[4주차] 딥러닝 기반 음성합성(2)
작성자: 이성범
1. Intro
1) 음성에서 다루는 Task
-
음성인식
- Speech to Text (STT)
- 음성 신호를 텍스트로 변환하는 과정
- 음성을 하나의 인터페이스(사람과 기계를 연결하는 매개체 ex, 마우스)로 사용하기 위한 필수적 기술
-
음성합성
- Text to Speech (TTS)
- 주어진 텍스트를 음성 신호로 변환하는 과정
- 사용 예: 성우가 없어도 오디우북을 만들 수 있고, ARS Service에서 상담원이 필요 없게됨
-
화자인식
- 입력된 음성 신호가 누구로부터 온 것인지 파악하는 과정
- 누구로부터 온 것인지 파악할 수 있기 때문에 지문인식, 패턴 입력 등과 더불어 보안에 도움이 될 수 있는 기술
-
음성향상
- 음성 신호에서 잡음을 제거하여 유용한 신호를 추출하는 과정
이번 장에서는 다양한 Task 중에서 음성합성, 즉 음성을 생성하는 것을 주로 다룰 것 이다.
2) 디지털 신호처리
우리가 듣는 음성은 Analog 신호 이다. 여기서 Analog 신호란 시간을 축으로 연속적인 신호라는 것이다. 그런데 이러한 아날로그 신호는 컴퓨터와 같은 전자기기에서는 다룰 수 없기 때문에 아날로그 신호를 기계가 다룰 수 있는 디지털 신호로 바꿔주는 과정이 필요하다.
디지털 신호로 바꿔주는 방법은 이미 앞 주차에서 배웠다.
- Discrete-time Fourier Transform (DTFT)
- Discrete Fourier Transform (DFT)
- Fast Fourier Transform (FFT)
- Short-time Fourier transform (STFT)
- Spectrogram
- Mel-spectrogram
이 중에서 우리가 주의 깊게 보아야할 방법은 바로 Mel-spectrogram 이다. Mel-spectrogram 이란 Spectrogram을 mel-scale로 재조정한 것으로, 신호를 일정 간격마다의 주파수 분석을 통해서 주파수의 크기를 기준으로 시각화한 것이 Spectrogram인데, 사람의 귀는 주파수 대역에 따라 민감도가 달라(낮은 주파수 일 수록 그 차이에 더 민감함)서 이러한 주파수 단위의 Spectrogram을 사람이 더 잘 받아들일 수 있게 mel-scale 단위로 재조정한 것이 바로 Mel-spectrogram 이다. Mel-spectrogram은 음성 신호의 feature로 주로 사용되며, 우리가 앞으로 다룰 음성 생성 모델 또한 Mel-spectrogram을 인풋으로 받는다.
3) Vocoder
보코더의 사전적 정의는 통신을 위한 음성 압축 기술이지만, 여기서는 보코더를 단순히 음성을 합성(생성)해주는 Model이라고 이해하면 된다.

음성 합성은 위의 그림과 같은 형태로 이루어지는데, 우선 Text를 End to End Model(ex. Tacotron)에 통과시켜서 Mel-spectrogram을 생성하고, 생성된 Mel-spectrogram을 다시 Waveform generator에 통과시켜서 최종적으로 음성을 생성하게 된다. 여기서 Waveform generator가 보코더에 해당된다.
Waveform generator은 Target으로 Mel-spectrogram을 사용하는데, 그 이유는 다음과 같다.
- Mel-spectrogram은 일정 구간에서 나타나는 주파수 성분의 크기를 나타내므로 실수 값으로 표현할 수 있다.
- 원 음성 신호(raw waveform)에 비해 압축된 형태의 데이터로 이루어져 다루기 쉽다.(차원의 수가 적절하다는 것)
그런데 Mel-spectrogram은 phase 정보를 포함하고 있지 않으므로(여기서 의미하는 phase는 반복되는 파형의 한 주기에서 첫 시작점의 각도 혹은 어느 한 순간의 위치를 의미하며, 페이즈(phase)는 원본 신호를 주기 신호로 분해했을 때 각 주기성분의 시점이 어딘인지(즉, 각 주기성분들이 어떻게 줄을 맞춰서 원본 신호를 생성했는지)를 나타내는 요소가 되기 때문에 phase를 잘 추정한다면 음성의 퀄리티를 높일 수 있다.), 본래의 음성 신호를 완벽히 복원하기 어려워 주파수 성분의 크기만으로 원 음성 신호를 잘 복원할 수 있는 알고리즘이 필요하며, 이 알고리즘 우리가 앞으로 배울 Neural vocoder 이다.
- Neural vocoder
- Mel-spectrogram을 입력으로 받아 음성 신호(waveform)을 생성하
는 딥러닝 모델 - 다량의 데이터 학습을 통해 neural vocoder는 mel-spectrogram과 음성 신호 사이의 관계를 이해하고, 고품질의 음성을 생성
- 대표적인 neural vocoder
- Autoregressive model: WaveNet vocoder
- Flow-based model: WaveGlow, FloWaveNet, Parallel WaveNet, ClariNet
- GAN-based model: ParallelWaveGAN, VocGAN
- Mel-spectrogram을 입력으로 받아 음성 신호(waveform)을 생성하
이번 강의에서는 Autoregressive model과 Flow-based model을 다룬다.
2. Deep Generative Model
1) Deep Generative Model 이란?
Deep Generative Model은 간단하게 말해서 어떠한 확률 z를 추정하고 추정된 확률 z에서 새로운 데이터를 생성하는(샘플링) 모델이라고 생각하면된다. 따라서 Generative Model에서는 확률 z를 어떻게 구할 것이냐?가 중요한 Task가 된다.
(1) 생성 모델의 종류
- Autoregressive Model
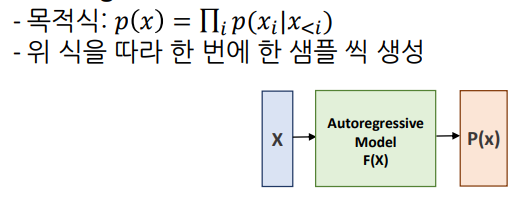
t-1 까지의 데이터를 계속 Autoregressive 하게 활용하여 확률을 계산하는 모델
- Generative Adversarial Network (GAN)
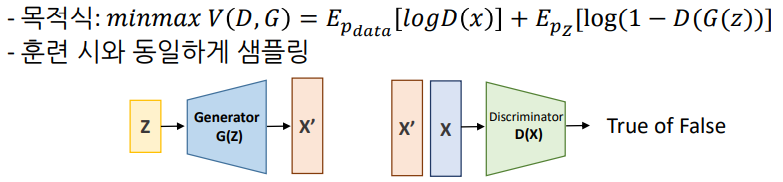
생성자와 판별자를 적대적으로 학습 시켜서 판별자를 속이는 데이터를 생성하는 모델
- Variational Autoencoder (VAE)
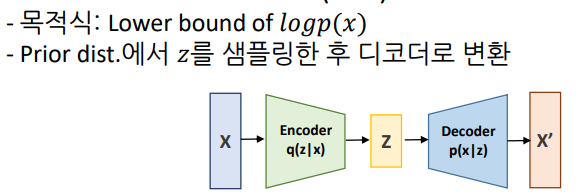
사전 분포에서 z를 얻어서 다시 복원시키는 모델
- Normalizing Flow
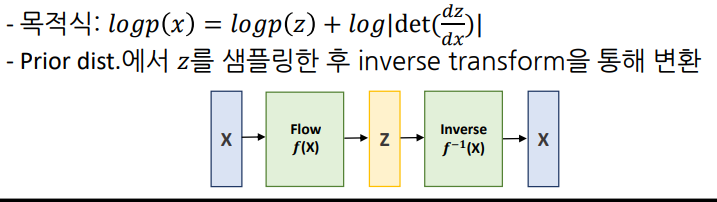
사전 분포에서 z를 얻은 후 역변환을 통해서 다시 복원시키는 모델
(2) Log-Likelihood
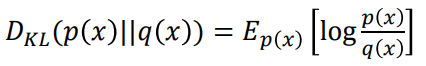
그렇다면 우리는 z라는 확률 분포를 어떻게 추정하게 되는 것 일까? 바로 Kullback–Leibler divergence를 계산하면 된다. KL divergence는 두 확률 분포 𝑝(𝑥), 𝑞(𝑥)가 서로 얼마나 다른지를 나타내는 척도로 활용되는 함수로 이 값이 0이 된다면 두 확률분포가 동일하다고 할 수 있다. 따라서 우리는 KL divergence가 최소화 될수 있도록 모델을 구성하면 된다.

KL divergence는 다음과 같은 성질은 가지는데, 간단하게 말해서 KL divergence는 항상 0보다 크거나 같고(0이면 동일한 분포), 그 반대는 성립하지 않는다는 것이다.
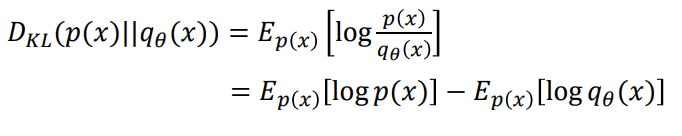
실제 데이터 분포 𝑝(𝑥)와 이를 추정하는 분포 𝑞𝜃(𝑥)가 있을 때 𝑝(𝑥)와 𝑞𝜃(𝑥)가 얼마나 다른지를 측정하는 지표로 KL divergence를 사용하면. (𝑝(𝑥)||𝑞𝜃(𝑥))를 최소화하는 𝜃를 찾으면 두 확률 분포는 유사해 질 것이다.
따라서 우리는 위 식에서 [𝑙𝑜𝑔𝑞𝜃(𝑥)]를 최대가 되도록 식을 최적화 시키면 KL divergence가 최소가 될 것이다.(값을 최대화 하기 위해서는 경사상승법을 사용해야 하는데 대부분의 프레임워크에서는 다 경사하강법을 기반으로 최적화 된다. 따라서 우리는 값에 -를 붙여서 최적화를 시키게 되고 이에 앞에 negative라는 말이 붙게 된 것이다!)
Log-Likelihood는 [𝑙𝑜𝑔𝑞𝜃(𝑥)]이 값을 계산하는 과정을 의미하는 것이고, Log-Likelihood를 계산하는 방법에 따라서 다음과 같이 생성 모델이 분류된다.
- Autoregressive Model
- Normalizing Flow
- Variational Auto-Encoder
2) Autoregressive Model
(1) Autoregressive Model 이란?
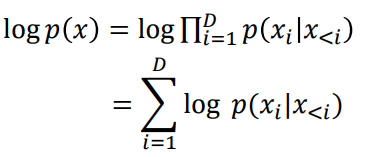
Autoregressive Model을 위와 같은 목적 함수를 Chain Rule을 통해 최대화 하는 방향으로 계산된다. (과거의 나를 고려해서 미래를 예측하겠다는 느낌)
(2) 그래프 모델
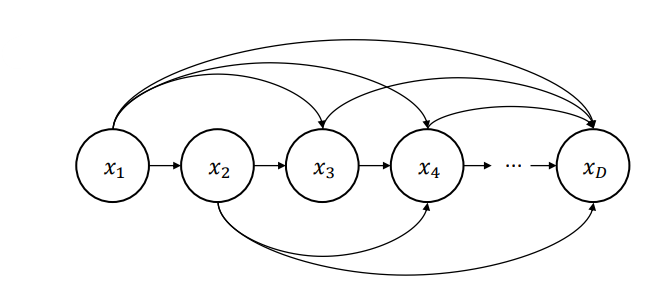
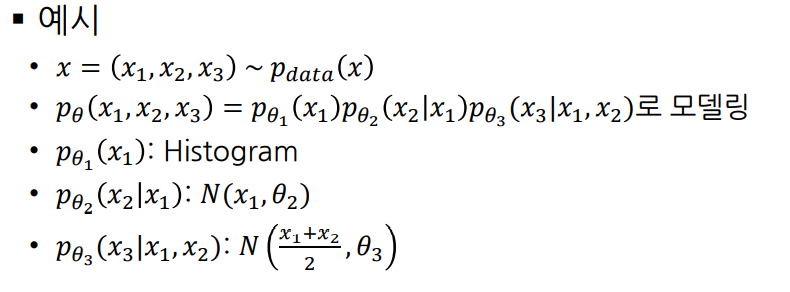
그래프 모델은 다음과 같은 방식으로 모델이 구성되는데, 본 모델의 문제점은 High-dimensional data를 모델링할 경우 파라미터 수가 매우 증가한다는 것이고, 서로 다른 조건부 확률 분포를 모델마다 독립적으로 훈련한다는 것이다.
(3) RNN-based approach
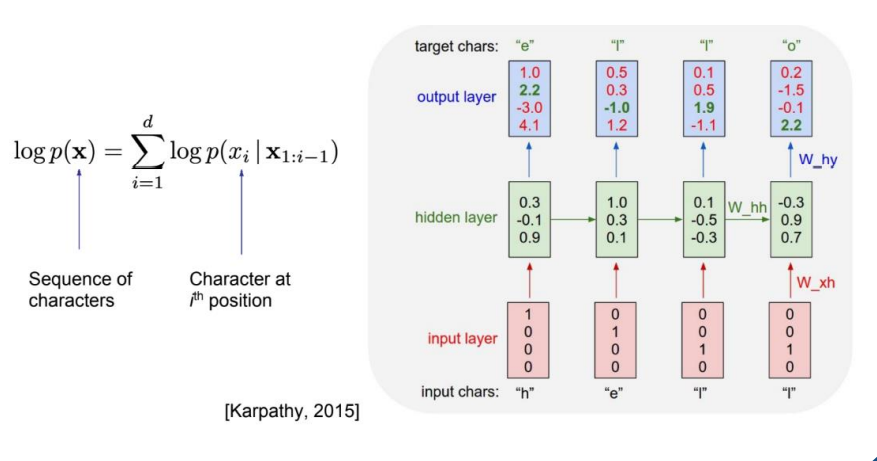
RNN-based Model은 다음과 같이 hidden layer를 공유하는 방식으로 훈련하기 때문에 그래프 모델의 독럽적으로 훈련한다는 단점을 해결했다.
(4) PixelCNN
PixelCNN은 이미지를 생성하기 위한 모델로 Autoregressive Model의 목적 함수를 표현할 수 있는 CNN 아키텍쳐를 제사한 모델이다.
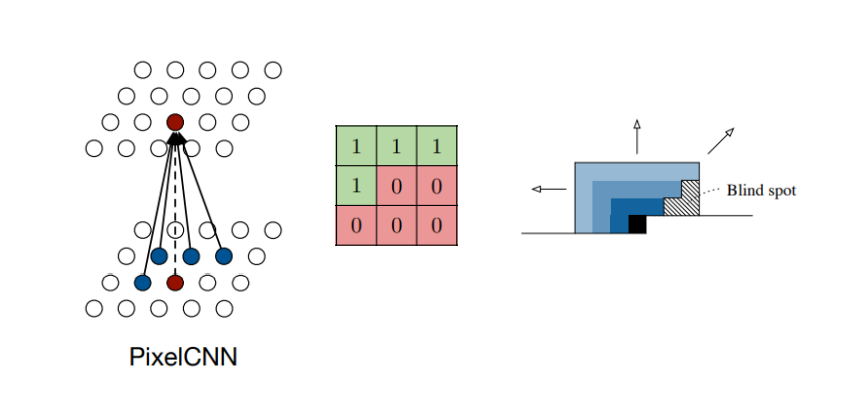
PixelCNN은 다음과 같이 Masked Convolution을 각 convolutional layer에 적절히 적용하여 이전 샘플들만 뉴럴 네트워크의 인풋으로 사용되도록 설계했는데, Bilnd spot이 발생한다는 문제점을 가진다. (Masked 때문에 모델이 고려하지 못하는 부분이 생기는 것)
(5) WaveNet
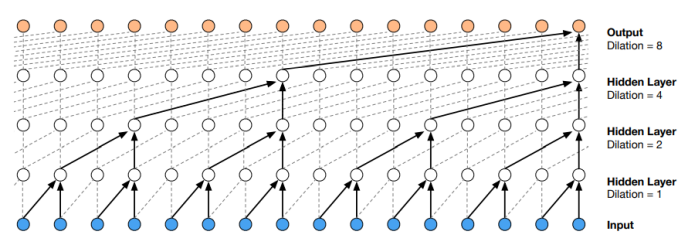
WaveNet은 Dilated and causal CNN 으로 요약할 수 있는데, 여기서 causal 이란 왼쪽에만 패딩을 취하고 오른쪽으로만 stride 하는 방식으로 sequential data를 표현하는데 적합한 형태이다. Dilated는 위의 그림과 같은 형태로 receptive field를 넓히는 방식이다. 음성 신호의 특징을 잘 모델링하기 위해서는 receptive field가 상당히 넓어야 하는데 (과거의 정보를 조금 더 많이 고려해야 한다는 것), receptive field를 넓히기 위해서는 엄청나게 많은 수의 layer를 쌓아야 한다. 이는 매우 비효율적이고, 비효과적인 방식이기 때문에 Dilated 방식을 적용하면 적당한 수의 layer만으로도 상당히 넓은 receptive field를 갖도록 모델 설계할 수 있다.
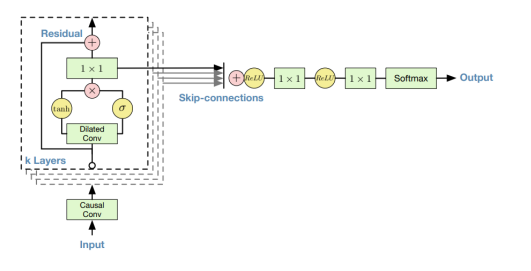
WaveNet은 위 그림과 같이 모델이 구성되어 있는데, Residual block과 skip connection을 사용하여 깊은 네트워크를 효과적으로 훈련할 수 있도록 했고, Non-linearity는 다음과 같은 gated activation unit을 사용해 학습했다.
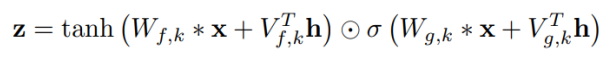
3) Flow-based Model
(1) Flow-based Model 이란?
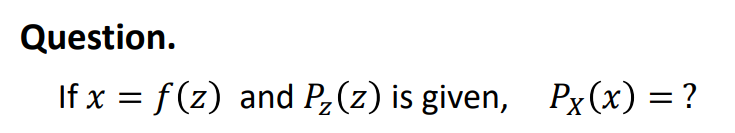
Flow-based Model은 다음과 같은 가정이 주어졌을 때, 를 구하는 것이라고 할 수 있다.
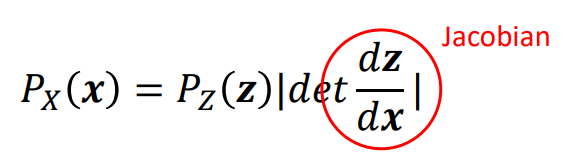
의 경우에는 x가 N 차원의 벡터이기 때문에 다음과 같이 Jacobian Determinant를 활용한 식으로 구할 수 있다.
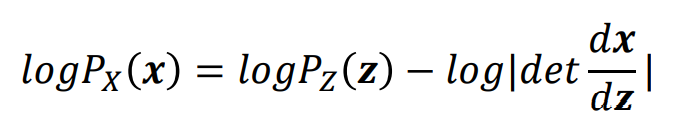
그런데 우리의 목표는 Log-Likelihood를 구하는 것이기 때문에 최종적으로 다음 식을 이용한다.
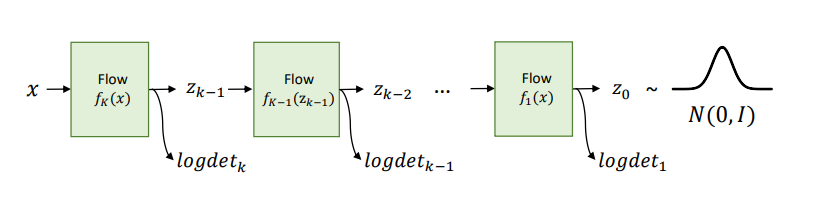
𝑧 = 𝑓(𝑥)인 경우 𝑝(𝑥) = 𝑝(𝑧) 𝑑𝑒𝑡 || 의 식으로 나타낼 수 있는데, 우리는 위의 그림과 같이 각각의 모든 log determinant를 다 고려할 것이고 Log-Likelihood를 고려하는 것이기 때문에 최종 목적식은 아래와 같다. (여기서 같은 경우에는 임의로 설정한다고 한다. ex, 가우시안 분포 등)
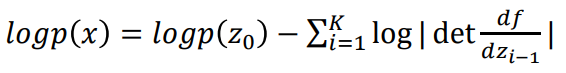
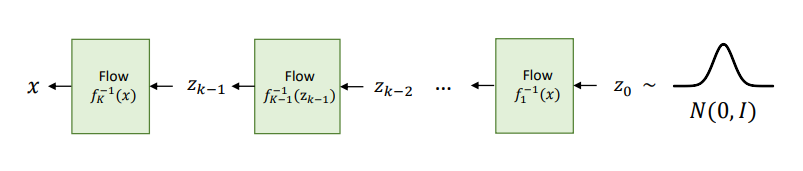
이렇게 학습된 모델에서 를 𝑁(0,𝐼)로부터 샘플링 한 뒤 위 그림과 같이 역변환하여, Autoregressive Model과 다르게 빠르게 샘플링할 수 있다.
여기서 𝑧 변수들의 sequence를 Flow라 하고, p(z)의 sequence는 Normalizing Flow라고 부른다. 그래서 Flow-based Model 이라고 말하는 것이다.
그런데 Flow-based Model, 즉 Normalizing Flow를 이용하기 위해서는 다음과 같은 두 가지 조건이 필요하다.
- 𝑥 → 𝑧 (training), 𝑧 → 𝑥 (sampling)와 같은 과정에서, Invertible이 쉬워야 한다.
- Jacobian Determinant 계산이 쉬워야 한다.
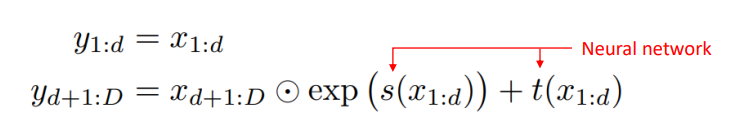
이 두 가지 조건을 충족시키기 위해서 다음과 같이 Affine coupling layer를 이용했다. 이 방식은 식을 통해서도 알 수 있듯이 첫번째 절반은 변환시키지 않고, 두 번째 절반만을 변환시키는 방식이다.
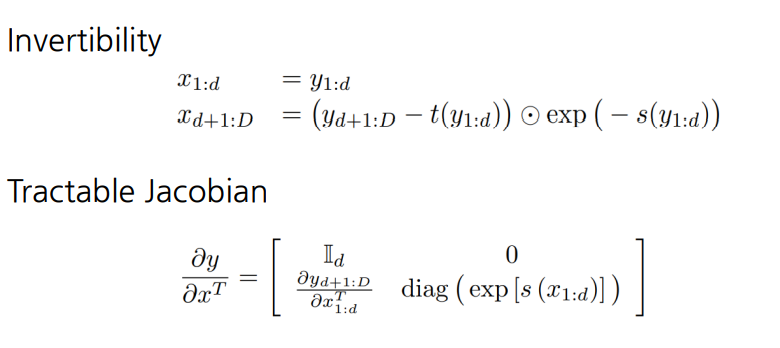
이러한 Affine coupling layer 덕분에 다음과 같이 Invertible과 Jacobian Determinant 계산이 쉬워졌다.
(2) RealNVP
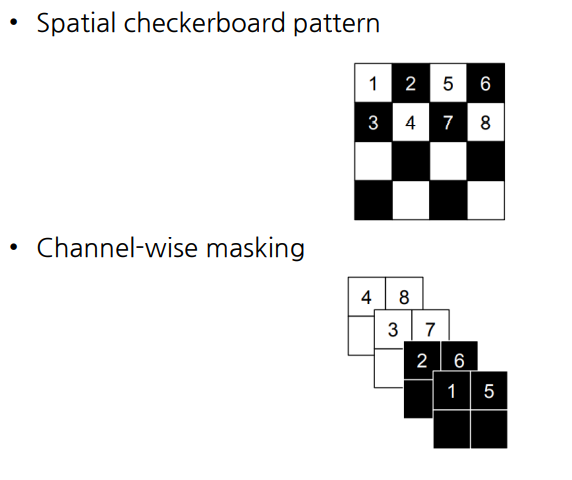
그런데 Affine coupling layer의 연산 방식은 절반만 변환시키는 방식이기 때문에 표현력이 제한된다는 문제점을 가진다. 그래서 주기적으로 Affine coupling layer에 input으로 들어가는 변환되는 성분을 바꿔줘서 이러한 문제점을 해결한 모델이 바로 RealNVP이다. RealNVP는 Permutation 연산을 통해서 주기적으로 변환되는 성분을 바꿔주었다.
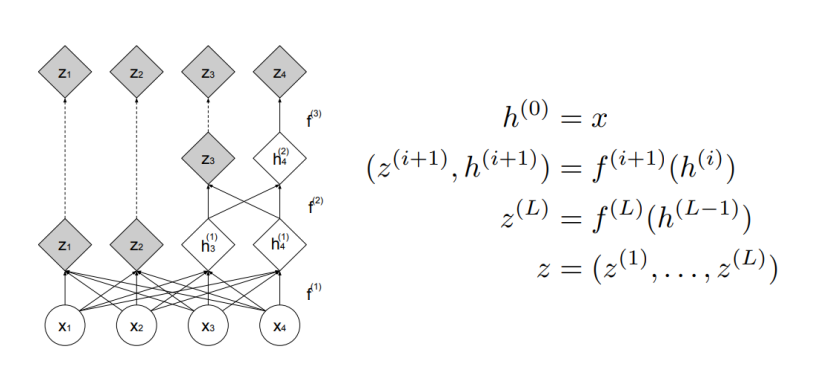
RealNVP는 플로우 블록을 충분히 깊게 쌓기 위해 다음과 같은 Multi-scale architecture을 제안했다.(제한적인 함수를 쓰기 때문에 모델이 깊어진다는 특징을 가져서 중간마다 깊게갈 부분을 선택함)
(3) Glow
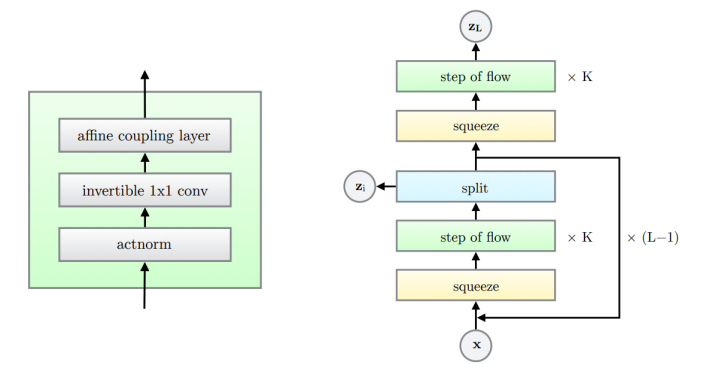
Glow는 다음과 같이 Actnorm, Invertible 1x1 conv, Affine coupling layer를 기본 블록으로 설정하여 깊은 플로우 네트워크를 형성한 모델이다.
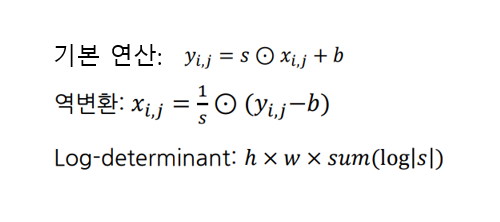
대부분에 고해상도의 이미지를 학습시키기 위해서는 batch size를 작게하는데, 이러힌 경우에 batch normalization을 그대로 사용하는 것은 부적절할 수 있어, 이에 대한 해결책으로 나온 방식이 바로 Actnorm이다. Actnorm은 다음과 같은 연산을 수행하며 s, b를 학습 파라미터로 설정하고, 초기 값은 initial batch statistics로 결정한다. 역변환과 Log-determinant 또한 계산이 쉽다는 것을 알 수 있다.
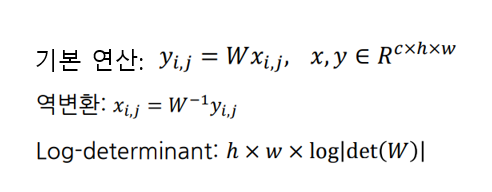
Invertible 1x1 conv은 RealNVP에서 사용된 permutation 연산을 1x1 convolution의 형태로 재해석한 방식이다. 다음과 같이 기본 연산과, 역변환, Log-determinant 모두 계산이 쉽다는 것을 알 수 있다.
3. 최신 음성 합성 모델
1) WaveNet Vocoder
WaveNet vocoder는 주어진 mel-spectrogram에 해당하는 오디오(waveform)를 생성하는 보코더의 역할을 수행하도록 기존의 WaveNet을 수정한 것이다.
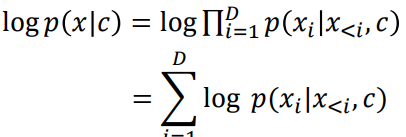
본 모델의 목적 함수는 다음과 같다. 여기서 x는 raw audio이고, c는 mel-spectrogram 이다. 인풋으로 raw audio와 mel-spectrogram 두개가 들어간다.
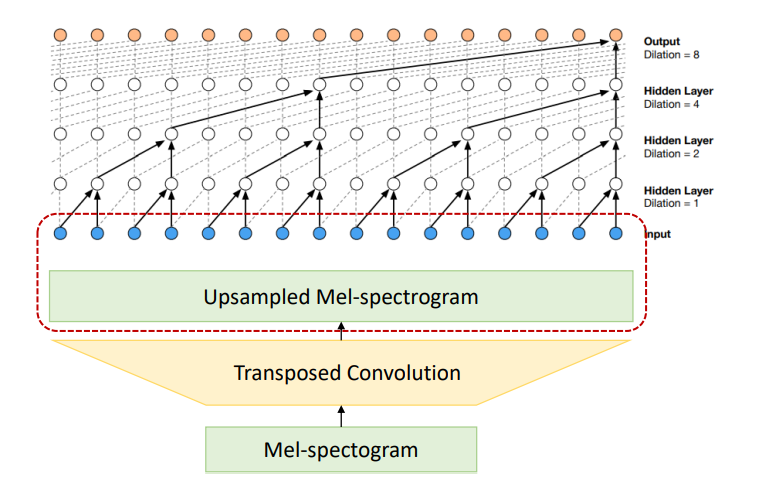
본 모델은 다음과 같은 형태로 학습이 된다. Mel-spectogram을 Transposed Convolution을 통해서 Upsample 하는데, 이 이유는 mel-spectrogram과 raw audio가 서로 시간 축으로 길이가 다르기 때문에, 이 길이를 맞춰주기 위해서 Transposed Convolution을 통해서 mel-spectrogram을 Upsample 하는 것이다.
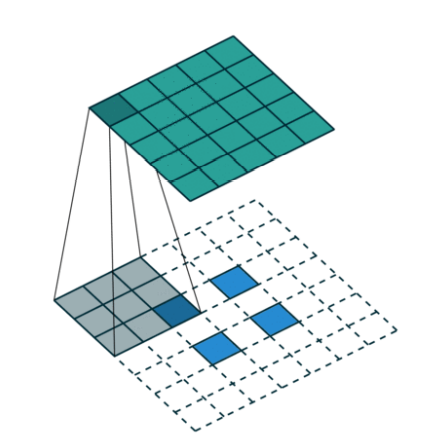
Transposed convolution은 다음과 같이 convolution의 반대 과정이라고 생각하면 된다.
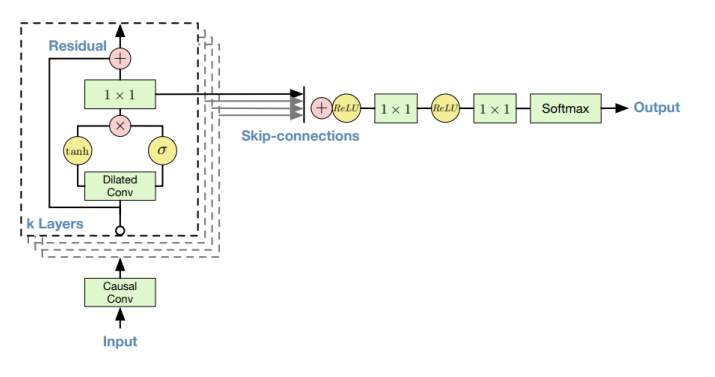
WaveNet Vocoder는 다음과 같이 WaveNet의 Residual block과 skip connection을 동일하게 적용한다. 그리고 말단의 layer를 z를 추정하는 방식으로도 수정할 수 있다고 한다.
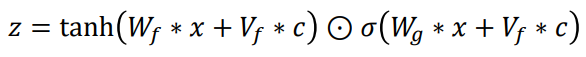
그런데 WaveNet Vocoder는 Non-linearity를 구하는 방식이 WaveNet과 조금 다르게, mel-spectrogram과 raw audio를 각각 서로 다른 변수에 곱하고, 더한 뒤에 각각을 tanh 함수와 sigmoid 함수에 통과시켜서 두 아웃풋을 element-wise 곱을 하는 형태이다.(인풋으로 mel-spectrogram과 raw audio 2개를 사용하기 때문인 것으로 생각됨)
WaveNet Vocoder의 장점
- 생성된 샘플을 바탕으로 새로운 샘플을 생성하여 음질의 퀄리티가 좋은 편
- 직관적인 목적 함수
- 1~2초 길이의 음성 신호 및 mel-spectrogram을 이용하여 훈련 가능
- CNN 기반 모델이므로 실제 사용 시에 훨씬 더 긴 길이의 음성 신호 합성 가능 (ex. 7초에 해당하는 mel-spectrogram을 입력으로 주면 이에 해당하는 음성 생성 가능)
WaveNet Vocoder의 단점
- Autoregressive property로 인한 느린 샘플링 속도 (성능은 좋지만 샘플링 속도가 매우 느려서, Normalizing Flow의 병렬적처리를 활용하여 조금 더 샘플링 속도를 높인 모델들이 우리가 앞으로 다룰 FloWaveNet, WaveGlow, Parallel WaveNet 임, 그러나 본 모델들은 샘플링 성능이 WaveNet Vocoder 보다 좋지 못하다는 단점을 가짐)
- 훈련 과정과 샘플링 과정의 mismatch (ex. teacher forcing / 인풋에 정답만 넣기 때문에)
2) FloWaveNet
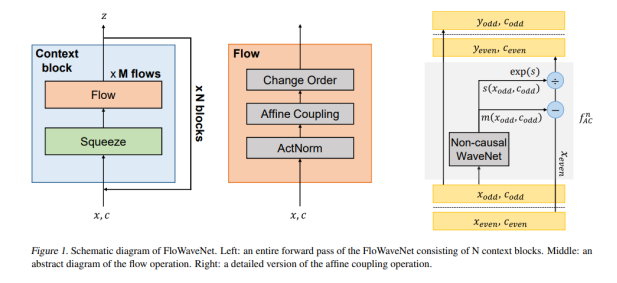
FloWaveNet은 다음과 같은 Architecture를 가진다.
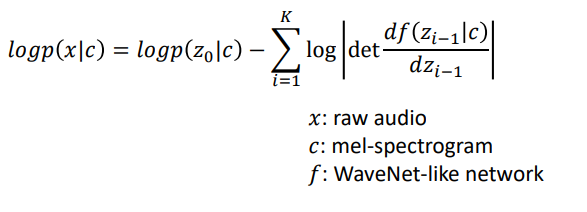
목적식은 다음과 같으며, 인풋으로 raw audio와 mel-spectrogram이 모두 사용된다는 것을 알 수 있다.
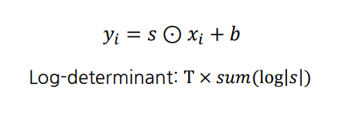
FloWaveNet의 ActNorm은 다음과 같은 식으로 이루어지며 기존의 ActNorm과 동일하다.
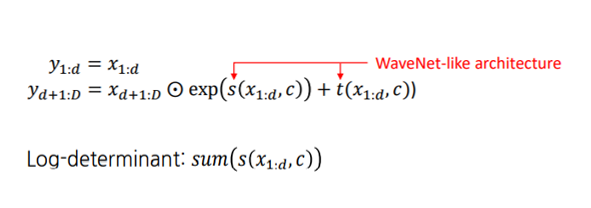
FloWaveNet의 Affine Coupling Layer은 다음과 같은 식으로 이루어지며, raw audio와 mel-spectrogram이 모두 사용된다는 것을 알 수 있다.
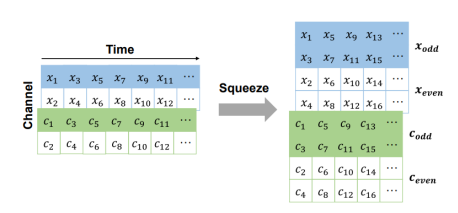
FloWaveNet의 Squeeze는 다음과 같이 채널을 변환시키는 방식이며, 이러한 방식을 하는 이유는 Affine Coupling Layer의 계산을 위한 것이다(절반만 변환을 시키는 연산을 하려면 1차원의 오디오 데이터의 채널을 증감 시켜줄 필요가 있음)
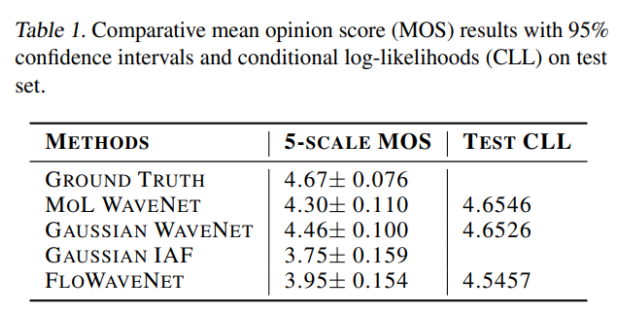
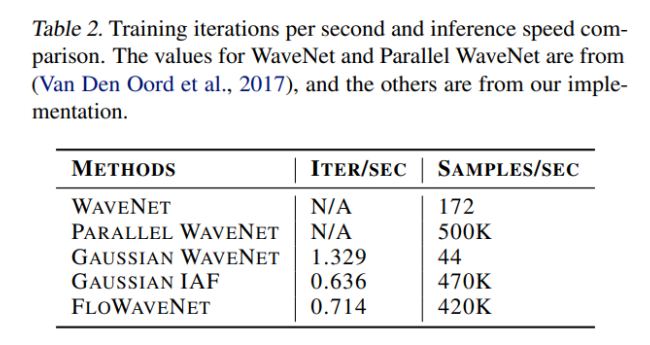
FloWaveNet은 다음과 같은 성능을 보여준다.
3) WaveGlow
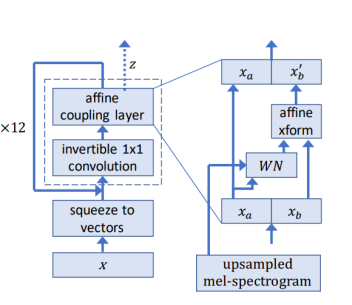
WaveGlow는 다음과 같은 Architecture을 가지고 있다.
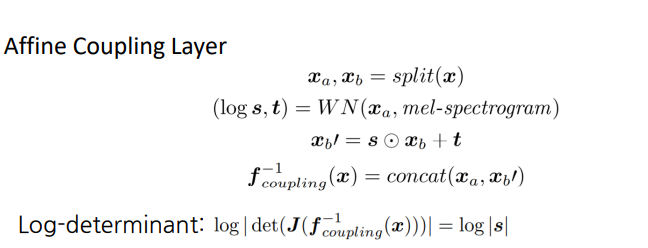
WaveGlow는 다음과 같은 식으로 Affine Coupling Layer를 계산한다.
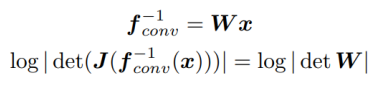
WaveGlow는 Affine coupling layer를 통과하기 전 채널을 섞어 주기 위하여 다음과 같은 식으로 1x1 invertible convolution를 사용한다.
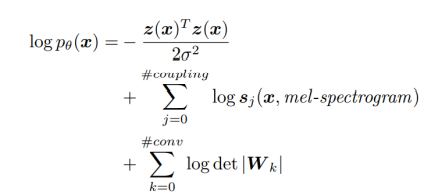
WaveGlow의 최종 목적 함수는 다음과 같다.
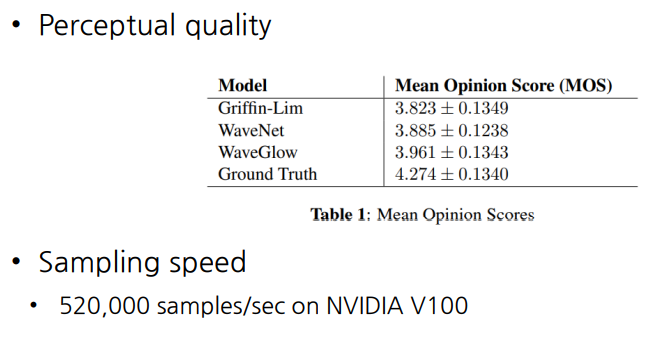
WaveGlow의 성능은 다음과 같다.
FloWaveNet과 WaveGlow의 차이점은 다음과 같다.
- 채널을 서로 섞어주는 방법으로 WaveGlow는 1x1 invertible conv을 시용하는데, FloWaveNet은 channel ordering을 이용해 직접 바꿔준다.
- FloWaveNet은 Actnorm을 사용하는데, WaveGlow는 아무런 BN을 사용하지 않는다.
그런데 두 모델의 공통점은 Affine Coupling Layer의 제한적인 형태(반만 변환을 해주는 것) 때문에 확률 분포를 잘 표현하기 위해서는 수많은 Flow step을 요한다는 것이고 (모델의 깊이가 깊어짐), 이에 수많은 파라미터를 요하게 되어 메모리 비효율적인 모델인 모델이 된다는 것이다.

4) Parallel WaveNet
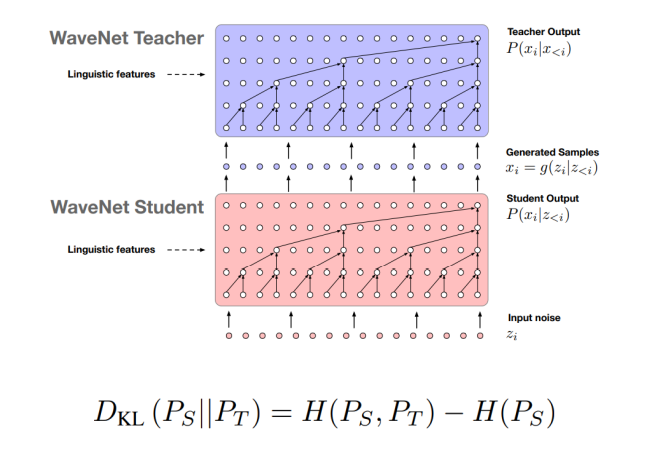
Parallel WaveNet은 다음과 같은 Knowledge Distillation 방식으로 이루어져 있다. 이는 WaveNet Teacher 모델의 능력을 표현할 수 있는 작은 WaveNet Student 모델을 만드는 것으로, 모델이 작아지는 만큼 파라미터의 수가 줄어들어 다음과 같이 샘플링 속도가 빨라지고, 성능 또한 큰 차이가 없다.
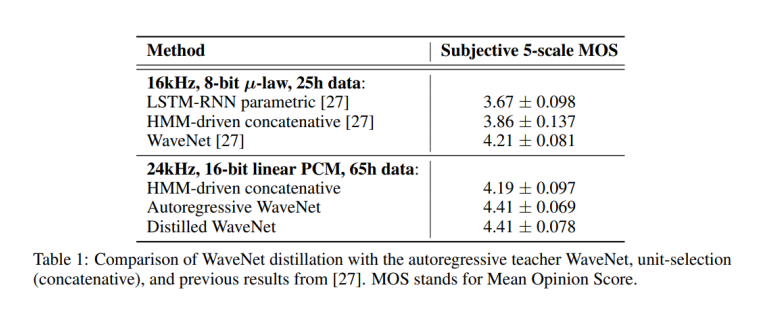

참고자료

3개의 댓글

WaveNet Vocoder의 upsampling이 noise를 만들지 않나요?
사이즈를 맞추는 대가로 없는 정보를 만드는게 어느정도 효과가 있는지 궁금합니다..!

[15기 안민준]
[질문]
- 강의 중에 WaveNet 과 WaveNet Vocoder의 개념 이해가 완벽하게 되지 않은 것 같습니다. 일반 WaveNet 그 자체가 Vocoder 로 쓰일 수 있다고 이해했는데, 잘못 이해한 것인가요?
<음성에서 다루는 Task>
- 음성 인식 : 음성을 하나의 인터페이스로 사용하기 위한 필수적 기능
- 음성 합성 : 텍스트를 음성 신호로 변환
- 화자 인식 : 입력된 음성 신호가 어디서 왔는지
- 음성 향상 : 잡음 제거
<디지털 신호처리>
- 아날로그 신호를 기계가 다룰 수 있는 디지털 신호로 바꿔주는 작업
<Vocoder 모델의 종류>
- 생성: 자기회귀 모델, GAN, VAE, Normalizing Flow
- 학습을 위해 KL-Divergence를 손실 함수로 표현
<Vocoder의 RNN-Based approach>
PixelCNN
- Autoregressive 모델을 CNN으로 모사함
WaveNet - 왼쪽에 패딩, 오른쪽으로만 stride : 시간 축을 표현하는 데 좋다. (casual)
- receptive field 를 효율적으로 넓힘 (Dilated)
Flow-based Model - 자코비안 행렬식을 활용해서 역함수를 구할 수 있다.
Glow - 깊은 flow 네트워크
- Actnorm 도입 : 정규화를 그대로 수행할 때 발생하는 비효율성 해결
<엄청 빠른 모델 두 개>
- FlowWaveNet
- WaveGlow
[15기 황보진경]
1. FloWaveNet의 그림을 보면 x(raw audio), c(mel-spectrogram)이 둘다 인풋으로 들어가는데, 그럼 inference과정에는 어떻게 되는 건가요?
2. Parallel wavenet에서 어떤 부분이 병렬인지 잘 이해가 되지 않습니다..