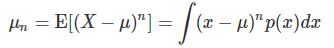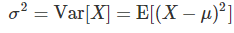
분산과 표준편차
우리가 하려는 목적은 데이터로 부터 pdf를 예측하는 것이다. 그렇기 때문에 pdf가 어디에 모여있는가를 알아내는 것을 기댓값(평균)이고 얼마나 퍼져 있는가를 알아보는게 분산과 표준편차이다.
확률분포의 분산
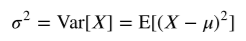
그래서 위와 같은 기호를 사용한다.
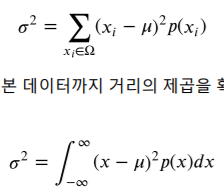
계산방법은 위와 같이 확률질량함수와 확률밀도함수 일때가 나누어져 있다.
분산의 성질
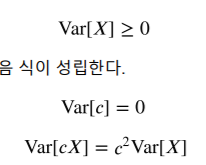
분산은 제곱으로 구해졌기 때문에 항상 양수이다.
상수의 분산은 0 이며 상수곱은 밖으로 나올때 제곱이 된다.
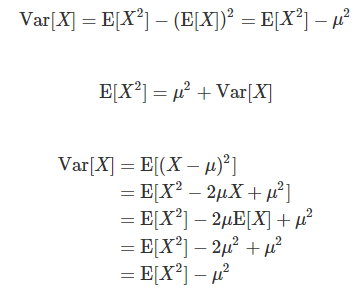
또한 분산은 기댓값의 연산으로도 구할 수 있다.
두 확률변수의 합의 분산
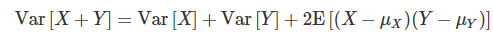
이제 E[X]는 위와 같이 요약된 기호를 사용하도록 하자 그래서 두 확률변수의 분산은 위와 같은 성질을 만족하게 된다.
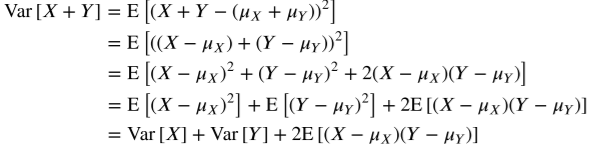
확률변수의 독립
두 확률변수가 서로 독립(independent)이라는 것은 두 확률변수가 가질 수 있는 모든 사건의 조합에 대해 결합사건의 확률이 각 사건의 확률의 곱과 같다는 뜻이다.
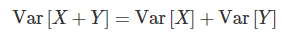
이때 매우 중요한 성질이 이전에는 두 확률변수의 합의 분산의 식이 매우 길었으나 두 확률변수가 독립이라면 기댓값이 0이 되어 위와 같은 수식만 남게 된다.
표본평균의 분산
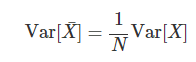
데이터의 갯수로 분산을 나눈것과 표본평균의 분산과 값이 같다
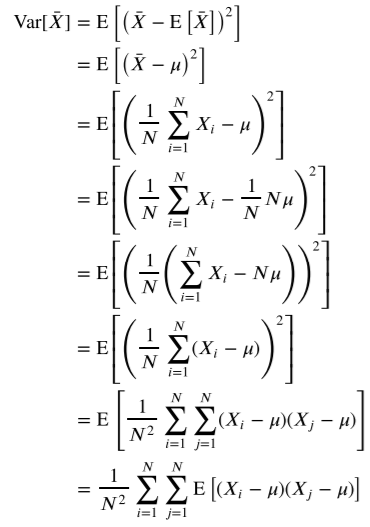
마지막에 i와 j가 다르다면 서로 독립이다.(주사위는 언제 뽑든 서로에게 영향을 미치지 않는다.) 따라서 i와 j가 같은 항만 남게 되고 아래의 식으로 변화하게 된다.
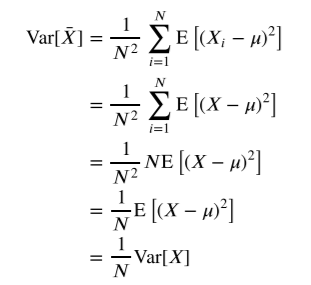
그렇다면 정리해 보자
1. 표본평균의 평균은 모집단의 평균과 같고
2. 표본평균의 분산은 모집단읜 분산의 데이터 갯수로 나눈것과 같다.
우리가 표본을 잘뽑아내면 실재 모집단이 나오겠지만 아니라면? 그 경우 분산이 넓기 때문에 진짜 모집단인지 알 수가 없다.
그렇기에 모집단을 수십 수억개로 늘리어서(N값) 표본평균 분산을 한없이 0으로 보낸다면?(공식에 따라 표본평균의 분산은 모집단의 분산을 갯수로 나눈것과 같다.)
그때는 어떤 데이터를 뽑든 모집단의 평균과 같은 값이 나올 수 밖에 없다.
데이터의 갯수가 무한하면 표보평균의 평균이 모집단의 평균이다.
연습문제 7.3.3

표본분산의 기댓값
이제 기댓값을 구하기는 하였지만 모집단의 분산은 여전히 알 방법이 없다. 하지만 위에서 평균에 대한 이야기를 하였으니 어째서인지 분산도 비슷한 성질을 뛸껄로 예상이 된다.
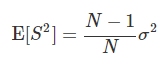
표본의 분산의 평균은 모집단의 분산의 값에 (N-1)/N 을 곱한것과 비슷하다.
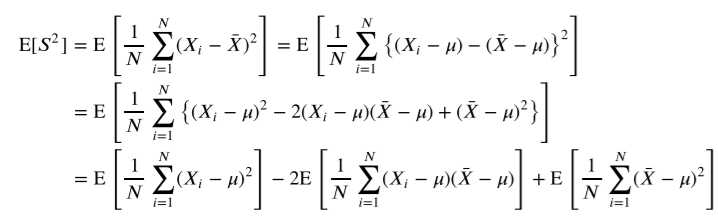
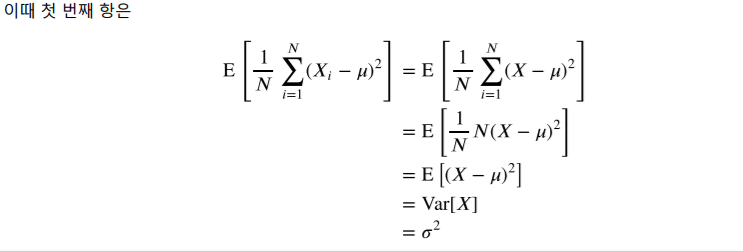
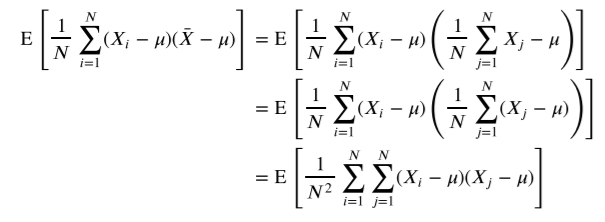
i와 j가 같을 때를 제외하고는 모두 독립이기 때문에
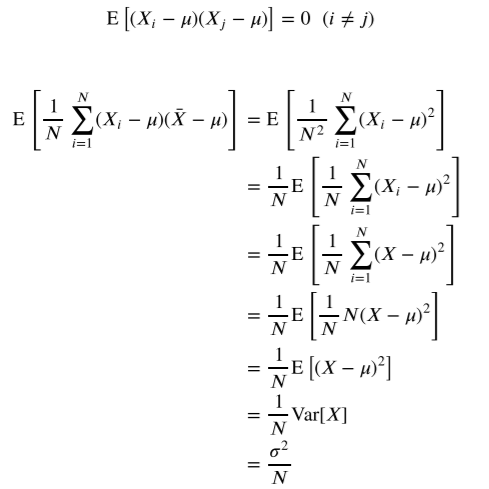
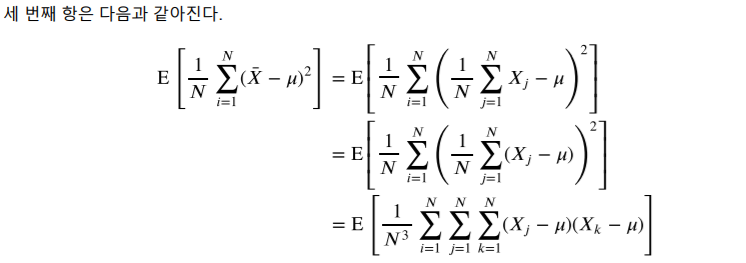
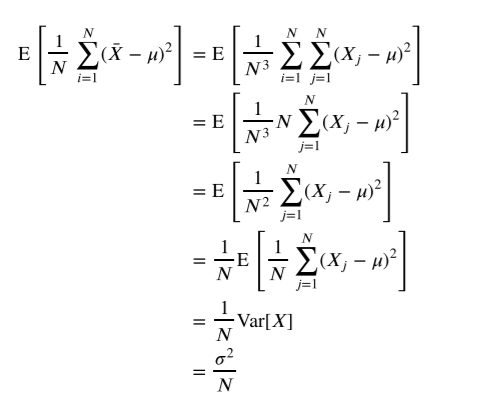
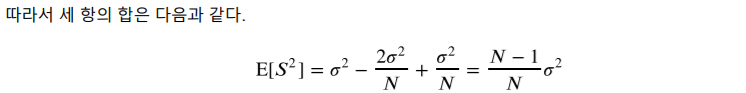
증명은 위와 같다.
위의 계산은 편향된 분산값이다. 왜냐하면 표본평균의 값이 데이터가 많이 몰려있는 쪽으로 편향되기 때문이다.
만약 이렇게 데이터가 몰려있는 위치에 있는 표본평균을 기준으로 각 데이터까지의 거리를 계산하면 원래의 기댓값으로부터의 거리보다 작게 나올 수 있다.

따라서 편향된 표본분산 값 앞에 N/(N-1) 을 곱하여 주어서 조금 더 큰 값을 만들어 주어야 한다.
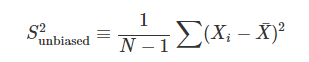
사실상 위의 식만을 알고 있어도 이번단원에서 가장 중요한 부분을 알고 간것으로 생각해 볼 수 있다.

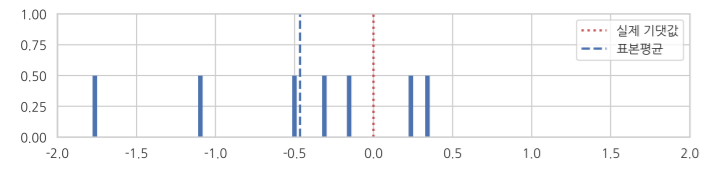
이러한 이유를 좀 더 직관적으로 이해하기 쉽도록 설명해 보면 위와 같이 설명될 수 있다.
한마디로 우리가 표본에서 구한 평균은 실재 모평균과는 괴리가 존재하게 된다. 특히나 한 쪽으로 몰리어 있기에 그 값이 오히려 작게 나오는 것이다.
비대칭도와 첨도
-
비대칭도(skew) : 3차 모멘트 값에서 계산하고 확률밀도함수의 비대칭 정도를 가리킨다. 비대칭도가 0이면 확률분포가 대칭을 의미한다.
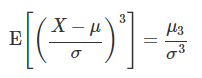
-
첨도(kurtosis) : 4차 모멘트 값에서 계산하며 확률이 정규분포와 대비하여 중심에 모여있는지 바깥으로 퍼져있는지를 나타낸다.
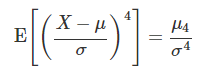
모멘트
위에서 다룬 값 모두 모멘트이고 앞으로는 아래와 같이 모멘트를 정의하도록 한다.