0. 확률적 생성모형
확률적 생성모형은 확률적 판별모형과 유사하나 베이즈 정리를 사용하여 확률을 구해주기만 하면 확률적 생성모형으로 불리고 명확하게 판별해 주면 확률적 판별모형이라고 부른다.
numpy 사용
생성모형 = 기본모형
LDA(Linear Discriminant Analysis) : 선형판별분석법
QDA(Quadratic Discriminant Analysis) : 이차판별분석법
결과값 y의 클래스값에 따른 x의 분포에 대한 정보를 먼저 알아낸 후 => 베이즈 정리를 사용하여 주어진 x에 대한 y의 확률 분포를 구하는 방법이다.
이때 베이즈 정리는 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리이다.
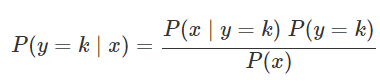
위와 같은 공식을 이용하여 확률을 구하게 되며 왼쪽은 사후확률(x가 주어졌을 때 y가 k일 확률)로 우리가 구하고자 하는 확률이다. 오른쪽의 P(y=k)는 사후확률, P(x|y=k)는 가능도를 의미한다.
이때 P(x)의 값은 구지 알아낼 필요는 없다. 왜냐하면 밑에 붙어 있는 값이 없다면 값들은 0~1 사이의 확률값이 아닌 더 큰 값이 나온다. 하지만 우리가 구하는 것은 분류이지 명확한 확률이 아니기 때문에 구지 P(x)까지 구하여 나누어 줄 필요가 었다. 하지 않아도 차이가 생기기 때문이다.
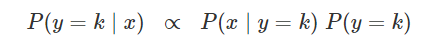
그렇기 때문에 위와 같이 가능도x사전확률값에 사후확률이 비례한다고 생각할 수 있다.
그럼 이제 사전확률에 대해서 알아보자 사전확률은 학습용 데이터로 제공된 데이터들을 분류해놓는 것이다.
P(y=k) = (y=k 인 데이터의 수) / (전체 데이터의 수)
만약 이러한 정보조차 없다면 그냥 1/2로 해버리자
사전확률은 알고 있기 때문에 가능도 함수( P(x|y=k) )만 알 수 있다면 우리가 원하는 분류모형이 만들어 진다. 이러한 가능도 함수를 알아내는 방법을 가지고 LDA/QDA/나이브베이지안으로 나뉜다.
- 가능도 함수 구하는 방법
- 가정 : P(x|y=k)가 특정한 확률분포 모형을 따른다고 가정 ex> 정규분포를 따른다.
- k번째 클래스에 속하는 학습 데이터를 사용하여 이 모형의 모수값을 구한다. (평균과 분산)
- 구한 모수값이 곧 P(x|y=k) 이기 때문에 앞으로는 어떠한 x값을 가지고 오더라도 P(x|y=k)값을 구할 수 있다.
ex> 정상인이면서 몸의 온도가 37.8도일 확률을(가능도) 구해보자(평균 : 37.5, 분산 : 0.1^2)
#정상인
rv_normal = sp.stats.norm(local=37.5,scale=0.1)
rv.pdf(37.8)1. QDA(Quadratic Discriminant Analysis)
독립변수 x가 실수이고 확률분포가 다변수 정규분포라고 가정한다. 단 차이점은 y=k마다 다른 다변수 정규분포이다.
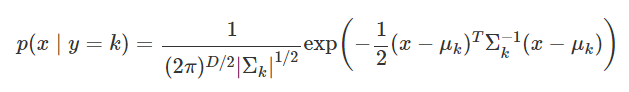
식을 보면 알겠지만 평균과 분산값이 k에 따라 계속 달라진다.
사용법
from sklarn.discriminant_analysis import QuadraticDiscriminantAnalysis
qda = QuadraticDiscriminantAnalysis(store_cocariance=True).fit(X,y)sklearn에서 제공하는 QuadraticDiscriminantAnalysis을 사용하여서 이차판별문제를 풀 수 있다.
이때 속성값으로
- priors_: 각 클래스 k의 사전확률.
- means_: 각 클래스 k에서 x의 기댓값 벡터 μk의 추정치 벡터.
- covariance_: 각 클래스 k에서 x의 공분산 행렬 Σk의 추정치 행렬. (생성자 인수 store_covariance 값이 True인 경우에만 제공)
이제 우리가 삽입하는 데이터는
문제 : QDA를 이용하여서 붗꽃 분류문제를 풀고
2. LDA(Linear Discriminant Analysis)
3. 나이브 베이즈 모형(텍스트 분석)
목적 : 텍스트 데이터 처리에 주로 사용되는 모형 - 텍스트는 BOW(Bag of Words) 방법을 사용하기 때문에 x의 종류가 굉장히 많다. 그렇기 때문에 앞에서 사용하였던 LDA/QDA 가 불가능
나이브 베이즈 방법 : QDA + 조건부 독립
이름 : 나이브(Naive : 순진함)가 들어가는 이유는 조건부 독립 때문이다. 만약에 두개의 변수가 같은 종이라고 하더라도 항상 두 변수의 값이 독립이지 않을 수 있다. 다른말로 현실에서 일어나는 것이 쉽지 않기 때문에 순진하다는 이야기를 사용한다.
조건부 독립
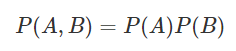
위의 식은 독립이다.
여기에서 조건부 독립이라고 하면 조건이 되는 C가 추가 되었을 때에만 독립이 되는 것을 이야기 한다.
- 기호

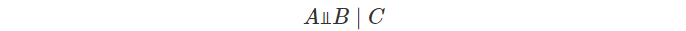
- 무조건부 독립
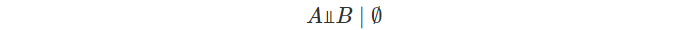
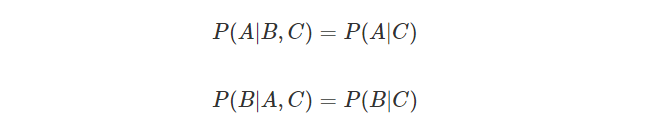
무조건부 독립이면 위의 성질을 만족한다.
하지만 조건부 독립과 무조건부 독립은 아무런 관계가 없다. 예를 들어서 사람의 키는 부모의 키를 따른다. 그렇기 떄문에 자식의 키는 부모의 키가 있다는 가정 하에서 독립이다. 하지만 부모 없이 자식의 키만을 비교한다면 둘 사이의 상관관계가 생길 수 밖에 없다.
나이브 가정
우리가 조건부 독립을 배우는 이유는 바로 나이브 가정 때문이다.
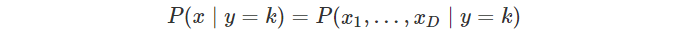
우리가 앞으로 다룰 가능도 함수는 D차원(입력값이 무한하다면) 가능도함수의 값을 계산하는 것은 현식적으로 쉽지 않다. 따라서 나이브 베이즈 분류모형에서는 모든 차원의 독립변수가 조건부독립이라고 가정하여 이용한다. 이러한 가정을 나이브 가정이라고 부른다.
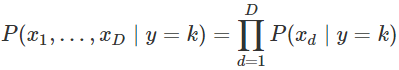
독립이기 떄문에 가능도함수는 모두 곱해져수 구해진다.
여기에서 가능도함수를 무엇을 사용하느냐에 따라서 값이 달라진다.
- 정규분포 : 실수
- 베르누이 분포 : 0또는 1
- 다항분포 : 정수
로 가정하였으나 실재로는 그냥 아무렇게나 넣어도 개똥같이 나온다. 어찌되었든 똥이 나온다는 이야기이다. 그렇기 때문에 사용하는데 에러가 났는지 조차 스스로 확인하기 어려우니 위의 가정을 외우고 사용하자.
- 정규분포 가능도 모형
x 데이터의 원소가 모두 실수이고 클래스마다 특정한 값 주변에서 발생한다고 하면 가능도 분포로 정규분포를 사용한다. 모든 단변수 독립변수들이 서로 조건부독립이고 가정하여서 값들을 곱해준 형태를 가지게 된다.

- 베르누이분포 가능도 모형
x 데이터가 0 또는 1인경우에 사용한 경우. 각각의 조건부 독립적인 베르누이 확률변수이다.
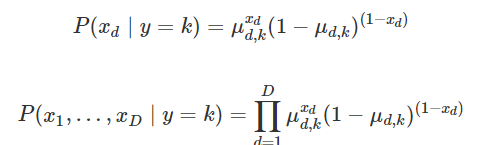
그래서 모든 값들이 곱해진 형태로 나타나게 된다.
- 다항분포 가능도 모형
x 데이터 전체가 다항분포라고 가정(다항분포에서 변수가 가지는 값은 면이 4개인 주사위를 10번 던지어서 1~4까지 나온 값들의 횟수를 계산해 놓은 것이다.)
이때는 각각의 것들을 결합분포함수가 원래 곱하기 형태이기 때문에 그냥 나이브 베이즈 모형안에 사용한다.
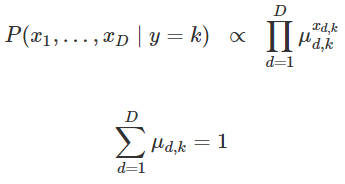
사이킷런에서 제공하는 나이브베이즈 모형
- GaussianNB: 정규분포 나이브베이즈
- BernoulliNB: 베르누이분포 나이브베이즈
- MultinomialNB: 다항분포 나이브베이즈
공통 속성들
- classes_
종속변수 Y의 클래스(라벨) - classcount
종속변수 Y의 값이 특정한 클래스인 표본 데이터의 수 - classprior : 사전확률
종속변수 Y의 무조건부 확률분포 P(Y) (정규분포의 경우에만) - classlog_prior
종속변수 Y의 무조건부 확률분포의 로그 logP(Y) (베르누이분포나 다항분포의 경우에만)
정규분포 나이브베이즈 모형
가우시안 나이브베이즈 모형 GaussianNB은 가능도 추정과 관련하여 다음과 같은 벡터인 속성을 가지게 된다.
- theta_: 정규분포의 기댓값 μ
- sigma_: 정규분포의 분산 σ^2
- 실재 사용법과 예시
정규분포 나이브베이즈 모형 구하는 방법
from sklearn.naive_bayes import GaussianNB model_norm = GaussianNB().fit(X, y)
사전확률
model_norm.classes_ model_norm.class_count_ model_norm.class_prior_

확률분포의 모수를 계산하기
실재 계산 결과를 보아도 원래의 모수의 대각선 방향에 있는 값들이 나온 것을 확인할 수 있다.

이제 정규분포를 따르는 나이브베이즈 모형을 가지고 아래의 값을 모델화 하고 예측하여 보자
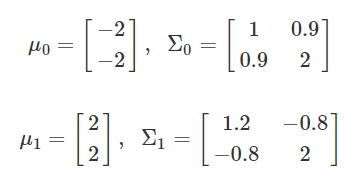
%matplotlib inline
np.random.seed(0)
rv0 = sp.stats.multivariate_normal([-2, -2], [[1, 0.9], [0.9, 2]])
rv1 = sp.stats.multivariate_normal([2, 2], [[1.2, -0.8], [-0.8, 2]])
X0 = rv0.rvs(40)
X1 = rv1.rvs(60)
X = np.vstack([X0, X1])
y = np.hstack([np.zeros(40), np.ones(60)])
model_norm = GaussianNB().fit(X, y)
rv0 = sp.stats.multivariate_normal(model_norm.theta_[0], model_norm.sigma_[0])
rv1 = sp.stats.multivariate_normal(model_norm.theta_[1], model_norm.sigma_[1])
xx1 = np.linspace(-5, 5, 100)
xx2 = np.linspace(-5, 5, 100)
XX1, XX2 = np.meshgrid(xx1, xx2)
plt.grid(False)
plt.contour(XX1, XX2, rv0.pdf(np.dstack([XX1, XX2])), cmap=mpl.cm.cool)
plt.contour(XX1, XX2, rv1.pdf(np.dstack([XX1, XX2])), cmap=mpl.cm.hot)
plt.scatter(X0[:, 0], X0[:, 1], marker="o", c='b', label="y=0")
plt.scatter(X1[:, 0], X1[:, 1], marker="s", c='r', label="y=1")
x_new = [0, 0]
plt.scatter(x_new[0], x_new[1], c="g", marker="x", s=150, linewidth=5)
plt.legend()
plt.title("NaiveBayes Predict Model")
plt.axis("equal")
plt.show()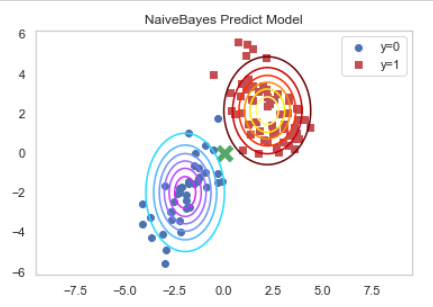
이렇게 나온 모델을 가지고 (0,0) 에서의 데이터의 클래스값을 예측해 보자
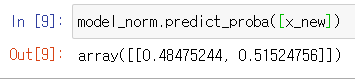
model_norm.predict_proba([x_new])
예측 결과 클래스 1일 확률은 0.48, 클래스 2일 확률은 0.51 인 것을 확인할 수 있다.
그렇다면 이 값의 중간과정인 가능도 함수는 어떻게 나올까?
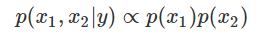
조건부독립이기 때문에 두 값의 조건부확률은 두 확률을 곱한 것으로 나오게 된다.
- 연습 문제 1
붓꽃 분류문제를 가우시안 나이브베이즈 모형을 사용하여 풀어보자.
(1) 각각의 종이 선택될 사전확률을 구하라.
(2) 각각의 종에 대해 꽃받침의 길이, 꽃받침의 폭, 꽃잎의 길이, 꽃잎의 폭의 평균과 분산을 구하라.
(3) 학습용 데이터를 사용하여 분류문제를 풀고 다음을 계산하라.
- 분류 결과표
- 분류 보고서
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB
iris = load_iris()
x1=iris.data
y1=iris.target
model1 = GaussianNB().fit(x1,y1)
model1.class_prior_
print(model1.theta_)
print(model1.sigma_)
from sklearn.metrics import confusion_matrix
y1_pred = model1.predict(X1)
confusion_matrix(y1,y1_pred)
from sklearn.metrics import classification_report
print(classification_report(y1,y1_pred,target_names=['class0','class1','class2']))

베르누이분포 나이브베이즈 모형
x가 0또는 1의 바이너리 값이 들어갈때 사용 가능
정규분포 나이브베이즈 모형에서 추가된 부분
- featurecount: 각 클래스 k에 대해 d번째 동전이 앞면이 나온 횟수 Nd,k - 이걸 카운트 해서 베르누이분포 모수의 로그를 구함
- featurelog_prob: 베르누이분포 모수의 로그
이때의 가능도 함수는 아래와 같은 식을 가지게 된다.
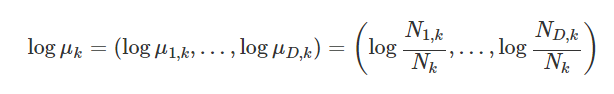
사용법 - 나이브 베이즈에서 베르누이 모형을 가져와 fit 하면 된다.
from sklearn.naive_bayes import BernoulliNB
model_bern = BernoulliNB().fit(X, y)- 스무딩
베르누이 분포 모수의 측정을 할때 횟수가 적은 경우 0또는 1이라는 극단적인 모수 추정값이 나올 수 있지만 현실적으로 이런일은 있을 수 없기 때문에 데이터를 조작하여서 사용하는 것.
예를 들어서 10번 던지어 앞면(=1) 이 10번 나왔다고 하면 문제가 되기 때문에, 가상의 동전을 만든다. 이 동전은 μ가 1/2인 동전이다.
(가짜동전(1) + 진짜동전(10)) / (가짜동전(2) + 진짜동전(10)) = 11/12 라는 값이 나오게 된다.
사기친거 아니냐고? 하지만 우리의 사전지식에 따르면 10번 모두 1이 나오는게 더 말이 안되기 때문에 근거가 존재한다.
여기에서도 섞는 횟수를 조절할 수 있다. 이때 섞는 값을 α라고 한다.
(가짜동전(1 α) + 진짜동전(10)) / (가짜동전(2 α) + 진짜동전(10))
이러한 것을 라플라스 스무딩 또는 애드원 스무딩 이라고 부른다.
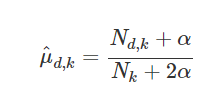
사용법
X = np.array([
[0, 1, 1, 0],
[1, 1, 1, 1],
[1, 1, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1],
[0, 1, 1, 0],
[0, 1, 1, 1],
[1, 0, 1, 0],
[1, 0, 1, 1],
[0, 1, 1, 0]])
y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])위와 같이 4개의 키워드를 사용하여 10개의 메일을 정상 메일 4개와 스팸 메일 6개를 BOW 인코딩한 행렬이다. y가 0인 것이 정상 메일이다.
이제 위에서 나온 값들을 분류하고 전체 갯수와 스무딩을 통하여서 사전확률을 구하여 보자
fc = model_bern.feature_count_
fc
또한 이것의 각 모수별 스무딩을 하여서 나온 결과 역시 살피어 보자. 알겠지만 여기에서 나오는 모수는 가능도함수에 들어가기 때문에 스무딩과 계산의 과정을 거치어 가야만 한다.
theta = np.exp(model_bern.feature_log_prob_)
theta
model_bern.alpha
이번에는 새로운 데이터로 이게 무엇인지 예측하여 보자
x_new=np.array([0,0,1,1])
model_bern.predict_proba([x_new])
결과물은 스팸 메일이 아닌 것으로 확인된다.
- 연습 문제 2
(1) MNIST 숫자 분류문제에서 sklearn.preprocessing.Binarizer로 x값을 0, 1로 바꾼다(값이 8 이상이면 1, 8 미만이면 0). 즉 흰색과 검은색 픽셀로만 구성된 이미지로 만든다
sklearn.preprocessing.Binarizer은 특정 숫자 이하의 숫자를 0과 1로 바꾸어 주는 함수이다. 우리가 사용하는 함수가 베르누이분포이기 때문에 필수적인 함수라고 볼 수 있다.
from sklearn.datasets import load_digits
digits=load_digits()
X=digits.data
y = digits.target
X
from sklearn.preprocessing import Binarizer
X2=Binarizer(7).fit_transform(X)
X2
이렇게 바뀐것을 확인할 수 있다.
(2) BernoulliNB 클래스의 binarize 인수를 사용하여 같은 문제를 풀어본다.
BernoulliNB(binarize=7) 로 입력하여서 binarize없이도 만들어 낼 수 있다.
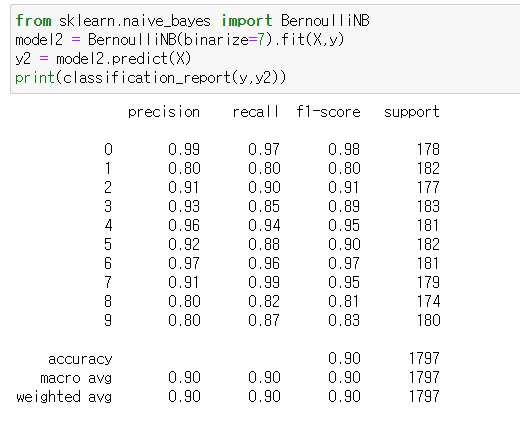
(3) 계산된 모형의 모수 벡터 값을 각 클래스별로 8x8 이미지의 형태로 나타내라. 이 이미지는 무엇을 뜻하는가?
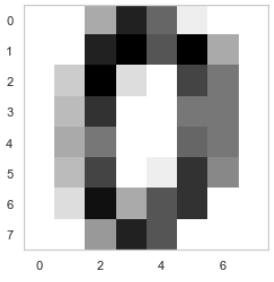
from sklearn.datasets import load_digits digits=load_digits() X=digits.data y = digits.target plt.imshow(X[0,:].reshape(8,8),cmap=plt.cm.binary) plt.grid(False) plt.show()
from sklearn.preprocessing import Binarizer X=Binarizer(7).fit_transform(X) plt.imshow(X[0,:].reshape(8,8),cmap=plt.cm.binary) plt.grid(False) plt.show()
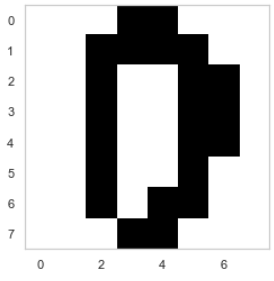
from sklearn.naive_bayes import BernoulliNB
model2 = BernoulliNB().fit(X,y)
y2 = model2.predict(X)
from sklearn.metrics import classification_report
print(classification_report(y,y2))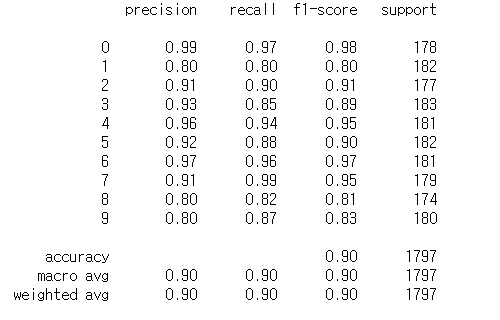
다항분포 나이브베이즈 모형
기존에 동전과 같이 나올 수 있는 경우가 두가지 인것과 다르게 주사위를 여러번 던지어서 나온 경우들을 다시금 카운트한 것을 이야기 한다.
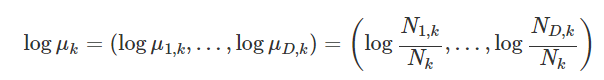
보면알겠지만 가능도함수의 공식은 베르누이분포와 크게 다르지 않다.
반면 스무딩 공식은
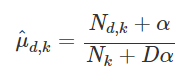
베르누이분포와 다르게 α값에 D라고 하는 나올 수 있는 경우의 수가 붙게 된다. 예를들어서 주사위는 6면, 6가지의 경우의 수가 존재하기 때문에 D는 6이 들어가게 된다.
속성 역시 베르누이분포와 동일하다
- featurecount: 각 클래스 k에서 d번째 면이 나온 횟수 Nd,k
- featurelog_prob: 다항분포의 모수의 로그
- 사용법
X = np.array([
[3, 4, 1, 2],
[3, 5, 1, 1],
[3, 3, 0, 4],
[3, 4, 1, 2],
[1, 2, 1, 4],
[0, 0, 5, 3],
[1, 2, 4, 1],
[1, 1, 4, 2],
[0, 1, 2, 5],
[2, 1, 2, 3]])
y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
from sklearn.naive_bayes import MultinomialNB
model_mult = MultinomialNB().fit(X, y)- 연습 문제 3
베르누이분포에서는 어쩔 수 없이 값을 0과 1로만 구분지었다 하지만 다항분포 나이브베이즈에서는 그렇게 할 필요가 없다.
MNIST 숫자 분류문제를 다항분포 나이브베이즈 모형을 사용하여 풀고 이진화(Binarizing)를 하여 베르누이 나이브베이즈 모형을 적용했을 경우와 성능을 비교하라.
from sklearn.datasets import load_digits
digits = load_digits()
X2 = digits.data
y2 = digits.target
from sklearn.naive_bayes import GaussianNB
model = GaussianNB().fit(X2, y2)
y2_pred = model.predict(X2)
from sklearn.metrics import classification_report
print(classification_report(y2, y2_pred))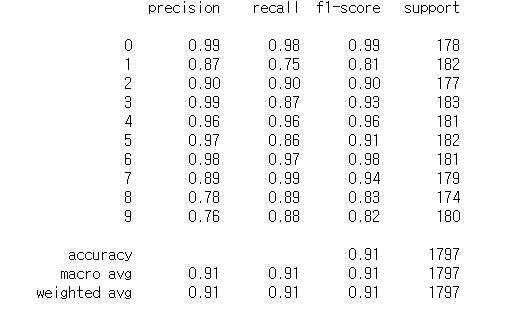
위에서 보았던 베르누이분포 보다 정확도가 올라간 것을 확인할 수 있다.
- 연습 문제 4
텍스트 분석에서 TF-IDF 인코딩을 하면 단어의 빈도수가 정수가 아닌 실수값이 된다. 이런 경우에도 다항분포 모형을 적용할 수 있는가?
텍스트 분석에 나이브베이즈 밖에 사용할 수 있는 모형이 많이 존재하지 않는다. TF-IDF 인코딩을 사용하여서 문서를 처리한다. TF-IDF는 그 단어가 들어가 있는 문서의 갯수를 계산하여 준다. 그런데 문제는 이 인코딩 방식은 실수값을 사용한다. 과연 실수값에서도 정수를 가정한 다변수 나이브베이즈 모형이 작동할지가 문제이다.
X4 = np.array([
[3.1, 4.0, 1.0, 2.0],
[3.0, 5.0, 1.0, 1.0],
[3.0, 3.5, 0.0, 4.0],
[3.0, 4.0, 1.0, 2.8],
[1.0, 2.1, 1.0, 4.0],
[0.0, 0.0, 5.0, 3.0],
[1.0, 2.0, 4.0, 1.0],
[1.0, 1.0, 4.1, 2.0],
[0.0, 1.0, 2.0, 5.0],
[2.9, 1.0, 2.0, 3.0]])
y4 = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
from sklearn.naive_bayes import MultinomialNB
model_mult4 = MultinomialNB().fit(X4, y4)
y4_pred = model_mult4.predict(X4)
from sklearn.metrics import classification_report
print(classification_report(y4, y4_pred))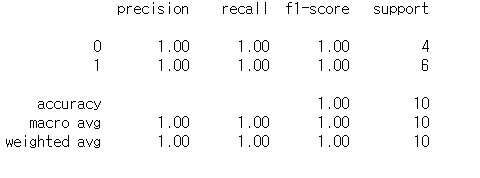
결론은 별탈없이 결과가 나오지만 개똥같은 결과가 나온다. 그렇기 때문에 사용할거면 최대한 가정한 것을 따라서 코딩하자.
뉴스그룹 문제
pipeline : 기존에 모델을 만든다면
x_train -> preprocess -> fit -> transform -> model -> fit 와
x_test -> transform -> model -> predit의 매우 복잡한 구조를 가지고 있었다.
하지만 piprline으로 위의 과정들을 모두 이어내면
x_train -> fit 과
x_tes -> predict 만으로 과정을 줄일 수 있게 된다.
그래서 뉴스데이터를 가지고 와서 실재 파이프라인을 구성하여 보자
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset="all")
X = news.data
y = news.target
from sklearn.feature_extraction.text import TfidfVectorizer, HashingVectorizer, CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
# vect, model : Pipeline 안에 있는 과정들의 이름 - 원하는데로 조절
model1 = Pipeline([
('vect', CountVectorizer()),
('model', MultinomialNB()),
])
model2 = Pipeline([
('vect', TfidfVectorizer()),
('model', MultinomialNB()),
])
model3 = Pipeline([
('vect', TfidfVectorizer(stop_words="english")),
('model', MultinomialNB()),
])
model4 = Pipeline([
('vect', TfidfVectorizer(stop_words="english",
token_pattern=r"\b[a-z0-9_\-\.]+[a-z][a-z0-9_\-\.]+\b")),
('model', MultinomialNB()),
])위에서 만든 파이프라인을 활용하여서 가져온 뉴스 데이터를 데이터 처리해보자
%%time
from sklearn.model_selection import cross_val_score, KFold
for i, model in enumerate([model1, model2, model3, model4]):
scores = cross_val_score(model, X, y, cv=5)
print(("Model{0:d}: Mean score: {1:.3f}").format(i + 1, np.mean(scores)))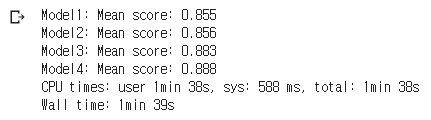
분석결과 stop_words가 좀 더 많을 수록 데이터가 정확하게 나온 것을 확인할 수 있다.
연습 문제 5
(1) 만약 독립변수로 실수 변수, 0 또는 1 값을 가지는 변수, 자연수 값을 가지는 변수가 섞여있다면 사이킷런에서 제공하는 나이브베이즈 클래스를 사용하여 풀 수 있는가?
이제 생각해 보자 사용 용도에 따라서 나이브베이즈를 나눈 것을 확인할 수 있다. 하지만 만약 데이터가 우리가 원하는데로 한 종류로 한정된 것이 아닌 중구난방으로 종류가 흩어져 있다면 어떻게 처리하여야 하는 것일까?
이 경우에는 가능도 함수에서 x의 범위를 쪼개는 방법이 존재한다.
만약 1~10 까지 실수이고 11~20까지 0과 1이고 21~30까지 정수이면 각 범위로 쪼개어서 구한다.
(2) 사이킷런에서 제공하는 분류문제 예제 중 숲의 수종을 예측하는 covtype 분류문제는 연속확률분포 특징과 베르누이확률분포 특징이 섞여있다. 이 문제를 사이킷런에서 제공하는 나이브베이즈 클래스를 사용하여 풀어라.
