본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
4. 금융/재무 산업에서의 AI 혁신
금융 분야에서의 인공지능
- 업무 자동화
- 금융 편의 서비스
- 개인화된 자산 운용 서비스
- 신용평가
업무 자동화
기존의 반복 업무를 자동화하는 SW기술인 RPA(Robotic Process Automation)에 인공지능을 접목하여 스스로 판단하여 업무 수행을 하는 인지형 RPA 기술이 활용되고 있다.
기존의 업무 자동화는 규칙 기반으로 A가 발생했을 때 B를, C가 발생했을 때 D로 행동하도록 일일이 행동 양식을 지정해줘야 했다. 그러나 설계된 상황이 발생했을 때에는 정확도가 높은 대응이 가능하지만 범주에서 벗어났을 때는 대응을 할 수 없다는 치명적인 단점이 있었다!
인공지능 기반 업무 자동화가 도입되면서 다양한 사용자들의 요구에 맞춰 기계가 상황을 인식하고 판단할 수 있어 유연한 대처가 가능해졌다!
금융 편의 서비스
고객의 편의성을 높일 수 있는 인공지능 기반 인터페이스를 제공하여 송금, 조회, 이체, 금융 상품 추천, 마케팅 등의 금융 서비스를 제공하고 있다.
개인화된 자산 운용 서비스
고객의 투자성향과 투자금액에 따라 개인 맞춤형 자산 운용 서비스를 제공(≒로보어드바이저)

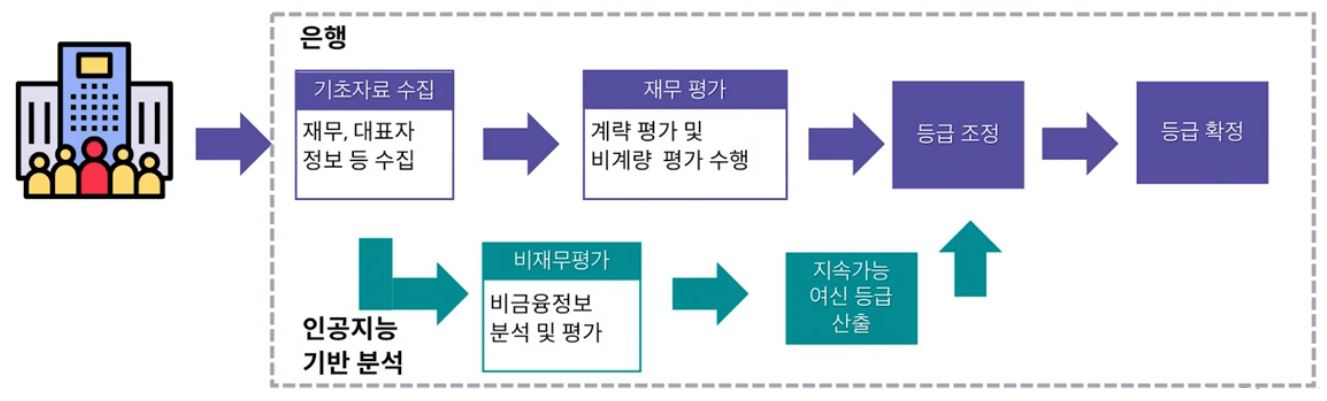
신용 평가
인공지능 기반의 기술을 바탕으로 고객의 신용 등급을 세밀하게 평가한다.
기존 금융 정보 뿐만 아니라 비금융정보까지 분석함으로써 금융 서비스 사각지대의 고객까지 서비스 범위가 확대되었다.
실습✍ 인공지능으로 주가 예측하기
주식 데이터를 바탕으로 인공지능 모델을 사용하여 미래의 주식 가격을 예측하는 과정을 수행해 보자.
- 데이터 구조 확인
본격적으로 주식 가격을 예측해보기 전 먼저 주식 데이터의 기본적인 구조 및 정보를 확인하자
데이터에는 3월 2일부터 7월 30일까지 105개의 날짜별 주식 정보에 대한 값들이 저장되어 있다.
| 변수 | 의미 |
|---|---|
| Date | 날짜 |
| High | 고가 |
| Low | 저가 |
| Open | 시가 |
| Close | 종가 |
| Volume | 거래량 |
| Adj Close | 수정 종가 |
- 실습 코드
- 아래 코드를 사용하여 출력된 데이터를 확인하고 학습을 수행해보시오.
ma.data_plot()
import machine as ma
def main():
"""
지시사항 1번. 출력된 데이터를 확인하고 학습을 수행해보세요.
"""
ma.data_plot()
if __name__ == "__main__":
main()
- 결과
...
주식 데이터의 상단 5개 행을 출력
Date High Low Open Close Volume Adj Close
0 2020-03-02 55500 53600 54300 55000 30403412 55000
1 2020-03-03 56900 55100 56700 55400 30330295 55400
2 2020-03-04 57600 54600 54800 57400 24765728 57400
3 2020-03-05 58000 56700 57600 57800 21698990 57800
4 2020-03-06 57200 56200 56500 56500 18716656 56500
주식 데이터의 하단 5개 행을 출력
Date High Low Open Close Volume Adj Close
100 2020-07-24 54400 53700 54000 54200 10994535 54200
101 2020-07-27 55700 54300 54300 55600 21054421 55600
102 2020-07-28 58800 56400 57000 58600 48431566 58600
103 2020-07-29 60400 58600 60300 59000 36476611 59000
104 2020-07-30 60100 59000 59700 59000 19285354 59000
주식 데이터의 모든 열을 출력
Index(['Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close'], dtype='object')
주식 데이터의 요약 통계 자료 출력
High Low ... Volume Adj Close
count 105.000000 105.000000 ... 1.050000e+02 105.000000
mean 51996.190476 50637.619048 ... 2.390007e+07 51310.476190
std 3278.145108 3365.597879 ... 1.152018e+07 3331.829995
min 43550.000000 42300.000000 ... 0.000000e+00 42500.000000
25% 49350.000000 48500.000000 ... 1.621493e+07 48800.000000
50% 51600.000000 50300.000000 ... 2.105442e+07 51200.000000
75% 54700.000000 53200.000000 ... 2.759696e+07 53800.000000
max 60400.000000 59000.000000 ... 5.946293e+07 59000.000000
[8 rows x 6 columns]실습✍ 파생변수 생성
주가 예측을 수행할 때 데이터에 존재하는 기존 변수 이외에 새로운 변수들이 추가될 수록 예측 성능을 높일 수 있다.
이번 실습에서는 주식 데이터에 들어있는 기본 데이터들을 가공하여 이동평균, 거래량 이동평균, 이격도 등을 계산하여 데이터프레임에 추가해보도록 하자
• 종가: 해당 날짜의 마감 주가
• 이동평균: 해당 날짜 이전 N일 간의 평균치
• 이격도: 주가와 이동평균 간의 차이 비율
- 실습 코드
- 아래 코드를 사용하여 이동평균값(MA),거래량 이동평균값(VMA) 이격도값(disp) 변수를 추가해보시오.
ma.data_preprocess()
import machine as ma
def main():
"""
지시사항 1번. 이동평균값(MA),거래량 이동평균값(VMA), 이격도값(disp) 변수를 추가해보세요.
"""
ma.data_preprocess()
if __name__ == "__main__":
main()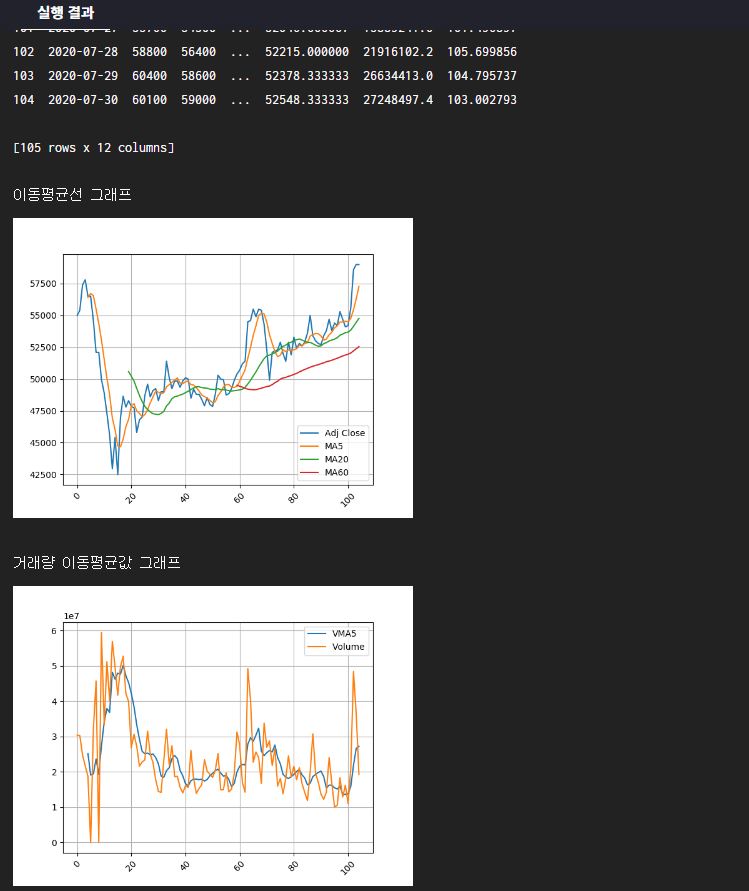
실습✍ 주가 예측 체험
이번 실습에서는 앞선 실습에서 확인한 주식 데이터를 바탕으로 딥러닝 모델을 학습시키고 이를 활용하여 주가 예측을 수행해보자
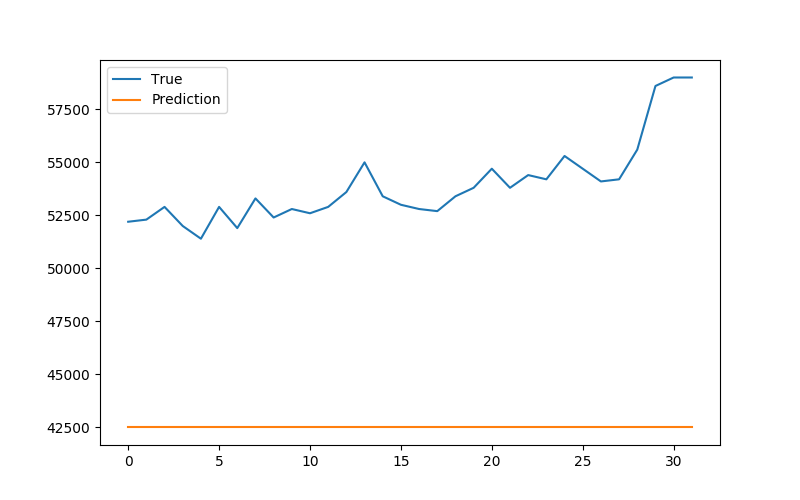
출력된 그래프는 2020년 7월 1일부터 30일까지의 종가를 비교하는 그래프로 파란선은 실제값을 의미하며, 노란선은 예측값을 의미한다.
- 실습 코드
- 아래 코드를 사용하여 딥러닝 모델의 학습과 예측을 수행해보시오.
ma.train()
import machine as ma
def main():
"""
지시사항 1번. 딥러닝 모델의 학습과 예측을 수행해보세요.
"""
ma.train()
if __name__ == "__main__":
main()