
본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
2. 이커머스 산업의 AI 혁신
이커머스 분야에서의 인공지능
- 맞춤형 상품 추천
- 개인화된 마케팅 전략
- 고객 편의 서비스 제공
맞춤형 상품 추천
고객은 스스로 경험한 적 없는 상품에 대한 선호도 파악이 어렵다.
하지만 기업은 보유한 데이터를 바탕으로 고객군 별로 모든 상품에 대한 선호도를 예측할 수 있다. 이를 바탕으로 고객 개개인에게 해당 선호동 예측 결과값을 제공한다.
👉 소비자 개개인의 데이터에 기반해 추천 상품 목록을 제작 및 제공, 추가 매출 기회 획득
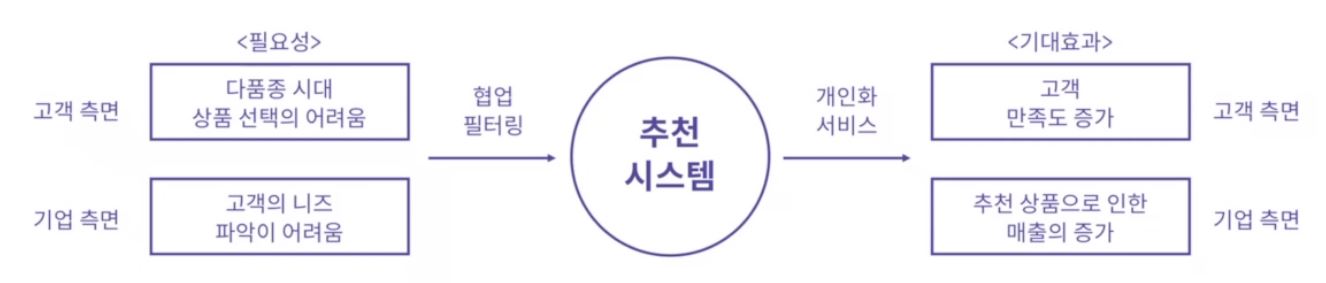
여기서 사용되는 것이 바로 추천 알고리즘이다.
추천 알고리즘
미리 설정한 규칙 기반 추천이 아닌 고객 데이터에 따른 인공지능형 추천 알고리즘이다.
구매 내역, 고객 프로파일, 소비 패턴, 상품 선호도 등의 데이터를 바탕으로 미래의 소비를 예측한다.
👉 고객들의 선호도 데이터가 많이 쌓일 수록 정밀한 예측이 가능!
추천 알고리즘에는 크게 두 가지가 있다. 아이템 기반 추천 방식과 이용자 기반 추천 방식이다.
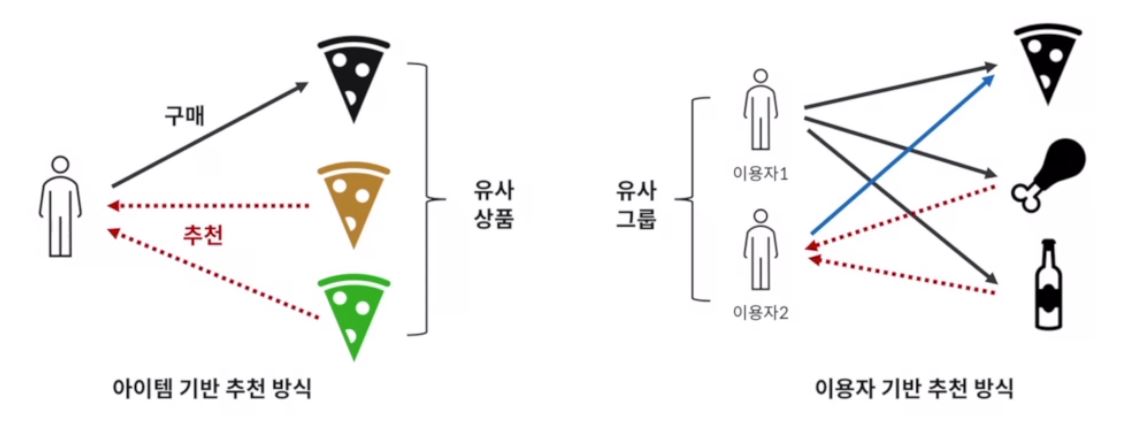
이 추천 알고리즘을 가장 잘 사용하는 대표적인 서비스가 바로 유튜브 추천 알고리즘이다
유튜브의 경우 대부분의 조회수가 검색이 아닌 추천 동영상을 통해 발생하며
고객 개인의 취향과 영상 간의 관계, 동질 집단의 특성 등을 분석하여 맞춤 동영상을 추천한다.
개인화된 마케팅 전략
고객 개개인의 특성을 분석하여 소비자들 각각에 최적화된 서비스를 제공하는 것이다.
다양한 도구를 통해 고객 프로파일, 행동, 성향, 관심사 데이터 등을 수집하여 분석한다.
👉 AI를 활용하여 고객별 구매 성향을 예측하여 맞춤형 마케팅 메시지 도출 가능
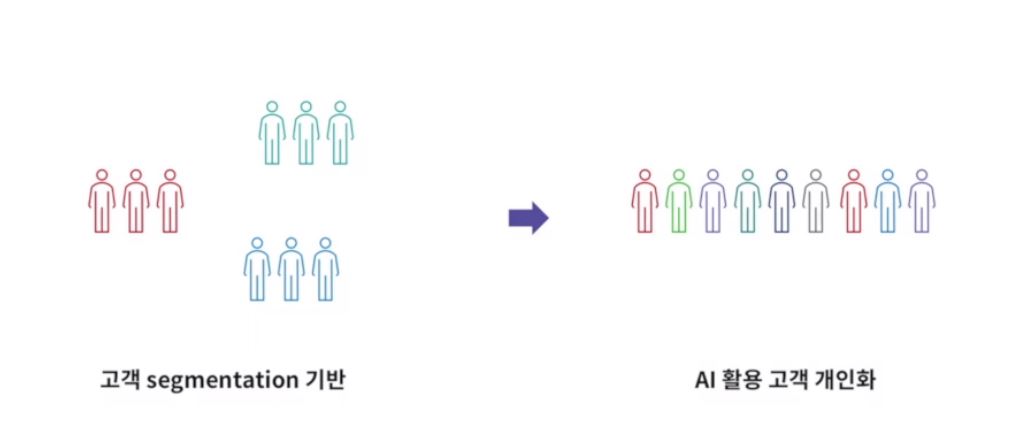
과거에는 시간과 비용의 한계로 고객을 단순한 기준에 따라 분류를 했다면, 지금은 인공지능을 활용하여 모든 고객에게 개개인의 특성을 맞춘 마케팅 메시지를 보낼 수 있다!
👉 보다 더 높은 마케팅 매출 기회를 획득할 수 있게 된다!!
고객 편의 서비스 제공
쇼핑의 편의성을 높일 수 있도록 다양한 인공지능 기술을 활용한 서비스를 제공할 수 있다.
Amazon의 AI 비서 알렉사의 경우 AI스피커를 활용하여 주문 상황 조회, 배송 조회, 제품 추천, 기존 상품 재구매 등의 다양한 편의 기능을 지원하며 이는 추가 매출 기회 획득으로 이어진다.
또한 챗봇은 고객문의에 대한 신속한 처리로 고객의 편의는 물론 다각화된 문의 대응 기능이다.
실습✍ 웹사이트는 어떻게 나에게 맞는 상품을 추천하는가?
넷플릭스 데이터를 살펴보고 인공지능 모델을 학습하는 과정을 수행해 보자
유튜브 영상을 보고 있던 중 나도 모르게 새로운 영상을 추천 받으며 보고 있지 않은가?
웹상에서 운영되는 영상, 쇼핑, 광고 기업들은 여러분에게 새로운 상품을 보여주기 위하여 인공지능을 활용한 추천 알고리즘을 사용하고 있다.
- 실습 데이터
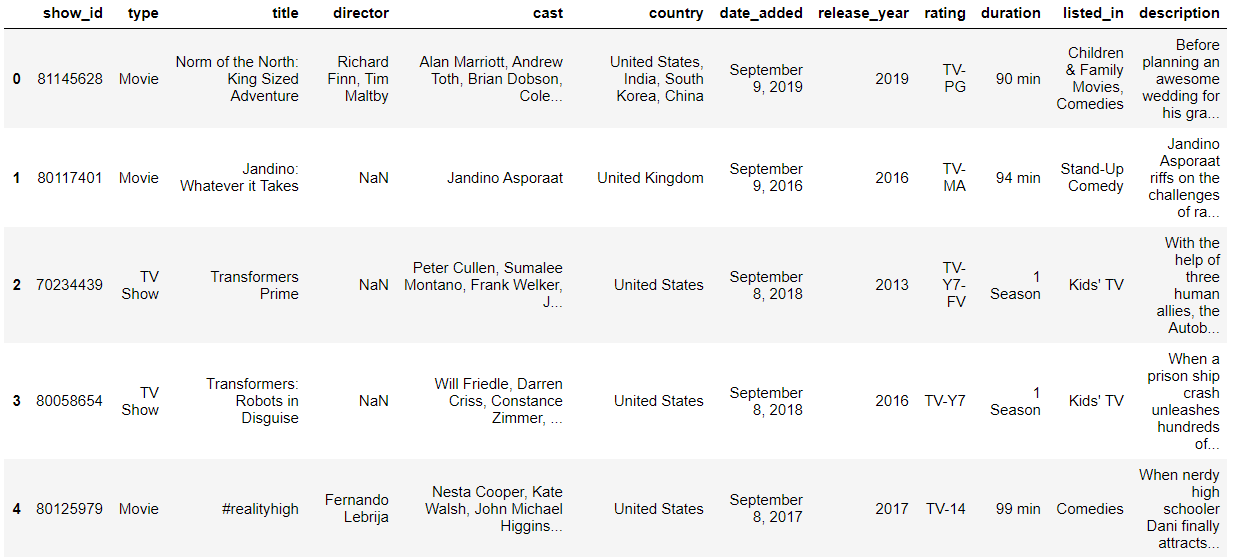
데이터에는 6234개의 콘텐츠에 대하여 12 가지 변수에 대한 값들이 저장되어 있다.
| 변수 | 의미 |
|---|---|
| show_id | 넷플릭스 콘텐츠 id |
| type | 콘텐츠 타입 |
| title | 콘텐츠 제목 |
| director | 감독 |
| cast | 캐스팅된 배우 |
| country | 국가 |
| date_added | 업로드 된 날짜 |
| release_year | 배포된 연도 |
| rating | 콘텐츠 등급 ex) 전체 이용가 |
| duration | 콘텐츠 분량 |
| listed_in | 장르 |
| description | 줄거리 요약 |
- 실습 코드
- 주어진 코드를 사용하여 인공지능 모델 학습을 수행해 보자 :
ma.preprocess()
import machine as ma
def main():
"""
지시사항 1번. 인공지능 모델 학습을 수행해보세요.
"""
netflix_overall, cosine_sim, indices = ma.preprocess()
if __name__ == "__main__":
main()
다음 실습으로 넘어가 결과를 확인해 보자
실습✍ 추천 알고리즘 결과 확인
콘텐츠 기반의 추천 알고리즘을 사용하여 새로운 콘텐츠를 추천받아 보자.
콘텐츠 기반의 추천 알고리즘은 콘텐츠와 콘텐츠 간의 유사성을 학습하여 특정 콘텐츠를 선택했을 때, 유사성이 높은 콘텐츠들을 리스트 업 할 수 있다.
따라서 사용자의 과거 시청 콘텐츠 데이터가 주어진다면 이 콘텐츠들과 유사한 콘텐츠들을 추천할 수가 있다.
이번 실습에서는 넷플릭스의 영상 콘텐츠 데이터를 입력 했을 때 유사성을 바탕으로 가장 비슷한 상위 10개의 추천 콘텐츠를 출력해보도록 하자.
- 실습 코드
- 실습 코드 내 작은 따옴표 사이에 아래 예시 중 원하는 영화명을 골라 입력하시오.
• Vagabond
• Pororo - The Little Penguin
• The Lord of the Rings: The Return of the King
• Larva
import machine as ma
def main():
netflix_overall, cosine_sim, indices = ma.preprocess()
"""
지시사항 1번. 따옴표 사이에 들어가 있는 영화명을 지우고 왼쪽 지문의 예시 중 원하는 영화명을 입력해보세요.
"""
title = 'The Lord of the Rings: The Return of the King'
print("{}와 비슷한 넷플릭스 콘텐츠를 추천합니다.".format(title))
ma.get_recommendations_new(title, netflix_overall, cosine_sim, indices)
if __name__ == "__main__":
main()- 결과
The Lord of the Rings: The Return of the King와 비슷한 넷플릭스 콘텐츠를 추천합니다.
title \
1 The Lord of the Rings: The Two Towers
2 The Darkest Dawn
3 Indiana Jones and the Kingdom of the Crystal S...
4 9
5 The Matrix
6 The Matrix Revolutions
7 V for Vendetta
8 Singularity
9 The Matrix Reloaded
10 Supergirl
country release_year Similiarity
1 New Zealand, United States 2002 0.808694
2 United Kingdom 2016 0.368605
3 United States 2008 0.287019
4 United States 2009 0.273009
5 United States 1999 0.273009
6 United States 2003 0.273009
7 United States, United Kingdom, Germany 2005 0.266733
8 Switzerland, United States 2017 0.260643
9 United States 2003 0.255377
10 United Kingdom, United States 1984 0.252861 