1. Chapter03 들어가기 전
: Airflow 책을 학습하는 방법 을 참고하여 Github 에서 clone 받은 소스 중 Chapter03 경로로 이동한 후 아래와 같이 Docker Compose 명령어를 수행하여 Airflow 환경을 세팅한다.
Airflow 컴포넌트 컨테이너 실행
: 이 때 docker compose 빌드 실행 후 오류가 발생 하는 경우 아래 오류 대응 히스토리를 참고하길 바란다.
# 만약 chapter02 의 도커 컨테이너가 실행 중이라면 먼저
# cd data-pipelines-with-apache-airflow/chapter02/ && docker-compose down
# 명령어를 실행한다.
$ cd data-pipelines-with-apache-airflow/chapter03/
$ docker-compose up --build2. chapter03 Docker Compose 오류 대응 히스토리
1) 5000 Port 중복 사용 오류
[ 에러 메시지 ]
Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:5000 -> 0.0.0.0:0: listen tcp 0.0.0.0:5000: bind: address already in use[ 원인 ]
: MacOS M1 에서는 내장 시스템에서 5000번 포트를 이미 점유하고 있기 때문에 5000번 포트를 중복해서 사용할 수 없다.
[ 대응 ]
: MacOS 에서 사용중인 5000번 포트 서비스를 종료하거나, docker-compose.yml 에서 events_api 서비스 정의 부분에 5000번 포트(인바운드)를 다른 숫자로 변경 해주면 된다. 나는 events_api 서비스의 인바운드 포트 번호를 5000 에서 5007 로 바꿔서 진행했다.
# ./data-pipelines-with-apache-airflow/chapter03/docker-compose.yml
events_api:
build: ./docker/events-api
image: manning-airflow/events-api
ports:
- "5007:5000"2) 모듈 버전 이슈
: docker-compose.yml 에서 event-api 서비스를 실행할 때 /data-pipelines-with-apache-airflow/chapter03/docker/events-api/requirements.txt 에 기재 되어 있는 모듈을 설치하도록 Dockerfile 에 명령 해두고 있다. 이 때 설치 되는 모듈이 릴리즈 되면서 더이상 지원하지 않는 모듈 등의 이유로 모듈 설치 오류가 계속 나올 것이다. 나와 같은 현상이라면 아래 버전 이슈 대응 히스토리를 참고하면 된다.
[ 에러 메시지 - 1 ]
Traceback (most recent call last):
File "/app.py", line 8, in <module>
from flask import Flask, jsonify, request
File "/usr/local/lib/python3.8/site-packages/flask/__init__.py", line 14, in <module>
from jinja2 import escape
ImportError: cannot import name 'escape' from 'jinja2' (/usr/local/lib/python3.8/site-packages/jinja2/__init__.py)[ 원인 ]
: Flask 1.1.2 모듈을 설치하면 Jinja2.3.0 버전이 기본으로 설치 되는데 Jinja2.3.0 버전에서는 escape 모듈이 삭제 되었다고 한다.
[ 대응 ]
: requirements.txt 에 Jinja2==2.11.3 를 추가하여 버전을 다운그레이드 하여 실행해야 한다.
[ 에러 메시지 - 2 ]
Traceback (most recent call last):
File "/app.py", line 8, in <module>
from flask import Flask, jsonify, request
File "/usr/local/lib/python3.8/site-packages/flask/__init__.py", line 14, in <module>
from jinja2 import escape
File "/usr/local/lib/python3.8/site-packages/jinja2/__init__.py", line 12, in <module>
from .environment import Environment
File "/usr/local/lib/python3.8/site-packages/jinja2/environment.py", line 25, in <module>
from .defaults import BLOCK_END_STRING
File "/usr/local/lib/python3.8/site-packages/jinja2/defaults.py", line 3, in <module>
from .filters import FILTERS as DEFAULT_FILTERS # noqa: F401
File "/usr/local/lib/python3.8/site-packages/jinja2/filters.py", line 13, in <module>
from markupsafe import soft_unicode
ImportError: cannot import name 'soft_unicode' from 'markupsafe' (/usr/local/lib/python3.8/site-packages/markupsafe/__init__.py)[ 원인 ]
: jinja2 2.11.3에서 soft_unicode 의 markupsafe 모듈 지원이 중단 된 것 같다.
[ 대응 ]
: markupsafe 모듈을 사용할 수 있도록 requirements.txt에 MarkupSafe==2.0.1 을 추가 한다.
[ 에러 메시지 - 3 ]
Traceback (most recent call last):
File "/app.py", line 8, in <module>
from flask import Flask, jsonify, request
File "/usr/local/lib/python3.8/site-packages/flask/__init__.py", line 19, in <module>
from . import json
File "/usr/local/lib/python3.8/site-packages/flask/json/__init__.py", line 15, in <module>
from itsdangerous import json as _json
ImportError: cannot import name 'json' from 'itsdangerous' (/usr/local/lib/python3.8/site-packages/itsdangerous/__init__.py)[ 원인 ]
: flask 를 설치하면 기본적으로 설치 되는 itsdangerous 모듈이 하위 버전이라서 itsdangerous 에서 json 을 확장할 수 없는 오류이다.
[ 대응 ]
: requirements.txt에 itsdangerous==2.0.1 을 추가 한다.
(추가로, faker==8.3.0 도 같이 추가해준다.)
3) requirements.txt 수정
: 위 오류를 모두 대응하기 위해 requirements.txt 를 아래와 같이 수정하면 된다.
# /data-pipelines-with-apache-airflow/chapter03/docker/events-api/requirements.txt
click==7.1.2
faker==8.3.0
flask==1.1.2
itsdangerous==2.0.1
pandas==1.1.3
numpy==1.19.5
Jinja2==2.11.3
MarkupSafe==2.0.1
Werkzeug==1.0.1
python-dateutil==2.8.24) docker-compose 빌드
: 위 내용을 모두 수정 하였다면, chapter03 경로에서 다시 docker-compose 명령어로 빌드 하면 된다.
# ./data-pipelines-with-apache-airflow/chapter03/
docker-compose up --build # 백그라운드에서 실행 시킬 경우 -d 옵션을 추가한다.: 정상적으로 빌드 되면 아래와 같이 chapter03 에 해당하는 컨테이너 5개가 실행 될 것이다. chapter03-init-1 컨테이너는 init 후 셧다운 되므로 해당 컨테이너가 실행 되지 않아도 신경쓰지 말자.
# docker ps 명령어 실행
CONTAINER ID IMAGE COMMAND PORTS NAMES
c064ecf19fc1 manning-airflow/airflow-data "/usr/bin/dumb-init …" 8080/tcp chapter03-scheduler-1
f9ff4d6fafe0 manning-airflow/airflow-data "/bin/bash -c 'airfl…" chapter03-init-1
46bec22aea27 manning-airflow/airflow-data "/usr/bin/dumb-init …" 0.0.0.0:8080->8080/tcp chapter03-webserver-1
6f962352bb67 postgres:12-alpine "docker-entrypoint.s…" 0.0.0.0:5432->5432/tcp chapter03-postgres-1
ebce6bd13032 manning-airflow/events-api "python /app.py" 0.0.0.0:5007->5000/tcp chapter03-events_api-13. API 테스트
: chapter03 에서 제공하는 api(chapter03-events_api-1) 를 사용해보고 정상적으로 호출 된다면 본격적으로 chapter03 을 시작할 수 있다. api 호출 시 docker-compose.yml 에서 수정했던 api 포트를 꼭 기억하길 바란다.
API 호출
: API 호출 후 반환 되는 데이터는 data-pipelines-with-apache-airflow/chapter03/docker/events-api/app.py 경로에서 생성하며, 2019년 01월 05일을 기준으로 30일 전까지의 임의 사용자 이벤트 로그이다.
curl http://localhost:5007/events
[{"date":"Thu, 06 Dec 2018 00:00:00 GMT","user":"17.149.126.122"},
...
{"date":"Fri, 04 Jan 2019 00:00:00 GMT","user":"218.141.141.249"}
,{"date":"Fri, 04 Jan 2019 00:00:00 GMT","user":"181.77.7.69"}
,{"date":"Fri, 04 Jan 2019 00:00:00 GMT","user":"90.191.242.202"}]API 데이터 시점 변경하기
: 이 게시물을 수정하고 있는 날짜인 2023년 06월 30일을 기준으로 30일 전까지의 사용자 데이터가 생성 될 수 있도록 app.py 코드를 살짝 바꿔보겠다.
# data-pipelines-with-apache-airflow/chapter03/docker/events-api/app.py
# 변경 전
app.config["events"] = _generate_events(end_date=date(year=2019, month=1, day=5))
# 변경 후
app.config["events"] = _generate_events(end_date=date(year=2023, month=6, day=30))수정 후 chapter03/ 경로에서 docker-compose down 명령어로 컨테이너를 내려주고 다시 docker-compose up --build 해주면 된다. 그리고 api 를 다시 호출해 보면 아래와 같이 데이터의 "date" 필드의 날짜가 변경 되어 반환 되는 것을 확인할 수 있다.
curl http://localhost:5007/events
[{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"207.170.133.229"},
{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"214.103.176.75"},
{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"204.140.126.193"},
...
{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"157.215.154.254"},
{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"70.135.229.39"},
{"date":"Wed, 31 May 2023 00:00:00 GMT","user":"158.66.46.76"}]4. 01_unscheduled.py 코드 이해하기
: chapter03 에서는 chapter03-events_api-1 컨테이너로 events api 를 호출하여 사용자 로그를 가져온 후 분석 결과를 도출하는 흐름으로 설명이 진행된다. 01_unscheduled.py 코드를 보면서 task 순서를 인지하고 다음 순서로 넘어가면 좋을 것 같다.
내가 01_unscheduled.py 에서 수정한 코드
: Airflow 2의 기본 timezone 은 UTC 이다. 때문에, 스케줄링 개념 이해에 방해 받지 않도록 아래 코드를 추가하여 timezone 을 Asia/Seoul로 지정하였다. 그리고 start_date 값을 2023년 06월 25일로 수정 하였다.
- start_date: Airflow Dag 가 처음 실행 되는 시점이다.
# data-pipelines-with-apache-airflow/chapter03/dags/01_unscheduled.py
import pendulum # 코드 추가
kst_tz = pendulum.timezone("Asia/Seoul") # 코드 추가
dag = DAG(
dag_id="01_unscheduled",
start_date=datetime(2023, 6, 25, tzinfo=kst_tz), # 코드 수정
schedule_interval=None
)코드 수정 후 http://localhost:8080/code?dag_id=01_unscheduled 로 접속하여 변경된 코드가 잘 적용 되었는지 확인해보자.
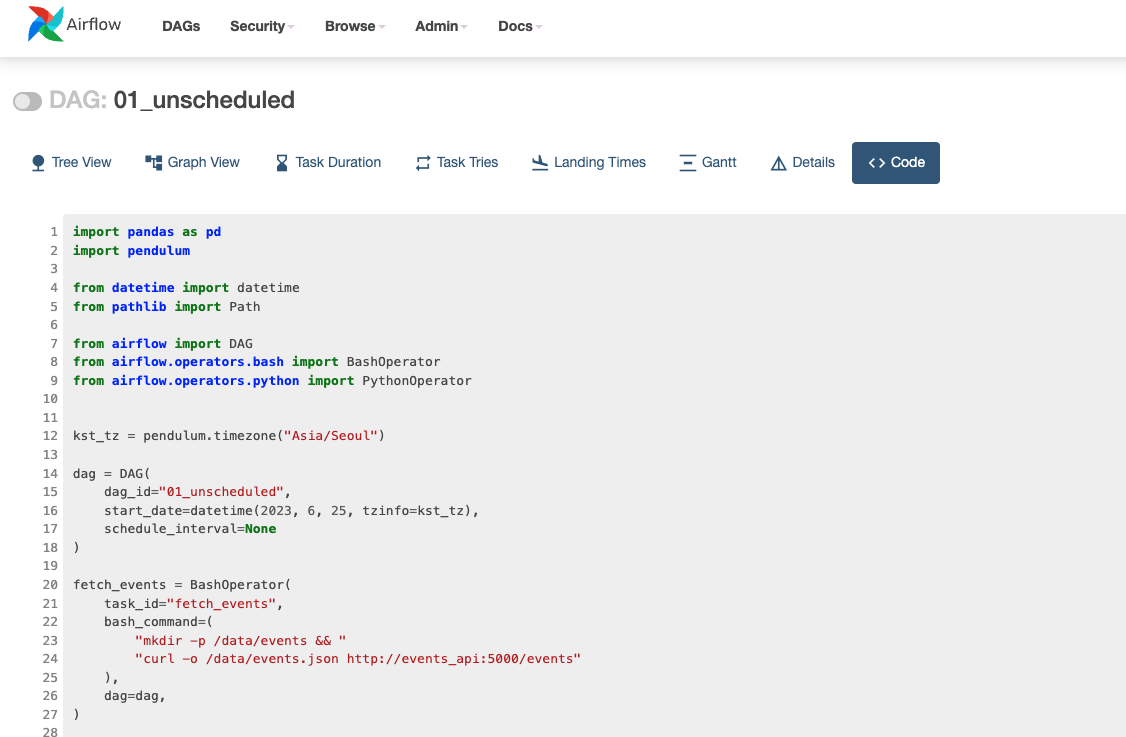
DAG 코드 분석
Airflow DAG 정의를 위한 라이브러리 호출
''' Airflow 를 정의하기 위한 라이브러리 호출 '''
import pandas as pd
import pendulum
from datetime import datetime
from pathlib import Path
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperatorDAG 객체 정의
: DAG 객체에 schedule_interval 값을 None 으로 지정하여 직접 트리거 해야 실행 되도록 한다
''' Airflow DAG 객체 정의 및 타임존 지정'''
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="01_unscheduled",
start_date=datetime(2023, 6, 25, tzinfo=kst_tz),
schedule_interval=None
)BashOperator - fetch_events task 정의
: /data/events 디렉토리를 생성한 후 curl 명령어로 api 를 호출하여 반환 된 데이터를 /data/events.json 파일로 저장하는 작업을 fetch_events 라는 Task 로 정의하였다. 이 때, api 는 같은 컨테이너 내부에서 호출 하기 때문에 포트번호를 5007 이 아니라 5000 으로 기입해야 한다.
fetch_events = BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data/events && "
"curl -o /data/events.json http://events_api:5000/events"
),
dag=dag,
)PythonOperator - calculate_stats task 정의
: PythonOperator 가 실행 될 때 _calculate_stats() 함수가 실행 되도록 python_callable 인자로 해당 함수를 넘겨주고, 해당 함수에 파라미터를 op_kwargs 에 지정하였다. 해당 task 의 기능 설명은 아래 주석을 참고하자.
def _calculate_stats(input_path, output_path):
"""Calculates event statistics."""
# output_path("/data/stats.csv")의 부모 경로("data/")가 존재하는지 확인하고 없으면 생성
Path(output_path).parent.mkdir(exist_ok=True)
# input_path("/data/events.json") 을 pandas DF 로 생성
events = pd.read_json(input_path)
# "date", "user"를 기준으로 그룹핑 하여 카운트
stats = events.groupby(["date", "user"]).size().reset_index()
# 결과를 output_path 에 저장
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
op_kwargs={"input_path": "/data/events.json", "output_path": "/data/stats.csv"},
dag=dag,
)Task 실행 순서 정의
fetch_events >> calculate_stats4. 01_unscheduled.py 코드 실행하기
: 해당 DAG 는 schedule_interval 값이 None 이기 때문에 Airflow WEB UI 에서 DAG 를 활성화 하여도 실행 되지 않는다. DAG 활성화 후 아래 이미지와 같이 직접 트리거 해주면 된다.
WEB UI 에서 DAG 트리거 하기
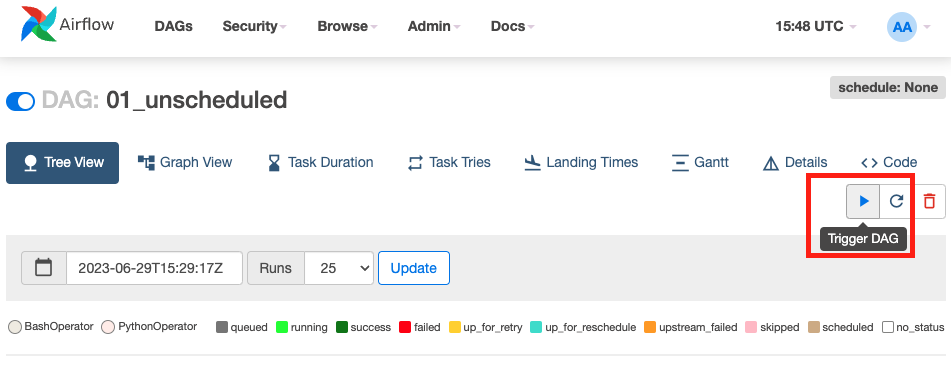
🤔 참고: Configureation JSON 영역에 설정 값을 추가하여 DAG 에서 유동적으로 인자 값을 받을 수 있도록 할 수 있다.(지금은 아래 이미지 처럼 비워두고 진행 하면 된다.)
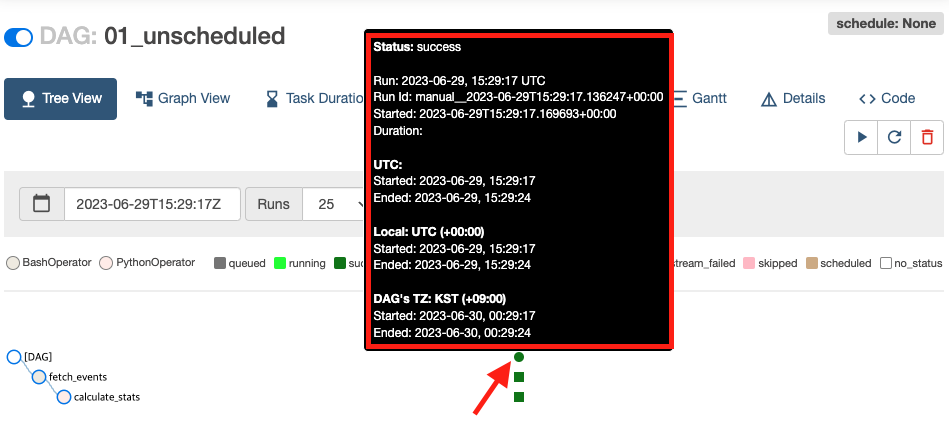
DAG 실행 상태 확인
: 아래 이미지 처럼 Tree View 화면에서 실행 내역에 마우스 커서를 올리면 실행 상태 정보를 확인할 수 있따. 각 Task 모두 Success 상태인 것을 볼 수 있다.
DAG 실행 결과물 확인
: DAG 가 정상적으로 실행 된 것을 확인 하였으니, 실제 경로에 파일이 잘 생성 되었는지 docker 컨테이너에 접속해서 확인해 보겠다.
# 스케줄러 컴포넌트 컨테이너에 접속
$ docker exec -it chapter03-scheduler-1 /bin/bash
# 데이터 저장 경로로 이동 후 파일 조회
$ cd /data && ls
events events.json stats.csv
# 집계 데이터 확인
$ cat stats.csv
2023-06-03 00:00:00+00:00,183.238.0.157,20
2023-06-03 00:00:00+00:00,184.90.98.54,18
2023-06-03 00:00:00+00:00,185.134.124.27,27
2023-06-03 00:00:00+00:00,186.10.161.62,22
2023-06-03 00:00:00+00:00,186.214.184.105,29
...5. DAG 스케줄링하기
: 01_unscheduled.py 에서는 schedule_interval 값을 None 으로 설정 했기 때문에 직접 트리거하지 않으면 DAG 가 실행하지 않았다. 이제는 DAG 의 schedule_interval 값을 지정하여 정기적으로 실행 될 수 있도록 Airflow 의 스케줄링에 대해 알아보자.
매일 DAG 실행하는 방법(with. "@daily")
: 매일 자정(00시 00분 00초)에 일 배치로 실행되도록 하려면 아래 예제 처럼 schedule_interval 값을 @daily 문자열로 지정해주면 된다.
# @daily 예제
dag = DAG(
dag_id="01_unscheduled",
schedule_interval="@daily"
)DAG class 확인해보기
: 그렇다면, @daily 는 실제로 어떻게 수행 되는걸까? 상위 클래스의 소스를 확인해보자.
아래 코드를 보면, DAG class 객체를 선언 하면서 사용자가 지정한 schedule_interval 인자 값을normalized_schedule_interval 함수 내부의cron_presets.get(self.schedule_interval) 부분에서 처리한다.
# dap.py
@functools.total_ordering
class DAG(LoggingMixin):
...
@property
def normalized_schedule_interval(self) -> ScheduleInterval:
warnings.warn(
"DAG.normalized_schedule_interval() is deprecated.",
category=RemovedInAirflow3Warning,
stacklevel=2,
)
if isinstance(self.schedule_interval, str) and self.schedule_interval in cron_presets:
_schedule_interval: ScheduleInterval = cron_presets.get(self.schedule_interval)
elif self.schedule_interval == "@once":
_schedule_interval = None
else:
_schedule_interval = self.schedule_interval
return _schedule_interval
그렇다면, cron_presets 가 무엇인지 확인해보자. dag 패키지에서는 from airflow.utils.dates import cron_presets, date_range as utils_date_range 와 같이 dates 의 cron_presets 를 확장하고 있다. cron_presets 를 확인하면 아래와 같이 Dict 변수로 정의 되어 있다. 때문에, @daily 로 schedule_interval 값을 설정하면 cron 규칙을 사용하여 0 0 * * * 간격으로 DAG 가 실행된다.
# dates.py
cron_presets: dict[str, str] = {
"@hourly": "0 * * * *",
"@daily": "0 0 * * *",
"@weekly": "0 0 * * 0",
"@monthly": "0 0 1 * *",
"@quarterly": "0 0 1 */3 *",
"@yearly": "0 0 1 1 *",
}"@daily" 스케줄링 테스트
: 이번에는 data-pipelines-with-apache-airflow/chapter03/dags/02_daily_schedule.py 파일에서 schedule_interval, start_date, end_date 값을 아래 코드와 같이 수정하면 어떻게 동작 하는지 확인해보자.
# data-pipelines-with-apache-airflow/chapter03/dags/02_daily_schedule.py
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="02_daily_schedule",
schedule_interval="@daily",
start_date=datetime(2023, 6, 20, tzinfo=kst_tz),
end_date=datetime(2023, 6, 30, tzinfo=kst_tz),
)🤔 참고: 당연히 코드 수정 후 Airflow WEB UI 에서 02_daily_schedule DAG 를 활성화 해주어야 한다. 또한, end_date 는 DAG 마지막 실행 시점을 의미한다.
02_daily_schedule DAG 실행 상태 확인
: 아래 이미지와 같이 2023-06-20 ~ 2023-06-30 까지 10개의 DAG 가 실행된 것을 볼 수 있다. 즉, start_date 와 end_date 사이 기간 동안 schedule_interval 로 지정한 간격 만큼 DAG 가 실행 된다는 것을 눈으로 확인해 보았다.
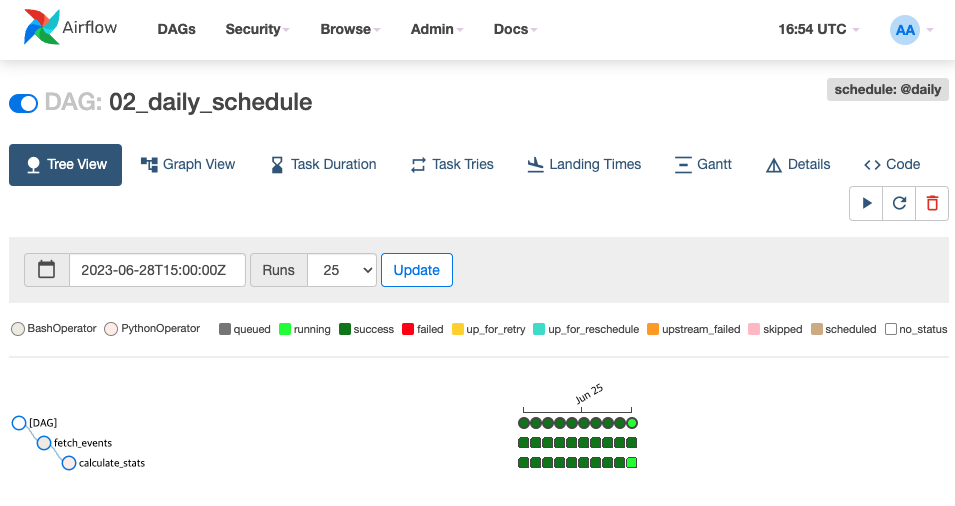
🤔 참고: 만약 end_date 값이 설정 되어 있지 않다면, start_date 를 기준으로 현재 시점까지 schedule_interval 간격만큼 실행 된다.
6. 스케줄 간격(schedule_interval)에 따라 DAG 가 실행 되는 시점
: schedule_interval 값을 @daily(0 0 * * *) 으로 지정하고, start_date 값을 2023년 06월 20일로 지정 했을 때, DAG가 최초로 실행 되는 실제 시점은 언제일까? 바로, 2023년 06월 21일 자정이다.(책 44p 참고)
처음에 이 개념이 잘 이해 되지 않겠지만, 아래 그림을 보면 이해하기 쉽다.
2023-06-21 00:00:00 에 "2023-06-20 00:00:00 ~ 2023-06-20 23:59:59" 범위로 DAG 가 실행 되는 것이다. 즉, 첫 번째 실행 시점 = start_date + schedule_interval 이다.

🤔 참고: 만약, start_date 가 2023-06-20 이고, schedule_interval 이 @houry(0 * * * *) 라면 첫 번째 실행 시점 은 2023-06-20 00:00:00 + @houry(0 * * * *) 더한 시점인 2023년 06월 20일 01시 00분 00초 이다.
7. Cron 기반의 스케줄 간격 설정하기
: 위에서 schedule_interval 을 @daily, @hourly 와 같이 지정 했을 때 클래스 내부적으로 인자 값이 cron 기반의 규칙으로 동작하는 것을 알 수 있었다. 실제로, @daily 와 같이 cron_preset 를 사용하는 것보다 cron 규칙을 직접 사용하는 경우가 더 많다.
# 개념
*(분, 0~59) *(시, 0~23) *(일, 1~31) *(월, 1~12) *(요일, 0~6 = 일~토)
# 예시
0 * * * * # 매시간 정각에 실행 -> 0시, 1시, 2시, 3시 4시... 실행
0 3 * * * # 매일 3시 정각에 실행 -> 매일 3시 00분에 실행
0 3 5 * * # 매월 5일 3시 정각에 실행 -> 1월 5일 3시 00분에 실행, 2월 5일 3시 00분에 실행
0 3 5 1 * # 매년 1월 5일 3시 정각에 실행 -> 2022년 1월 5일 3시 정각에 실행, 2023년 1월 5일 3시 정각에 실행# cron 기반의 스케줄 간격 설정하기
dag = DAG(
dag_id="cron_example",
schedule_interval="20 * * * *", # 매시간 20분에 실행
start_date=dt.datetime(year=2019, month=1, day=1),
end_date=dt.datetime(year=2019, month=1, day=5),
)8. 빈도 기반의 스케줄 간격 설정하기
: Cron 기반으로 스케줄 하지 않고, 3일마다 task를 실행하는 방법은 아래 예제와 같이 datetime 의 timedelta 를 이용할 수 있다.
# data-pipelines-with-apache-airflow/chapter03/dags/04_time_delta.py
import pendulum
from datetime import datetime
from datetime import timedelta
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="04_time_delta",
schedule_interval=timedelta(days=3),
start_date=datetime(year=2023, month=6, day=20),
end_date=datetime(year=2023, month=6, day=25),
)🤔 왜? Cron 기반으로 빈도 기반의 스케줄을 완벽히 대체할 수 없을까?
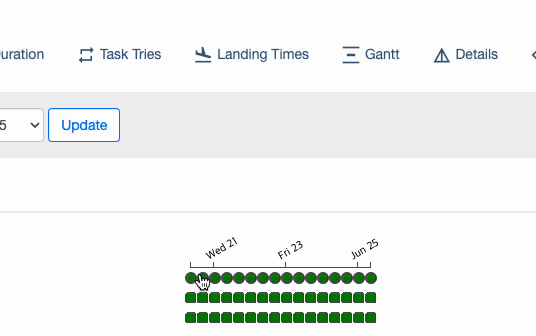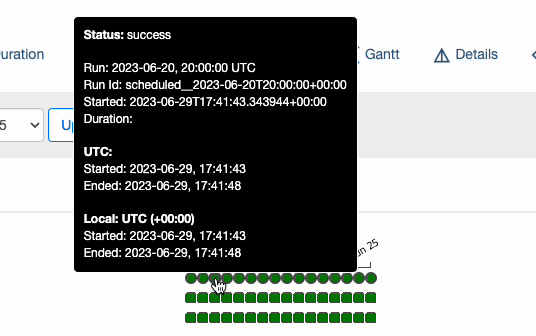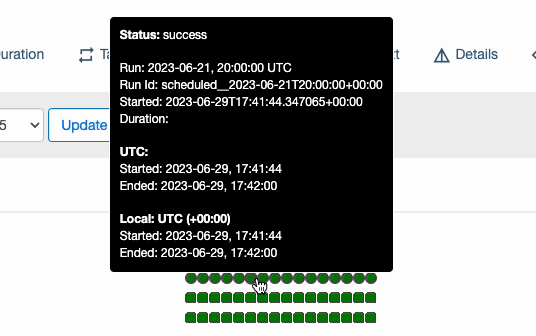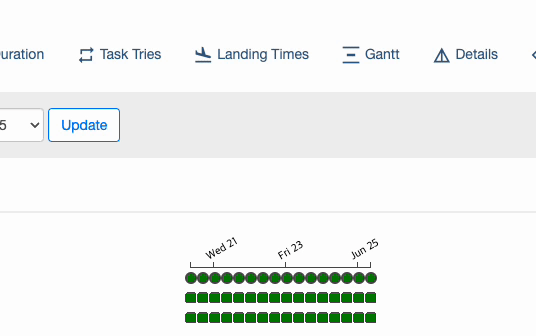
: Cron 기반으로도 간격을 설정할 수 있지만 완벽하지 않다. 예를 들어, 아래와 같이 실행 간격을 0 */10 * * * 라고 설정하여 10시간 마다 정각에 실행하길 기대할 수 있지만, 실제로 수행 되는 시점은 00시, 10시, 20시, 00시, 10시, 20시...를 반복한다. 반면에, datetime.timedelta(hours=10) 로 설정하면 시작 시점을 기준으로 정확히 10시간 간격으로 실행된다.
# Cron 기반 간격 설정
dag = DAG(
dag_id="test_my_dag",
schedule_interval="0 */10 * * *",
start_date=datetime(2023, 6, 20),
end_date=datetime(2023, 6, 25),
)
# 실행 시점
2023년 6월 20일 00:00
2023년 6월 20일 10:00
2023년 6월 20일 20:00
2023년 6월 21일 00:00
2023년 6월 21일 10:00
2023년 6월 21일 20:00
...
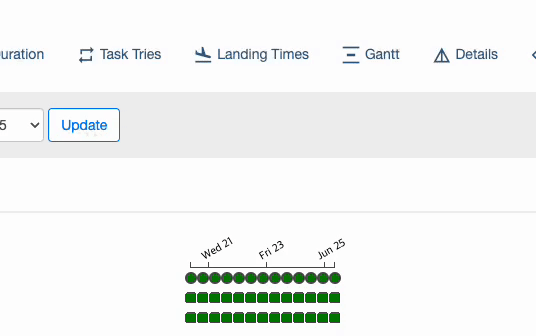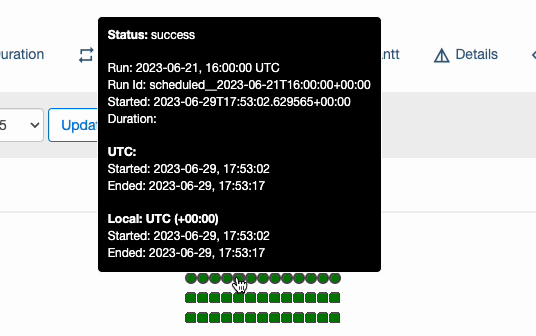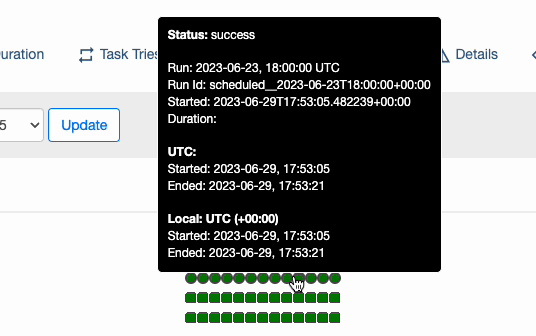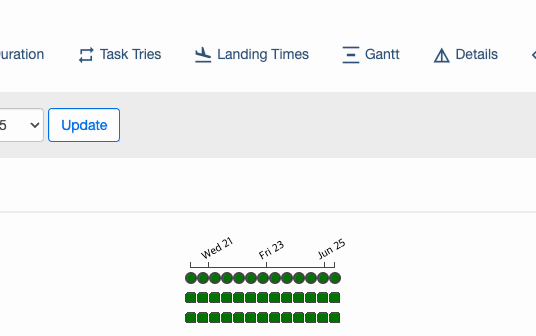
# 빈도 기반 간격 설정
from datetime import datetime
from datetime import timedelta
dag = DAG(
dag_id="04_time_delta",
schedule_interval=timedelta(days=3),
start_date=datetime(year=2023, month=6, day=20),
end_date=datetime(year=2023, month=6, day=25),
)
2023년 6월 20일 00:00
2023년 6월 20일 10:00
2023년 6월 20일 20:00
2023년 6월 21일 06:00
2023년 6월 21일 16:00
2023년 6월 22일 02:00
...
9. 데이터 증분 처리하기
: 위에서 start_date 와 end_date 사이에 schedule_interval 간격 만큼 task 가 동작하는 것을 보았다. 그렇다면, 시간 간격 마다 각 task 에서 데이터를 증분 처리하는 방법은 무엇일까?
예를 들어, where yyyymmdd = '2023-06-20' 와 같이 일단위로 매일 증분 처리하는 SQL 용 DAG가 있는 경우에는 '2023-06-20' 을 하드코딩 하지 않고, 아래 예시와 같이 DAG 실행 시간을 인자로 받아서 처리할 수 있도록 만들면 될 것이다.
# 소스
# SQL 쿼리
my_query = f'''
INSERT ...
SELECT * FROM MY_TABLE
WHERE where yyyymmdd = "{target_date}"
'''
# 실행
2023년 06월 20일 실행 -> where yyyymmdd = '2023-06-20'(실제 실행 시점: 21일 00시)
2023년 06월 21일 실행 -> where yyyymmdd = '2023-06-21'(실제 실행 시점: 22일 00시)
2023년 06월 22일 실행 -> where yyyymmdd = '2023-06-22'(실제 실행 시점: 23일 00시)
...API 에서 특정 날짜의 데이터 조회하기
: chapter03-events_api-1 컨테이너에서 동작 중인 API 에 start_date, end_date 값을 get 파리미터로 넘겨서 시간 범위 만큼의 데이터를 조회할 수 있다. 아래 예제와 같이 API 를 호출 할 경우 2023년 06월 20일 하루에 해당하는 데이터를 반환 받을 수 있다.
# API 호출 테스트
curl http://localhost:5007/events?start_date=2023-06-20&end_date=2023-06-2106_templated_query.py 사용하기
: Airflow 에서는 jinja 문법을 사용하는 template 개념을 지원한다. 어떻게 사용하는 것인지 바로 06_templated_query.py 예제를 보면서 이해해보자.
# data-pipelines-with-apache-airflow/chapter03/dags/06_templated_query.py
'''2023-06-20 부터 2023-06-25 까지 매일 자정에 DAG 수행'''
dag = DAG(
dag_id="06_templated_query",
schedule_interval="@daily",
start_date=dt.datetime(year=2023, month=6, day=20),
end_date=dt.datetime(year=2023, month=6, day=25),
)
'''bash_command 부분에 {{execution_date}} 템플릿을 사용한다.'''
fetch_events = BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data/events && "
"curl -o /data/events.json "
"http://events_api:5000/events?"
"start_date={{execution_date.strftime('%Y-%m-%d')}}&" # (실제 실행 날짜 - 1일) 값을 의미하는 날짜를 문자열 '%Y-%m-%d' 로 변환하여 start_date 파라미터 값으로 넣겠다는 의미
"end_date={{next_execution_date.strftime('%Y-%m-%d')}}" # 실제 실행 날짜 값을 의미하는 날짜를 문자열 '%Y-%m-%d' 로 변환하여 end_date 파라미터 값으로 넣겠다는 의미
),
dag=dag,
)🤔 만약, 위 코드와 같이 작성하고 Dag 를 활성화 하면 어떻게 동작할까?
- 실제 Dag 가 스케줄링 되어 시작(실행) 하는 시점: 2023년 06월 21일 00시 00분 00초
- 2023년 06월 21일 00시 00분 00초에 {{ execution_date }} 값: 20230620
즉, execution_date = 스케줄링 시작 시점 - schedule_interval 라고 생각하면 된다.
템플릿을 사용하는 이유(ex. execution_date)
: 굳이, 개념 헷갈리게 execution_date 와 같은 템플릿을 사용하는 이유는 무엇일까? 만약, 매일 배치가 무조건 수행에 성공한다면 배치 실행 시 now() 시간을 사용하여 데이터를 증분 처리 할 수 있을 것이다. 그런데, 만약 배치에 수행이 실패하고 다음 시간으로 넘어갔거나, 과거 시점의 배치를 다시 한 번 실행 해야할 경우에는 now() 로 당시 시간대의 데이터를 타겟팅 할 수 없다. Airflow 에서 execution_date 를 위에 06_templated_query.py 예제와 같이 사용하면, 각 배치 실행 시점에 스케줄 되었던 히스토리를 참조하여 execution_date 가 할당 된다. 그러면 우리는 별도 코드 수정 없이 Airflow WEB UI 에서만 배치를 다시 실행 시키면 된다.
execution_date 외 자주 사용 되는 템플릿
: Airflow 공식문서 - 템플릿 레퍼런스를 참고하면 좋다.
execution_date = 스케줄링 시작 시점 - schedule_intervalnext_execution_date = 스케줄링 시작 시점의prev_execution_date = 스케줄링 시작 시점 - schedule_interval - schedule_interval
나는 위에 3개를 가장 많이 사용중인데 해당 템플릿은 Airflow 버전에 따라 deprecated 된다고 한다. 공식문서를 참고하여 적절히 사용하면 될 것 같다. 또한, 내가 속한 팀에서는 DAG() 객체를 선언할 때 start_date, end_date 에 timezone 을 "Aisa/Seoul" 로 지정하는데 execution_date 를 사용할 때에도 동일하게 아래 예제와 같이 "Asia/Seoul" 로 지정하여 사용한다.
'''Airflow DAG 에 타임존 설정하기'''
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="02_daily_schedule",
schedule_interval="@daily",
start_date=datetime(2023, 6, 20, tzinfo=kst_tz),
end_date=datetime(2023, 6, 30, tzinfo=kst_tz),
)
fetch_events = BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data/events && "
"curl -o /data/events.json "
"http://events_api:5007/events?"
"start_date={{execution_date.in_timezone('Asia/Seoul').strftime('%Y-%m-%d')}}&"
"end_date={{next_execution_date.in_timezone('Asia/Seoul').strftime('%Y-%m-%d')}}"
),
dag=dag,
)10. 백필(Backfill) 사용하기
: “백필” 이란 단어 의미 그대로 재처리, 메우는 작업으로 이해할 수 있다. 과거 시점에 schduled 된 task 를 재실행하여, 변경된 분석 로직을 저장하거나 재처리하기 위해 사용 되는 프로세스 이다. 책에서는 catchup 설정에 대해서만 간략히 소개 하였는데, Airflow 에서는 백필 프로세스를 처리하기 위한 방법으로 catchup 외에도 backfill 커맨드도 중요 하므로 함께 요약 해보겠다.
catchup 개념
: start_date 가 2023-06-20 이고, schedule_interval 은 @daily 이면서, Dag 를 등록하는 현재 시점이 2023-06-25 일 때 catchup 이 true 로 활성화 되어 있다면, 2023-06-20 부터 @daily 간격으로 모든 Dag가 scheduled 된다. 만약, catchup 이 false 로 비활성화 되어 있다면, start_date 와 상관 없이 2023-06-25 것 부터 스케줄링 될 것이다.
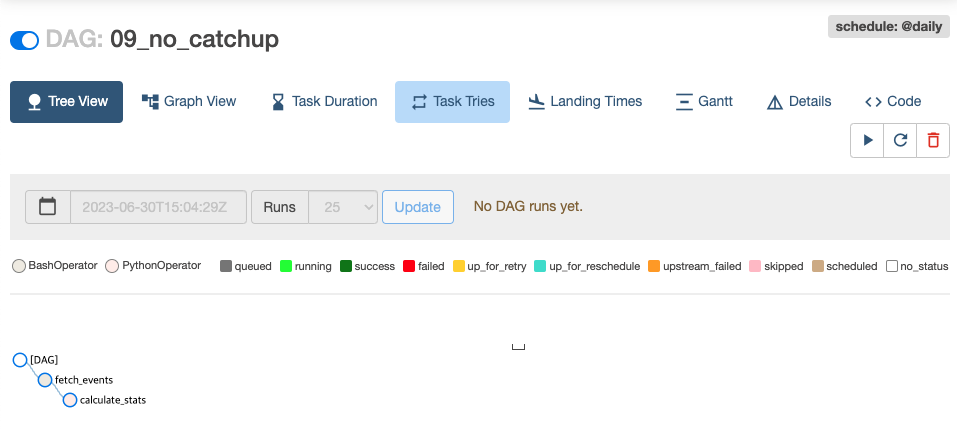
catchup False 일 때
: 아래 예제와 같이 09_no_catchup.py 에서 타임존만 지정해주고 catchup = False 상태로 Dag 를 활성화 해보겠다.
# data-pipelines-with-apache-airflow/chapter03/dags/09_no_catchup.py
import pendulum
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="09_no_catchup",
schedule_interval="@daily",
start_date=dt.datetime(year=2023, month=6, day=20, tzinfo=kst_tz),
end_date=dt.datetime(year=2023, month=6, day=25, tzinfo=kst_tz),
catchup=False,
)아래 이미 처럼 cathup 이 False 이면, Dag 를 새로 활성화 하여도 과거 시점은 스케줄링 하지 않는다.
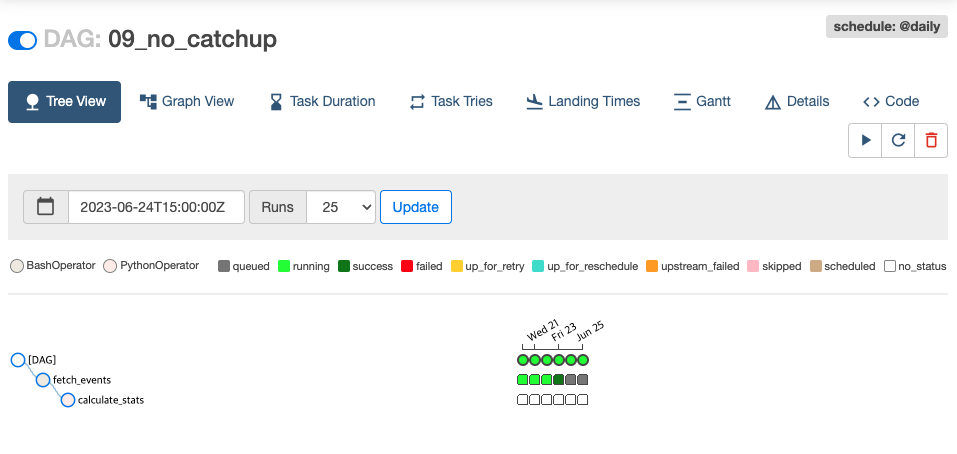
catchup True 일 때
: 이번에는 같은 09_no_catchup.py 에서 catchup = True 바꿔서 다시 활성화 해보겠다.
# data-pipelines-with-apache-airflow/chapter03/dags/09_no_catchup.py
import pendulum
kst_tz = pendulum.timezone("Asia/Seoul")
dag = DAG(
dag_id="09_no_catchup",
schedule_interval="@daily",
start_date=dt.datetime(year=2023, month=6, day=20, tzinfo=kst_tz),
end_date=dt.datetime(year=2023, month=6, day=25, tzinfo=kst_tz),
catchup=True,
)아래 이미지 처럼 cathup 이 True 이면, Dag 를 활성화 할 때 과거 시점부터 모두 스케줄링 된다.
catchup 을 True 로 사용하는 경우
: 여러 경우가 있겠지만, 예를 들면, 원래 Dag 에서 지정했던 start_date ~ end_date 범위보다 더 과거부터 start_date 를 설정하여 Dag 를 수행하고 싶을 때 사용하면 된다. 아래 코드와 같이 변경 하면 2022년 4월 13일 부터 2023년 6월 20일 전까지 모두 스케줄링 된다.
# 변경 전
dag = DAG(
dag_id="09_no_catchup",
schedule_interval="@daily",
start_date=dt.datetime(year=2023, month=6, day=20, tzinfo=kst_tz),
end_date=dt.datetime(year=2023, month=6, day=25, tzinfo=kst_tz),
catchup=True,
)
# 변경 후
dag = DAG(
dag_id="09_no_catchup",
schedule_interval="@daily",
start_date=dt.datetime(year=2022, month=4, day=13, tzinfo=kst_tz),
end_date=dt.datetime(year=2023, month=6, day=25, tzinfo=kst_tz),
catchup=True,
)backfill 개념
: catchup 과 비슷하지만, start_date, end_date 설정 범위와 상관 없이 Cli 에서 backfill 명령어를 사용하여 start_date, end_date 를 임의로 정하여 실행할 수 있다.
backfill 사용 방법
: backfill 은 아래 예제 처럼 Cli 에서 사용 가능하다. 다양한 옵션과 주의 사항이 있으므로 반드시, 링크 걸어둔 Backfill 공식 문서를 확인하길 바란다.
# 기본 사용 방법
$ airflow dags backfill \
--start-date START_DATE \
--end-date END_DATE \
dag_id
# 타임존을 설정하는 방법
airflow dags backfill \
--start-date 2023-06-20T00:00:00+09:00 \
--end-date 2023-06-25T00:00:00+09:00backfill 주의사항
-
한 번에 많은 task 가 실행 되므로, 서버에 부하가 생길 수 있다. 따라서 설정 옵션에서 동시성을 적절히 제한하여 사용해야한다.
(동시성을 제한하는 DAG 객체의 파라미터: concurrency, max_active_runs) -
catchup 설정으로 실행 되는 것은 web ui 상에서 scheduled 된 것을 확인할 수 있으나, cli 를 통해서 backfill 을 사용하면 별도 스케줄로 관리 되는 것 같다. (해당 부분은 향후 사용하면서 자세히 알아봐야겠다.)
11. 태스크 디자인을 위한 모범 사례
: Airflow Dag 를 개발 할 때 원자성, 멱등성을 보장할 수 있도록 개발하는 것이 중요하다.
📍 원자성
: 데이터베이스의 원자성 트랜잭션을 떠올리면 된다. 하나의 task에서 중간 작업이 실패 하였는데 마지막 작업은 성공하고 다음 task 가 실행 되도록 개발 되면 원자성이 파괴 된 상태 이다. 즉, task 에서 중간 작업이 실패 하였다면, 해당 task 전체가 실패 상태로 상태 값이 업데이트 되고, 다음 task 는 실행 되면 안 된다.
📍 멱등성
: Airflow의 성격상 execution_date 를 이용하여 catup, backfill 등의 처리를 하는 경우가 종종 있다. 이것 말고도 Dag로 생성한 데이터 마트에 문제가 있어 task 를 clear 한 후 재처리하는 경우도 있을 수 있다. 이런 경우 Dag를 재실행 할 때마다 데이터가 달라지면 서비스에 문제가 생길 수 있다. 각 스케줄된 dag는 재실행 하여도 동일한 결과를 보장할 수 있도록 멱등성을 보장 해야한다.
