[Python] 대학원 입학과 스펙의 연관성 #8_Train Data & Test Data

우리가 흔히 말하는 '스펙' (GRE 점수, Research 여부, TOEFL 시험 성적 등)이 대학원 입학에 미치는 영향과 가장 중요한 역할을 하는 요소에 관한 데이터 분석
#8 에서는 train data와 test data에 대해 알아 보겠습니다
***해당 분석은 Google Colab를 활용하여 출력한 자료들입니다
환경 세팅하기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
#MAE (Mean Absolute Error) 실제값과 예측값 차이를 절대값으로 변환해 평균을 구하는 것
#RMSE (Root Mean Squared Error) 오차 제곱 평균값의 제급근
from sklearn.metrics import mean_squared_error, mean_absolute_error
from math import sqrtTrain Data, Test Data 값 선택하기
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.3, shuffle = True, random_state = 1)Linear Regression 값으로 오차 범위 계산
#1. model 생성
linear_model = LinearRegression()
#2. model 학습
linear_model.fit(train_x, train_y)
#3. model로 예측하기
linear_predict_y = linear_model.predict(test_x)
print("Linear Regression Error")
print("MAE : ", mean_absolute_error(test_y, linear_predict_y))
print("RMSE : ", sqrt(mean_squared_error(test_y, linear_predict_y)))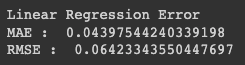
plt.title("Linear Regression")
plt.bar(train_x.columns, linear_model.coef_)
plt.show()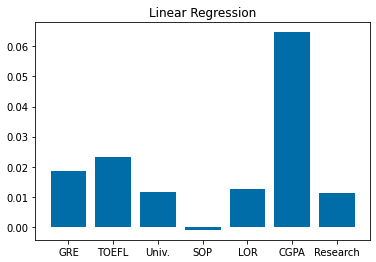
Random Forest 값으로 오차 범위 계산
#1. model 생성
randomforest_model = RandomForestRegressor()
#2. model 학습
randomforest_model.fit(train_x, train_y)
#3. model로 예측하기
randomforest_predict_y = randomforest_model.predict(test_x)
print("Random Forest Regression")
print("MAE : ", mean_absolute_error(test_y, randomforest_predict_y))
print("RMSE : ", sqrt(mean_squared_error(test_y, randomforest_predict_y)))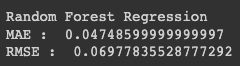
plt.title("Random Forest")
plt.bar(train_x.columns, randomforest_model.feature_importances_)
plt.show()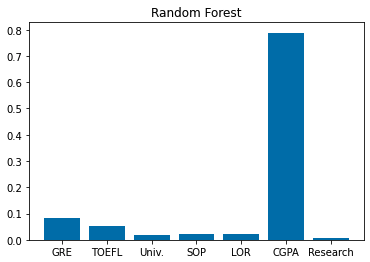

데이터 분석가