 www.pubgesports.kr
www.pubgesports.kr
*저는 배틀그라운드 제작사, 게이머, 대회와 아무런 상관이 없읍니다.
이전 글에서 야심차게 배경설명을 했다. 사실 분석은 정말 쪼꼬맸는데.. 주변과 나 자신의 기대가 커져서 조금 더 이것저것 해보려고 하고 있는 중이다. 어떻게 설명하면 좋을지 잘 모르겠지만 일단 해본다.
 시작은 이랬다. 좋은 꿈을 꿨어야 했다.
시작은 이랬다. 좋은 꿈을 꿨어야 했다.
데이터를 받아 배웠던 내용들과 구글링을 이렇게 저렇게 버무려 가기 시작했다.
1. 데이터셋 확인 및 불러오기
- 제공받은 데이터는 PCS1, 2, 3 ASIA 경기의 한국 선발전 데이터
- 각 매치에 관한 일반 서머리 데이터 테이블과 각 매치의 슈팅(총기) 관련 데이터 테이블 두 가지가 있다. 미리 확보한 아래 데이터를 불러온다.
-matches.xlsx
-shooting.xlsx - PCS3 ASIA 한국 선발전을 거쳐 한국 대표로 선발된 팀이 2020. 11.에 PCS3 ASIA 대회를 함
- PCS3 ASIA 한국 대표 선발 팀은 아래와 같음
-OGN ENTUS(ENT)
-Afreeca Freecs(AF)
-Gen.G(GEN)
-GRIFFIN(GRF)
-VRLU GHIBLI(VLG)
-OP.GG SPORTS(OPGG)
테이블은 대략 아래와 같다.
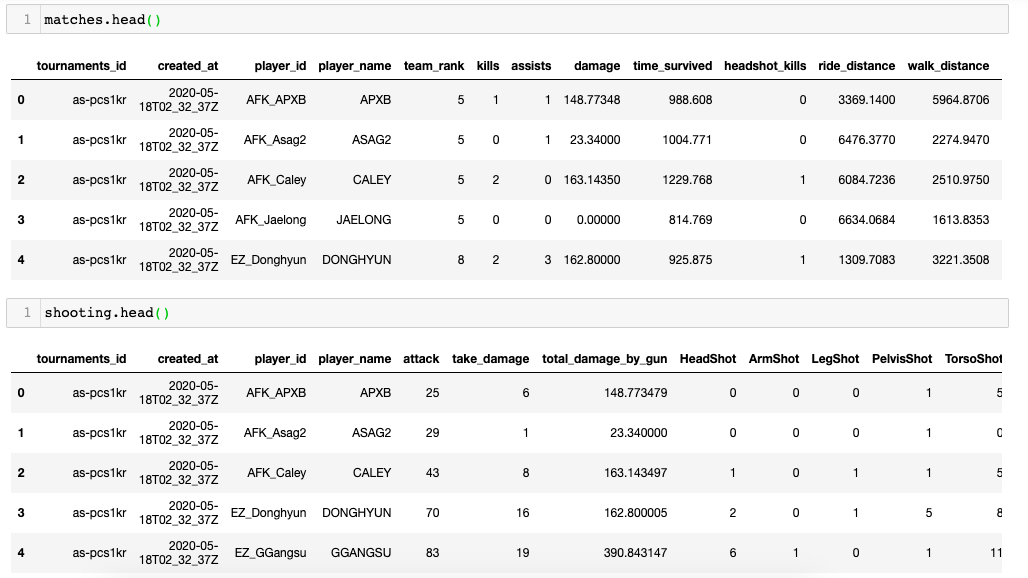
기본적으로 데이터프레임의 1개 행은 플레이어 1명의 1경기 관련 데이터다. matches.xlsx 데이터는 플레이어 아이디와 언제 한 경기인지를 비롯하여 팀 랭킹, 킬 수, 어시스트 수, 생존시간, 이동거리 등 경기 전반에 관한 한 플레이어의 정보를 담고 있다. 8614개의 행, 17개 열로 이루어져 있다. matches라는 변수에 할당했다.
shooting.xlsx 데이터는 그중에서도 게임의 핵심이라 할 수 있는 총기사용에 관한 데이터다. 총기를 활용한 공격 수, 상대에게 피해를 가한 수, 피해량, 부위별 명중 수 등을 담고 있다. 8178개의 행, 13개 열로 이루어져 있다. shooting이라는 변수에 할당했다.
데이터의 플레이어는 341명, 출전팀은 66개로 집계된다.
2. EDA (탐색적 데이터 분석)
2.1 플레이어별 유효공격 정도: kills, assists, damage
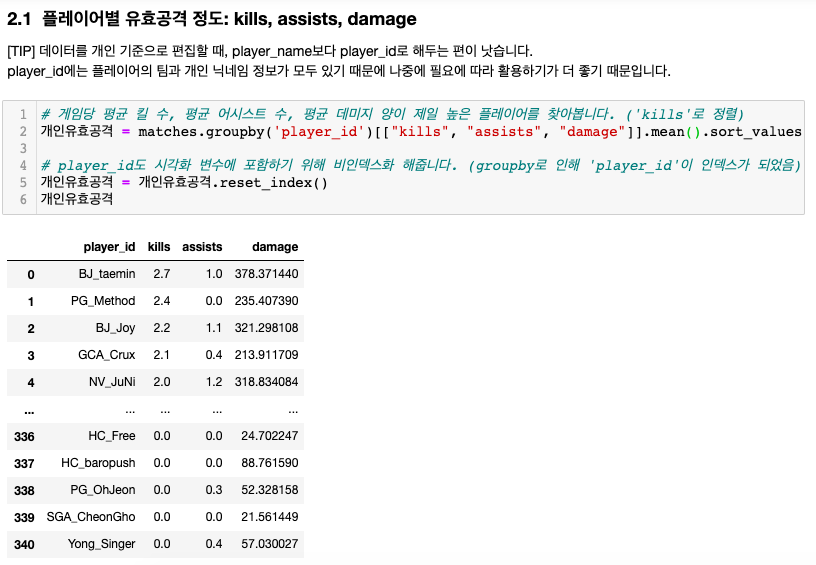
우선 개인별로 데이터가 마련되어 있으니, 개인 차원에서 어떤 경향을 보이는지 알고 싶었다. matches 테이블에서 게임당 평균 킬 수(kills), 평균 어시스트 수(assists), 평균 피해량(damage)을 구해 킬 실적 순으로 줄을 세워봤다.
341명의 플레이어 중 게임당 킬 성과가 가장 좋은 사람 누구야!?
 *말하고 넘어가고 싶었던 부분이 있다. 주피터 노트북에도 작게 적혀있는데, 전체 테이블을 보면
*말하고 넘어가고 싶었던 부분이 있다. 주피터 노트북에도 작게 적혀있는데, 전체 테이블을 보면 player_id와 player_name이 모두 존재한다. plyer_id는 사실상 "팀명_닉네임"으로 구성돼있는데, 개인 단위로 컬럼들을 간결하게 만들고 싶을 때 둘 중 어떤 걸 남기는 게 나을까? player_id다. 왜냐면 이건 나중에 팀명을 따로 떼어낼 수 있어 활용도가 높기 때문이다. 이걸 너무 늦게 깨달아서 player_name로 지지고 볶고 참 많이 했다.
TOP6 여러분 왜 아무도 없어?!
암튼, 표를 보면 조금 이상하다. player_id의 팀명 부분을 보자. 잘한 순서대로라면 한국대표로 뽑힌 6개팀 이름이 주로 보여야 하는 거 아닌가? 서머리에서는 하나도 보이지 않는다.
위에 언급한 세 가지 요소로 K-means 클러스터링을 해봤다. 그럼 잘 하는 애들 그룹이 좀 나눠지지 않을까.
from sklearn.cluster import KMeans
import plotly.express as px
X = 개인유효공격[['kills', 'assists', 'damage']]
kmeans = KMeans(n_clusters=8, random_state=0).fit(X)
fig = px.scatter(
개인유효공격, x = 'damage', y='kills', hover_data=['player_id'], color=kmeans.labels_)
fig.show()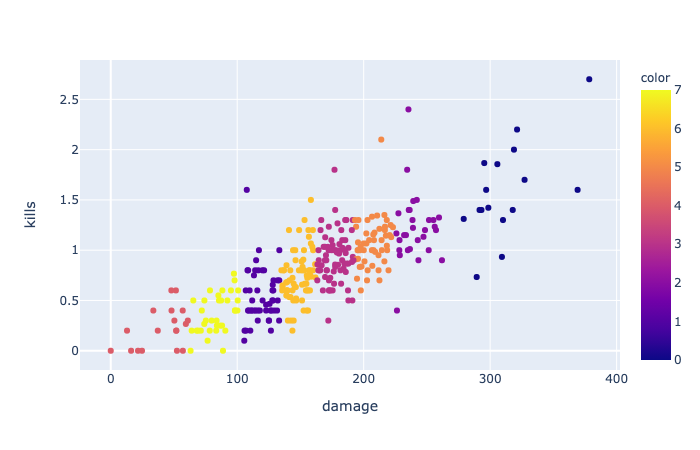 아쉽게도 이미지에 누가 누군지 나타나진 않지만, 표 상에서 상위 5위 안에 들었던 초멘 플레이어들이 가장 오른쪽 클러스터(잘하리라 짐작되는) 분포해있다. 이상하게도 우리의 톱6(ENT, GEN, OPGG, GRF, VLG, AF)는 잘 존재하지 않는다.
아쉽게도 이미지에 누가 누군지 나타나진 않지만, 표 상에서 상위 5위 안에 들었던 초멘 플레이어들이 가장 오른쪽 클러스터(잘하리라 짐작되는) 분포해있다. 이상하게도 우리의 톱6(ENT, GEN, OPGG, GRF, VLG, AF)는 잘 존재하지 않는다.
앗, 뽀록의 함정
사실 이 부분은 '경기 참여 수'를 고려하지 않았을 때 일어나는 현상이다. 많게는 총 100회까지 토너먼트를 치른 플레이어와 10회 이하를 치른 선수의 데이터가 같이 있다면? 후자가 어떤 식으로든 되게 잘한 한 번은 있을 수 있다.
팀 단위로 조금 더 살피면서 경기 참여 수 부분을 조정해봐야겠다고 생각했다. 아래에서는 드러나지 않지만 이후 판다스 쿼리를 통해 매치 수 50 이상의 플레이어 데이터만 추렸다.
2.2 팀별 유효공격 정도: kills, assists, damage
전처리가 고됐지만, 결과와 설명 먼저 투척해둔다.
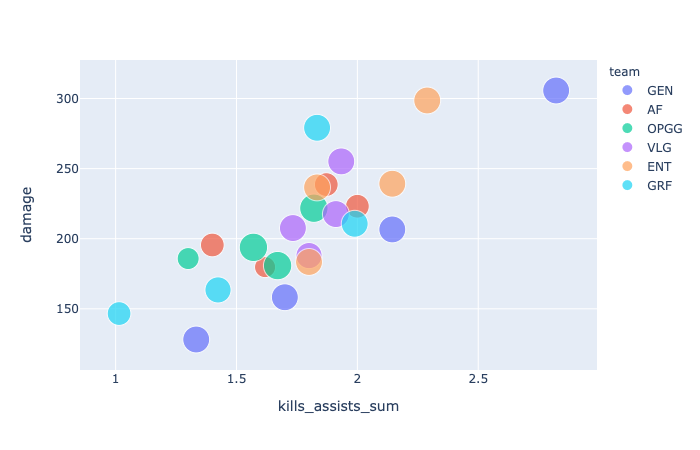
위 시각화를 통해 전반적인 개별 플레이어의 역량과 팀플레잉 정도를 파악할 수 있다.
- 위 그래프에서 동그라미 하나는 플레이어 한 명을 가리키며, 색깔은 각팀을 나타낸다.
- x축은 한 게임당 킬, 어시스트 합의 평균이고, y축은 한 게임에서 일으킨 데미지 양이다.
- 원의 크기는 참여 게임 수라 여기선 크게 중요하진 않다.
TOP6 팀별 특징 정리 1
- GEN (군청색 원): 독보적인 플레이어 PIO가 존재하나, 선수별 역량 차가 큽니다. 스타플레이어의 기여가 큰 것으로 보입니다.
- ENT (주황색 원): 뛰어난 플레이어 UNDER를 기반으로 전반적인 플레이어의 역량이 높습니다. 모 설명 영상에서 '구멍이 없다'고 한 말이 떠오릅니다.
- GRF (하늘색 원): 2HEART가 데미지 정도에서 뛰어난 역량을 보이나 MINSUNG 이후 플레이어 간의 격차가 있는 편입니다.
- VLG (보라색 원): ENT보다는 떨어지지만, 전반적으로 역량이 매우 뛰어나며, 팀원 간 격차가 가장 적은 편에 속합니다.
- AF (다홍색 원): EJ와 HANSIA가 훌륭한 플레이를 보이나 역시 팀원간 격차가 드러납니다. 표 상에서는 팀내 3위인 SHADOW까지만 보이네요.
- OPGG (녹색 원): 팀내 선두를 달리는 AYOH가 안정적인 실적을 보이고 DUMBO와 SILKY가 그 뒤를 받치고 있으나 ENT, VLG보다는 확실히 약세입니다.
이 내용들을 기반으로 당신은 이들 중 2위를 예측할 수 있겠는가? 다음을 더 보자
2.3 팀별 총기 유효공격 정도: attack, take_damage, total_damage_by_gun
이번엔 matches가 아닌 shooting 데이터를 활용해 2.2와 유사한 작업을 해봤다.
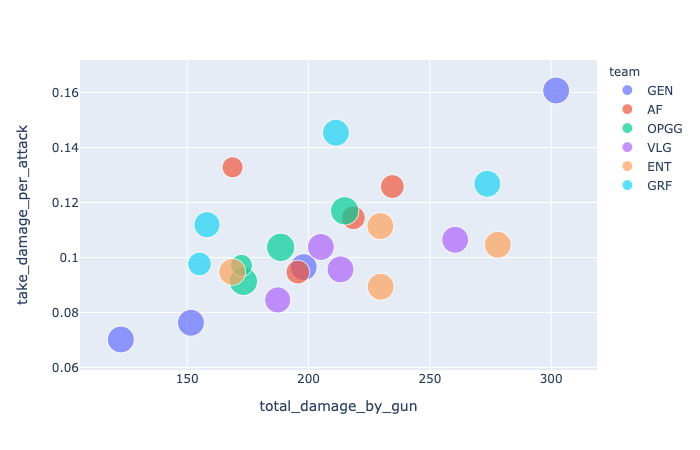
위 시각화를 통해서도 전반적인 개별 플레이어의 역량과 팀플레잉 정도를 파악할 수 있다.
- 위 그래프에서 동그라미 하나는 플레이어 한 명을 가리키며, 색깔은 각팀을 나타낸다.
- x축은 한 게임당 총기로 일으킨 데미지 양의 평균이고, y축은 한 게임에서 공격 시도 대비 데미지를 입힌 정도이다.
- 원의 크기는 참여 게임 수라 여기선 크게 중요하진 않다.
TOP6 팀별 특징 정리 2
- GEN (군청색 원): 여기서도 PIO는 독보적입니다. 하지만 역시 선수별 역량 차가 큰 것을 재확인할 수 있습니다.
- ENT (주황색 원): 전반적으로 총기 명중률이 높진 않아보이지만, 기본 평균 이상입니다. UNDER의 총기 총 데미지량이 매우 높은 편입니다.
- GRF (하늘색 원): 2HEART가 총 데미지와 명중률에서 뛰어난 역량을 보이고 MINSUNG은 명중률이 높은 신중한 플레이를 하는 것으로 보입니다. 멤버간 편차가 있는 편입니다.
- VLG (보라색 원): 여기서도 팀원 간 격차가 가장 적은 것으로 보이고, ENT보다 밀집도가 높습니다. HIKARI가 뛰어난 역량을 보입니다.
- AF (다홍색 원): 전반적인 실적이 좋은 편이나 두드러지는 플레이어(EJ)가 상대적으로 덜 명확합니다. DAENGCHAE의 명중률이 높은 편입니다.
- OPGG (녹색 원): 이 기준으로는 AF보다 약간 약세지만, 선수별 성과가 고루 분포되어 있습니다.
여기까지 봤을 때는 어떤가. 사실 서로 다른 두 데이터 시각화는 비슷한 경향을 보이고 있다. 서로 영향을 줄 수 밖에 없는 변수들이기 때문이다.
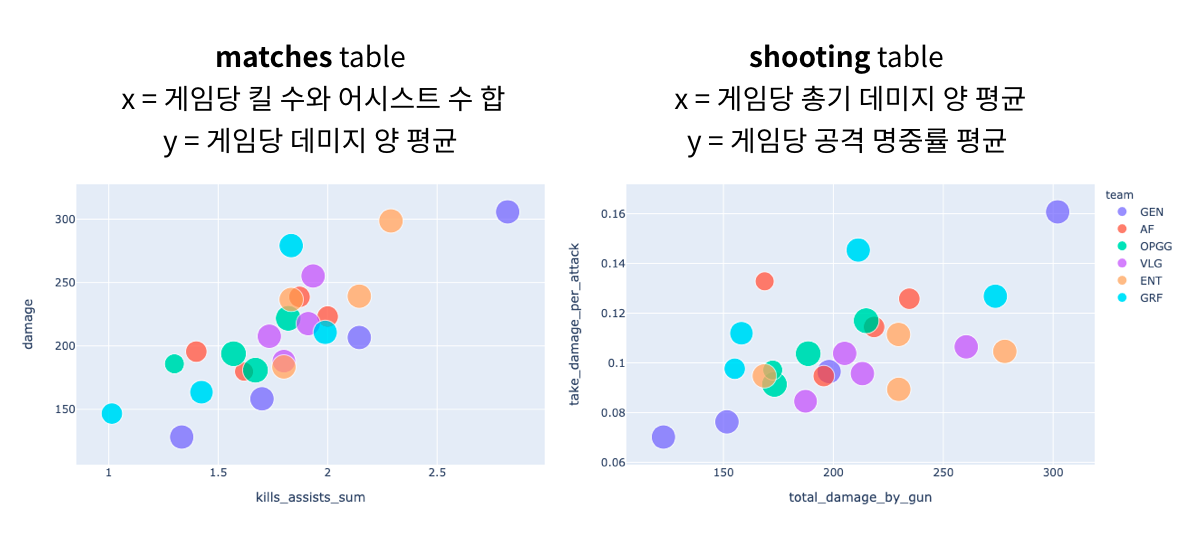 두개 같이 다시 보기 (두 그래프 다 오른쪽 상단에서 홀로 빛나는 플레이어는 Gen.G의 PIO다.)
두개 같이 다시 보기 (두 그래프 다 오른쪽 상단에서 홀로 빛나는 플레이어는 Gen.G의 PIO다.)
모든 결과를 알고난 후 EDA 형태로 다시 살펴보니 사실 나는 좀 놀라웠다. 내가 선택한 팀이 어떤 명확한 특징을 보이고 있었기 때문이다. 그것이 무엇일까. 조금 더 진행된 분석과 함께 다음 편에서..
