0. Speech Synthesis
음성 합성의 경우 주어진 Text를 Speech로 변환해 주는 System, Task
HMM (Hidden Markov Model)
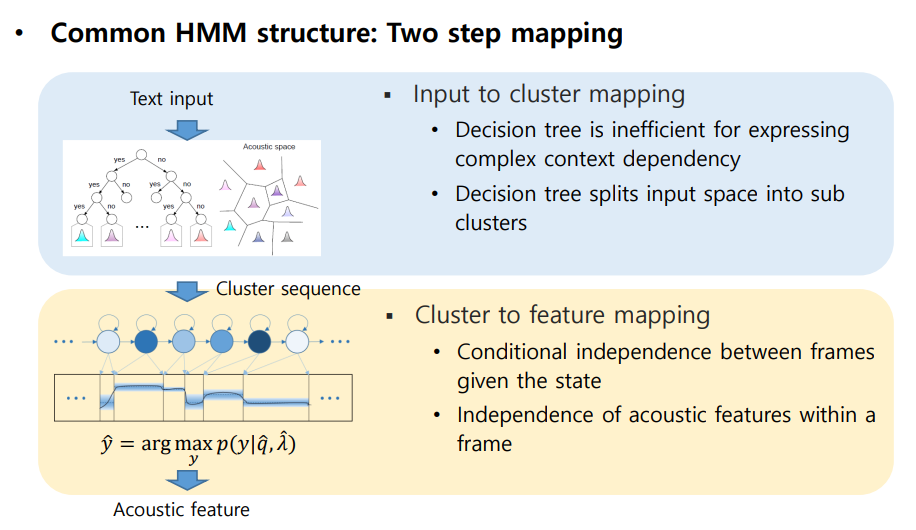
HMM 방법은 통계적 SPSS(Statistical parametric speech synthesis) 음성 학습 방법으로 Two step Mapping으로 이루어져 있다.
-
Text input을 Decision tree를 이용하여 cluster mapping을 한다.
- Decision tree를 사용하면 input space가 sub cluster로 나뉘어 지기 때문에 성능저하, 분기로 인해 복잡한 context 정보를 표현하는데 문제가 있음
-
Cluster sequence를 이용하여 Feature mapping을 진행함
- HMM의 가정 : First-order Markov Assumption, Output Independence Assumption으로 인해 성능 저하
위의 문제를 해결하기 위해 Deep learning 사용(Cluster to feature mapping - DNN or Acoustic Model - DNN)
시간에 따라 변화하는 음성을 모델링 하기에는 DNN이 부족하여 RNN 사용 (Long-term dependency 문제가 있기 때문에 gate를 적용한 LSTM 사용, previous and future contexts도 고려해야 하기 때문에 Bidirectional LSTM)
Tacotron
SPSS 방법 같은 경우 다양한 모델로 이루어져 있음 이를 End-to-End Speech synthesis 제안
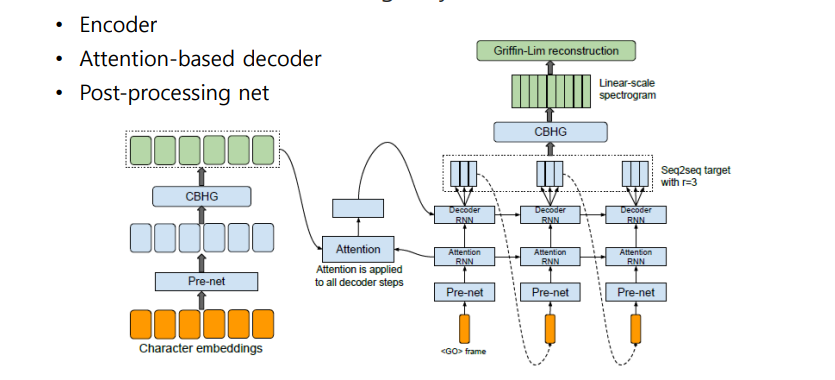
Input(Characters)이 들어오면 Encoder + Decoder 구조를 통해 Mel-spectrogram이 Output으로 나옴
- CBHG : Convolution Bank + highway network + GRU
- Encoder : Pre-net을 이용하여 모델의 convergence와 generalization을 위해 Bottleneck layer (two FC Layers + Dropout)
- Decoder : Align된 Attention을 사용하여 Mel-spectrogram을 생성 (여러 frame에 대한 spectrogram을 생성 후 마지막 frame만 다음 spectrogram을 예측하는데 input으로 줌 )
- Post Processing : Mel-spectrogram을 Linear-scale spectrogram을 생성하기 위한 과정, Griffin-lim vocoder를 통해 음성 생성
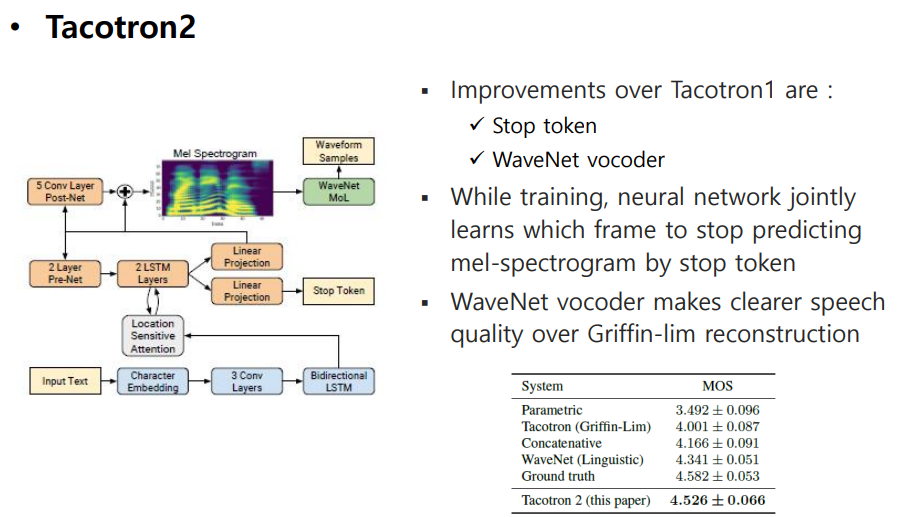
Tacotron2
-
Stop Token : Tacotron은 max length를 지정해 두고 auto-regressive하게 학습이 됨(뒷 부분을 자르고 학습함)
-
WaveNet Vocoder : Griffin-Lim vocoder보다 좋은 성능
Transformer TTS
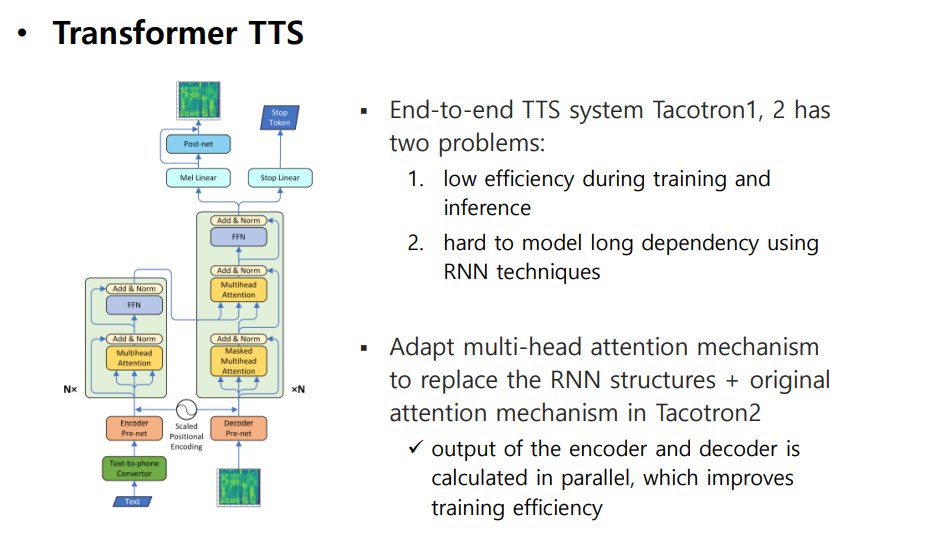
Tacotron의 경우 RNN을 많이 사용하여 오래걸림
-
RNN을 Transformer의 Multi-head Attention (Self-attention) 으로 바꿔 Encoder , Decoder를 Parallel하게 학습할 수 있다.
-
학습은 빨라졌지만, Inference 할 때 여전히 auto-regressive 함, 학습시 Teacher forcing 하기 때문에 exploration bias가 생긴다.
1. 개인화 (Multi-Speaker, Style Modeling)
사람들은 Emotion, Speech rate, Prosody 등 다양한 스타일을 통해 대화를 한다. TTS의 경우 어떻게 스타일을 모델링하고, disentangle(분리) 하는지에 대한 다양한 연구가 진행되고 있다.

Personal TTS를 위해 Multi-speaker TTS 같은 모델이 필요하지만, Multi Data (DB)에 존재하는 경우 Personal TTS 성능이 좋지만 DB와 동떨어진 경우 성능이 좋지 않다.
1.1 D-vector based Multi-speaker
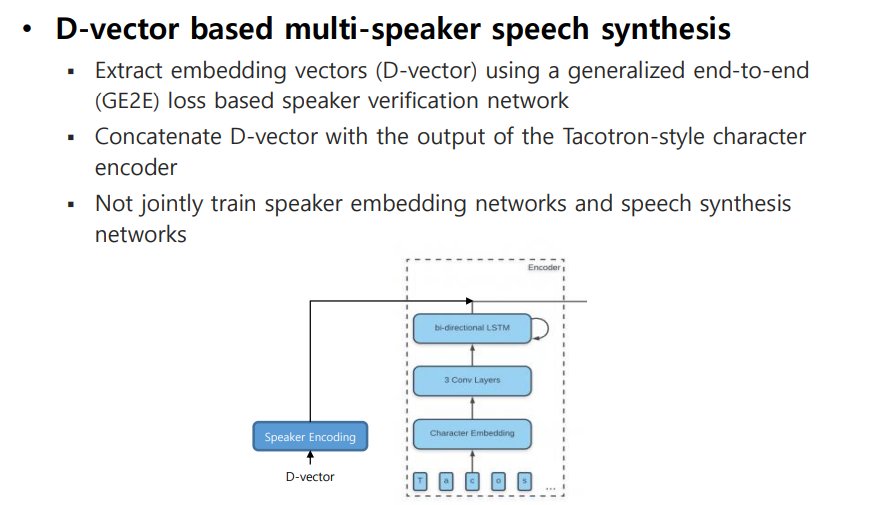
-
Tacotron2의 Encoder Output에 Speaker Embedding을 concat하여 Multi-speaker 모델을 학습하였다.
-
Speaker Embedding을 위해 D-vector를 사용하였다.
D-vector : 화자 검증(Speaker Verification)에서 많이 사용되는 방법으로, End-to-End 모델을 통해 Speaker의 utterance를 d-vector로 modeling하여 test utterance의 d-vector와 consine similarity를 구하여 accept/reject하는 task에서 사용되었다.
위 논문에서는 Speaker의 utterance에서 general한 특성과 다른 unique한 특성을 식별하는 representation으로 사용하였다. -
Speaker Encoding 부분과 Tacotron2 Encoder 부분을 따로 학습하는 방법으로 진행된다.
1.2 Global Style Token
위의 D-vector 자체가 Speech synthesis를 위한 방법이 아니기 때문에 성능 향상에 한계가 있다. 이를 해결하기 위해 reference encoder를 사용하여 reference speech로 부터 style을 추출하여 Tacotron에 적용시키는 방법이 발전 되었다.
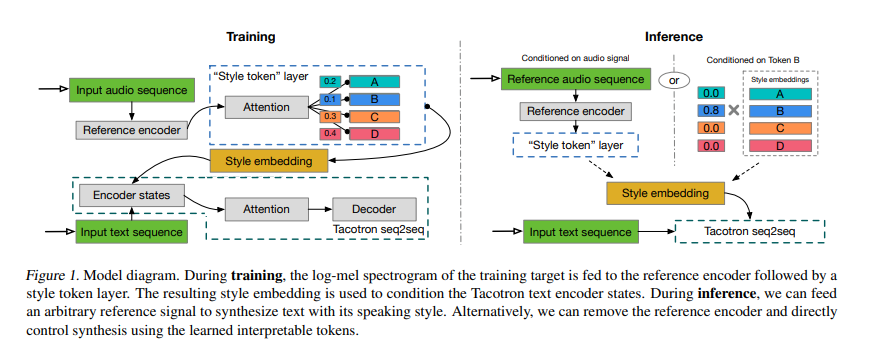
-
Speech의 style을 GST 모델이 자체적으로 label에 대해 soft interpretable는 방법이다.
-
Target으로 하고 싶은 Style의 reference speech를 Input으로 주어 reference encoder를 통해 얻어진 style embedding에 대해 self-attention을 적용하여 각 token에 대한 style을 학습하게 됨
reference encoder : 2D-convolution layer * 6 + GRU Layer
Training
-
variable length audio가 reference encoder를 통해 fixed-length vector로 embedding (reference embedding)
-
reference embedding이 Attention Module인 style token layer를 입력 된다.
- Attention : reference embedding과 각 token 사이의 유사성을 학습 (GSTs)
-
각각의 token에 대해 weighted sum으로 표현된 GSTs (Style embedding) 을 text encoder의 condition으로 줌
-
Tacotron과 jointly training을 함, 따라서 GSTs에는 style or prosody labels가 필요하지 않음
Inference
-
특정한 Token에 condition을 줄 수 있다. (하지만 원하는 style을 적용하기 위해서는 Inference에서 reference speech를 적용하여 각각의 token이 어떠한 style에 영향을 주는지 확인해야 함)
-
Different audio signal을 통해 condition을 줄 수 있다.

한계 : GST Model의 style token에 대해 학습하는 것은 Training set에 대해서 학습을 하는 것이다. 즉, DB 내에서만 학습하기 때문에 유의미하거나 독특한 token에 대해 학습을 하지 못한다 (단순하게 구성된 DB의 경우 Emotion, Prosody에 대해 다양한 style을 학습하지 못한다.)
1.3 VAE-Tacotron2
Motivate : Movitation style을 latent variable을 통해 Modeling
위의 두 방법은 Style을 fixed-dimension으로 하여 modeling을 하였지만 VAE-Tacotron2는 latent variables을 통해 확률적(stochastic)으로 modeling을 함
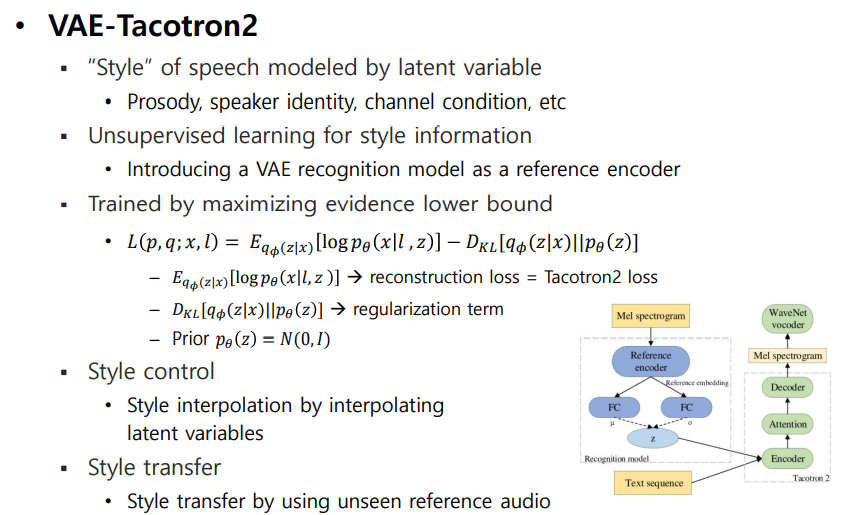
-
reference speech를 fixed-length short latent variables로 representation한 VAE + End-to-End Model Tacotron2
-
reference speech를 위의 GST에서 제안한 reference encoder로 embedding한 후 two separate FC layers에 linear activation을 통해 latent variable z의 generate하도록 구성 , z는 reparameterization trick 으로 구성
VAE의 latent variable z의 probability 로 설정한다. 즉, 컨트롤 가능한 prior을 설정함으로써 likelihood 를 알수 있으면 posterior 또한 알 수 있다. (joint probability) 여기서 likelihood 는 NN을 학습함으로써 구할 수 있다.
-
학습을 하기 위해서 VAE의 ELBO (Evidence Lower BOund)와 유사하게 log-likelihood를 사용한 reconstruction loss (= Tacotron2 loss), KLD regularization term을 사용한다.
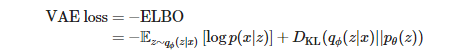
- reference audio 를 통해 style을 control,transfer 하거나 latent variable을 interpolating 하여 control을 해야 한다.
1.4 Gaussian mixture VAE (GMVAE)
VAE의 경우 데이터를 control하는 latent variable z의 probability , 단일 정규분포로 가정을 하고 학습을 진행한다. 음성에는 다양한 특징(gender, speaker, accent, speech rate, etc)들이 존재한다. 따라서 여러 Gaussian distribution을 혼합하여 데이터를 control 하는 latent variable의 probability를 구하자는 것이 Gaussian mixture model의 핵심
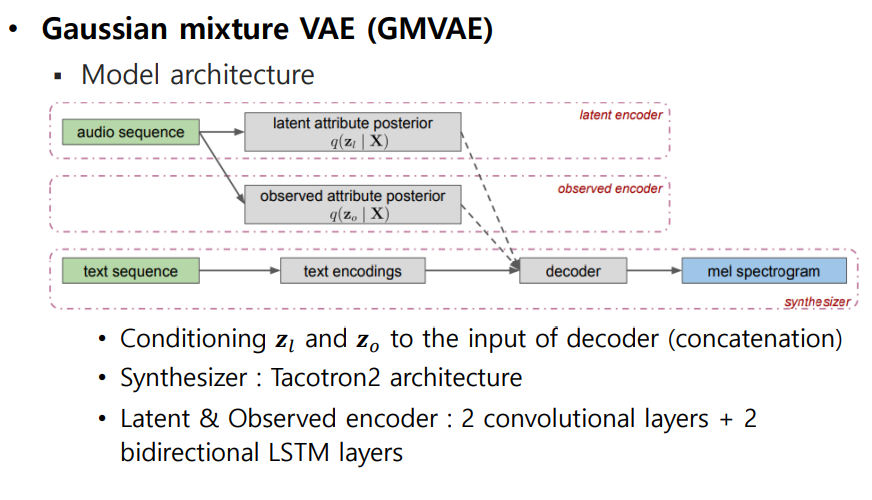
-
VAE-Tacotron2를 발전시켜 Hierarchical latent variable을 통해 Modeling함, VAE와 유사한 방식으로 ELBO를 통해 학습을 한다.
-
learned prior를 통해 systematic sampling mechanism을 확인한다. (style control)
-
latent variables을 통해 disentangled attribute representations을 학습한다.
-
training data에서 해석 가능한 cluster set을 발견 ex. one cluster for clean speech and another for noisy speech
-
2 separate latent spaces
- Labeled(observed) attributes : Categorical observed labels ()는 continuous attribute space를 categorization하는 것으로 생각할 수 있다. Observed class는 continuous space에서 mixture component()를 형성하며, diagonal-covariance Gaussian 분포로 나타낼 수 있다.
ex) speaker label, gender label - Unlabeled(latent) attributes : K-way categorical discrete variables 로 부터 D-dimensional continuous variable 을 sampling 함
ex)prosody elements(accent, speech rate, etc), noise
- Labeled(observed) attributes : Categorical observed labels ()는 continuous attribute space를 categorization하는 것으로 생각할 수 있다. Observed class는 continuous space에서 mixture component()를 형성하며, diagonal-covariance Gaussian 분포로 나타낼 수 있다.


2. 보코더 (Vocoder)
2.1 Intro
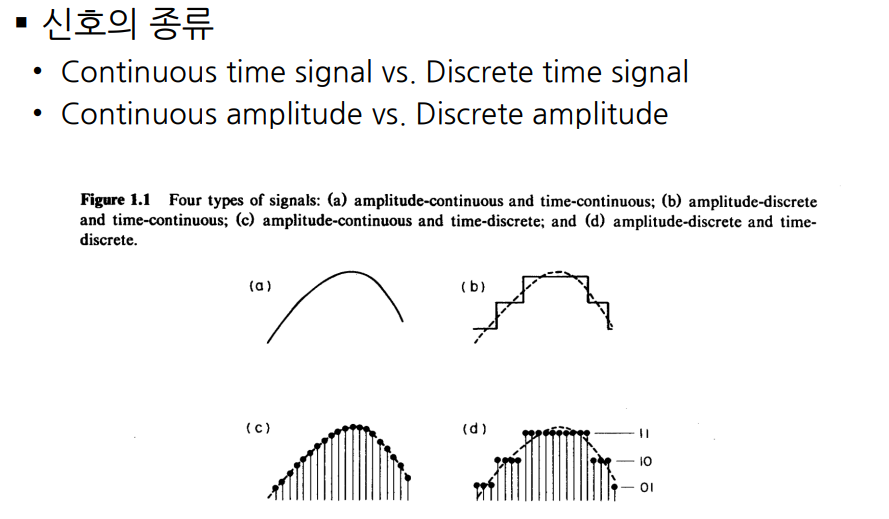
음성신호는 아날로그 신호, 시간축으로 연속적으로 진행되는 신호 이다. 컴퓨터로 처리하기 위해서는 연속된 신호를 Discrete 하게 만들어 입력으로 받아야한다.
신호의 종류로는 시간축에 대해서 연속되는지에 대해 Continuous time signal, Discrete time signal로 나뉘며, Amplitude에 대해 Continuous 한지 Discrete한지로 나뉘어 진다.
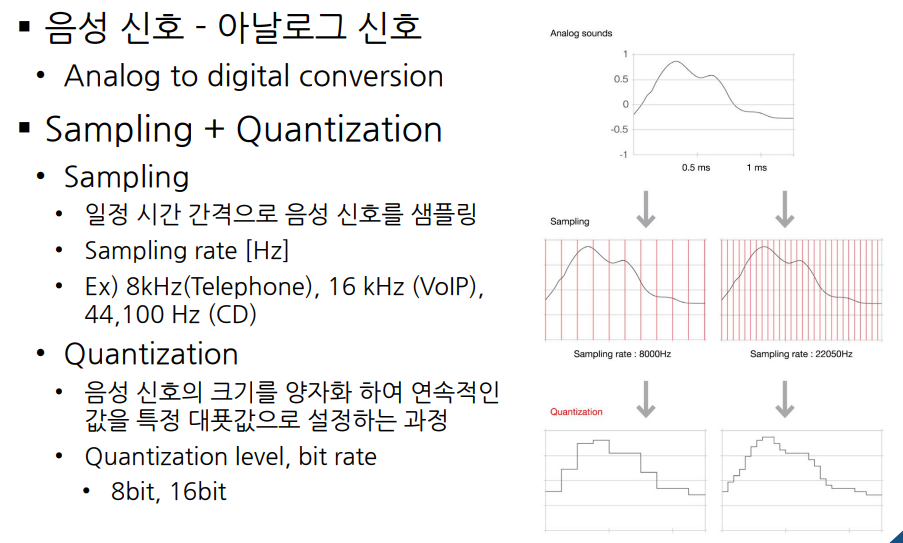
음성신호를 디지털로 바꾸기 위해서는 Sampling과 Qunatization을 사용하는데, Sampling의 경우 time 축으로, Quantization은 amplitude 축으로 진행한다. (Nyquist sampling theorem)
Frequency 영역에서 연속된 시간 신호 해석하는 방법으로 주기 함수에는 Fourier series, 비주기 함수에는 Fourier transform을 사용하여 특정 Frequency의 크기를 표현할 수 있다. ( 에 대해 )

Sampling한 신호의 경우 time과 amplitude가 discrete하기 때문에 위의 Fourier Transform을 특정 주기(N)의 영역으로 바꿔야 하기 때문에 DFT를 사용한다. 의 복잡도를 가지고 있기 때문에 FFT를 사용함
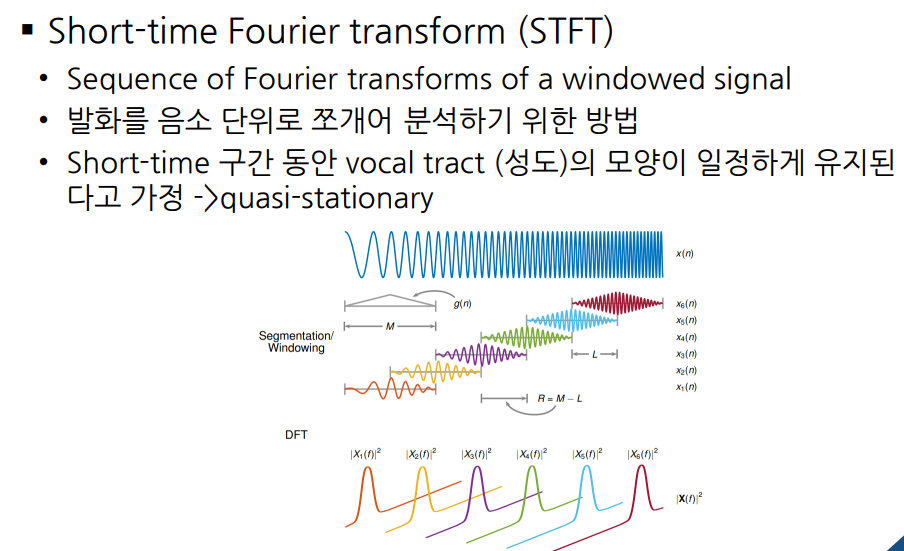
시간에 따라 변하는 주파수를 분석하기 위해, 주파수를 의미 있는 음성 신호로 사용하기 위해 나누어 구간에 대해 Fourier transform을 processing 한다. (window function : Hamming, Hanning window) 이렇게 DFT, FFT, STFT를 진행하면 Spectogram이 나오게 된다.
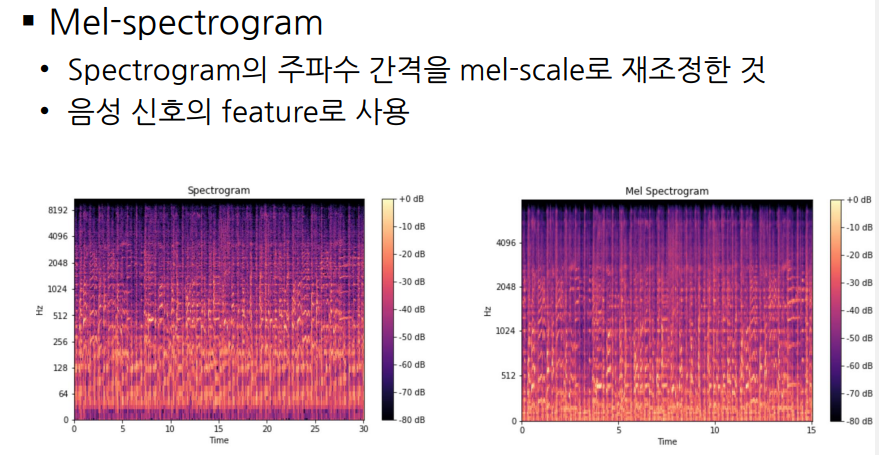
사람의 귀는 주파수에 따라 민감도가 다르기 때문에, Spectogram을 사람의 귀의 특성에 맞게 고려하자 하여 Mel-scale을 통해 재조정한 Mel-spectogram을 음성 신호의 feature로 사용한다.
2.2 Vocoder
Audio를 주파수 영역에서 분석하기 위해 STFT를 통해 의미 있는 음성 신호로 사용할 수 있다. Magnitude 값을 이용하여 Mel-scale로 변환한 Mel-spectrogram을 사용하여 음성 feature로 사용하는데, 주파수의 magnitude와 phase 정보를 알고 있으면 SFTF를 Inverse하여 원본 Audio를 복원할 수 있다. 하지만 Mel-spectrogram을 이용한 TTS 모델의 경우 phase, magnitude 정보가 아닌 magnitude만 이용하여 phase 정보를 예측하고, 이를 통해 원본 Audio도 예측해야 한다. 이러한 역할을 하는 것이 Vocoder이다.
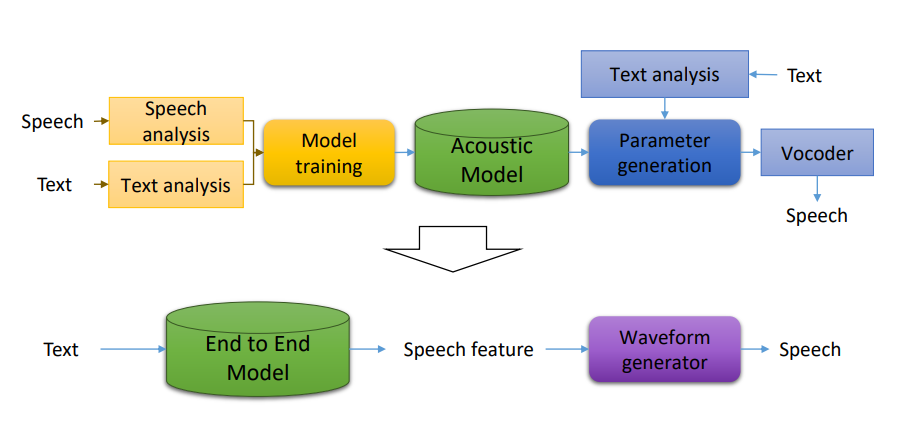
고전적인 음성합성의 경우 발음기관의 concept에 맞춰 모델링을 진행하였지만 최근 Deep learning을 사용한 End-to-End Model로 바뀌면서 Text에 해당하는 speech feature를 Waveform으로 변환하여 speech를 생성하는 방법으로 바뀌었다. 이때 Waveform generator가 mel-spectrogram을 input으로 받아 Waveform을 생성한다. (텍스트에 해당하는 음성신호는 phase 정보가 포함되어 있기 때문에 굉장히 큼 ex 5초 음성 신호는 120k 개의 sample로 이루어짐, Mel-spectrogram의 경우 phase 정보가 없기 때문에 실제 음성 신호보다는 작은 dimension을 가지기 때문에 효율적임)
하지만 phase 정보가 없는 Mel-spectrogram으로 waveform을 생성하기 때문에 완벽히 복원하기 어렵고, 다량의 학습데이터로 일반화를 하여 phase에 대한 예측을 한다.
이때 주로 사용하는 알고리즘이 Griffin-Lim, Neural Vocoder이다
Griffin-Lim
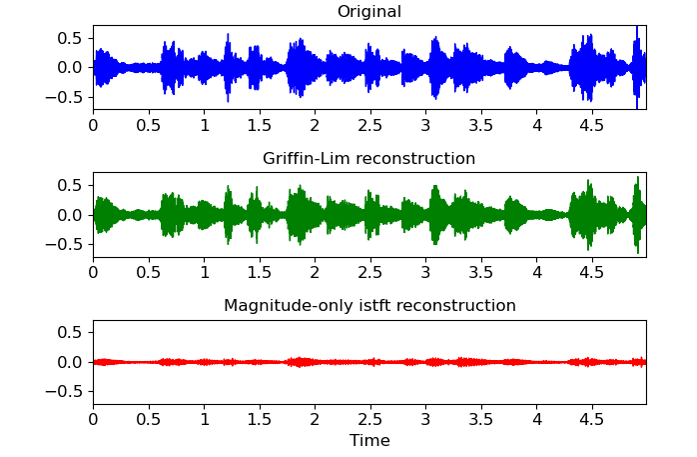
사진출처 : https://cvml.tistory.com/14
Griffin-Lim 알고리즘은 Mel-spectrogram으로 계산된 STFT의 magnitude 값을 통해 원본 음성을 예측하는 rule-based 알고리즘이다.
STFT의 redundancy에 기반하여 phase를 reconstruction하는 방법이다. STFT phase 정보를 구하기 위해 임의의 값으로 두고, 예측된 음성의 STFT magnitude값과 Mel-spectrogram으로 계산된 STFT magnitude 값의 MSE가 최소가 되도록 반복 하여 원본 음성을 찾아는 방법이다.
Neural Vocoder
Mel-spectrogram을 입력으로 받아 waveform을 생성하는 딥러닝 모델, 다량의 데이터를 학습하여 mel-spectrogram과 음성 신호 사이의 phase를 예측하여 음성을 생성하는 방법이다. 학습 시, 1~2초 정도로 나누어진 음성 신호를 학습하여 메모리 사용의 부담을 줄일 수 있다 .
- Autoregressive model : WaveNet vocoder
- Flow-based model : WaveGlow, FloWaveNet, Parallel WaveNet, ClariNET
- GAN-based model : ParallelWaveGAN, VocGAN

4개의 댓글

[15기 황보진경]
Speech Synthesis는 주어진 text를 speech로 변환시키는 task이다.
이번 강의에서는 개인화된 TTS와 vocoder를 다루었다.
[개인화 (Multi-speaker, Style Modeling)]
1. D-vector based Multi-speaker
Tacotron2의 encoder output에 speaker encoding을 나타내는 d-vector를 concatenation하는 구조이다. d-vector는 speaker verification에서 사용되는 representation이다.
2. Global Style Token
Style을 나타내는 reference speech로부터 reference encoder를 적용하여 token화 시킨다. 이를 text encoder에 text와 함께 추가하는 방법론을 사용한다.
3. VAE-Tacotron2
style latent variable에 확률적 요소를 추가한다. VAE와 유사하게 reparameterization trick을 사용한다. Latent variable을 interpolate하여 스타일을 변화시킬 수 있다.
4. Gaussian mixture VAE
VAE-Tacotron2의 개선된 형태로 latent variable에 계층적 요소를 추가하였다.
[보코더 (Vocoder)]
Mel-Spectrogram으로부터 원본 audio를 예측하는 task를 수행하는 모델이다. phase정보가 없기 때문에 iSTFT를 수행할 수 없다. 원본 오디오보다는 작은 dimension을 가지기 때문에 vocoder 파트가 존재한다.
1. Griffin-Lim
STFT의 redundancy를 이용하여 phase정보를 복원하고 예측된 STFT magnitude값과 mel-spectrogram의 magnitude값의 차이(MSE)가 최소가 되도록 하는 rule-based 알고리즘이다.
2. Neural Vocoder
딥러닝을 이용하여 보코더를 구현한다. 크게Autoregressive한 방식, flow-based 방식, GAN-based 방식으로 나뉜다.

[15기 조효원]
- HMM은 2 step으로 mapping을 진행한다. 1) Text input -> cluster mapping(seqs) 2)Feature mapping. 하지만 HMM은 가정 자체가 first order M Assumption을 사용할 뿐만 하니라 cluster mapping에서 sub cluster 만드는 과정에서 많은 정보를 잃기에 성능이 그리 좋지 않을 수 있다. 따라서 sequential data에 적합하며 feature를 모델링하기에 좋은 LSTM을 사용한다.
- LSTM cell을 사용하여 모델링한 대표적인 예가 Tacotron이다. Encoder-Decoder 구조로 이루어진 이 모델은, encoder가 input char를 받아 레이어들을 순차적으로 거치면 Decoder가 mel-spectorgram을 내보낸다. 그럼 Griffin-lim vocoder를 이용해 mel-spec-> linear scale spectrogram -> speech의 순서로 바꾸어준다.
Tacotron2에서는 stop token을 도입해 성능을 향상시키는 한편, vocoder를 wav2vec vocoder로 변경하였다. - Tacotron계열은 RNN을 사용하기에 너무 느리고 long term dependency를 고려하기 어렵다. 따라서 Transformer를 사용한 것이 Transformer TTS이다.
- TTS를 할 때, unseen data에 대해 약하다는 단점이 있다. 이를 극복하기 위해 D-vector라는 개념을 도입한다. 구체적으로는 speaker verification network의 embedding vec을 가져와 character encoder에 붙인 것이다. 하지만 여전히 성능 향상에 한계가 있었으므로, reference encoder를 사용하는 방식으로 변경되었다. 이는 style을 추출하는 방식인데, 추출한 speaker style을 label에 대해 soft interpretation한다.
- VAE-Tacotron2에서는 syle latent variable에 확률적 요소를 추가한 모델이며, Gaussian mixture VAE는 이에 계층 요소를 추가해 개선한다.
- Vocoder는 magnitude만 이용해 phase 정보를 예측, 이를 통해 원본 audio를 예측하는 모델이다. mel-spectrogram -> waveform -> speech의 순서로 변경되며, 이때 phase가 없으므로 이를 일반화/예측하는 모델을 학습한다고 할 수 있다.

[15기 이성범]
-
사람들은 Emotion, Speech rate, Prosody 등 다양한 스타일을 통해 대화를 한다. 따라서 TTS의 경우 어떻게 스타일을 모델링하고, disentangle(분리) 하는지에 대한 다양한 연구가 진행되고 있다.
-
이에 대한 연구가 바로 Multi-Speaker, Style Modeling 이라고 할 수 있다.
-
D-vector based Multi-speaker
- Speaker Encoding 부분과 Tacotron2 Encoder 부분을 따로 학습하는 방법으로 진행
- Tacotron2의 Encoder Output에 Speaker Embedding을 concat하여 Multi-speaker 모델을 학습
- Speaker Embedding을 위해 D-vector를 사용
- D-vector는 화자 검증(Speaker Verification)에서 많이 사용되는 방법으로, End-to-End 모델을 통해 Speaker의 utterance를 d-vector로 modeling하여 test utterance의 d-vector와 consine similarity를 구하여 accept/reject하는 task에서 주로 사용된다.
-
Global Style Token
- Speech의 style을 GST 모델이 자체적으로 label에 대해 soft interpretable는 방법
- Target으로 하고 싶은 Style의 reference speech를 Input으로 주어 reference encoder를 통해 얻어진 style embedding에 대해 self-attention을 적용하여 각 token에 대한 style을 학습
- reference encoder는 2D-convolution layer * 6 + GRU Layer 로 이루어짐
- GST Model의 style token에 대해 학습하는 것은 Training set에 대해서 학습을 하는 것이다. 즉, DB 내에서만 학습하기 때문에 유의미하거나 독특한 token에 대해 학습을 하지 못한다.
-
VAE-Tacotron2
- VAE-Tacotron2는 latent variables을 통해 확률적(stochastic)으로 modeling하는 방법
-
Gaussian mixture VAE
- VAE의 경우 데이터를 control하는 latent variable z를 단일 정규분포로 가정을 하고 학습을 진행한다. 음성에는 다양한 특징(gender, speaker, accent, speech rate, etc)들이 존재한다. 따라서 여러 Gaussian distribution을 혼합하여 데이터를 control 하는 latent variable의 probability를 구하자는 것이 Gaussian mixture model의 핵심
[15기 안민준]
내용 정리는 다음 링크에 해 두고 있습니다.
https://github.com/YMGYM/ML_paper_study/blob/main/TacademyAudioSynth/lecture4.md
https://github.com/YMGYM/ML_paper_study/blob/main/TacademyAudioSynth/lecture6.md