사용 패키지
missingno : 결측 데이터 검색(빠진 데이터 검색)
sklearn.impute 패키지 : 결측 데이터 채워넣기
patsy 패키지 : 데이터 선택, 변환, 추가, 스케일링
sklearn.preprocessing 패키지 : 스케일링, 변환
1. missingno-결측찾기
데이터를 입력하다보면 빠져있는 데이터 = 결측 데이터가 존재한다.
missingno 패키지는 그런 결측데이터를 찾아주는 역활을 한다.
주의점
NaN값은 부동소수점 실수 자료형에만 있는 값이므로 정수 자료형 데이터프레임에 넣을 떄는 Int64Dtype 자료형을 명시해 주어야 한다.
동일하게 시간 자료형을 넣을 때도 parse_dates 인수로 날짜시간형 파싱을 해주어야 datetime64[ns] 자료형이 되어 결측 데이터가 NaT(not a Time)값으로 표시된다.
사용법
- 예를 들어 다음과 같이 csv 파일을 읽어 들였다고 하자
- 여기에서는 임시로 csv 파일을 만들어 내겠다.
from io import StringIO
csv_data = StringIO("""
x1,x2,x3,x4,x5
1,0.1,"1",2019-01-01,A
2,,,2019-01-02,B
3,,"3",2019-01-03,C
,0.4,"4",2019-01-04,A
5,0.5,"5",2019-01-05,B
,,,2019-01-06,C
7,0.7,"7",,A
8,0.8,"8",2019-01-08,B
9,0.9,,2019-01-09,C
""")
#여기에서 인자의 타입을 모두 정의해 주었다.
df = pd.read_csv(csv_data,dtype={"x1": pd.Int64Dtype()},
parse_dates=[3])
df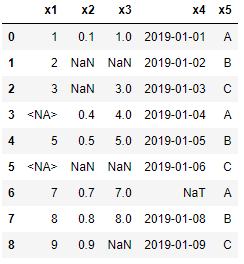
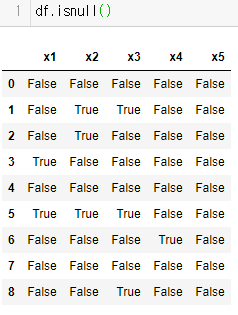
그냥 클래스 메소드를 사용할 수도 있지만 이게 양이 수만 수천개가 되면 눈으로 딸아갈 수 가 없다.
그래서 missingno library를 사용하면 이를 그림으로 볼수가 있다.

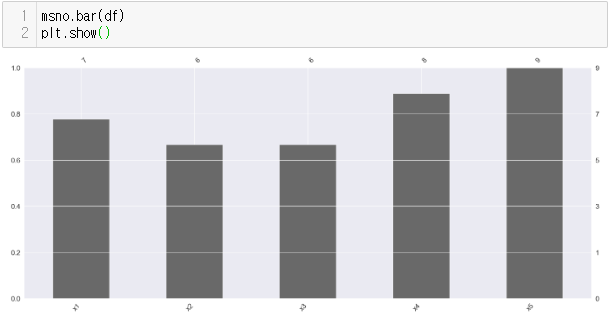
정리하면 missingno로 볼 수 있는 결측데이터의 표현방식은 총 3가지이다.
1번 이미지에 나와 있는 좌측 행렬과 우측 스파크라인
2번 이미지에 나와 있는 막대 그래프가 그것이다.
2. sklearn-impute-결측 채우기
결측데이터가 너무 많다고 하면 이를 처리할 방법도 필요하다.
- 결측데이터를 완전히 삭제
- 결측데이터를 비슷한 값으로 채워넣기가 그것이다.
1) 결측데이터 완전히 삭제
- 행단위로 삭제하려면 판다스의 메소드를 사용하면 된다.
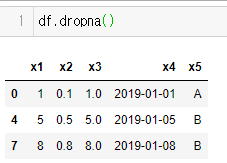
- 반대로 열단위로 삭제하려면
dropna함수내axis인자값을 바꾸면 된다.

문제는 이 친구를 사용하면 NaN이 하나만 있어도 데이터를 삭제해버린다.
그래서 조건을 주도록해보자thresh를 이용하자
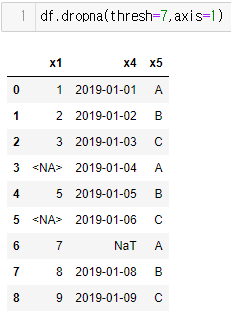
했더니 7개 이상인 열만 삭제된 것을 확인할 수 있다.
2) 결측데이터 채워넣기
반대로 결측데이터를 채워 넣으려면 어떤 인자를 사용하는 것이 좋을까?
가장 좋은 방법은 평균이나 중앙값 혹은 최빈값을 사용하는 것이다.
이때 사용하는 것이 sklearn-impute에 포함된 SimpleImputer 클래스와 fit_transform 클래스 메소드이다.
- 빈칸을 어떤 것으로 채울지 먼저 정해준다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="most_frequent")
# most_frequent : 최빈값, mean : 평균값, median : 중앙값
- 실재 데이터 프레임으로 만들어 준다.
df = pd.DataFrame(imputer.fit_transform(df),columns=df.columns)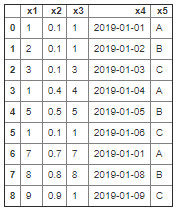
실재값이 채워진다.
이와 비슷하게 titanic에서 비어있는 곳만을 채워 보자면
import sklearn.impute from SimpleImputer
- 보면 알겠지만 마스킹 같다.
imputer_embark_town = SimpleImputer(strategy="most_frequent")
- Series 수정에는 판다스까지 불러올 필요 없이 마스크로 바꾼다.
titanic["emark_town"] = imputer_embark_town.fit_transform(
titanic[["embark_town"]])
titanic["emarked"] = imputer_embark_town.fit_transform(
titanic[["embarked"]])
msno.matrix(titanic)
plt.show()
오른쪽에 보이는 스파크라인을 보면 알겠지만 바코드 같이 생긴 기다란 선이 생기어 있다.
-age는 중앙값으로 결측데이터를 채웠다.
imputer_age = SimpleImputer(strategy="median")
titanic["age"] = imputer_age.fit_transform(titanic[["age"]])
msno.matrix(titanic)
plt.show()
스파크라인 역시 한줄로 바뀐것을 볼 수 있다.
3. patsy - 선택,변환,추가,스타일링
시작하기 전에 patsy에서 제공하는 5행의 임의의 실수 데이터를 제공하는
demo_data 함수를 소개하겠다.
from patsy import demo_data
df =pd.DataFrame(demo_data("x1","x2","x3","x4","x5"))
df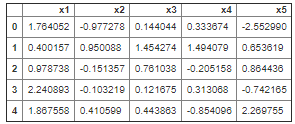
patsy 패키지에서 가장 많이 사용하는 것은 dmatrix 함수이다.
from patsy import dmatrix
- dmatrix는 인자로 왼쪽에는 필요한 데이터 열과 연산된 열
- 그리고 오른쪽에는 우리가 사용할 데이터프레임을 넣는다.
data_transform("x1+x2+x3+0",data=df)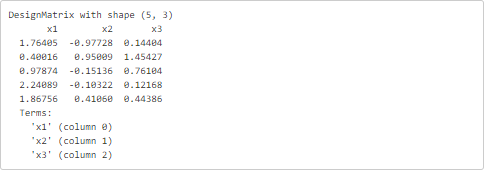
x1,x2,x3가 출력된 것을 알 수 있다.
반대로 따로 연산 결과를 출력할 수 도 있다.
- 이건 x2의 로그값도 같이 출력하는 것
data_transform("x1+np.log(abs(x2))",df)
- 이건 x1과 x2의 곱을 표현하는 것 **상호작용**
data_transform("x1,x2,x1:x2+0",df)
- 이건 x1, x2 그리고 x1과 x2의 곱을 표현하는 것
data_transform("x1*x2+0",df)
- x1과 x2를 더하여 새로운 데이터를 만들고 싶다면 다음과 같다.
data_transform("x1+x2+I(x1+x2)",df)
- 그것도 아닌 함수로 표현해서 자신이 원하는 연산을 표현할 수도 있다.
def ten_times(x1):
return x1*10
data_transform("ten_times(x1)",df)이제 우리가 지금까지 +0(-1) 혹은 +1 을 넣는 이유에 대해 설명 하자면 아무것도 안적었을 때 앞에 Intercept라는 칸이 새롭게 생긴다. 이건 후에 회귀분석 때문이다.
필자는 아직 안배워서 잘 모르겠다. 그런가 보다.
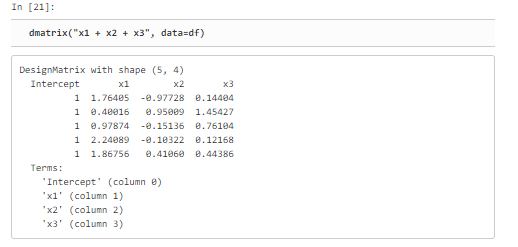
선형회귀분석 할 때 조건수 때문에 데이터의 평균을 0으로 표준편차를 1로 만드는 스케일링 작업을 하는 것이 분석 결과의 품질을 높일 수 있다.
이는 patsy 패키지에서 지원한다.
- 평균을 0으로 스케일링
dm = dmatrix("center(x1)+0",df)
- 평균은 0으로 표준편차는 1로 스케일링
dm = dmatrix("standardize(x1)+0",df)
dm = dmatrix("scale(x1)+0",df)왜 standardize와 scale 두개가 존재하는지는 필자도 잘 모른다.
이때 만들어진 메트릭스 안에는 평균값을 저장하고 있다.
왜냐하면 우리가 한 번 만든 모델링을 테스트 데이터가 새롭게 들어와서 평균이나 분산을 바꾼다면 그때는 다른 데이터에 대해서 원하지 않는 값이 나올 수 있기 때문이다.
그렇기 때문에 함수 내부에는 평균값을 가지고 있고 이를 확인 하는 방법은
dm.design_info.factor_infos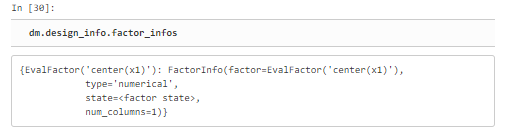
를 사용하면 볼 수 있다.
4. sklearn.preprocessing 패키지
sklearn.preprocessing 내부에서도 StandardScaler, RobustScaler, PolynomialFeatures, FuntionTransformer 클래스를 주로 사용한다.
이 4개의 클래스 내부에는 동일하게 fit_transform() 함수를 가지고 있는 데
이 클래스 내부에 있는 함수를 활용하여서 데이터를 바꾸는 것에 대해 알아보자
1) StandardScaler
fit_transform 함수를 사용하면 저장된 데이터의 평균을 0으로 표준편차를 1로 바꾸어 준다.
from sklearn.preprocessing import StandardScaler
x = np.arange(7).reshape(-1,1)
# 행은 임의로 열은 1차원
- 객체 생성
scaler = StandardScaler()
scaler.fit_transform(x)
하면은 이와 같이 평균은 0이고 표준편차는 1인 데이터로 바뀌게 된다.
2) RobustScaler
하지만 여기에서 문제가 만약
x2 = np,vstack([x,[[1000]]])형태로 1000이라는 값이 들어간다면? 당연히 평균이 0으로 맞추기 위해 데이터들이 과도하게 한쪽으로 쏠릴 가능성이 높아진다.
그래서 RobustScaler 클래스를 받아들여서 평균값이 아닌 중앙값이 0, IQR(interquartile range)이 1기 외도록 변환해 주는 방법을 사용한다. 이 방법으로 아웃라이어 값이 존재하더라도 해결할 수 있다.
(IQR은 중앙값을 기준으로 잡을때 데이터가 50%모여 있는 구간을 이야기 한다.)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaler.fit_transform(x2)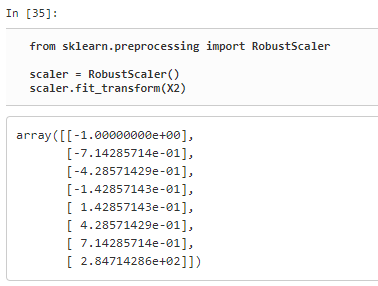
나온 결과물은 어느 한쪽으로 치우쳐지지 않은 형태를 뛰고 있다.
3) PolynomialFeatures
입력받은 테이터를 다항식의 값처럼 바꾸어주는 클래스이다.
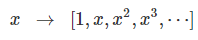
from sklearn.preprocessing import PolynomialFeatures
x = np.arange(7).reshape(-1,1)
poly = PolynomialFeatures(degree=2)
poly.fit_transform(x)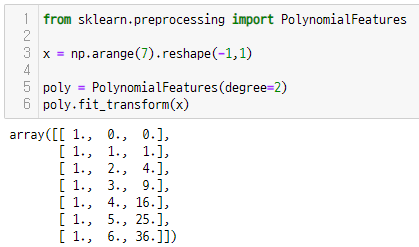
결과는 위의 다항식처럼 데이터를 바꾸어 준다.
4) FunctionalTransformer
이 클래스는 우리가 만들어 놓은 함수를 가지고 배열을 바꾸어 준다.
예를 들어 sinΘ와 cosΘ와 같은 삼각함수는 10도와 370도는 같은 값이다. 하지만 코드 영역에서는 이를 반영하기 어렵기에 이를 반영하여 데이터를 바꾸어 주는 기능을 우리가 직접 구현하는 방법이다.
from sklearn.preprocessing import FunctionTransformer
x = 90 * np.arange(9).reshape(-1,1)
def degree2sincos(x):
x0 = np.sin(x * np.pi/180)
x1 = np.cos(x * np.pi/180)
x_new = np.hstack([x0,x1])
return x_new
x2 = FunctionTransformer(degree2sincos).fit_transform(x)
x2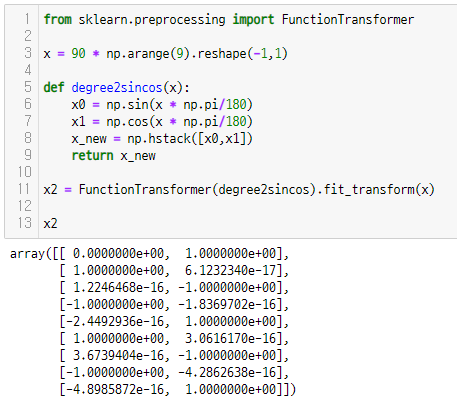
실행결과를 보면 알겠지만 0도부터 720도까지 2바퀴를 돌면서 sin과 cos의 값을 보여준다.
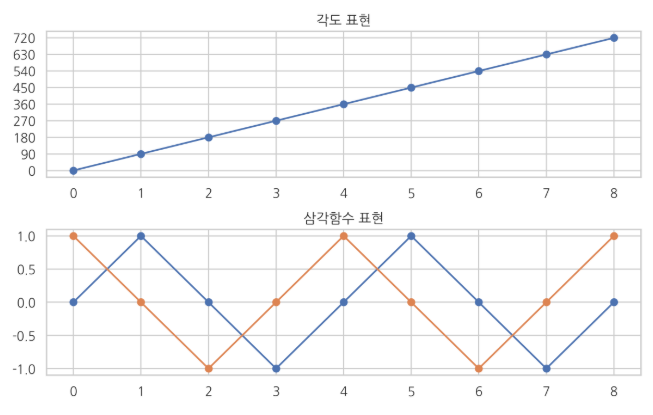
이를 그림으로 표현한 것을 보아도 그러하다.
