[6주차] PARALLEL WAVEGAN
PARALLEL WAVEGAN
: A FAST WAVEFORM GENERATION MODEL BASED ON GENERATIVE ADVERSARIAL NETWORKS WITH MULTI-RESOLUTION SPECTROGRAM
Abstract
논문이 제시하는 Parallel WaveGAN은
- distillation 과정이 없고 빠르며 메모리 소비가 적은 GAN 기반 보코더이다.
- Generator
- non-autoregressive WaveNet
- multi-resolution STFT loss + adversarial loss
- 단순한 구조이지만 높은 퀄리티의 speech가 생성된다. (MOS: 4.16)
Introduction
기존의 Deep Generative model들은 좋은 퀄리티의 speech를 생성한다.
하지만 WaveNet 같은 autoregressive model은 inference speed가 느리다는 문제가 있다.
이를 해결하기 위해 teacher-student framework 기반의 Knowledge Distillation 기법을 적용하였지만, 이는 학습 과정이 복잡하고 잘 훈련된 teacher 모델이 필요했다.
기존 Vocoder 모델의 문제점
- 느린 inference speed
- 복잡한 계산 과정
느린 속도와 복잡한 계산 과정을 해결하기 위해 본 논문은 Distillation 기법을 사용하지 않는 Parallel WaveGAN을 제안하였다.
이 모델은 multi-resolution STFT loss와 adversarial loss를 결합하여 non-autoregressive WaveNet (Generator)을 학습시킨다.
그 결과 학습 과정도 훨씬 단순해지면서 적은 parameters로 자연스러운 speech를 생성할 수 있다.
- multi-resolution STFT loss + waveform-domain adversarial loss
-> 기존 distillation 기반 Parallel WaveNet (e.g. ClariNet)과 distillation이 없는 Parallel WaveGan 모두에 효과적. - Parallel WaveGAN은 ClariNet 모델보다 학습 속도와 합성 속도가 빠르다.
- Parallel WaveGAN은 ClariNet가 생성한 speech의 퀄리티와 비슷하거나 더 좋다.
METHOD
Parallel waveform generation based on GAN
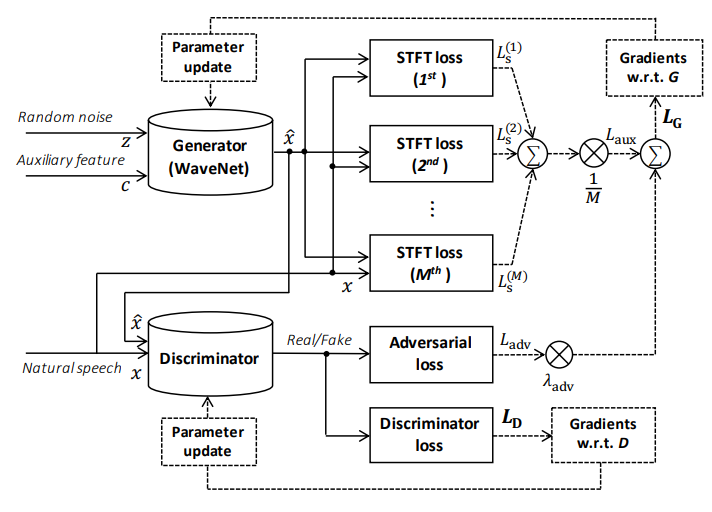
Parallel WaveGAN은 GAN 기반의 모델이므로 generator(G)와 Discriminator(D) network로 구성된다.
Generator로 WaveNet을 사용하는데, 기존의 WaveNet과 다른 점은 아래 3가지이다.
- causal convolutions 대신 non-causal convolutions을 사용한다.
- input으로 Gaussian 분포에서 도출된 random noise을 사용한다.
- 학습 단계와 생성 단계 모두 non-autoregressive 모델을 사용한다.
Adversarial Loss

z : input white noise
Generator는 adversarial loss를 최소화하여 discriminator를 속이길 시도하며 실제 waveforms의 분포를 학습한다.
Discriminator Loss
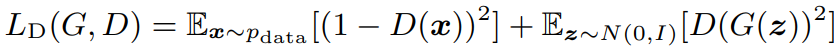
- x : target waveform
- pdata : 실제 waveform의 분포
반면, discriminator는 generator가 생성한 샘플을 가짜로 잘 분류하기 위해 위의 discriminator loss를 사용한다.
Multi-resolution STFT auxiliary loss

- cycle GAN을 이용하여 손으로 그린 그림을 사진으로 생성하는 예시
-> adversarial loss에 auxiliary loss를 추가로 함께 최적화시켰을 때 더 좋은 결과가 나옴
저자는 이 방법을 음성 합성에 적용하였다.
adversarial trainig process의 안정성과 효율성을 향상시키기 위해 본 논문은 처음으로 multi-resolution STFT auxiliary loss 개념을 제안한다.
single STFT loss
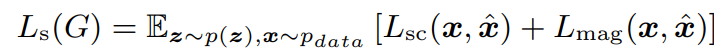
- Lsc: Spectral convergence Loss
- Lmag: log STFT magnitude loss
STFT loss: Spectral convergence (SC)

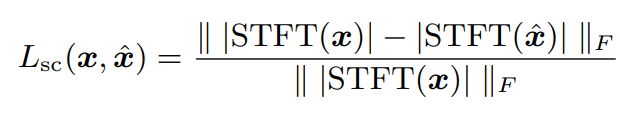
Generator가 저주파수를 중심으로 강조되는 components에 대해 reproduce하도록 한다.
STFT loss: Log-scale STFT magnitude loss
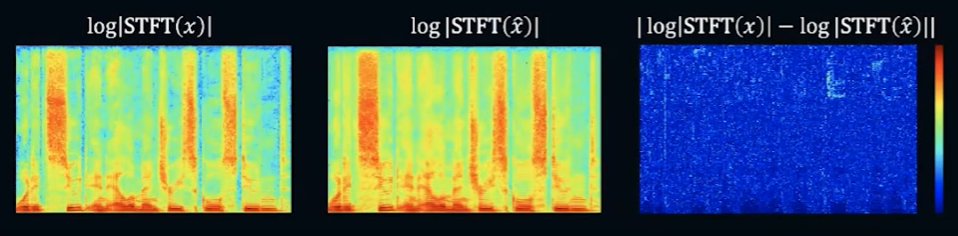
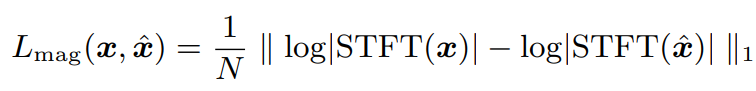
Generator가 speech의 디테일한 구조를 reproduce하도록 한다.
즉 Spectral convergence와 Log STFT magnitude loss는 상호보완적인 관계이다.
Multi-resolution STFT loss (final auxiliary loss)
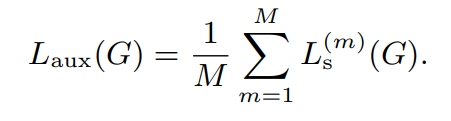
- M : STFT loss의 개수
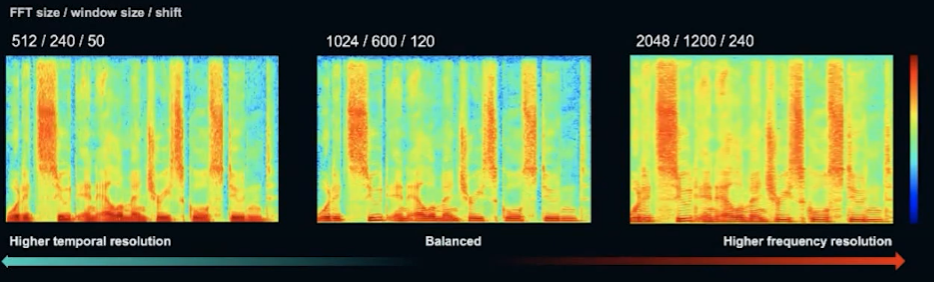
STFT 기반 time-frequency representation에서는 time과 frequency가 trade-off 관계이다. (예를 들어, window size가 커지면 frequency resolution은 높아지고 time resolution은 낮아진다.)
이를 해결하기 위해 매개변수를 조정한 여러 STFT loss들의 평균을 사용한다. 또한 이는 하나의 resolution STFT를 사용했을 때의 overfitting 위험을 방지한다.
final loss function for the generator
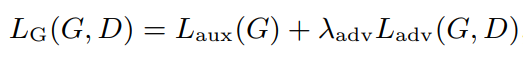
- λadv: 두 loss의 비율을 맞추기 위한 하이퍼파라미터
위에서 소개한 auxiliary loss와 adversarial loss의 합이 최종 loss function이 된다.
auxiliary loss와 adversarial loss를 공동으로 최적화함으로써 generator는 실제 음성의 분포를 더 효과적으로 학습할 수 있다.
EXPERIMENTS
Experimental setup
- Data
- 여성 일본어 전문 성우가 녹음한 음성학적, 과정적으로 균형 잡힌 음성 말뭉치
- 24kHz로 샘플링, 16비트로 양자화
- training data: 11,449개의 문장 (23.09시간), validation, test data: 각 250 문장 (0.35시간)
- log-mel spectrogram으로 추출하여 generator의 입력인 auxiliary feature로 사용
- multi-resolution STFT loss의 parameters
: 3가지의 STFT loss를 사용
Evaluation
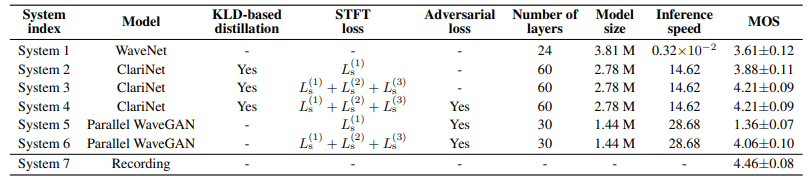
- Inference speed: Parallel WaveGAN > ClariNet > WaveNet
- Model size: WaveNet > ClariNet > Parallel WaveGAN
- MOS: Ground Truth > ClariNet > Parallel WaveGAN > WaveNet
- Single STFT Loss vs. Three STFT Loss (Mean Opinion Score)

multi-resolution STFT loss를 사용하였을 때 perceptual quality가 향상되는 것을 확인할 수 있다. 즉 auxiliary loss가 speech 생성 모델에 효과적이라는 것을 확인하였다.
- Training time comparison

Parallel WaveGAN은 복잡한 density distillation 과정이 필요없기 때문에 다른 모델들에 비해 학습 속도가 빠르다.
- Text-to-speech

Transformer TTS 모델로부터 생성된 aucoustic features를 각 Vocoder의 input auxiliary features로 사용하였을 때의 MOS(Mean Opinion Score).
TTS의 Vocoder로서 Parallel WaveGAN의 성능은 knowledge-Distillation 기반의 ClariNet-GAN 모델과 필적하는 것을 확인할 수 있다.
CONCLUSION
Parallel WaveGAN
- based on GAN
- distillation-free
- loss function: adversarial loss + multi-resolution STFT loss
- fast and compact (1.44M Parameters)
- 4.16 MOS (TTS)
작성자: 김윤혜

[15기 황보진경]
지식전이 기법을 사용하지 않은 GAN 기반의 보코더이다. 기존의 auto-regressive model은 생성 속도가 느리다는 문제가 있다. 이를 해결하기 위해 teacher-student framework 기반의 방법론 등이 등장하였지만 이 역시 학습 과정이 복잡하고 잘 훈련된 Teacher model이 필요하다는 단점이 있다. 이를 개선하고자 제안된 Parallel WaveGAN은 학습 속도와 합성 속도가 빠르고 파라미터의 수가 적음에도 불구하고 자연스러운 음성을 생성할 수 있다.
일반적인 GAN의 adversarial loss 외에도 Parallel WaveGAN은 Multi-resolution STFT auxiliary loss를 사용한다. 합성된 음성과 실제 음성의 STFT가 유사하도록 추가한 loss 이며, STFT에서 time과 frequency의 Trade-off 관계를 고려하여 다양한 해상도의 STFT loss를 사용한다.
TTS로 사용될 때에는 log-mel spectrogram을 노이즈와 함께 generator에 입력으로 사용한다.