0. 요약
visualized and understand GANs at the unit-, objet-, and scene-level
1. Introduction
Generative Adversarial Networks (GAN)을 활용하여 성공적으로 다양한 Task들을 수행하고 있지만, 정작 GAN이 어떤 지식들을 학습할 필요가 있는지와 잘못된 결과들의 원인을 탐색하는데는 여전히 의문이다. 이는 직접적으로, 다양한 GAN의 학습 효과를 증진시키는 것과 관련있다. 따라서, GAN이 어떻게 구조들을 represent하게 되는지 이해할 필요가 있다.

-
Object concepts과 관련있는, 해석가능한 unit의 그룹들을 식별한다. unit들의 featuremap들이 semantic segmentation과 match되게 된다.
Semantic segmentation?
: featuremap과 semantic segmentation과 어떠한 관계가 나타나는지 확인해보자. -
Network 내에서, object들을 나타나게 하고 사라지게 할 수 있는 set of units들을 식별한다. 이들을 효과를 정량화한다.
Causal Effect?
: 그림 (c)에서와 같이 unit을 ablating하면 tree가 제거되고, unit을 activating하면 tree가 생성되는지 인과관계를 밝혀보자. -
Causal object들과 background간의 관계를 점검한다. 새로운 이미지에 물체를 대입했을 때 다른 object들과 어떻게 상호작용하는지 파악한다.
GAN의 경우, building에 door를 생성하지, tree에 door를 생성하지 않는다.
2. Method
"Our goal is to analyze how objects such as trees are encoded by the internal representations of a GAN generator G: "
GAN의 generator는 의 확률분포를 학습하는 과정을 통해서 (latent vector or random vector)을 통해 에 근사시킨다. (논문의 경우, low dimension인 latent vector를 통해 image을 생성한다.)
따라서 GAN의 수식은 다음과 같이 간단히 나타낼 수 있다.
여기서 은 를 생성하기 위한 정보들을 모두 가지고 있기 때문에, image에서의 임의의 의 존재를 추론해 볼 수 있다. 단순히 그 정보의 존재 유무만을 파악하고자 함이 아니라, 어떻게 encoded되었는지 파악하는 것이 핵심이다.
직관적으로, featuremap들 중 가 P에 위치한다고 했을 때, 도움이 되는 featuremap의 집합들이 있을 것이고, 그다지 도움이 되지 않은 featuremap의 집합들이 있음을 알 수 있다.
주요개념
Dissection: identify the classes that have an explicit representation in by measuring the agreement between individual units of and every .
Intervention: for the represented classes identified through dissection, we identify causal sets of units and measure causal effects between units and object classes by forcing sets of units on and off.
2.1 CHARACTERIZING UNITS BY DISSECTION
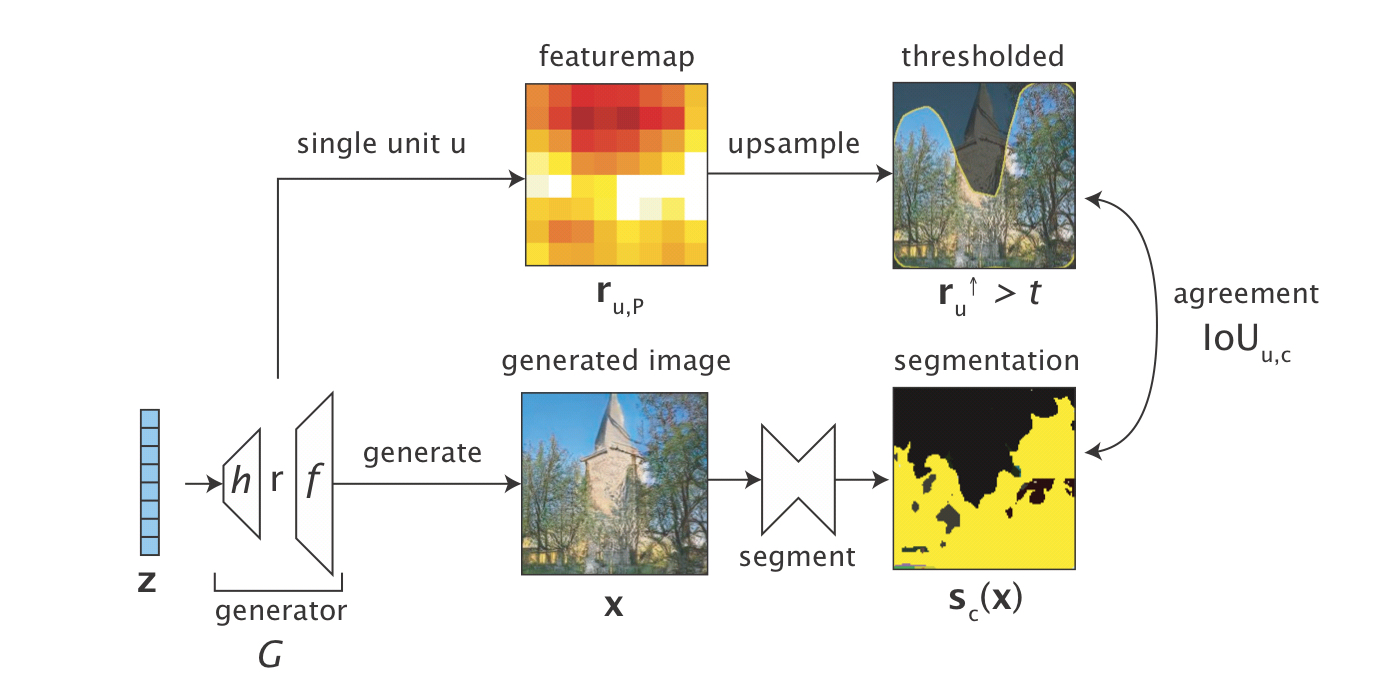
앞서, 은 의 정보들을 담고 있다고 말하였다. 따라서, convolution generator를 사용하여 생성된 중 single unit (featuremap의 one channel)를 추출하여 사용해보자.
당연히, 은 기존의 이미지의 크기보다 작기 때문에, 이를 upsample한 후의 결과와 실제 segmentation 모델을 통해 학습한 결과와 픽셀 단위에서 얼마나 일치하는지 확인한다. (두 결과값 모두 binary masked 형태로 나타난다)
IoU (Intersection over Union)
두 영역의 교차영역의 넓이를 합영역의 값으로 나눈 값을 뜻합니다. 객체 검출에서 예측된 경계 상자의 정확도를 평가하는 지표 중 하나로 사용되며, 예측된 경계 상자와 실제 참값(ground truth) 경계 상자의 IOU를 해당 경계 상자의 ‘정확도’로 간주합니다.
하지만, 우리의 목표는 output과 강하게 연관관계를 나타내는 unit을 찾는 것이 아니라, object를 발생시키는 representation의 일부분을 찾는 것이 목표이며, 이들의 조합을 찾는 것이 베스트이다.
2.2 MEASURING CAUSAL RELATIONSHIPS USING INTERVENTION
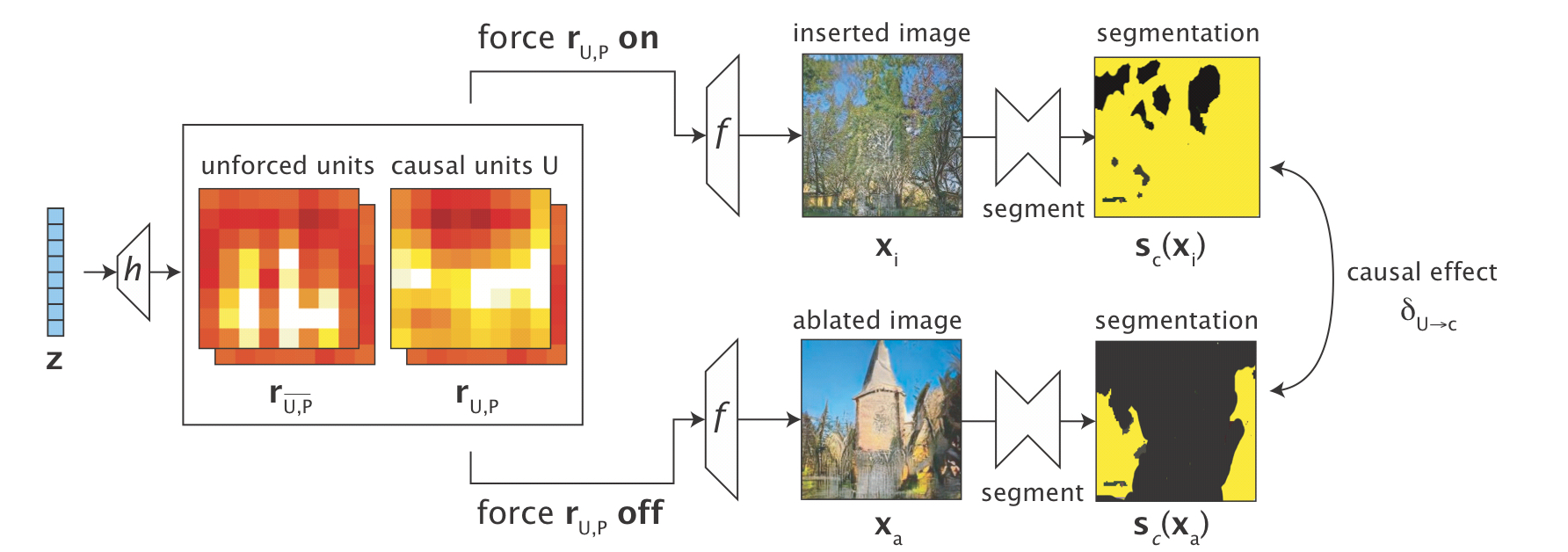
"We test whether a set of units U in r cause the generation of c by forcing the units of U on and off"
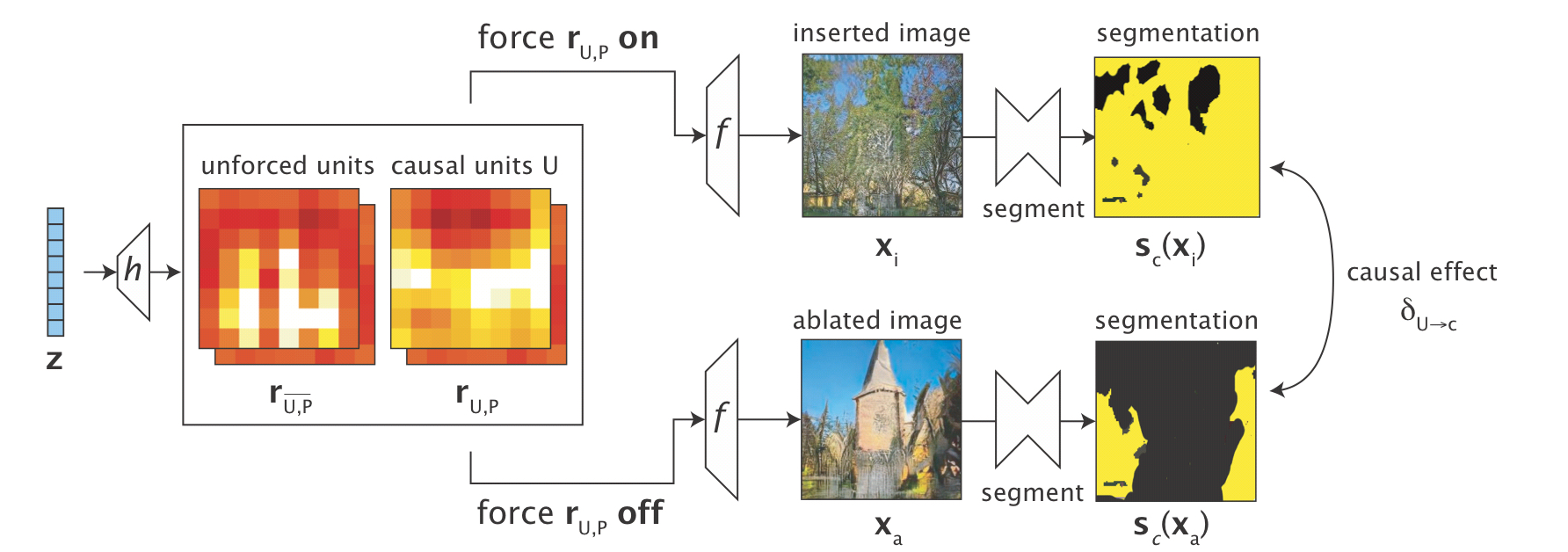
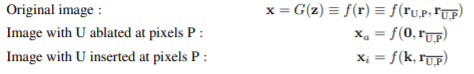
앞에서 언급했듯이, 임의의 을 예측하는데 도움이 되는 featuremap과 도움이 되지 않은 featuremap이 있음을 언급하였다. 따라서 은 다음과 같이 둘로 나눠 표기할 수 있다. 해당 논문에서는 forced component와 unforced component로 나눠 설명하고 있다. 이를 직관적으로 이해한다면 원본 Image에서 도움이 되는 featuremap의 픽셀들을 0으로 치환함으로써, Image에서 해당 를 지울 수 있으며, k (a per-class constant)로 치환함으로써 Image에 해당 를 주입할 수 있다.
예를 들어, 가 tree를 나타낸다고 가정해보자. 그렇다면, 해당 featuremap을 0으로 치환한다는 것은 그 특징들을 없앤다는 의미가 같을 것이다. 반대로 그 특징을 추가한다면 Image에는 그 특징이 더욱 강하게 나타날 것이다.
위의 그림에서 볼 때, inserted image부분에서는 tree가 추가된 양상이 나타나고 있으며, ablated image에서는 tree가 지워진 양상이 나타나고 있다.
per-class constant
For interventions for class c, we set k to be mean featuremap activation conditioned on the presence of class c at that location in the output
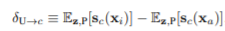
수식은 다음과같고, 를 생성한 와 를 제거한 의 차이를 최대화하는 a set of units U를 찾는 것이다.

해당 논문에서는 d개의 units으로 고정시켜서 조합을 구하는 방법을 사용하지 않고, 를 정의하여 objective function을 변형하였다. 이후에 에 대해 L2 Loss를 취해줌으로써 minimal set of casual units을 얻었다.
Result
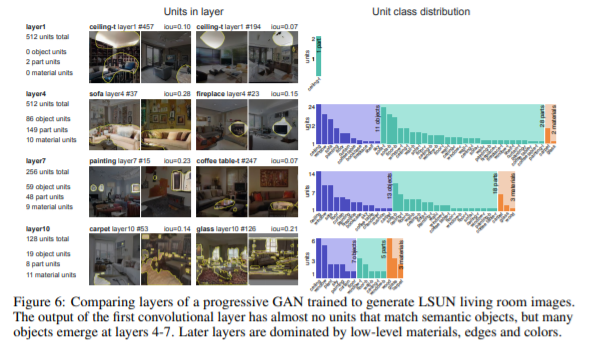
Classifier network에서 나타나는 특징과 같이 GAN에서 역시 비슷한 현상을 찾아볼 수 있었다. 초기 layer에서는 어떠한 object에 대응되지 못했지만, 중반에는 4-7개의 object들과 매칭되는 unit들을 볼 수 있었다.
DIAGNOSING AND IMPROVING GANS

GAN으로 이미지를 생성한 결과 artifact의 영향을 미치는 unit들이 있음을 확인할 수 있었으며, 해당 unit들을 제거한 결과 결과의 visual quality를 향상시킬 수 있었다.
Discussion
결과적으로, GAN에서의 representation들을 해석할 수 있었으며, object들과 관련된 signal들을 확인할 수 있었을 뿐만 아니라, object들의 나타내는 variable들의 effect도 확인할 수 있었다. 이를 통해서 GAN을 결과들을 비교할 수 있었으며, debug할 수 있었다.
discriminator는 단지 real or fake를 구분하는 역할을 하기 때문에 해당 논문에서는 GAN의 generator 부분에 대해서 파악하였다.
