[6주차] Unsupervised Source Separation By Steering Pretrained Music Models
작성자 : 15기 안민준
본 리뷰는 투빅스 15&16기 음성 세미나에서 동명의 논문의 내용을 정리하고 공유하기 위해 만들었습니다.
출처가 적혀 있지 않은 이미지는 모두 본 논문에 수록된 이미지입니다.
Abstract
본 논문은 기존에 음악 생성과 태깅 모델을 그대로 사용하여 Source Seperation 모델을 얻습니다.
음악 생성 모델은 OpenAI의 JUKEBOX 모델을 사용했으며, 태깅 모델은 4 종류를 묶어서 사용했습니다.
이 논문을 통해 소스 분리 작업에서 음악 생성 & 태깅 모델의 가능성을 기대할 수 있다고 말합니다.
Introduction
데이터셋 부족과 모델 전이(?)
- MIR 영역에서는 데이터셋의 부족으로 인해 어려움을 겪는 중이고 특히 Source Seperation(소스 분리) 모델은 well-labeled 된 데이터가 없다고 합니다.
- 기존 소스 분리 모델은 분리할 수 있는 소스의 종류의 한계가 있습니다. (Voice, Bass, Drums, "기타" - MUSDB18)
- 최근 연구들은 음악 생성 모델 등을 MIR 쪽에 적용하려는 시도를 하고 있습니다.
본 논문에서는
- 본 논문에서는 사전 학습된 모델이 어떻게 musical source seperation 작업에 적용되는지 보일 예정입니다.
- 태깅 모델의 추론 결과를 JUKEBOX가 생성하는 방법으로 사용했습니다.
- Gradient Ascent(경사 상승법) 을 JUKEBOX의 임베딩 공간에 적용하고 디코딩된 오디오를 입력값의 마스크로 사용했습니다. (후에 자세히 설명합니다)
Prior work
기존 방법론
- 기존 연구들은 '이미 존재하는 데이터셋에서 성능을 최대화하는 것'에 초점을 맞추어 진행했습니다.
- 가장 유명한 데이터셋인 MUSDB18은 악기 소스가 제한되어 있고, 데이터셋 크기도 너무 작아서(150개) 증강이 어렵습니다.
- 딥러닝의 발전으로 Non-negative Matrix Facotization(NMF)와 같은 비지도 방법론이 도입되었으나, 일부 휴리스틱한 알고리즘이 도입되어야 합니다.
- 반복, 화성, 타악(박자)와 같은 음악적 특징을 사용하는 시도도 있었으나, 음원의 종류에 따라 안되는 경우가 많았습니다.
최근 방법론

MixIT방법론 (https://deepai.org/publication/unsupervised-sound-separation-using-mixtures-of-mixtures)
- Mixture Invariant Training (MixIT) 사용
- Mixtures of mixtures (MoMs)를 생성하고 이를 overseparating 하는 방법(?)
- 악기 소스가 독립적이지 않기 때문에 음악 영역에는 적합하지 않습니다.
- VAE를 사용한 연구도 있으나, 학습이 어느정도 필요합니다.
- 본 논문에서 제안하는 방법은 학습이 전혀 필요하지 않은 방법이라고 강조합니다.
Background
OpenAI's JUKEBOX

jukebox(https://openai.com/blog/jukebox)
- JUKEBOX는 계층적 VQ-VAE 부분(3개) 의 인코더 부분과 Language Model 의 생성 모델로 구분됩니다.
- VQ-VAE는 입력 오디오를 3개의 주파수를 가진 토큰으로 분리합니다.
- 이 중에서 본 논문에선 VQ-VAE중 5.51kHz로 압축하는 인코더(Bottom Level)를 사용합니다.
Automatic Music Tagging
- Music Tagging은 음성 신호에 대해 multi-hot, binary labels 를 예측합니다.
- 대부분 CNN을 사용한 구조입니다.
- 본 논문에서는 멜 스펙토그램을 받는 FCN 과, constant-Q-transform을 받는 HarmonicCNN을 사전 학습하여 사용했습니다.

(https://www.semanticscholar.org/paper/Automatic-music-tagging-with-Harmonic-CNN-Won-Chun/267975c8eb081abebbdf5c13a09f0e3e3b1099bd/figure/0)
Proposed System
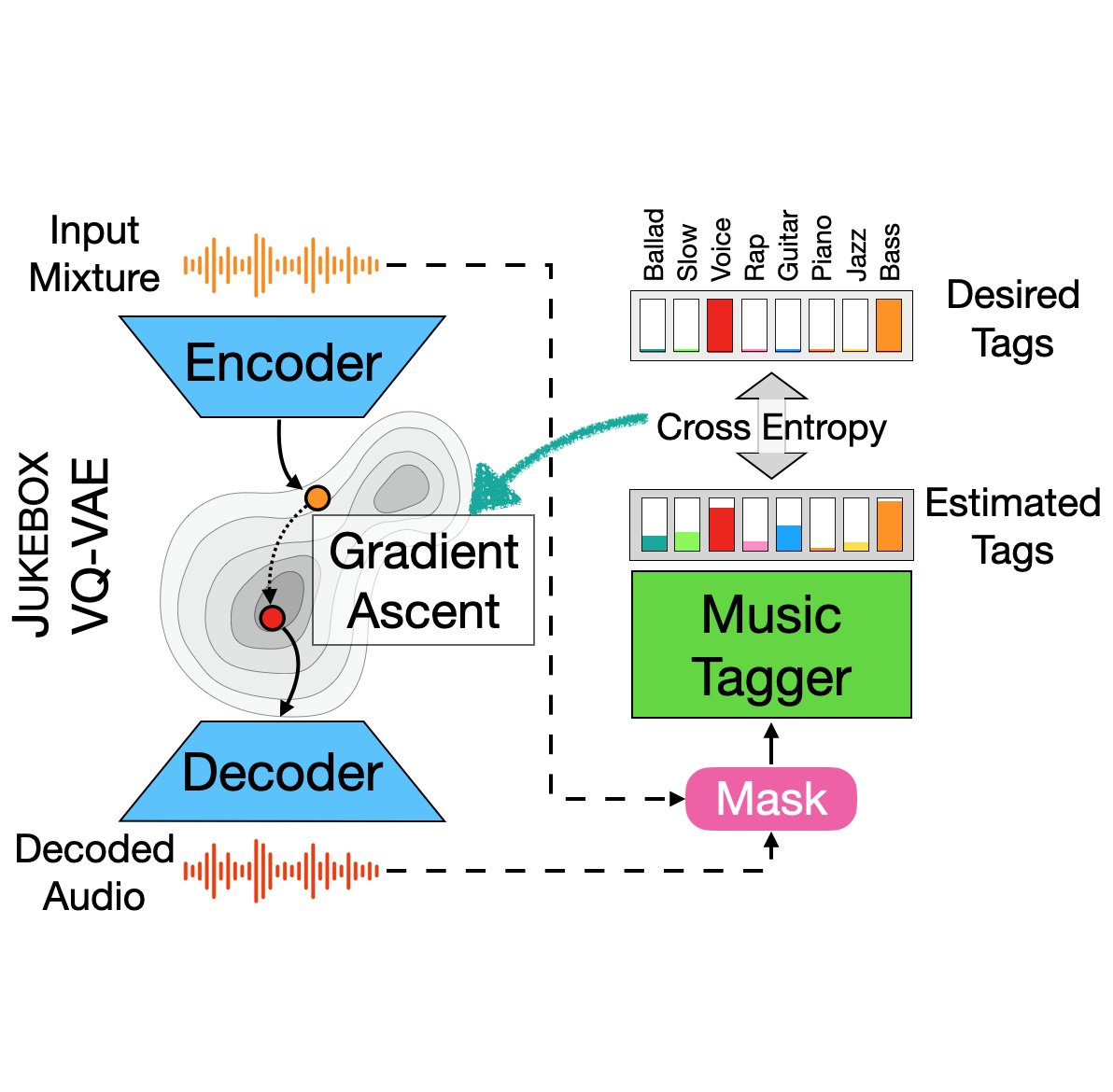
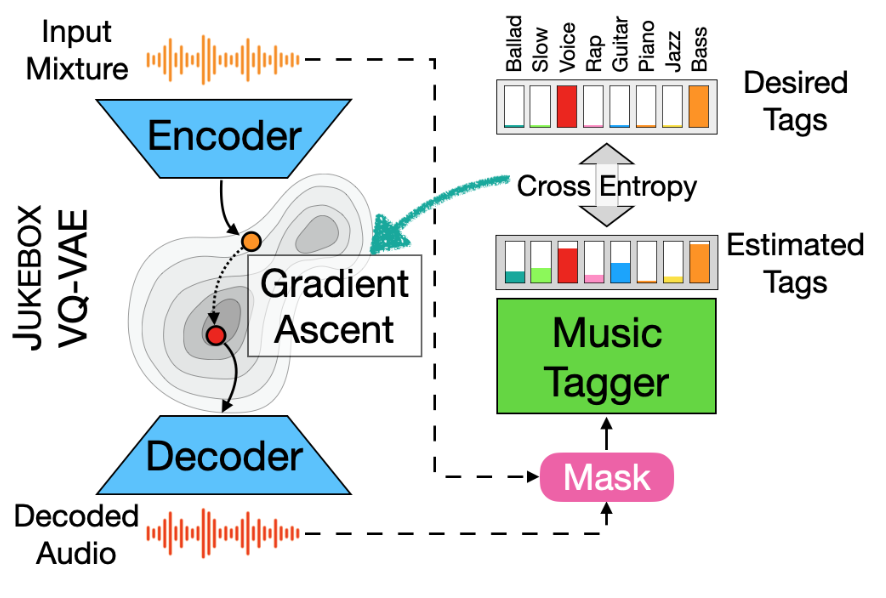
- 본 논문에서는 JUKEBOX의 VQ-VAE모델과, Tagging 모델을 차용했기 때문에 앞글자를 차용해서 TAGBOX라고 명칭했습니다.
- 음성 입력이 들어가면 VQ-VAE모델이 입력값을 변화시키고 태깅 모델이 변환된 신호에서 sources의 집합들을 태깅합니다.
실행 순서

- 분리할 악기들을 기록한 Tag 인 을 생성합니다.
- 입력 이미지 를 인코더 에 넣어 임베딩 를 구합니다.
- 이 임베딩은 에 의해 웨이브폼 로 변환됩니다.
- 에 마스킹을 적용하고 태깅 모델에 넣습니다.
- 이 때 마스킹을 적용하는 방법은 다음과 같습니다.
- 원본 음원 와 앞서 나온 를 스펙트로그램으로 변환하여 , 를 구합니다.
- 마스크 를 구합니다.
- 앞서 구한 에 마스킹을 적용하여 를 구합니다.
- 를 STFT 역변환을 적용하여 웨이브폼 형태 로 변환합니다.
- 를 태깅 모델에 넣어 Binary Cross-entropy Loss : 를 구합니다.
- Loss가 JUKEBOX 임베딩공간에서 gradient ascent 를 거칩니다.
- 를 통해 최종 출력을 구합니다.
기타
- 본 모델은 Source Seperation을 위한 어떠한 추가 학습도 하지 않았다는 점이 특징입니다.
- Tag에 분리할 모델을 적용했기 때문에 Gradient Ascent 과정에서 필요로 하는 정보만 남는 느낌인 것 같습니다.
- 마스킹은 원하는 음원을 얻기 위해 제거되어야 하는 부분을 나타냅니다.
Experimental Validation
기존 시스템과 비교
- 딥 러닝 지도학습 시스템, 기존 비지도학습 시스템으로 테스트 해 보았습니다.
- MUSDB18이나 Slakh2100 데이터셋 두개를 활용하여 테스트했다고 합니다.
- SDRi(Source-to-Distortion Ratio improvment) 지수로 표현했습니다.
pretrained model 별 비교
- FCN과 HarmonicCNN 구조 두개를 비교해 보았습니다.
- SDRi 지수로 표현했습니다.
Results and Discussion
기존 시스템과 비교

- 다른 비지도 학습 논문에 비해 뛰어난 성과를 보였습니다.
- 반면 특별한 목적에 맞게 설계된 논문보다는 성능이 낮았습니다.
- 기존보다 더 넓은 Source Type 에 대해서 예측할 수 있는 것이 포인트
pretrained model 별 비교

- FCN 이 가장 좋은 결과이나, 평가 방식에 따라서 다른 결과가 나타났습니다.
기타 토론
- 마스킹 시 FFT 크기를 여러 개 잡는 방식, gradient ascent를 100번 수행 등 성능을 높이는 트릭이 존재합니다.
- Masking을 넣지 않고 모델을 작동시켜 보니 Style Transfer와 비슷하게 동작하는 재밌는 모습을 보였습니다.
- 학습 시킬 때 엄청난 양의 음악을 사용했기 때문에, 추가 학습 없이 이런 일이 가능했을 것으로 생각됩니다.
- 이 모델을 통해 MIR의 데이터 부족 문제를 해결할 수 있었으면 좋겠다고 말합니다.
Conclusion
- TAGBOX - 비지도 Source Seperation 모델을 제안했습니다.
- 이때 어떠한 모델도 추가 학습이 이루어지지 않았습니다.
- 기존보다 더 넓은 Source를 추출할 수 있습니다.

투빅스 15&16 음성세미나 입니다.
[15기 황보진경]
본 논문은 추가적인 학습 없이 사전 학습된 음악 생성 모델과 태깅모델만으로 source separation을 진행하였다. Source separation은 라벨링이 없기 때문에 관련 데이터셋이 많지 않다. 최근에는 이를 해결하고자 mixture의 mixture를 생성한 후 이것들을 모두 분리하는 MixIT 방법론이 도입되었지만 음악 영역에는 적합하지 않다.
Jukebox
주크박스는 인코더 부분과 생성 모델로 구분된다. 인코더에서는 입력 오디오를 세 개의 주파수를 가진 토큰으로 분리한다. 음악에서 중요한 정보는 주로 낮은 주파수 영역대에 포함되어 있기 때문에 본 논문에서는 5.51kHz로 압축하는 인코더만을 사용한다.
Music Tagging
Music Tagging은 음성 신호에 라벨을 예측하는 Task로 주로 CNN을 사용하여 이뤄졌다. 본 논문에서는 FCN과 HarmonicCNN을 사용했다.
방법
성능이 완벽히 좋지는 않지만, 학습을 전혀 하지 않고 separation을 이루었다는 의의가 있다.