[7주차] Unsupervised Singing Voice Conversion
원본 논문 보기
작성자: 15기 김태희
0. Abstract
본 논문은 텍스트, 음계 등에 구애 받지 않고 한 가수의 목소리를 다른 가수의 목소리로 변환하는 비지도형 네트워크를 제안한다.
Supervised:
가사, 음표, 발음, 가수들 간의 매칭 샘플 등을 사용하여 학습
본 논문은 CNN encoder 와 WaveNet decoder로 이루어져 있는 구조를 제안함과 함께 새로운 data augmentation 과 loss를 도입하여 target 가수의 목소리와 유사도가 높은 singing voice 를 생성하고자 한다.
1. Introduction
기존의 딥러닝 방식들은 언어적인 특징들과 반주되는 음들을 기반으로 하여 singing voice 를 생성해 내었다. 본 논문에서는 이와는 조금 다른, 한 가수의 목소리를 다른 가수의 목소리로 변형을 하는 방법을 제안한다.
본 논문은 Unsupervised 방식을 제안한다. Supervised 학습을 진행할 시 필요한 다양한 가수들 간의 매칭 샘플들, 가사와 해당 텍스트의 발음, 음표 등의 데이터가 필요하지 않기에 보다 적은 데이터로 학습이 가능하다는 장점이 있다. 또한, 딥러닝 기술의 발전으로 인해 음악으로부터 사람의 음성을 분리하는 기술이 발전하여 학습 데이터 구축도 빠르게 가능하다.
Contributions
- Unsupervised singing voice conversion 방식을 제안 - target 가수는 다른 곡에서부터 모델링
- Unsupervised 방식으로 학습된 single encoder와 single decoder의 효과 확인
- Two-phase training 방식의 unsupervised audio translation 제안
- 여러 identity들의 backtranslation 방식 제안
- 효과적인 학습을 위한 data augmentation 방식 제안
2. Related Work
WaveNet
본 논문의 방법은 WaveNet autoencoder 에서부터 차용되었다. 본래 single instrument를 모델링하던 것에서부터 나아가 single encoder + multiple decoder 구조를 활용하여 여러 악기간의 translation 방식이 나왔으며, 이 때 parallel data를 사용하지 않았다는 점은 본 논문에서 제안하는 학습 방식과 유사하다.
그러나 supervised learning방식인 기존의 WaveNet autoencoder들과는 달리 본 논문에서는 unsupervised 방식으로 학습을 진행한다.
VQ-VAE
기존의 unsupervised VQ-VAE 방식에서의 voice conversion은 WaveNet autoencoder로부터 생성된 quantized latent space를 기반으로 한다. 본 논문에서는 domain confusion loss를 사용하여 기존 one-hot-embedding을 통한 discretization보다 더 speaker-invariant 한 voice conversion 성능을 얻었다.
Singing Synthesis and Conversion
WaveNet의 등장 이후 unit-selection, HMM 등의 고전적인 생성 방법들에서 벗어나게 되었다. WaveNet decoder를 사용한 singing synthesis 시스템은 입력으로 음표와 가사를 받아 출력으로 vocoder feature 들을 생성해 내었고, 해당 방식을 응용하여 target singer의 음성을 생성하였다.
최근에는 singing voice conversion시 parallel 데이터를 요구하지 않는, 일상 대화 속의 target voice를 사용한 방법을 제안하였지만 sample 들은 만족스럽지 않은 결과들을 보였다.
Backtranslation
Backtranslation은 본래 NLP에서 기계번역을 목적으로 고안된 방법이다. 본 논문에서의 conversion system은 언어의 샘플 를 언어의 로 번역 후, 의 training pair를 가지고 역으로 언어를 번역하는 backtranslation 방법을 이용해 source singer 에 가까운 synthetic 데이터를 생성한다.
Mixup Training
기존의 Mixup Training에서는 두 개의 샘플 를 beta distribution()으로부터 샘플링한 weight()을 가지고 weighted sum을 진행한 새로운 virtual sample을 가지고 training을 진행하였다.
본 연구에서는 샘플들의 변화가 크면 안 되므로 beta distribution대신 uniform distribution을 사용한다.
3. Method
전체적인 모델 구조는 다음과 같다.
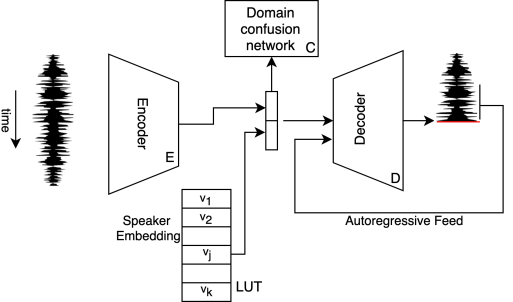
본 논문에서 제안한 singing voice conversion method는 single encoder와 target singer의 vector-embedding에 컨디션된 single decoder로 이루어져 있다.
- : Encoder
- : Decoder
- : Domain confusion network, singer classification network - input sample에 해당하는 가수 예측
- : 번째 가수에 대해 학습된 임베딩 벡터, 모든 가수들에 대한 임베딩 벡터를 Look Up Table(LUT)에 저장
- : 번째 가수에 대한 input sample
3.1 Conversion Network
학습은 총 2가지의 phase로 이루어진다.
First Phase
: softmax 에 기반한 reconstruction loss를 singer들의 샘플에 각각 적용
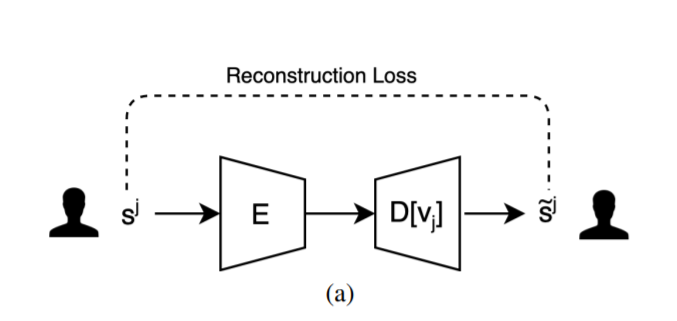
첫 번째 phase에서는 confusion network C 가 각 singer에 대한 classification loss를 최소화한다.
- : Cross entropy loss
더불어 번째 가수의 샘플 이 encoder와 decoder를 거쳐서 나온 값이 원래의 와 같아지도록 reconstruction loss를 최소화한다. (흔히 알려져 있는 autoencoder의 학습 방법과 같다)
Second Phase
: translation이 잘 되도록 학습
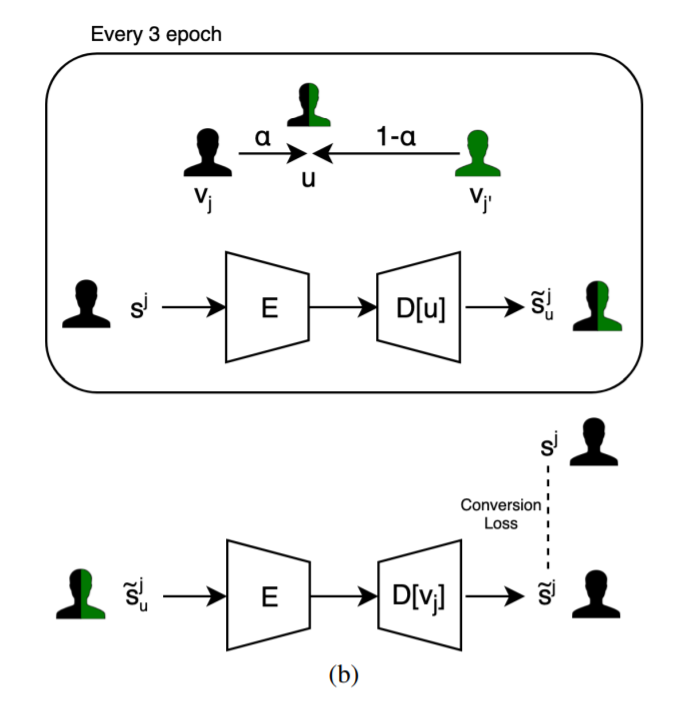
Second phase에서는 translation을 진행하는 두 가수의 parallel sample을 생성 후 해당 데이터를 기반으로 네트워크를 학습시킨다. 두 가수가 함께 있는 데이터를 만들 시 mixup 기술을 사용한다.
모든 mixup 샘플()는 mixup singer embedding 인 에 의해 변화한다. 이 때 mixup된 vector 는 다음과 같이 나타내질 수 있다.
: [0, 1] 사이에서 uniformly sampling된 weight
이후 mixup vector와 번째 가수의 encoded sample 을 decoder에 넣어서 mixup sample 를 생성한다.
위 과정을 거쳐 생성된 mixup sample을 가지고 second phase training이 시작되었을 때, 3 번의 epoch 마다 새로운 mixup smaple을 생성한다. 생성된 샘플들은 다시 autoder 에 넣어 를 잘 reconstruction 할 수 있도록 학습을 진행한다.
최종 인퍼런스로 어떤 가수의 노래 샘플 를 번째 가수의 목소리로 변환을 할 시 를 encoder에 넣고 그 결과값을 에 대해 컨디션된 디코더에 넣어 구할 수 있다.
3.2 Audio Input Augmentation
본 논문에서 제시한 모델은 사람의 singing voice만을 담고 있는 데이터셋을 필요로 한다. 현재 구축된 학습용 데이터셋은 각 가수마다 4-9개만의 짧은 노래들로 구성되어 있으므로 data augmentation을 통해 데이터를 추가적으로 생성하였다.
다음과 같은 방법으로 데이터셋을 최대 4배로 증강시켜 학습을 진행한다.
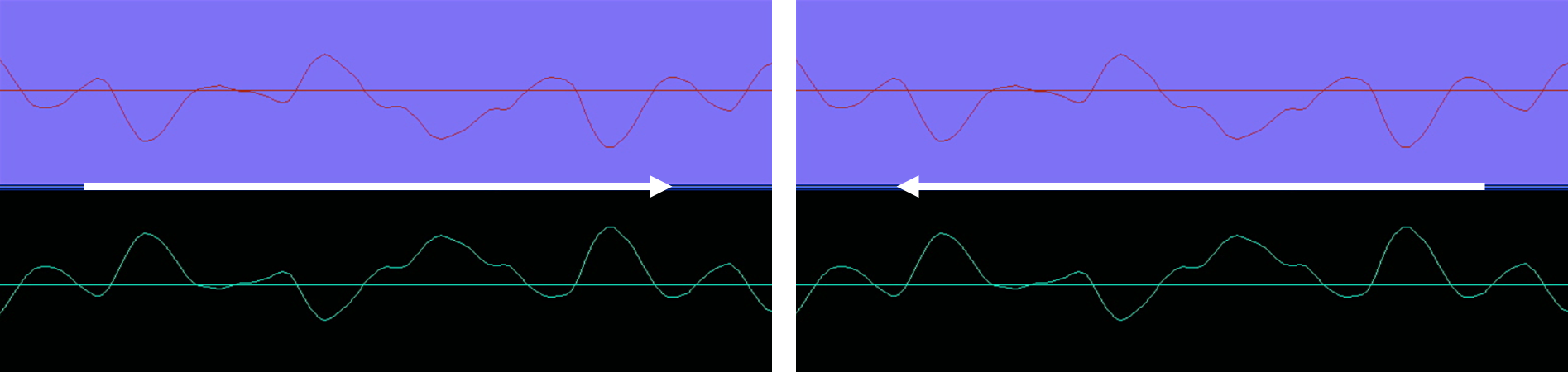
- 원본 음성 데이터
- 원본 음성 데이터를 거꾸로 재생한 신호
- 원본 음성 데이터의 위상을 180도 전이한 신호
- 원본 음성 데이터를 거꾸로 재생 후 위상을 180도 전이한 신호
3.3 Architecture of Sub-Networks
Encoder
WaveNet과 유사한 dilated convolutional network를 사용
- fully convolutional network
- 3 blocks of 10 residual-layers 30 layers total
Decoder
WaveNet decoder 사용
- singer 에 따른 conditioning을 위해 audio encoding을 target singer embedding과 합쳐진 상태로 받음
- 4 blocks of 10 residual layers 40 layers
Classifier/Confusion Network
- 3 개의 1D convolution layer
- ELU activation function
- output layer
4. Experiments
Singing voice conversion system의 평가를 위한 public benchmark의 부재로 실제 ground truth 노래들과의 비교를 통해 검증을 진행하였다.

사람이 직접 점수를 매겨 Naturalness(Quality)와 Similarity를 평가한 결과이다.
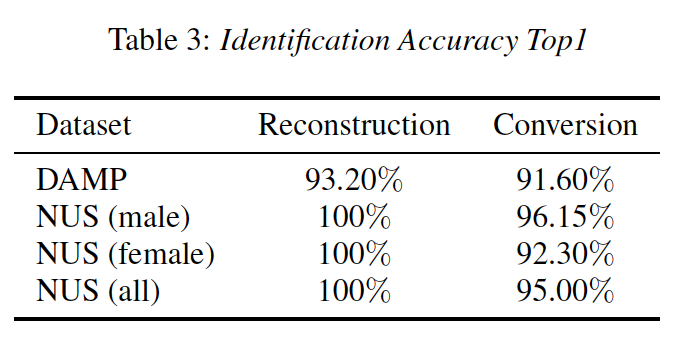
생성된 음성과 target voice의 유사도는 voice identificability 를 판단하는 CNN 의 인식 정확도로 측정할 수 있다.
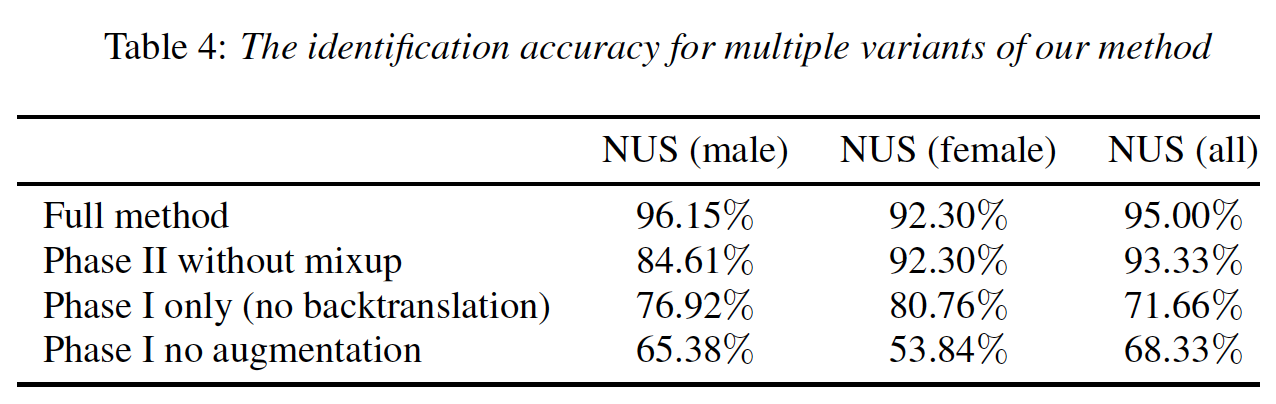
사용된 요소들을 하나씩 제거했을 때의 성능을 파악하는 Ablation study 결과 full method일 시 가장 좋은 성능을 보였다. 이로 인해 논문에서 제안한 방법들이 모두 voice conversion 의 성능 향상에 기여한다는 것을 확인할 수 있다.
샘플 결과: https://enk100.github.io/Unsupervised_Singing_Voice_Conversion/

2개의 댓글

[15기 황보진경]
본 논문은 두 단계로 이뤄진 unsupervised sining voice conversion에 대해 다루고 있다.
먼저 인코더와 디코더로 이뤄진 confusion network C가 각각의 singer에 대한 classification loss(reconstruction loss로 사용함)를 최소화하도록 학습된다. 이후에 두 가수의 mix-up embedding vector를 이용하여 디코더에서 mixup sample을 생성하고, mixup sample을 이용하여 첫번째 단계와 마찬가지로 reconstruction loss를 최소화하도록 학습을 진행한다.
학습을 진행하는 과정에선 총 세가지 augmentation 방법을 사용하였다: 원본 음성을 거꾸로 재생한 신호, 위상을 180도로 바꾼 신호, 거꾸로 재생 후 위상을 180도 바꾼 신호
모델의 구조는 Wavenet과 유사하다. 인코더는 fully convolutional network이며, 10개의 residual layers로 이뤄진 블록을 3개 사용한다. decoder는 wavenet decoder를 사용하며 10개의 residual layers로 이뤄진 블록을 4개 사용한다. Confusion network는 3개의 1D conversation layer와 ELU activation function으로 이루어 졌다.
[15기 안민준]
Introduction
본 논문은 한 가수의 목소리를 다른 가수의 목소리로 변환하는 Singing Voice Conversion 작업을 수행한다.
이 논문에서 unsupervised란 가사, 음표, 발음, 가수 등 '메타데이터'를 사용하지 않았다는 것을 의미한다.
Related Works
Method
Conversion Network
Audio Input Augmentation