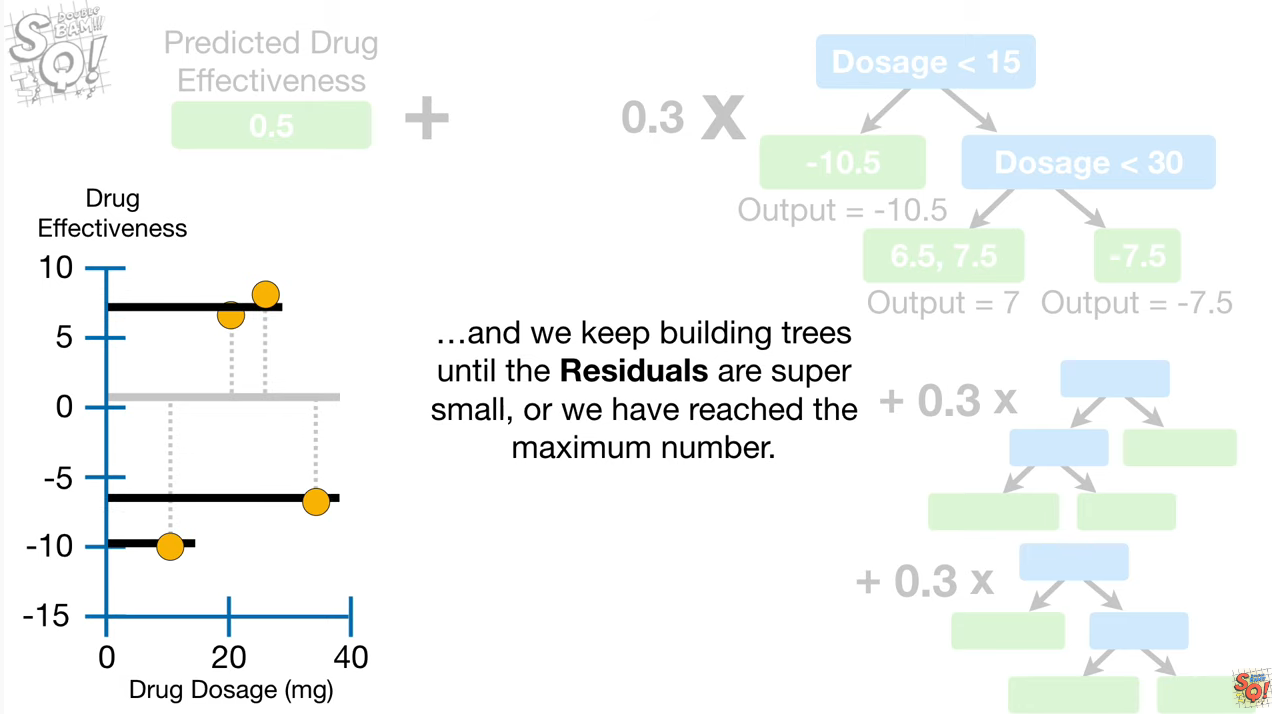
XGBoost는 Greedy Algorithm을 통해 약분류기 트리 M(X), G(X), H(X)를 생성하고, 분산처리를 통해 각 트리의 가중치를 빠르게 찾아냅니다.
우리가 예측하고자 하는 타겟 Y는 위와 같이 예측됩니다.
XGBoost의 과정을 정리하자면 다음과 같습니다.
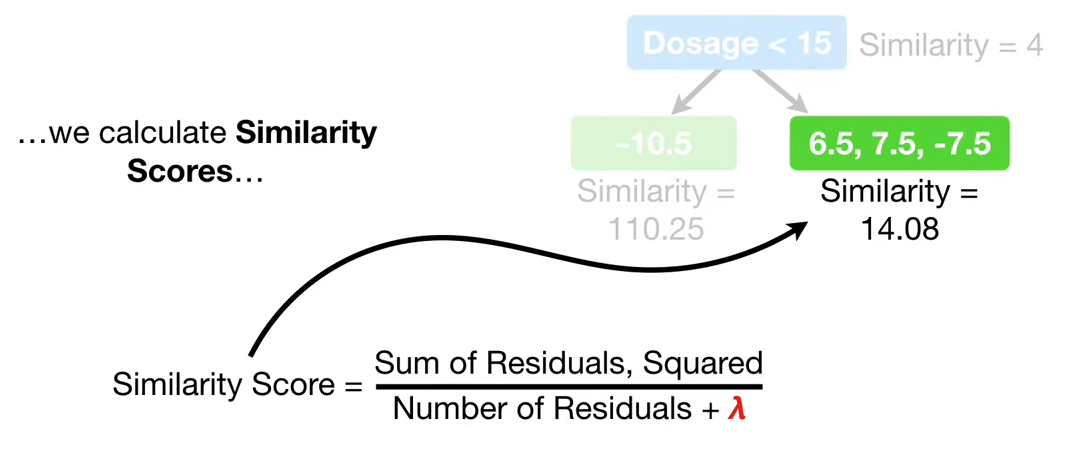

먼저, split을 한 후, 각 child 노드의 Similarity와 Information Gain을 계산합니다.

gamma는 사용자가 지정한 트리 복잡도 파라미터입니다. Gain에서 gamma를 뺀 값이 음수이면 해당 branch를 prune합니다.
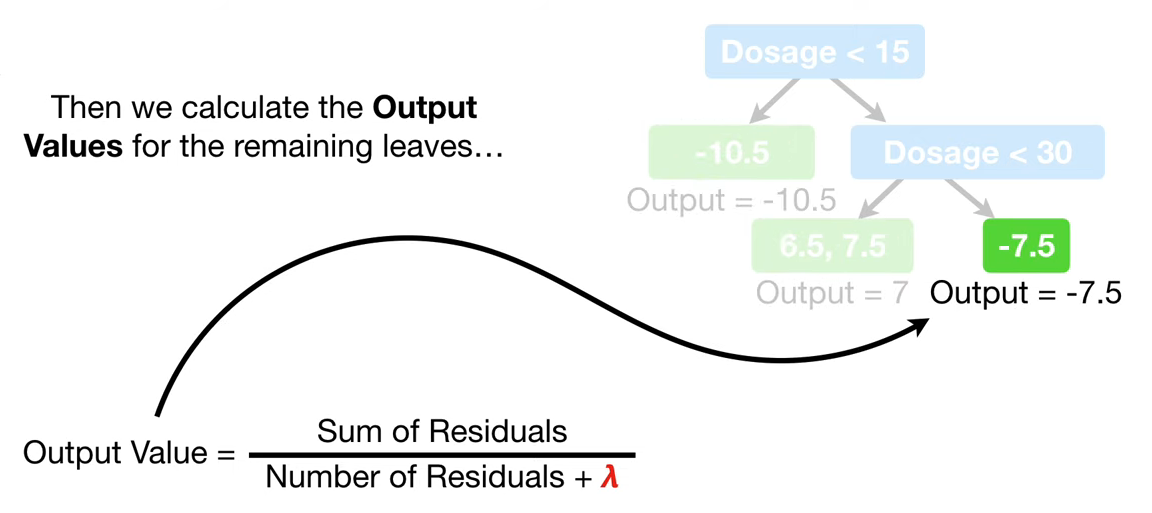
Pruning 결정 후, 트리가 완성되면 각 leaf node의 output values를 계산합니다.
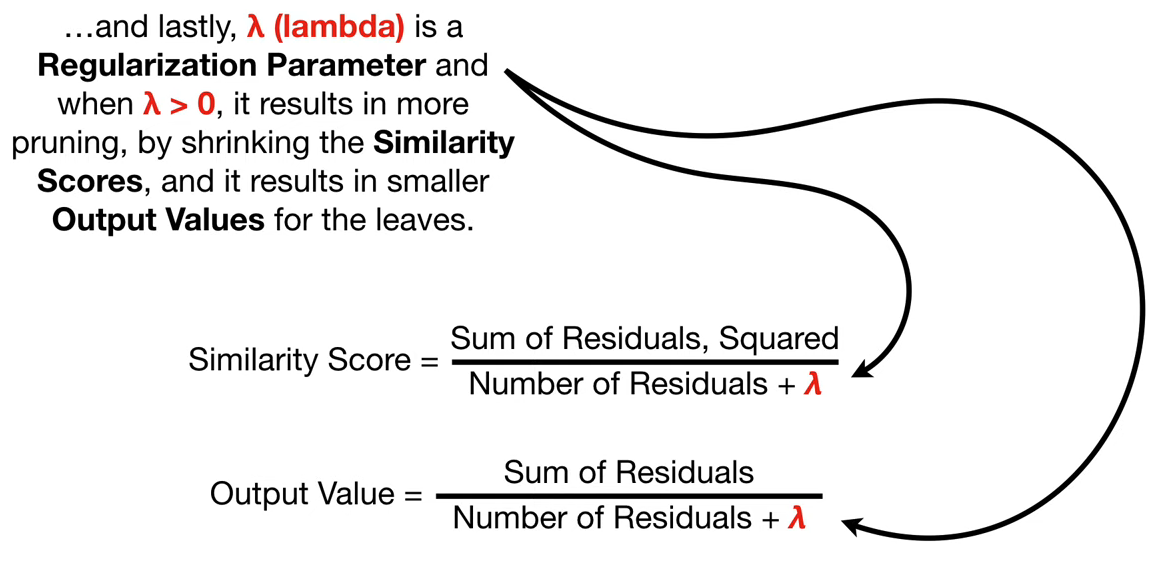
lambda는 오버피팅을 방지하는 역할을 하며, output value와 similarity score의 분모에 더해줍니다.
- 특징
XGBoost는 다음과 같은 6가지 특징을 가지고 있습니다. 이 중, 과정 설명 부분에서 다루어지지 않은 Parallelized tree building과 Efficient handling of missing data에 대해 더 자세히 살펴보겠습니다. Cache awareness and out-of -core computing부분은 기술적인 부분에 속해 다루지 않겠습니다. 더 궁금하신 분은 논문이나 자료를 참고해주세요~
참고자료 - https://www.youtube.com/watch?v=VHky3d_qZ_E (논문 내용 설명 강의- 강필성교수님)
논문 - https://arxiv.org/pdf/1603.02754.pdf
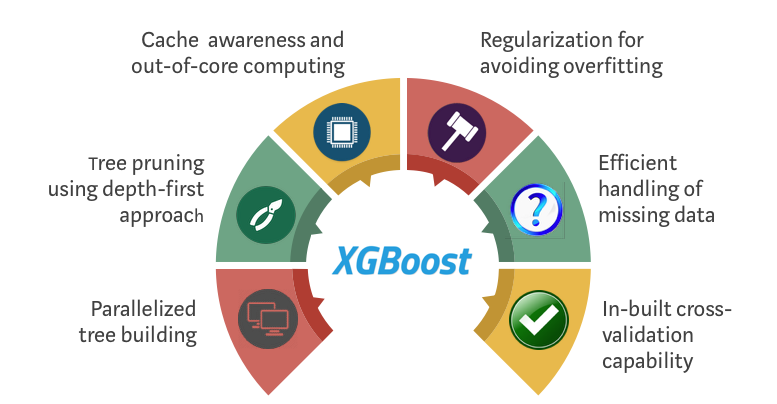
1. Parallelized tree builing
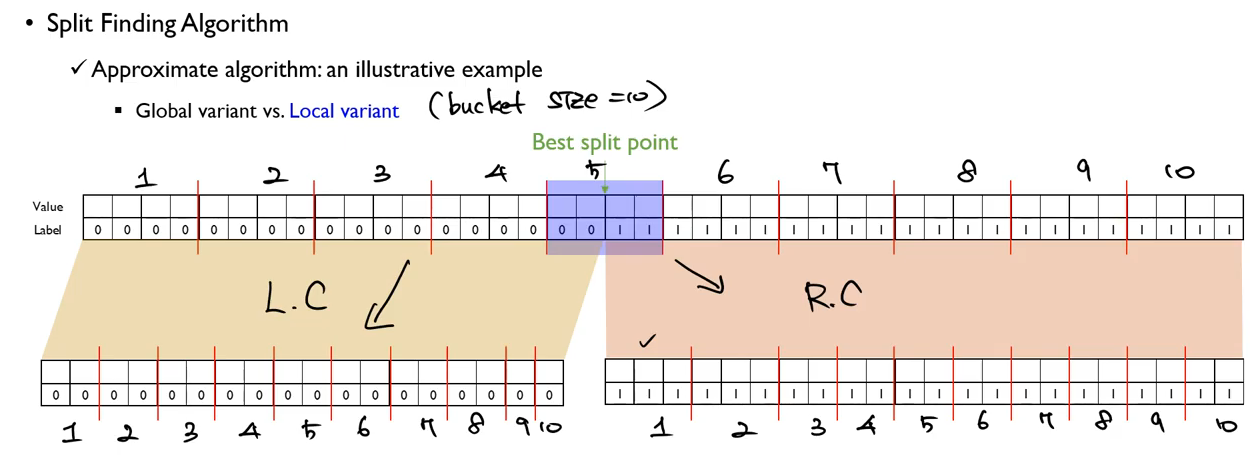
- Split Finding

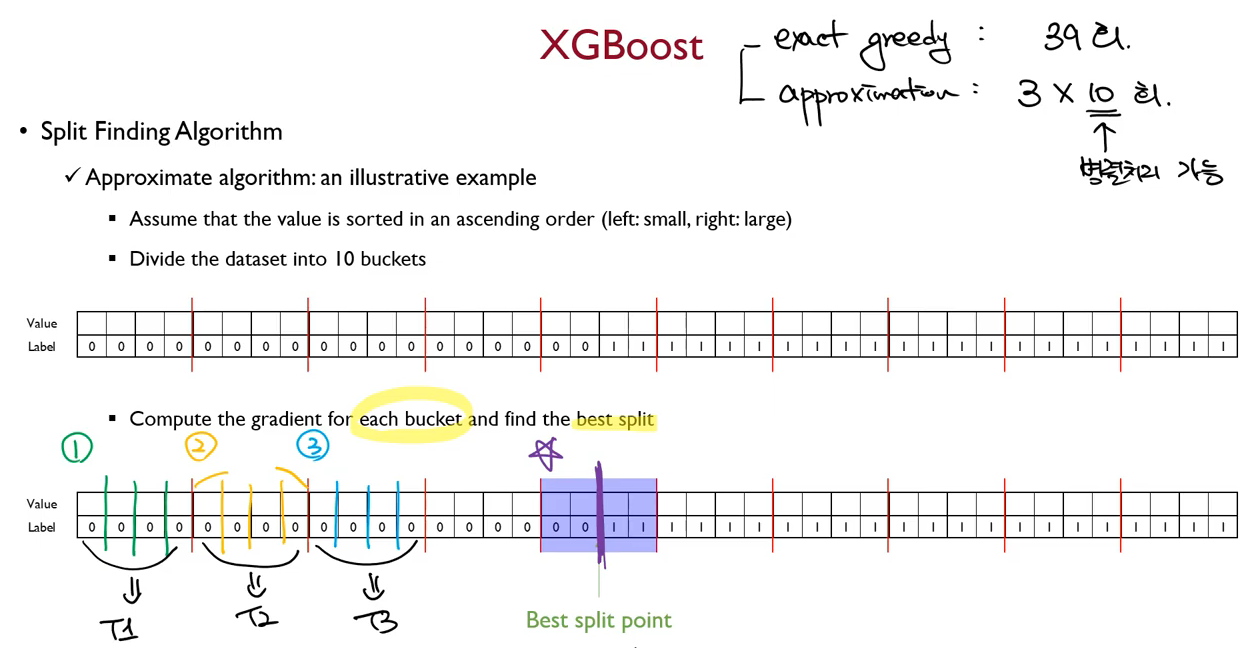
여러개의 bucket으로 데이터를 split하여 각 분기점의 gradient를 계산합니다. 이 때, 전체 데이터를 이용하는 것이 아니라 한 bucket 내의 데이터만을 이용합니다. 기존의 greedy algorithm을 사용하였다면 40개의 데이터가 있을 때, 39번 계산을 해야하지만, 이 방법(Approximation)을 사용하면 30번만 연산하면 됩니다. 가장 중요한 점은 각 bucket을 병렬처리 할 수 있다는 점입니다. 첫번째 bucket은 Thread1에서, 두번째는 Thread 2에서 ... 등으로 동시에 처리가 가능합니다.
- Global variant vs Local variant
child node의 bucket을 나누는 두가지 방법이 존재합니다.
먼저, Global variant 방식은 다음과 같이 전체 child에서 bucket의 수를 유지하는 방법입니다.
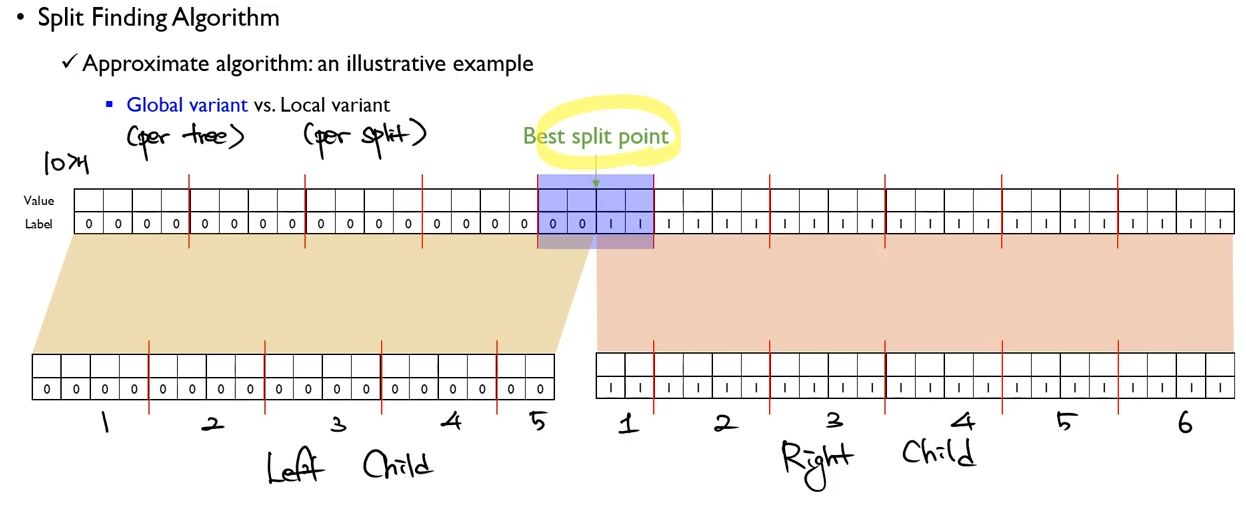
반면, Local variant 방식은 child node 하나에서 bucket의 수를 유지하는 방법입니다.
두 방법에 따른 AUC 성능 결과는 다음과 같습니다.
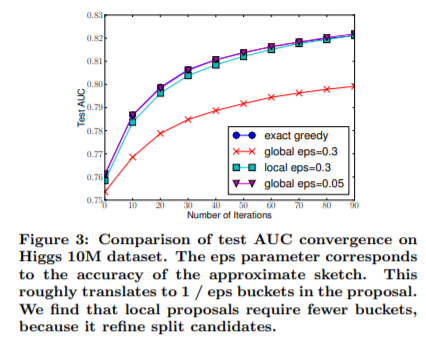
둘 중 어떤 방법이 절대적으로 더 우세한 것은 아닙니다. 다만, global variant 방식을 사용할 때에는 eps 를 좀 더 크게 두어야 한다는 것을 보여줍니다.
2. Efficient handling of missing data - sparsity aware algorithm
XGBoost에서는 결측치를 다룰 때, 학습 과정에서 각 split별로 default direction을 정의한 후, test data에서 결측치가 발견되면 default direction대로 split하는 방식을 사용합니다.
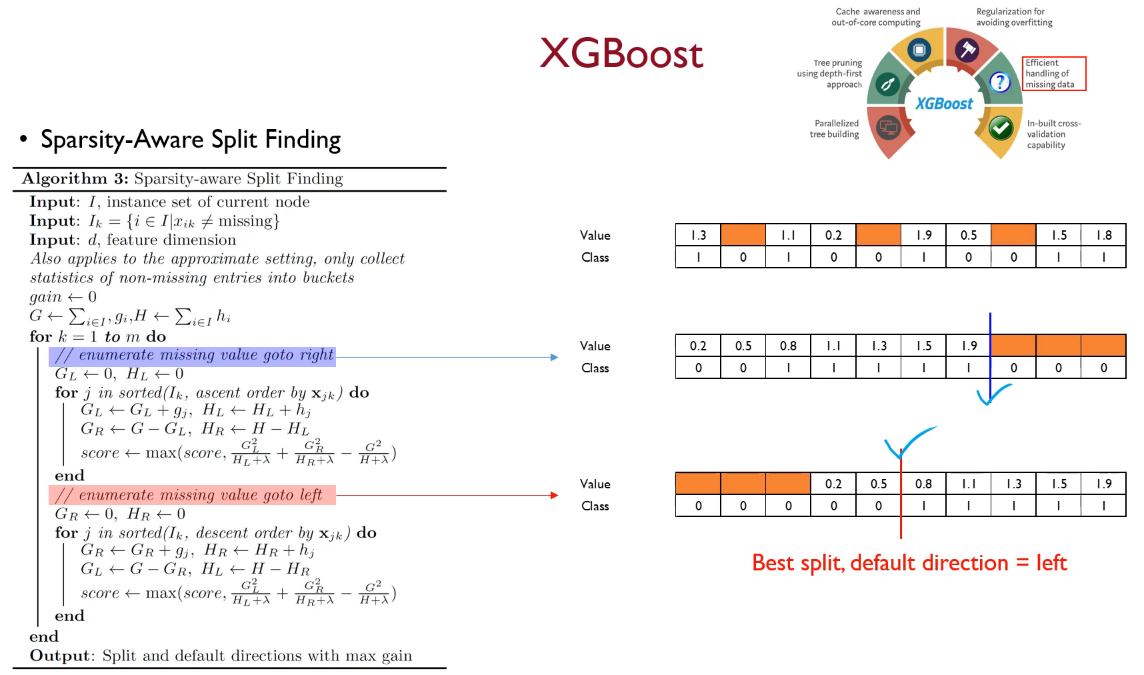
오른쪽으로 missing value를 보낸 결과와 왼쪽으로 보낸 결과를 비교해보면 왼쪽으로 보낸 결과가 이 split에서는 더 결과가 좋습니다. 따라서 이 split에서의 default direction은 왼쪽입니다.
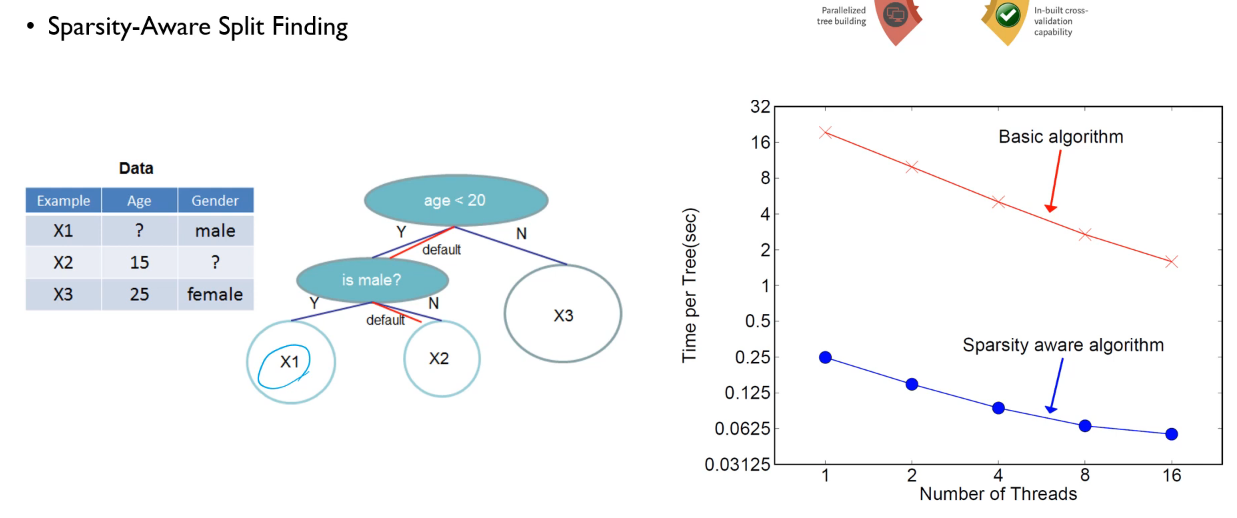
예시를 통해 보겠습니다. 첫번째 split에서는 default direction이 왼쪽이고, 두번째 split에서는 오른쪽입니다. 이 경우에, X1,X2,X3를 분류하면 위 그림과 같이 분류됨을 알 수 있습니다. 오른쪽 그래프를 보면, 이러한 sparsity aware algoritmn을 통해 tree를 만드는 시간을 단축했음을 알 수 있습니다.
뿐만 아니라 XGBoost는 이러한 특징들도 가지고 있습니다.
- xgboost 분류기 아래에 다른 알고리즘을 붙여서 앙상블 학습이 가능 (이미지 Transfer Learning처럼)
- 평가함수,목적함수 등 옵션을 자유롭게 선택 가능해서 유연성이 좋다
- Cross validation 기반
- 수식
책에 나와있는 Objective function과 Loss를 수식 표현에 관심이 있으신 분들은
https://www.youtube.com/watch?v=ZVFeW798-2I 을 참고하시면 도움이 될 것입니다 :)
- Parameters
XGBoost의 파라미터는 크게 일반, 부스터, 학습과정으로 나뉩니다.
<파라미터> 일반, 부스터, 학습과정
① 일반 파라미터
booster : 어떤 부스터 구조를 쓸지 결정 – gbtree, gblinear, dart
nthread : 몇 개의 쓰레드를 동시에 처리할지 – 디폴트 : 가능한 많이
num_feature : feature 차원의 숫자를 정하는 옵션 – 디폴트 : 가능한 많이
② 부스팅 파라미터
eta : learning rate
gamma : 트리 복잡도 파라미터. 커지면 트리 깊이가 줄어들어서 보수적인 모델이 된다. – 디폴트 : 0
max_depth : 한 트리당 깊이 – 디폴트 : 6, 키울수록 과적합 위험 ↑
lambda : L2 Regularization Form에 달리는 weights이다. 숫자가 클 수록 보수적인 모델이 된다.
alpha : L1 Regularization Form weights. 숫자가 클수록 보수적인 모델이 된다.
③ 학습 과정 파라미터
object : 목적함수. reg-linear(linear-regression), binary-logistic(binary-logistic classification),
count-poission(count data poison regression) 등 다양하다.
eval_metric : 모델의 평가 함수를 조정하는 함수다. Rmse(root mean square error), log loss(log-likelihood),
MAP(mean average precision) 등, 해당 데이터의 특성에 맞게 평가 함수를 조정한다.
④ 커맨드 라인 파라미터
num_rounds : boosting 라운드를 결정. 적당히 큰 것이 좋고 epoch 옵션과 동일하다.
실습코드
- XGBoost 시각화
# plot decision tree
from numpy import loadtxt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
from xgboost import plot_tree #xgboost 시각화 함수
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
##set up the parameters
rcParams['figure.figsize'] = 100,200
# load data
dataset = pd.read_csv('diabetes.csv', delimiter=",")
# split data into X and y
X = dataset.iloc[:, 0:8]
y = dataset.iloc[:, 8]
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=7)
print(len(y_train), len(y_test))
# fit model no training data
model = XGBClassifier(
booster='gbtree',
objective='binary:logistic',
learning_rate=0.03,
n_estimators=150,
reg_alpha =0.15,
reg_lambda=0.7,
max_depth=4,
subsample=1
)
model.fit(x_train, y_train)
# plot single tree
plot_tree(model)
plt.show()
# make predictions for test data
y_pred = model.predict(x_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))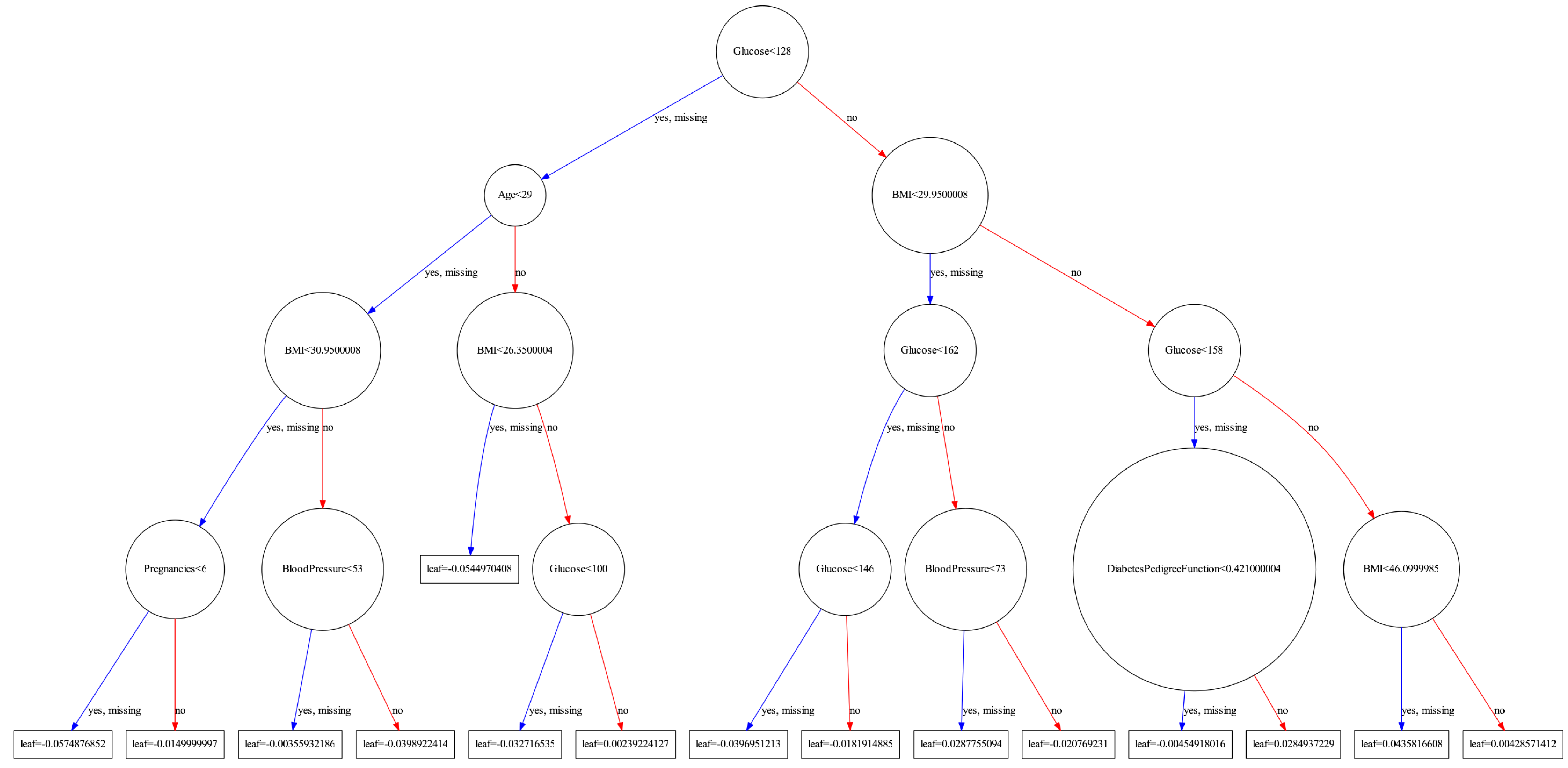
XGBoost 모델이 생성한 최종 Tree를 시각화한 모습입니다.
- Feature Importance
from xgboost import plot_importance
rcParams['figure.figsize'] = 10, 10
plot_importance(model)
plt.yticks(fontsize=15)
plt.show()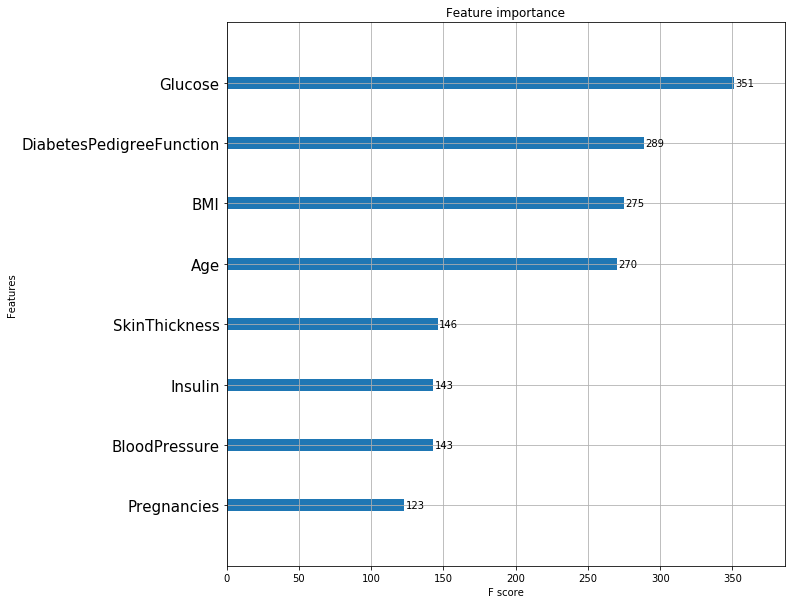
Tree depth가 3일때, 피마 인디언의 당뇨병을 진단하는 데 가장 중요한 요소는 Glucose입니다.
다만, 피쳐 중요도의 순서가 Decision Tree의 split 기준 변수의 순서는 아닙니다. DT는 Information gain을 기준으로 노드와 split 기준을 선정하지만, Feature Importance는 분류에러가 기준이기 때문입니다.
일반적으로는 순서가 대부분 일치하지만, 기준이 다르기에 항상 같지는 않습니다.
Tree의 depth가 달라지면 Tree와 그 정확도와 그 정확도도 달라지기 때문에 Feature importance도 달라질 수 있습니다.
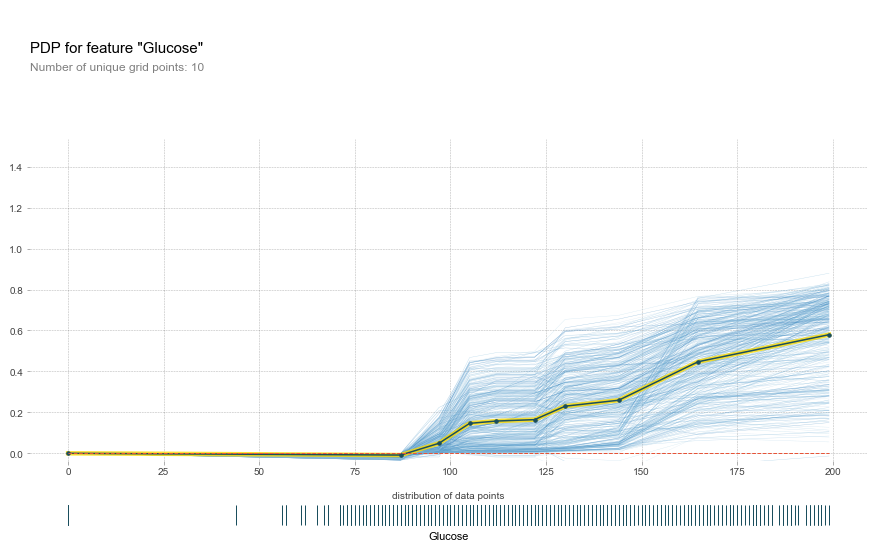
- PDP Plot - pdpbox 모듈을 이용
-target plot
from pdpbox import pdp, info_plots, get_dataset
pima_data = dataset
pima_features = dataset.columns[:8]
pima_target = dataset.columns[8]
fig, axes, summary_df = info_plots.target_plot(
df=pima_data, feature='BloodPressure', feature_name='BloodPressure', target=pima_target
)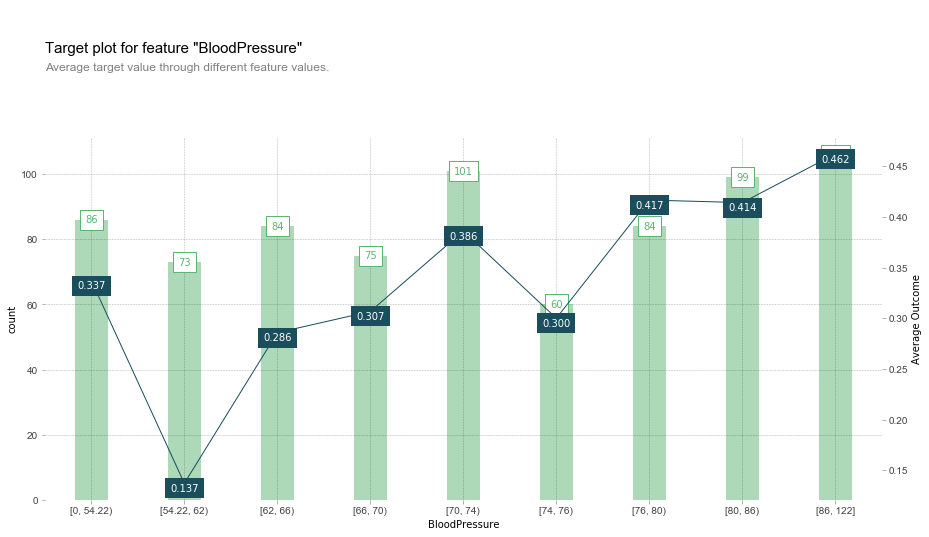
x축은 혈압, 왼쪽 Y축(막대그래프)은 각 수치 구간별 데이터 개수(count), 오른쪽 Y축은 당뇨병 진단비율, 각 막대는 구간별 데이터를 의미한다.
특이한 점은, target plot을 만들 때에는 모델을 함수 input으로 받지 않는다. 이것은 학습 데이터를 철저하게 분석할 수 있으면 모델을 예측할 수 있는 믿음을 바탕으로 하기 때문이라고 한다. 실제로 plot을 보면 모델의 예측값이 필요하지 않음을 알 수 있다. (EDA 시각화 느낌)
-pdp plot
pdp_gc = pdp.pdp_isolate(
model=model,
dataset=pima_data,
model_features=pima_features,
feature='Glucose'
)
# plot information
fig, axes = pdp.pdp_plot(
pdp_gc,
'Glucose',
plot_lines=False,
frac_to_plot=0.5,
plot_pts_dist=True
)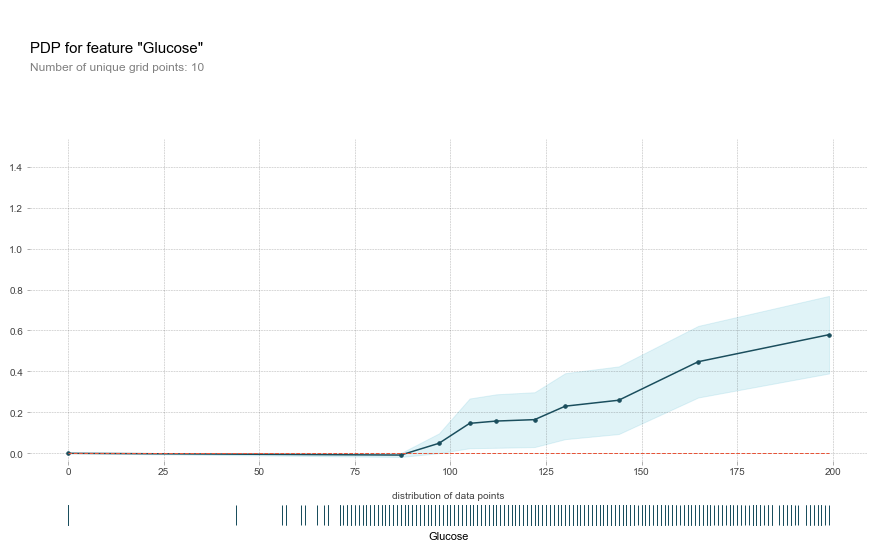
plot lines 옵션을 True로 두면 이러한 plot을 그릴 수 있습니다.
-target plot interact
데이터 전체에 대한 당뇨변 진단 결과를 그리고, feature간 관계를 표시
fig, axes, summary_df = info_plots.target_plot_interact(
df=pima_data,
features=['BloodPressure', 'Glucose'],
feature_names=['BloodPressure', 'Glucose'],
target=pima_target
)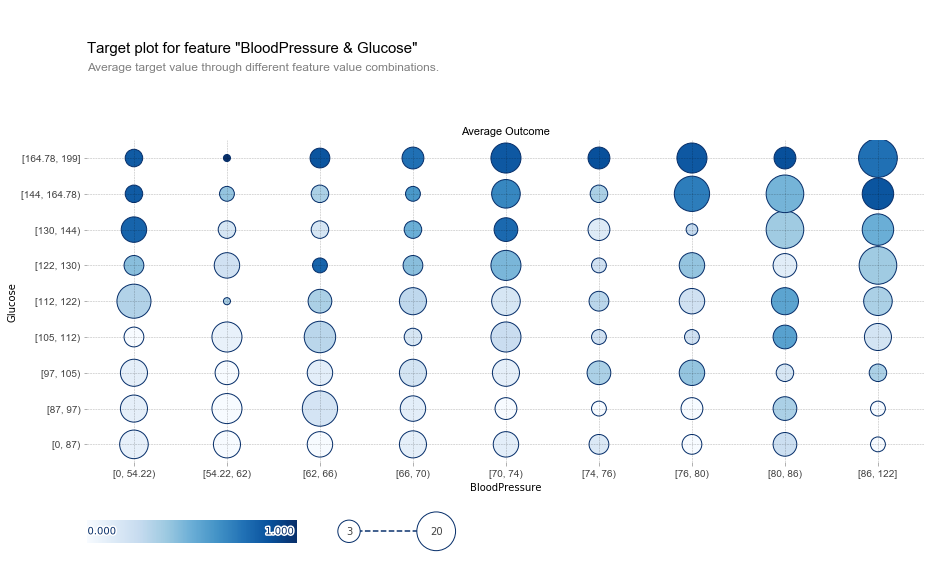
데이터 수 = 원의 크기 , 색이 진할수록 당뇨병 확률이 높음
- pdp interact
pdp_intertatcion = pdp.pdp_interact(
model=model,
dataset=pima_data,
model_features=pima_features,
features=['BloodPressure', 'Glucose']
)
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=pdp_intertatcion,
feature_names=['BloodPressure', 'Glucose'],
plot_type='contour',
x_quantile=True,
plot_pdp=True
)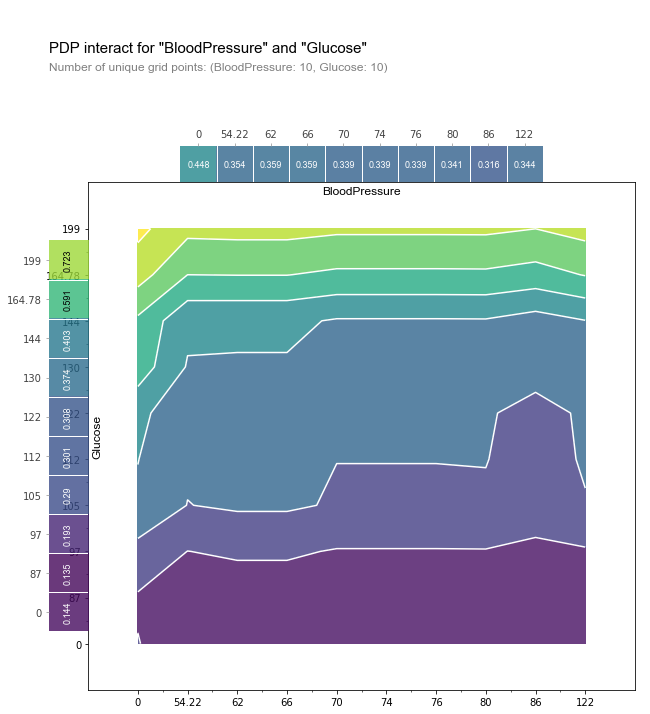
x축과 평행한 부분 : Glucose에 더 의존적
y축평행/종모양 부분: BloodPressure에 더 의존적
참고자료
추가 질문 답변
Q1) PDP 플롯
PDP 원본 논문 : https://statweb.stanford.edu/~jhf/ftp/trebst.pdf (40페이지 정도로 꽤나 방대한 분량입니다...)
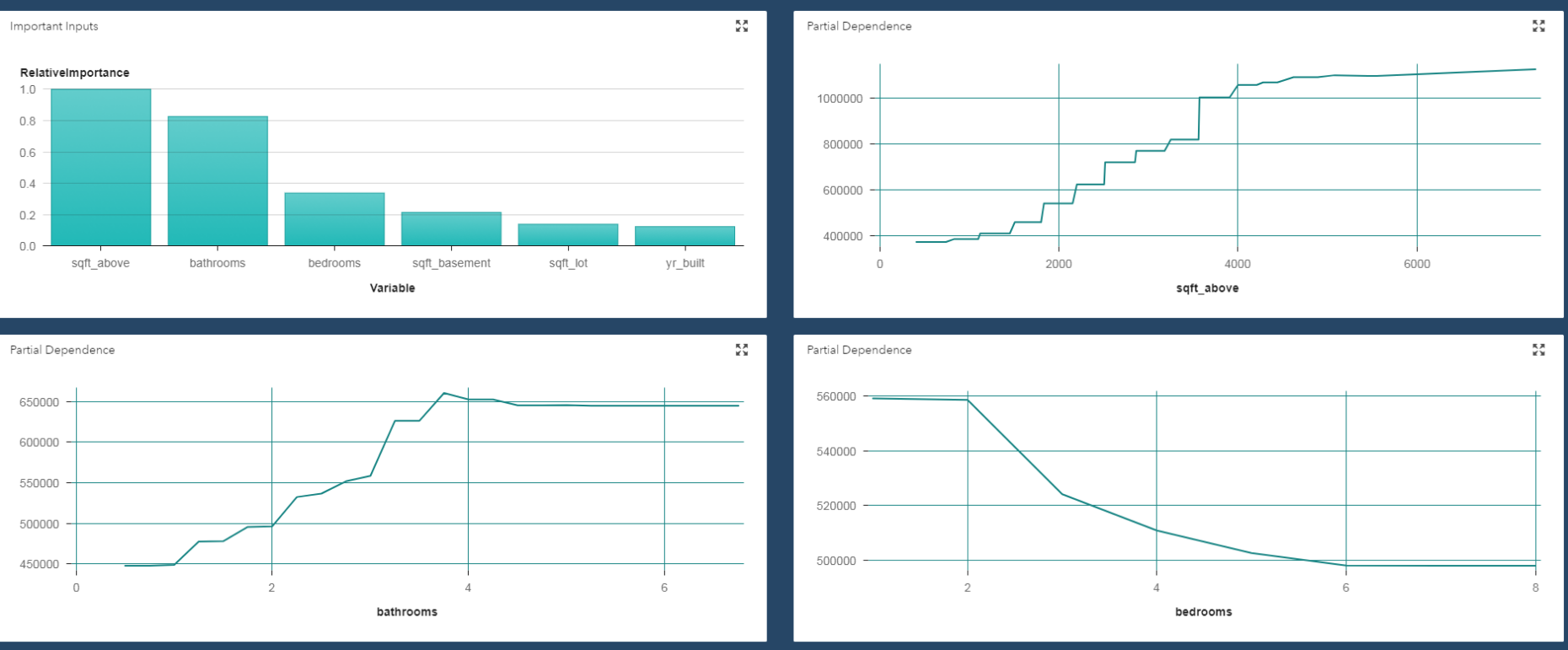
X축: 변화시킬 변수, Y축: 변화를 알고싶은 값.
위 그래프에서는 변수 중요도와 sqft(넓이) , 화장실 수, 침실 수(X축들)에 따른 가격 변화(Y축)를 나타내었다. 평균값을 plot한 것.
결국, 이 plot을 예시로 들면,
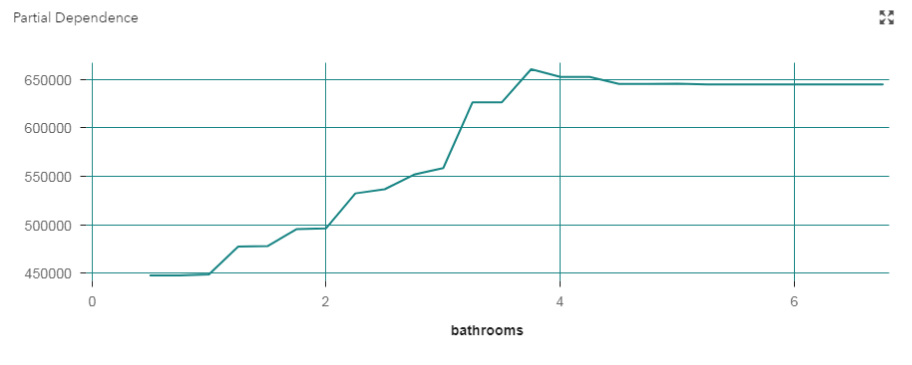
sqft_above, bathrooms, bedrooms, sqft_basement, sqft_lot, yr_built 변수 6개를 통해 집값을 예측하는데
관심이 있는 변수 x_1: bathrooms(화장실 수), 나머지 변수: x_1을 제외한 모든 변수(5개)
Y축 : 집값을 나타냄. 나머지 변수 5개를 변화시킨 평균.
이 때, 평균을 구하는 법: 주변분포처럼. (주변화)

출처: https://blog.naver.com/mykepzzang/220837645914
PDP는 주변분포의 개념을 적용한 것입니다. 주변 분포를 구하듯 나머지 변수를 변화시키는 방법을 이용하는 것 같습니다.
참고링크
https://blogsaskorea.com/116
http://ds.sumeun.org/?p=1954
https://blog.naver.com/mykepzzang/220837645914
https://m.blog.naver.com/tjdrud1323/221740255370 => 가장 자세히 설명되어있습니다.
Q2) XGBoost 병렬 처리 어떻게 하는지
답변 1) https://medium.com/blablacar/thinking-before-building-xgboost-parallelization-f1a3f37b6e68
Branch level: 각각의 tree branch가 따로따로 train 된다. => 이 방법이 앞에서 설명한 bucket 나누는 방식으로 추정.
2가지 병렬처리 방법
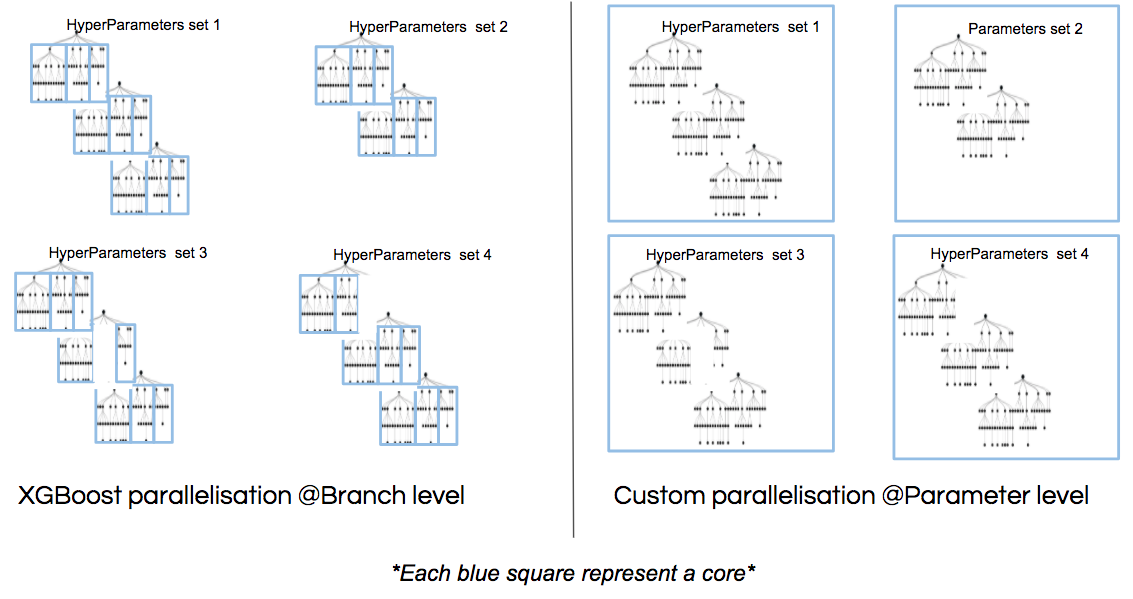
답변 2) https://m.blog.naver.com/nicolechae0627/221811579005, http://machinelearningkorea.com/2019/07/25/xgboost-%EC%9D%98-%EB%B3%91%EB%A0%AC%EC%B2%98%EB%A6%AC%EA%B0%80-%EC%96%B4%EB%96%BB%EA%B2%8C-%EA%B0%80%EB%8A%A5%ED%95%A0%EA%B9%8C/
3가지 방법
방식1. Parallelize Node Building at Each Level 분기 나뉜것을 각각 병렬처리
트리 레벨마다 노드의 생성을 병렬처리 방식으로 생성한다.Split된 노드들에 각각 cpu코어를 할당해 병렬처리한다.(병렬처리의 기준은 트리의 레벨) decision tree는 노드마다 high prediction accuracy 를 얻기 위해 과도하게 split하기 때문에 workload imbalanced problem 을 초래한다. (노드마다 인스턴스 숫자가 달라서 트리의 균형이 깨자는 현상) 그리고 속도의 개선이 별로 없는 방식이다. (일을 하는 쪽만 계속 하는 구조)
방식2. Parallelize Split Finding on Each Node 분기가 나뉘는 지점 계산을 병렬처리
한 노드로부터 자식노드를 생성하기 위해서는 feature마다 enumerate 하여 split을 찾아야 한다. 위의 아이디어는 노드의 split finding을 병렬처리하는 것으로 노드별로 feature를 sorting 한 담에 가장 엔트로피가 낮아지는 지점을 계산을 해야하는데 이 sorting을 병렬처리 한다. 각기 다른 feature들을 split 하는 방식이다. 노드생성을 병렬처리하는 위의 방식보다 훨씬 빠른 방법이다. 그러나 small node에 too much overhead를 초래한다.
방식3. Parallelize Split Finding at Each Level by features 처음부터 feature별로 정렬

위의 두 방식에는 두 개의 루프가 존재한다. outer loop로는 트리의 레벨마다 leaf nodes들을 돌고 있고, inner loop으로는 feature들을 돈다. 방식 3은 outer loop와 inner loop의 순서를 바꾸는 것에서 착안했다. 이를 통해 같은 레벨에서 다른 feature 의 split을 병렬처리할 수 있다. 즉 split 한 노드에서 sorting 하는게 아니라 처음부터 feature를 sorting을 대충한 다음에 추후 필요할때마다 leaf 노드에서 sorting을 진행한다
참고링크
http://machinelearningkorea.com/2019/07/25/xgboost-%EC%9D%98-%EB%B3%91%EB%A0%AC%EC%B2%98%EB%A6%AC%EA%B0%80-%EC%96%B4%EB%96%BB%EA%B2%8C-%EA%B0%80%EB%8A%A5%ED%95%A0%EA%B9%8C/
https://m.blog.naver.com/nicolechae0627/221811579005
https://stackoverflow.com/questions/34151051/how-does-xgboost-do-parallel-computation
