Opportunities and Challenges in Expainable Artificial Intelligence (XAI): A survey
by Arun Das and Paul Rad
본 게시글은 Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey 논문의 내용을 정리하고, XAI 연구의 전반적인 동향을 이해하는 것을 목표로 합니다.
논문는 https://arxiv.org/abs/2006.11371 에서 확인하실 수 있습니다.
본 게시글의 이미지는 출처가 적혀 있으며, 출처가 적혀있지 않은 이미지는 원 논문의 이미지입니다.
Abstract
- 인공 신경망 기술은 다양한 분야에 사용되고 있습니다.
- 하지만 인공 신경망의 블랙박스 특징 때문에 사용이 제한되는 분야가 발생합니다.
- 설명가능 인공지능(XAI) 기술은 인공지능의 결정에 대해 해석적이고, 직관적이며, 이해가능한 설명을 제공합니다.
- 본 논문은 XAI를 scope, methodology, explanation level에 따라 정리하며 설명했습니다.
- 또한 XAI 연구분야에서 2007년 부터 2020년까지 역사적 타임라인을 보여 주며, 연구를 정리했습니다.
- 추가적으로 8개의 XAI알고리즘의 explanation maps 를 평가하며, 한계점과 미래 발전 방향에 대해 논할 것입니다.
Introduction
인공지능
- DNNs(Deep Neural Networks) 은 많은 파라미터들을 가지고 있기 때문에 점점 이해하기 어려워지고 있습니다.
- 이에 더해서 심층 신경망의 결정을 해석하는 것은 관련 지식을 필요로 합니다.
- 이런 지식들은 AI 비전문가나, 최종사용자와 같이 정확한 결과가 더 중요한 사람들에게는 필요가 없는 지식일 수 있습니다.
XAI 연구의 이유
지난 연구들에 의하면 우리가 XAI를 필요로 하는 이유는 다음 키워드로 정리될 수 있을 것입니다.
- 인간의 호기심
- 더 좋은 학습을 유도하기 위해
- 결정에 대한 투명성, 신뢰성, 공정성 확보를 위해
논문의 목표
- XAI를 시간 순서대로 파악하고, 세가지 카테고리로 분류해 명확성과 접근성을 올립니다.
- XAI 연구의 핵심 수학적 모델을 요약하고 분류하며 한계와 발전 방향을 평가할 것입니다.
- 8개의 XAI알고리즘의 explanation maps를 생성하고 분석해 볼 것입니다.
기타
-
본 논문은 2007년부터 2020년까지 출판된 연구를 기반으로 했습니다.
-
연구는 Google Scholar, ACM Digital Library, IEEEXplore, ScienceDirect, Spinger, arXiv 등에서 참고하여 정리했습니다.
Taxonomies and Organization
Taxonomies
본 논문은 XAI를 Scope, Methodology, Useage 의 세 가지 관점에서 분류했습니다.
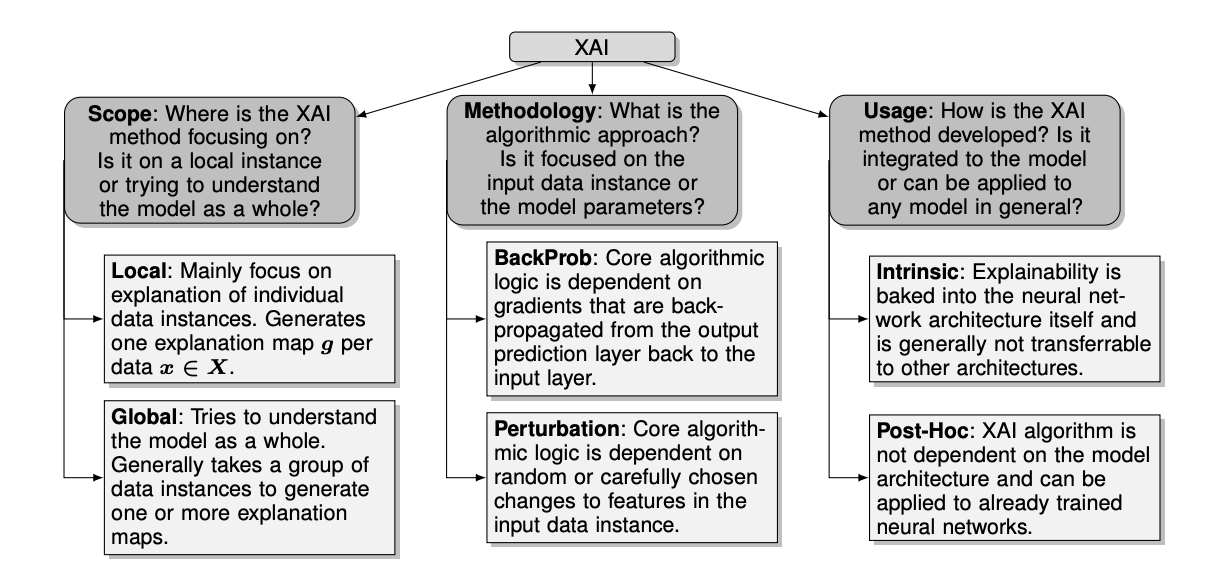
-
Scope
-
데이터에 대한 설명 범위를 말합니다.
-
Local : 전체 데이터 X 안의 단일 데이터 x에 대해서만 설명이 가능하도록 설계된 방법
-
Global : 모델 전체에 대해서 인사이트를 제공하며, 입력 전체의 배열에 대해 설명을 제공하는 방법
-
-
Methodology
- 설명가능 모델 내부에 존재하는 핵심 알고리즘의 방향성을 말합니다.
- Backpropagation-based : 역전파 과정중, 편미분을 활용하여 설명력을 얻습니다.
- Perturbation-based : occlusion, 부분적으로 제거된 피쳐, 마스킹, 조건부 샘플링 등의 방법을 사용합니다. 역전파가 필요 없다는 장점이 있습니다.
-
Usage
- 특정 모델에만 적용될 수 있는지, 외부 알고리즘에도 적용될 수 있는지를 말합니다.
- Model-intrinsic : 솔루션이 특정 모델 구조에 종속되어 있는 기법입니다.
- Post-hoc(model-agnostic) : 이미 잘 예측중인 인공지능 모델에 대입될 수 있는 방법입니다. 다양한 형태의 데이터에도 적용이 가능하게 됩니다.
평가방법의 제공
-
Section 7에서, XAI알고리즘의 정량적, 정성적 평가를 위해 몇가지 평가 알고리즘을 제안했습니다.
-
투명성,신뢰성,편향이해 -
이 평가방법은 아직 완벽하지는 않지만, 미래에 많은 발전가능성을 가지고 있습니다.
오픈 소스
-
깃허브 플랫폼의 오픈소스 패키지를 제공합니다.
-
많은 사용자가 기여한 알고리즘이 포함된 패키지들을 선택했습니다.
수식 표기
본 논문에서 제안된 모든 수식은 다음 표현 방법을 따릅니다.

Definitions and Preliminaries
본 논문에서는 XAI의 정의를 다음과 같이 설정했습니다.
AI 시스템의 신뢰성과 투명성을 향상시키기 위해 설계된 일련의 기술과 알고리즘
DNN과 XAI
- 신경망을 설명하기 위한 접근이 많은 연구에서 제안된 바 있습니다.
- 신경망에 적용된 설명가능 인공지능의 목표는 다양한 방법으로 모델의 예측값을 설명하는 것에 집중하게 됩니다.

-
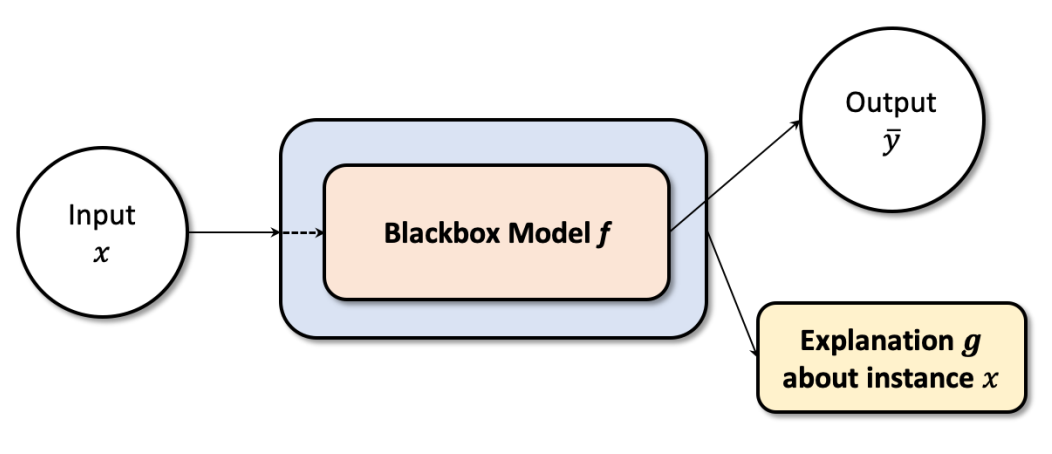
논문에서 DNNs를 설명하기 위해 설명한 그림입니다.
-
딥러닝 모델은 하나의 가 딥러닝 모델 를 통과하여 라는 결과를 산출합니다.
-
이때 는 전체 데이터 안의 단일 데이터이며, 다른 메타데이터가 포함되어있지 않은 데이터입니다.
-
가 딥러닝 모델을 통과하여 를 반환하는데, 이는 특정 클래스 에 포함된 결과입니다.
-
이 신경망 모델을 로 표현합니다.
용어 정리
Interpretability
해석가능성(Interpretability)이란 특정 알고리즘이 어떻게 동작하는지 이해할 수 있게, 충분한 표현을 제공하는 알고리즘의 기능이나 특징이다.
- 해석가능한 도메인은 이미지나 텍스트 등 사람이 이해할 수 있는 영역을 포함합니다.
Interpretation
해석(Interpretation)이란 복잡한 도메인의 단순화된 표현이다. 예를 들어 ML모델의 결과물이나, 사람이 이해가능/합리적인 의미있는 콘셉트이다.
-
rule-based 모델의 예측 결과물은 rule-set을 통해 쉽게 해석될 수 있습니다.
-
CNN 네트워크 등은 의사 결정에 영향을 미친 부분을 추론할 수 있습니다.
Explanation
설명(Explanation) 이란 ML모델이나 외부 알고리즘에 의해 생성된 추가적인 메타 정보이다. 이는 피처 중요도나, 입력 데이터와 출력 데이터의 관련성을 묘사한다.
-
예를 들어 이미지에 대해서는 입력 이미지와 같은 크기의 픽셀 맵인 explanation map이 생성될 수 있습니다.
-
텍스트에 대해서는 word-by-word influence scores가 있습니다.
White-box
딥러닝 모델 에 대해서, 모델 파라미터 와 모델 구조가 알려져 있는 경우, 이 모델을 화이트박스(White-box)라 여긴다.
-
화이트 박스 모델은 모델 디버깅을 용이하게 하고, 신뢰도를 향상시킵니다.
-
하지만 단순히 모델 구조와 파라미터에 대해서 아는 것은 모델을 설명 가능하게 하지는 않습니다.
Black-box
모델 파라미터나 네트워크 구조가 최종 사용자에게 숨겨져 있으면 이를 블랙박스(Black-box)라고 여긴다.
- 웹 기반 딥러닝 모엘 서비스나, 제한된 비즈니스 플랫폼에서의 API식 모델은 입력 데이터를 받아 단순히 결과물만 반환하는 블랙박스적 구성을 띄고 있습니다.
논문에서는 4개의 용어를 더 설명하는데, XAI가 중요한 이유와 함께 설명합니다.
이것들은 의료, 신용등급 측정 등에서 인공지능이 사용되기 위해 필요한 윤리성, 사법성, 안전성을 가지기 위해 필요한 것들이라고 말합니다.
Transparent
딥러닝 모델의 표현이 사람이 알아듣기 충분한 경우, 모델을 투명하다(Transparent)고 여긴다.
1) XAI는 투명성을 증가시킵니다.
XAI는 결과물을 사람이 인식할 수 있게 해석하므로 투명성과 공정성이 증가합니다.
투명성이 높으면 결과물의 질이 상승하고, 외부 공격을 차단할 수 있게 됩니다.
본 논문은 투명성이 필요한 이유를 잘 나타내는 예시로 두 개를 제시합니다.
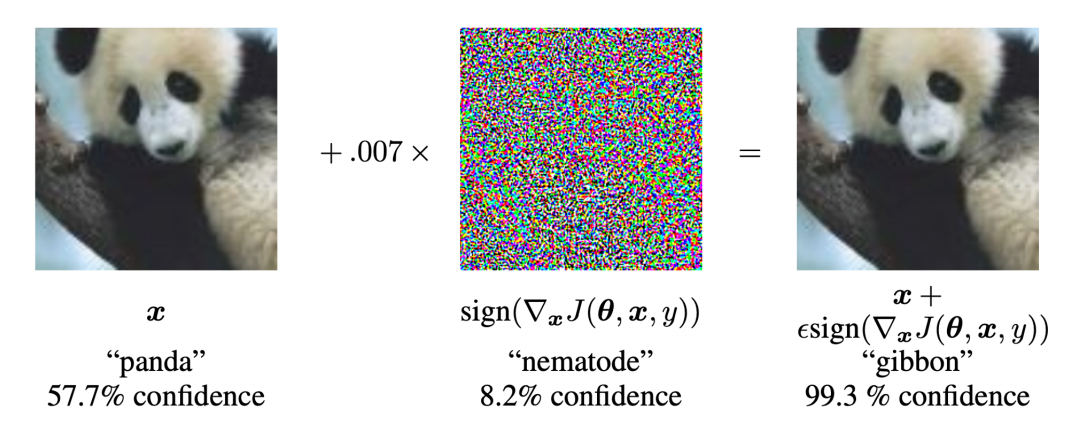
첫 번째 예시로 적대적 공격을 이야기하며 다음 사진을 보여 주었습니다. 원본 이미지에 약간의 적대적 노이즈를 더해 주니 판다를 긴팔원숭이로 이해하게 되는 문제가 있었다고 합니다.
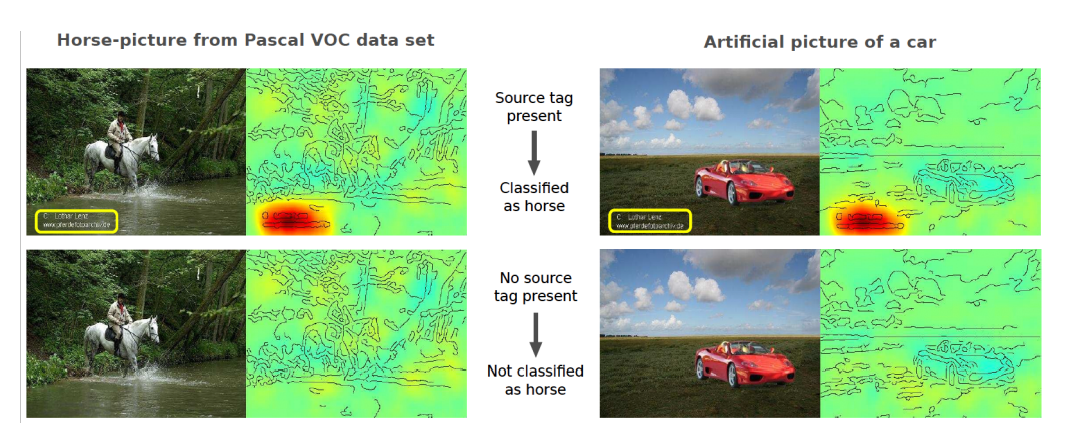
두 번째 예시로 이미지를 분류할 때 워터마크에 집중하여 분류하는 모습을 보였던 사진입니다. 이미지에서 텍스트를 제거하니 정상적인 분류가 아닌 값을 반환합니다. 인공지능 모델이 텍스트에 대해 학습된 것으로 볼 수 있을 것입니다.
논문은 우리가 자동화된 알고리즘에 의존할 수록 AI알고리즘이 공격을 방어하고 투명한 결과를 제공하는 것은 매우 중요해져야 할 것이라고 말합니다.
Trustbility
딥러닝 모델의 신뢰가능성(Trustbility)은 최종 사용자인 인간으로서, 현실 환경에서에서 모델의 의도한 동작에 대해서 측정된 확신의 정도이다.
2) XAI는 모델의 신뢰성을 높입니다.
인간은 사회적 동물로서 특정 상황에 대한 지식과 사실에 의해 결정을 내립니다.
자연스럽게 아무 설명이 없는 최적의 결정보다 덜 합리적인 결정에 대해 과학적 설명/논증이 있는 것이 더 낫다고 여기게 될 것입니다.
따라서 '특정 결정이 왜 내려졌는가' 는 최종 사용자가 인공지능에 대해 신뢰감을 가지는 데 매우 중요한 요소가 됩니다.
Bias
딥 러닝 알고리즘의 편향(Bias)은 편향된 가중치, 편견, 선호, 인간의 데이터 수집이나 학습 알고리즘 부족에 의해 유발된 학습된 모델의 경향성이다.
3) XAI는 모델의 편향을 이해하고 공정성을 증가시킵니다.
XAI 기술을 통해 모델의 행동을 이해하는 것은 모델의 편향과 왜도에 대한 이해를 증가시킬 수 있습니다.
입력 공간(input space)에 대한 이해는 편향이 줄어든 모델이나, 더 빠른 모델에 대한 연구가 가능하게 할 것입니다.
정리
XAI 기법은 인공지능을 사용하고 제작하는 데 많은 이점을 가져다 줄 것입니다. 하지만 설명을 위해 적합한 방법을 선택하는 것은 많은 주의와 노력이 필요합니다.
이후 본 논문은 다양한 기법을 제시해 보며 논의합니다.
Scope of Explanation
앞서 이야기했던 세 가지 분류 중 설명 범위에 대해 분류한 예시들입니다.
Local Explanations
-
첫 번째 분류는 '로컬 설명' 입니다.
-
의사가 분류 모형의 결과를 가지고 진단을 내린다고 가정하면, 의사는 인공지능의 예측에 대해 깊은 예측과 '왜 그렇게 생각했는지' 명확한 설명이 필요합니다.
-
위 사례와 같은 유형의 문제가 Locally explainable한 방법의 한 예입니다.
로컬 설명은 모형 와 단일 데이터 를 통해 설명 내용인 를 만드는 것입니다.
논문에서는 그림으로 다음과 같이 표현합니다.
- 초기 연구는 히트맵, rule-based한 방법, 베이지안, 피처 중요도, 등을 사용했습니다.
- 이 결과들은 항상 양수인 real-valued metrics/vectors였다는 문제점이 있습니다.
- 최근 연구는 attribution maps나 그래프 기반, 게임이론 기반 등을 사용해 양수와 음수의 결과를 모두 사용합니다.
- 주로 양의 분포값은 특정 피처가 결과가 나오는데 긍정적 영향을 미친 것이고, 음의 분포값은 결과의 부정적인 영향을 미치는 것입니다.
Activation Maximization
참고 : https://m.blog.naver.com/vyoyo/221552750022
- CNN에서 Layer-wise 한 피처의 중요도를 파악하는 방법입니다.
- 특정 채널의 activation을 최대화 하는 패턴가 있다면, 그 가 채널이 학습한 피처의 패턴이라고 볼 수 있다는 아이디어에서 시작합니다.
- 실행 알고리즘은 다음과 같습니다.

- 랜덤한 픽셀로 구성된 이미지 을 구한다.
- 이미지를 파라미터가 고정된 학습 모델에 넣고 그래디언트를 구한다.
- 정해진 학습률만큼 activation값이 최대화하는 방향으로 움직인다.
- 학습이 완료되면 는 특정 패턴의 이미지가 나타날 것이다.
- 학습이 완료되면 다음과 같은 결과가 나오게 됩니다.
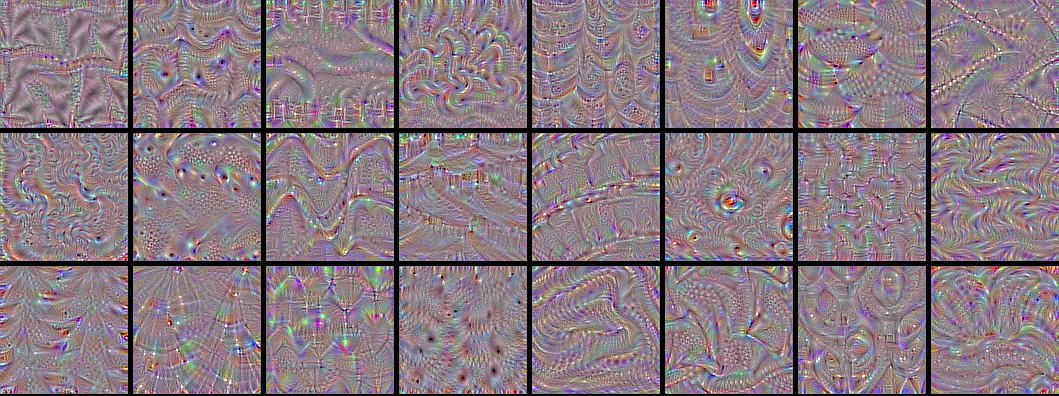
출처 : How convolutional neural networks see the world
Saliency Map Visualization
참고 자료 : https://yeoulcoding.tistory.com/76
- 샐리언시 맵은 사람이 물체를 볼 때 관심 영역에 시선을 먼저 집중하는 데서 아이디어를 얻습니다.
- 샐리언시 맵은 출력 카테고리에 대한 모델의 그래디언트를 계산합니다. 이 그래디언트를 시각화하면 픽셀에 대한 중요도를 볼 수 있을 것입니다.
- 이 때 양의 그래디언트를 가지면 출력 결과에 더 큰 영향을 줄 것이라는 가정을 합니다.
- 저자는 1) 클래스 모델 시각화, 2) image-specific 시각화의 두 가지 시각화 방법을 제안했지만, 1) 클래스 모델 시각화는 글로벌 기법이므로 후에 설명합니다.

- 샐리언시 맵의 추출은 다음 과정을 통해 이루어집니다.
- 명확하게 라벨링된 이미지와 잘 훈련된 모델을 준비한다.
- 이미지를 모델에 넣어 출력 벡터를 구한다.
- 구한 벡터를 input 이미지에 대해 편미분하여 기울기를 구한다.
- 3)의 결과의 3개의 값(R, G, B) 중 최댓값을 취한 뒤에 절댓값을 취한다.
- 결과를 반환한다.
Layer-wise Relevance BackPropagation (LRP)
참고 : https://angeloyeo.github.io/2019/08/17/Layerwise_Relevance_Propagation.html
- LRP 기술은 DNN의 출력값을 분해(Decompose)하여 각각의 피처에 대한 타당성 점수(relevance scores)를 구합니다.
- CNN에서는 타당성이 레이어간 전파되며, RNN 에서는 타당성이 은닉 상태와, 메모리 셀에 전파되는 등 모든 모델에 적용이 가능합니다.
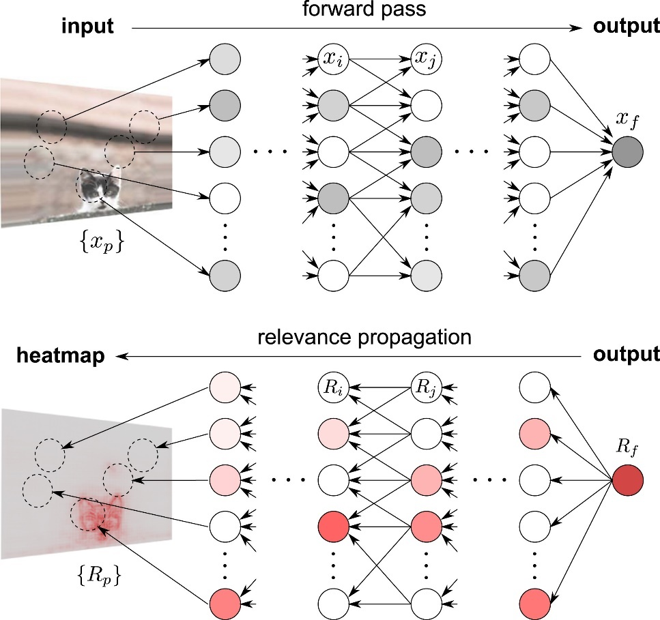
출처 : Layer-wise Relevance Propagation - 공돌이의 수학정리노트
-
각 층에서 역순으로 출발하여 각 층의 타당성 점수를 전파합니다.
-
하나의 뉴런의 출력은 그 노드에 대한 타당성 점수의 합으로 나타내어집니다.
-
타당성 점수의 전파는 다음 그림과 같이 표현됩니다.
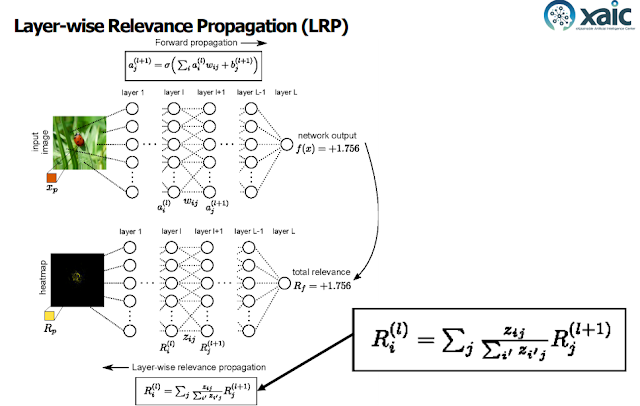
출처 : 딥러닝 안에서 일어나는 과정을 해석하는 설명가능 인공지능 기술
- 한 계층의 타당성 점수의 합은 이전 계층의 모든 타당성 점수의 합으로 나타내어집니다. (보존 공식)
- 이렇게 얻은 마지막 계층의 타당성 점수를 시각화하면 중요도를 시각적으로 표현할 수 있을 것입니다.
- LRP 방법은 모델의 정확도 손실 없이 연산량이나 저장 비용 등을 절감하는 network pruning으로도 사용될 수 있습니다.
Local Interpretable Model-Agnostic Explanations (LIME)
참고 : https://yjjo.tistory.com/3
-
LIME은 '중요한 부분일 수록 변형되었을 때 예측값이 크게 변한다'는 아이디어에서 출발해, 입력을 변형시키면서 예측값을 크게 변화시키는 값을 찾는 방법입니다.
-
이미지에서 LIME은 연속적인 '슈퍼픽셀'을 통해 중요성을 찾으려 하는 방법입니다..
-
0 (목표값이 없다) 또는 1(목표값이 있다) 을 예측하는 방법 대리 모델을 생성하는 방법으로 문제를 단순화 하게 됩니다.
-
이미지 형태 데이터에 대해서는 다음 방식으로 이미지를 변형합니다.
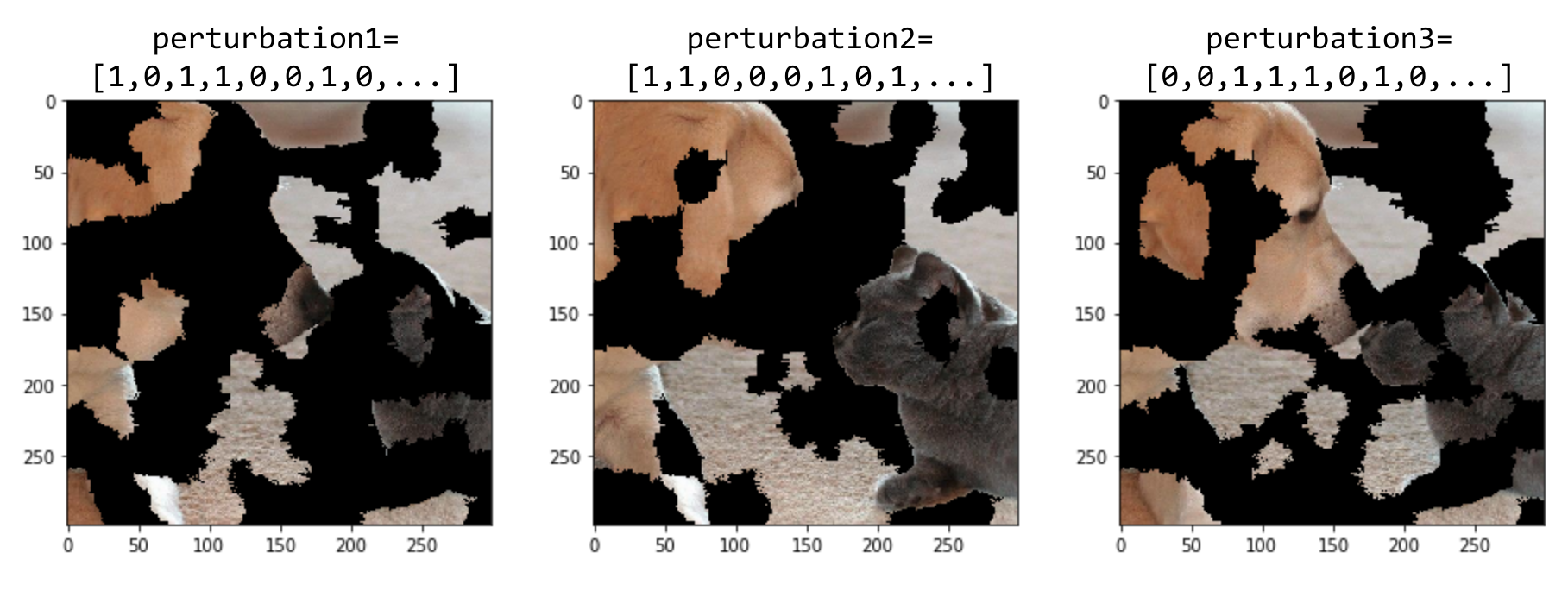
출처 : Interpretable Machine Learning for Image Classification with LIME
- 식으로 최적화 문제를 나타낼 수 있습니다.
- LIME는 위 식 ( )을 최소화하는 방향으로 학습을 진행합니다.
- 는 와 의 차이이며, 이를 최소화해야 합니다. (예측 값이 비슷할수록 중요한 데이터가 포함되어 예측 오차가 작아질 것입니다.)

출처 : Interpretable Machine Learning for Image Classification with LIME
- LIME 분석을 텍스트 데이터에 대해 출력하면 다음과 같은 결과물이 나타납니다.

출처 : 머신러닝 모델의 블랙박스 속을 들여다보기 : LIME
후속 연구
최근에는 LIME을 발전시키는 많은 후속연구들이 나타났습니다. 본 논문은 그 사례를 몇 가지 보여줍니다
-
Sound-LIME(SLIME) : LIME을 활용해 목소리 탐지 시스템을 설명하고자 했습니다.
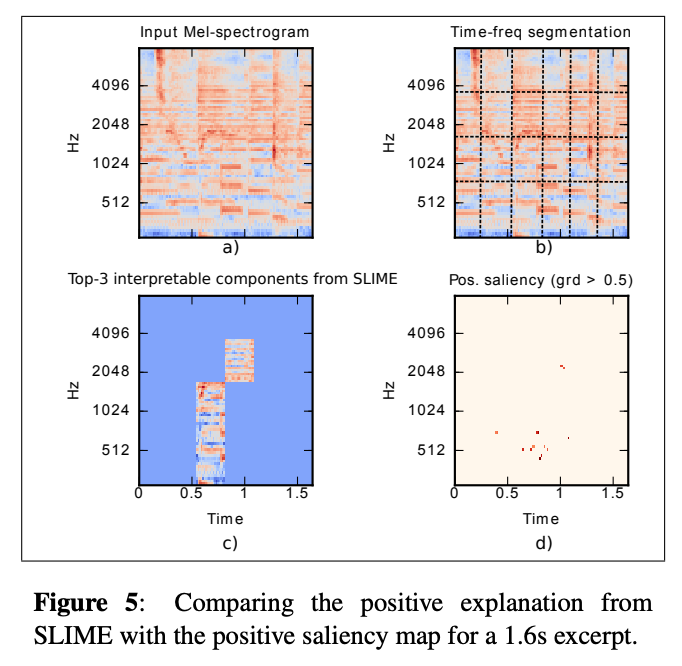
출처 : Local Interpretable Model-Agnostic Explanations for Music Content Analysis
-
KL-LIME : 베이지안 모델을 설명하기 위한 LIME 모델로, KL-divergence (두 확률분포 간 차이)를 최소화하는 모형을 발견했습니다.
-
DLIME : 무작위 변형이 아닌 계층적 클러스터링이나 KNN기법을 사용한 방법입니다. 기존 방법에 비해 더 안정적으로 분석이 가능해졌다고 합니다.
-
Quadratic-LIME(QLIME) : 대리 모델을 비선형으로 설정해도 LIME을 적용할 수 있게 했습니다.
-
Modified Perturbed Sampling operation for LIME(MPS-LIME) : 슈퍼픽셀 선택 방법을 변경했습니다. (그래프적 방법 도입)
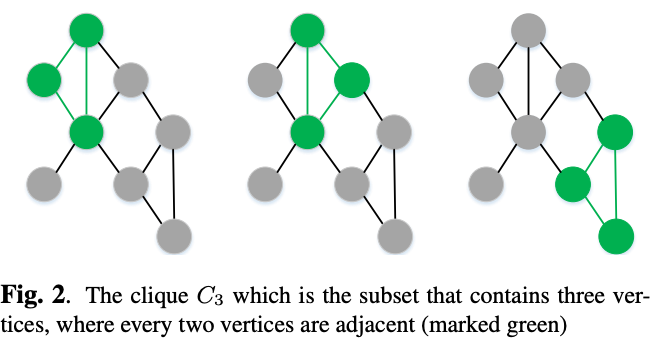
출처 : A Modified Perturbed Sampling Method for Local Interpretable Model-agnostic Explanation
SHapley Addictive exPlanations (SHAP)
참고 : https://datanetworkanalysis.github.io/2019/12/23/shap1, https://eair.tistory.com/30
- SHAP는 input 가 예측값에 미친 피처별 기여도를 설명합니다.
- 섀플리값은 '연합 게임이론'에서 플레이어의 기여도에 따라 보상을 배분하는 방법에 대한 표현입니다.
- 기여도를 분석하는 피처는 테이블 형태에서는 각각의 행이, 이미지에서는 슈퍼픽셀이 될 수 있습니다.
- 이 방법은 의 식으로 설명됩니다.
- 는 특성 벡터로서 특정 피처가 있으면 1, 없으면 0으로 계산하고, 는 섀플리 값 (기여도)를 의미합니다.
- 는 존재하는 피처들의 섀플리 값의 합으로 설명됩니다.
기본적인 SHAP 방법은 이후 다양한 방법에 적용되었습니다.
KernelSHAP
- LIME 모형에 SHAP커널을 사용하여 값을 추정합니다.
- 대량의 데이터에서 필요한 계산량을 감소시켰습니다.
- 모든 머신러닝 알고리즘에 적용될 수 있습니다. (피처를 랜덤 샘플링해서 제거하는 방식 사용)
LinearSHAP
- 최대 연합의 크기 이 작은 경우에서 효율적인 방법입니다.
DeapSHAP
-
DeepLIFT 방법을 적용했습니다.
-
DeepLIFT는 역전파 시 기울기 변화량을 사용해서 영향력을 계산하는 방법입니다.
출처 : Learning Important Features Through Propagating Activation Differences(논문 발표)
후속 연구
SHAP 방법은 의료 분야에서 의사결정을 설명하기 위해 종종 사용되어졌습니다.
본 논문은 의료 분야에서 SHAP의 추가적인 적용에 대해서 설명합니다.
-
extendedSHAP : 이상 탐지를 위해 사용되던 오토인코더를 설명합니다. 오토인코더가 재구성(reconstruction)할 때의 오차를 사용해 확인하게 됩니다.
-
Baseline Shapley(BShap) : 특정 피처가 상대적으로 덜 중요할 때 비직관적인 설명을 내는 문제를 해결했습니다.
-
KernelSHAP 의 확장 : 상관관계가 있는 피처들을 해석하기 위해 개발되었습니다.
-
TreeExplainer : SHAP을 트리 모델에 대해 확장했다. 트리 모델의 로컬 설명이 다항시간 안에 계산될 수 있음을 밝습니다.
-
LSTM에 대해 확장 : DeepSHAP 알고리즘을 사용해 LSTM에 확장했습니다.
Global Explanations

- 글로벌하게 설명하는 방법은 딥러닝 모델을 더 해석하기 쉬운 선형 모델로 추론하는 방법이라고 볼 수 있습니다.
- Rule-based나 트리 모형, 선형 모델은 그 자체로도 글로벌하게 해석가능한 모델이라 추가적인 방법이 필요하지 않습니다.
- 일반적으로 입력들의 배열에 대해서 블랙박스 모형의 전반적인 경향을 보여주게 됩니다.
Global Surrogate Models
참고 : https://christophm.github.io/interpretable-ml-book/global.html
- Global Surrogate Model은 비선형적 모델을 설명이 가능한 선형 모델이나 트리 모델로 근사시키는 방법입니다.
- 본 모델을 설명하기에는 너무 복잡하기 때문에 훨씬 단순한 모형으로 표현하고자 하는 것입니다.
- "어떻게 내 AI 모델이 일반화될 수 있는지", "어떻게 내 AI모델의 변형이 작동하는지"에 대한 질문에 대답합니다.
- Surrogate Model의 대표적인 예시는 feature-rich layer embeddings 가 있습니다.
- SHAP, LIME등을 대리자로 사용해서도 예측할 수 있습니다.
모델의 진행은 다음과 같습니다.
- 데이터셋 를 선정한다.
- 블랙박스 모델 에 를 넣어 예측값을 생성한다.
- 해석가능한 모델의 타입을 설명한다.(선형 모델, 의사결정트리...) 이를 대리 모델로 선정한다
- 와 (예측값)에 대해 대리 모델을 학습시킨다.
- 대리 모델을 해석한다.
Class Model Visualization
참고 : https://glassboxmedicine.com/2019/07/13/class-model-visualization-for-cnns/
-
Activation Maximization을 Class Model을 사용하여 글로벌하게 확장한 방법입니다.
-
이미지 클래스를 분류하는 모델 는 클래스 이미지 에 대해 예측값을 반환합니다.
-
이 클래스 이미지의 확률 를 최대화하는 방향으로 학습되게 됩니다.
-
설명 이미지는 으로 표현됩니다.
-
L2 Norm부분은 이미지가 너무 극단적인 값으로 뛰는 것을 막아주게 됩니다.
-
이렇게 생성된 이미지는 블랙박스 모델이 특정 클래스에 대해 어떤 특징을 학습했는지를 나타낼 수 있습니다.
-
몽환적이고, 알록달록한 색 때문에 생성된 이미지를 'Deep Dream' 이라고 부르기도 한다고 합니다.

출처 : DeadNet: Identifying Phototoxicity from Label-free Microscopy Images of Cells using Deep ConvNets
LIME Algorithm for Global Explanations
참고 : https://yjjo.tistory.com/3
- 서브모듈러 선택 알고리즘(SP-LIME으로 불린다) 을 사용해 전역 중요도를 생성합니다.
- 동작원리가 surrogate model과 비슷하다고 볼 수 있습니다.
방법
- 블랙박스 모델 와 데이터 을 정의해 LIME을 수행한다
- B는 우리가 선택한 데이터의 집합(Budget)이다.
- 를 최대한 많이 설명하는 가장 적은 데이터 입력을 수행하는 경우를 에서 찾는다.
- 이때 탐욕 알고리즘 (전체를 모두 수행하는 방법) 이 사용된다.
Concept Activation Vectors (CAVs)
- 신경망의 내부 상태를 인간이 이해할 수 있는 영역으로 변환합니다.
- 해석가능한 글로벌 모델을 라 할 때, 로 표현가능하게 하는 방법입니다.
- 은 블랙박스 모델 의 벡터 표현, 는 인간이 이해할 수 있는 벡터 공간입니다.

- 얼룩말을 가지고 긍정적(positive) concept인 (줄무늬 등)과 부정적(Negative) concept인 으로 분리했습니다.
- 특정 데이터 가 와 을 구분할 수 있는 이진 분류 모델을 학습시킵니다.
Testing with CAVs
-
CAV의 방법 중 하나로 TCAV가 있습니다.
-
그래디언트 기반 방법처럼 방향도함수(directional derivatives)를 사용하는 방법입니다.
-
특정 입력에 대한 의 예측값의 민감도를 평가합니다.
-
TCAV 점수는 입력값 변화에 따른 특정 레이어 출력()의 변화량으로 설정합니다.
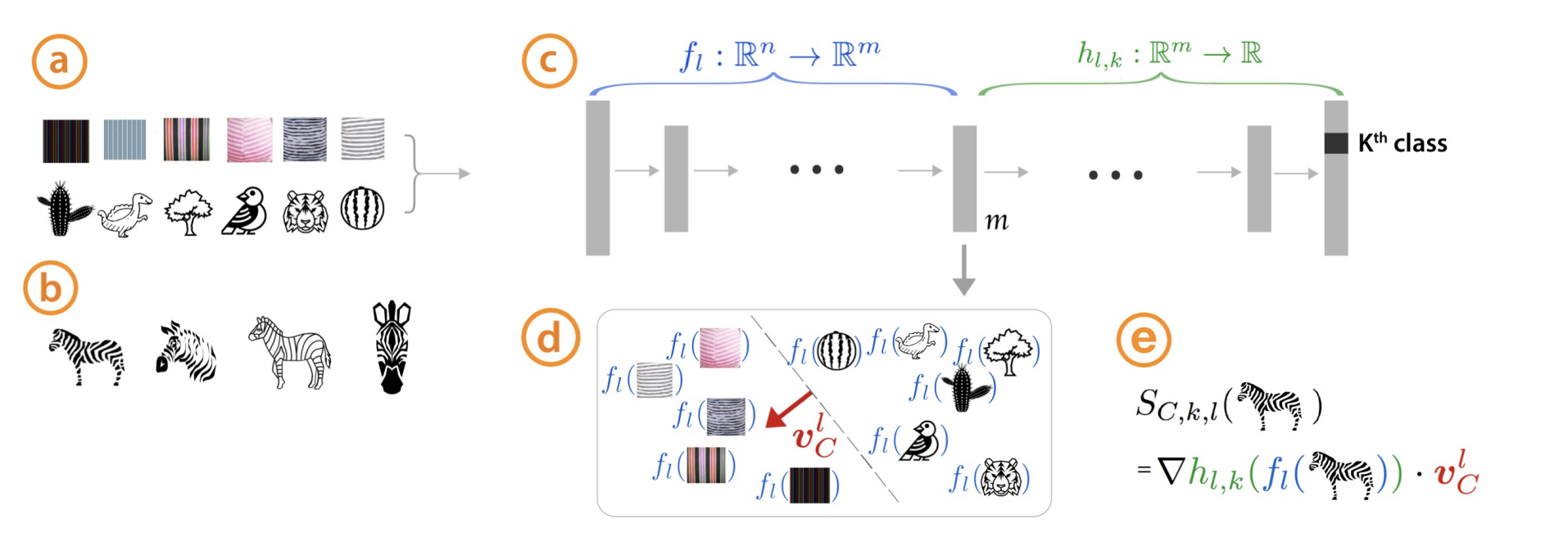
- TCAV는 입력 특징이 적절하게 선택되지 못하면 좋은 결과를 얻지 못한다는 단점이 있습니다.
- 서로 관련성이 높은 특징 또한 성능을 감소시킬 수 있습니다.
후속 연구
CAV 방법은 이후에 다양한 발전이 있었습니다.
- Automatic Concept-based Explanations (ACE) : 다중 해상도(multi-resolution) 세그먼테이션을 수행할 수 있게 한 연구입니다.

출처 : Towards Automatic Concept-based Explanations
- Casual Concept Effect(CaCE) : 딥러닝 모델에 대한 high-level concepts의 있고 없음에 따른 인과관계에 집중하는 방법이라고 합니다.
- ConceptSHAP : 각각 발견된 콘셉트의 중요성과 완전성(completeness) 점수를 계산합니다. 특정 지역에 대해 콘셉트를 유지하는 클러스터링을 수행하게 됩니다.
Spectral Relevance Analysis(SpRAy)
-
SpRAy는 LAP설명법을 기반으로 한 로컬 인스턴스의 최상단 부분을 설명하는 기법입니다.
-
LRP 모델에서 자주 나오는 특징을 파악하고 분석하게 합니다.
-
자세한 설명은 알고리즘을 참고해서 보면 이해하는 데 도움이 될 것 같습니다.

-
LRP를 통과한 결과값에 대해 Specral Cluster Analysis(SC) 와 EigenMapAnalysis를 수행하게 됩니다.
-
이렇게 나온 결과물로 importrance cluster가 반환되는데, 이걸 t-SNE 등으로 시각화할 수 있습니다.
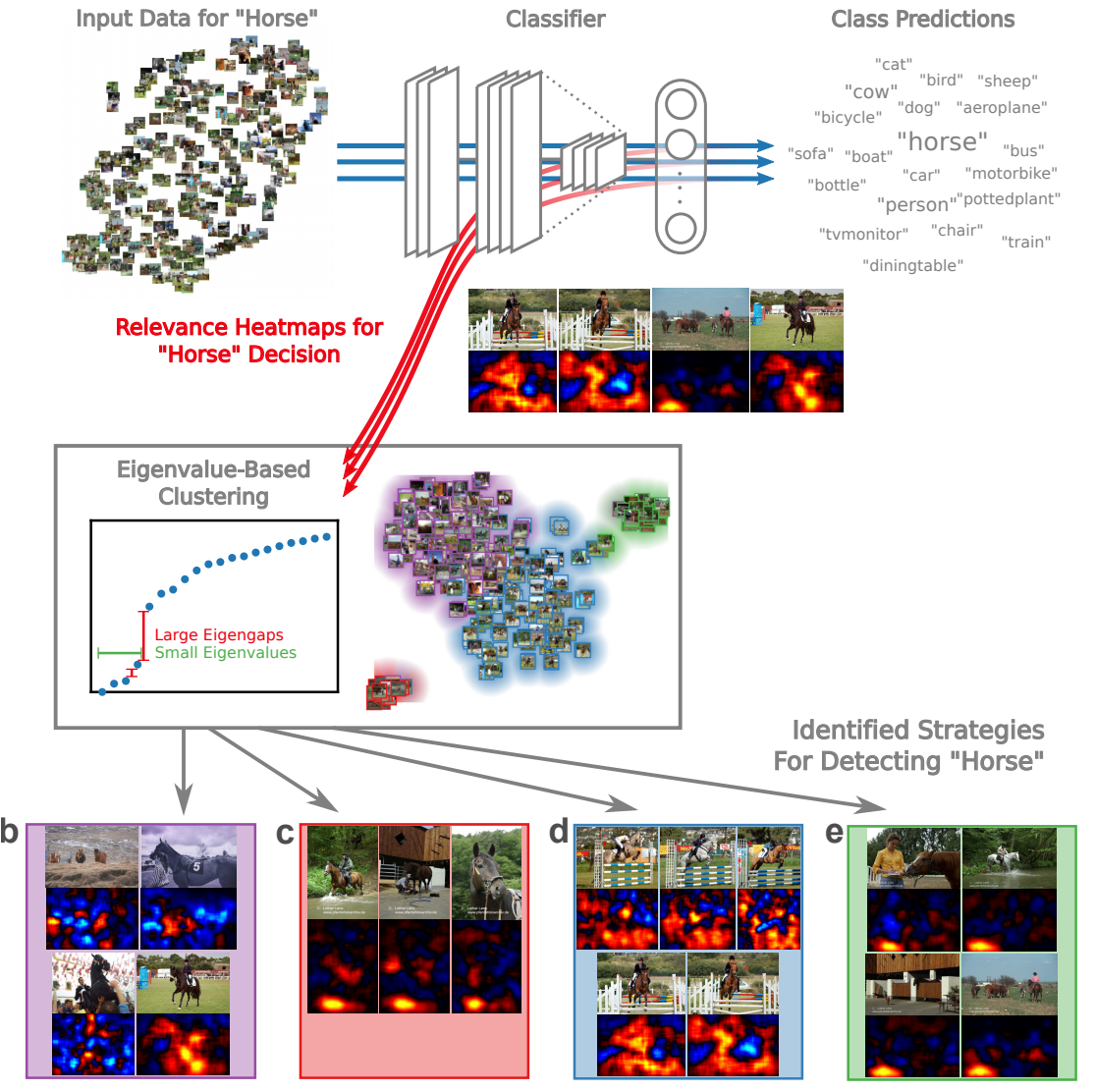
Global Attribution Mapping
-
GAM은 각각의 피처들의 conjoined rankings를 랭크 벡터 로 나타냅니다.
-
로컬 분석을 먼저 한 뒤에, pair-wise rank distance matrix/cluster을 찾는 방향으로 진행됩니다.
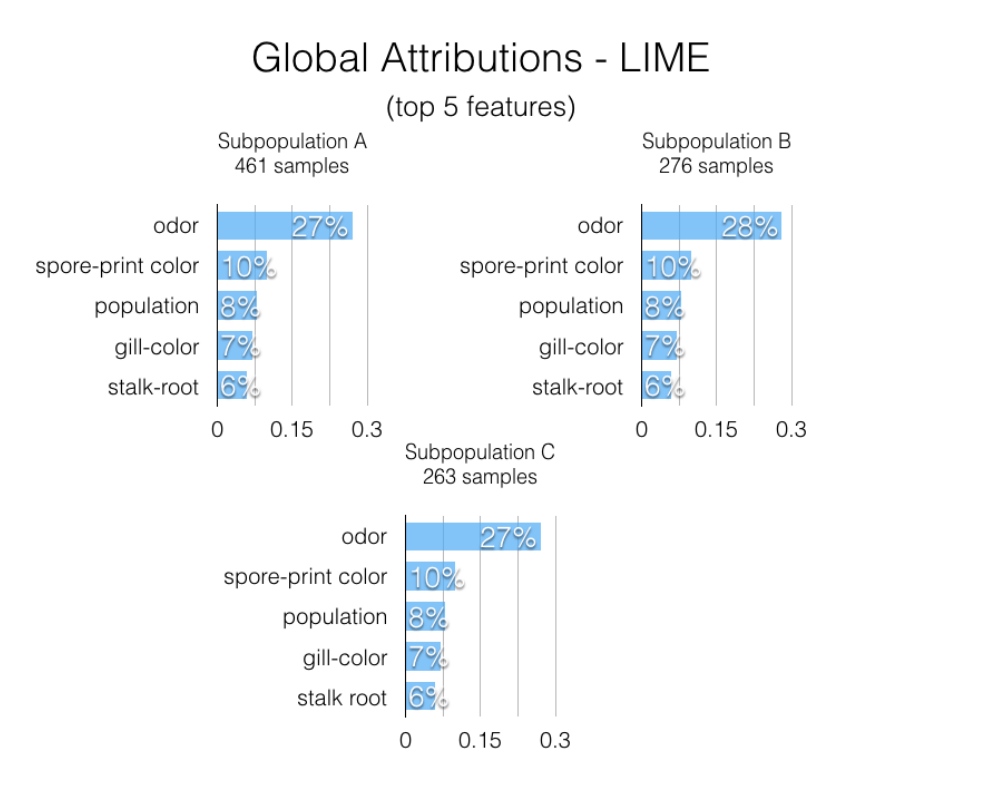
출처 : Global Explanations of Neural Networks: Mapping the Landscape of Predictions
Neural Additive Model (NAMs)
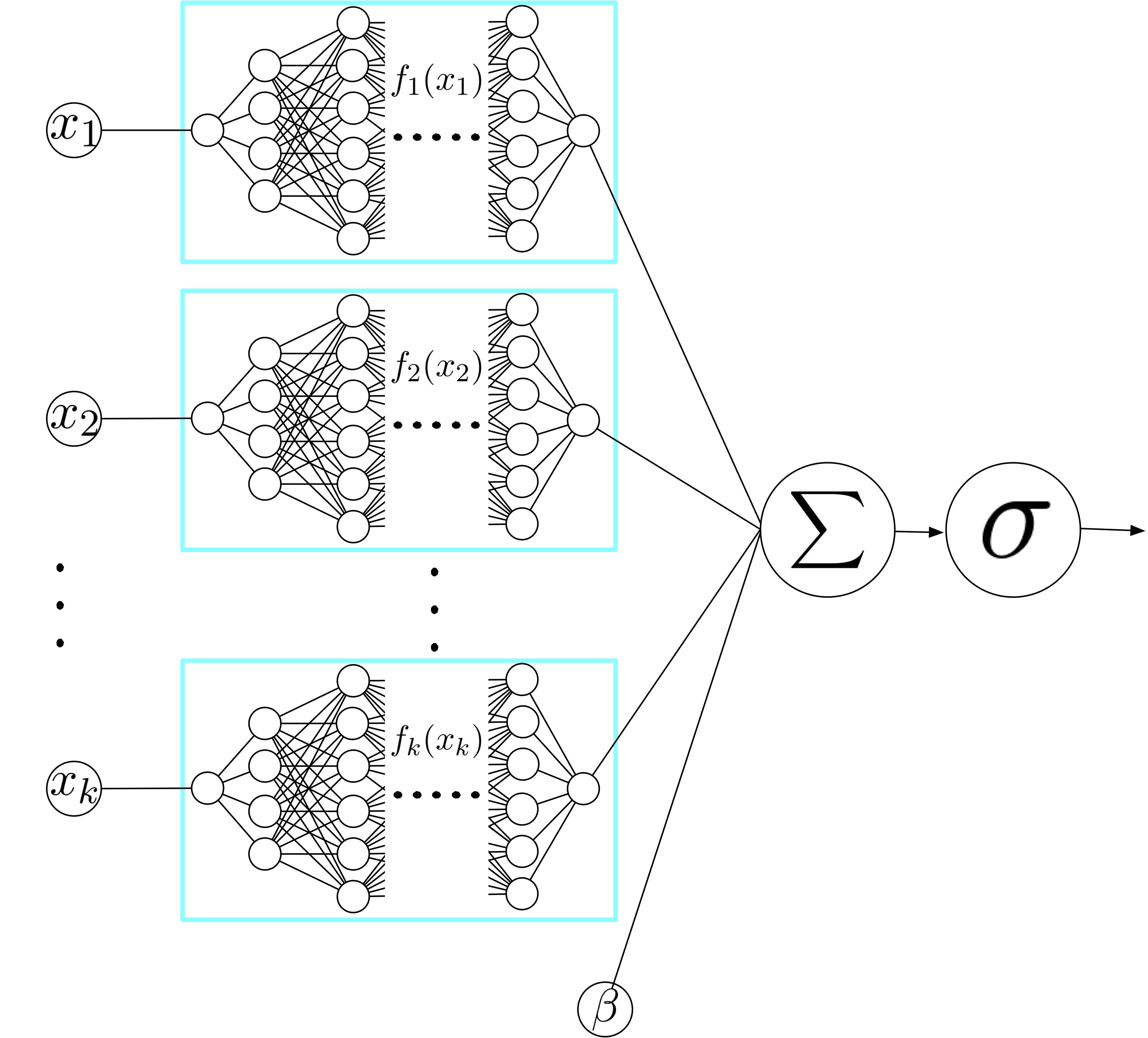
-
한 피처에 주목하는 하나의 인공 신경망을 각각 만들어서 합치는 방법으로 모델을 설명합니다.
-
generalized additive models (GAM)을 구성하여 분석합니다.
-
논문의 저자는 ReLU를 개선한 exp-centered (ExU) $ h(x) = f(e^w * (x-b))$ 을 도입했고, 가중치 초기화로 with 를 사용했다고 합니다.
-
음수 값은 클래스 예측 확률을 낮추고, 양수 값은 클래스 예측 확률을 증가시킨다고 볼 수 있습니다.
-
NAM을 사용하면 출력값과 상관 없이 각각의 피처에 대한 정확한 설명이 가능하다는 장점이 있습니다.
