※ 출처 : 데이터 사이언스 스쿨
확률적 데이터와 확률변수
확률적 데이터
확률적 데이터 : 예측할 수 없는 값
분포
확률적 데이터의 확률이 나올 빈도를 기록한 것
표현하는 방법
1. 카운트 플롯 (범주형 데이터일 때)
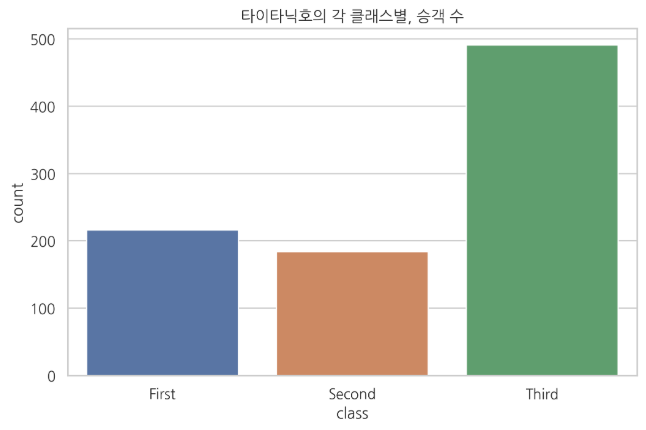
sns.countplot(x="class", data=titanic)
plt.title("타이타닉호의 각 클래스별, 승객 수")
plt.show()2. 히스토그램
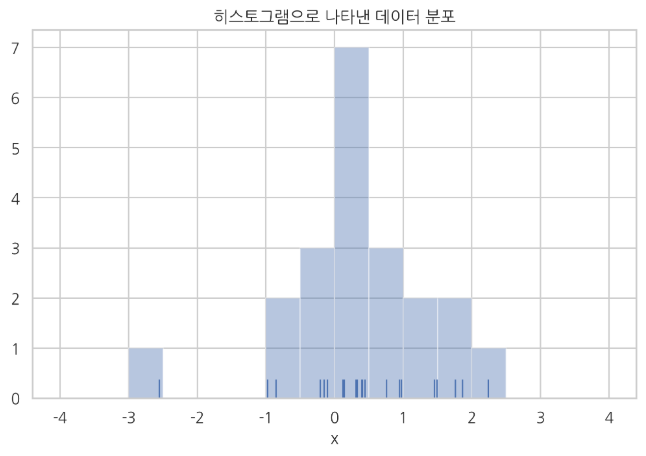
- 내가 만든 히스토그램을 이미지로 출력하는 magic command
%matplotlib inline
- 랜덤의 난수 값을 저장
np.random.seed(0) #random의 seed 값 변경
x = np.random.normal(size=21) #무작위 표본 추출
- 만들어진 난수를 표현하기
bins = np.linspace(-4, 4, 17)
sns.distplot(x, rug=True, kde=False, bins=bins)
plt.title("히스토그램으로 나타낸 데이터 분포")
plt.xlabel("x")
plt.show()3. 기술통계 = 묘사통계, 요약통계
: 여러가지 숫자를 계산하여 그 숫자로서 분포를 나타내는 것
- 표본평균, 표본중앙값, 표본최빈값
- 표본분산, 표본표준편차
- 표본왜도, 표본첨도
1) 표본평균
: 분포를 요약하는 대푯값
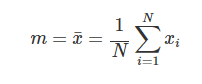
표본평균은 데이터 분포의 대략적인 위치
import numpy as np
np.mean(x)2) 표본중앙값
: 전체 자료를 크기별로 정렬하였을 때 가장 중앙에 위치하는 값을 의미
만약 데이터의 수가 짝수이면 N/2 과 N/2+1 값의 평균이 중앙값
만약 데이터의 수가 홀수이면 (N+1)/2 번째 표봄값이 중앙값
import numpy as np
np.median(x)3) 표본최빈값
: 데이터값 중 가장 빈번하게 나오는 값을 의미하지만 연속적인 값을 가지는 데이터에서는 똑같은 값이 나올 확률이 매우 작기 때문에 의미가 없음
import numpy as np
np.argmax(x) #이산 데이터의 최댓값 계산
np.histogram(x) #데이터를 구간으로 나누어 각 구간에 들어가는 데이터 개수 계산4) 분산과 표준편차
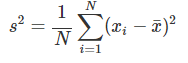
분산은 위와 같은 공식으로 계산하며 이때 주의하여야 하는 점은
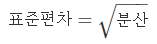
위의 공식으로 표준편차를 다시금 구할 수 있다.
np.var(x) #표본분사
np.std(x) #표본표준편차
np.var(x, ddof=1) #비편향 표본분사
np.std(x, ddof=1) #비편향표본표준편차4. 분포의 표현
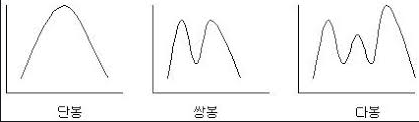
분포의 모양에 따라 단봉/쌍봉/다봉의 세가지로 분류하여 호칭
또한 대칭분포또한 존재하는데 분포가 표본평균을 기준으로 대칭인 분포를 대칭분포라고 부르며 이때 표본중앙값과 표본평균은 같은 단봉분포이다.
경우에 따라서는 하나의 최고값만을 가지는 단봉분포에서 표본최빈값은 표본평균과 같아지기도 한다.
5. 표본비대칭동
: 확률표본이 대칭분포인지 확인하는 방법으로(평균과의 거리의 세제곱 이용)
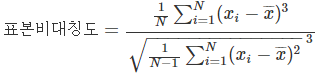
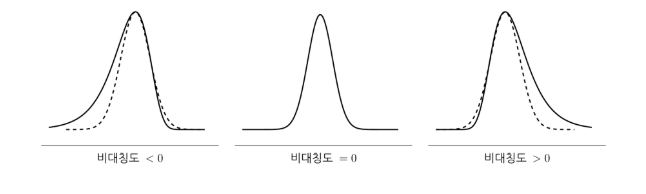
위의 공식을 활용하여 구할 수 있다. 이때 0에 가까울 수록 대칭분포의 형태를 뛴다.
6. 표본첨도
: 데이터가 얼마나 중앙에 몰리어 있는지를 확인하는데 사용하는 방법이다.
(평균과의 거리의 네제곱 이용)
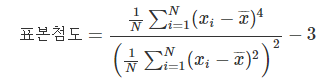

예술가