BM25
BM는 검색을 위한 ranking function이다.
이는 TF-IDF 와 마찬가지로 lexical한 의미를 기반으로 점수를 매기는 방법이다.
가장 대표적인 식은 다음과 같이 계산된다.
: document D
: query, 는 query word 들
: Inverse Document Frequency, 많은 문서에 단어가 있으면 덜 중요
: document D 길이 / 전체 문서 평균 길이, 지금 문서가 얼마나 긴 문서인지 생각
: 단어 q_i가 D에서 얼마나 등장했는지, term frequency
: parameter
b의 역할
b는 문서가 길수록 tf 값이 늘어날 것이므로 이를 보정해주기 위해 있는 값의 정도를 나타낸다.
0인 경우 이 값은 반영이 되지 않고, 1인 경우 모두 반영된다.
일반적으로는 0.75를 쓴다고 한다.
의 역할
포화속도를 정한다고 이해할 수 있다.
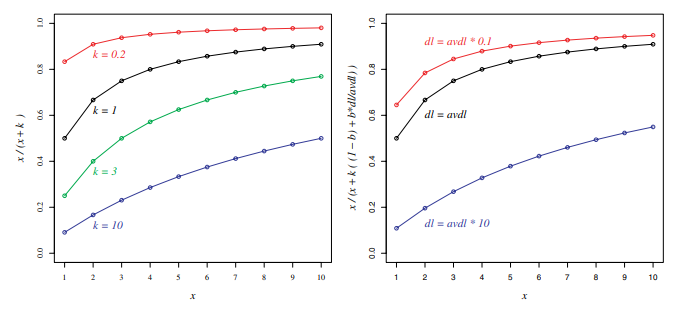
그래프를 보면, k가 작을수록 빠르게 포화되어 tf가 증가되어도 거의 점수 상승이 업슨 것을 볼 수 있다.
즉, 어느 정도 단어가 많이 등장하는 것까지는 의미가 있고 그 이후로는 영향이 미미하게 되는데, 이 임계점을 정하는 것 정도로 해석할 수 있다.
참고자료
https://www.staff.city.ac.uk/~sbrp622/papers/foundations_bm25_review.pdf
IDF는 여러 variations가 있지만 다음과 같이 계산된다.
: 전체 문서 수
: 해당 단어를 포함한 문서의 개수
식의 의미를 해석해보면 해당 단어를 포함한 문서의 개수가 많아질수록 값은 0에 가까워지는 것을 볼 수 있다.
