Attention 구조
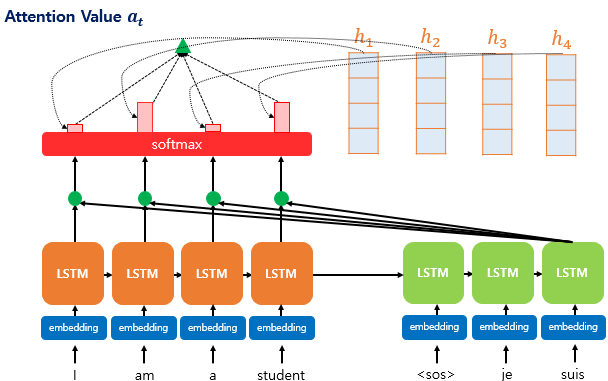
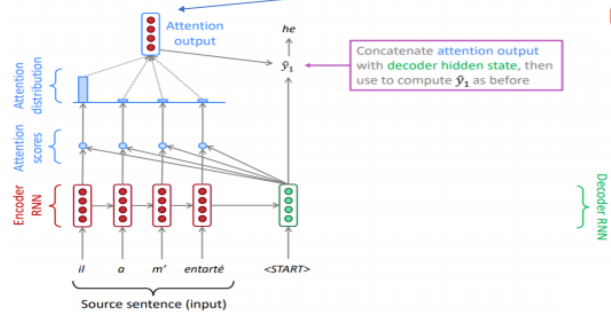
[용어 정리]
Attention Score: 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 값들이 디코더의 현 시점의 은닉 상태 s_t 와 얼마나 유사한지를 판단하는 스코어 값
Attention Weight: Attention Score에 softmax 를 적용한 값. hidden state vector와 곱해지는 비중 담당.
Attention Distribution: Attention Score에 softmax 를 적용한 값(Attention Weight)의 모임. 모든 값을 합하면 1이 되는 확률 분포
그림 출처, 참고 링크 : https://catsirup.github.io/ai/2020/03/27/attention.html
Attention is not explanation
이 논문이 다른 논문에 인용된 맥락
Jain and Wallace 2019 = Attention is not explainable
Wiegreffe and Pinter 2019 = Attention is not not explainable
NLP 관련 XAI 트렌드 서베이 논문: https://arxiv.org/pdf/2010.00711.pdf
[A Survey of the State of Explainable AI for Natural Language Processing]

[An attentive survey of Attention Models]

[Explainable recommendation models]

[Is Attention Interpretable?]

[Analyzing the Structure of Attention in a Transformer Language Model]

"이 논문에 대한 반박도 이어지지만, 충분히 고려해야 하고, Attention의 설명력에 대한 의구심을 던진 중요한 관점의 논문" 정도의 포지션인 것 같습니다.
인용 논문 목록을 보면 XAI 논문이 아닌 Attention 관련 논문에서도 등장하고 있음을 보아 NLP XAI 분야 뿐 아니라 Attention 분야에서도 중요한 관점인 것으로 보입니다.
논문 내용
이 논문에서는 attention weight와 model output(prediction) 간의 관계가 "explainable"하지 않다고 주장합니다. 즉, 높은 값의 attention weight를 가지는 input unit이 output에 대해 설명력을 가진다는 전제가 잘못되었다는 것입니다. 논문에서는 이것을 증명하기 위해 attention weight, input, output간의 관계를 살펴보는 실험을 진행하였습니다.
논문에서 주장하는 'Attention이 explainable 하기 위해서 만족해야 하는 두 가지 가정'은 다음과 같습니다.
- Attention weight는 feature importance를 측정하는 다양한 방법들과 상관관계가 있다.
- Alternative(adversarial) attention weight는 예측 결과의 변화를 야기할 것이다.
이 논문에서는 이 두 가지 가정이 Attention을 주로 활용하는 많은 NLP 태스크에서 거의 관찰되지 않았다고 말합니다. 논문에서는 Binary text classification, Question Answering, Natural Language Inference task에 대해 실험하였습니다.
하나의 예시를 들어 설명합니다.

텍스트 감정 분류 예시입니다. 양쪽 모두 분류 결과는 'negative'입니다. 왼쪽은 original attention distribution, 오른쪽은 advarsarial(alternative) attention distribution에 해당합니다. 왼쪽에서는 'waste' 토큰이 결과와 연관성이 높고, 오른쪽에서는 'was' 토큰이 결과와 연관성이 높습니다. 집중하고 있는 토큰이 전혀 다르지만, 같은 결과를 예측하고 있습니다. 따라서, 이러한 방식은 'explanation'에 적합하지 않다고 주장합니다.
실험
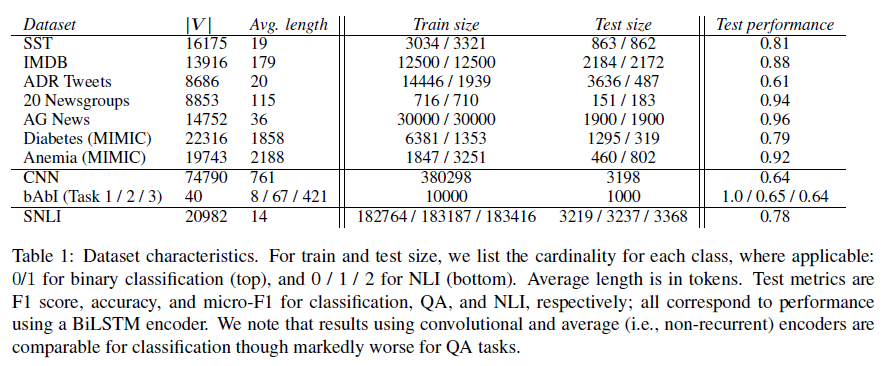
논문에서 사용한 데이터셋은 다음과 같습니다.
output distributions 간의 차이를 측정하기 위해서는 Total Variation Distance (TVD) 를 사용하였고, attention distributions 간의 차이를 측정하기 위해서는 Jensen-Shannon Divergence (JSD) 를 사용하였습니다.
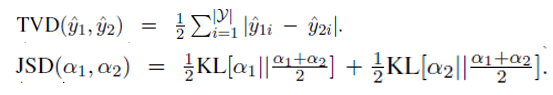
- Attention과 Feature importance 방법 간의 상관관계 실험
Attention과 1)Gradient based feature importance 방법(τ_g), 2)feature들을 하나씩 제거할 때, model output의 변화(τ_loo) 간의 상관관계를 실험하였습니다.
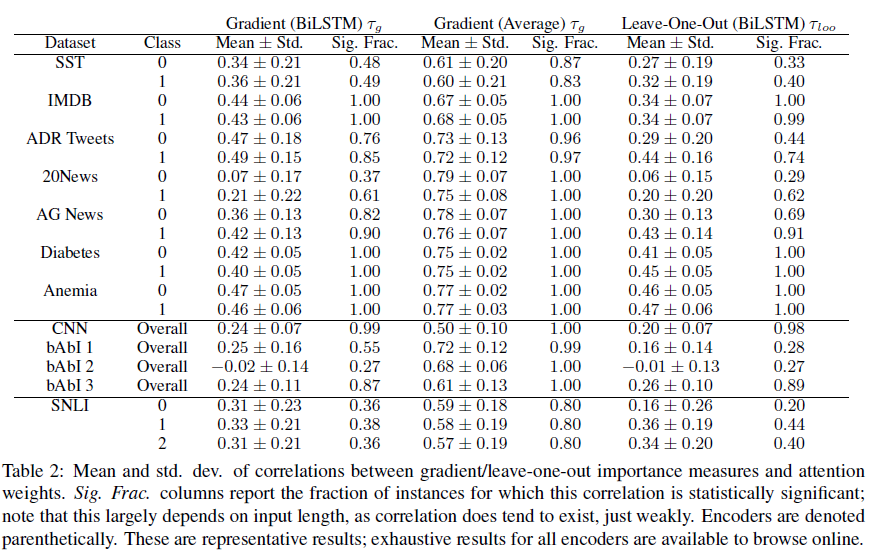
(τ_g의 histogram인데 τ_loo와 상당히 유사해서 논문에는 이 것만 실었다고 합니다.)
주황색: positive로 예측된 경우들
보라색: negative로 예측된 경우들
SNLI 데이터의 경우에는 보라색:contradiction, 주황색: entailment, 초록색: netural (예측 라벨)
히스토그램을 보면 BiLSTM 인코더 모델의 경우에 대체로 0 주위에 몰려있는 분포임을 알 수 있습니다. 즉, 상관관계가 거의 다 0과 가까워 약한 수준이라는 것입니다.
반면, Average(non-recurrent/convolutional 모델) 인코더 모델의 경우에는 상관관계가 높습니다. 이 실험 결과를 통해 알 수 있는 점은 Attention weights는 contextualized embedding이 있는 모델에서 Feature importance와 일치도가 낮다는 점입니다.
- Adversarial(=counterfactual) Attention Distribution 생성
논문에서는 두 가지 방법으로 adversarial distribution을 생성합니다.
1) 원래의 attention weight를 단순히 섞어 재배치합니다.
2) 원래의 distribution과 가장 다르지만 같은 결과를 도출하는 adversarial distribution을 직접 생성합니다.
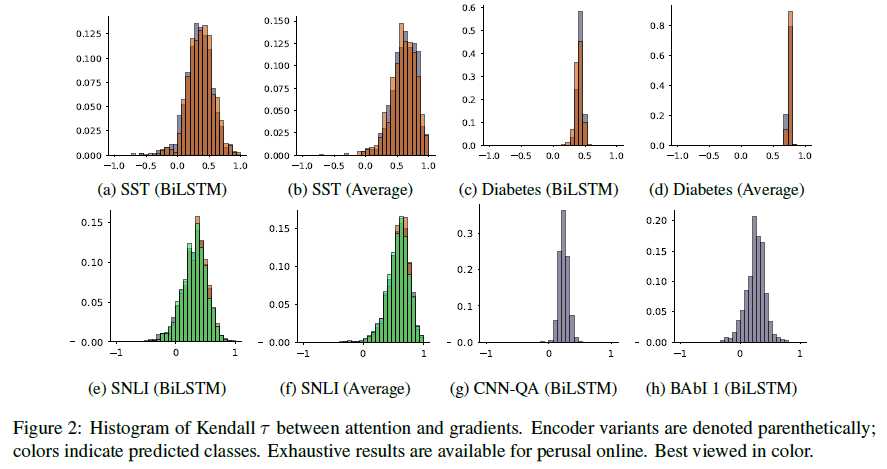
1) 원래의 attention weight를 단순히 섞어 재배치
Figure 3 에서는 원래의 attention value의 max 값과 적대적 조절에 의한 변화량의 중앙값을 시각화합니다. attention weight 값이 큼에도 불구하고 변화량이 작은 경우는 attention weight가 작은 사이즈의 feature들로 output을 설명 가능할지도 모르지만, weight 부분을 무작위로 재배치했을 때 결국 결과의 변화가 적은 경우입니다.
(c)의 diabetes 데이터셋의 경우에는 positive 클래스(주황색)은 weight가 설명의 역할을 할 수 있음을 알 수 있습니다. 이 경우 조금만 attention weight를 바꿔도 결과에 큰 차이가 있습니다. 하지만, 이 경우는 positive 클래스에 대해 높은 precision을 가지는 몇몇 토큰이 없어질 경우 결과에 큰 영향을 미치기 때문이고, 이것은 어떤 규칙이라기보다는 데이터셋의 특성에 따른 예외에 가깝다고 주장합니다. (electronic health records를 다루어 diabetes 여부를 판별하는 데이터셋입니다)
2) 원래의 distribution과 가장 다르지만 같은 결과를 도출하는 adversarial distribution을 직접 생성
이전에 다루었던 논문에서 나온 판다의 사진에 노이즈를 더한 결과 모델이 사진을 긴팔원숭이로 분류하게 되는 경우와 유사하다고 이해하시면 수월할 것 같습니다.
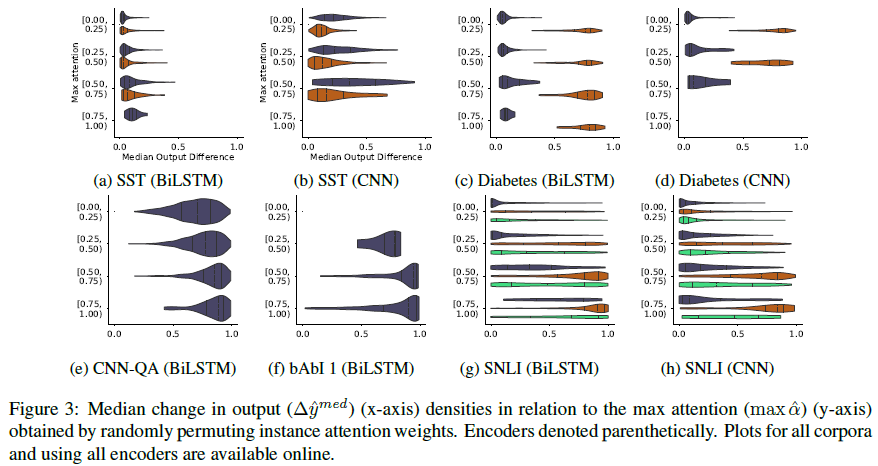
이 히스토그램은 모델별 JSD(distribution간의 차이를 나타내는 단위) 최댓값의 분포를 나타냅니다. JSD값이 큰 경우가 많은 것으로 보아, 모델의 output을 바꾸지 않지만 원래의 distribution과는 차이가 큰 경우를 자주 볼 수 있음을 알 수 있습니다.
1)에서와 유사하게, 여기서도 diabetes 데이터의 경우에 positive 클래스에 대한 JSD가 낮고 negative의 경우 높은 경향을 볼 수 있습니다.
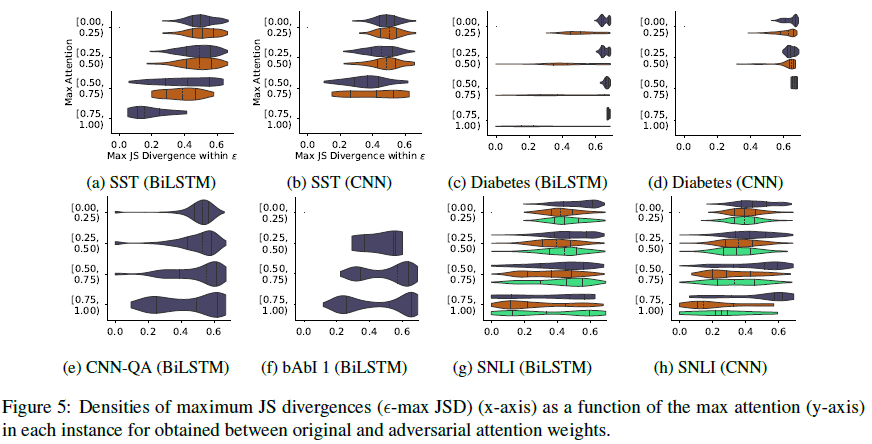
plot을 통해 attention weight값이 높은 경우에도 divergence가 높은 경우가 많음을 알 수 있습니다.
Attention is not not explanation
논문 저자의 presentation 영상이 공개되어 있으니 참고하셔도 도움될 것 같습니다. https://www.youtube.com/watch?v=KokBC8zBEWE
앞선 논문의 많은 '가정'들에 의문을 제기하는 논문입니다. 'explanation'의 정의에 따라 충분히 달라질 수 있다고 주장하며 4개의 실험을 진행합니다.
논문 내용
진행한 4가지의 실험은 다음과 같습니다.
- simple frozen uniform weights baseline (3.2)
- a variance calibration based on multiple random seeds (3.3)
- diagnostic framework using frozen weights from pretrained models (3.4)
- end-to-end adversarial attention training protocol (4)
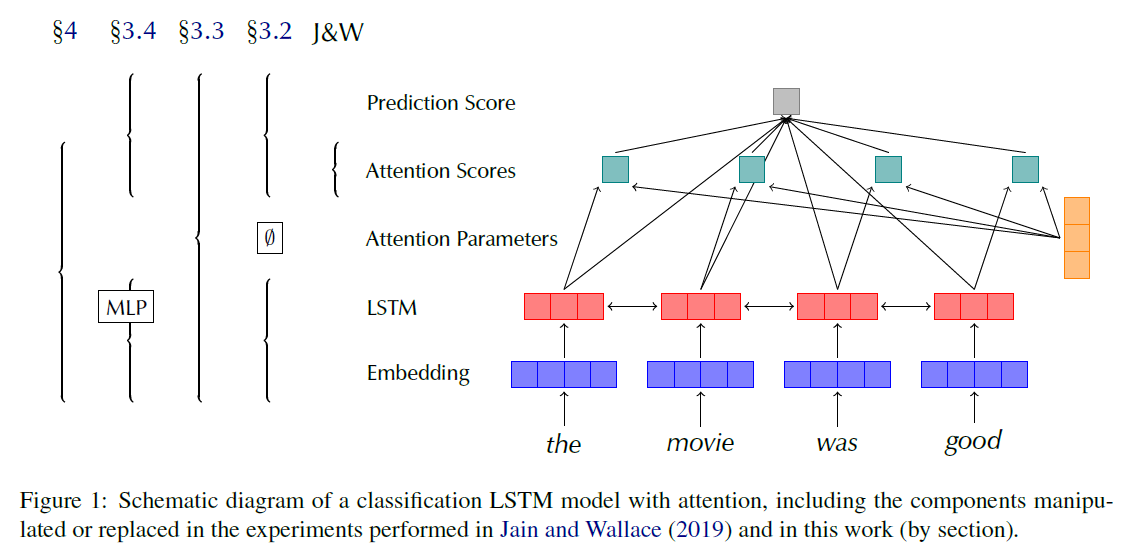
1. simple frozen uniform weights baseline
Attention weights들이 uniform distribution으로 고정되어있는 실험입니다.
실험 결과, 적어도 어떤 데이터셋에서는 uniform weight 모델도 trained 모델처럼 좋은 성능이 나왔습니다. 따라서, Jain and Wallace 논문의 '랜덤하게 weight를 바꾸어 변화량을 관찰하는 시도'가 설명력이 없다고 판단하는 근거가 될수 없다고 반박합니다.
2. a variance calibration based on multiple random seeds
여러 개의 학습 시퀀스를 각각 다른 random seed로 초기화하여 attention weight의 expected variance를 측정하는 실험입니다. 이렇게 variation을 고려하면서 적대적 모델과 원래 모델을 비교하면 적대적 모델의 결과를 더 잘 해석할 수 있다고 합니다.
adversarial distribution의 결과가 해석 불가능하다고 가정했던 이전의 논문을 반박하는 포인트로 보입니다.
3. diagnostic framework using frozen weights from pretrained models
위의 그림에서 보이는것과 같이 LSTM과 임베딩 부분을 MLP로 대체하여 맥락을 반영하지 못하도록 한 pre-trained 모델입니다. 이를 통해 Attention이 model에 구애받지 않고 (model-agnostic) 토큰에 대해 의미있는 해석을 보여줄 수 있습니다. 모델의 pre trained score 가 잘 작동한다면, 설명력이 있다고 판단합니다.
실험 결과, LSTM pre trained 모델이 (3.2)에서의 baseline 보다 더 좋은 성능을 보였습니다. 이를 통해 데이터셋의 word level 구조보다 attention 모듈이 더 중요함을 알 수 있습니다. 따라서, attention weights가 중요하지 않고 임의적이라는 Jain and Wallace의 주장은 틀리다고 주장합니다.
4. end-to-end adversarial attention training protocol
원래의 학습된 base model의 attention score를 반영하도록 loss함수를 수정하여 adversarial distribution의 파라미터를 학습하는 방법입니다. Jain and Wallace 논문에서 adversarial distribution을 생성하는 방법에 대한 대안입니다. 이 방법으로 생성한 adversarial 모델은 원래 모델보다 분류 정확도가 낮습니다.(adversarial distribution이 모델 분류 결과를 바꾸지 못한다는 Jain and Wallace의 주장 반박)
"Explanation"의 정의의 문제이다.
Explanation이라는 정의는 적어도 transparency, explainability, interpretability 라는 3개의 개념을 포함합니다. Attention 매커니즘의 weight는 hidden state의 비중을 쉽게 이해할 수 있는 방향으로 보여주기 때문에 모델에 대한 통찰을 제공한다고 주장합니다(provide a look).
또한, Explanation에 대해 더 넓게 보는 시각도 있다. 이러한 시각에 따르면, Jain and Wallace가 보여준 Attention의 'not explainable' 한 점도 넓은 정의에 의하면 explainable 할 수 있다고 주장합니다.
결론
- 이전의 Attention의 설명력에 관한 연구들이 Jain and Wallace에 의해 틀린 말이 되어버린 것이 아니다.
- Jain and Wallace의 주장처럼 특히 분류 문제에서 adversarial distribution이 존재하므로, 무조건적으로 attention weight로 설명하는 접근은 위험하다.
- 그러나 우리의 말에 따라 Jain and Wallece의 논문은 반박의 여지가 있다.
- "Attention MIGHT BE Explanation"
