made by 토니한
powered by [데이터사이언스 스쿨]
1. 데이터 분석이 뭔데
결론은 그래서 우리는 뭘 하는 건데? 이다.
데이터 분석가 데이터 사이언티스트 뭐시기 모두가 알고 모두가 한다지만 정확하게 하는 사람이 없는 그 분야 데이터 사이언티스트의 목적은 쉽게 2가지로 생각해 볼 수 있다.
- 데이터 간의 관계 파악
- 파악된 관계에서 새로운 데이터(예측)를 찾아내기
보통은 2번 때문에 딥러닝과 머신러닝의 개념이 생기고 발전하였다.
2. 예측
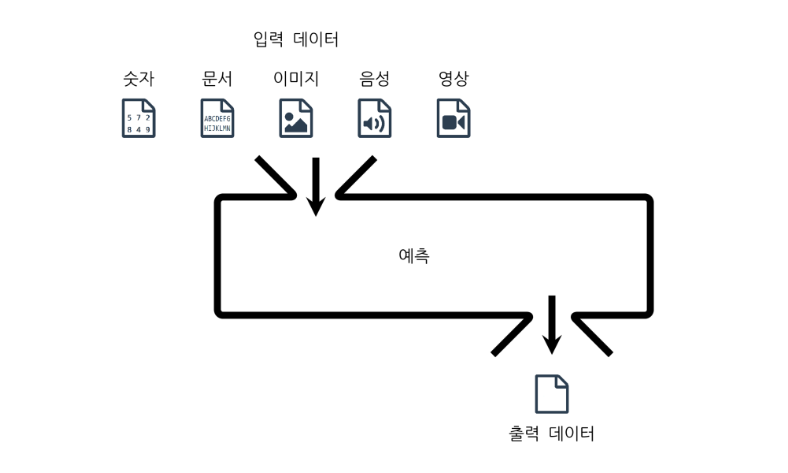
예측한다는 것은 말 그대로 입력데이터(독립변수, 특징, 설명변수 : X)를 가지고 어떤 함수를 거치어서 출력데이터(목적 데이터, 종속변수/라벨, 클라스 : Y)를 만든다는 의미이다.
하지만 기계에게 입력만 준다고 답을 주지 않는다. 기계는 신이 아니다. 우리의 노예다.
1) 규칙기반 방법, 학습기반 방법
이러한 예측을 위해 예측용 함수를 만드는 방법은
1. 규칙기반 : 사람이 입력과 출력을 보고 함수 작성
2. 학습기반 : 기계가 입력과 출력을 보고 함수 작성
이 존재한다.
우리가 말하는 예측은 학습기반이다. 그렇기에 앞으로는 학습기반만을 다루도록 한다.
2) 학습기반 - 지도학습
지도 학습은 우리가 입력과 출력을 모두 주는 방법이다. 이 방법으로 기계는 입력에 대해 출력을 예측하는 모델을 만들어 낸다.

대표적으로 이러한 데이터를 학습용 데이터(데이터셋) 라고 부른다.
이때 출력데이터를 특별하게 목표값이라고 부른다.
그런데 여기서 문제가 되는게 입력값은 구하기 쉽다. 그런데 목표값은 구하기 어렵다. 그래서 목표값을 닝겐들이 일일히 작성해 주어야 하는데 그 과정을 레이블링 한다고 한다.
그렇다 노가다다
이미지넷의 등장
레이블링을 처음에는 대학원생들이 했는데 320만장 가까운 입력의 출력값을 따로 저장하는 일은 쉽지 않았다.
그래서 대학생한테 돈 주고 시키었는데 돈도 많이 들고 시간도 오래 들었다.
그래서 구글을 찾아갔다. 구글이 친히 기계인지 아닌지를 판단해주는 시스템을 개발함과 동시에 무료로 데이터셋을 만들방법을 고안하시기를
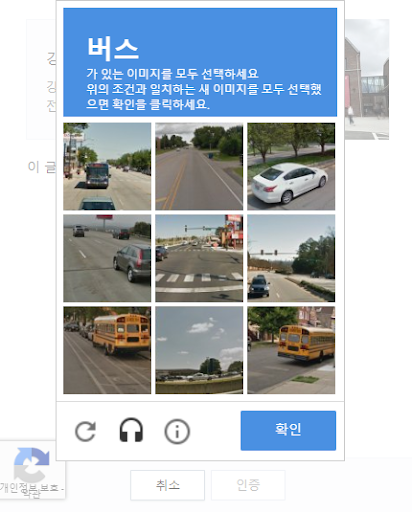
캡챠다...
그렇다 이거 명분은 기계인지를 파악한다고 하고 실채는 그냥 구글 데이터분석용 데이터 셋을 만드는 도구이다.
이렇게 만든 데이터셋을 저장하고 있는 사이트가 이미지넷이다.
이와 동시에 대회 ILSVRC를 열었는데 여기에서 처음으로 GPU를 사용한 딥러닝(CNN)을 사용했다고 한다.
전처리와 인코딩
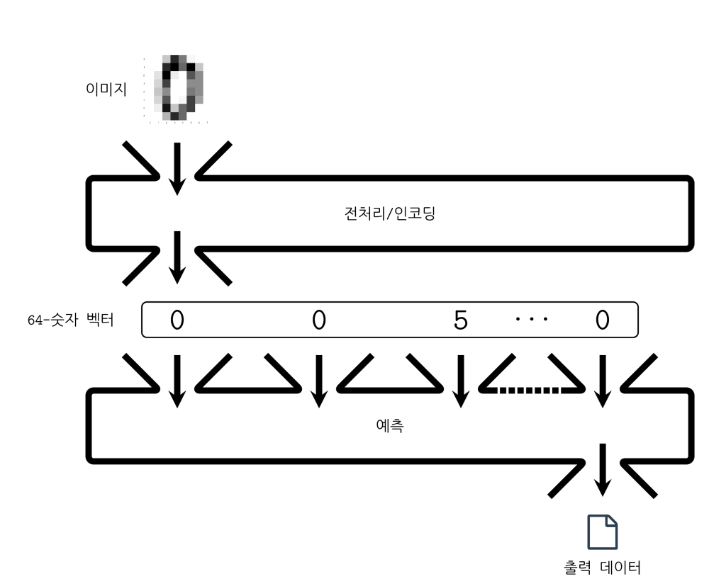
하지만 입력과 출력이 있다고 기계가 바로 입력을 받아들이는 것은 아니다.
그래서 입력 데이터를 한 번 컴퓨터가 읽을 수 있는 형태로 바꾸어 주는데 그것이 전처리와 인코딩이다.
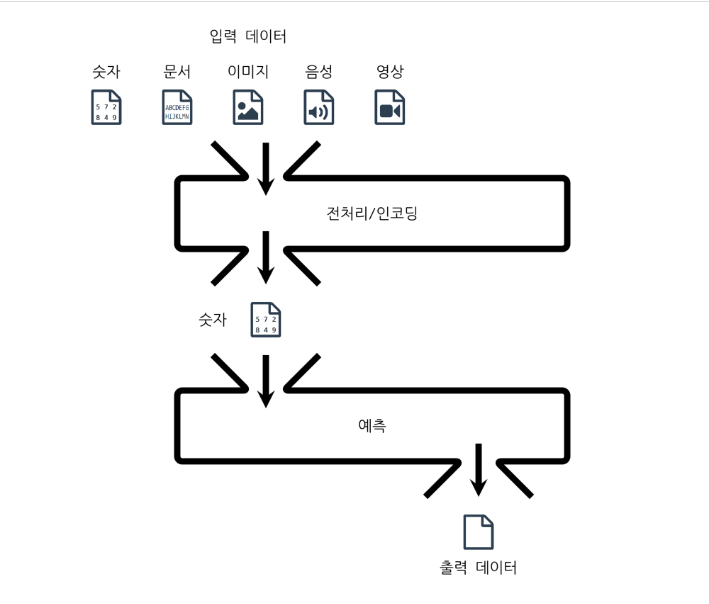
입력차원
이제 입력되는 데이터를 숫자로 바꾸게 될텐데 바꾸어 나타난 숫자의 갯수가 입력차원이다. 이때 중요한 것은 이 숫자의 갯수는 한 번 고정하면 바꿀 수가 없다.
왜냐하면 함수가 한 번 고정된 입력의 갯수까지만 입력을 받기 때문에 이를 초과하면 받아들일 수 없기 때문이다.
인코딩의 예
인코딩의 예 : 이미지 데이터
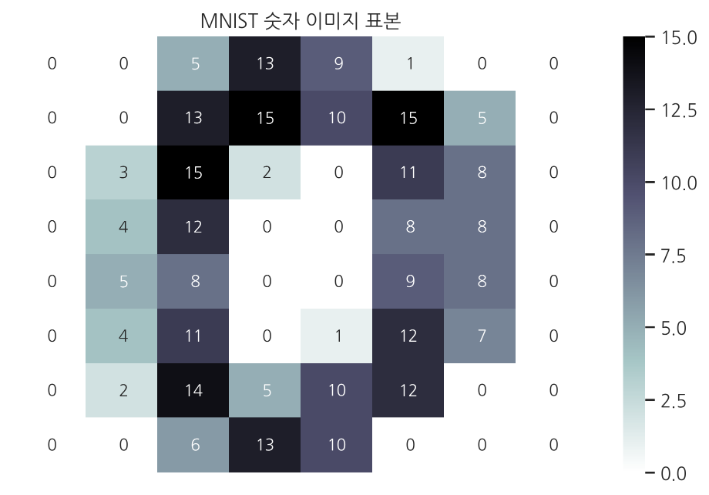
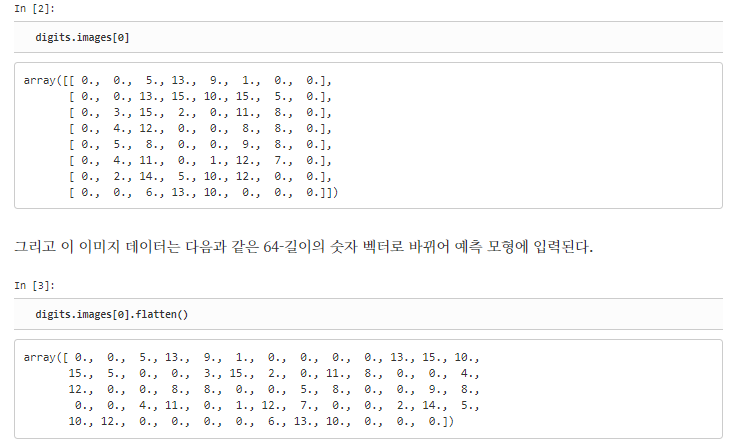
대표적인 인코딩 예는 바로 MNIST 라이브러리에 존재하는 저해상도 이미지이다. 위와 같이 하나의 숫자 데이터가 8x8 비트안에 저장되어 있다.
이 이미지를 1차원 배열로 바꾼다음 함수에 넣어야 한다.
인코딩의 예 : 문서 데이터
그럼 문서는 어떻게 할까? 문서는 크기가 제각각이라서 차원을 고정하기 힘들다.
그래서 사용하는 것이 BOW(Bag of Words) 방법이다.
이 방법은 특정한 단어가 문서에 몇 번 나왔느지만 세어 그 빈도를 벡터로 표시하는 방법이다.
단어를 1부터 10000까지 나누고 한 문서에서 나온 리스트에 저장된 단어와 같은 단어들을 세는 방법이다.
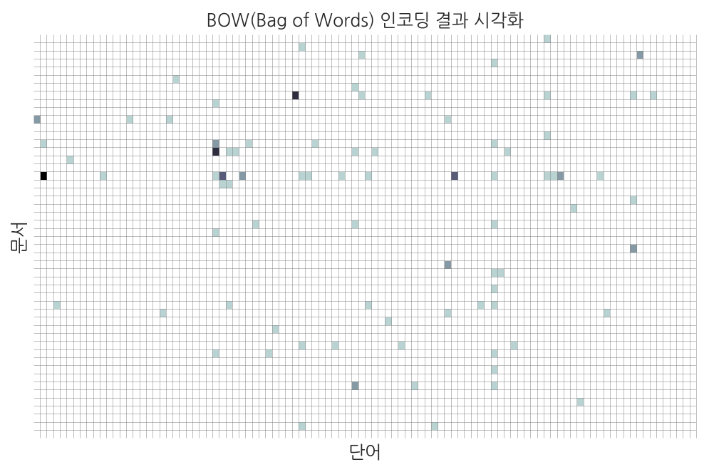
이렇게 단어와 문서 1번부터 10000번까지의 정보중 동일한 단어를 점으로 표시하였다.
인코딩의 예 : 카테고리 값
카테고리값은 기호로 표시되며 비연속적이다. 그렇다보니 카테고리간에는 비교를 할 수 없다.
대표적으로 고양이과 개다.
이걸또 세부적으로 나누어 나올 수 있는 경우에 수에 따라 이진 클래스 와 다중 클래스로 나눈다.
이렇게 세부적인 설명이 있는 걸 보면 알겠지만 우리가 푸는 문제는 사실 카테고리 문제이다.
회귀분석과 분류
예측을 통해 출력하고자 하는 값이 숫자이면 회귀분석(regression analysis - X로 Y를 예측한 모델로 다른 문제분석으로 회귀한다)이고
출력하는 값이 카테고리이면 분류(classification - 같은 종류의 데이터)라고 부른다.
회귀분석의 예
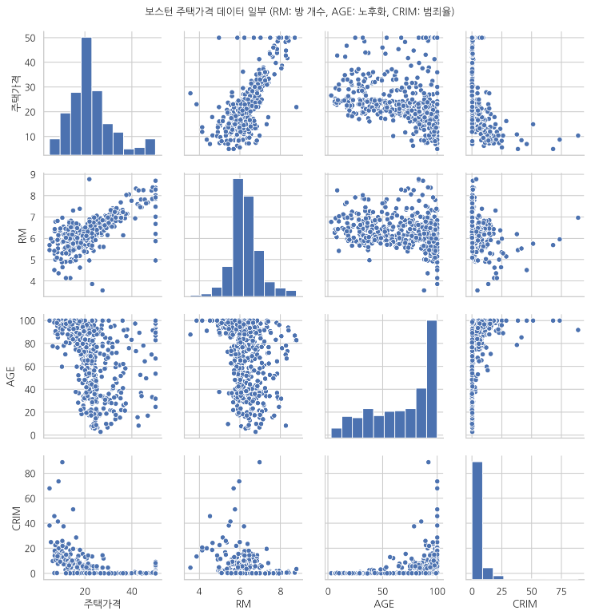
회귀분석의 대표적인 예가 주택가격이다. 이미 다 나와 있는 값들을 잘 결합해서 함수를 만들어 낸고 아 이건 한 이쯤 가격이겠다 예측하는 거다.
분류의 예
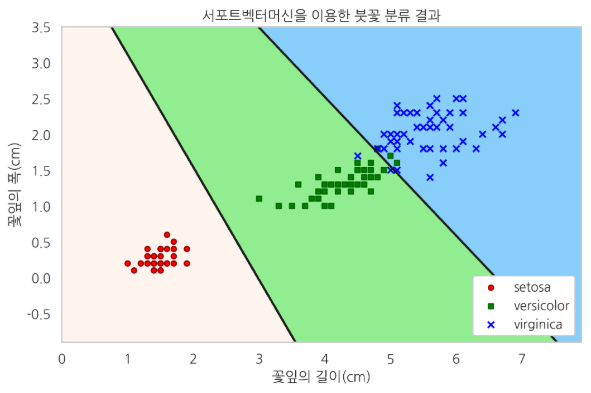
서포트벡터머신(SVC)을 이용하여 데이터를 분류하면 다음과 같다. 이를 통해 빨간색은 뭐고 초록색은 뭐고를 카테고리로 나뉘어서 알아볼 수 있다.
그렇다 회귀분석과 다르게 특정한 함수보다는 비슷한 분류를 통해 새로운 데이터를 예측할 수 있다.
하지만 여기에서도 문제인 것이
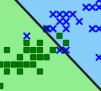
완벽하게 분류가 되지 않는다는 점이다.
그래서 이 문제를 해결해야 한다는 단점이 존재한다.
3) 학습기반 - 비지도학습
이제 입력과 출력같이 일치하지 않는 경우가 종종생긴다. 이는 어디까지나 닝겐이기 때문에 데이터셋이 별로라서 생기는 문제이다.
그렇기에 기계한테 입력을 많이 줄테니 이게 뭔지를 분류해보라고 하는 것이 비지도학습이다.
즉 인간이 결과까지 주었던 것을 기계가 알아서 답도 찾고 소도키우게 하는게 비지도학습이다.
클러스터링
클러스터링 방법은 입력데이터에서 유사한 데이터끼리 같은 그룹으로 모으는 방법이다.
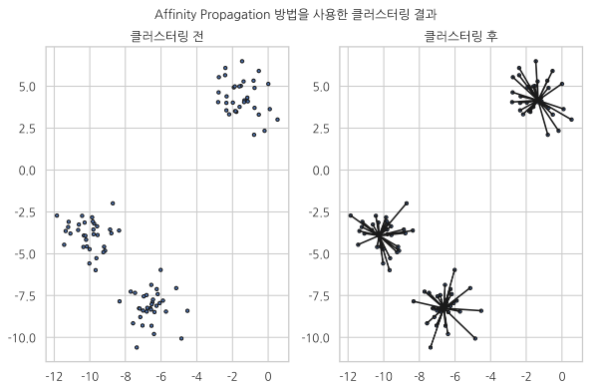
대표적으로 Affinity Propagation 방법이 존재한다.
그런데 Affinity Propagation은 또 입력데이터를 다 주어야 해서 귀찮다.
그래서 imputation 방법이 또 존재한다.
이건 입력데이터들로 다른 입력데이터까지 맞추게하는 방법이다.
오늘의 결론
인공지능은 인간의 귀찮음의 결정체이다.
