
본 글의 내용은 안재현 님의 저서 'XAI 설명 가능한 인공지능, 인공지능을 해부하다.' 를 주로 참고하여 작성하였음을 알려드립니다.
대리분석이란?
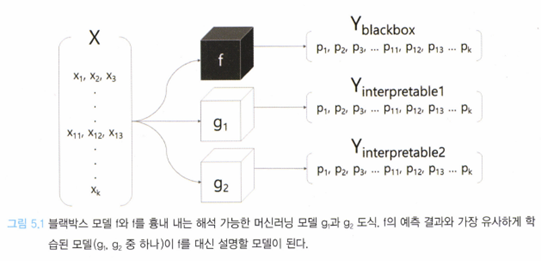
대리 분석은 이름에서 예상할 수 있듯이 본래 기능을 흉내내는 대체재를 만들어 프로토타입이 동작하는지 판단하는 분석 방법이다. XAI에서 대리분석 또한 본래 인공지능 모델이 너무 복잡해서 분석하는 것이 연산적인 제약으로 인해 불가능할 때 유사한 기능을 흉내내는 인공지능 모델 여러 개를 만들어 본래 모델을 분석하는 기법을 말한다.
출처: XAI 설명 가능한 인공지능, 인공지능을 해부하다.
본래 분석해야 할 모델을 f라고 할 때, 이를 흉내 내는 모델인 g를 만드는 것이 대리 분석의 목표이다. 이 때, 모델 g는 모델 f와 학습 방식이 같을 수도 있고, 다를 수도 있다. 모델 g를 결정하는 핵심 조건은 아래와 같다.
- 모델 f보다 학습하기 쉽다.
- 설명 가능하다.
- 모델 f를 유사하게 흉내 낼 수 있으면 된다.
또한, 모델 g의 학습 과정은 다음 두 가지로 나뉜다.
- 학습 데이터 전부를 사용한다.
- 데이터의 라벨 별로, 또는 데이터의 일부만 사용한다.
학습하는 과정이 끝나면, 모델 g는 모델 f를 조금이나마 흉내 낼 것이고, g는 설명 가능하기 때문에 원래의 모델 f가 어떻게 학습됐을 지 간단하게 나마 설명할 수 있다. 즉, 모델 g는 모델 f보다 정확도가 떨어지지만, 모델 f를 대변할 수 있다.
이 때, 학습 데이터(일부 또는 전체)를 사용해 대리 분석 모델을 구축하는 것을 글로벌 대리분석(Global Surrogate Analysis)이라 하고, 학습 데이터 하나를 해석하는 과정을 로컬 대리 분석(Local Surrogate Analysis)라고 부른다.
대리 분석법의 장점은 아래와 같다.
- 모델 애그노스틱(model-agnostic technology, 모델에 대한 지식 없이도 학습할 수 있음)하다.
- 적은 학습 데이터로도 설명 가능한 모델을 만들 수 있다.
- 중간에 모델 f가 바뀌더라도 피처만 같다면 대리 분석을 수행할 수 있다.
대리 분석 모델은 블랙박스 모델과 완전히 분리돼(decoupled)있고, 이러한 특성은 XAI 분야 내에서도 중요한 관심사이기 때문에 기억해두는 것이 좋다.
글로벌 대리 분석(Global surrogate)
본 글에서는 글로벌 대리 분석을 다루지 않고, 로컬 대리 분석에 대해서만 기술하겠다.
로컬 대리 분석(Local Surrogate)
로컬 대리 분석은 데이터 하나에 대해 블랙박스 모델이 해석하는 과정을 분석하는 기법으로, 주로 LIME(Local Interpretable Model-agnostic Explanations)으로 더 잘 알려져 있다.

🔺일렉기타를 치는 있는 리트리버’ 사진을 LIME을 사용해 분석한 결과. 해당 사진을 예측할 때 블랙박스가 집중한 영역을 확인할 수 있다. 출처:Ribeiro et al(2015). " Why should i trust you?" Explaining the predictions of any classifier
다음으로, LIME(Local Intcrprctablc Modcl-agnostic Explanations) 기법에 대해서 자세히 다뤄보자.
LIME을 다루기 이전, 참고
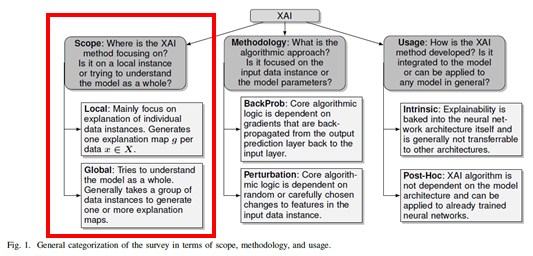
XAI 모델이 어디에 중점을 두는지에 대한 개념인 로컬과 글로벌은 비단 대리 분석뿐만 아니라 다른 XAI 기법들에서도 중요한 요소라 할 수 있다.
출처: Das, A., & Rad, P. (2020). Opportunities and challenges in explainable artificial intelligence (xai): A survey
로컬 기반 분석(Local-Based Analysis)
 🔺Gradient-based Saliency Maps.
🔺Gradient-based Saliency Maps.
출처: K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps,” 2nd International Conference on Learning Representations, ICLR 2014- Workshop Track Proceedings, Dec 2013.
글로벌 기반 분석(Global-Based Analysis)

🔺Class model-visualization method.
출처: K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps,” 2nd International Conference on Learning Representations, ICLR 2014 - Workshop Track Proceedings, Dec 2013.
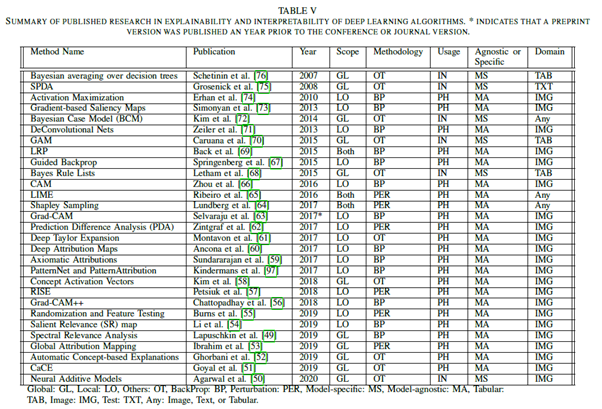
🔺많은 XAI 알고리즘들은 모델의 범위(global or local), 방법(back prop or perturbation or others), 의존성(model-agnostic or model-specific)에 따라 분류할 수 있다.
출처: Das, A., & Rad, P. (2020). Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv preprint arXiv:2006.11371.
아래에서 기술할 LIME 기법은 글로벌 및 로컬 특성을 모두 가지고 있으며, 변형(perturbation) 기반 방법을 사용하고, 모델 애그노스틱(Model-Agnostic)한 특성을 가진다는 것을 확인할 수 있다.
LIME
기존 딥러닝 모델의 신뢰도는 주로 테스트 데이터셋을 이용한 정확도로 검증하나, 현실 데이터와 테스트 데이터 사이의 괴리, 비전문가의 인공지능 모델 활용 제한 등으로 인해 해석에 어려움을 겪을 수 있다.
LIME은 모델이 현재 데이터의 어떤 영역에 집중했고, 어떤 영역을 분류의 근거로 사용했는지 알려주는 XAI 기법이다. 위에서 말했듯 LIME은 모델 학습 방법과 관계없이 사용 가능하므로 기존에 사용했던 학습 모델에 LIME을 적용하여 설명 가능하게끔 변환할 수 있다.
LIME 알고리즘, 직관적으로 이해하기
만약 우리가 지식인 사이트의 직원이고, 끊임 없이 올라오는 질문에 대해 이 질문이 진정성 있는지(sincere), 진정성 없는지(insincere) 판단해야 한다고 가정해보자. 데이터의 양이 너무 많기 때문에 우리는 머신러닝 모델을 만들어 분류를 하려 한다. 즉, 입력 데이터는 “글, 언어”이다. 이 경우 LIME을 적용하면 머신러닝 모델의 분류 근거에 대해 다음과 같이 시각화 할 수 있다.
입력 데이터가 인간의 언어일 때(NLP)

출처 : Explaining Text classifier outcomes using LIME | by Maha Amami | Towards Data Science
이 때 insincere란 중립적이지 않거나, 누군가를 폄하하거나 비방하거나, 선동적이거나, 거짓에 기반한 내용인 내용을 포함하는 것으로 정의된다. 위의 글 처럼 stupid, earth, insist 등의 단어로부터 해당 질문이 굉장히 감정적이고, 선동적인 특성을 띤다고 볼 수 있다(75%의 정확도로 옳게 판별).
입력 데이터가 이미지일 때(Image classification)

위처럼 귀여운(?) 개구리 이미지를 개구리로 판단한 근거(또는 당구대, 열기구로 판단한근거)들을 이미지 형식으로 설명해주고 있다.
출처:Marco Tulio Ribeiro, Pixaby
그렇다면, LIME은 어떤 원리로 이미지 분류 및 텍스트 분류에 대한 근거를 설명해주는 것일까?
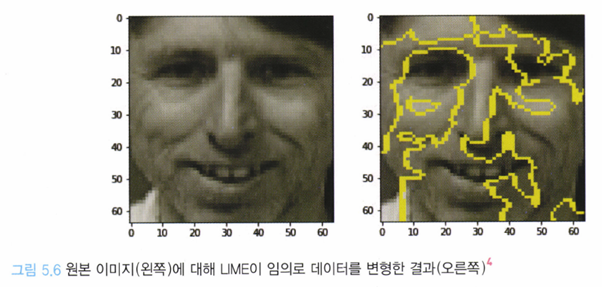
LIME은 입력 데이터에 대해 부분적으로 변화를 주는데, 이것을 변형(perturbation) 또는 샘플 퍼뮤테이션(sample permutation)이라 한다. 즉, 어떤 이미지가 모델의 입력값으로 들어온다면 해석이 가능하게끔 ‘인식 단위’를 쪼개고 이미지를 해석한다.
출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
이렇게 쪼개진 이미지를 노란색 실선으로 이해 단위를 구분하고, 이렇게 나뉜 영역을 조합해 원본 모델이 대상을 가장 잘 분류할 수 있는 ‘대표 이미지’를 구성한다.

출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
어떤 이미지가 입력 값으로 주어졌을 때, 이미지 내 특정 관심 영역을 라 하고, 초점 주변으로 관심 영역을 키워갈 때 기준 로부터 동일한 정보를 가지고 있다고 간주할 수 있을 때, 이 영역을 이라 하고 이를 슈퍼 픽셀(super pixel)이라 한다.

출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
이런 슈퍼 픽셀에 대해서는 sklearn-image의 Segmentation 모듈을 참고하자.
이제 앞으로 사용할 를 아래와 같이 정의하자.
: 이미지 전체를 입력으로 받고, 특정 사람일 확률을 결과로 반환하는 블랙박스 모델
: 슈퍼 픽셀 의 마스킹 정보
: 슈퍼 픽셀 의 마스킹 정보인 를 입력으로 받고, 와 동일한 값을 결과로 반환하게끔 학습된 해석 가능한 모델
이 때, LIME으로부터 얻어지는 설명(explanation)은 아래와 같은 식으로부터 얻어진다
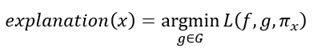
출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
는 각 를 입력으로 받아, 각 가 블랙박스 모델 의 예측에 얼마나 영향을 미치는 지를 예측한다.
LIME 논문에서는 를 단순한 선형결합 모델인
을 사용했고, 마스크 로 대표되는 각 슈퍼 픽셀 의 영향의 정도를 로 파악할 수 있게끔 설계했다.
은 손실함수로 슈퍼 픽셀 에 대한 분류 모델 의 예측 결과와 마스킹 데이터 에 대한 회귀 모델 의 검증 결과를 비교해 유사성을 계산한다
출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
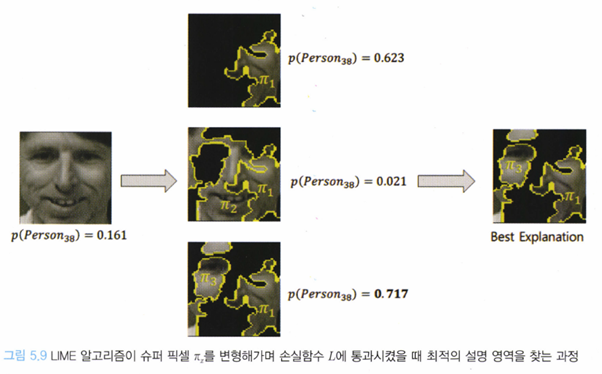
즉, LIME은 손실함수가 최저가 되게 하는 슈퍼 픽셀 조합을 찾는다. 즉, 슈퍼 픽셀 의 모든 조합에 대한 의 분류 결과와 에 대응하는 마스킹 데이터 에 대한 의 결과값의 차이가 적게끔 학습한다. 이를 통해 모델 f가 가장 영향을 많이 받는 슈퍼 픽셀 π_x을 찾는다.
그렇게 찾은 슈퍼 픽셀의 조합(위 그림에서는 )에 대해 해석 가능 모델 g를 학습시키게 된다. 그렇게 찾은 슈퍼 픽셀에 대응하는 마스킹 데이터 을 사용하여 의 선형 모델을 구성하고, 을 통해 이 얼마만큼의 중요도를 갖는지 간접적으로 알 수 있게 된다.
위와 같은 과정으로부터 LIME은 복잡한 분류 모델인 의 결정경계를 찾아야 한다는 것을 알 수 있다.

출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
그림 5.10은 블랙박스 분류 모델 f과 유사한 결정을 내리는 설명 가능 모델 g를 구현하는 초기 과정이다. 흰색 영역은 ‘긍정’으로 분류되는 영역이고, 흑색 영역은 ‘부정’으로 분류되는 영역이다. 이 때 위 그림의 빨간색 원으로 나타나는 지점 x는 입력 이미지를 뜻한다. 설명 가능 모델 g는 위 그림에 나타나 있는 결정 경계를 흉내내야 한다.
이 때, 이전에 정의한 입력 이미지 x의 일부인 슈퍼 픽셀 π_x들을 적절히 조합한 슈퍼 픽셀 집합을 샘플링해서 입력 이미지와 유사한 주변 샘플들을 효과적으로 구할 수 있다. LIME은 이 주변 샘플들을 이용해 입력 이미지 x 근처를 조사해(f의 분류 결과를 살핌으로써) 결정경계를 구하는 것이다(논문에서는 샘플링 한 뒤 K-Lasso를 통해 근사적으로 결정 경계를 구한다).
만약 샘플링하지 않고 영역 내 모든 샘플들을 조사함으로써 결정경계를 구하려 한다면 선형 모델로는 복잡한 결정 경계를 표현하지 못 할 뿐더러, 복잡한 결정 경계를 표현하기 위해 복잡한 모델을 택하는 것은 설명 가능성을 보장하지 못한다.

출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
그림 5.12처럼 LIME은 입력 이미지 근방을 샘플링한 뒤 얻은 와 주변 이미지 를 입력으로 받은 의 출력과 비슷한 지, 그렇다면 얼마나 유사한지 (유사성 가중치를 사용해) 구한다. 주변 이미지들의 일부는 기존 입력 이미지 와 같은 ‘긍정’으로 분류될 것이고, 나머지는 기존 입력 이미지 와 반대되는 ‘부정’으로 분류될 것이다. 이로부터 다음과 같은 통찰을 얻을 수 있다(입력 이미지 는 흰색 영역에 위치하기에 블랙박스 모델 에 의해 ‘긍정’으로 분류된다는 것을 기억하자).
주변 이미지가 ‘긍정’으로 분류되는 경우: 해당 주변 이미지는 예측에 도움이 되는 부분(슈퍼 픽셀, )을 가지고 있다.
주변 이미지가 ‘부정’으로 분류되는 경우: 해당 주변 이미지는 예측에 도움이 되지 않은 부분(슈퍼 픽셀, )을 가지고 있다.
이렇게 입력 이미지와 샘플링된 주변 이미지를 사용하면 아래와 같이 의 결정 경계를 (근사적으로) 찾아낼 수 있다.
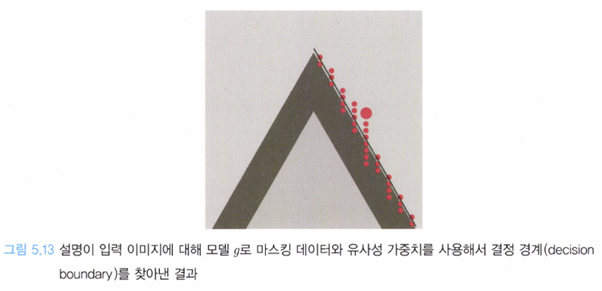
출처 : XAI 설명 가능한 인공지능, 인공지능을 해부하다.
즉, LIME은 결정 경계를 탐색하기 위해 입력 이미지와 샘플링 된 주변 이미지를 사용하기 때문에 비교적 간단한 선형 함수를 설명 가능 모델 로 택하더라도 결정 경계를 충분히 표현할 수 있다는 가정을 사용한다.
(위의 식에서 는 의 중요도,즉 의 중요도를 나타낸다.)
LIME의 장점
- LIME은 분류에 사용한 블랙박스 모델 f가 무엇이든 적용할 수 있다(model-agnostic)
- LIME은 딥 러닝이나 GPU 등을 사용하지 않고도 적용할 수 있는, 가벼운 XAI 기법이다.
- LIME은 행렬로 표현 가능한 데이터(텍스트, 이미지)에 작동하는 XAI 기법이다. 서브모듈러를 찾고, 이를 이용해 설명하기 때문에 결과를 직관적으로 만들 수 있다.
LIME의 단점
-
슈퍼 픽셀을 구하는 알고리즘과 모델 의 결정 경계를 확정 짓는 방식이 비결정적(non-deterministic)이다.
- LIME은 슈퍼 픽셀 알고리즘에 따라 마스킹 데이터가 달라지며, 모델 g는 샘플링 위치에 따라 랜덤한 결과를 보일 수 있다.
- 이러한 비결정 문제는 ‘샘플링’을 사용하는 대부분의 문제에서 발생할 수 있다.
-
LIME은 데이터 하나에 대한 설명이기 때문에 모델 전체에 대한 일관성을 보전하지 못한다.
- 서브모듈러 픽(Submodular pick) 알고리즘을 사용한 SP-LIME으로 데이터세트 전체를 활용해 서브모듈러를 선정할 수 있게끔 보완하였다.
LIME 실습
텍스트 데이터에 대한 설명(Explanation)
데이터
from sklearn.datasets import fetch_20newsgroups
# 뉴스 그룹에 대한 20가지 카테고리를 포함하는 dataset
newsgroups_train=fetch_20newsgroups(subset='train')
newsgroups_test=fetch_20newsgroups(subset='test')데이터는 뉴스 기사에 대해 20가지의 카테고리를 포함하는 sklearn의 dataset을 사용해보자.
데이터 요약

데이터 개수

텍스트를 분류하기 위해 단어의 빈도를 예측에 사용하는 나이브 베이즈 모델을 사용하도록 하자.
import sklearn
import sklearn.metrics
from sklearn.naive_bayes import MultinomialNB
# TF-IDF를 사용한 전처리과정 : 문서(글)-->벡터(숫자)
vectorizer=sklearn.feature_extraction.text.TfidfVectorizer(lowercase=False) # 소문자 변환 x
train_vectors=vectorizer.fit_transform(newsgroups_train.data) # (데이터 샘플) x (단어 개수)의 matrix
test_vectors=vectorizer.transform(newsgroups_test.data) # (데이터 샘플) x (단어 개수)의 matrix
# 학습 (나이브 베이즈)
nb=MultinomialNB(alpha=0.01)
nb.fit(train_vectors, newsgroups_train.target)
# 테스트
pred=nb.predict(test_vectors)
sklearn.metrics.f1_score(newsgroups_test.target, pred, average='weighted')약 83.5%의 f1 score를 보인다.
이제 위에 적용한 벡터화와 나이브 베이즈의 예측을 한 번에 진행하는 파이프라인을 만들고, 첫 번째 데이터에 대한 확률 예측 값을 출력하자.
from sklearn.pipeline import make_pipeline
pipe=make_pipeline(vectorizer, nb) # 벡터화 + 나이브베이즈 모델
# 파이프라인을 이용해 데이터 하나에 대한 (벡터화+예측확률)을 반환하자. (fit, transform 과정이 불필요)
predict_classes=pipe.predict_proba([newsgroups_test.data[0]]).round(3)[0]
print(predict_classes)결과

출력으로 특정 클래스에 속할 확률을 반환해야한다
rank=sorted(range(len(predict_classes)), key=lambdda x:predict_classes[x],
reverse=True)
for rank_index in rank:
print('[{:>3}위]\t{:<4}class ({:.1%})'.format(rank.index(rank_index)+1,
rank_index, predict_classes[rank_index]))결과
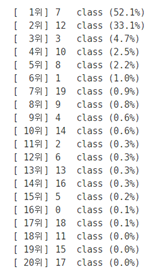
위에 적용한 벡터화와 나이브 베이즈의 예측을 한 번에 진행하는 파이프라인을 만들고, 첫 번째 데이터에 대한 확률 예측 값을 출력하자. 여기까지가 일반적인 분류 모델이 (하나의 데이터에 대해) 할 수 있는 역할이다. 이제 해당 예측에 대해 LIME을 적용해보도록 하자.
LIME library는 기본적으로 텍스트 모듈, 이미지 모듈, 테이블 분류, 선형 공간 분류와 같은 모듈을 제공하고, 사용자가 직접 수정할 수 있는 이산 모듈과 설명 모듈을 제공한다. 텍스트 데이터이기 때문에 텍스트 모듈을 사용해 예측에 대한 설명을 진행하자.
# !pip install lime
from lime.lime_text import LimeTextExplainer
explainer=LimeTextExplainer(class_names=class_names)위의 explainer 객체는 LIME의 텍스트 하이라이트 알고리즘 객체이며, 매개변수로 피처 선택 방식, BOW(Bag of Words) 수행 방식, 커널 크기 등을 수동으로 지정할 수 있다.
# LIME 객체는 해석하고 싶은 데이터와 흉내내고 싶은 모델을 객체로 받는다.
exp=explainer.explain_instance(newsgroups_test.data[0], # 첫 번째 텍스트 데이터.
pipe.predict_proba,# 텍스트를 입력으로 받고,(벡터화를 거쳐) 카테고리 별 확률을 반환한다.
top_labels=1) # 가장 확률이 높은 클래스만 보여준다. 이전의 개념에서는 이미지 데이터의 일부분인 슈퍼 픽셀 개념을 도입해 LIME의 작동방식을 설명하였으나, 텍스트에서는 (벡터화가 진행된) 텍스트 데이터의 부분 벡터(A bag of word)를 사용해 기존의 분류 모델(나이브 베이즈)을 모사하는 선형 모델을 학습한다.
해당 선형 모델의 카테고리 분류 기준이 결정경계로 모사되며, 결정 경계에 걸리는 0번 데이터의 단어 집합이 서브 모듈로 출력된다. 즉, 결정경계 근처의 모듈이 ‘긍정,부정’을 가르는 ‘중요 요소’이다.
# LIME의 설명을 곧바로 확인하기.
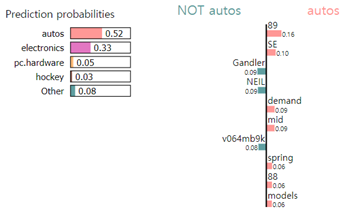
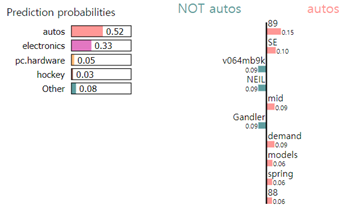
exp.show_in_notebook(text=newsgroups_test.data[0])결과
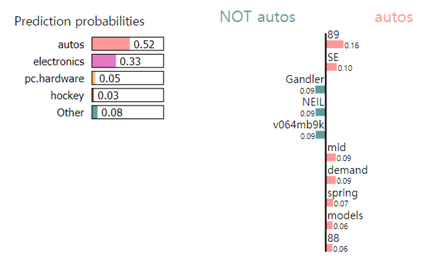

이 때, submodular는 텍스트 하이라이트로 나타나있다. 즉, LIME이 기존의 분류 모델을 모사했을 경우 위에 나타난 서브 모듈러 조합(여기서는 단어 벡터의 조합)이 결정경계를 가장 잘 모사한다고 판단했고, 가중치는 선형 모델에서의 가중치와 동일할 것.
이러한 가중치들을 바탕으로 자동차에 대한 사전지식이 없음에도 불구하고 분류 모델이 해당 데이터를 ‘자동차’로 분류했는지 파악할 수 있게 된다.

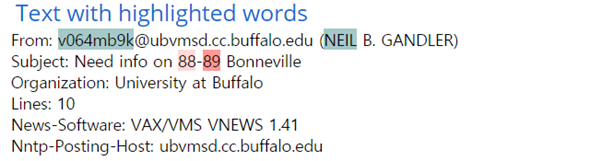
그림: 가중치가 높게 나온 88-89를 포함한 88-89 Bonneville을 검색한 결과
LIME의 단점에서 언급했듯이, LIME은 샘플링을 통해 결정 경계를 확정 짓기 때문에 코드를 실행할 때 마다 다른 결과를 보일 수 있다.
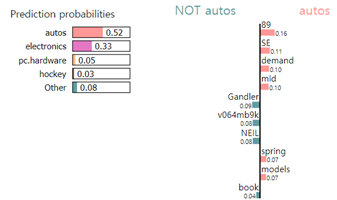
이미지 데이터에 대한 설명(Explanation)
데이터
마찬가지로 sklearn의 내장된 데이터를 사용하도록 하자.
import numpy as np
import matplotlib.pyplot as plt
from skimage.color import gray2rgb, rgb2gray # sklearn-image
from skimage.util import montage # 일렬로 배열된 이미지를 커다란 사각형으로 재배열.
from sklearn.datasets import fetch_olivetti_faces입력
faces=fetch_olivetti_faces()
print(np.array(faces.images).shape) # 400개의 64x64 이미지이다.결과
(400,64,64)데이터는 아래와 같다.

LIME은 기본적으로 RGB 채널을 가지는 이미지에 대해서 사용가능하기 때문에 흑백 이미지를 RGB 이미지로 바꿔주어야 한다.
X_vec=np.stack([gray2rgb(iimg) for iimg in faces.images], 0) # 이미지를 컬러로 변환해 아래로 쌓는다.
y_vec=faces.target#.astype(np.uint8)
print('shape of X: ', X_vec.shape,'\n'+'shape of y: ', y_vec.shape)결과
shape of X: (400, 64, 64, 1)
shape of y: (400,)
이미지 분류 모델(CNN)
이미지 분류 모델로 간단한 CNN을 사용하도록 하자. 데이터의 규모가 작기 때문에 어떤 모델을 사용해도 괜찮다. 데이터세트를 학습 세트와 검증 세트로 나누도록 하자.
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
X_train, X_test, y_train, y_test=train_test_split(X_vec,
y_vec,
train_size=0.8)
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
y_train_num=np.argmax(y_train, axis=1)
y_test_num=np.argmax(y_test, axis=1)모델을 아래와 같이 정의하자.
from keras.models import Sequential
from keras.layers import MaxPooling2D
from keras.layers import Conv2D
from keras.layers import Activation, Dropout, Flatten, Dense
num_classes=40
# 모델 구조 정의
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=[64,64,3], padding='same')) #64,64,3
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 전결합층
model.add(Flatten()) # 벡터형태로 reshape
model.add(Dense(512)) # 출력
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes)) # 40개
model.add(Activation('softmax'))
# 모델 구축하기
model.compile(loss='categorical_crossentropy', # 최적화 함수 지정
optimizer='rmsprop',
metrics=['accuracy'])
# 모델 확인
model.summary()
모델이 클래스에 대한 예측 확률을 잘 반환하는지 확인하기 위해 학습되지 않은 모델에 테스트 데이터를 입력시켜 보자.
model.predict(X_train[0].reshape(-1,1))결과
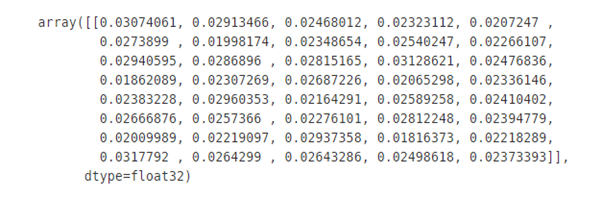
정상적으로 모델이 정의되었으므로, 모델을 학습시킨 후 테스트 세트를 이용해 정확도를 출력해보자.
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
mc = ModelCheckpoint('best_model.h5', monitor='val_accuracy', save_best_only=True)
es = EarlyStopping(monitor='val_accuracy', verbose=1, patience=50)
model.fit(X_train, y_train, epochs=500,validation_split=0.2,callbacks=[es,mc])
# 모델 평가하기
score = model.evaluate(X_test, y_test)
print('accuracy=', score[1]) # acc
92.5%의 정확도를 보인다.
이러한 CNN 예측 모델을 대상으로 LIME을 적용하기 위해, LIME의 이미지 모듈을 불러오고 설명 객체를 할당하도록 하자.
이미지에 LIME 적용
from lime import lime_image # 이미지 모듈
from lime.wrappers.scikit_image import SegmentationAlgorithm # LIME이 사용할 수 있게.
explainer=lime_image.LimeImageExplainer()이 때 이미지를 슈퍼 픽셀로 분할하는 알고리즘을 직접 설정할 수 있다. quickshift, slic, felzenswalb 등이 존재한다.
segmenter=SegmentationAlgorithm('slic',
n_segments=100, #이미지 분할 조각 개수
compactness=1, # 유사한 파트를 합치는 함수, log scale, default : 10
sigma=1) # 스무딩 역할, 0과 1 사이의 float이를 토대로 LIME 설명 객체를 이용해 데이터 하나에 대해 예측을 진행해보자. LIME 설명 객체의 매개변수로는 기본적으로 (1) 설명이 필요한 데이터 1개 (2) 해당 데이터에 대해 분류를 진행 할 분류 모델 을 필요로 한다. 이번에는 추가로 정교한 분석을 위해 확률 기준 상위 5개의 후보를 반환하고(top_labels), 샘플링 개수를 설정하고(num_samples), 위에서 정의했던 설정대로 이미지를 분할하도록 하자(segmentation_fn).
olivetti_test_index=0
exp=explainer.explain_instance(X_test[olivetti_test_index], #데이터하나
classifier_fn=model.predict,# 40 class의 확률 반환 (softmax)
top_labels=5, # 확률 기준 1-5위 분석
num_samples=1000,# 샘플링 공간
segmentation_fn=segmenter) # 이전에 lime의 형식에 맞게 래핑된 분할 알고리즘이 때, sklearn의 regressor가 기본 설명 모델로 쓰인다. classifier_fn 매개변수에는 ‘카테고리에 속할 확률’을 반환하는 분류 모델을 전달해야 한다. 위에서 정의한 CNN 모델은 마지막에 softmax 활성화 함수를 거치기 때문에 각 클래스에 속할 확률을 정상적으로 반환한다. sklearn의 분류기에서는 classifier.predict_proba로 전달할 수 있다.
LIME 설명기, 데이터, 그리고 예측 모델을 이용해 설명 값을 반환했으므로 이를 아래와 같은 코드로 시각화하도록 하자.
from skimage.color import label2rgb #
# 캔버스
fig, ((ax1, ax2), (ax3, ax4))=plt.subplots(2,2,figsize=(8,8))
ax=[ax1,ax2,ax3,ax4]
for i in ax:
i.grid(False)
# 예측에 가장 도움되는 세그먼트만 출력
temp, mask=exp.get_image_and_mask(y_test_num[0],
positive_only=True, # 설명 모델이 결과값을 가장 잘 설명하는 이미지 영역만 출력
num_features=8, # 분할 영역의 크기
hide_rest=False) # 이미지를 분류하는 데 도움이 되는 서브모듈 외의 모듈도 출력
# label2rgb : 형광색 마스킹
ax1.imshow(label2rgb(mask, temp, bg_label=0), interpolation='nearest')
ax1.set_title('Positive Regions for {}'.format(y_test_num[0]))
# 모든 세그먼트 출력
temp, mask=exp.get_image_and_mask(y_test_num[0],
positive_only=False, # 설명 모델이 결과값을 가장 잘 설명하는 이미지 영역만 출력
num_features=8, # 분할 영역의 크기
hide_rest=False) # 이미지를 분류하는 데 도움이 되는 서브모듈 외의 모듈도 출력
ax2.imshow(label2rgb(4-mask, temp, bg_label=0), interpolation='nearest') # 역변환
ax2.set_title('Positive/Negative Regions for {}'.format(y_test_num[0]))
# 이미지만 출력
ax3.imshow(temp, interpolation='nearest')
ax3.set_title('Show output image only')
# 마스크만 출력
ax4.imshow(mask, interpolation='nearest') # 정수형 array.
ax4.set_title('Show mask only') # 정수형
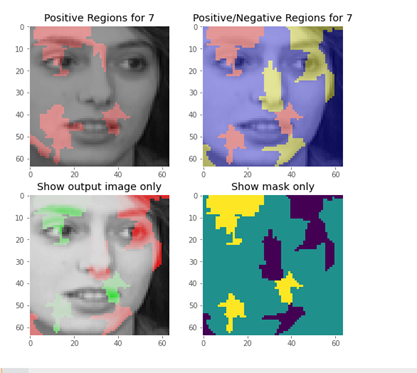
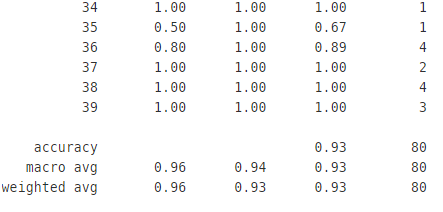
추가로, CNN의 이미지 분류 모델은 93%의 정확도를 보였었다.
from sklearn.metrics import classification_report
y_pred=model.predict(X_test)
y_pred_num=np.argmax(y_pred, axis=1)
print(classification_report(y_true=y_test_num, y_pred=y_pred_num))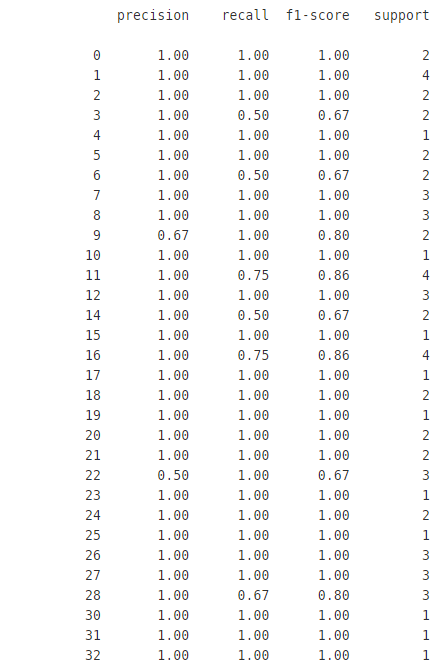
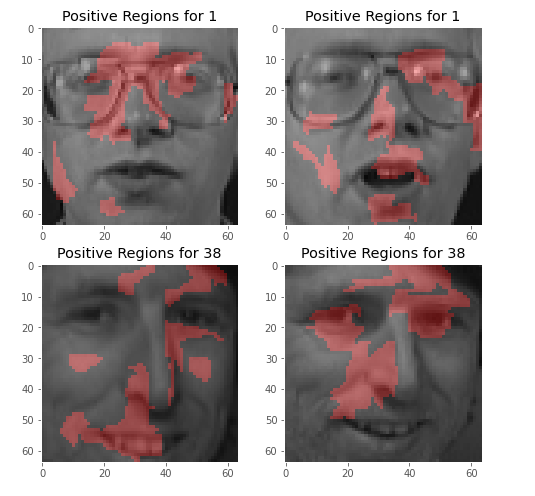
이 중 잘 분류한 1번, 38번을 대상으로 LIME을 시행할 경우 아래와 같다
그 외에, 실질적으로 기존 데이터의 target을 잘 못 예측한 클래스는 3, 6, 11, 14, 16, 28 등이 있다. 이 중 28번째 클래스, 즉 28번째 사람에 대해 예측한 데이터를 분석하도록 하자.
np.where(y_test_num==28)결과: array([37,52,73])
test data의 37번째 data를 이용해 자세한 분석을 시행하자.
%matplotlib inline
## 조금 더 자세히 출력하자. (기존의 )
test_idx=37
exp=explainer.explain_instance(X_test[test_idx], #데이터하나
classifier_fn=model.predict,# 40 class의 확률 반환 (softmax)
top_labels=5, # 확률 기준 1-5위 분석
num_samples=1000,# 샘플링 공간
segmentation_fn=segmenter) # 이전에 lime의 형식에 맞게 래핑된 분할 알고리즘
fig,m_axs=plt.subplots(2,5, figsize=(10,4))
for i, (c_ax, gt_ax) in zip(exp.top_labels, m_axs.T):
temp, mask=exp.get_image_and_mask(i,
positive_only=True, # 설명 모델이 결과값을 가장 잘 설명하는 이미지 영역만 출력
num_features=12, # 분할 영역의 크기
hide_rest=False, # 이미지를 분류하는 데 도움이 되지 않는 세그먼트는 출력 x
min_weight=0.001)
c_ax.imshow(label2rgb(mask, temp, bg_label=0),
interpolation='nearest')
c_ax.set_title('Positive for {}\nScore:{:2.2f}%'.format(i,
100*y_pred[test_idx, i]))
c_ax.axis('off')
face_id=np.random.choice(np.where(y_train_num==i)[0])
gt_ax.imshow(X_train[face_id])
gt_ax.set_title('Example of {}'.format(i))
gt_ax.axis('off')이 코드는 왜 CNN 모델이 28번째 사람을 36번째의 사람으로 오해했는지, 어떤 영역을 보고 잘 못 판단했는지 세그먼트를 출력해준다.

잘 못 판단한 첫 번째 사진의 경우 입 주변, 코, 그리고 눈을 위주로 살펴보았다. 아무래도 수염이 있는 걸로 인식이 된걸까? 그 외에 제대로 판단한 두 번째 사진의 경우 눈을 판단 근거로 삼지 않고 주로 볼과 광대 위주로 보고 판단한 것을 알 수 있다.
예시로 사용된 얼굴 이미지의 경우 풍경 사진, 동물 사진 등과 같이 구분 영역이 뚜렷하지는 않기 때문에 여전히 사용자가 보기에 이해가 힘든 부분이 있을 수 있고, 이미지 분할 알고리즘과 하이퍼 파라미터 설정, 설명 모델 선택, 샘플링 개수 등에 따라서 설명 방식 또한 달라질 수 있다. 그렇기 때문에 얼굴 이미지와 같이 비교적 판단하기 어려운 데이터들은 설정 값을 다양하게 변경하면서 설명 모델의 분석을 관찰 할 필요가 있다고 생각한다.
여담
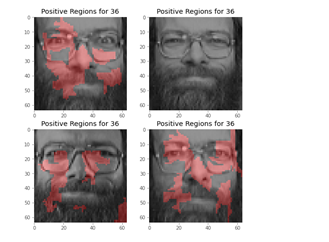
개인적으로 생각하기에 36번님의 특징은 수염인 것 같은데, 생각보다 수염에 집중하지는 않는다. 이러한 사실은 이미지 분류 모델에 LIME을 적용하기 이전에 이미지 분할(Segmentation) 알고리즘에 대해서도 충분히 살펴보고, 작동 방식에 대해 어느정도 이해해야 할 필요성을 내포한다.
