[3주차] XAI survey paper review (2)
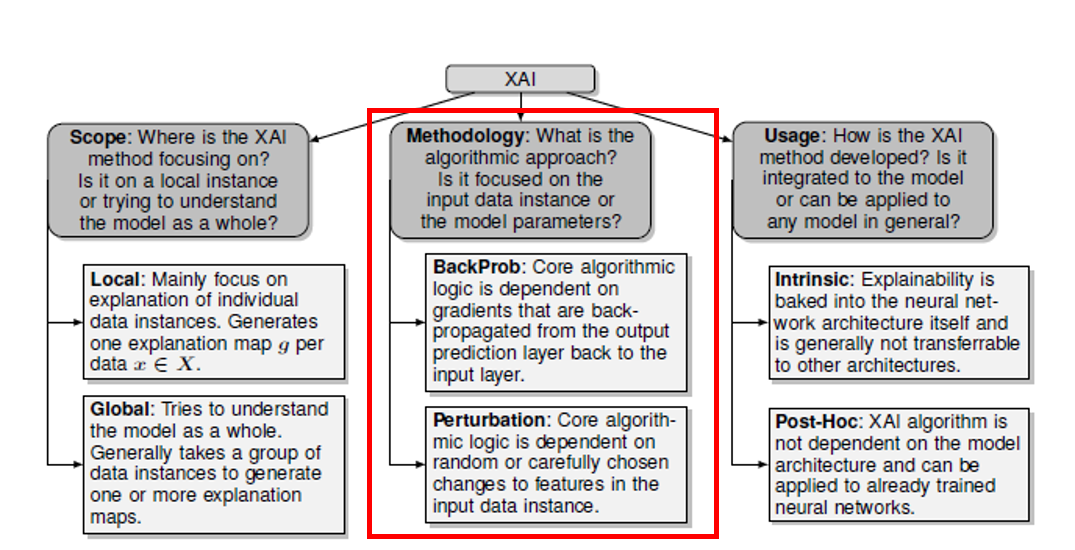
Differences in the methodology
앞서 설명했던 XAI 방법론(explainable algorithm)들 간의 차이점에 대해 살펴보는 섹션입니다. XAI 방법론은 1) 모델에 사용되는 데이터에 주는 변화 등에 초점을 맞춘 방법론과 모델 구조와 파라미터에 초점을 맞춰 모델을 설명하는 방법론으로 크게 구분지을 수 있습니다.
1)의 경우에는 perturbation-based, 2)의 경우에는 backpropagation-based 방법론이라고 할 수 있습니다.
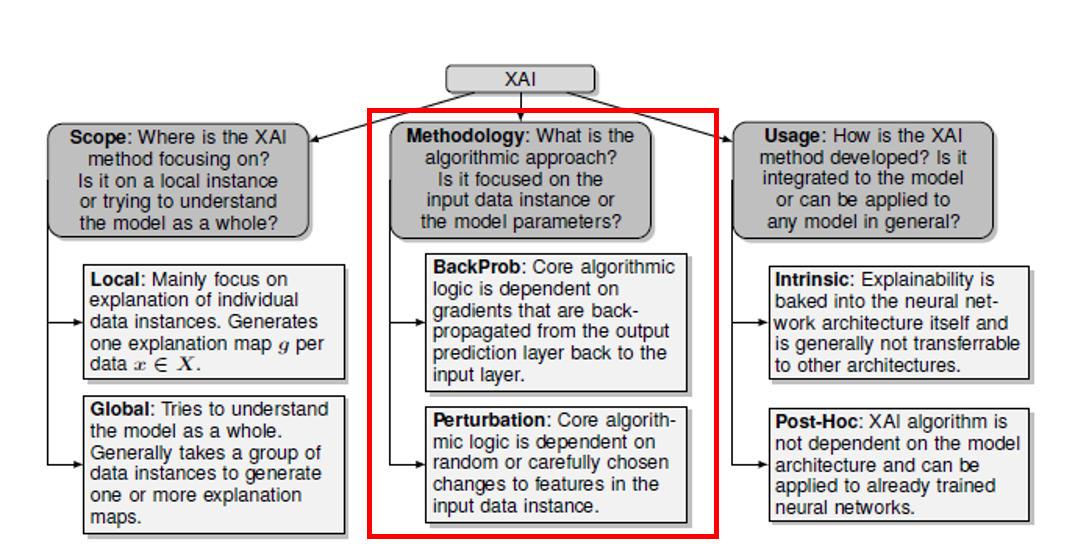
Perturbation-based
Perturbation based methodology은 모델에 주어지는 입력 데이터 값에 다양한 변화를 주며 학습 모델을 반복적으로 조사함으로써 모델을 설명하고자 하는 것입니다.
해당 방법론의 예시로는,
- 입력 데이터 변수 중 특정 변수를 0, 혹은 random한 다른 값(논문의 표현을 빌리자면 random conterfactual instances)들로 대체
- 하나 혹은 여러 개의 픽셀 (superpixels) 을 선택
- blurring
- shifting
- masking
앞서 배웠던 SHAP과 LIME의 경우에 각각 game theoretic framework 하에서 변수를 제거하며 변수의 correlation을 탐구한다는 점, 그리고 입력 패치를 반복적으로 제공하며 각각의 superpixels에 대한 시각적 설명이 생성된다는 점에서 perturbation-based에 해당합니다.
DeConvolution nets for Convolution Visualizations
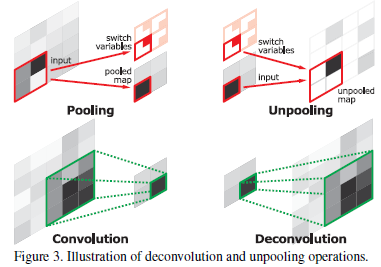
DeConvolution nets (a.k.a. DeConvNets)은 기존 CNN의 neural activations를 시각화하기 위해 Zeiler et al. (2013) 에 의해 고안된 CNN 네트워크입니다. 기존 CNN과 정반대의 결과를 리턴하기 위해 unpooling layer와 deconv layer를 포함하고 있다는 것이 특징입니다. 기존의 CNN이 feature dimension을 줄이며 이미지 내의 특징들을 추출해냈다면, 반대로 DeConvNets는 신경망의 activity를 시각화하기 위해 입력 픽셀 공간으로 다시 매핑하는 activation map을 만들어냅니다. 이로써 딥러닝 모델 내의 각 레이어들이 무엇을 어떻게 학습하는지에 대해 이해하는 데 도움을 줍니다.
[DeConvNets vs ConvNets]
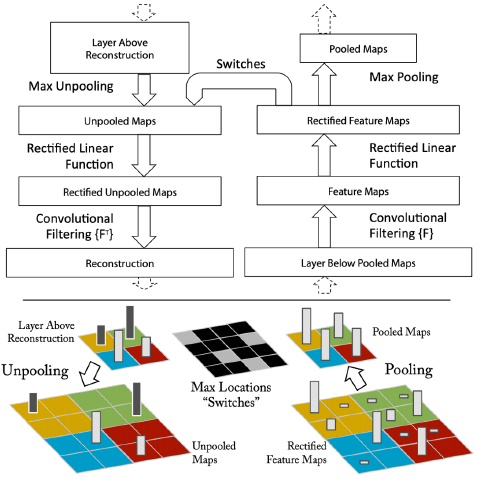
[Unpooling / Deconvolution layer]
Prediction Difference Analysis (Zintgraf et al.)
Prediction Difference Analysis는 변수가 여러 개 존재할 경우, conditional sampling을 통해 CNN의 이미지 분류 작업에 대한 설명을 하는 방법입니다. 예측된 클래스 c에 대한 각 입력 변수들의 relevance score를 계산함으로써, 모델의 결정에 대해 각 변수가 어떠한 상관관계를 갖는지에 대해 분석할 수 있습니다. 해당 relevance는 와 간의 차이에 의해 계산됩니다. 이때 표현은 를 제외한 모든 변수들로 구성된 입력 셋을 의미합니다.
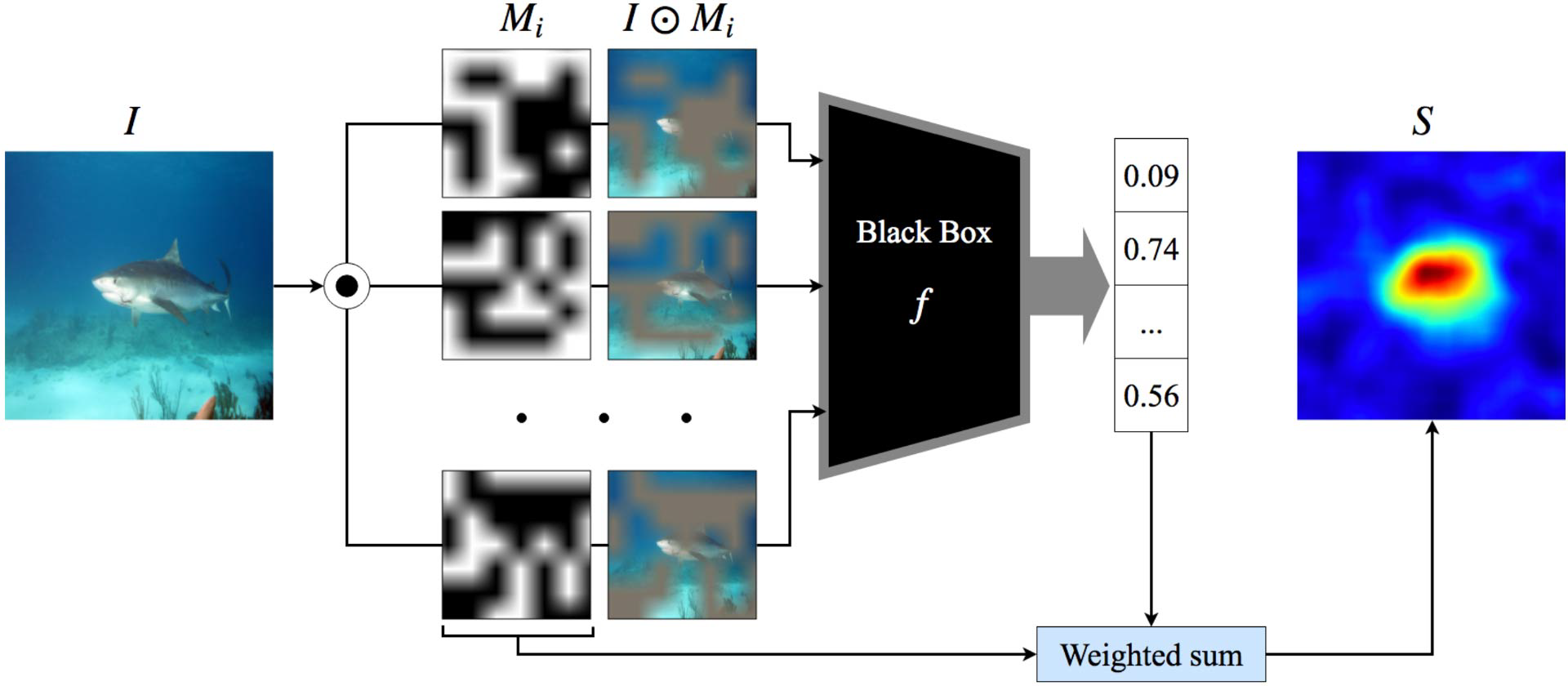
Randomized Input Sampling for Explanation (RISE)
Petsiuk et al. (2017)에 의해 RISE는 randomized masks (i.e. 랜덤하게 값이 assign된 이진 행렬) 를 입력 이미지에 원소별로 곱해줌으로써 입력 이미지를 교란(perturb)시킵니다. 아래의 그림을 참고하면, 마스킹을 함으로써 해당 부분이 지워진 것처럼 표현이 되었음을 알 수 있습니다. 이후 마스킹된 이미지는 black box prediction 함수인 f를 거쳐 classification에 대한 confidence score를 리턴하게 됩니다. 이후 이를 각 마스크와 weighted sum을 통해 saliency map을 리턴하는 데 사용하게 됩니다.
[RISE architecture]
Randomization and Feature Testing
Burns et al. (2019)는 변수를 전혀 관련없는 값들로 채워넣음으로써 중요 변수들을 가려내는 방법인 Interpretability Randomization Test (IRT)와 One-Shot Feature Test (OSFT)을 소개했습니다.
그러나 하나 이상의 변수를 입력 값으로부터 제외하는 것은 입력 차원에 대한 변화를 주기 힘든 딥러닝에서는 활용이 어렵습니다. 이는 인공신경망을 활용한 학습은 사전학습된 모델을 바탕으로 학습을 이어나가는 경우가 많기 때문입니다. 또한 값을 0으로 만들어버리거나 혹은 conterfactual한 변수값들로 넣어주는 경우는 변수 간 correlation때문에 제대로된 퍼포먼스를 기대할 수 없게됩니다.
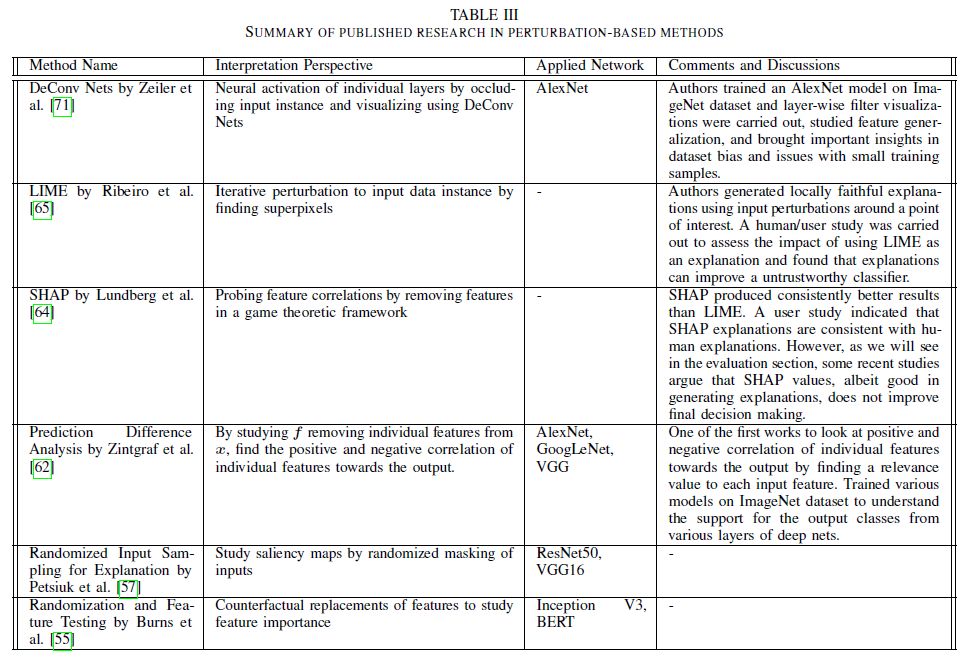
Summary Table for perturbation-based methods
논문에서 제공한 perturbation 기반 방법론을 정리한 테이블입니다.
BackPropagation-based (or Gradient-based)
입력 변수 공간에 변화를 줌으로써 각 변수의 기여도 등을 측정하고자 했던 perturbation 기반의 방법론과는 달리 backprob 기반 방법론은 신경망 결과에 입력 x가 어떻게 영향을 미치는가를 설명하기 위해 신경망 내에서 정보 흐름의 backward pass에 주목합니다.
Saliency Maps
 Saliency maps는 Simonyan et al. (2013) 이 처음 소개한 것으로, 모델이 예측한 결과에 각 픽셀이 미치는 영향을 시각화한 것입니다. 앞서 언급한 Zeiler et al. (2013)의 DeConvNets에서도 saliency maps를 시각화하기 위해 역전파를 활용합니다. 이때 정확한 시각화를 위해서 Negative Gradient가 0으로 clipping되지 않는다는 점에서 주목을 받기도 했습니다. Guided backpropagation 방법 또한 Simonyan et al.을 개선한 방법으로 gradient-based method 중 하나입니다.
Saliency maps는 Simonyan et al. (2013) 이 처음 소개한 것으로, 모델이 예측한 결과에 각 픽셀이 미치는 영향을 시각화한 것입니다. 앞서 언급한 Zeiler et al. (2013)의 DeConvNets에서도 saliency maps를 시각화하기 위해 역전파를 활용합니다. 이때 정확한 시각화를 위해서 Negative Gradient가 0으로 clipping되지 않는다는 점에서 주목을 받기도 했습니다. Guided backpropagation 방법 또한 Simonyan et al.을 개선한 방법으로 gradient-based method 중 하나입니다.
Gradient class activation mapping (CAM)
대부분의 saliency 방법론은 pooling layer에서 max pooling 대신 global average pooling을 활용합니다. Zhou et al. (2016)은 global average pooling 대신 class activation mapping (CAM) 을 활용함으로써 한 번의 forward-pass만으로 입력 이미지에서 class-specific image region을 잡아내고자 했습니다. Grad-CAM과 Grad-CAM++은 CNN을 깊게 쌓고, 시각화를 좀 더 향상시켜 CAM 방법을 개선한 방법입니다.
GradCAM은 입력 이미지에서 class-specific한 영역을 잡아낼 뿐 아니라, 반대로 모델 결과에 부정적인 영향을 미치는 영역 또한 찾아냄으로써 counterfactual한 부분까지 찾아낼 수 있다는 장점이 있습니다. 이를 통해 classification, image segmentation, visual question answering (VQA) 등의 영역까지 널리 활용되고 있습니다. 아래의 그림은 GradCAM을 활용해 segmentation 알고리즘의 성능을 향상시킬 수 있음을 보여주고 있습니다.

Salient Relevance (SR) Maps
Li et al. (2019)에 의해 고안된 Salient Relevance (SR) map은 입력 이미지의 LRP를 기반으로 하여 context까지 인지할 수 있는 salience map입니다. SR map에서는 LRP relevance map을 찾아낸 뒤, 해당 map에서 각 픽셀에 해당하는 saliency value를 찾는 과정을 수행합니다. 알고리즘을 정리하면 다음과 같습니다.

Attribution Maps
한편 ICML 2017에서 M.Sundararajan이 발표한 "Aiomatic attribution for deep networks"에서는 기존의 Gradient 기반 방법론이 완벽히 모델에 대한 설명력을 갖추지 못했다면서 Integrated Gradients (IG)를 제안합니다. 기존의 gradient 방법론이 output의 gradient에 해당 output에 대응되는 input의 값을 곱하는 방식을 활용했다면, Sundararajan et al. (2017)은 baseline x'으로부터 관심있는 input인 x까지의 직선거리 상의 모든 점들의 gradients를 적분하는 방식 (Integrated Gradients; IG)를 고안해냈습니다.
수식은 다음과 같습니다.
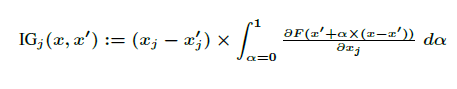
이때 는 gradient가 계산되는 차원을 의미하며, 대부분의 경우 베이스라인 는 영행렬 혹은 영벡터를 선택합니다. 이미지의 경우라면 검은 배경 이미지가 될 것이고, 텍스트 분류라면 0으로 초기화된 벡터값이 될 것입니다. 하지만 모든 경우에 위와 같은 베이스라인이 채택되는 것은 아니며 간혹 오히려 성능을 저하시키는 현상이 발생할 수 있으니 태스크에 맞게 선택해야 합니다.
한편, Expected Gradients(EG)는 Instead Gradient를 개선하여 나온 것으로 모델 설명력을 높이기 위해 도메인 지식을 모델 내에 인코딩시키는 방식을 제안합니다. 수식은 다음과 같으며, 이때 는 unerlying data 도메인의 분포를 의미합니다.
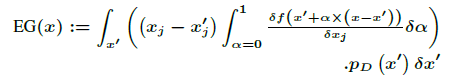
Things desired in backprob-based Methods (한계 및 개선사항)
위에서 언급한 것과 같이 다양한 gradient 기반 방법론이 제안되었지만, 여전히 한계는 존재합니다. Sundararajan et al.은 다음과 같은 특성들을 충족한다면 더 나은 XAI 기술이 될 것이라고 주장합니다.
-
Sensitivity: 하나의 특성만 다른 두 가지의 인풋이 있다고 했을 때 그 다른 특성은 non-zero attribution을 가져야 한다.
-
Implementation invariance: 두 네트워크의 결과가 모든 입력에 대해 동일하다면, 다른 implementations를 가진다고 하여도 이 두 네트워크는 functionally equivalent해야 한다.
-
Completeness: Attribution을 모두 더 하면 입력 x와 baseline 입력 x'에 대한 모델 f의 output의 차이와 동일해야 한다.
-
Linearity: 네트워크 A와 네트워크 B의 선형결합으로 이루어진 네트워크 C (=aXA + bXB)가 있다고 할 때, C의 attribution은 a X attr(A) + b X attr(B) 이어야 한다.
Model Usage or implementation level
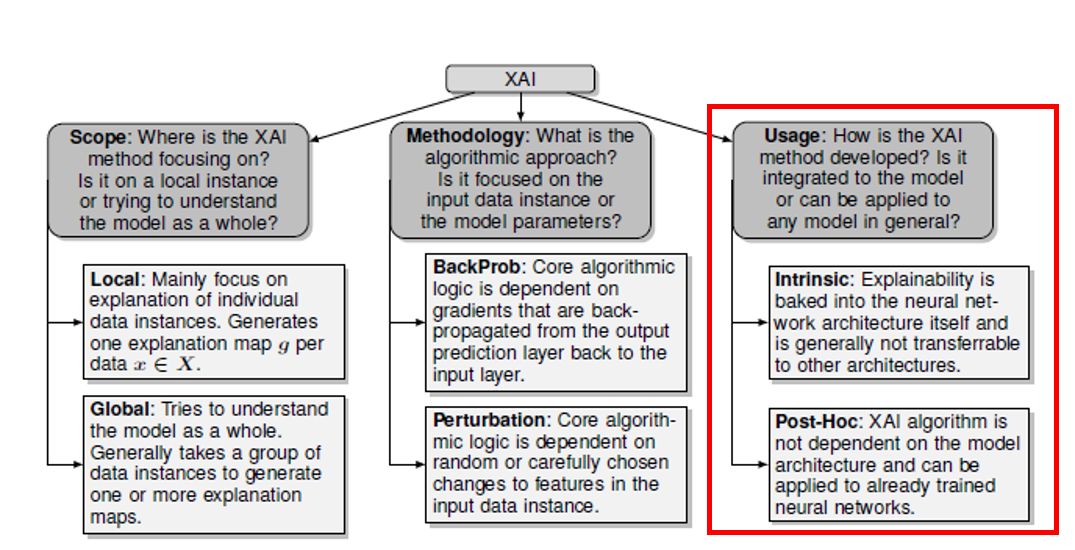
쉽게 말하면, XAI 방법론이 각 모델마다 달라져야 하는지 혹은 모델 간에 일반화되어 사용될 수 있는지를 논합니다.
Model Intrinsic
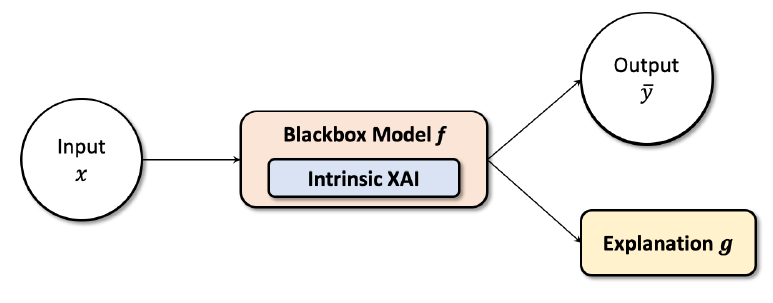
Intrinsic methods of explanations은 Explainer는 모델마다 다르며 다른 모델에 다시 사용되는 것이 불가능하다는 것을 의미합니다.
Trees and Rule-based Models
결정트리와 같은 Shallow rule-based 모델은 inherent interpretable 모델입니다. SHAP이나 LIME을 포함한 많은 설명 가능한 알고리즘은 선형 혹은 tree 기반 모델을 활용하기 때문에 이와 같은 알고리즘들도 inherent interpretable하다고 할 수 있습니다.
Generalized additive models (GAMs)
GAM 계열의 모델들 또한 inherent interpretable 모델입니다. GAM은 GLM(Generalized Linear Model)의 확장으로 기존 glm에서 정의되었던 종속변수와 독립변수와의 선형관계를 비모수적 함수를 이용하여 비선형적으로 표현 가능한 모델입니다.
Sparse LDA and Discriminant Analysis
베이지안 비모수 모델인 Graph-Sparse LDA와 Sparse Penalized Discriminant Analysis(SPDA) 또한 inherent interpretable하다고 할 수 있습니다. 전자의 경우 설명 가능하고 예측의 방식으로 topic summary를 할 수 있도록 고안된 방식입니다. (기존에 주어진 카테고리로 예측하는 방식으로 추정)
SPDA는 spatio-temporal interpretability를 향상시키고 Functional Magnetic Resonance imaging 데이터에 있어서 classification accuracy를 높이기 위해 고안되었습니다.
이러한 모델에 내재되어 있는 설명력을 갖춘 경우에는 확장성이 좋지 못합니다. 해당 모델을 사용할 수 있는 환경을 제대로 세팅을 하지 않는 경우 모델 사용 자체가 어렵기 때문에 그 한계를 가지는 단점이 있습니다.
Post-Hoc
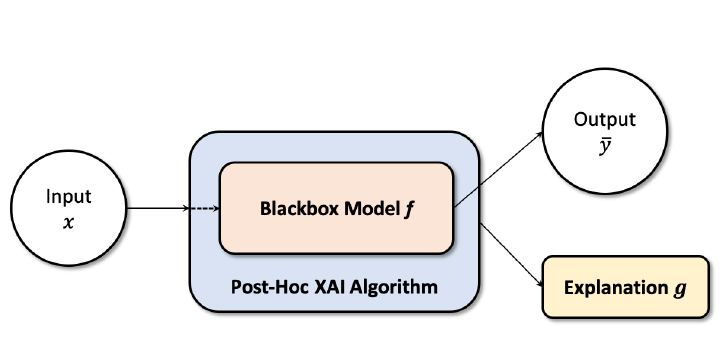
Post-Hoc 방식의 XAI 알고리즘은 모델 외부에서 모델에 대해 설명할 수 있는 알고리즘입니다. 모델의 성능을 해치지 않고 설명력을 더해준다는 점에서 매우 유용합니다. DeConvNets, Saliency maps, LRP 등이 이에 속합니다.
Evaluation Methodologies, Issues, and Future Directions
Evaluation Schemes
아직 Interpretability를 정량적으로 측정하는 데에 있어서 많이 미흡하지만 현재에 존재하는 evaluation scheme을 정리해보자면 다음과 같습니다.
System Causability Scale
user facing human-AI machine-interface에 대한 설명을 위해 고안.
Benchmarking Attribution Methods
feature attributions와 relative importance가 어느 정도 정확한지를 측정하기 위함.
BAM은 모델별로(model contrast) , 같은 모델 내에서 입력별로(input dependence), functionally equivalent inputs에 따라(input independence) explainer가 얼마나 성능을 보여주는지 측정합니다.
{kind=link}
- Model constrast scores
: object로 학습된 모델 와 가 리턴한 attribution에 대한 차이
- Input dependence rate
: scene-only 이미지로 학습된 경우, input dependence는 추가된 물체가 less important라고 attributed된 region을 리턴하는 비율을 측정
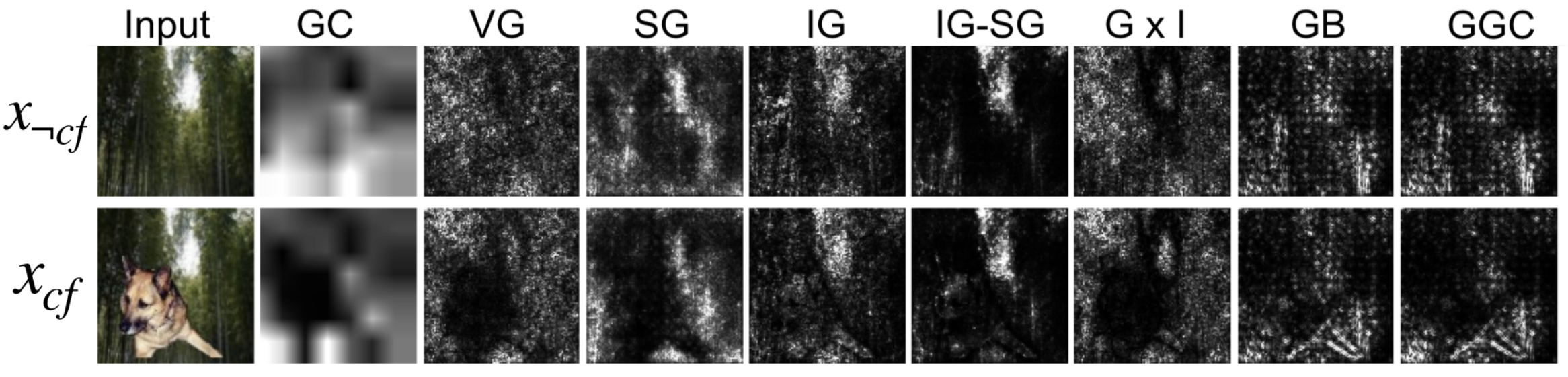
- Input independence rate
: scene-only 이미지로 학습한 모델이 주어졌을 때 input independence는 기능적으로 크게 중요하지 않은 패치가 붙어있는 이미지가 크게 explanation에 영향을 미치지 않는 비율을 측정
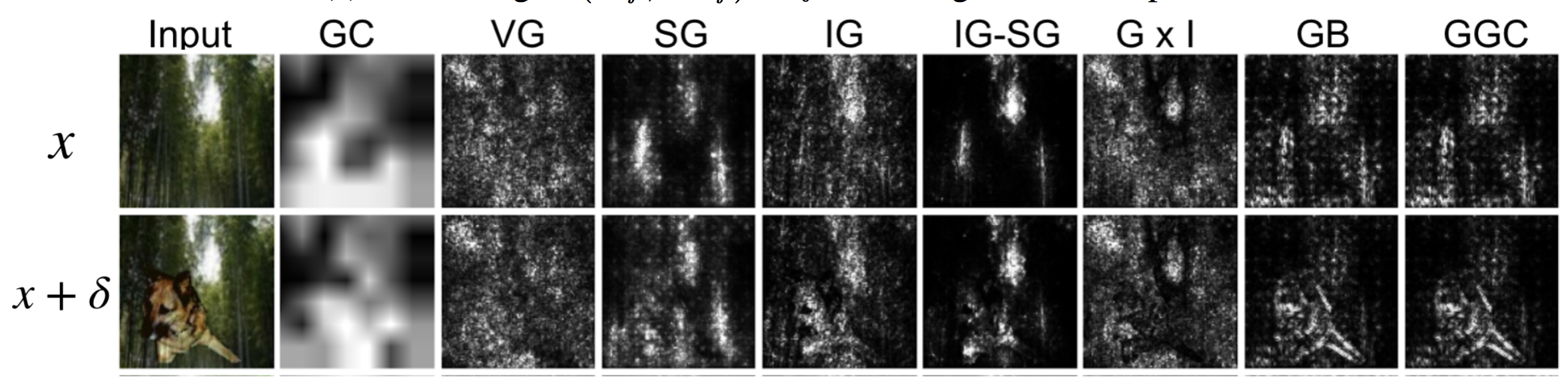
Faithfulness and Monotonicity
-
faithfulness: evaluate the correlation between importance scores of features to the performance effect of each feature towards a correct prediction
-
monotonicity: 피처 중요도에 따라 모델에 피처를 점진적으로 더해나가며 각 데이터 피처의 성능에의 기여도를 측정하는 방법
Human-grounded Evaluation Benchmark
사람의 평가를 벤치마크 삼아 설명 모델을 평가합니다. 다양한 의견을 수집함으로써 최대한 human bias를 제거하고자 합니다.
A Case-study on Understanding Explanation Maps
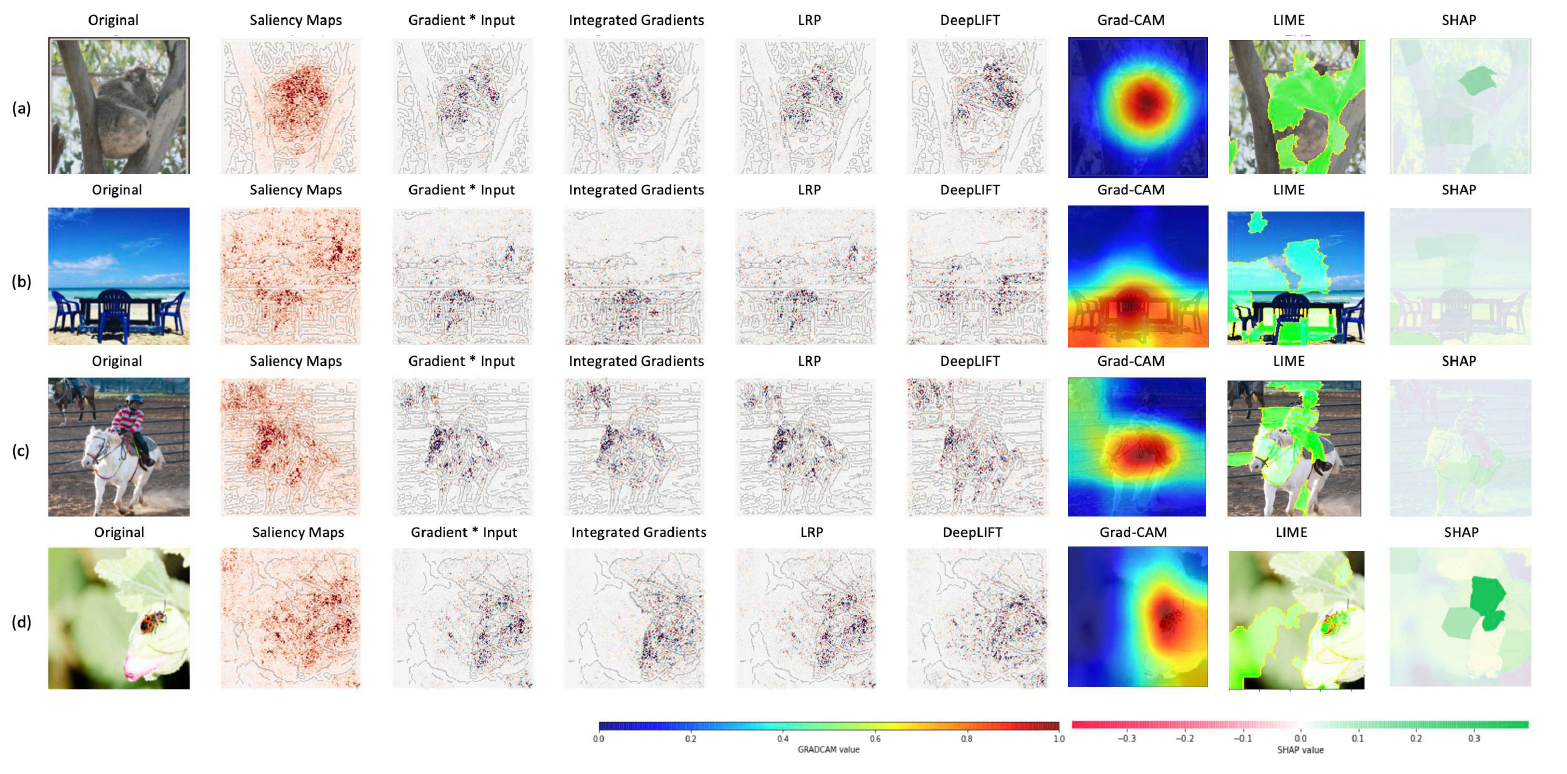
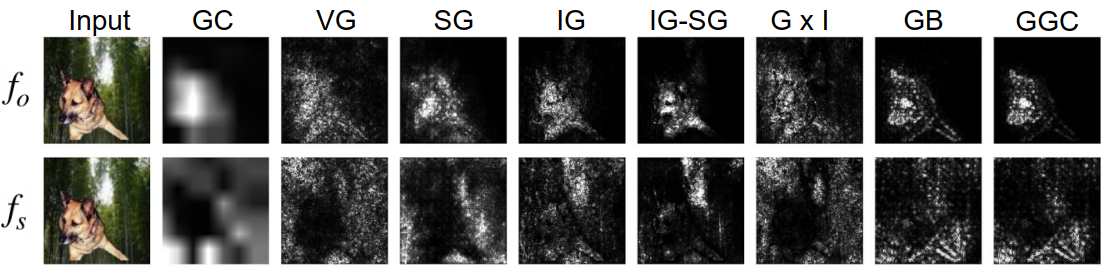
survey 논문에서 저자들이 직접 Saliency maps, gradient X input, integrated gradients (IG), LRP, DeepLIFT, Grad-CAM, LIME, SHAP의 방법을 4가지 이미지에 적용한 결과입니다. 참고로, 각 이미지의 경우 위에서부터 모델의 정확도는 94.5 (코알라), 38 (sanbar), 17.4 (말), 95.5 (무당벌레) 를 보여주었습니다.
GRAD-CAM value는 0~1의 범위를 갖고, 0은 no influence & 1은 highest influence of individual pixels (모델의 결정 내에서) 를 의미합니다. SHAP value의 경우에는 -0.3부터 0.3의 범위로 음수의 값은 모델이 해당 결정을 내리는 데에 부정적으로 기여한 부분 (decrease output class probability), 반대로 양수의 값은 해당 결정을 내리는 데에 긍정적으로 기여한 부분 (increase output class probability) 입니다.
Limitations
앞서 살펴본 것처럼 XAI 또한 여러 한계점을 가지고 있습니다.
- 사람이 XAI의 explanation maps을 추론하기가 힘들다는 점
- XAI 알고리즘에 대한 정량적인 평가가 어렵다는 점
입니다. 또한 알고리즘 자체가 더 개선되어야 하는 부분도 분명히 존재합니다. 일례로, explanation map visualization의 경우 Ghorbani et al. (2019)은 input image을 아주 조금 교란시켜도 (adding small perturbations) 잘 알려진 XAI 방법들이 리턴하는 결과가 매우 달라지는 걸 발견했습니다.
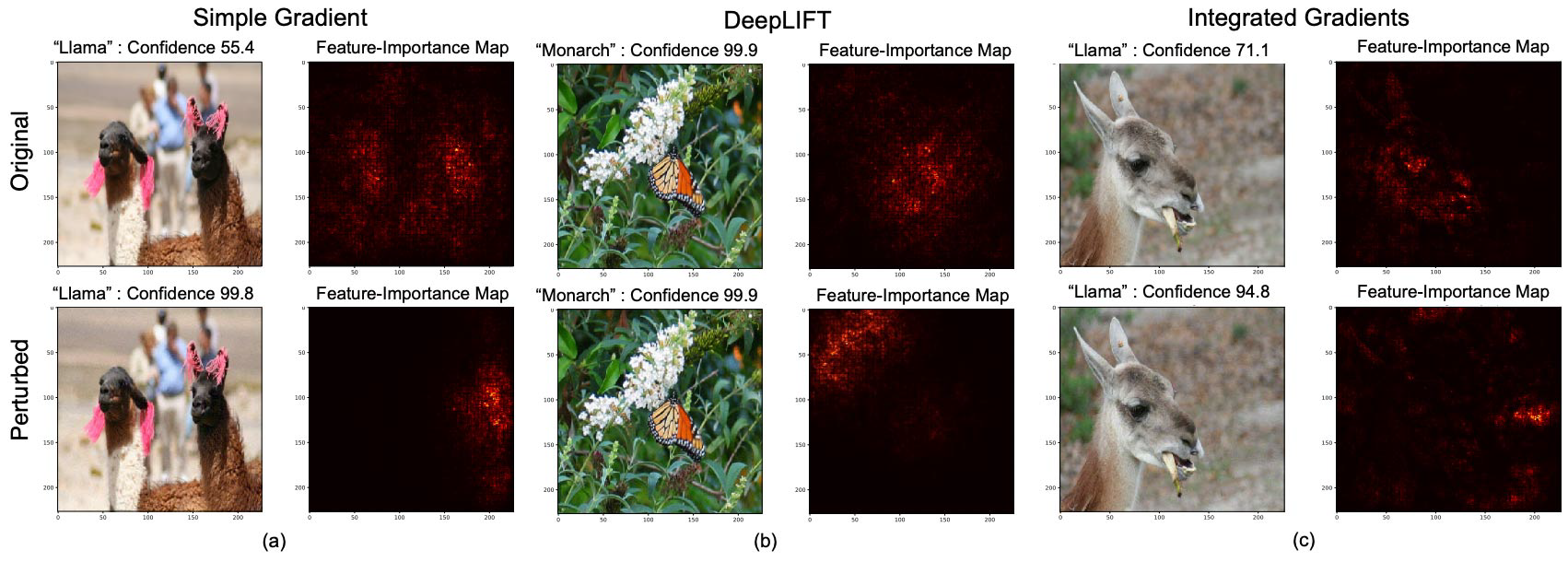
Conclusion
지금까지 XAI란 무엇인지, 왜 필요한지, 어떠한 모델이 있는지, 어떤 식으로 분류되는지에 대해 알아보았습니다.
XAI 알고리즘은 scope, methodology, usage의 기준으로 분류할 수 있었으며, scope의 경우 local과 global, methodology의 경우 perturbation과 gradient, usage의 경우 intrinsic, post-hoc으로 구분할 수 있었습니다. 이에 맞추어 LIME, SHAP, LRP, DeconvNets, Saliency Map, CAM 등의 다양한 알고리즘을 알아보았습니다.
정량적인 평가 방법의 부재와 같은 한계가 분명히 존재하지만 black-box 모델을 설명함으로써 모델의 신뢰성을 높이고, 현재 신뢰성의 부재로 인해 AI의 사용이 제한된 분야로까지의 확장을 꾀하기 위해 XAI에 대한 지속적인 연구가 이루어지고 있습니다.
