참고자료
1. 강필성 교수님 강의
2. https://en.wikipedia.org/wiki/Association_rule_learning
연관 규칙 분석
연관 규칙 분석의 정의
연관 규칙 분석이란 item set X,Y에 대해 'X를 사면 Y를 산다.'와 같은 규칙, 즉 X->Y 에 해당하는 X,Y를 찾아내는 것이다.
이때, X는 Antecedent (조건절), Y는 Conequent (결과절)로 부른다.
연관 규칙 분석은 알고리즘은 장바구니 분석이라고도 불린다.
연관 규칙 분석을 위한 dataset 구성
우리는 연관 규칙 분석을 위해서 item matrix를 구성하여 이용하기도 하는데, item matrix는 다음과 같다.
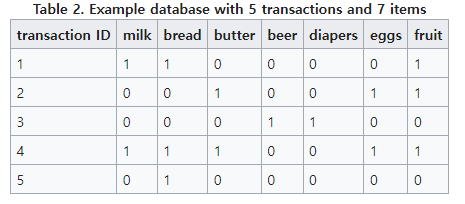
- transaction은 영수증을 의미하며, 나머지 각각의 열은 item을 의미한다.
용어 및 특징
-
item set - item 들의 집합이다. 위의 dataset의 경우 {milk}, {butter, beer} 등이 될 수 있다.
-
Antecdent : 조건절, item set 에서 하나의 원소가 된다.
-
Cosequent : 결과절, item set 에서 하나의 원소가 된다.
-
Antencedent -> Consequent 에서 각각의 절의 원소는 교집합이 없어야 한다.
ex) {milk, bread} -> {bread,butter} 와 같은 규칙은 없다.
규칙의 지표
우리는 item set의 개수가 늘어날수록 X->Y에 해당하는 조건을 많이 찾을 수 있다.
이러한 조건들이 얼마나 믿을 수 있는 조건인지 판별하는 기준으로 세 가지가 있다.
Support (지지도)
조건절이 발생할 확률로 이게 지표가 되는 이유는 조건일 발생해야 규칙을 적용할 기회가 높아지기 때문이다.
교과서적으로는 조건절이 발생할 확률이지만, 조건절과 결과절이 함께 발생할 확률로도 쓰이기도 한다고 한다.
해당 post에서는 강필성 교수님 강의에 맞춰 전자로 간주한다.
Confidence (신뢰도)
조건절이 일어났을 때, 결과절이 일어날 확률
Lift (향상도)
A와 B가 독립, 즉 아무런 연관이 없었을 확률과 동시에 일어날 확률 비교
Lift = 1 : 둘은 독립, 아무런 영향 없음
Lift > 1 : 둘은 긍정적 연관이 있음
Lift < 1 : 둘은 부정적 연관이 있음
직관적으로 Lift를 이해해보면, A와 B가 동시에 들어갈 확률이 분자에 들어가므로,
만약 정말 A->B 라는 조건이 맞다면 A, B가 함께 들어갈 것이므로 Lift는 증가할 것이다.
반면, 소주와 타이레놀과 같은 경우는 둘이 동시에 구매하는 경우가 없기 때문에, Lift는 1보다 작아지게 되고 둘 사이는 부정적 연관이 있다고 볼 수 있다.
Lift가 필요한 이유
기본 아이템이 결과절에 들어간 경우 confidence = 1이 나오기 때문에, 이때, confidence는 적절한 규칙의 기준이 되지 못한다.
예를 들어, 맥주집의 경우 맥주는 무조건 시키기 때문에 Support(피자 -> 맥주), Support(치킨 -> 맥주) 모두 1이 나오게 된다.
규칙 만들기
데이터에서 규칙을 만들고 위에서 본 규칙의 평가 지표를 활용하여 좋은 규칙을 찾아낼 수 있다.
하지만 이때, 모든 규칙을 다 보게 된다면 계산량이 너무 많아지게 된다.
그래서 A priori 알고리즘을 적용한다.
A priori algorithm
어차피 규칙을 찾은 후에 평가 지표를 적용할 거, 차라리 미리 적용하는 알고리즘으로 이해해볼 수 있을 것 같다.
그래서 애초에 이 알고리즘은 frequent item sets에 대해서만 고려한다.
이때, frequent item sets란 평가 지표였던 support의 임계점을 넘는 item set들이다.
이게 중요한 점은 만약 {milk}의 support가 임계치를 넘지 못했다면, {milk, bread} 또한 support가 임계치를 넘지 못하는 것은 자명하기 때문에 앞으로는 모든 milk가 들어간 item을 고려할 필요가 없다는 것이다.
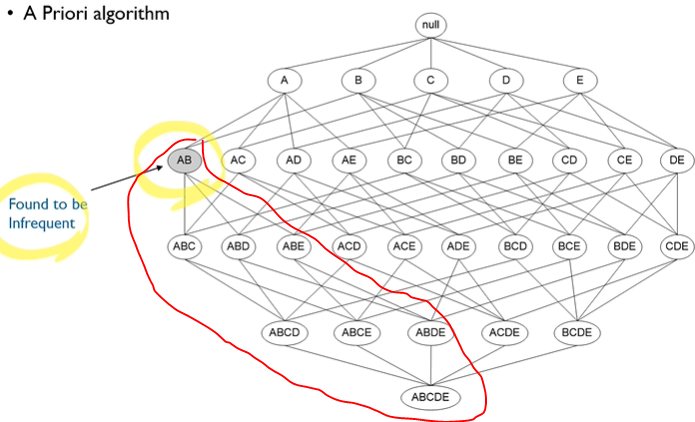
따라서 위에서 빨간색 부분은 애초에 규칙의 조건절로 고려를 하지 않아도 된다.
알고리즘 또한 물건 1개만 살 경우에서부터 시작하여 하나씩 늘려보면서, 위에서 본 것처럼 support의 임계치를 넘지 못하면 그의 super set을 제거하는 방식으로 작동한다.
