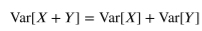이산확률변수가 두 개 이상 있는 경우에느 각각의 확률분포 뿐만 아니라 복합적인 확률분포를 살펴보아야 한다. 이걸 결합확률분포함수라고 부른다.
pmf : 확률질량함수
pdf : 확률밀도함수
grades = ["A", "B", "C", "D", "E", "F"]
scores = pd.DataFrame(
[[1, 2, 1, 0, 0, 0],
[0, 2, 3, 1, 0, 0],
[0, 4, 7, 4, 1, 0],
[0, 1, 4, 5, 4, 0],
[0, 0, 1, 3, 2, 0],
[0, 0, 0, 1, 2, 1]],
columns=grades, index=grades)
scores.index.name = "Y"
scores.columns.name = "X"
pmf = scores / scores.values.sum()위와 같은 변수를 사용할 예정이다.
배울것을 요약하자면
결합 pmf, 주변 pmf, 조건부 pmf
결합 pdf, 주변 pdf, 조건부 pdf
다변수 확률변수
결합확률질량함수
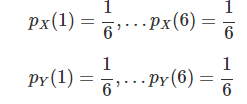
X와 Y 각각을 확률질량함수로 표현하면 위와 같고
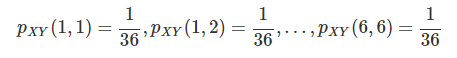
X와 Y를 함께 확률질량함수로 표현하면 위와 같다.
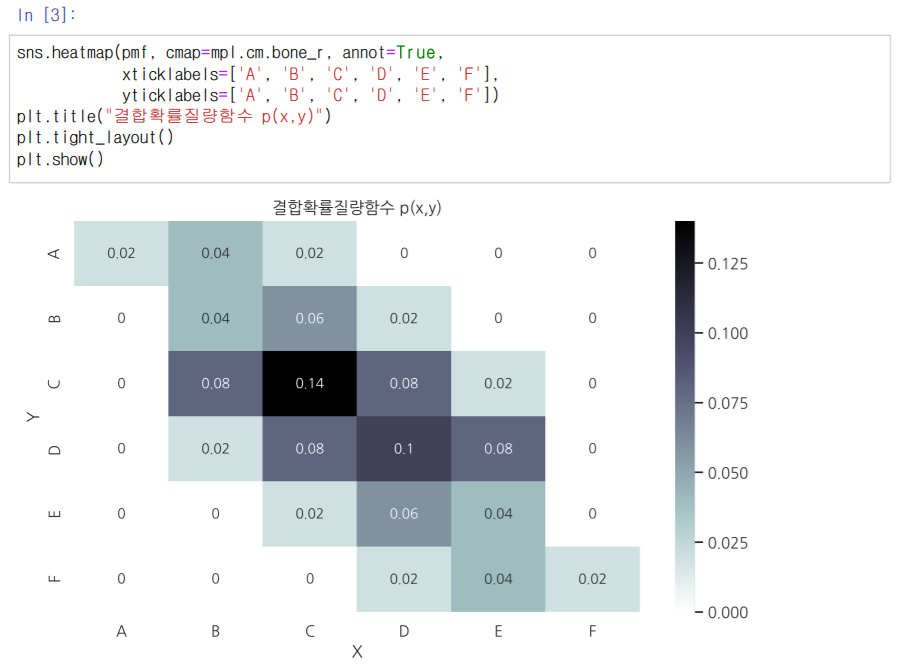
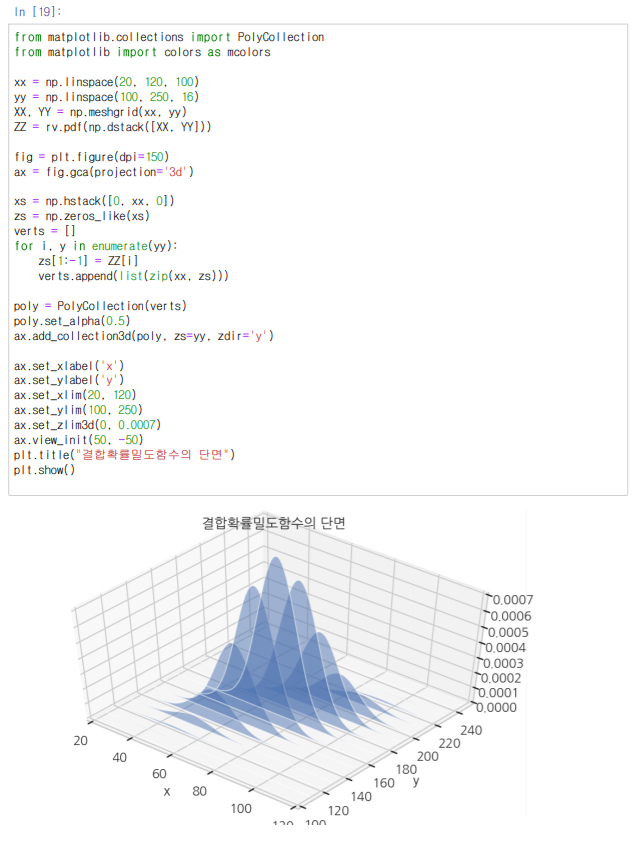
실재 위의 확률들을 결합활률질량함수로 출력해 보면 다음과 같은 그래프를 그릴 수 있을 것이다.
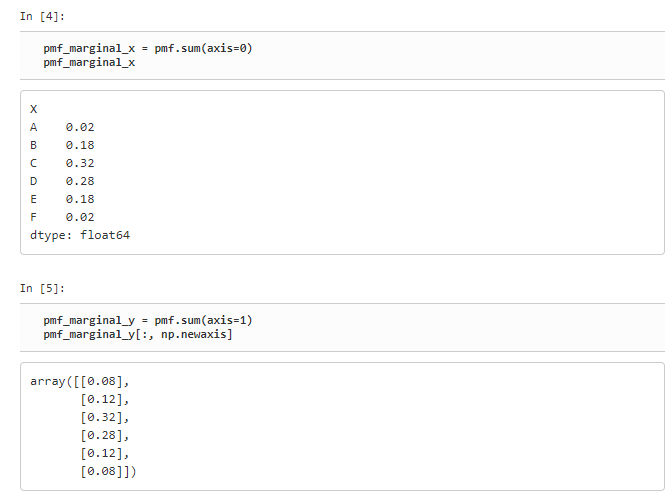
주변확률질량함수
결합확률질량함수에 대해 하나의 확률변수 값에 대해서만 확률분포를 표시한 함수를 주변확률질량함수라고 부른다.
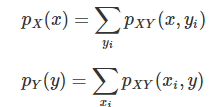
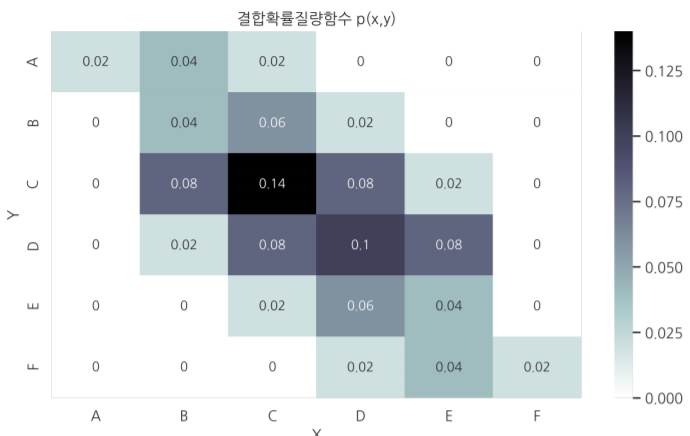
이를 보기 쉽게 그림으로 표현하면 위와 같이 나열된 결합확률질량함수를 한방향을 잡고서 쭉 더한 것과 같다고 볼 수 있다.
실재 코드에서는 sum과 axis를 이용하여서 구하면 된다. (pmf는 DataFrame 이름이다)
3. 조건부확률질량함수
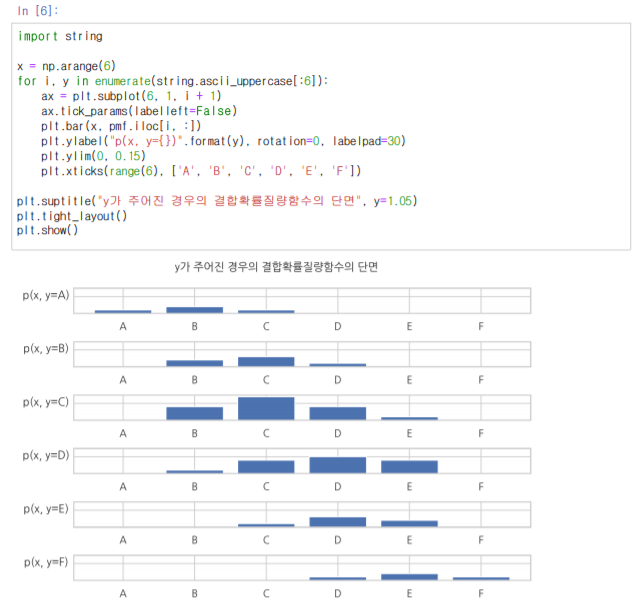
위의 이미지는 각 값변 확률을 나타낸 값들이다. 보면 알겠지만 위에서 보았던 결합확률질량함수이다. 하지만 과연 여기에서 y의 값이 정해졌다면 관련된 확률질량함수들은 확률분포인가? 만약 확률분포라고 하면 합이 1이 되어야 할 것이다. 하지만 위의 값들의 합은 결코 1이 나올 수 없다.
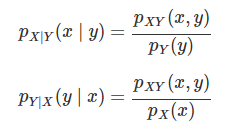
그렇기에 하나의 조건하에서 확률분포를 만들어 준 것을 조건부확률질량함수라고 부를 수 있다. 다른말로 단면을 짤라서 확률을 구한 것을 조건부확률질량함수라고 부른다.
그리고 그 결과는 전체적으로 값이 커지기 때문에 그 합이 1이 되었다고 볼 수 있다.
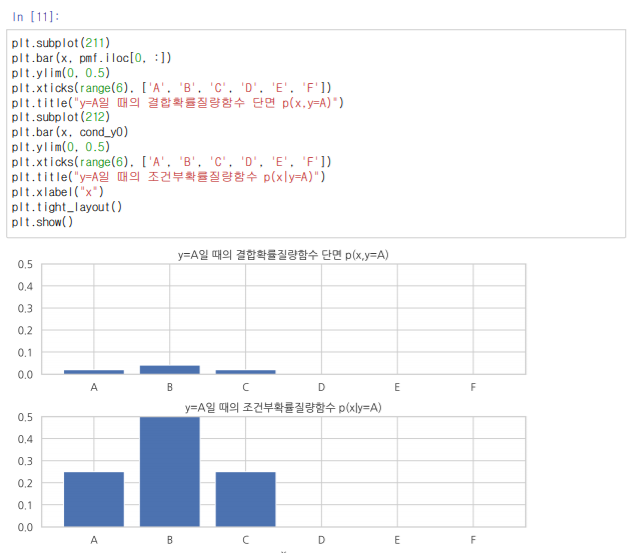
다변수 연속확률변수
이제 pdf에 대해서 다루어 보자 pdf는 pmf와 다르게 연속된 값을 사용하며 어떤 근처에서 값이 얼마나 많이 나왔는지를 알려주는 상대적인 값이다.
그렇기 때문에 위와 같은 그래프에서 임의의 가장 많이 나올 값을 찍어보라고 하면 y:170에 x:70일 것이다. 왜? 이 값이 상대적으로 다른 값에 비해서 많이 나왔기 때문에 중앙에 위치한 것이기 때문이다.
결합누적확률분포함수
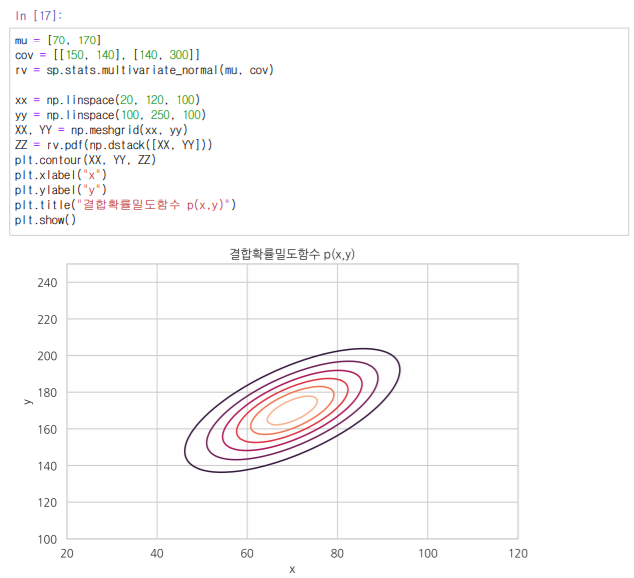
결합확률밀도함수/주변확률밀도함수
위와 같이 한 방향으로 값을 모두 모아 낸 것을 주변확률밀도함수라고 부른다.
이를 좀 더 자세하게 단면으로 보면 위와 같은 등고선을 띄게 될 것이다.
조건부확률밀도함수
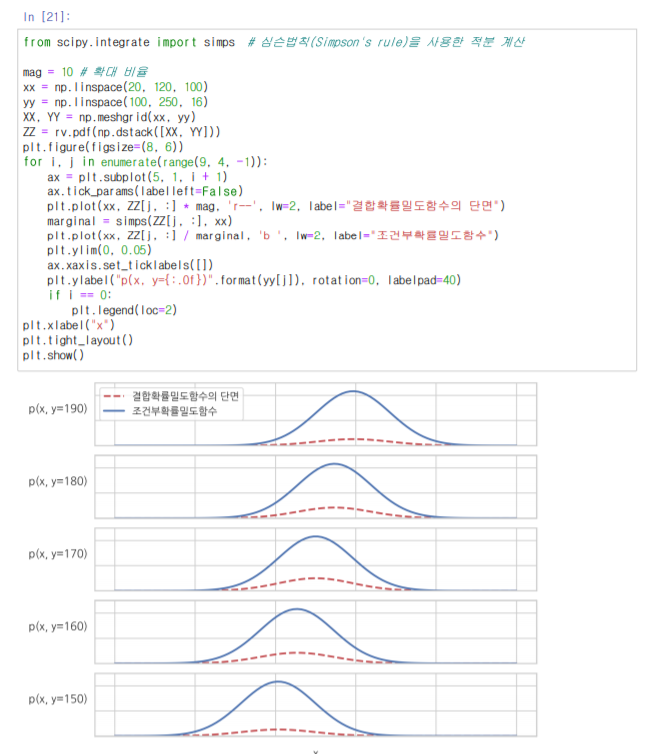
여기에서 조건부확률밀도함수는 위와 같이 단면을 면적으로 나누어 주면 그 합이 1이 되기 때문에 조건부확률밀도함수라고 부를 수 있다.
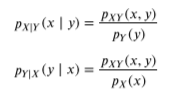
독립과 상관
-
상관 : 두 확률변수가 있을 때, 한 확률변수의 표본 값이 달라지면 다른 확률변수의 조건부 분포가 달라질 때 서로 상관 관계가 있다고 볼 수 있다.
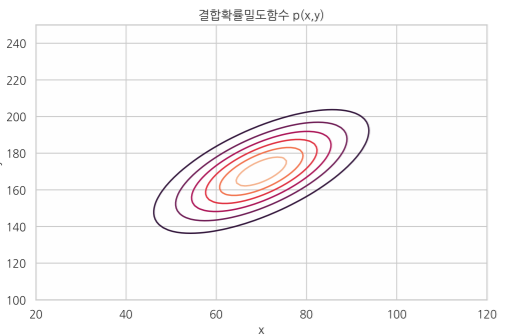
예를 들어서 키와 몸무게의 pmf가 존재한다고 하자 만약 이때 y 값 즉 키가 달라진다면 몸무게의 값도 바뀐다고 볼 수 있는가? 위의 그래프를 보면 그렇다. 이러한 변화가 생기는 것을 우린 서로 상관 관계가 있다고 부른다는 것이다. -
독립 : 반대로 두 확률변수가 상관 관계가 아니면 서로 독립이라고 부른다.
이를 수학적으로 표현하면 다음과 같다.
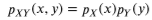
또한 이때 3변수 이상에서 독립이라면 어떠한 변수 두개를 고르더라도 서로 독립이다.
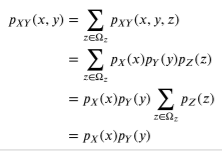
왜냐하면 위와 같이 Z의 확률 값의 합은 1이기 때문에 그 결과는 동일하기 때문이다.
반복시행
반복시행은 독립의 가장 큰 예시이다. 만약에 주사위를 돌린다고 생각하여 보면 주사위가 중간에 깨지지 않는 이상 모든 면의 확률은 동일할 것이다. 이때 매 시행에서 나온 값들의 조합 확률은 모든 확률을 곱한 것과 같다.
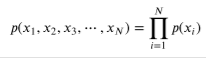
조건부 확률분포(독립)
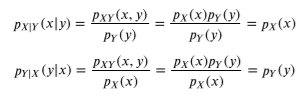
독립일때의 조건부 확률분포는 분자의 항이 두개로 분리되는 차이점이 생기게 된다. 이는 다른 말로 조건이 어떤 값이든 상관없이 이 조건부 확률분포는 항상 같은 값을 가지게 된다.

그래서 이전에는 두 확률변수의 결합확률질량함수를 각 칸에 맞추어 일일히 구하여 주었지만 이제는 그냥 X와 Y의 분포값들을 쭉 구한다음 서로서로 곱하여서 주변확률질량함수를 구하면 결합확률질량함수가 나오게 된다.
그러면 좀 더 쉽게 독립인지를 확인하는 방법은 없을까?
독립 확률변수의 기댓값
독립인 두 확률변수 X, Y의 기댓값은 다음 성질을 만족한다.
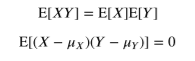
이러한 성질은 나아가 분산에도 영향을 미친다.
독립 확률변수의 분산
전단원에서 다루었다 싶이 분산의 합은 따로 띄어 노을 수 있다. 단, 특이하게 생긴 식이 하나 더 붙어서.
하지만 독립일 경우 그 특이하게 생긴 식이 붙지 않아도 된다. 왜냐하면 그 값이 0 이니까.