참고:
https://towardsdatascience.com/what-are-the-best-metrics-to-evaluate-your-regression-model-418ca481755b
https://shinminyong.tistory.com/32
https://www.analyticsvidhya.com/blog/2021/05/know-the-best-evaluation-metrics-for-your-regression-model/
모두 sklearn에서 사용할 수 있다.
from sklearn.metrics import (mean_squared_error,
mean_absolute_error,
mean_squared_log_error,
median_absolute_error,
explained_variance_score,
r2_score)
식은 아래와 같다.
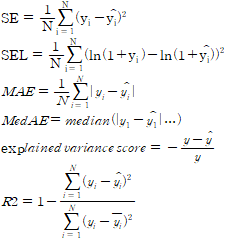
SE 대신 RMSE, SEL대신 RMSEL인데 한글에선 잘 안되는 것 같다.
위에어 언급한 것 외에도 훨씬 많은 metric들이 있으나 가장 많이 쓰이는 것부터 정리한다.
RMSE(root mean squared error):
가장 기본적인 손실함수이다. 자주 사용되는 이유는, 적어도 식이 미분가능하기 때문이다. 미분이 가능하므로 최적화 등에 쉽게 사용할 수 있다. 대칭적이고, 큰 오차에 더 큰 가중치를 둔다는 특징이 있다. 오차항의 제곱에 루트를 씌운 값이기 때문에, 오차와 동일 차원이 되고, 따라서 해석하기에 좀더 용이하다는 장점이 있다.
결과물이 단일 숫자로 나오기 대문에 정말 많은 직관을 얻을수는 없다는 단점이 있지만, 단일 값을 이용해 모델간의 비교를 돕는다는 데에는 장점이 있다.
또한 주 단점으로 outlier에 취약하다는 단점이 있다.
루트를 씌우지 않은 MSE를 사용해도 되는데, 데이터의 크기가 크면 RMSE가 훨씬 선호된다.
RMSLE(RMSE log of error) : 타겟이 지수적으로 증가할 때 적합하다. 단, 양의 오차에 더 큰 가중치를 준다(원래 보다 더 작은 값으로 예측된 데이터에 더 큰 패널티 부과. 따라서 대칭적이지 않다.). 또한, RMSE에 비해 아웃라이어에 더 강하다.
MAE(mean absolute errors): MSE에 비해 사실 더 직접적으로 오차항에 대해 알려주는 식. 대칭적이며, MSE와는 달리 큰 오차에 가중치를 주지 않는다.
단점은 미분이 안되기 때문에, loss function으로 쓸 수 없고 대신 미분이 되는 optimizer를 사용해야 함.
MedAE(median absolute erorrs): MAE와 비슷하지만, outlier에 민감하지 않다.
explained variance score: 모델이 설명하는 타겟 분산에 대한 부분. 0과 1 사이의 값을 갖는다.
R2: 잔차의 평균이 0이면 동일한 결과를 산출. 아닌경우는 다른 결과를 갖는데, 특히 out-of-sample에 대해 음의 값을 가질 수 있다. R2가 이름이 그런 이유는 식에 Correlation coefficient의 제곱항이 들어 있기 때문. 모델이 의존 변수를 얼마나 잘 설명하는가에 대해서는 좋은 값이지만, overfitting문제를 다루지 않는다는 단점이 있다. 만일 독립변수가 너무 많다면 모델이 너무 복잡해지고, R2는 높은데 막상 테스트 데이터에는 안 좋은 결과를 자주 보게 된다. 보통 그래서 패널티를 이용해서 조정.
R2가 다른 사람들에게 모델이 결과의 얼마정도 부분을 설명하는지 말하기 쉽기 때문에 자주 사용된다. MSE, MAE등은 회귀 모델에서 나온 결과물 사이를 비교할 때 주로 사용된다.
수정 R2 : R2의 단점은, feature의 수가 증가할수록 그 이상의 값이 나오는 경향이 있다는 것. 그래서 독립변수가 많으면 패널티를 추가한다.
