[Python] 대학원 입학과 스펙의 연관성 #7_feature선택, 숫자 데이터 표준화

우리가 흔히 말하는 '스펙' (GRE 점수, Research 여부, TOEFL 시험 성적 등)이 대학원 입학에 미치는 영향과 가장 중요한 역할을 하는 요소에 관한 데이터 분석
#7 에서는 feature선택과 숫자 데이터에 대한 표준화 방법에 대해 알아 보겠습니다
***해당 분석은 Google Colab를 활용하여 출력한 자료들입니다
주요 이상치 제거 방법
Feature 선택하기
feature_num = ['GRE', 'TOEFL', 'Univ.', 'SOP', 'LOR', 'CGPA', 'Research']
feature = ['Research']위는 2시그마를 기준으로 이상치를 제거하였고 그 보다 더 크거나 작은 값을 입력할수도 있다
숫자 데이터 표준화 하기
from sklearn.preprocessing import StandardScaler
#scaler 생성
scaler = StandardScaler()
scaler.fit(data[feature_num])
x_num = scaler.transform(data[feature_num])
#dataframe으로 변형
x_num = pd.DataFrame(data = x_num, index = data[feature_num].index, columns = data[feature_num].columns)
#dataframe 합치기
x = pd.concat([x_num, data[feature]], axis = 1)
y = data['Admit']
x.head()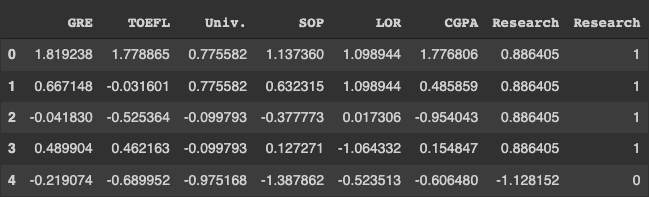
각 컬럼마다 숫자 범위가 달라서 그 중요도를 보기 어려울 때 위와 같이 표준값으로 변형시켜주면 그 변화를 한눈에 보기 쉬워진다
카테고리 데이터 DUMMY 처리 하기
#카테고리 데이터 dummy 처리하기
feature_category = ['Research']
#dummy 처리
x_category = pd.get_dummies(data[feature_category], columns = feature_category)
x_category.head()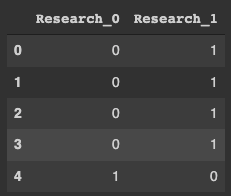
머신러닝이 학습할 수 있도록 변환 필요하기 때문에 위와 같이 실행한다

데이터 분석가