[5주차] MUSIC COMPOSITION WITH DEEP LEARNING: A REVIEW
MUSIC COMPOSITION WITH DEEP LEARNING: A REVIEW
작성자 : 15기 안민준
본 리뷰는 투빅스 15&16기 음성 세미나에서 동명의 논문의 내용을 정리하고 공유하기 위해 만들었습니다.
출처가 적혀 있지 않은 이미지는 모두 본 논문에 수록된 이미지입니다.
Abstract
- 본 논문은 AI의 음악 작곡과 인간의 음악 작곡과 창작 과정을 연결하는 관계를 찾는 것을 목표로 한다.
- 딥 러닝 기반의 최신 음악 작곡 과정, 이론적인 음악 작곡, 인공지능의 창의성과 인관과 인공지능의 작곡 유사성에 관한 질문 등 다양한 부분을 수록하였다.
Introduction
- 음악 : 피치와 리듬의 반복
- 음악 작곡 : 새로운 음악 부분을 만들어 내는 과정 => 창의성이 필요함
- 음악 작곡 영역은 MIR 부분에서 중요한 요소임
- 음악 작곡의 분야:
- 멜로디 생성
- 멀티트랙(다중악기) 생성
- Style transfer
- Harmonization
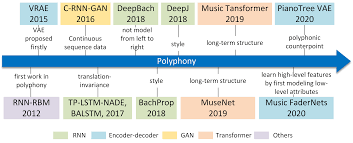
From Algorithmic Composition to Deep Learning
음악 작곡 인공지능의 발전 역사에 대해서 서술하고 있다.
크게 알고리즘 중심적인 방법과 신경망 중심적인 방법으로 나눠서 설명한다.
알고리즘적 방법
- 1980년대 Experiments in Musical Intelligence (EMI) (David Cope)
- 2000년대 Marcov chain 과 음악 문법의 조합 (by David Cope), Project1(PR1) (by Koening)
DNN을 사용한 방법
- Harmonize Melodies를 다양한 스타일로 생성 가능하나, 일반화 & 음악 문법에서 단점
- 1980~2000년대 처음 신경망을 사용한 모델이 등장
- 최근, 딥러닝을 사용한 모델이 등장하기 시작함
- CV나 NLP 부분의 모델을 전이학습 시키는 방법이 사용 => 음악을 하나의 언어로 이해할 수 있다.
Neural Network Architectures for Music Composition with Deep Learning
크게 VAE, GAN, LSTM/Transformer 를 사용한 방법으로 구성된다.
Variational Auto-Encoders (VAEs)

- Encoder-Decoder 구조
- latent space 를 생성하는 방법으로 사용
- 오토인코더에 대한 자세한 설명은 여기서 확인
Generative Adversarial Networks (GANs)
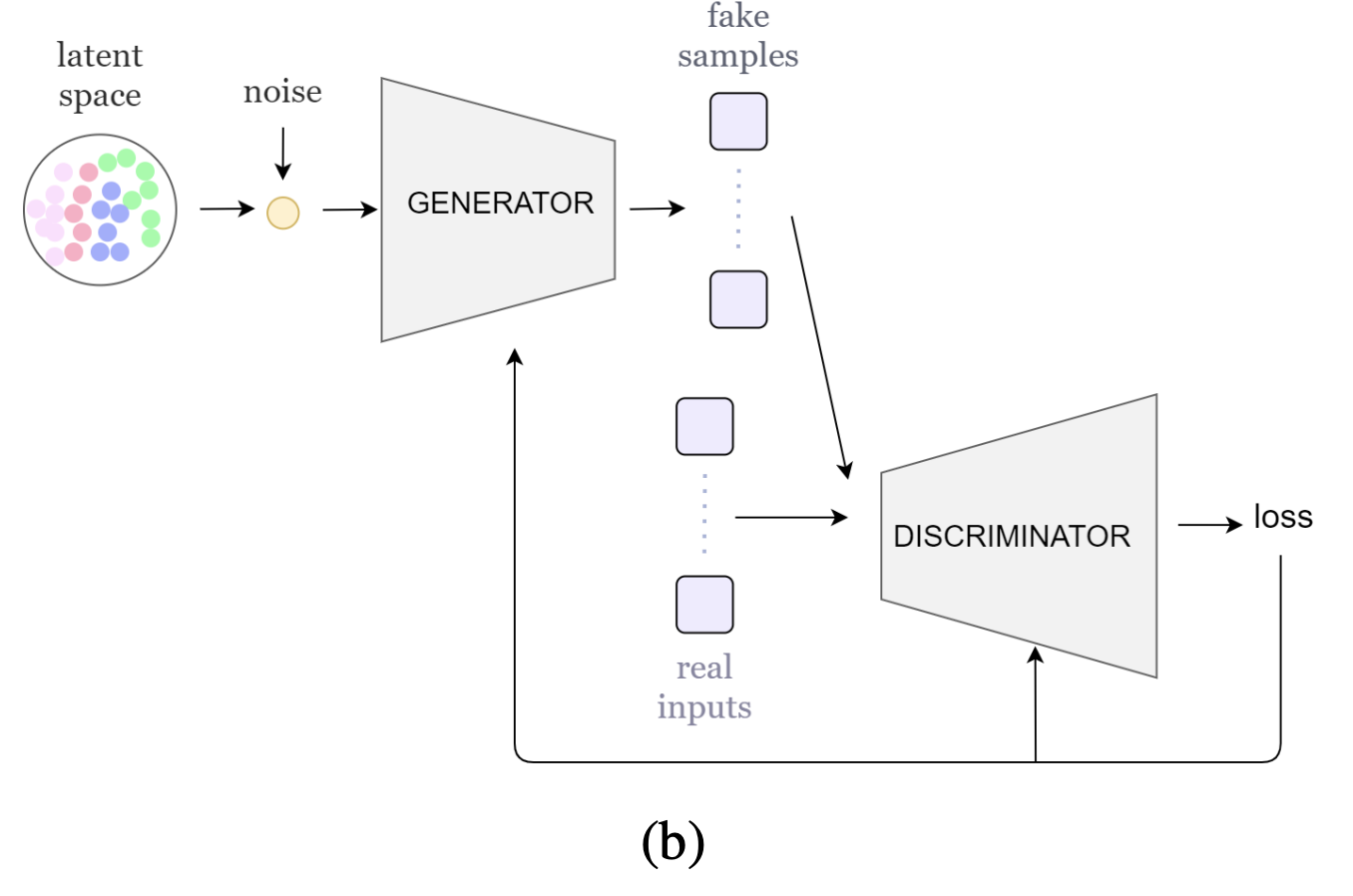
- Generator , Discriminator 로 구분된 네트워크
- 생성자는 입력 데이터의 확률 분포 를 학습하며, 구분자는 구분할 수 있는 확률을 높이는 것을 목표로 한다.
- 생성자와 구분자는 MLP나 LSTM, CNN 으로도 구성될 수 있다.
Transformers
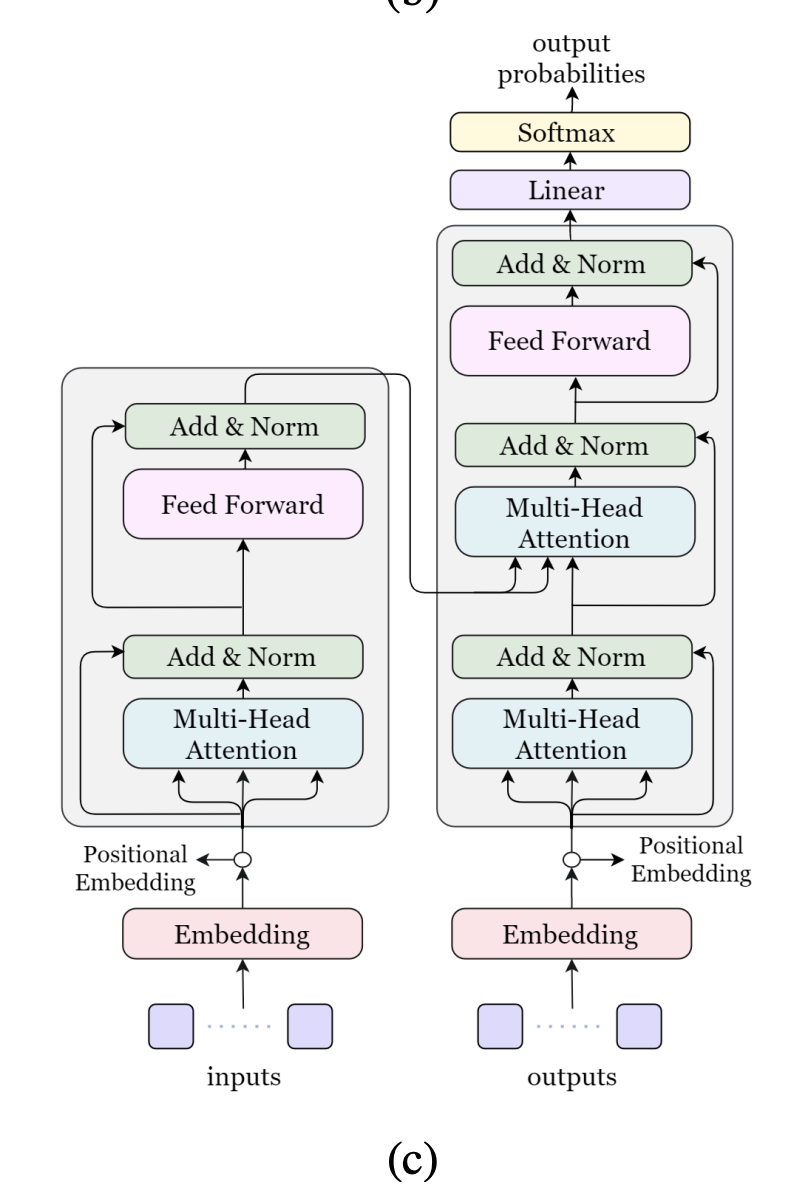
- LSTM 등과 같은 Auto-regressive 모델에도 사용할 수 있다.
- Attention 메커니즘이 핵심
- 인코더와 디코더에 Attention 을 연결시켜서 작동하는 방식
The Music Composition Process
본 논문은 음악 작곡이 사람이 글을 쓰거나 말을 하는 것과 비슷하다고 설명하며, 아래와 같은 특징을 가진다고 설명한다.
- 음악 작곡 방식의 차이
- 클래식 음악 : motif 를 멜로디나 music phrase 로 발전시킴
- pop/jazz : 코드 진행을 즉흥 연주, 작곡을 사용해 멜로디로 발전
- 두 가지 부분으로 구성됨
- 멜로디 (melodic part)
- 반주(accompaniment part)
- 다양한 악기들 (다른 주파수 특징을 가짐)을 기악(Instrumentation)과 편곡(Orchestration) 을 사용해서 쌓는다.
- 음악의 두 가지 특징
- 시간(리듬)
- 이미지의 가로축과 비슷
- 음악의 구조와 연관
- 저레벨 : Notes(음)
- 고레벨 : sections (섹선)
- 화음
- 이미지의 세로축과 비슷
- 노트, 피치, 코드 등 화성(harmony)의 구성을 담당한다.
- 저레벨 : 노트(note) 단위
- 고레벨 : 코드
- 코드의 연속 : 코드 진행 (chord progression)
- 시간(리듬)
기본적인 음악의 구성 요소

- Harmony(화성) : 노트 -> 화성 -> 코드 -> 진행
- Music Form or Structure : 모티프 -> 프레이즈 -> 섹션 -> 작곡(섹션의 구성)
- Melody and Texture
- 텍스쳐 : 음악의 소재가 하나의 작품으로 결합된 것
- 멜로디 : 단선율, 다선율의 노트들
- Instrumentation(기악) and Orchestration(편곡)
- 기악은 악기 조합에 초점을 맞춘다. Track 단위
- 편곡은 멜로디의 배분에 초점을 맞춘다.
이외에도 Dynamic(다이내믹) 부분이 있지만, 작곡보단 연주에 더 집중된 부분이므로 본 논문에선 다루지 않는다.
Melody Generation

Deep Learning Models for Melody Generation: From Motifs to Melodic Phrases
- 일반적으로 음악을 작곡할 때는 모티프나 코드 진행을 작곡하고, 프레이즈나 멜로디로 발전시킴
- 초기 딥 러닝 모델은 모티프를 작곡하는 시도를 했으며, 이후 더 긴 음악을 작곡하고자 함
- 이후 창의성을 향상시키기 위해 생성 모델 도입. (현재 MusicVAE가 가장 좋은 성능을 냄)
- Lakh 데이터셋을 사용해 학습 (1.5백만개의 곡이나 있다..)
- Music Transformer, MuseNet 등과 같은 Transformer 모델이 후에 등장하여 더 긴 멜로디를 생성할 수 있었다.
- 아예 긴 멜로디를 생성하려 하면 이전 시간과 상관 없이 랜덤하게 생성됨
- TransformerVAE, Piano Tree와 같은 모델을 섞는 경우도 나타나기 시작 : 더 긴 멜로디를 생성할 수 있음
- 최근 가장 성능이 좋은 모델은 Denoising Diffusion Probabilistic Models(DDPMs)을 기반으로 한 모델. 64 마디의 곡 생성 가능
Structure Awareness
- 멜로디가 뭉쳐 섹션이 된다.
- 섹션은 음악 장르에 따라 다양한 이름을 가짐
- 팝&트랩 : Chorus, verse
- 클래식 : Exposition, development, recapitulation
- ABAB등으로 쓰이기도 함
- 짜임새 있는 음악을 만드는 것은 어려운 작업이다.
- Self-Similarity 제약조건을 사용하여 만드려는 시도 (Convolutional Restricted Boltzmann Machine - C-RBM 을 사용한 시도 등) 가 있었음 - 템플릿을 정해놓고 학습 및 생성을 실행함
- 최근엔 템플릿 없이 생성하려는 시도를 하고 있음.
Harmony and Melody Conditioning
- Transformer 모델에서 다선율의 멜로디를 작곡할 수 있음
- 만들어진 멜로디에 화성을 붙이는 작업은 HMM에서 RNN으로 넘어가는 중
- Multi-Track accompaniment에 대해선 GAN 기반 생성 모델이 우세. (MICA 등)
- 인간과 같이 코드 반주에서 멜로디를 만들어 내는 모델, ChordAL과 같이 End-to-End 모델 등 다양한 모델 또한 시도 중
Genre Transformation with Style Transfer
- 스타일 변환 : 존재하는 음의 피치를 올리거나, 새로운 악기를 추가하거나 하는 방식의 style transfer
- 스타일의 임베딩 벡터를 구하고, 이를 사용해 변환을 수행
- Style Transfer 의 아이디어가 적용되어서 MIDI-VAE 등이 나타남
- Transfer Learning을 사용해서 적용 가능 (예를 들어 jazz 데이터셋으로 학습한 뒤 다른 데이터셋으로 미세조정 실시)
- 하모니와 텍스처도 종종 연구되기도 한다.
Instrumentation and Orchestration
기악과 편곡(Instrumentation and Orchestration) 은 음악 장르에 있어서 기본적인 요소이며 작곡가의 특징을 나타낸다. 기악(Instrumentation)은 비슷한 악기들을 앙상블을 만들기 위해 조합하는 방법을 나타내며, 편곡(Orchestration)은 비슷하거나 다르게 작성된 섹션을 선택 및 조합하는 것이다.
From Polyphonic to Multi-Instrument Music Generation

- 현존하는 딥 러닝 기반 모델들은 컴퓨터 음악이 사용하는 Multi-Track 부분에 적합하지 않다.
- 생성한 트랙들이 같은 화성을 따라가야 하는데 그러지 않음 (음색과 화음을 고려하지 않는다)
- 현재 해결에 많은 어려움을 겪는 중
Multi-Instrument Generation from Scratch
-
예전엔 드럼 - 멜로디 생성 모델들이 종종 있었음
-
GAN과 VAE를 사용해서 주로 생성함
- MuseGAN
- MusAE
-
Transformer를 사용하기도 함 (MusicTransformer, LakhNES)
-
Conditional Multi-Track Music Generation Model(MMM)

- 노트를 지우고 복원하는 방법을 통해(BarFill) 학습
- 단일 트랙을 합쳐서 음악을 생성하는 방식
-
이 방식들은 기악과 편곡에는 적합하지 않음
- 다른 트랙들의 특징 (Key 등..) 을 파악하기 어려움
- 악기의 수를 정하거나 높은 질의 멜로디 작곡을 하기 어려움
Evalutaion and Metrics
딥 러닝 작곡 모델의 평가 방법은 객관적인 방법과 주관적인 방법이 모두 존재한다. 특히 음악 작곡은 '창의성'의 영역을 측정해야 하기 때문에 주관적인 방법이 중요하다. 객관적인 방법은 모델의 결과의 질을 정량화하는데 도움이 된다.
Objective Evaluation
- 모델의 성능 측정에 다음 지표를 사용한다
- perplexity, BLEU, precision, recall, F-score, loss(?)
- 음악적인 요소를 가미한 지표들도 있다.
- Pitch-related, Rhythm-related, Harmony-related, Style Transfer-related (Ji et al.)
Subjective Evaluation
- 음악의 창의성, 참신성 부분을 평가함
- 가장 많이 사용되는 방법 : 사람이 듣고 작곡가가 누구인지 맞추는 방식
- Side-by-side rating : 스코어 기반의 방식
- 평가하는 사람의 구성 특징을 잘 생각해야 함
- 많이 들을수록 피로가 쌓이는 것을 감안해야함
Discussion
Are the current DL models capable of generating music with a certain level of creativity?
MusicVAE의 경우에는 긴 음악을 생성할 수 있으나, 음악의 리듬과 같은 패턴을 인식하지 못하는 것 같은 모습을 보인다.
What is the best NN architecture to perform music composition with DL?
더 긴 시계열을 만들기 위해 Transformer 구조가 도입되었다.
VAE, GAN의 경우 스타일과 같은 고레벨 특징들을 추출할 수 있는 특징이 있다.
따라서 Best를 구하기는 어렵다.
Could end-to-end moethods generate entire structured music pieces?
아직까지 완전한 구조를 만들 수 있는 모델은 존재하지 않는다.
조만간 가능해질 것으로 보이긴 한다.
하지만 작곡 AI가 사람을 돕는 분야로 발전할지, 혼자 작곡을 다 하는 쪽으로 발전할지는 두고 봐야 할 문제로 보인다.
Are the composed pieces with DL just an imitataion of the inputs or can NNs generate new music in styles that are not present in the training data?
지금까지 제작된 인공지능으로 볼 때 표절이나 모방이 아닌 것으로 확인되었다.
음악 표절은 악기, 리듬, 톤 등 많은 요소들이 있어서 쉽게 일어나기 어렵다.
Should NNs compose music by following the same logic and process as humans do?
Auto Regression 모델에서 유사성이 보인다.
How much data do DL models for music generation need?
엄청 많은 음악 데이터가 필요하다.
하지만 최신 모델들의 경우는 텍스트 등 다른 영역에서 pre-trained 된 모델을 가져 와서 전이학습 하는 방법으로 데이터 부족 문제를 해결했다.
Are current evaluation methods good enough to compare and measure the creativity of the composed music?
음악의 창의성과 NN의 특징 들 모두를 고려하는 평가 지표가 필요하다.
Conclusions and Future Work
이 논문에서 DL을 사용한 음악 생성 모델을 살펴보고, 이 분야에서 필요한 몇 가지 질문들을 알아보았다.
본 논문에서 이야기하는 미래 연구 방향은 다음과 같다.
- 더 긴 음악 시퀀스 생성
- Human-AI interaction
- 데이터셋의 편향 해결
- 더 높은 생상성
본 논문을 넘어서는 고민 방향성
- 인공지능이 작곡한 음악의 저작권은?
- 어떤 부분에서 다른 작곡가와 차별화를 둘 수 있을까?

3개의 댓글

[15기 황보진경]
본 강의에서는 딥러닝 기반의 음악 작곡에 대해서 다루었다. 음악 작곡에 사용되는 딥러닝 구조는 크게 세가지가 있다.
1. VAE: Encoder를 이용하여 latent space로 mapping하고, decoder를 사용하여 원본을 재생성하는 구조로 학습한다.
2. GAN: 생성자가 입력 데이터의 분포를 학습하고, 구분자는 생성된 샘플과 진짜 샘플을 구분하도록 경쟁적으로 학습한다.
3. LSTM / Transformer: Auto-regressive model이나 attention mechanism을 적용한다.
멜로디 작곡
초기에는 모티프를 작곡하였으며,더 길고 좋은 성능의 작곡을 위해 Music VAE, Music Transformer, MuseNet 등이 등장하였다. 이 외에도 템플릿 등을 사용하여 구조적으로 안정된 음악을 만들고자 하는 시도가 있었다. 혹은 다선율의 멜로디나 화성을 위해 GAN 등의 모델들이 등장하였다. 음악의 스타일이나 장르를 바꾸기 위해 Style Transfer의 아이디어를 차용한 MIDI-VAE 등이 나타났다.
기악과 편곡
다양한 악기로 이뤄진 음악을 생성하기 위해 MuseGAN, MusAE 등이 등장했다. 노트를 지우고 복원하거나 단일 트랙을 합쳐서 음악을 생성하는 방식을 사용한다.
Evaluation & Metrics
정량적인 방법으로는 perplexity, BLEU, recall, F-score 등의 지표를 사용하고 때에 따라 피치나 리듬 등의 음악적 요소를 고려한 지표들도 등장하였다.
정성적인 방법으로는 주로 사람이 듣고 스코어를 매기는 방식을 사용한다.
음악 생성 모델로 소개된 것들의 거의 텍스트 생성 모델들을 변형한 형태인 부분이 흥미로웠습니다. 논문에서는 gpt2 등의 pretrained 모델을 전이학습시키는 경우에 대해서도 이야기가 나왔는데 이런 모델들은 multitrack 음악을 input으로 받을 수 없는지가 궁금합니다. 한 문장의 질문이 tokenized 되어 들어가는 것과 달리 다양한 소리가 섞인 음악은 어떤 식으로 모델에 들어가게 될까요?