머신러닝
1.0. 머신러닝 성능 평가 명령
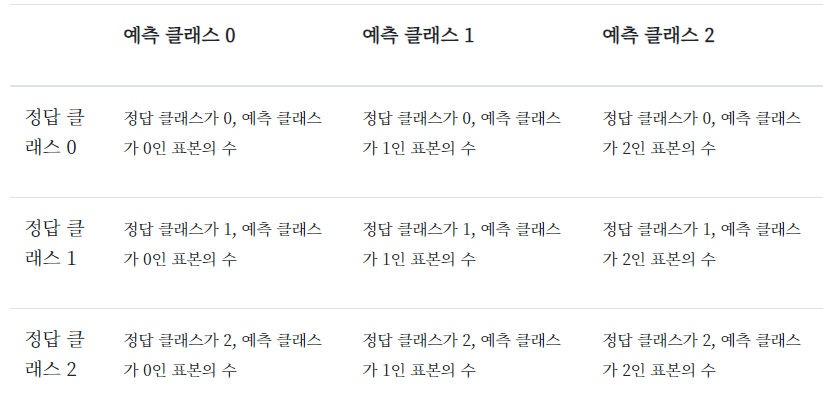
confusion_matrix(y_true, y_pred)accuracy_score(y_true, y_pred)precision_score(y_true, y_pred)recall_score(y_true, y_pred)fbeta_score(y_true, y_pred, b
2.1-1 데이터 분석의 소개
made by 토니한powered by \[데이터사이언스 스쿨]결론은 그래서 우리는 뭘 하는 건데? 이다.데이터 분석가 데이터 사이언티스트 뭐시기 모두가 알고 모두가 한다지만 정확하게 하는 사람이 없는 그 분야 데이터 사이언티스트의 목적은 쉽게 2가지로 생각해 볼 수
3.2-1 데이터 전처리 기초
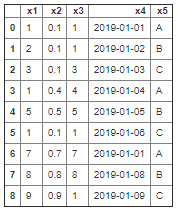
사용 패키지 missingno : 결측 데이터 검색(빠진 데이터 검색) sklearn.impute 패키지 : 결측 데이터 채워넣기 patsy 패키지 : 데이터 선택, 변환, 추가, 스케일링 sklearn.preprocessing 패키지 : 스케일링, 변환 1. mis
4.4. 지도학습 - 확률적 판별모형(회귀분석, 의사결정나무)
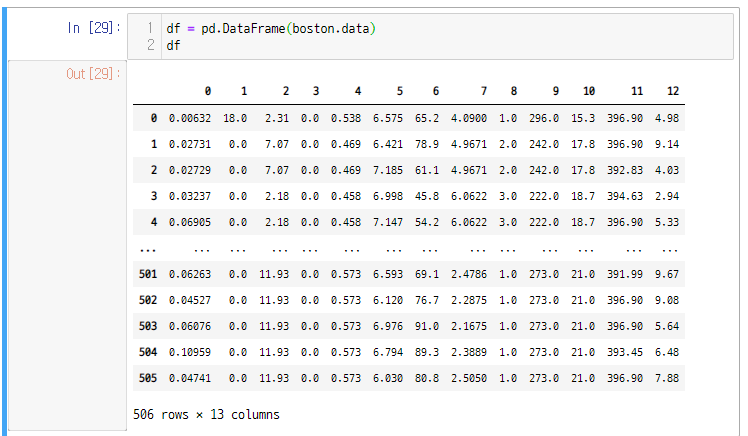
이제 제대로 된 회귀분석에 앞서 회귀분석이 어떠한 것을 알아내는 것인지를 알기 위해 보스턴 집값 데이터를 가지고 데이터간의 상관관계를 보도록 하겠다.이렇게 이상하게 된다.하면 이렇게 예쁜 모양의 데이터 프레임이 생성된다.이것의 상관 관계를 알아보기 위해 스캐터 플롯을
5.4. 지도학습 - 확률적 생성모형(LDA/QDA, 나이브 베이지안)
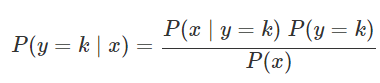
확률적 생성모형은 확률적 판별모형과 유사하나 베이즈 정리를 사용하여 확률을 구해주기만 하면 확률적 생성모형으로 불리고 명확하게 판별해 주면 확률적 판별모형이라고 부른다.LDA(Linear Discriminant Analysis) : 선형판별분석법QDA(Quadratic
6.matplotlib 출력이 안될때

를 맨 위에 작성해 보기