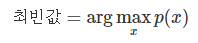powerd by 데이터 사이언스 스쿨
1. 확률변수의 기댓값
2. 확률변수의 변환
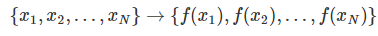
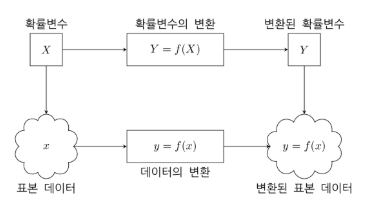
확률변수를 함수에 넣어 새로운 데이터를 뽑아낸다.
이렇게 기존의 확률변수를 사용하여 새로운 확률변수를 만드는 것을 확률변수의 변환이라고 한다.
이때 중요한 게 지금 다루고 있는 pmf 의 확률변수는 나올 수 있는 경우들이지 확률을 뜻하지 않는다.
예시로 주사위를 굴리는데 확률변수 Y는 확률변수 X의 두배의 값을 가진다고 하면
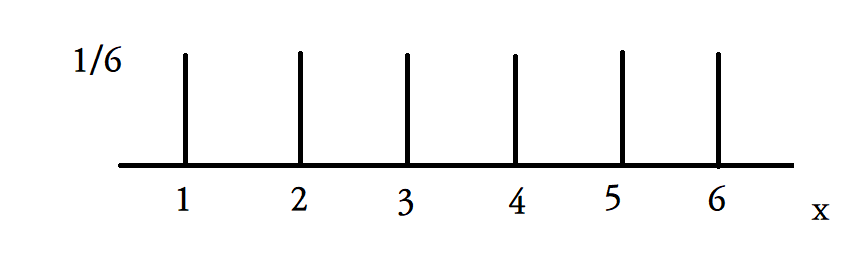
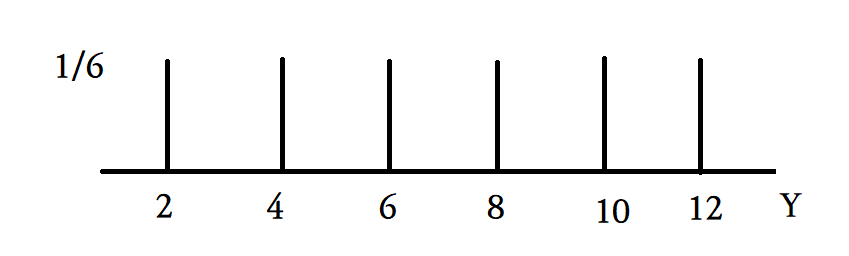
이렇게 확률은 동일한데 확률변수의 값만 다른 두개의 pmf 가 나오게 된다.
이렇게 보는게 오히려 맞을 것이다.
만약 여러번의 케이스를 돌리어서 다른 확률변수가 나왔다면?
그때는 X 기호 오른쪽 아래에 몇번째로 돌린 경우인지 적어주면 된다.
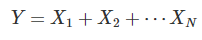
3. 기댓값의 성질
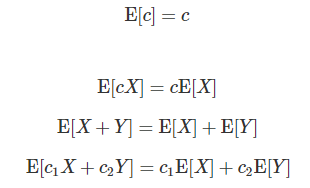
위의 4가지만 알면 된다.
code : 확률변수 곱이 아니면 뭐든지 분리가능
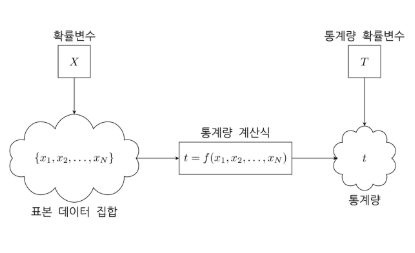
4. 통계량
확률변수에서 N개의 모든 데이터를 뽑아낸 다음 데이터들을 어떤 공식에 집어 넣어서 하나의 숫자를 국한 것을 통계량이라고 한다. 예를 들어 표본의 합, 표본평균, 표본중앙값 같은 우리가 익히 아는 값들을 이야기 한다.
1) 표본평균 확률변수
확률변수에서 N개의 데이터를 뽑아내여 평균값을 구해내는 것을 표본평균이라고 부른다.
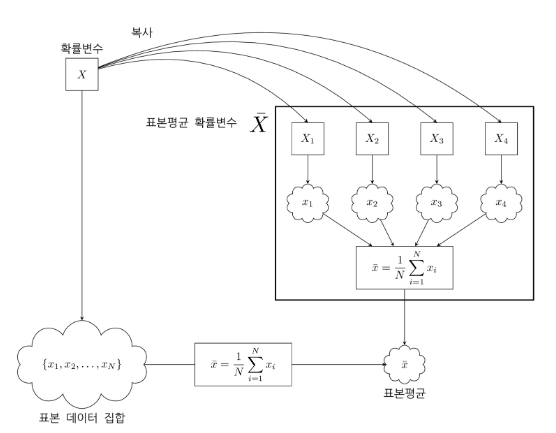
사실은 위에서 배운 확률변수 변환에 사용되는 함수를 여기에서는 평균값으로 정의한 것일 뿐이다.
그래서 표본평균 확률변수에서 X_i는 i번째로 실형된 표본값을 생성하는 확률변수를 의미한다. 그리고 이렇게 생성된 확률변수는 평균을 내어서 표본평균을 구해낼 수 있다.
2) 기댓값과 표본평균과 관계
연습문제 7.3.3

내 대답
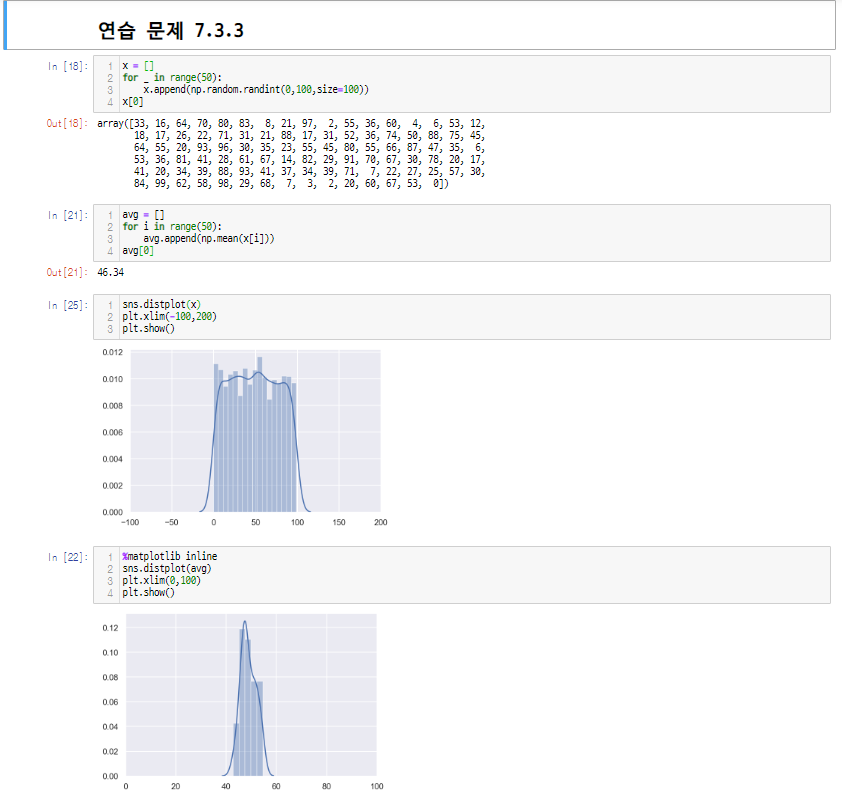
여기에서 중요한 것은 우리가 사용하던 확률변수 하나의 표본평균과 확률변수들의 표본평균들의 평균은 값이 같다!!
그렇기 때문에 위의 결과 그래프에서도 값들이 대다수 중앙에 몰리어 있다는 것을 알 수 있고 이는 나아가
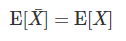
라는 수식이 맞다는 것을 알 수 있다.
즉, 표본평균은 확률변수의 기댓값 근처의 값이 된다.
그럼 이 정보가 왜 필요할까? 우리는 모집단의 값을 모르기 때문에 표본들의 값으로 모집단의 값을 구해야 한다. 그런데 여기에서 표본평균의 평균은 모집단의 기댓값과 같다는 결론이 나왔기에 우리는 앞으로 표본평균들을 미리 구해놨다면 쉽게 모집단의 평균을 구할 수 있다.
3) 중앙값
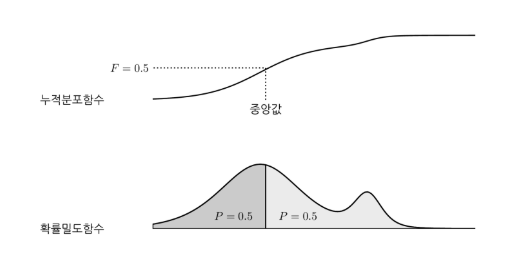
중앙값은 pdf의 중간을 잘라 좌 우 히스토그램의 면적이 0.5로 동일한 값이 나오게 하는 값을 의미한다.
cdf에서는 높이가 0.5가 되는 위치의 값을 의미한다.
4) 최빈값
최빈값은 pdf 가 가장 커지는 위치를 의미한다.