[3주차] 딥러닝 기반 음성합성(2) Deep Learning, Tacotron2, Transformer
1. End to End의 도입
Text를 DT를 활용해 Cluster로 나누면 DT의 독립성, 공간의 이진분할을 바탕으로한 feature 생성 때문에 맥략적인 의미 파악이 어렵게 된다.이에 따라 비선형성을 활용할 수 있는 Deep Learning을 활용해 End to End 구조로 TTS Task를 풀자고 하였다.
 TTS with DL
TTS with DL
초기에 제안된 DNN을 활용한 모델의 구조는 위와 같다.
binary feature에는 phone에 관한 정보, DT에서 활용했던 Question들에 대한 정보, numerical feature에는 phrase안의 단어 수와 같은 정보들이 들어가게 된다.
 LSTM
LSTM
음성은 sequential한 data이기 때문에 RNN계열의 모델들이 많이 활용이 되었고, long-term dependency를 해결하기 위해 gate가 있는 LSTM, GRU등이 많이 활용되었다. 연속적인 음성을 발화할 때, 현재 발음과 이후의 발음 간에는 상호적인 연관성이 있기 때문에 bi-directional RNN이 활용된다.
강의 발표 기준으로 Text에서 바로 음성을 합성해주는 (정확히 말하면 mel-spectrum까지) end-to-end 모델들에 대한 연구가 많이 지행되고 있다.
2. Tacotron2
2.1 Tacotron1
 Tacatron1
Tacatron1
Encoder
- Embedding Layer
TTS는 Input text를 character level로 처리해서 모델의 Input으로 넣어준다.
아래와 같은 Indexing을 통해 Look up Table에서 Embedding Vector를 가져온다.
char2idx = {char: idx for idx, char in enumerate(vocab)}
idx2char = {idx: char for idx, char in enumerate(vocab)}-
Prenet
Linear Layer로, Encoder의 Input과 Decoder의 Input에서 일종의 정보를 filtering하는 역할을 한다.
(bottleneck layer for convergence and generalization) -
CHBG
 CHBG
CHBG
Convolution Bank + Highway + GRU의 약어로 1D Convolution Bank, Highway 네트워크, 그리고 Bidirectional GRU로 이루어져 있다. CBHG에 입력으로 들어간다.
수초짜리의 음성 데이터를 정해진 크기만큼 순차적으로 학습하고, convolutional layer로 목소리 특징을 뽑아내 동시에, 뽑혀진 부분 특징을 위의 RNN에서 전체적으로 보면서 결과를 만들어 내는 것을 목표로 하고 설계한 구조이다.
Encoder는 Kernel 사이즈를 1부터 16까지 16개를 사용하게 되고 Decoder의 Mel-spectrogram을 처리하는데 사용되는 CBHG의 경우 Kernel 사이즈를 1부터 8까지 8개를 사용한다. (Kernel 개수/Stride는 이후에 skip-conection을 해야해서 맞춰줘야함)
이후 Convolution 연산 이 된 벡터를 Sequence 축을기준으로 Max Pooling > 1D Convolution > Batch Normalization을 수행하였다.
이후에는 단순 Residual Connection이 아닌 Highway layer를 활용해 Residual Connection을 진행
는 를 어떤 가중치로 weighted sum할 지를 결정할지 학습하는 layer이다.
음성합성에서 CHBG가 성능 향상에 중요하다고 하지만 Tacotron2에서 이 구조를 활용하지 않았는데 더 좋은 성능을 기록함
- Bi-directional RNN
CHBG를 통과하온 Text-Feature에 Bi-directional RNN을 통과하여 양방향으로의 context 학습
Decoder
-
Input
Decoder의 Input으로는 이전 time-step에서 생성한 Mel-Spectrogram의 마지막 Frame을 Input으로 넣어준다.
(그림상으로는 3번째)
Training 시에는 Golden Mel-Spectrogram Frame (Teacher Forcing)
Inference 시에는 모델이 이전 step에서 생성한 Mel-Spectrogram의 마지막 Frame -
Prenet
Encoder의 prenet과 동일 -
Attention RNN
 Attention
Attention
Decoder 현재 time-step으로 들어온 mel-spectogram이 Encoder text의 어떤 부분과의 관계를 바탕으로 형성되었는지 alignment를 시켜주는 구조이다.
TTS의 경우 Attention이 걸리는 방향이 Monotonic해야하는데 이는 이후 Tacotron2의 LSA에서 설명할 예정이다.
-
Uni-directional RNN
Attention RNN위에 RNN Layer를 하나 더 쌓아서 mel-spectogram의 순차적인 관계를 학습한다. -
Mel-Spectrogram
Tacotron의 경우 여러 Frame의 mel-spectogram을 한번에 생성하도록 모델이 설계되어있다.
1) 매 Frame보다 여러 Frame을 생성하는게 학습상으로 유리하다.
2) 음성 신호는 여러 프레임에 거쳐서 하나의 발음이 수행되기 때문에 해당 구조의 가정은 유의미하다. -
Linear-Spectrogram
Encoder에서 설명한 CHBG를 활용해 Mel-Spectrogram으로부터 Linear-Spectrogram을 생성한다. -
Griffin-Lim Algorithm
Griffin-Lim Algorithm이라는 음성 재구성 알고리즘을 통해서 음성으로 변환된다.
해당 알고리즘은 Filter들을 바탕으로 Waveform을 만들어주는 rule-based 방법이다.
Loss
Tactron1의 경우 Decoder의 CHBG를 통과하기 전인 각 Mel-Spectrogram Frame과 실제 Label의 Mel-Spectrogram Frame간의 MSE,CHBG 통과 이후 각 Lin-Spectrogram Frame과 실제 Label의 Lin-Spectrogram Frame간의 MSE을 더한 Loss에 대해서 Gradient를 흘려 학습을 진행하게 된다.
mel_loss = MSE(mel_outs - mel_targets)
lin_loss = MSE(lin_outs - lin_targets)
loss = mel_loss + lin_loss2.2 Tacotron2
기존 Tacotron1의 한계점을 극복하기 위해 제안된 모델
 Tacotron2
Tacotron2
Tacotron1 대비 크게 바뀐 부분은 아래와 같다.
3 Conv layers
CHBG가 단순 1D ConvNorm(1d convolution layer + batch norm)로 바뀌었음
for _ in range(hparams.encoder_n_convolutions):
conv_layer = nn.Sequential(
ConvNorm(hparams.encoder_embedding_dim,
hparams.encoder_embedding_dim,
kernel_size=hparams.encoder_kernel_size, stride=1,
padding=int((hparams.encoder_kernel_size 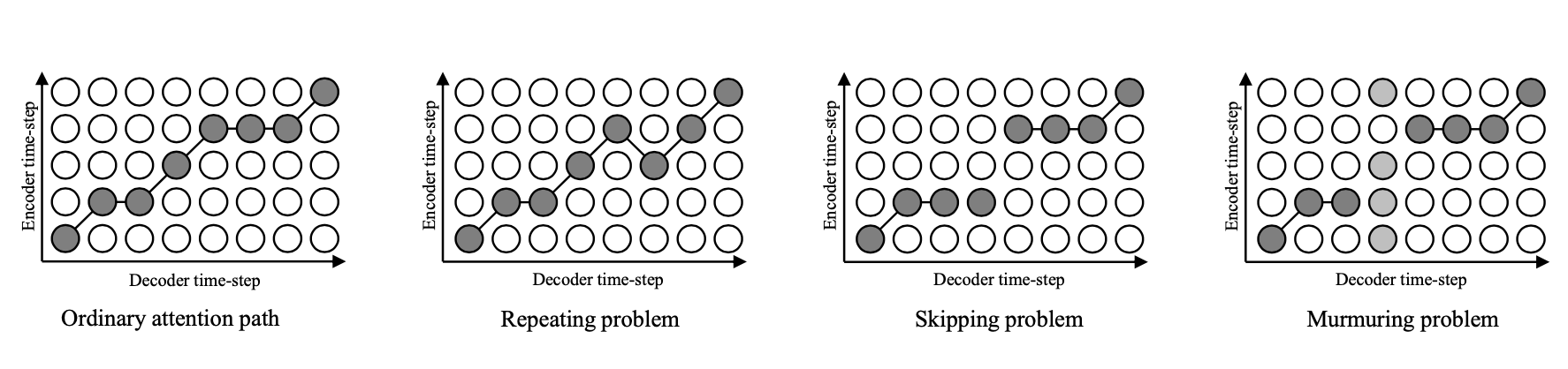- 1) / 2),
dilation=1, w_init_gain='relu'),
nn.BatchNorm1d(hparams.encoder_embedding_dim))
convolutions.append(conv_layer)
self.convolutions = nn.ModuleList(convolutions)Local Sensitive Attention
Attention은 적절한 Position에 있는 vector들 간에 걸리면 내적/유사도 연산으로 성능이 증가하나, 관련 없는 vector들 간에 걸리면 모델이 높은 confidence level로 예측을 하게 되는 원인이 된다.
TTS의 경우 현재 음성의 발음이 Input text의 sequential한 순서대로 진행이 되어야하기 때문에 Attention이 Sequential하게 걸려야 한다.
 Attention Pattern
Attention Pattern
아래의 조건에 맞게 Attention이 걸려야 한다.
- Monotonicity
- Local continuity
- Focusing
따라서 단순한 Additive attention mechanism(Bandau Attetnion)에 attention alignment 정보를 추가한 형태의 Attention을 진행함
이전 시점에서 생성된 attention alignment()를 이용하여 다음 시점 Attention alignment()를 구할 때 추가로 고려
:Encoder bi-LSTM에서 생성된 i번째 feature
: Decoder LSTM에서 (t-1)번째 time-step에서 생성된 feature
class LocationLayer(nn.Module):
def __init__(self, attention_n_filters, attention_kernel_size,
attention_dim):
super(LocationLayer, self).__init__()
padding = int((attention_kernel_size - 1) / 2)
self.location_conv = ConvNorm(2, attention_n_filters,
kernel_size=attention_kernel_size,
padding=padding, bias=False, stride=1,
dilation=1)
self.location_dense = LinearNorm(attention_n_filters, attention_dim,
bias=False, w_init_gain='tanh')
def forward(self, attention_weights_cat):
processed_attention = self.location_conv(attention_weights_cat)
processed_attention = processed_attention.transpose(1, 2)
processed_attention = self.location_dense(processed_attention)
return processed_attentionclass Attention(nn.Module):
def __init__(self, attention_rnn_dim, embedding_dim, attention_dim,
attention_location_n_filters, attention_location_kernel_size):
super(Attention, self).__init__()
self.query_layer = LinearNorm(attention_rnn_dim, attention_dim,
bias=False, w_init_gain='tanh')
self.memory_layer = LinearNorm(embedding_dim, attention_dim, bias=False,
w_init_gain='tanh')
self.v = LinearNorm(attention_dim, 1, bias=False)
self.location_layer = LocationLayer(attention_location_n_filters,
attention_location_kernel_size,
attention_dim)
self.score_mask_value = -float("inf")
def get_alignment_energies(self, query, processed_memory,
attention_weights_cat):
"""
PARAMS
------
query: decoder output (batch, n_mel_channels * n_frames_per_step)
processed_memory: processed encoder outputs (B, T_in, attention_dim)
attention_weights_cat: cumulative and prev. att weights (B, 2, max_time)
RETURNS
-------
alignment (batch, max_time)
"""
processed_query = self.query_layer(query.unsqueeze(1))
processed_attention_weights = self.location_layer(attention_weights_cat)
energies = self.v(torch.tanh(
processed_query + processed_attention_weights + processed_memory))
energies = energies.squeeze(-1)
return energiesStop Token
기존에는 지정한 Decoder Time-step 끝까지 Mel-Spectrogram을 생성하도록 하였으나 발화가 끝났는데도 생성하는 것은 time-cost가 크다.
이를 해결하기 위해 Tacotron2은 Decoding을 조기 중단 시키는 Stop Token이 생성되도록 하는 Layer를 추가하였다.
종료 조건의 확률을 계산하는 경로는 Decoder RNN으로부터 매 시점 생성된 vector를 FFN 통과시킨 후 sigmoid 함수를 취하여 0에서 1사이의 확률로 변환합니다. 이 확률이 Stop 조건에 해당하며 사용자가 설정한 threshold를 넘을 시 inference 단계에서 mel-spectrogram 생성을 멈추는 역할
def inference(self, memory):
""" Decoder inference
PARAMS
------
memory: Encoder outputs
RETURNS
-------
mel_outputs: mel outputs from the decoder
gate_outputs: gate outputs from the decoder
alignments: sequence of attention weights from the decoder
"""
decoder_input = self.get_go_frame(memory)
self.initialize_decoder_states(memory, mask=None)
mel_outputs, gate_outputs, alignments = [], [], []
while True: #free learning 모드
decoder_input = self.prenet(decoder_input)
mel_output, gate_output, alignment = self.decode(decoder_input)
mel_outputs += [mel_output.squeeze(1)]
gate_outputs += [gate_output]
alignments += [alignment]
if torch.sigmoid(gate_output.data) > self.gate_threshold:
break
elif len(mel_outputs) == self.max_decoder_steps:
print("Warning! Reached max decoder steps")
break
decoder_input = mel_output
mel_outputs, gate_outputs, alignments = self.parse_decoder_outputs(
mel_outputs, gate_outputs, alignments)
return mel_outputs, gate_outputs, alignmentsLoss
Tactron2의 경우 Decoder가 생성한 Mel-Spectrogram Frame과 실제 Label의 Mel-Spectrogram Frame간의 MSE로 Loss를 계산한다.
loss = MSE(mel_outs - mel_targets)Wavenet Vocoder
Tactron2는 Mel-Spectrogram까지만 생성하고,
생성한 Mel-Spectrogram는 따로 학습한 WaveNet의 구조를 변경한 모델을 Vocoder로 사용해 음성 신호로 변환한다.
Wavenet Vodoer 역시 Teacher Forcing으로 학습하며, Tactron2과 동일한 Data로 훈련할 때 좋은 성능을 기록한다고 합니다.
즉 Text에서 Speeech까지의 완전한 End to End의 모델은 아니다!
Tacotron1에 Wavenet Vocoder를 붙여도 괜찮은 음질이 생성된다고 한다.
Metric
TTS의 경우 정량적인 수치보다는 사람이 실제 Speech를 받아들이는게 더 중요함으로 피실험자에게 음성을 들려주고 1점에서 5점까지 0.5점씩 증가하여 점수를 매기는 mean opinion score(MOS)가 주요 평가지표로 확인된다고 한다.
 Tacotron2 MOS
Tacotron2 MOS
3. TTS Transformer
Tacotron1, Tacotron2의 경우 RNN 기반으로 Text와 Speech에 대한 정보를 생성하기 때문에 1) Stack을 쌓는 병렬처리 불가 2) Long-term dependency의 한계가 존재한다. 이를 위해 기존 Tacotron의 RNN 구조에 Transformer의 Multi-head self attention을 도입한 TTS Transformer 모델이 도입되었다.
 TTS Transformer
TTS Transformer
TTS Transformer의 장점
- 병렬처리 가능 : 속도가 Tacotron2 대비 4.25배 상승
- Long-term dependency 해결 : positional encoding + self-attention으로 거리에 제약 없이 모든 입력 벡터와의 관계 학습 가능
TTS Transformer의 한계
- 여전히 느린 Inference : Decoder에서 다음 mel-spectogram의 frame을 생성하여면 Encoder와 Attention이 필연적
- Exploration bias : Inference 과정에서의 Error propagation 해결 불가 (Tacotron과 동일)
Attention이 잘못 걸리면 아예 생성이 잘못됨으로 강의 기준으로 이를 대체할 모델 구조가 많이 탐색중이라고 한다.
작성자 : 16기 장준원
References
출처의 검색일은 모두 2021.11.10.-2021.11.13이다.

6개의 댓글

[15기 안민준]
타코트론의 prenet은 linear layer라고 하셨는데, 이 경우 이후 sequential 한 정보가 끊어지지 않나요? 이에 관해 문제가 없는지, 해결된 문제인지 듣고 싶습니다.
*Tacotron2 에서 Location Sensitive Attention이 Monotonic 하게 증가하는 부분을 잘 설명해 주신 점이 좋았습니다ㅎㅎ

[15기 조효원]
- Transformer TTS에서 Text-to-phone converter가 있는데, 혹시 어떤 식으로 이루어는지 궁금합니다.

[15기 이성범]
-
Text의 경우 글의 맥락을 모델이 학습할 수 있어야 하기 때문에, 비선형성을 활용할 수 있는 Deep Learning을 활용해 End to End 구조로 TTS Task을 해결하고자 함
-
음성은 sequential한 data이기 때문에 RNN계열의 모델들이 많이 활용됨
-
Tacotron1
- Tacotron1은 Encoder, Attention-based Decoder, Post-processing Net으로 이루어짐
- Encoder는 Embedding Layer, Pre-net, CHBG로 이루어져 있고, Embedding Layer는 기존에 이미 구해진 Text의 임베딩을 불러와 사용하고, Pre-net은 Linear Layer로 Encoder의 Input과 Decoder의 Input에서 일종의 정보를 filtering하는 역할을 하고, CHBG는 1D Convolution Bank, Highway 네트워크, 그리고 Bidirectional GRU로 이루어져 있다.
- Attention-based Decoder에 인풋으로 전 time-step에서 생성한 Mel-Spectrogram의 마지막 Frame을 넣어주고, 그 후에 Pre-net을 거치고, Attention RNN을 거친 후에 Encoder에서 설명한 CHBG를 활용해 Mel-Spectrogram으로부터 Linear-Spectrogram을 생성한다.
- 그 후에 Griffin-Lim Algorithm이라는 음성 재구성 알고리즘을 통해서 음성으로 변환해주는데, 해당 알고리즘은 Filter들을 바탕으로 Waveform을 만들어주는 rule-based 방법이다.
-
Tacotron2
- 기존 Tacotron1의 한계점을 극복하기 위해 제안된 모델이다.
- Tacotron1에서 사용되는 CHBG가 단순 1D ConvNorm(1d convolution layer + batch norm)로 바뀌었다.
- TTS의 경우 현재 음성의 발음이 Input text의 sequential한 순서대로 진행이 되어야 하기 때문에 Attention이 Sequential하게 거르기 위한 방식으로 적용되어야 한다. 이에 단순한 Additive attention mechanism(Bandau Attetnion)에 attention alignment 정보를 추가한 형태의 Attention을 진행하였다.
- Tactron2는 Mel-Spectrogram까지만 생성하고, 생성한 Mel-Spectrogram는 따로 학습한 WaveNet의 구조를 변경한 모델을 Vocoder로 사용해 음성 신호로 변환한다.
-
TTS Transformer
- Tacotron1, Tacotron2의 경우 RNN 기반으로 Text와 Speech에 대한 정보를 생성하기 때문에 1) Stack을 쌓는 병렬처리 불가 2) Long-term dependency의 한계가 존재, 이를 위해 기존 Tacotron의 RNN 구조에 Transformer의 Multi-head self attention을 도입한 TTS Transformer 모델이 도입
- TTS Transformer의 장점은 병렬처리 가능, Long-term dependency을 해결했다는 것이다.
- TTS Transformer의 한계는 여전히 느린 Inference와 Exploration bias를 가진다는 것이다.
[15기 황보진경]
이번 강의는 딥러닝 기반의 End-to-End TTS에 대해 설명한다. 초기에는 DNN, LSTM 등의 방법이 제안되었으며, 이후에 Tacotron, Transformer TTS 등이 제안되었다. TTS에서는 MOS(Mean Opinion Score)가 평가지표로 사용된다.
[Tacotron1]
먼저 text input은 linear layer인 Prenet을 거쳐 input이 filtering된다. 이후 CHBG(1d Convolutional Bank + Highway network+ biderectional GRU)를 거쳐 생성된 sequence를 attention에 사용한다. 이 때, residual connection은 wighted sum 형태인 highway network의 구조를 띄고 있다.
Mel-spectrogram을 input으로 사용한다. text와 mel-spectrogram을 정렬하는 Attention RNN, 순차적인 관계를 학습하는 Uni-directional RNN, CHBG를 거치면 linear spectrogram이 만들어진다. 이를 Griffin-Lim 알고리즘을 통해 waveform 형태로 바꿀 수 있다.
[Tacotron2]
Tacotron2의 단점을 개선하기 위해 제안된 모델이다. 먼저, CHBG과 1d convoution layer + batch normalization으로 대체되었다. 또한, sequential attention을 추가하였으며, 효율성을 위해 stop token이 추가되었다.
이후에는 wavenet vocoder를 사용하여 speech synthesis를 진행한다.
[TTS Transformer]
병렬처리가 불가능하고, Long-term dependency의 한계를 극복하기 위해 TTS Transformer가 제안되었다. 인코더-디코더 모델을 차용하고 있으며, RNN 대신에 Multi-head self attention을 사용한다.