목표
- BMI 데이터를 활용하여 비만도를 판별하는 모델을 만들어보자
- 머신러닝 용어를 이해해 보 통해 머신러닝 과정 7단계를 이해 해보자
- 문제 정의: 목표/ 어떤 모델 생성/ 머신러닝 도구 어떤 것을 쓸것인지?
- 데이터 수집: DATABASE, 공공포털사이트(CSV, EXCEL, JSON), 크롤링, 설문조사(Survey)
- 데이터 정제(전처리: Preprocessing): 이상치 처리, 결측치 처리, 특성공학(처리, 수정, 불필요한 값 삭제, 새로운 의미로 추출)
- 탐색적 데이터 분석(EDA: Exploraty Data Analysis)
- 모델 선택 및 하이퍼 파라미터(사람 설정하는 값) 튜닝
- 모델 학습
- 모델 예측 및 평가
# 필요한 도구 셋팅
import pandas as pd # pandas 라고 하는 라이브러리를 불러서 pd(별칭)로 사용하겠음
import numpy as np # np 별칭
import matplotlib.pyplot as plt # plt 별칭, 시각화 도구
# 머신러닝 sklearn(scikit-learn)
from sklearn.neighbors import KNeighborsClassifier # knn 분류 모델
from sklearn.metrics import accuracy_score # 정확도 점수 ( 얼마나 잘 예측했는지 평가하는 지표)데이터 준비(수집)
# 데이터를 불러와서 data 변수 대입
# 퀴즈: pd csv 읽어주는 기능, 코드는 뭘까? pd.read_csv()
# CSV 파일을 읽어오는 예제
# 경로: 1. 절대경로 , 2. 상대경로
data = pd.read_csv('./data/bmi_500.csv')
# 데이터 프레임 출력
data
# 데이터 프레임에서 정보를 확인하는 기능(함수)
# info()
data.info()
# (500,4), 결측치x, Dtypes: int(정수), object(문자열)데이터 전처리: Gender 컬럼(특성) 삭제
# del, remove, drop
# data.drop('컬럼명', axis=1)
# 행 방향(축) axis=0, 열 방향 axis=1
data2 = data.drop('Gender', axis=1) # 결과화면 (저장)
# data 원본 상태 유지
data2.head(2) # 위에서 부터 행 2개 출력하는 기능 EDA(데이터 분석)
- 기술 통계량 확인
- 시각화를 통해 데이터 레이블 분포 현황 확인
# 퀴즈2: 판다스에서 기술 통계 확인하는 기능(함수)
# data.describe()
data2.describe()
# 몸무게 값이 높은 값으로 데이터가 수집되어 있음 확인
data['Label'].describe()
# data2.describe(include='all')# 클래스 개수 몇개인지 6개
# 레이블 각각 몇개씩 들어있는지
# .unique() 중복없이 값을 확인하는 기능
# .value_counts() 값의 횟수를 세어주는 기능
len(data2['Label'].unique())
print("클래스 개수:" ,data2['Label'].unique().size)
data2['Label'].value_counts()# 파이썬 사용자 정의 함수 생성
# def
def label_draw(label,color):
# 데이터 label에 해당하면 접근
# 시각화 코드
d = data2[data2['Label'] == label] # loc 접근 인덱서
plt.scatter(d['Weight'],d['Height'], label=label, c=color)# True 해당하는 행 출력하는 코드 * 데이터 사이언스
# data2[data2['Label'] == 'Weak']data2['Label'].unique()label_draw(label='Obesity',color='orange')
label_draw(label='Extreme Obesity',color='red')
label_draw(label='Overweight',color='yellow')
label_draw(label='Normal',color='green')
label_draw(label='Weak',color='cyan')
label_draw(label='Extrmely Weak',color='blue')
# 그래프 옵션
# x, y축 이름(레이블) 설정
# 범례 표시
plt.xlabel('Weight')
plt.ylabel('Height')
plt.legend()
plt.show()
# 2개 정도는 label값이 잘못 달렸을 수도 있겠다.
# 분석 마지막에 평가진행할 시 성능이 너무 안좋을 경우는 해당 데이터의 영향이 있을 수도 있지않을까?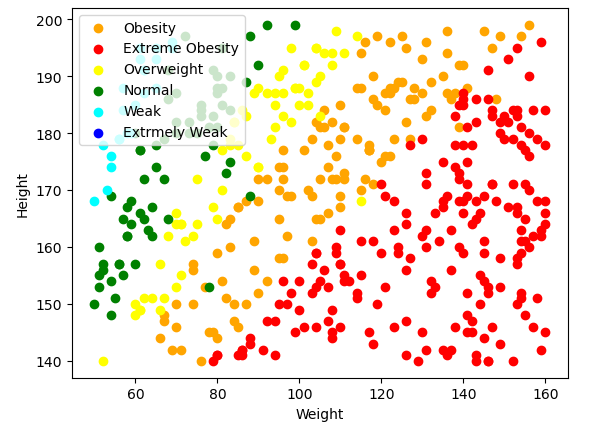
모델링(modeling)
# 모델 객체 생성 & 하이퍼 파라미터 정의
# K == n_neighbors == 확인하는 이웃의 수
# n_neighbors 값이 바뀌면 예측값 바뀐다!
knn_model = KNeighborsClassifier(n_neighbors=5)# 학습하기
# 재료 ( 학습 데이터 == 훈련 데이터 )
# 7:3 70% 훈련 , 30% 테스트(예측)# 컬럼(열) 분리
# 문제, 답 분리
X = data2[['Height','Weight']]
y = data2['Label']
#print('문제데이터:', X.shape)
#print('답데이터:', y.shape)
# data2.loc[:,['Height','Weight']]
# data2.loc[:,:'Weight']
# data2.iloc[:,[0,1]]
# data2.iloc[:,:2]
# 500개 70%> 350개
# 30%> 150개
X_train = X.iloc[:350] # X.iloc[시작행:끝행]
X_test = X.iloc[350:]
y_train = y.iloc[:350]
y_test = y.iloc[350:]
print("훈련문제:", X_train.shape)
print("훈련답:", y_train.shape )
print("테스트문제:", X_test.shape )
print("테스트답:", y_test.shape )훈련문제: (350, 2)
훈련답: (350,)
테스트문제: (150, 2)
테스트답: (150,)
# 학습하는 함수
# knn_model.fit(훈련문제, 훈련답)
# fit: 데이터에 맞춰서 모델이 학습하기 때문에
knn_model.fit(X_train, y_train)KNeighborsClassifier()
X_test.head(2)# 모델 예측하기
# 모델.predict(테스트문제)
pre = knn_model.predict(X_test)
# 예측값은 실제와 같다? 다를 수 있음
# 최대한 동일하게 맞추도록 하는게 좋은 모델
pre# 평가하는 함수(기능) - 분류 측정 지표
# accuracy_score()
# test 성능 확인
accuracy_score(y_test, pre) # 100% 다 맞춘 것, 90.6% 만큼 맞춘 것 0.9066666666666666
sklearn 모델 저장하는 코드
import joblib
# 모델을 저장할 때 사용하는 라이브러리
joblib.dump(knn_model, './data/bmi_knn_model.pkl')['./data/bmi_knn_model.pkl']
# 저장된 모델 불러와서 활용
bmi_model = joblib.load('./data/bmi_knn_model.pkl')
bmi_model.predict([[185,65],[165,65]])
h,w = input("height,weight입력>>").split(',')
# print(type(h),h)
result = bmi_model.predict([[int(h),int(w)]])
resultheight,weight입력>> 185,65
array(['Normal'], dtype=object)
print(f"당신의 몸무게는 {w}kg, 키는 {h}cm 입니다. bmi label은 {result[0]}입니다.")당신의 몸무게는 65kg, 키는 185cm 입니다. bmi label은 Normal입니다.

개발자