DPR 논문 리뷰
Abstract
- 기존 검색 방법인 Sparse embedding을 사용한 검색 방법인 TF- IDF 또는 BM25 처럼 Lexical한 방법이 아닌 Dense embedding을 사용한 Semantic한 방법 성능이 좋다.
- Dense embedding은 적은 수의 question and passages 로 학습을 시킬 수 있다.
- Dense embedding을 위해 Question encoder와 Passage encoder 2개가 존재
- 여러 QA 데이터셋에 적용해보니까 실제 BM25를 사용한 방법보다 약 9% ~ 19% 성능 향상이 있었다. multiple ODQA benchmarks에도 도움을 준다
1. Introduction
- QA task는 보통 two stage framework 구조를 가짐.
- retriever : 정답이 있을만한 후보를 가져오는 모델
- reader : retrieved contexts에서 정답을 추출하는 모델
- Dense embedding의 장점
- semantic 한 의미를 학습하기 때문에 paraphrasing된 단어도 잘 찾음
- ex) ‘bad guy’와 ‘villan’, 두 단어는 전혀 다른 생김새지만 의미가 비슷함
- 의미를 ‘학습’하는 것이기에 a task-specific representation도 잘 학습할 수 있는 flexibility
- MIPS 알고리즘을 활용하여 효율적으로 검색을 수행할 수 있음
- semantic 한 의미를 학습하기 때문에 paraphrasing된 단어도 잘 찾음
- Dense embedding의 단점
- 좋은 학습을 위해서는 많은 수의 pairs of question and context가 필요함
- 근데 이거 ICT 방법이 해결
- ICT 방법이 BM25 뛰어넘음
- ICT 방법의 2가지 약점
- 연산량이 많으며, regular sentences가 question의 좋은 대체제가 되지 못함
- Context encoder는 question - answers 페어로 fine-tuning 되지 않기 때문에 최적이 아닐 것이라는 점. ( context encoder 학습은 ICT 방법이라 passage만 보고 학습함)
- DPR 방법은 ICT와 달리 additional pretraining 없이, 적은 수의 pairs of question and passage만 이용해서 학습
- DPR에서는 standard BERT와 Dual encoder 구조 ( for question, for passage)
- DPR은 retrieval 성능도 끌어올리고 end to end QA acc도 향상시킴 ( NQ dataset에서 )
- 이 논문에의 기여 2가지
- pretraining 없이 간단한 fine tuning the question and passage encoders 로 충분
- (당연해보이지만) 좋은 retrieval 성능은 좋은 end to end QA 정확도로 이어짐
2. Background
- 간단한 ODQA 배경 설명
- Document를 일정 단위로 쪼개서 passage 만듦,passage 들이 모여서 Corpus 집합.
- passage는 단어의 집합이고 우리는 passage에서 답이 될만한 answer span 찾는 것
- 이떄 retriever의 역할은 Corpus의 집합에서 정답이 있을만한 부분집합 C_retireved 찾는 것
- 부분집합의 크기를 k로 고정하여 top k accuracy 등으로 retriever 평가 가능
3. Dense Passage Retriever (DPR)
- triplet loss
3.1 Overview (DPR의 과정)
- passage들을 passage encoder를 이용하여 d(=768)차원을 가지는 embedding 공간에 사전에 배치
- question을 question encoder를 이용하여 d(=768) 차원을 가지는 embedding 공간에 위치
- 이때 question embedding vector와 가장 가까운 top k 개의 passage embedding vector 선별
- 가까운 기준 = Inner Product (=Dot Product)
- 계산 효율성을 위해 decomposable한 유사도 계산 법 중 선택
- Euclidean 거리도 써봤는데 실험 결과 Dot Product가 더 좋음
- Encoder는 BERT 사용, → d = 768
- FAISS 이용하여 효율적으로 indexing
3.2 Training
- Loss 는 NLL(Negative Log Likelihood)을 사용해서 다음과 같이 구성
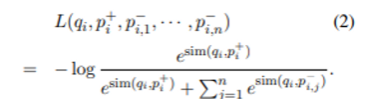
- $q_i$ : question i의 embedding
- $p_i^+$ : positive (gold) passage, = 해당 question i에 대한 정답을 포함하는 passage
- $p^-_{i,k}$ : negative passage, = 해당 question의 정답과 관계없는 passage
- loss가 최소화 되기 위해서는 gold passage와의 유사도가 최대한 올라가고 negative passage와의 유사도가 최대한 낮아져야 함.Positive and negative passages
- negative set을 3가지 종류로 나눔
- Random
- random passage from the corpus (무작위)
- BM25
- BM25 score가 높지만 정답이 들어있지 않은 passage
- lexical한 유사도는 가장 높지만 정답이 아닌 passage
- Gold passage of other questions in batch
- 같은 batch 안에 있는 다른 question의 답 passage
- computation efficient
- Random
In - batch negatives
- Batch 안에서 다른 question의 정답 passage를 negative passage로 활용하여 passage 단 B개 만으로 B X B 크기의 Similiarity matirx 만들 수 있음
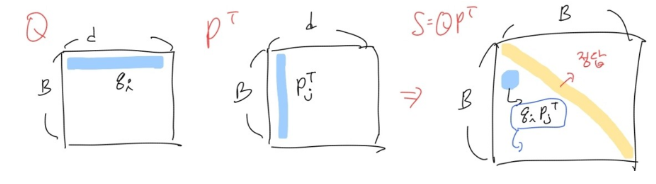
- B : batch size
- d : dimension of embedding
- Q : B 개의 question embedding matrix
- P : B 개의 question embedding matrix
- $S=QP^T$ : B x B 크기를 가지는 유사도 matrix4. Experimental Setup
4.1 Wikipedia Data Pre-processing’
- article들 전처리 하고, 중복되지 않는 100 words로 끊어서 passage 구성
- WIkipedia dump를 위 방식대로 전처리 했더니 21,015,324 passage 만큼 나옴
- 이때 Each passage에 article의 title 과 [SEP] 토큰을 함께 넣음
- ex) Title of the article [SEP] Passage
4.2 Question Answering Datasets
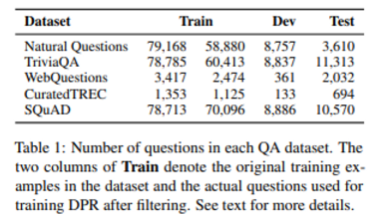
- 데이터는 위와 같은 목록으로 사용
- 여기서 주목할만한 데이터셋은 SQuAD인데, 이 데이터는 질문을 passage를 보고 작성했기 때문에 question과 passage의 유사도가 context 적인 부분이 상대적으로 적고, lexical한 부분이 큼.
5. Experiment: Passage Retrieval
- 실험에서 DPR을 학습시킬 때 negative setting은 batch size 128에 question 하나 당 추가적인 BM25 negative 추가
- 즉, 하나의 passage 당 negative는 127 (other gold) + 128 (BM hard) = 255개
5.1 Main Result
DPR과 BM25의 성능 비교
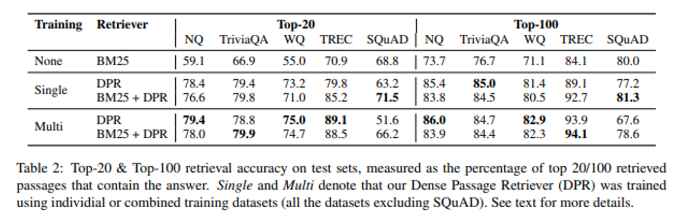
- Multi 는 SQuAD를 제외하고 학습한 것을 의미
- BM25 + DPR은 lexical한 의미와 semantic한 의미를 모두 담기 위해 BM25 score와 DPR score 합침
- 우선 전체적으로 기존 BM25 방법보다 DPR이 성능이 좋은 것을 확인할 수 있음
- SQuAD의 경우 BM25 + DPR acc가 DPR acc 보다 항상 좋은데, 이 원인을 논문은 2가지 측면에서 제시
- SQuAD 데이터의 생성과정 상 lexical한 matching이 원래 높음
- SQuAD 데이터셋은 고작 500개 정도의 article에서 나왔기 때문에 학습 데이터 분포에서부터 편향이 존재함
- 2번에 대한 근거는 다른 모든 데이터셋에서는 Multi Dataset으로 학습시킨 즉, 더 많은 데이터셋으로 학습시킨게 더 높은데, SQuAD는 Single Dataset 즉, 편향이 존재하는 SQuAD 학습 데이터로 학습시킬 때가 더 높음
- 위 결과에서 흥미로운 점은 SQuAD 데이터셋에서 BM25만을 쓴 결과보다 BM25 + DPR 이 더 결과가 좋다는 점이다. 이는 문맥적 의미도 섞어주는게 좀 더 안정적인 모델이 될 수도 있음을 의미하는 것 같다
5.2 Ablation Study on Model Training
Sample efficiency
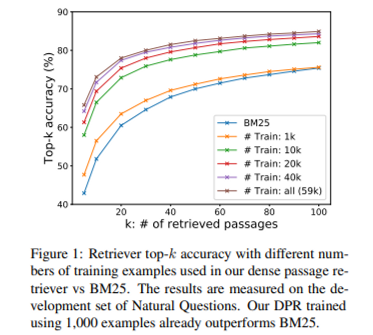
- 적절한 pretrained 된 model만 있다면 1000개의 training examples만 가지고도 기존 BM25를 뛰어넘음
In-batch negative training
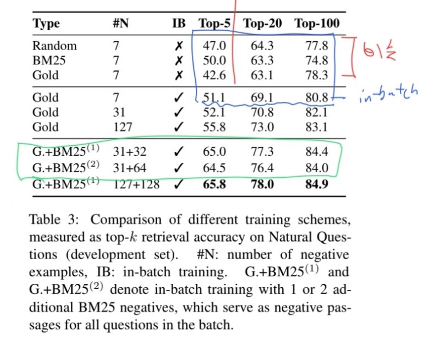
- 빨간색 부분을 보면 in batch negative를 쓰지 않는 상황에서 negative를 쓰더라도 top 20 이후로는 비슷한 것을 볼 수 있음
- 파란색 부분을 보면 똑같이 Negative 수가 7인데 In batch negative를 사용한게 더 성능이 좋음을 알 수 있음
- 전체적으로 보면 Gold에 BM25 negative 를 사용했을 때 효과적이지만 초록색 부분을 보면 BM25 negative를 passage 당 2개 넣었을 때는 큰 효과가 없는 것을 확인할 수 있음
Similarity and loss
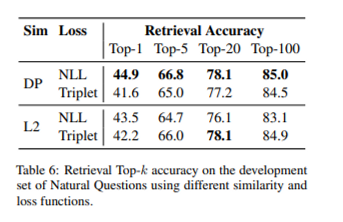
- 유사도를 구하는 기준으로 논문에서 사용한 dot product 분만 아니라 L2, cosine도 사용했는데 dot product와 L2가 비슷하게 좋고 cosine은 별로 안좋음
- NLL 이 Triplet 보다 좋음
Cross-dataset generalization
- DPR의 일반화 능력을 실험하기 위해 train은 NQ 데이터셋으로 하고 평가는 WebQuestions와 CuratedTREC로 했음
-
BM25 보다 좋으며, best fine-tuned 모델에 비해 성능 차이가 얼마 안남
WebQuestions TREC BM25 55 70.9 DPR(trained_NQ) 69.9 86.3 best fine-tuned 75 89.1
-
5.3 Qualitative Analysis
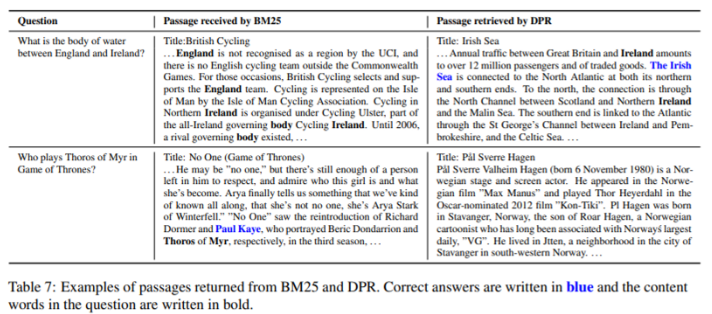
- 테이블에 보면 좌측은 BM25 검색 결과인데, Question과 매칭이 엄청 많은 lexical 유사도가 높은 문서를 가져왔는데 정답이 없는 경우가 위쪽, 정답이 있는 경우가 아래쪽
- 반면, 우측의 DPR은 lexical 유사도가 하나도 없음에도 정답을 찾아내기도 함
5.4 Run-time Efficiency
- 질의를 찾는 시간은 FAISS를 이용한 인덱싱을 사용한다면, DPR은 초당 995개의 질문 BM25 방법은 23.7개의 질문을 처리함
- 하지만 인덱싱 과정에서 DPR은 8.5시간, BM25는 역색인을 이용하면 30분 걸림.
6. Experiments: Question Answering
6.1 End-to-end QA System
- ODQA 의 구조
Retirever
-
문서 k개 가져오기
Reranker
-
문서 k개 재정렬
-
이때, cross attention 모델을 사용함,
- 이 방식이 Retriever의 dual encoder보다 성능이 더 좋음
- 그럼에도 불구하도 Retriever에서 애초에 cross attention을 사용하지 않는 이유는 passage의 score를 구하는 함수가 분해불가능하기 때문!
- 그래서 Retriever가 가져온 k개의 문서만을 대상으로 question과 유사도를 구함Reader
-
Reader는 3가지 확률식을 기반으로 파라미터를 학습함
- : L은 passage 단어 수, h는 각각 단어 embedding 차원
- : 여기서 k는 우리가 가져온 k개의 문서를 의미
- 이때, a span score는 으로 정의함
- 위 식을 기반으로 Reader는 marginal - log liklihood 사용해서 파라미터 를 학습함
-
6.2 Results
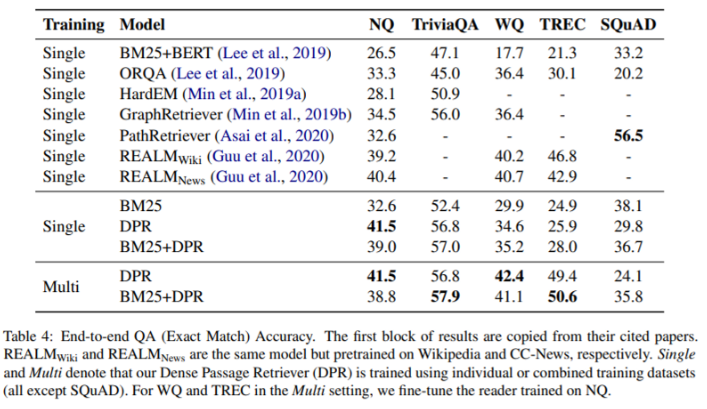
- score는 End-to-end 결과로 나온 answer과 실제 정답 간 EM score 사용
- 같은 Reader를 사용한 BM25와 DPR의 성능차이를 보면 Retrieval을 잘하면 end-to-end 점수가 오름
- large dataset인 NQ 같은 경우 Single과 Multi 차이가 거의 안나는데 small dataset WQ, TREC의 경우 확실히 Multi가 높음
- 추가적인 pretraining을 해야하고 비싼 training cost를 가진 ORQA, REALM를 dataset이 큰 NQ와 TriviaQA에서 DPR이 능가함
- dataset이 작을 경우에는 다른 데이터셋으로 같이 학습시켜서(Multi) 성능 향상 가능
7. Related Work
- Augmenting text-based retrieval with external structured information
- dense representation retireval
- cross-attention
- reformulated question vectors
- skip pasage retireval (DenSPI)
- jointly training
- REALM
- Hard negative
- n-1 번째 학습한 모델이 추측한 passage를 n 번째 학습할 때 negative로
- reader 모델을 T5나 BART와 결합
8. Conclusion
- dense retrieval 의 가능성을 보여줌
- 간단한 구조를 가진 dual - encoder로 성능을 뽑아낸 것으로 복잡한 구조가 필요 없음을 시사함
