[5주차] SLU survey
작성자: 투빅스 15기 조효원
Background
인간의 언어를 처리하는 모든 딥러닝 연구들의 최종적인 목표는 사람에 버금가는, 다른 말로는 "사람과 자유롭게 소통이 가능한 artificial agent"를 만드는 것이다. 즉, 음성 언어 처리의 궁극적 목표는 음성 대화 처리라고 할 수 있다.
자유롭게 소통하기 위해서는, 첫째로 말을 잘 해석해야 하고, 둘째로 맥락에 맞는 적절한 반응을 보여야 한다. 즉, 말의 이해가 모든 의사소통의 전제가 된다. 이때 말을 이해한다는 것은 말의 내용과 의도 뿐만 아니라, 전제, 함축 등까지 파악하는 것을 의미한다.
연구자들은 인간의 청지각 과정을 활용해 Spoken Language Understanding Model을 만들어왔다. 따라서, 우리의 첫 번째 스텝은 인간이 어떠한 과정을 통해 말을 이해하는지를 파악하는 것이다.
인간의 청지각 과정과 모델링
청지각 과정

인간의 청지각 과정은 다음과 같이 이루어진다. 먼저, 사람의 말을 통해 생성된 Acoustic Wave가 귀를 통해 들어온다. 들어온 음성은 달팽이관의 기저막을 진동시키며, 기저막에 연결된 청각 신경들은 이 진동에 따른 신호들을 신경 충격파의 형태로 변환해 뇌로 전달한다. 뇌에서는 해당 정보를 우리가 알고 있는 언어의 형태로 바꾸고, 최종적으로 그것이 무슨 의미를 가졌는지 이해한다. 이해가 끝나면, 맥락에 맞는 올바른 행동 혹은 발화를 한다.
청지각 모델링
이를 모델링하면 다음과 같다.

-
Endpointing
음성입력은 silence+signal+silence의 형태를 가지고 있다. 따라서, 끝점검출기를 통해 언제 signal이 시작되고 끝나는지 파악해 signal만을 추출한다. -
Feature Extraction (Neural Transduction)
특징 벡터열로 변환하는 과정을 의미한다. 딥러닝 모델의 입력값으로 변환해준다고 생각하면 된다. -
Recognition
음성을 텍스트로 전환하는 부분으로, ASR이라고 생각하면 된다. 특징 벡터열을 입력으로 받아서 단어열 혹은 문장을 답으로 제시한다. -
Natual Language Understanding
음성인식기의 출력인 단어열을 입력으로 받아 의미를 파악하는 과정을 의미한다. 일반적으로 slot-and-filling 표현 방식을 사용한다. -
Dialogue Management
언어모델에서 추출된 입력 문장의 의미를 바탕으로 대화 의미를 파악하여 주어진 Task를 수행하기에 적절한 판단을 내리고 system action을 생성한다.
Spoken Language Understanding (SLU)
머신러닝에서의 SLU는 청지각모델에서의 NLU 모듈까지를 대상으로 한다.
더 정확하게 Spoken Language Understanding(SLU)이란 음성 입력의 의도를 맞추는 태스크를 가리킨다. 예를 들어, ”I want to listen to Hey Jude by The Beatles”이라는 입력 문장이 들어왔을 때, 발화자의 의도는 노래를 틀라고 요청한 것이며, 그 노래의 제목은 Hey Jude, 가수는 The Beatles라는 정보를 찾아내야 한다.
이러한 방식으로 문장의 의미를 표현한 것을 semantic-frame structure라고 한다.
Frame이란 의미의 단위 중 하나인데, 하나의 상황을 의미적으로 표현하는 것을 의미한다. Frame은 부가적인 정보를 제공하는 element와 함께한다.

Semantic Frame Structure로 표현한다는 것은 2가지를 찾는 것을 의미한다.
1. Intent classification (IC)
identifying the correct frame
2. Slot Filling (SF)
filling the correct value for the slots(elements) of the frame

즉, 정리하자면, SLU는 음성 입력의 인텐트를 맞추고 내용을 구조화하는 태스크라 할 수 있다.
Approaches
음성 언어 처리의 접근법은 크게 두 가지로 나누어진다.
1. Cascaded 접근법 (Conventional)
- independent
- joint
2. End-to-End 접근법

Cascaded Approach
Cascaded 접근법은 여러 관련된 모델들을 순차적으로 잇는 방법으로, 위에서 언급한 SLU의 청지각 모델링을 그대로 따른다. 따라서, 사용자 발화를 텍스트로 옮기는 ASR(Automatic Speech Recognition)이 우선 실행된 뒤에, 사용자 발화에 담긴 인텐트를 파악한다.
ASR 모델은 말 그대로 소리 신호를 텍스트 데이터로 변환한다. 즉, 다루기 어렵고 복잡한 음성 신호의 영역을 단순 텍스트의 문제로 치환하는 것이다. 따라서, Cascased 모델들은 사실상 음성 모델이라기보다는 언어 모델에 가깝다. 실제로, 대부분의 모델들이 NLU 태스크에 집중한다. SF와 IC를 위해 RNN-based models(Mesnil et al., 2013), attention-based models(Liu and Lane, 2016), transformers models (Chen et al., 2019) 등이 이용되어 왔다. 즉, 우리가 알고 있는 언어 모델들을 사용한다. 앞서 SLU는 2가지 태스크(intent classification & slot filling)를 목적으로 한다고 했는데, 이 둘을 각각 학습 시키는 것을 independent model, 둘을 함께 고려하여 상호적으로 발전, 맞추게 하는 것이 joint model이다.
Cascaded 접근법은 크게 2가지의 장점을 가진다.
1. 첫째, 가용 데이터가 풍부하다 (data availability).
ASR, NLU 모두 연구가 많이 진행된 분야들이며, 구축된 데이터셋도 많다. 각 분야들 모두 해당 태스크를 수행하기 위한 모델의 성능을 높히기 위해 다양한 이론과 알고리즘이 있으며, 각각의 성능도 뛰어나다. 딥러닝은 기본적으로 데이터에 의존하는 모델 학습법이기 때문에 데이터가 많다는 것은 큰 이점이다.
2. 둘째, modular system이기 때문에 새로운 모델이 나오면 교체가 쉽다.
각각이 독립적이기 때문에 새로운 모델이 나오면 더 좋은 성능을 내는 모델을 쉽게 적용할 수 있다.
큰 장점을 가지는 Cascaded 접근법이지만, 여러가지 치명적인 문제들이 존재한다.
1. Cost/Complexity가 높다.
언제나 두 개의 모델(ASR, LM)를 학습시키고, 따로 최적화를 시켜야 하기 때문에 비용이 높다.
2. 선행 모델의 에러가 계속해서 이어진다 (error propagation)
ASR 모델의 성능이 높다고는 하지만, 여전히 에러가 있다. 이를 위해 1) 에러를 무시, 2) n개의 후보군을 뽑아서 선택, 3) 언어 모델을 에러에 견고하게 만들기 등의 해결방안이 제시되었지만, 여전히 완벽한 해결책은 제시되지 않았다.
End2End Approach
End2End 모델은 원시 음성을 입력 받아 ASR(Automatic Speech Recognition) 도움 없이 해당 음성의 인텐트를 파악한다.
사실 IWSLT 2018 evalution에서, Cascaded 모델들보다 성능이 두드러지게 나쁘기에 많은 발전히 필요하다고 보고했었다. 성능이 나쁜 이유를 생각해보면:
- 데이터의 부족
(source audio, target text)의 쌍으로 이루어진 코퍼스의 수는 절대적으로 부족하며, 당연하게도 MT나 ASR 단독의 학습을 위해 구축된 데이터셋보다 적다. 충분한 훈련 데이터가 필요한 딥러닝 모델의 특성상, 데이터의 부족은 치명적인 문제이다. - SRC audio input과 TRG text 시퀀스를 매핑하는 것의 어려움
Cascaded 모델에서는 source transcript가 intermedia가 되어 둘 사이를 이어주는 징검다리 역할을 했다. Google이 단순히 음성->인텐트로 학습시키는 것보다 intermedia의 존재가 성능을 크게 향상시킨다는 연구를 발표한 후, 다른 E2E 연구에서도 intermedia의 필요성을 느끼고 text에 다시 관심을 기울인다. 즉, 또 다시 2-stage NN model로 회귀한 것이다.
다른 점은, NLU 과정에서 src text -> trg text로 변환하는 decoder와 encoder의 정보를 활용하는 방식이다. Source language decoder의 hidden state에 어텐션을 주는 모델도 있고, Source Audio와 Source text 모두에 어텝션을 주는 모델도 있다. 혹은, 어려운 결정들은 피하도록 context vector만을 공유하는 모델도 존재한다. 주 초점은 또 다시 2-stage로 돌아갔다는 것이며 괜찮은 좋은 성능을 보이고 있다는 것이다.
대략적인 SLU의 outline이 잡혔으면, 2 stage로 돌아간 후 2020년에 발표된 모델이 꽤나 좋은 성능을 가진다고 하기에 소개하려 한다. Speech Model Pre-training for End-to-End Spoken Language Understanding.
본격적으로 모델에 대한 설명을 하기 이전에, 이해에 필요한 2가지 모델들을 우선 설명한다. 첫 번째는 데이터를 구축하는데 사용한 Montreal Forced Aligner(mfa)이며, 두 번째는 모델링 과정에서 사용한 SincNet이다.
1. Montreal Forced Aligner
음성정렬에 대한 개념은 이전에 CTC를 배우면서 이해했을 것이다.
Montreal Forced Aligner (mfa)는 Hidden Markov Model을 기반으로 강제 정렬을 해주는 모델로, Kaldi ASR toolkit을 이용해 3가지 stage를 거치면서 학습을 진행한다.
- Mononphone model
음운 컨텍스트에 관계없이 각 음소가 동일하게 모델링 - Triphone model
음소 양쪽의 컨텍스트를 고려하여 모델링 - MFCC
발화자의 차이를 고려하여 트라이폰 모델을 향상시키고 각 발화자에 대한 MFCC 계산.
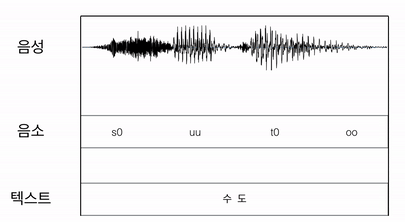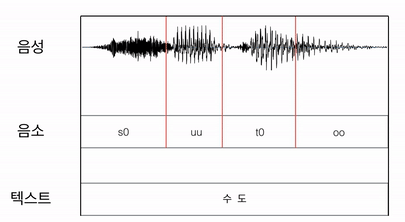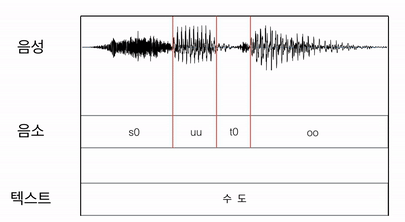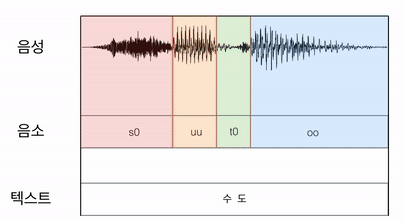
보다 자세히 설명해보면, 우선 음소가 적힌 텍스트와 음성 파일을 나란히 두고 균일하게 음성파일을 나누어서 음소파일과 매칭시킨다. 이후 EM(Expectation and Maximization) 알고리즘을 이용해서 각 음소가 차지하는 영역을 계산하며 매칭 된 길이를 수정해 나간다.
이때 monophone model에서는 단순하게 하나의 음소를 찾아낸 경계를 triphone model에서 수정해나가는 방식으로 학습을 진행한다.
이에 따른 결과물은 다음과 같다.
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0 xmax = 7.230000
tiers? <exists>
size = 2
item []:
item [1]:
class = "IntervalTier"
name = "word"
xim = 0
xmax = 7.230000
intervals: size = 18
intervals [1]:
xmin = 0.000000
xmax = 0.530000
text = "<SIL>"
intervals [2]:
xmin = 0.540000
xmax = 0.880000
text = "대만"
intervals [3]:
xmin = 0.890000
xmax = 0.930000
text = "이"
intervals [4]:
xmin = 0.940000
xmax = 1.290000
text = "그"
item [2]:
class = "IntervalTier"
name = "phoneme"
xim = 0
xmax = 7.230000
intervals: size = 80
intervals [1]:
xmin = 0.000000
xmax = 0.530000
text = "sil"
intervals [2]:
xmin = 0.540000
xmax = 0.610000
text = "d"
intervals [3]:
xmin = 0.620000
xmax = 0.680000
text = "e"
intervals [4]:
xmin = 0.690000
xmax = 0.750000
text = "m"TextGrid 파일을 다룰 때 pip install textgrid로 라이브러리를 받아서 사용하면 편하다!
2. SincNet
싱크넷(sincnet)은 단순하게 컨볼루션 필터가 싱크 함수인 1D conv이다.
SincNet을 이용하면 보다 빠르고 가벼우면서도 정확하게 음성의 피쳐를 추출할 수 있다. 구조를 살펴보면 다음과 같다.

위의 레이어들은 사실 다른 모델들과 크게 다른 점이 없다. 발화자가 누구인지 맞추는 과정을 통해서 가중치들을 수정/학습해나간다 정도만 이해하면 된다. 중요한 것은 첫 번째의 sinc 함수가 적용된 conv filter이다. 각 필터들은 원시 음성에서 우리의 태스크인, 발화자가 누구인지 맞추기 위해 중요하다고 판단되는 주파수 영역대의 정보를 추출해 상위 레이어로 보낸다.
즉, 우리가 SincNet을 이해하기 위해서는 1) time-domain에서 convolution 연산이 어떻게 진행되는지 2) sinc 함수가 무엇인지를 알아야 한다.
time-domain에서 convolution 연산
시간 도메인에서의 컨볼루션 연산의 정의는 다음과 같다.
x[n] 은 시간 도메인에서의 n 번째 raw wave sample, h[n] 은 컨볼루션 필터(filter, 1D 벡터)의 n 번째 요소값, y[n] 은 컨볼루션 수행 결과의 n 번째 값, L 은 필터의 길이(length)를 나타낸다.
예를 들어서 y[1]에 대한 수행 결과는 다음과 같다.

즉, 컨볼루션 연산 결과물인 y 는 입력 시그널 x 와 그에 곱해진 컨볼루션 필터 h 와의 관련성이 높을 수록 커진다. 컨볼루션의 형태에 따라서 어떤 입력값을 완전히 없애버릴수도 있다. 다시 말해 컨볼루션 필터는 특정 주파수 성분을 입력 신호에서 부각하거나 감쇄시킨다는 것.
그런데, 여기서 우리가 집중해야할 것은 시간(time) 도메인에서의 convolution 연산을 주파수(frequency) 도메인에서의 곱셈 연산과 동일하게 취급할 수 있다는 것이다.
이게 무슨 말인가 보면,

time domain의 가운데가 conv라고 가정했을 때, 저런 형태의 conv filter는 입력값을 그대로 반환하게 될 것이다. 그런데, 이와 유사하게 freq 영역에서도 같은 값을 반환하게끔 하는 곱셈 연산이 존재.

다음 예시를 보면, 밑의 그림과 같이 직사각형의 형태를 가지는 함수(구형 함수)를 주파수 도메인에서 입력 신호와 곱하면, f1 과 f2 사이의 주파수만 남고 나머지는 없어질 것이다. 이때 우리는 이에 시간 도메인에서 컨볼루션 연산을 수행한 결과와 대응시킬 수 았다. 그리고 이 때 컨볼루션에서 사용하는 함수가 싱크 함수(sinc function)이다.
Sinc function
태스크를 더 정확하게 수행하기 위해서는 Bandpass filter를 거쳐야 한다. 이는 앞서 언급했듯이 특정 주파수 영역대만 남기는 역할을 하는 함수이다. 그리고 당연하게도, 특정 주파수 영역대를 뽑아내는 것이기에 가장 이상적인 필터의 모양은 직사각형이다.

이때 우리는 주파수 도메인과 시간 도메인을 매핑해줄 수 있다. 바로 싱크 함수(Sinc function)를 통해서다.
주파수(frequency) 도메인에서 구형 함수(Rectangular function)으로 곱셈 연산을 수행한 결과는 시간(time) 도메인에서 싱크 함수로 컨볼루션 연산을 적용한 것과 동치이다.

구형 함수는 위와 같고, 싱크 함수는 를 로 나눈 것이다. . 둘은 서로 변환이 가능한데, 싱크 함수를 푸리에 변환(Fourier Transform)한 결과는 구형 함수가 되며, 이 구형 함수를 역푸리에 변환(Inverse Fourier Transform)하면 다시 싱크 함수가 된다. 즉, 두 함수는 푸리에 변환을 매개로 한 쌍을 이루고 있다는 이야기.

그 역도 성립한다. 구형 함수를 푸리에 변환한 결과는 싱크 함수가 된다. 이 싱크 함수를 역푸리에 변환을 하면 다시 구형 함수가 된다.

그런데, 문제는 싱크 함수를 통해 완전한 구형 함수를 얻어내려면 싱크 함수의 길이 이 무한해야 한다는 것이다. 이는 현실적으로 가능하지 않으므로 싱크함수를 유한한 길이로 자르는 과정이 포함된다. 길이별 비교는 다음과 같다.

보면 알겠지만 우리가 바라던 이상적인 모양인 사각형과 점점 달라지기에 원하는 주파수 정보는 덜 얻게 되고 필요없는 정보들이 자꾸 추가된다. 이 때문에, 단순히 특정 길이로 자는 것이 아니라 hamming windowing을 한다. 이는 필터의 양끝을 스무딩한다는 것이다.

sinc 함수의 해밍 윈도우를 푸리에 변환한 결과이다. 결과를 보면 알 수 있듯, 중심 주파수 영역대는 잘 캐치하고 그 외 주파수 영역대는 무시한다.

SincNet Filter
이제 SincNet의 첫 번째 레이어를 살펴보겠다. SincNet은 푸리에 변환(Fourier Transform) 없이 시간 도메인의 입력 신호를 바로 처리한다.
시간 도메인과 같에 따른 컨볼루션은 다음과 같았다.
이곳에 우리는 우리가 정의한 싱크 함수(컨볼루션 필터)를 적용한다.
과 는 bandpass 범위에 해당하는 스칼라 값으로, 에서 사이만 남기고 나머지 주파수 영역대는 무시한다. 첫 번째 괄호 안의 식은 해당 영역의 구형 함수를 시간 도메인으로 옮긴 결과이다. 이때, 과 는 learnable parameter이며, 저자들은 전자를 low cut-off frequency, 후자를 high cut-off frequency라고 부른다..
마지막의 은 hamming window이다.
Speech Model Pre-training for End-to-End Spoken Language Understanding
해당 모델은 E2E SLU들 중에서도 성능이 꽤나 괜찮은 아이로, 보통의 모델은 음소 혹은 단어 둘 중 하나만 사용하는 경향이 있는데, E2E SLU는 둘의 정보를 모델에 전부 녹여 성능을 높였다는 특징이 있다. 구조부터 살펴보면 다음과 같다.
Architecture

좌측은 Pretraining, 우측은 SLU task를 도식화해서 보이고 있다.
Pretrain
Pretrain은 음성을 입력 받아 음소(phoneme)와 단어(word)를 각각을 예측하면서 진행한다.
if isinstance(dataset, ASRDataset):
train_phone_acc = 0
train_phone_loss = 0
train_word_acc = 0
train_word_loss = 0
num_examples = 0
self.model.train()
for idx, batch in enumerate(tqdm(dataset.loader)):
x,y_phoneme,y_word = batch
batch_size = len(x)
num_examples += batch_size
phoneme_loss, word_loss, phoneme_acc, word_acc = self.model(x,y_phoneme,y_word)
if self.config.pretraining_type == 1: loss = phoneme_loss
if self.config.pretraining_type == 2: loss = phoneme_loss + word_loss
if self.config.pretraining_type == 3: loss = word_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
train_phone_loss += phoneme_loss.cpu().data.numpy().item() * batch_size
train_word_loss += word_loss.cpu().data.numpy().item() * batch_size
train_phone_acc += phoneme_acc.cpu().data.numpy().item() * batch_size
train_word_acc += word_acc.cpu().data.numpy().item() * batch_size
if idx % print_interval == 0:
print("phoneme loss: " + str(phoneme_loss.cpu().data.numpy().item()))
print("word loss: " + str(word_loss.cpu().data.numpy().item()))
print("phoneme acc: " + str(phoneme_acc.cpu().data.numpy().item()))
print("word acc: " + str(word_acc.cpu().data.numpy().item()))
train_phone_loss /= num_examples
train_phone_acc /= num_examples
train_word_loss /= num_examples
train_word_acc /= num_examples
results = {"phone_loss" : train_phone_loss, "phone_acc" : train_phone_acc, "word_loss" : train_word_loss, "word_acc" : train_word_acc, "set": "train"}
self.log(results)
self.epoch += 1
return train_phone_acc, train_phone_loss, train_word_acc, train_word_loss이처럼 단순히 어떤 음소인가, 어떤 단어인가를 classification하면서 layer를 학습한다.
SLU task
음소와 단어의 예측에서 사용한 분류 모델에서 상단의 classifier를 제외하고 위에 intent module을 하나 더 쌓아서 finetuning을 진행한다.
Phoneme module
st=>start: rax_text
op=>operation: SincNet
op1=>operation: Conv1
op2=>operation: Conv2
op3=>operation: bi-GRU
op4=>operation: Downsample
op5=>operation: bi-GRU
op6=>operation: Linear
op7=>operation: Softmax
e=>end: l_phoneme
st->op->op1->op2->op3->op4->op5->op6->op7->e원시 음성을 입력으로 받아, 싱크넷, 2개의 컨볼루션 레이어, 양방향 그루를 거치면 가 된다. 마지막으로, classifier (linear+softmax)를 거치면 이 되며, 이를 음소 레이블과 비교해 손실(loss)을 계산한 뒤 역전파(backpropagation)를 수행한다.
Word module
st=>start: h_phoneme
op3=>operation: bi-GRU
op4=>operation: Downsample
op5=>operation: bi-GRU
op6=>operation: Linear
op7=>operation: Softmax
e=>end: l_phoneme
st->op3->op4->op5->op6->op7->e을 입력으로 받아, 2개의 GRU를 지나, 를 얻는다. 이후 가 됩니다. 이후 classifier (linear+softmax)를 거치면 이 되며, 이를 단어 레이블과 비교해 손실(loss)을 계산한 뒤 역전파(backpropagation)를 수행한다.
Intent module
을 입력으로 받는다. finetuning할 태스크에 따라 모델의 형태 및 종류는 달라질 수 있다.
References
- Milind Rao, Anirudh Raju, Pranav Dheram, Bach Bui, Ariya Rastrow
(2020)(Amazon Alexa, USA), Speech To Semantics: Improve ASR and NLU Jointly via All-Neural Interfaces - Lugosch, L., Ravanelli, M., Ignoto, P., Tomar, V. S., & Bengio, Y. (2019). Speech model pre-training for end-to-end spoken language understanding.
- Interspeech 2019 Survey Talk by Jan Niehues
- 정민화 교수님 2021 "K-mooc 언어학과 인공지능" 수업
- 정민화 교수님 2021 음성언어처리 수업
- Ratsgo's Speechbook

[15기 황보진경]
인간의 청지각 과정과 모델링
SLU란 음성 신호에서 의미적인 요소를 파악하는 것이다.즉, Intent Classification과 Slot Filtering이 이루어져야 한다.
전통적으로는 SLU를 수행하기 위해 순차적으로 ASR->NLU를 수행했다. 먼저 ASR이나 NLU와 관련된 데이터가 풍부하고, 각각의 모델이 독립적으로 모듈화가 되어있어서 더 좋은 모델이 나오면 각각을 갈아끼울 수 있다는 장점이 있다. 그러나 두 개의 모델을 따로 학습시켜야 하므로 expensive하고, 선행 모델의 에러가 공유된다.
이를 개선하기 위해 End2End 방식이 제안되었다. 그러나 데이터도 부족하고, intermedia 없이 음성을 intent로 매핑하는 것이 어려워서 기존 방식만큼 성능이 좋지는 못하다.
Speech Model Pre-training for End-to-End Spoken Language Understanding